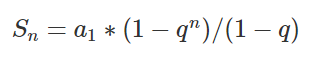课程目标
这节课准备再学习下训练模型的基本流程,因此还是选择快速入门课程。
整体流程
整体介绍下流程:
- 数据处理
- 构建网络模型
- 训练模型
- 保存模型
- 加载模型
思路是比较清晰的,看来文档写的是比较连贯合理的。
数据处理
看数据也是手写体数据集的例子。
他们把数据都放存储了一份,可以通过设置获取到训练集合和测试集合。
构建了一个以64为一批的包:
可以迭代获取到数据:

整体来说获取数据的部分还是比较清晰的。
网络构建
构建网络的方法和pytorch是比较接近的:

可以看出来,将数据先打平,然后放到全链接层,之后经过relu,再经过两个循环就构建好了网络。
模型的样子差不多是:

模型训练

通过截图可以看出来,损失函数和优化器都依次进行定义。注意这里使用的是交叉熵损失函数,所以要求的label是[batch_size],logits是[batch_size, num_class]。
损失函数的实现逻辑:
import numpy as np
def softmax(logits):
exp_logits = np.exp(logits - np.max(logits, axis=-1, keepdims=True))
probs = exp_logits / np.sum(exp_logits, axis=-1, keepdims=True)
return probs
def cross_entropy_loss(logits, labels):
probs = softmax(logits)
batch_size = logits.shape[0]
# 取出正确类别的概率
correct_log_probs = -np.log(probs[np.arange(batch_size), labels])
# 计算平均损失
loss = np.sum(correct_log_probs) / batch_size
return loss
# 示例
logits = np.array([[2.0, 1.0, 0.1], [1.2, 0.9, 3.2], [0.5, 2.1, 0.3]])
labels = np.array([0, 2, 1])
loss = cross_entropy_loss(logits, labels)
print(f'Loss: {loss}')
在这个实现中:
softmax 函数对 logits 进行 softmax 操作。
cross_entropy_loss 函数计算交叉熵损失。
np.log 计算负对数概率。
np.arange(batch_size) 创建一个数组 [0, 1, 2, …, batch_size-1] 用于选择正确类别的概率。
通过最上面训练的代码也可以看出来,每一个step会进行一次计算优化器,获得loss。然后每100个step输出一次数据。
在整体的更上层,执行了3个epoch。

保存模型

加载模型
整体看着也挺简单的:

打卡
完结撒花,打卡。

总结
今天又过了一次,从构建数据到构建模型,和训练的整体过程都介绍完毕了。这里的模型很简单,所以训练的时候也很简单。如果是大语言模型的训练过程,需要使用到更复杂的处理逻辑,可能会依赖DeepSpeed进行并行训练。希望在接下来的学习中有机会接触到。