前言
最近做项目,需要写一个controller(k8s的插件),需要从k8s的apiserver取数据,就用了自带的client-go,但是client-go是怎么从apiserver获取数据的一直没有研究过,只是看网上,看官方文档说是chunk读取数据,然而事实上,笔者却发现使用http2.0的长轮询。强烈建议使用linux或者mac开发机。
1. client-go demo
demo实际上就是官方代码,这段代码是网上流传的经典代码
client-go v0.25.3
kubernates 1.25.4
config, err := clientcmd.BuildConfigFromFlags("", "~/.kube/config")//注意路径
if err != nil {
log.Fatal(err)
}
//这2行是抓包的时候使用,日常是不需要的
config.TLSClientConfig.CAData = nil
config.TLSClientConfig.Insecure = true
clientSet, err := kubernetes.NewForConfig(config)
if err != nil {
log.Fatal(err)
}
//这里可以调一些参数,defaultResync很关键
factory := informers.NewSharedInformerFactoryWithOptions(clientSet, 0, informers.WithNamespace("default"))
informer := factory.Core().V1().Pods().Informer()//获取pod的informer,实际上使用client-go的api很多informer都创建了,直接拿过来用,避免使用的时候重复创建
informer.AddEventHandler(xxx) //事件处理,是一个回调hook
stopper := make(chan struct{}, 1)
go informer.Run(stopper)
log.Println("----- list and watch pod starting...")
sigs := make(chan os.Signal, 1)
signal.Notify(sigs, syscall.SIGINT, syscall.SIGTERM)
<-sigs
close(stopper)
log.Println("main stopped...")demo构建好了,实际上就可以在k8s启动后运行,本质上k8s的监听就是apiserver发送指令,驱动k8s的各个部件干活,驱动的本质的http的“推送”,为了真实的还原,使用抓包工具抓包分析,随便写一个deployment的yaml文件,可以自行构建,以官方文档为例Deployments | Kubernetes
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-deployment
labels:
app: nginx
spec:
replicas: 2
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx:1.14.2
ports:
- containerPort: 80因为笔者本地跑的东西比较多,节省资源就部署2个pod
2. apiserver抓包分析
针对刚刚到官方yaml,使用
kubectl apply -f xxx.yaml
即可部署deployment的pod,通过创建ReplicaSet创建POD
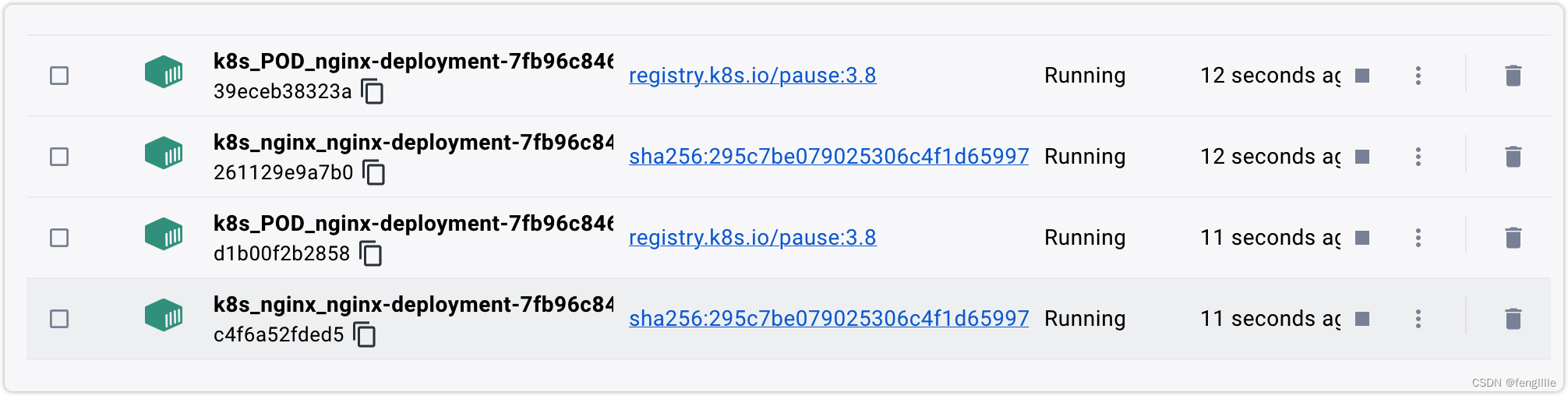
可以看到部署的POD,pause容器是k8s的定义容器,定义pod的网络等资源。以本地docker-desktop为例,对于本地,可以通过设置修改,看到k8s的容器
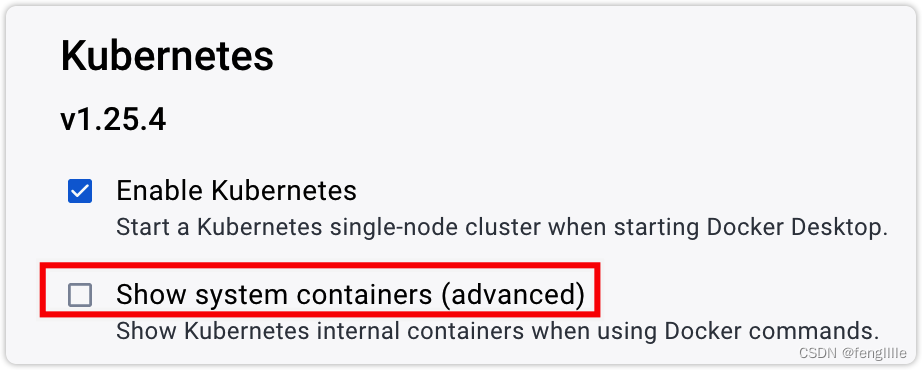
当然也可以使用kubectl。

2.1 抓包方式
实际上抓包方式总类很多,概括实现主要有2种,代理和复制,比如典型的VPN和tcpdump。代理比较好说,就是中间代理,在istio的时候envoy就是iptables代理;tcpdump也是linux很常用的方式,比如笔者以前讲的goreplay,使用pacap,通过bpf技术。
抓包工具wireshark就是tcpdump的典型实现,但是因为配置证书麻烦,所以此次使用代理抓包,也可以tcpdemp后使用wireshark分析,注意tls1.2和tls1.3的区别,tls1.3解包更困难,因为生成非对称的秘钥是算法动态生成的,相对tls1.2比较好解包。
这2个抓包工具是3个平台都有安装包的
实战wireshark
执行 sudo chown -R xxx:admin /dev/bpf*
然后抓取本地网卡,127的ip选择lo0即可,过滤port:tcp.port == 6443(6443是本地k8s的apiserver的端口,一般tls的端口默认443)
执行kubectl delete deployment nginx-deployment
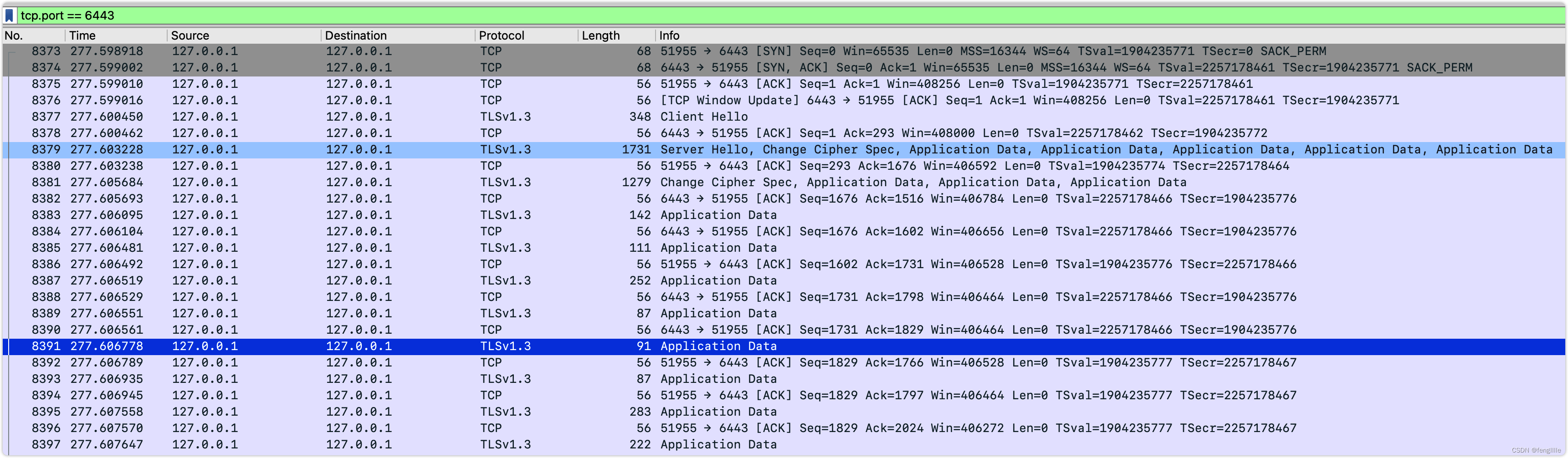
tls1.3 ,看来解包不容易,笔者查询资料,有ali的社区说可以使用代理解包,相对比较容易,笔者也试了,确实可以,但是有个问题文章没提到如何通过抓包来查看Kubernetes API流量-阿里云开发者社区 (aliyun.com)
可能是史上最全的Kubernetes证书解析 (qingwave.github.io)
实战charles
# 提取出客户端证书
grep client-certificate-data ~/.kube/config | \
awk '{ print $2 }' | \
base64 --decode > client-cert.pem
# 提取出客户端私钥
grep client-key-data ~/.kube/config | \
awk '{ print $2 }' | \
base64 --decode > client-key.pem
# 提取出服务端CA证书
grep certificate-authority-data ~/.kube/config | \
awk '{ print $2 }' | \
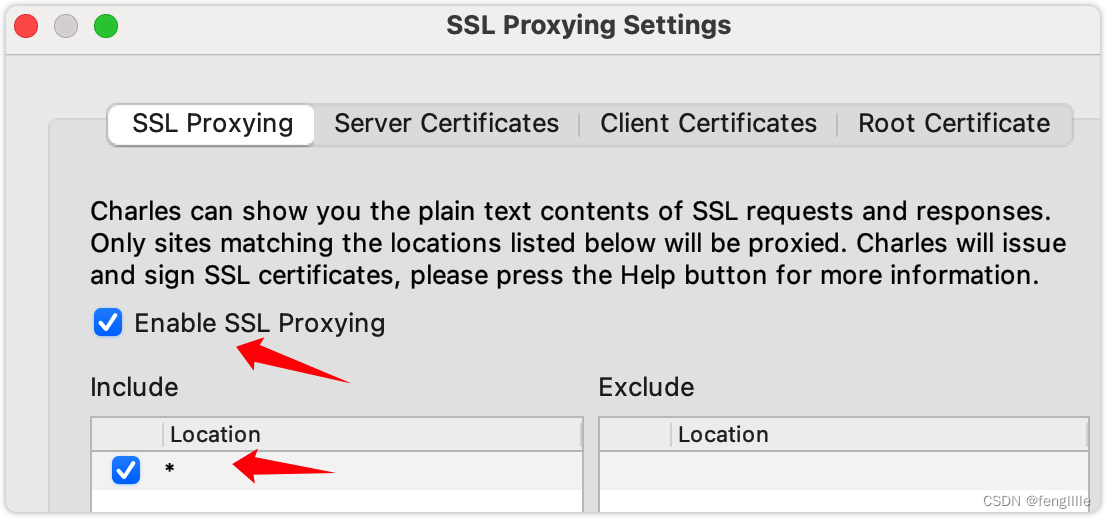
base64 --decode > cluster-ca-cert.pem提取kube的证书信息

![]()
导入文本,private key是私钥;cert是证书,里面有公钥,非对称加密。
勾上,k8s使用http2
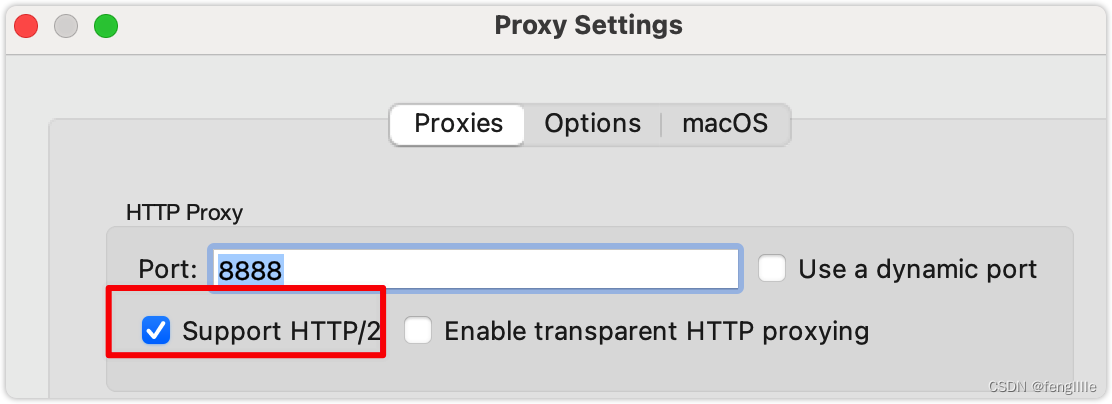
此时只想kubectl需要配置https_proxy,否则还是会直连
export https_proxy=http://127.0.0.1:8888/
如果不使用了,可以使用
删除,但是只对此次操作有效
export -n https_proxy=http://127.0.0.1:8888/
unset ,只会在当前环境有效
unset https_proxy
配置代理会出现证书不认识,可以把charles证书加入系统信任
huahua@huahuadeMac-mini kube % kubectl get pod
Unable to connect to the server: x509: certificate signed by unknown authority执行代理后,证书认证是不过的,因为charles代理了请求。需要忽略证书认证,或者导入charles的证书,避免麻烦,直接忽略吧
kubectl --insecure-skip-tls-verify get pods -A
huahua@huahuadeMac-mini kube % kubectl --insecure-skip-tls-verify get pods
Error from server (Forbidden): pods is forbidden: User "system:anonymous" cannot list resource "pods" in API group "" in the namespace "default"就是没权限,本地很好解决,用cluster-admin的权限角色给过去
huahua@huahuadeMac-mini .kube % kubectl create clusterrolebinding test:anonymous --clusterrole=cluster-admin --user=system:anonymous
clusterrolebinding.rbac.authorization.k8s.io/test:anonymous created至此抓包成功,代理后使用的tls1.2连接apiserver。如果是tls1.3还会麻烦点
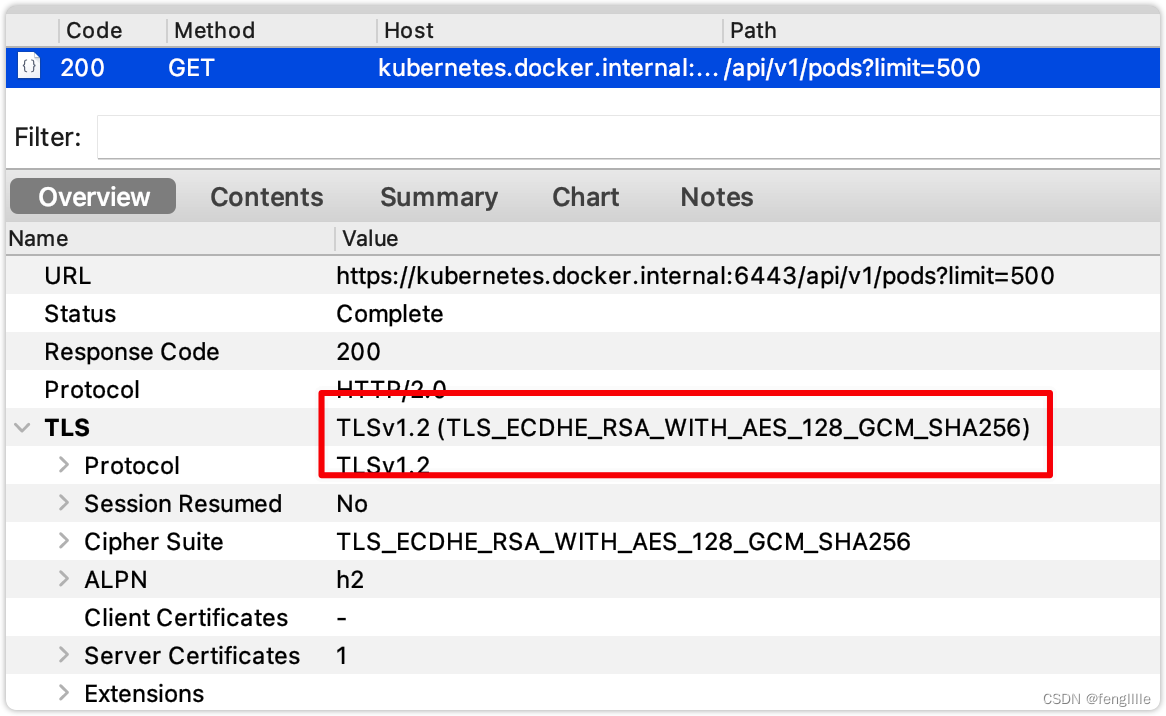
执行上面demo的代码
go build -o kube_listen .执行代理配置
export https_proxy=http://127.0.0.1:8888/./kube_listen #执行程序
执行
kubectl --insecure-skip-tls-verify apply -f nginx-deployment.yaml
分析抓包
对于监听程序抓包如下,实际上kubectl也是使用http访问apiserver,也可以被抓包到。

启动时会监听2个api,以demo的pod为例,实际上就是ListAndWatch的结果
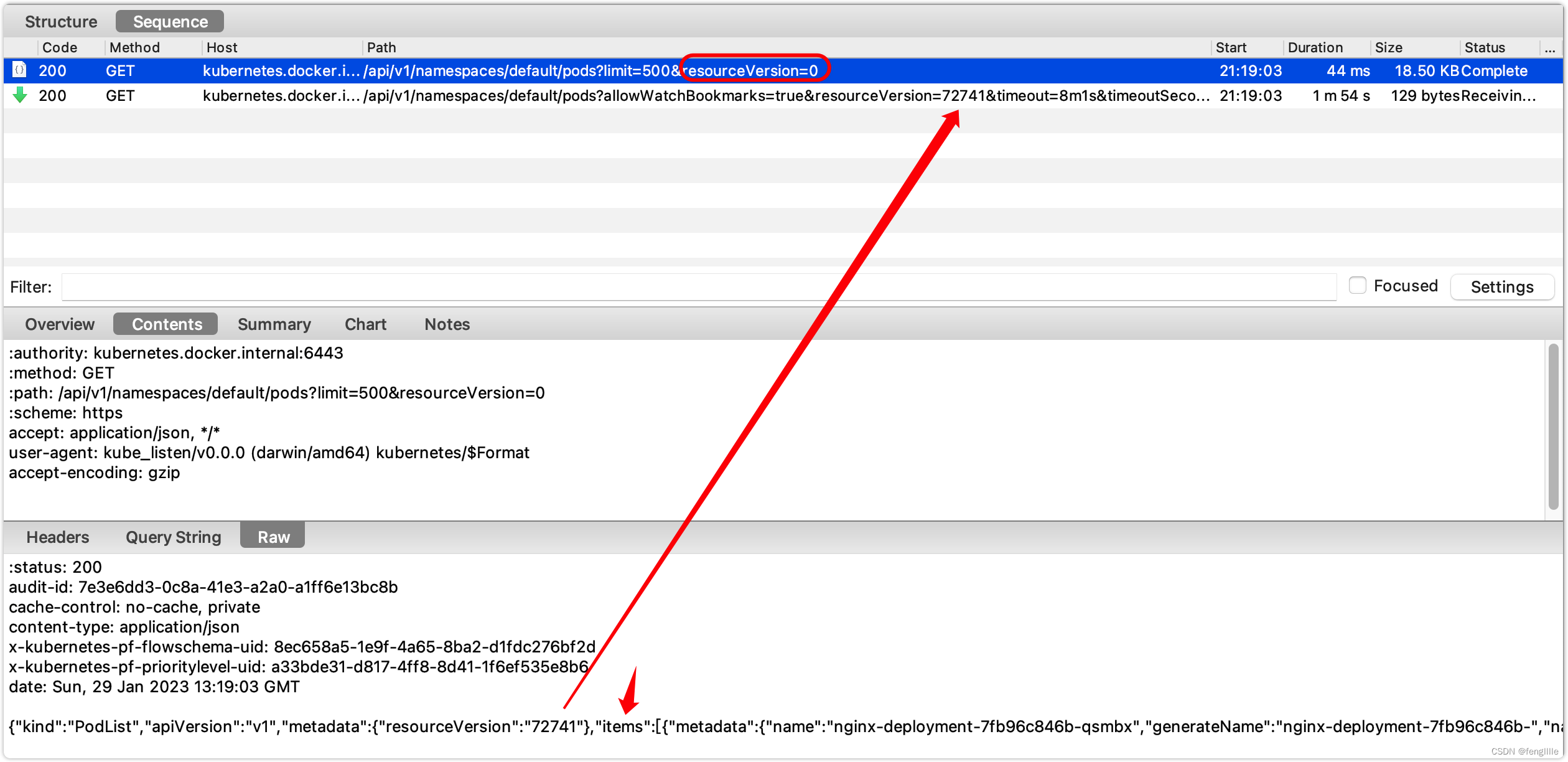
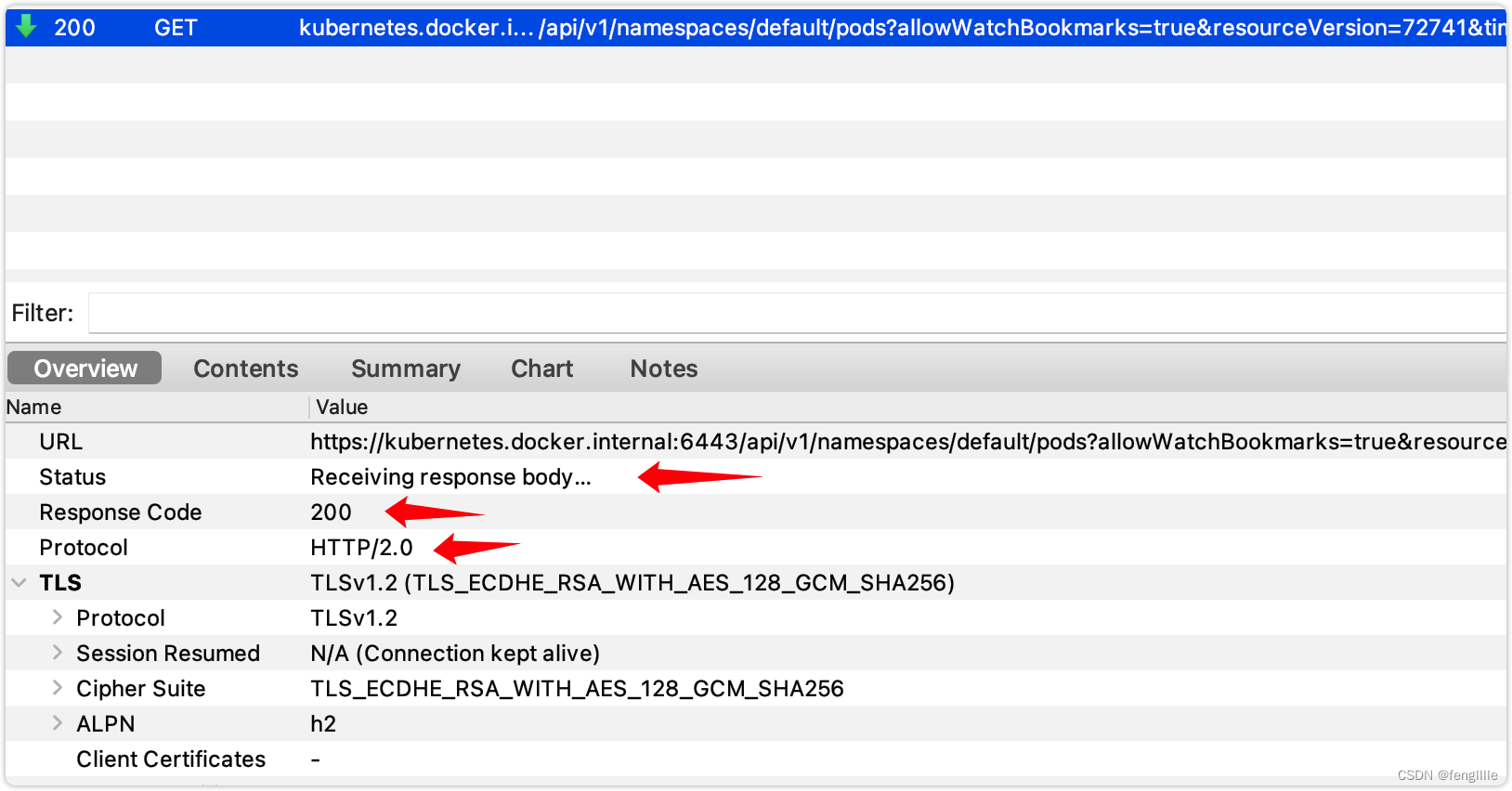
这个就是List的API。
首先发起请求,访问现在存在的pod数据,并且获取当前最新的资源版本(版本控制) ,Watch的接口。
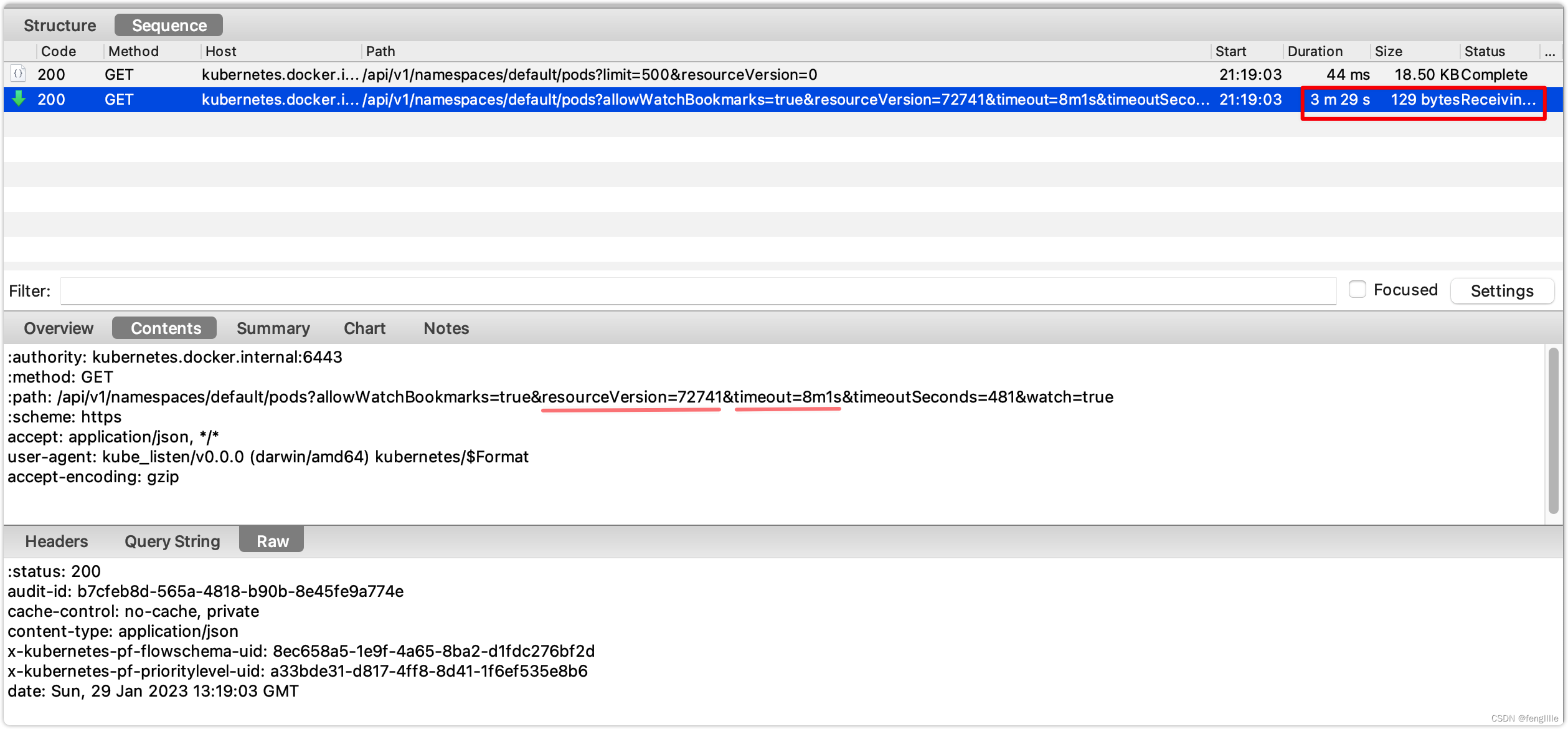

到了超时时间,发起新的请求
然后使用新版本号读取新的变更资源,读取是个长轮询的过程,且还是http2,在源码分析也可以得出相同结论。并非http1.1+chunk,chunk必须在header标记chunk,否则client怎么知道是chunk呢,chunk的数据是特殊格式的,解析也必须特殊解析。
然后试着让某个pod模拟突然down

推送了2条pod变更消息
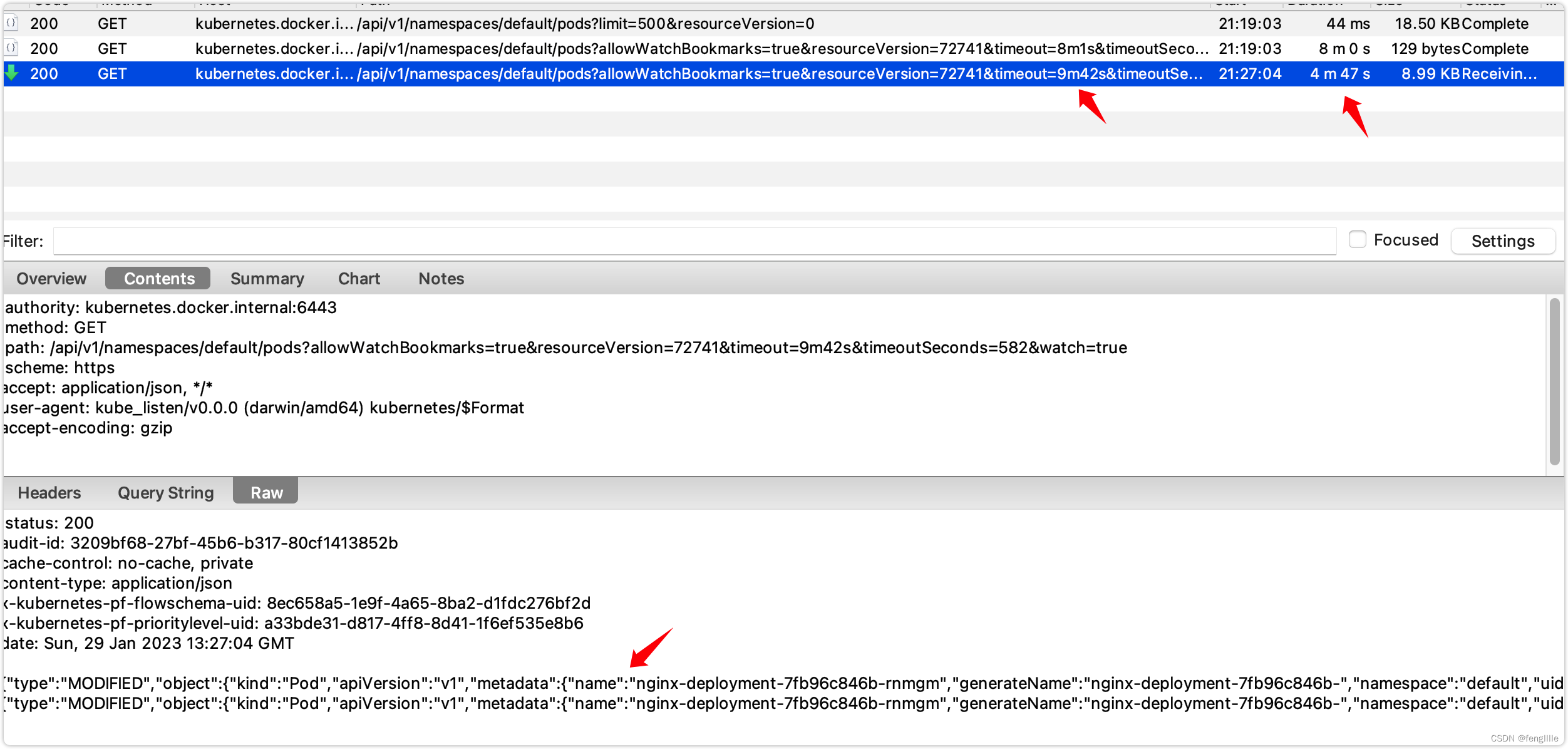
对比2个结果
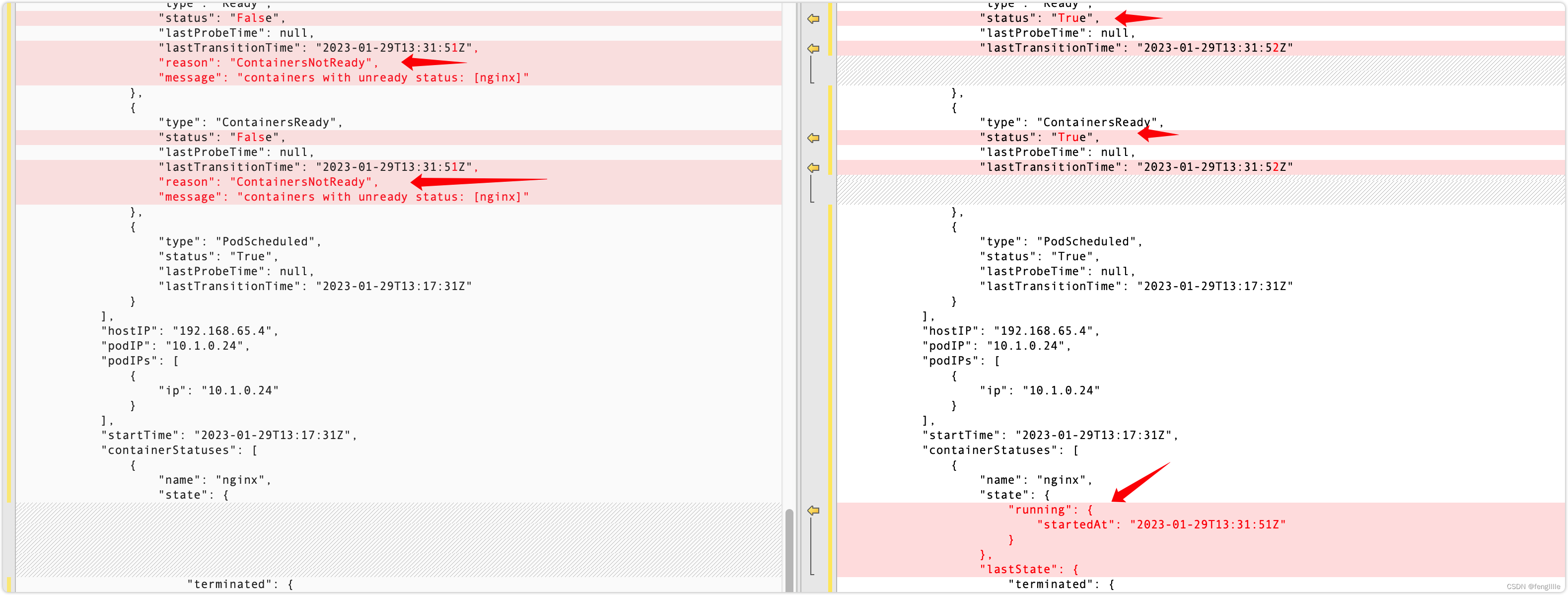
一个是pod down的message,一个是pod重启后的message,k8s的默认调度能力
观察一段时间会发现监听版本号太旧,会更新版本号,从新发起监听request请求

服务端会检测资源版本号,太旧就会直接返回,不确定是否定时检查,需要查看api-server的源码。
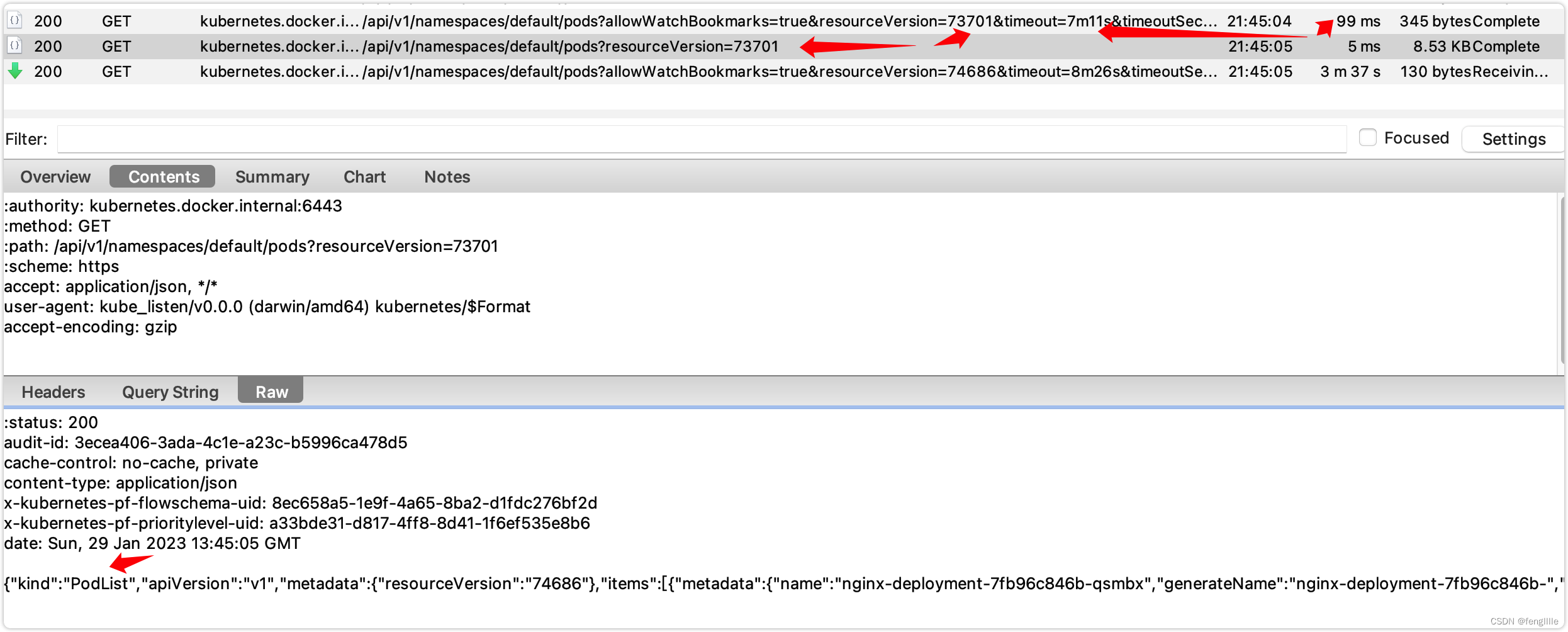
版本号太旧会继续执行List的操作请求,会获取到当前版本的pod的列表信息,然后执行Watch。
3. client-go 监听源码分析
笔者在分析api-server的时候,拿到github的apiserver的源码,发现没有main入口,查询github,发现代码入口在kubernates里面
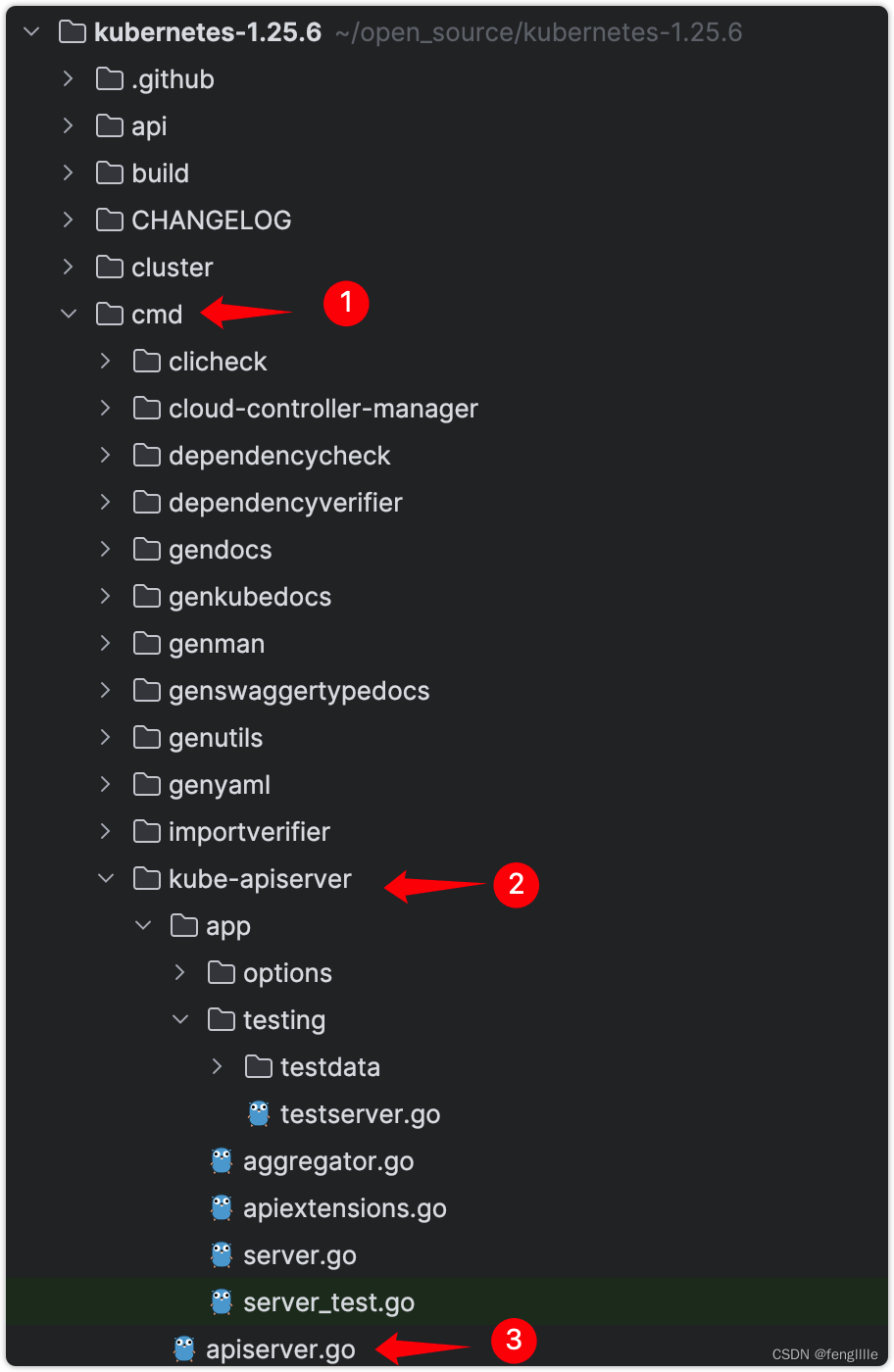
可以通过
kubectl --namespace="kube-system" describe pod kube-apiserver-docker-desktop
看到api-server的详情
3.1 client-go Config
第一步是读取配置,证书等的文件信息
clientcmd.BuildConfigFromFlags("", "~/.kube/config")读取的过程会根据参数使用不同的实现,本地模式使用DeferredLoadingClientConfig
load配置文件,调用k8s versioning.go自带的decoder
func LoadFromFile(filename string) (*clientcmdapi.Config, error) {
kubeconfigBytes, err := ioutil.ReadFile(filename)
if err != nil {
return nil, err
}
config, err := Load(kubeconfigBytes)
if err != nil {
return nil, err
}
klog.V(6).Infoln("Config loaded from file: ", filename)
// set LocationOfOrigin on every Cluster, User, and Context
for key, obj := range config.AuthInfos {
obj.LocationOfOrigin = filename
config.AuthInfos[key] = obj
}
for key, obj := range config.Clusters {
obj.LocationOfOrigin = filename
config.Clusters[key] = obj
}
for key, obj := range config.Contexts {
obj.LocationOfOrigin = filename
config.Contexts[key] = obj
}
if config.AuthInfos == nil {
config.AuthInfos = map[string]*clientcmdapi.AuthInfo{}
}
if config.Clusters == nil {
config.Clusters = map[string]*clientcmdapi.Cluster{}
}
if config.Contexts == nil {
config.Contexts = map[string]*clientcmdapi.Context{}
}
return config, nil
}读取的文件实际上是url、tls信息、content等信息
kubernetes.NewForConfig(config)
实际上就是初始化restClient
func NewForConfig(c *rest.Config) (*Clientset, error) {
configShallowCopy := *c
if configShallowCopy.UserAgent == "" {
configShallowCopy.UserAgent = rest.DefaultKubernetesUserAgent()
}
// share the transport between all clients
// 上面的注释很明显了,创建httpclient,share transport
httpClient, err := rest.HTTPClientFor(&configShallowCopy)
if err != nil {
return nil, err
}
// 看看如何share的
return NewForConfigAndClient(&configShallowCopy, httpClient)
}定位发现一堆使用httpClient
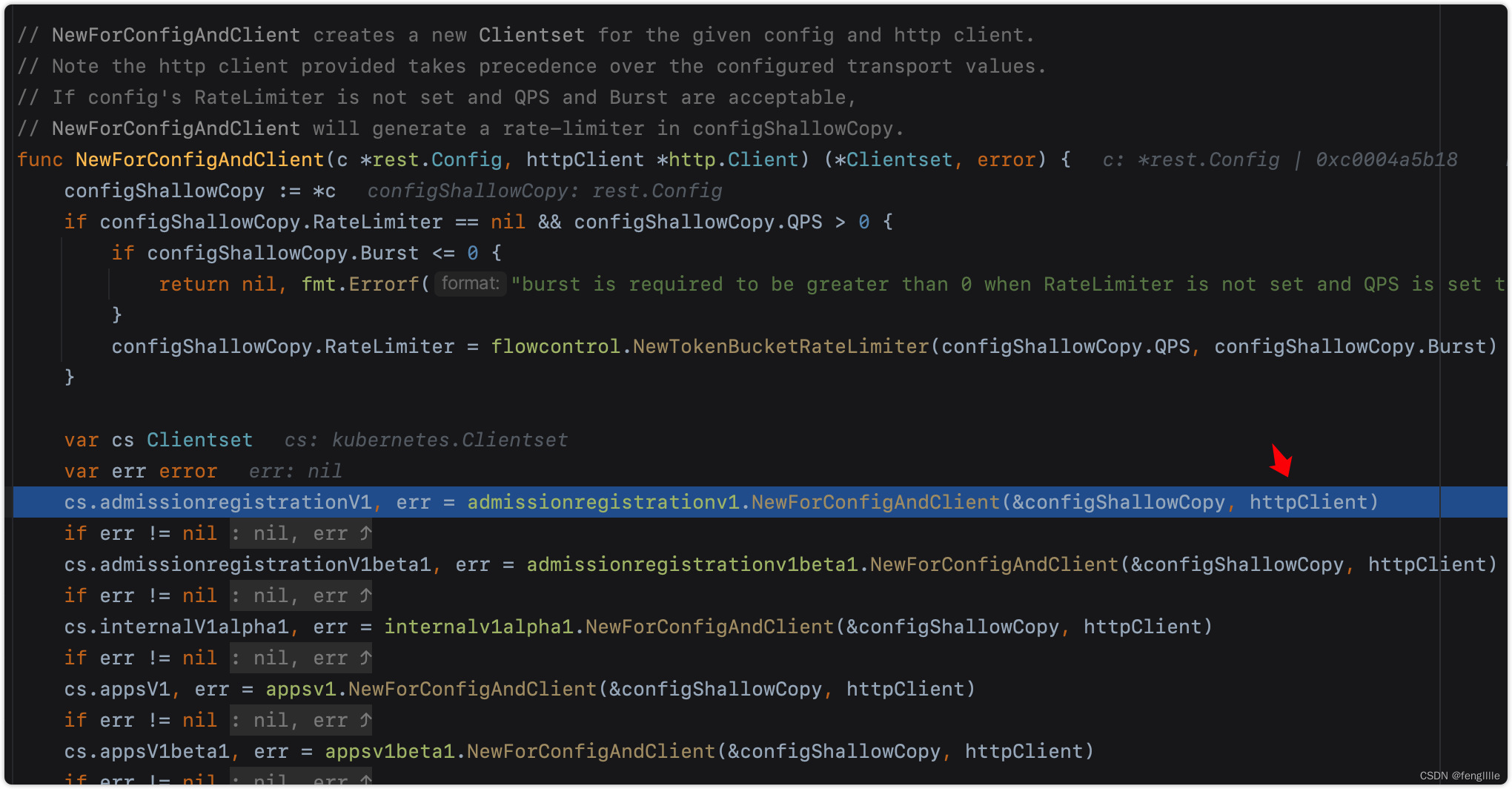
以第一个为例
// NewForConfigAndClient creates a new AdmissionregistrationV1Client for the given config and http client.
// Note the http client provided takes precedence over the configured transport values.
func NewForConfigAndClient(c *rest.Config, h *http.Client) (*AdmissionregistrationV1Client, error) {
config := *c
// 设置默认值, url path等
if err := setConfigDefaults(&config); err != nil {
return nil, err
}
//复用transport
client, err := rest.RESTClientForConfigAndClient(&config, h)
if err != nil {
return nil, err
}
return &AdmissionregistrationV1Client{client}, nil
}看看client的创建过程
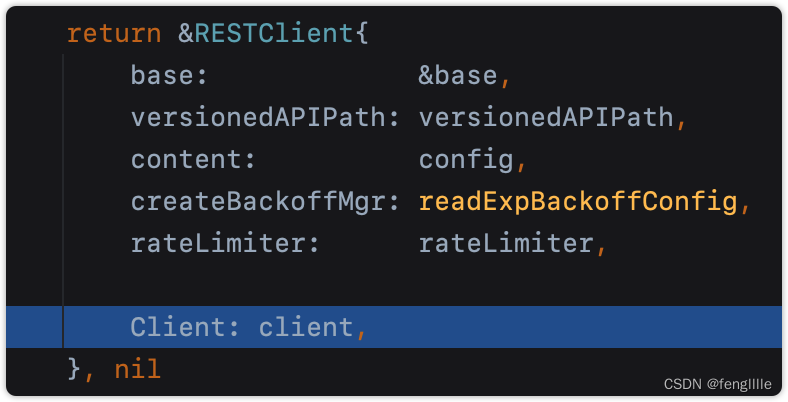
func RESTClientForConfigAndClient(config *Config, httpClient *http.Client) (*RESTClient, error) {
if config.GroupVersion == nil {
return nil, fmt.Errorf("GroupVersion is required when initializing a RESTClient")
}
if config.NegotiatedSerializer == nil {
return nil, fmt.Errorf("NegotiatedSerializer is required when initializing a RESTClient")
}
// 从配置拿到了url
baseURL, versionedAPIPath, err := defaultServerUrlFor(config)
if err != nil {
return nil, err
}
// 限流,不配置就是默认,如果开发k8s的插件,建议根据实际需求配置
rateLimiter := config.RateLimiter
if rateLimiter == nil {
qps := config.QPS
if config.QPS == 0.0 {
qps = DefaultQPS
}
burst := config.Burst
if config.Burst == 0 {
burst = DefaultBurst
}
if qps > 0 {
rateLimiter = flowcontrol.NewTokenBucketRateLimiter(qps, burst)
}
}
var gv schema.GroupVersion
if config.GroupVersion != nil {
gv = *config.GroupVersion
}
clientContent := ClientContentConfig{
AcceptContentTypes: config.AcceptContentTypes,
ContentType: config.ContentType,
GroupVersion: gv,
Negotiator: runtime.NewClientNegotiator(config.NegotiatedSerializer, gv),
}
// 复用httpClient,因为指针
restClient, err := NewRESTClient(baseURL, versionedAPIPath, clientContent, rateLimiter, httpClient)
if err == nil && config.WarningHandler != nil {
restClient.warningHandler = config.WarningHandler
}
return restClient, err
}
其他创建过程差不多,省略
informers.NewSharedInformerFactoryWithOptions(clientSet, 0, informers.WithNamespace("default"))
工厂类,初始化informer准备
factory.Core().V1().Pods().Informer()
前面的函数都是准备数据,重点看Informer函数
func (f *podInformer) Informer() cache.SharedIndexInformer {
return f.factory.InformerFor(&corev1.Pod{}, f.defaultInformer)
}
func (f *sharedInformerFactory) InformerFor(obj runtime.Object, newFunc internalinterfaces.NewInformerFunc) cache.SharedIndexInformer {
f.lock.Lock()
defer f.lock.Unlock()
informerType := reflect.TypeOf(obj)
informer, exists := f.informers[informerType]
if exists {
return informer
}
resyncPeriod, exists := f.customResync[informerType]
if !exists {
//关键参数之一
resyncPeriod = f.defaultResync
}
// 创建informer,注意有2个回调函数,函数指针
informer = newFunc(f.client, resyncPeriod)
f.informers[informerType] = informer
return informer
}回调函数,极其关键,ListWatch对应的函数List和Watch,跟前面抓包相对应。
// NewFilteredPodInformer constructs a new informer for Pod type.
// Always prefer using an informer factory to get a shared informer instead of getting an independent
// one. This reduces memory footprint and number of connections to the server.
func NewFilteredPodInformer(client kubernetes.Interface, namespace string, resyncPeriod time.Duration, indexers cache.Indexers, tweakListOptions internalinterfaces.TweakListOptionsFunc) cache.SharedIndexInformer {
return cache.NewSharedIndexInformer(
&cache.ListWatch{
ListFunc: func(options metav1.ListOptions) (runtime.Object, error) {
if tweakListOptions != nil {
tweakListOptions(&options)
}
return client.CoreV1().Pods(namespace).List(context.TODO(), options)
},
WatchFunc: func(options metav1.ListOptions) (watch.Interface, error) {
if tweakListOptions != nil {
tweakListOptions(&options)
}
return client.CoreV1().Pods(namespace).Watch(context.TODO(), options)
},
},
&corev1.Pod{},
resyncPeriod,
indexers,
)
}看看添加监听器
informer.AddEventHandler(xxx) // 刚刚设置的ResyncPeriod派上用场
func (s *sharedIndexInformer) AddEventHandlerWithResyncPeriod(handler ResourceEventHandler, resyncPeriod time.Duration) {
s.startedLock.Lock()
defer s.startedLock.Unlock()
if s.stopped {
klog.V(2).Infof("Handler %v was not added to shared informer because it has stopped already", handler)
return
}
//检查ResyncPeriod
if resyncPeriod > 0 {
if resyncPeriod < minimumResyncPeriod {
klog.Warningf("resyncPeriod %v is too small. Changing it to the minimum allowed value of %v", resyncPeriod, minimumResyncPeriod)
resyncPeriod = minimumResyncPeriod
}
if resyncPeriod < s.resyncCheckPeriod {
if s.started {
klog.Warningf("resyncPeriod %v is smaller than resyncCheckPeriod %v and the informer has already started. Changing it to %v", resyncPeriod, s.resyncCheckPeriod, s.resyncCheckPeriod)
resyncPeriod = s.resyncCheckPeriod
} else {
// if the event handler's resyncPeriod is smaller than the current resyncCheckPeriod, update
// resyncCheckPeriod to match resyncPeriod and adjust the resync periods of all the listeners
// accordingly
s.resyncCheckPeriod = resyncPeriod
s.processor.resyncCheckPeriodChanged(resyncPeriod)
}
}
}
//新增监听器
listener := newProcessListener(handler, resyncPeriod, determineResyncPeriod(resyncPeriod, s.resyncCheckPeriod), s.clock.Now(), initialBufferSize)
if !s.started {
// Informer未启动时加入监听
s.processor.addListener(listener)
return
}
// in order to safely join, we have to
// 1. stop sending add/update/delete notifications
// 2. do a list against the store
// 3. send synthetic "Add" events to the new handler
// 4. unblock
s.blockDeltas.Lock()
defer s.blockDeltas.Unlock() //阻塞Deltas队列,后面监听会用到,Informer的实现架构的一环
s.processor.addListener(listener) // Informer启动后加入监听器
for _, item := range s.indexer.List() { //对新监听器执行List操作,数据直接给过去
listener.add(addNotification{newObj: item})
}
}看关键部分addListener
func (p *sharedProcessor) addListener(listener *processorListener) {
p.listenersLock.Lock()
defer p.listenersLock.Unlock()
// 加入切片
p.addListenerLocked(listener)
if p.listenersStarted { //如果是已经启动,那么执行listener的run和pop;这是2个关键的chan处理函数
p.wg.Start(listener.run)
p.wg.Start(listener.pop)
}
}
func (p *sharedProcessor) addListenerLocked(listener *processorListener) {
p.listeners = append(p.listeners, listener)
p.syncingListeners = append(p.syncingListeners, listener)
}如果状态是已启动,把缓存的数据刷到handler事件(动态增加listener),看看这2个关键处理函数
func (p *processorListener) add(notification interface{}) {
p.addCh <- notification
}
func (p *processorListener) pop() {
defer utilruntime.HandleCrash()
defer close(p.nextCh) // Tell .run() to stop
var nextCh chan<- interface{}
var notification interface{}
for {
select {
case nextCh <- notification:
// Notification dispatched
var ok bool
notification, ok = p.pendingNotifications.ReadOne() //读取pending的缓存数据
if !ok { // Nothing to pop //读取到数据就在下一次循环给nextCh管道
nextCh = nil // Disable this select case
}
case notificationToAdd, ok := <-p.addCh: //这个是上面的函数,在Informer状态是启动时,或者启动后,写入的List数据
if !ok {
return
}
if notification == nil { // No notification to pop (and pendingNotifications is empty)
// Optimize the case - skip adding to pendingNotifications
notification = notificationToAdd
nextCh = p.nextCh
} else { // There is already a notification waiting to be dispatched
p.pendingNotifications.WriteOne(notificationToAdd) //写入listener缓存
}
}
}
}
func (p *processorListener) run() {
// this call blocks until the channel is closed. When a panic happens during the notification
// we will catch it, **the offending item will be skipped!**, and after a short delay (one second)
// the next notification will be attempted. This is usually better than the alternative of never
// delivering again.
stopCh := make(chan struct{})
wait.Until(func() {
//这就是handler的回调,nextChan就是上面pop产生
for next := range p.nextCh {
switch notification := next.(type) {
case updateNotification:
p.handler.OnUpdate(notification.oldObj, notification.newObj)
case addNotification:
p.handler.OnAdd(notification.newObj)
case deleteNotification:
p.handler.OnDelete(notification.oldObj)
default:
utilruntime.HandleError(fmt.Errorf("unrecognized notification: %T", next))
}
}
// the only way to get here is if the p.nextCh is empty and closed
close(stopCh)
}, 1*time.Second, stopCh)
}分析过程中发现listener有Informer启动前和启动后添加的过程,启动后已经分析,看看启动前Informer怎么启动的
informer.Run(stopper) //不少网上教程也有自己写controller的,实际上client-go已经封装了
go的匿名函数指针在client-go有非常多的地方应用,看起代码来很累😅,再用变量传来传去
func (s *sharedIndexInformer) Run(stopCh <-chan struct{}) {
defer utilruntime.HandleCrash() //处理panic
if s.HasStarted() { //实际上这个函数是启动Informer,所以如果已经启动就返回,避免重复启动
klog.Warningf("The sharedIndexInformer has started, run more than once is not allowed")
return
}
//fifo队列,对应的是lifo;这个设计是Informer的关键设计之一
fifo := NewDeltaFIFOWithOptions(DeltaFIFOOptions{
KnownObjects: s.indexer,
EmitDeltaTypeReplaced: true,
})
//关键的配置,非常关键,涉及整个架构的过程
cfg := &Config{
Queue: fifo, //deltafifo队列
ListerWatcher: s.listerWatcher, //list watch 函数接口
ObjectType: s.objectType, //监听类型,笔者这里监听的pod,因为前面的代码调用了Pod()函数
FullResyncPeriod: s.resyncCheckPeriod, //重新检查周期
RetryOnError: false,
//resync是listener的重新同步,可以看这个函数的实现
ShouldResync: s.processor.shouldResync, //是否需要重新同步的函数指针
Process: s.HandleDeltas, //处理delta的函数
WatchErrorHandler: s.watchErrorHandler, //见名知义
}
func() {
s.startedLock.Lock()
defer s.startedLock.Unlock()
s.controller = New(cfg)
s.controller.(*controller).clock = s.clock
s.started = true
}()
// Separate stop channel because Processor should be stopped strictly after controller
processorStopCh := make(chan struct{})
var wg wait.Group
defer wg.Wait() // Wait for Processor to stop
defer close(processorStopCh) // Tell Processor to stop
//cache缓存监控
wg.StartWithChannel(processorStopCh, s.cacheMutationDetector.Run)
wg.StartWithChannel(processorStopCh, s.processor.run) //这个run就是前面的解析的run函数
defer func() {
s.startedLock.Lock()
defer s.startedLock.Unlock()
s.stopped = true // Don't want any new listeners
}() //defer函数,在controller运行后更新状态
s.controller.Run(stopCh) //关键一步
}DeltaFIFO创建,里面是map和切片的结合体,还有锁
// NewDeltaFIFOWithOptions returns a Queue which can be used to process changes to
// items. See also the comment on DeltaFIFO.
func NewDeltaFIFOWithOptions(opts DeltaFIFOOptions) *DeltaFIFO {
if opts.KeyFunction == nil {
opts.KeyFunction = MetaNamespaceKeyFunc
}
f := &DeltaFIFO{
items: map[string]Deltas{},
queue: []string{},
keyFunc: opts.KeyFunction,
knownObjects: opts.KnownObjects,
emitDeltaTypeReplaced: opts.EmitDeltaTypeReplaced,
}
f.cond.L = &f.lock
return f
}还有线程安全的本地存储,所以实际上这个也可以用store里面取数据,常见的用法是nginx-ingress的用法Welcome - NGINX Ingress Controller (kubernetes.github.io),可以去看源代码用的store的方式。
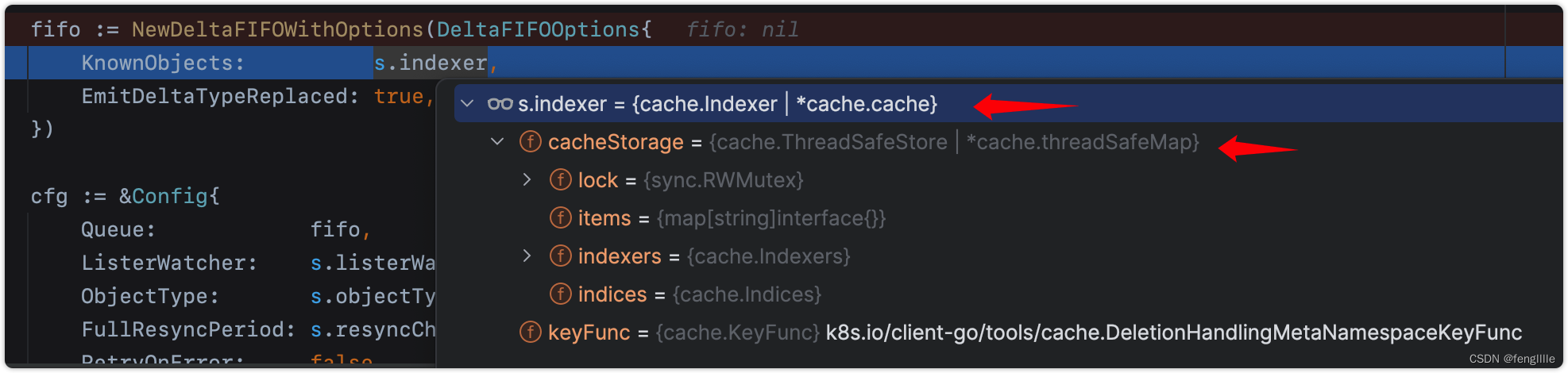
看看HandleDeltas处理队列的函数,这个是一个关键过程,所以List和Watch都会触发handler
func (s *sharedIndexInformer) HandleDeltas(obj interface{}) error {
s.blockDeltas.Lock()
defer s.blockDeltas.Unlock()
if deltas, ok := obj.(Deltas); ok {
return processDeltas(s, s.indexer, s.transform, deltas)
}
return errors.New("object given as Process argument is not Deltas")
}
// Multiplexes updates in the form of a list of Deltas into a Store, and informs
// a given handler of events OnUpdate, OnAdd, OnDelete
func processDeltas(
// Object which receives event notifications from the given deltas
handler ResourceEventHandler,
clientState Store,
transformer TransformFunc,
deltas Deltas,
) error {
// from oldest to newest
for _, d := range deltas {
obj := d.Object
if transformer != nil { //默认情况这个是nil,即不需要转换
var err error
obj, err = transformer(obj) //转换类型,前面的config里面是有类型的
if err != nil {
return err
}
}
//handler分发,这也是我们注册的handler生效的原因
switch d.Type {
case Sync, Replaced, Added, Updated:
if old, exists, err := clientState.Get(obj); err == nil && exists {
if err := clientState.Update(obj); err != nil { //更新状态,可以是本地缓存,也可以是队列,默认使用本地store ThreadSafeStore
return err
}
handler.OnUpdate(old, obj)
} else {
if err := clientState.Add(obj); err != nil { //同上
return err
}
handler.OnAdd(obj)
}
case Deleted:
if err := clientState.Delete(obj); err != nil { //同上
return err
}
handler.OnDelete(obj)
}
}
return nil
}s.controller.Run(stopCh) //最终的启动干活了
// Run begins processing items, and will continue until a value is sent down stopCh or it is closed. run就开始干活了,直到被stopCh关闭
// It's an error to call Run more than once. 调用多次是错误的
// Run blocks; call via go. 运行会阻塞,用协程调用
func (c *controller) Run(stopCh <-chan struct{}) {
defer utilruntime.HandleCrash() //处理panic
go func() {
<-stopCh
c.config.Queue.Close()
}() //关闭代码
r := NewReflector(
c.config.ListerWatcher,
c.config.ObjectType,
c.config.Queue,
c.config.FullResyncPeriod,
)
r.ShouldResync = c.config.ShouldResync
r.WatchListPageSize = c.config.WatchListPageSize
r.clock = c.clock
if c.config.WatchErrorHandler != nil {
r.watchErrorHandler = c.config.WatchErrorHandler
}
c.reflectorMutex.Lock()
c.reflector = r
c.reflectorMutex.Unlock()
var wg wait.Group
// 定时List And Watch
wg.StartWithChannel(stopCh, r.Run)
// delta队列取数据处理,监听后面的事情了
wait.Until(c.processLoop, time.Second, stopCh)
wg.Wait()
}继续看r.Run,这个是循环运行的函数,定时运行ListAndWatch,直到stopChan;r.ListAndWatch(stopCh)就是去读取和定时增量更新,所以会一直不断的List And Watch,对应抓包的循环调用List和Watch的url
// Run repeatedly uses the reflector's ListAndWatch to fetch all the
// objects and subsequent deltas.
// Run will exit when stopCh is closed.
func (r *Reflector) Run(stopCh <-chan struct{}) {
klog.V(3).Infof("Starting reflector %s (%s) from %s", r.expectedTypeName, r.resyncPeriod, r.name)
wait.BackoffUntil(func() {
if err := r.ListAndWatch(stopCh); err != nil {
r.watchErrorHandler(r, err)
}
}, r.backoffManager, true, stopCh)
klog.V(3).Infof("Stopping reflector %s (%s) from %s", r.expectedTypeName, r.resyncPeriod, r.name)
}定时循环
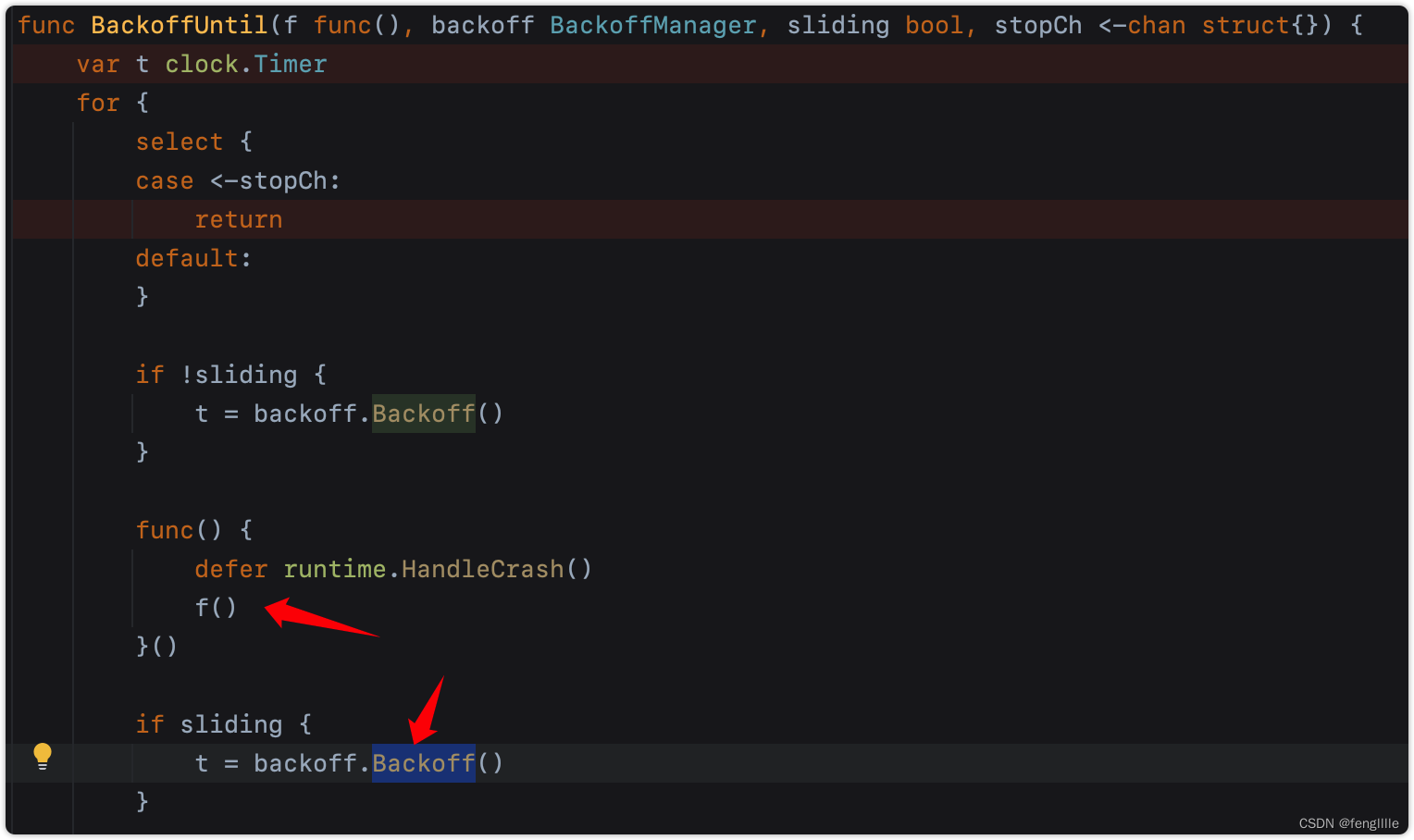
processLoop函数,不断的从queue delta队列取数据处理
func (c *controller) processLoop() {
for {
//使用函数指针的强制类型转换c.config.Process实际上在前面定义了,即s.HandleDeltas
obj, err := c.config.Queue.Pop(PopProcessFunc(c.config.Process))
if err != nil {
if err == ErrFIFOClosed {
return
}
if c.config.RetryOnError {
// This is the safe way to re-enqueue.
c.config.Queue.AddIfNotPresent(obj)
}
}
}
}HandleDeltas前面已经分析过了,交付handler与store
3.2 ListAndWatch的过程
实际上上面已经把Informer启动的过程分析完成,但是Informer的数据是怎么拿到的,毕竟数据的来源是根源,否则后面的delta队列和store也没有必要,需要进一步分析
// ListAndWatch first lists all items and get the resource version at the moment of call,
// and then use the resource version to watch.
// It returns error if ListAndWatch didn't even try to initialize watch.
func (r *Reflector) ListAndWatch(stopCh <-chan struct{}) error {
klog.V(3).Infof("Listing and watching %v from %s", r.expectedTypeName, r.name)
err := r.list(stopCh) //list,即前面抓包的list,读取资源版本号和items列表(此刻),用于Watch
if err != nil {
return err
}
resyncerrc := make(chan error, 1)
cancelCh := make(chan struct{})
defer close(cancelCh)
go func() {
resyncCh, cleanup := r.resyncChan()
defer func() {
cleanup() // Call the last one written into cleanup
}()
for {
select {
case <-resyncCh:
case <-stopCh:
return
case <-cancelCh:
return
}
if r.ShouldResync == nil || r.ShouldResync() {
klog.V(4).Infof("%s: forcing resync", r.name)
if err := r.store.Resync(); err != nil { //重新同步delta队列
resyncerrc <- err
return
}
}
cleanup()
resyncCh, cleanup = r.resyncChan()
}
}()
retry := NewRetryWithDeadline(r.MaxInternalErrorRetryDuration, time.Minute, apierrors.IsInternalError, r.clock)
for {
// give the stopCh a chance to stop the loop, even in case of continue statements further down on errors
select {
case <-stopCh:
return nil
default:
}
timeoutSeconds := int64(minWatchTimeout.Seconds() * (rand.Float64() + 1.0))
options := metav1.ListOptions{ //watch初始化,资源版本号,超时随机时长
ResourceVersion: r.LastSyncResourceVersion(),
// We want to avoid situations of hanging watchers. Stop any watchers that do not
// receive any events within the timeout window.
TimeoutSeconds: &timeoutSeconds,
// To reduce load on kube-apiserver on watch restarts, you may enable watch bookmarks.
// Reflector doesn't assume bookmarks are returned at all (if the server do not support
// watch bookmarks, it will ignore this field).
AllowWatchBookmarks: true,
}
// start the clock before sending the request, since some proxies won't flush headers until after the first watch event is sent
start := r.clock.Now()
//实际上是立即返回,但是response的body是阻塞的,除非apiserver给出结束标记,或者超时
w, err := r.listerWatcher.Watch(options) //watch核心,读取到监听数据
if err != nil {
// If this is "connection refused" error, it means that most likely apiserver is not responsive.
// It doesn't make sense to re-list all objects because most likely we will be able to restart
// watch where we ended.
// If that's the case begin exponentially backing off and resend watch request.
// Do the same for "429" errors.
if utilnet.IsConnectionRefused(err) || apierrors.IsTooManyRequests(err) {
<-r.initConnBackoffManager.Backoff().C()
continue
}
return err
}
//很关键,读取上面watch阻塞的response body的通信管道,写入delta fifo队列
// 上面是watch -- 阻塞 -- apiserver结束或超时 -- 写入管道
// 此处是从管道读取 -- 写入deltaFIFO;当没有数据是阻塞的,结束条件是超时,或者apiserver error信息
err = watchHandler(start, w, r.store, r.expectedType, r.expectedGVK, r.name, r.expectedTypeName, r.setLastSyncResourceVersion, r.clock, resyncerrc, stopCh)
retry.After(err)
if err != nil {
if err != errorStopRequested {
switch {
case isExpiredError(err):
// Don't set LastSyncResourceVersionUnavailable - LIST call with ResourceVersion=RV already
// has a semantic that it returns data at least as fresh as provided RV.
// So first try to LIST with setting RV to resource version of last observed object.
klog.V(4).Infof("%s: watch of %v closed with: %v", r.name, r.expectedTypeName, err)
case apierrors.IsTooManyRequests(err):
klog.V(2).Infof("%s: watch of %v returned 429 - backing off", r.name, r.expectedTypeName)
<-r.initConnBackoffManager.Backoff().C()
continue
case apierrors.IsInternalError(err) && retry.ShouldRetry():
klog.V(2).Infof("%s: retrying watch of %v internal error: %v", r.name, r.expectedTypeName, err)
continue
default:
klog.Warningf("%s: watch of %v ended with: %v", r.name, r.expectedTypeName, err)
}
}
return nil //结束当前任务执行定时任务 //wait.BackoffUntil函数,上面已经分析过了
}
}
}watchHandler
// watchHandler watches w and sets setLastSyncResourceVersion
func watchHandler(start time.Time,
w watch.Interface,
store Store,
expectedType reflect.Type,
expectedGVK *schema.GroupVersionKind,
name string,
expectedTypeName string,
setLastSyncResourceVersion func(string),
clock clock.Clock,
errc chan error,
stopCh <-chan struct{},
) error {
eventCount := 0
// Stopping the watcher should be idempotent and if we return from this function there's no way
// we're coming back in with the same watch interface.
defer w.Stop()
loop:
for {
select {
case <-stopCh:
return errorStopRequested
case err := <-errc:
return err
case event, ok := <-w.ResultChan():
if !ok {
break loop
}
if event.Type == watch.Error {
return apierrors.FromObject(event.Object)
}
if expectedType != nil {
if e, a := expectedType, reflect.TypeOf(event.Object); e != a {
utilruntime.HandleError(fmt.Errorf("%s: expected type %v, but watch event object had type %v", name, e, a))
continue
}
}
if expectedGVK != nil {
if e, a := *expectedGVK, event.Object.GetObjectKind().GroupVersionKind(); e != a {
utilruntime.HandleError(fmt.Errorf("%s: expected gvk %v, but watch event object had gvk %v", name, e, a))
continue
}
}
meta, err := meta.Accessor(event.Object)
if err != nil {
utilruntime.HandleError(fmt.Errorf("%s: unable to understand watch event %#v", name, event))
continue
}
resourceVersion := meta.GetResourceVersion()
switch event.Type {
case watch.Added:
err := store.Add(event.Object)
if err != nil {
utilruntime.HandleError(fmt.Errorf("%s: unable to add watch event object (%#v) to store: %v", name, event.Object, err))
}
case watch.Modified:
err := store.Update(event.Object)
if err != nil {
utilruntime.HandleError(fmt.Errorf("%s: unable to update watch event object (%#v) to store: %v", name, event.Object, err))
}
case watch.Deleted:
// TODO: Will any consumers need access to the "last known
// state", which is passed in event.Object? If so, may need
// to change this.
err := store.Delete(event.Object)
if err != nil {
utilruntime.HandleError(fmt.Errorf("%s: unable to delete watch event object (%#v) from store: %v", name, event.Object, err))
}
case watch.Bookmark:
// A `Bookmark` means watch has synced here, just update the resourceVersion
default:
utilruntime.HandleError(fmt.Errorf("%s: unable to understand watch event %#v", name, event))
}
setLastSyncResourceVersion(resourceVersion)
if rvu, ok := store.(ResourceVersionUpdater); ok {
rvu.UpdateResourceVersion(resourceVersion)
}
eventCount++
}
}
watchDuration := clock.Since(start)
if watchDuration < 1*time.Second && eventCount == 0 {
return fmt.Errorf("very short watch: %s: Unexpected watch close - watch lasted less than a second and no items received", name)
}
klog.V(4).Infof("%s: Watch close - %v total %v items received", name, expectedTypeName, eventCount)
return nil
}核心就是更新deltafifo和资源版本号
List 和 Watch就是这里触发,细节后面分析。
3.3 List的过程
r.list(stopCh)
// list simply lists all items and records a resource version obtained from the server at the moment of the call.
// the resource version can be used for further progress notification (aka. watch).
func (r *Reflector) list(stopCh <-chan struct{}) error {
var resourceVersion string
options := metav1.ListOptions{ResourceVersion: r.relistResourceVersion()}
initTrace := trace.New("Reflector ListAndWatch", trace.Field{Key: "name", Value: r.name})
defer initTrace.LogIfLong(10 * time.Second)
var list runtime.Object
var paginatedResult bool
var err error
listCh := make(chan struct{}, 1)
panicCh := make(chan interface{}, 1)
go func() {
defer func() {
if r := recover(); r != nil {
panicCh <- r
}
}()
// Attempt to gather list in chunks, if supported by listerWatcher, if not, the first
// list request will return the full response. 收集chunks的list;否则返回全部,笔者本地难道是不支持chunk 或者是需要配置开启chunk
pager := pager.New(pager.SimplePageFunc(func(opts metav1.ListOptions) (runtime.Object, error) {
return r.listerWatcher.List(opts) //回调函数List
}))
switch {
case r.WatchListPageSize != 0:
pager.PageSize = r.WatchListPageSize
case r.paginatedResult:
// We got a paginated result initially. Assume this resource and server honor
// paging requests (i.e. watch cache is probably disabled) and leave the default
// pager size set.
case options.ResourceVersion != "" && options.ResourceVersion != "0":
// User didn't explicitly request pagination.
//
// With ResourceVersion != "", we have a possibility to list from watch cache,
// but we do that (for ResourceVersion != "0") only if Limit is unset.
// To avoid thundering herd on etcd (e.g. on master upgrades), we explicitly
// switch off pagination to force listing from watch cache (if enabled).
// With the existing semantic of RV (result is at least as fresh as provided RV),
// this is correct and doesn't lead to going back in time.
//
// We also don't turn off pagination for ResourceVersion="0", since watch cache
// is ignoring Limit in that case anyway, and if watch cache is not enabled
// we don't introduce regression.
pager.PageSize = 0
}
//发起调用刚刚到回调函数,拿到items和resourceVersion
list, paginatedResult, err = pager.List(context.Background(), options)
if isExpiredError(err) || isTooLargeResourceVersionError(err) {
r.setIsLastSyncResourceVersionUnavailable(true)
// Retry immediately if the resource version used to list is unavailable.
// The pager already falls back to full list if paginated list calls fail due to an "Expired" error on
// continuation pages, but the pager might not be enabled, the full list might fail because the
// resource version it is listing at is expired or the cache may not yet be synced to the provided
// resource version. So we need to fallback to resourceVersion="" in all to recover and ensure
// the reflector makes forward progress.
list, paginatedResult, err = pager.List(context.Background(), metav1.ListOptions{ResourceVersion: r.relistResourceVersion()})
}
close(listCh) //协程管道通信
}()
select {
case <-stopCh:
return nil
case r := <-panicCh:
panic(r)
case <-listCh: //管道close,这里就不阻塞了
}
initTrace.Step("Objects listed", trace.Field{Key: "error", Value: err})
if err != nil {
klog.Warningf("%s: failed to list %v: %v", r.name, r.expectedTypeName, err)
return fmt.Errorf("failed to list %v: %w", r.expectedTypeName, err)
}
// We check if the list was paginated and if so set the paginatedResult based on that.
// However, we want to do that only for the initial list (which is the only case
// when we set ResourceVersion="0"). The reasoning behind it is that later, in some
// situations we may force listing directly from etcd (by setting ResourceVersion="")
// which will return paginated result, even if watch cache is enabled. However, in
// that case, we still want to prefer sending requests to watch cache if possible.
//
// Paginated result returned for request with ResourceVersion="0" mean that watch
// cache is disabled and there are a lot of objects of a given type. In such case,
// there is no need to prefer listing from watch cache.
if options.ResourceVersion == "0" && paginatedResult {
r.paginatedResult = true
}
//状态数据,表示list成功,官方注释明确
r.setIsLastSyncResourceVersionUnavailable(false) // list was successful
listMetaInterface, err := meta.ListAccessor(list)
if err != nil {
return fmt.Errorf("unable to understand list result %#v: %v", list, err)
}
resourceVersion = listMetaInterface.GetResourceVersion() //刚刚的版本号,从List函数读取的,就是上次请求apiserver的那个时刻的资源版本号
initTrace.Step("Resource version extracted")
items, err := meta.ExtractList(list) //拿到list数据
if err != nil {
return fmt.Errorf("unable to understand list result %#v (%v)", list, err)
}
initTrace.Step("Objects extracted")
// 写入delta FIFO队列
if err := r.syncWith(items, resourceVersion); err != nil {
return fmt.Errorf("unable to sync list result: %v", err)
}
initTrace.Step("SyncWith done")
r.setLastSyncResourceVersion(resourceVersion) //更新资源版本
initTrace.Step("Resource version updated")
return nil
}继续看List,反复在注释试图通过server的chunk读取,否则读取全部;检查设置limit,默认设置500
// List returns a single list object, but attempts to retrieve smaller chunks from the
// server to reduce the impact on the server. If the chunk attempt fails, it will load
// the full list instead. The Limit field on options, if unset, will default to the page size.
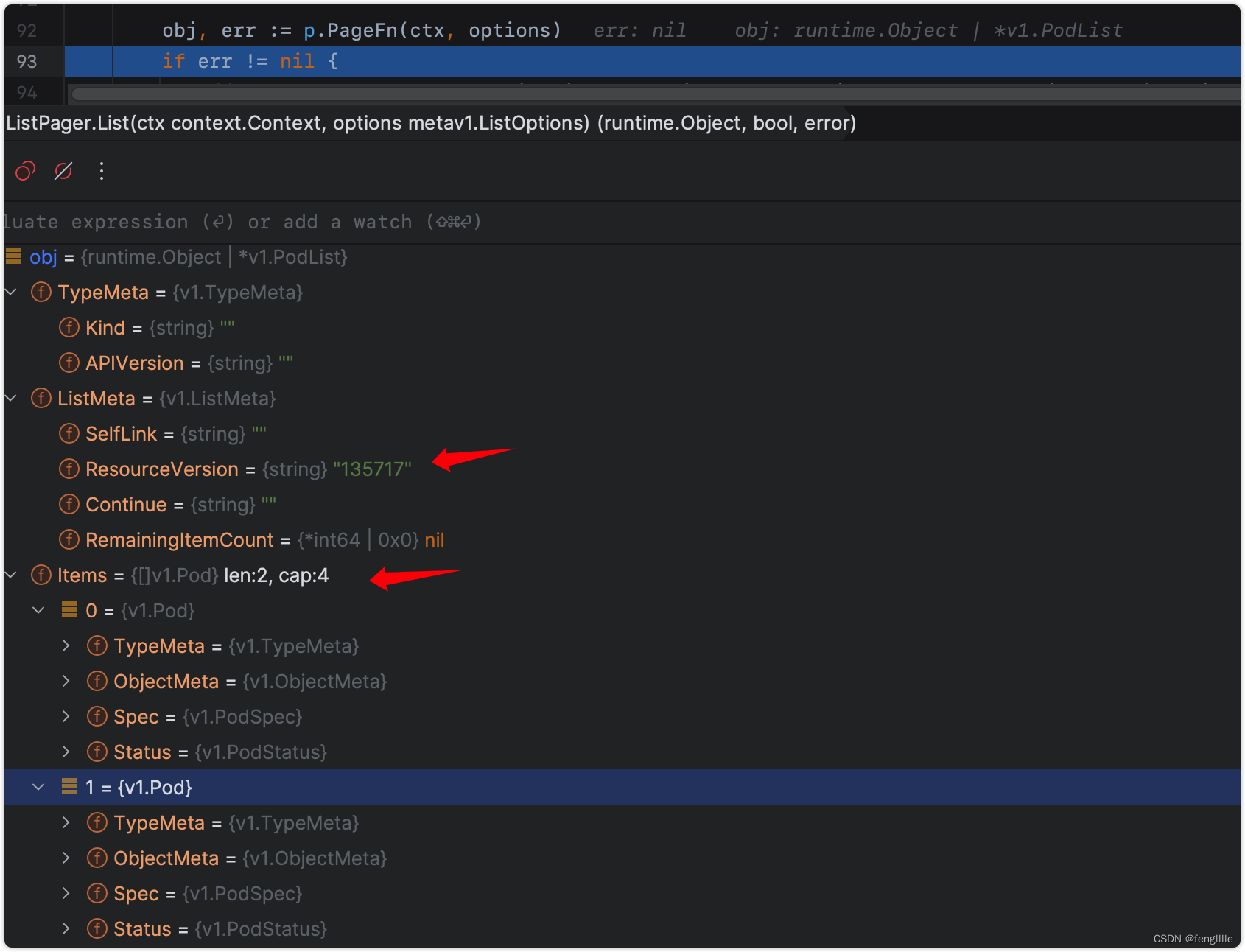
func (p *ListPager) List(ctx context.Context, options metav1.ListOptions) (runtime.Object, bool, error) {
if options.Limit == 0 {
options.Limit = p.PageSize
}
requestedResourceVersion := options.ResourceVersion
requestedResourceVersionMatch := options.ResourceVersionMatch
var list *metainternalversion.List
paginatedResult := false
for {
select {
case <-ctx.Done():
return nil, paginatedResult, ctx.Err()
default:
}
//调用刚刚设置的回调函数r.listerWatcher.List(opts),进而继续调用最开始配置的函数lw.ListFunc(options)
// 获取到资源版本号和items资源列表
obj, err := p.PageFn(ctx, options)
if err != nil {
// Only fallback to full list if an "Expired" errors is returned, FullListIfExpired is true, and
// the "Expired" error occurred in page 2 or later (since full list is intended to prevent a pager.List from
// failing when the resource versions is established by the first page request falls out of the compaction
// during the subsequent list requests).
if !errors.IsResourceExpired(err) || !p.FullListIfExpired || options.Continue == "" {
return nil, paginatedResult, err
}
// the list expired while we were processing, fall back to a full list at
// the requested ResourceVersion.
options.Limit = 0
options.Continue = ""
options.ResourceVersion = requestedResourceVersion
options.ResourceVersionMatch = requestedResourceVersionMatch
result, err := p.PageFn(ctx, options)
return result, paginatedResult, err
}
m, err := meta.ListAccessor(obj)
if err != nil {
return nil, paginatedResult, fmt.Errorf("returned object must be a list: %v", err)
}
// exit early and return the object we got if we haven't processed any pages
//没有资源,就返回了, 如果是分页,那么后面还有资源
if len(m.GetContinue()) == 0 && list == nil {
return obj, paginatedResult, nil
}
// initialize the list and fill its contents
if list == nil {
list = &metainternalversion.List{Items: make([]runtime.Object, 0, options.Limit+1)} //
list.ResourceVersion = m.GetResourceVersion()//非常重要,更新最新版本号,分页的时候
list.SelfLink = m.GetSelfLink()
}
// 分页准备,如果continue,那么还有数据,所以需要list定义且不断for循环拼接obj,直到分页结束。
if err := meta.EachListItem(obj, func(obj runtime.Object) error {
list.Items = append(list.Items, obj)
return nil
}); err != nil {
return nil, paginatedResult, err
}
// if we have no more items, return the list
if len(m.GetContinue()) == 0 { //分页结束
return list, paginatedResult, nil
}
// set the next loop up
options.Continue = m.GetContinue() //设置读取的分页,为下一次调用数据准备
// Clear the ResourceVersion(Match) on the subsequent List calls to avoid the
// `specifying resource version is not allowed when using continue` error.
// See https://github.com/kubernetes/kubernetes/issues/85221#issuecomment-553748143.
options.ResourceVersion = ""
options.ResourceVersionMatch = ""
// At this point, result is already paginated.
paginatedResult = true //分页标记
}
}
// List a set of apiserver resources
func (lw *ListWatch) List(options metav1.ListOptions) (runtime.Object, error) {
// ListWatch is used in Reflector, which already supports pagination.
// Don't paginate here to avoid duplication.
return lw.ListFunc(options)
}这里又回到了最开始的函数指针
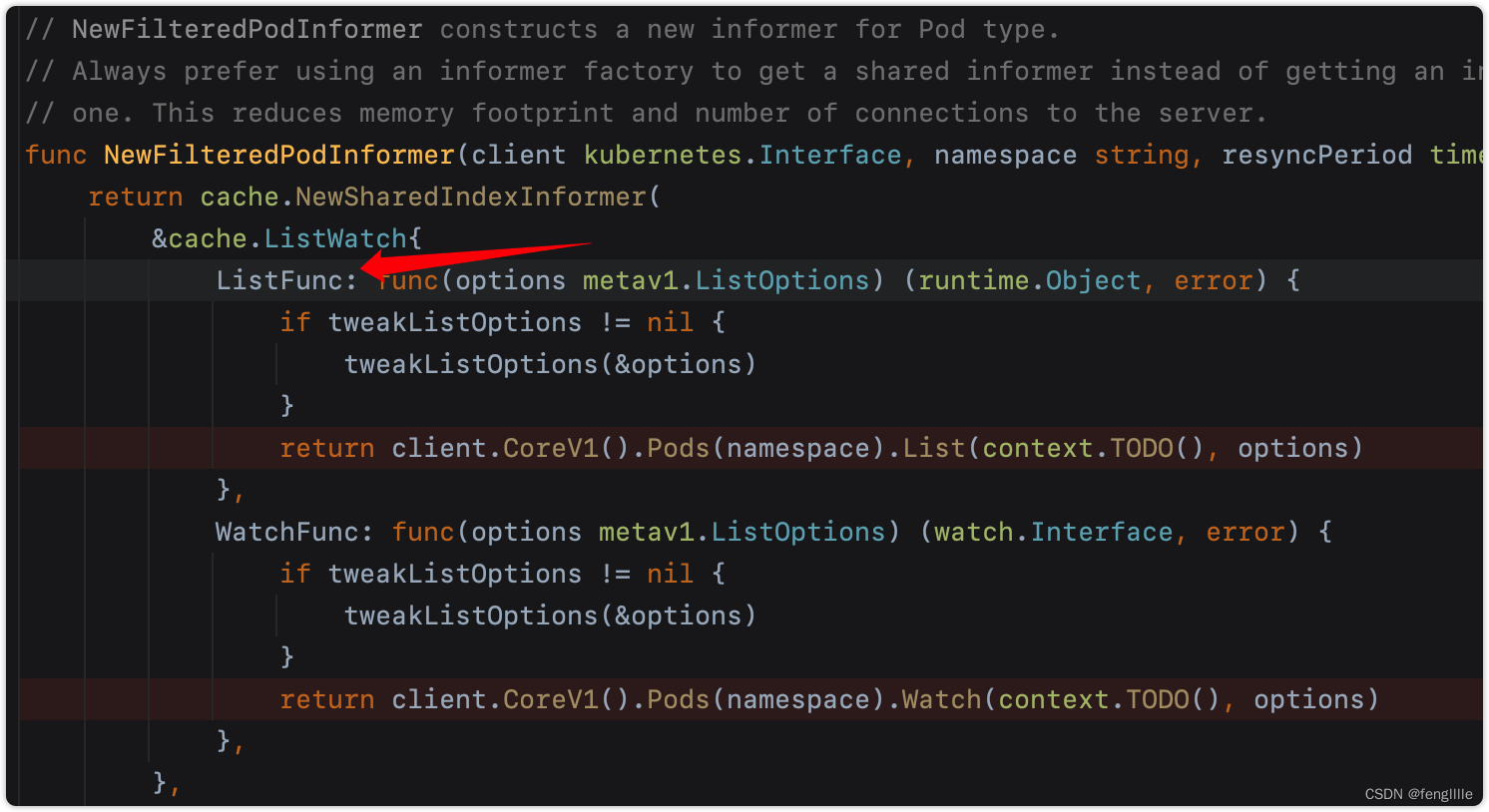
继续分析List函数
client.CoreV1().Pods(namespace).List(context.TODO(), options)
// List takes label and field selectors, and returns the list of Pods that match those selectors.
func (c *pods) List(ctx context.Context, opts metav1.ListOptions) (result *v1.PodList, err error) {
var timeout time.Duration
if opts.TimeoutSeconds != nil {
timeout = time.Duration(*opts.TimeoutSeconds) * time.Second
}
result = &v1.PodList{}
err = c.client.Get().
Namespace(c.ns).
Resource("pods").
VersionedParams(&opts, scheme.ParameterCodec).
Timeout(timeout).
Do(ctx).
Into(result)
return
}
func (r *Request) Do(ctx context.Context) Result {
var result Result
err := r.request(ctx, func(req *http.Request, resp *http.Response) {
result = r.transformResponse(resp, req)
})
if err != nil {
return Result{err: err}
}
if result.err == nil || len(result.body) > 0 {
metrics.ResponseSize.Observe(ctx, r.verb, r.URL().Host, float64(len(result.body)))
}
return result
}
func (r Result) Into(obj runtime.Object) error {
if r.err != nil {
// Check whether the result has a Status object in the body and prefer that.
return r.Error()
}
if r.decoder == nil {
return fmt.Errorf("serializer for %s doesn't exist", r.contentType)
}
if len(r.body) == 0 {
return fmt.Errorf("0-length response with status code: %d and content type: %s",
r.statusCode, r.contentType)
}
out, _, err := r.decoder.Decode(r.body, nil, obj)
if err != nil || out == obj {
return err
}
// if a different object is returned, see if it is Status and avoid double decoding
// the object.
switch t := out.(type) {
case *metav1.Status:
// any status besides StatusSuccess is considered an error.
if t.Status != metav1.StatusSuccess {
return errors.FromObject(t)
}
}
return nil
}3部曲,构建request,do,decode response body,注意这个decode是阻塞的,默认使用json的decoder,在List的过程,笔者本地并未阻塞,可能跟不支持chunk有关,或者笔者的K8S版本比较新,旧版本支持chunk。 笔者就读取到了抓包的第一个请求,获取500条以内的items pod列表,和当前资源版本号
3.4 watch核心过程
Watch实际上在上面讲的定时任务就会触发,最终触发WatchFunc函数指针
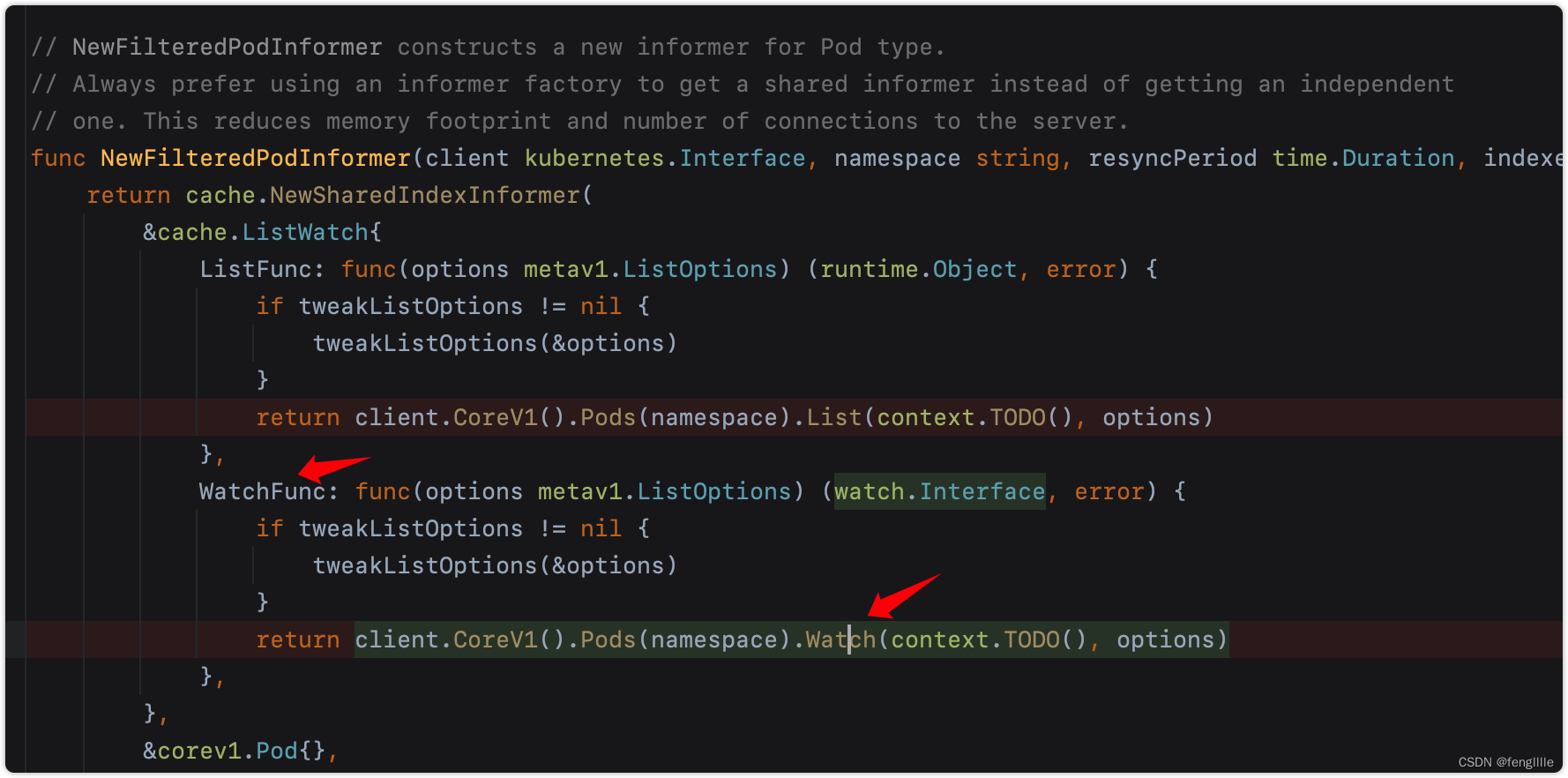
分析源码
// Watch returns a watch.Interface that watches the requested pods.
func (c *pods) Watch(ctx context.Context, opts metav1.ListOptions) (watch.Interface, error) {
var timeout time.Duration
if opts.TimeoutSeconds != nil {
timeout = time.Duration(*opts.TimeoutSeconds) * time.Second
}
opts.Watch = true
return c.client.Get().
Namespace(c.ns).
Resource("pods").
VersionedParams(&opts, scheme.ParameterCodec).
Timeout(timeout).
Watch(ctx)
}普通的Http请求,核心看Watch
// Watch attempts to begin watching the requested location.
// Returns a watch.Interface, or an error.
func (r *Request) Watch(ctx context.Context) (watch.Interface, error) {
// We specifically don't want to rate limit watches, so we
// don't use r.rateLimiter here.
if r.err != nil {
return nil, r.err
}
client := r.c.Client
if client == nil {
client = http.DefaultClient
}
isErrRetryableFunc := func(request *http.Request, err error) bool {
// The watch stream mechanism handles many common partial data errors, so closed
// connections can be retried in many cases.
if net.IsProbableEOF(err) || net.IsTimeout(err) {
return true
}
return false
}
retry := r.retryFn(r.maxRetries)
url := r.URL().String()
for {
if err := retry.Before(ctx, r); err != nil {
return nil, retry.WrapPreviousError(err)
}
req, err := r.newHTTPRequest(ctx)
if err != nil {
return nil, err
}
//http请求
resp, err := client.Do(req)
updateURLMetrics(ctx, r, resp, err)
retry.After(ctx, r, resp, err)
if err == nil && resp.StatusCode == http.StatusOK {
return r.newStreamWatcher(resp) //这里很关键,毕竟正常情况下就是这里处理的,就是http长轮询的原因,response的body控制阻塞,并通过管道跟delta和handler交互
}
//错误消息处理
done, transformErr := func() (bool, error) {
defer readAndCloseResponseBody(resp)
if retry.IsNextRetry(ctx, r, req, resp, err, isErrRetryableFunc) {
return false, nil
}
if resp == nil {
// the server must have sent us an error in 'err'
return true, nil
}
if result := r.transformResponse(resp, req); result.err != nil {
return true, result.err
}
return true, fmt.Errorf("for request %s, got status: %v", url, resp.StatusCode)
}()
//错误处理成功就返回,等下一次ListAndWatch了
//否则就再发一次请求
if done {
if isErrRetryableFunc(req, err) {
return watch.NewEmptyWatch(), nil
}
if err == nil {
// if the server sent us an HTTP Response object,
// we need to return the error object from that.
err = transformErr
}
return nil, retry.WrapPreviousError(err)
}
}
}可以看到Https 并不是chunk,没有chunk标记

newStreamWatcher
func (r *Request) newStreamWatcher(resp *http.Response) (watch.Interface, error) {
contentType := resp.Header.Get("Content-Type")
mediaType, params, err := mime.ParseMediaType(contentType)
if err != nil {
klog.V(4).Infof("Unexpected content type from the server: %q: %v", contentType, err)
}
objectDecoder, streamingSerializer, framer, err := r.c.content.Negotiator.StreamDecoder(mediaType, params)
if err != nil {
return nil, err
}
handleWarnings(resp.Header, r.warningHandler)
//帧处理,命名可以简单认为http2,resp.Body,这个是个流,可以被server阻塞
frameReader := framer.NewFrameReader(resp.Body)
watchEventDecoder := streaming.NewDecoder(frameReader, streamingSerializer)
//这个是神奇操作,就是数据的接收操作
return watch.NewStreamWatcher(
restclientwatch.NewDecoder(watchEventDecoder, objectDecoder),
// use 500 to indicate that the cause of the error is unknown - other error codes
// are more specific to HTTP interactions, and set a reason
errors.NewClientErrorReporter(http.StatusInternalServerError, r.verb, "ClientWatchDecoding"),
), nil
}实际上就是协程读取Decoder sw.receive()
// NewStreamWatcher creates a StreamWatcher from the given decoder.
func NewStreamWatcher(d Decoder, r Reporter) *StreamWatcher {
sw := &StreamWatcher{
source: d,
reporter: r,
// It's easy for a consumer to add buffering via an extra
// goroutine/channel, but impossible for them to remove it,
// so nonbuffered is better.
result: make(chan Event),
// If the watcher is externally stopped there is no receiver anymore
// and the send operations on the result channel, especially the
// error reporting might block forever.
// Therefore a dedicated stop channel is used to resolve this blocking.
done: make(chan struct{}),
}
go sw.receive()
return sw
}sw.receive()
// receive reads result from the decoder in a loop and sends down the result channel.
func (sw *StreamWatcher) receive() {
defer utilruntime.HandleCrash()
defer close(sw.result)
defer sw.Stop()
for {
//核心就这里,不断的读取,直到EOF,或者sw done
action, obj, err := sw.source.Decode()
if err != nil {
switch err {
case io.EOF:
// watch closed normally
case io.ErrUnexpectedEOF:
klog.V(1).Infof("Unexpected EOF during watch stream event decoding: %v", err)
default:
if net.IsProbableEOF(err) || net.IsTimeout(err) {
klog.V(5).Infof("Unable to decode an event from the watch stream: %v", err)
} else {
select {
case <-sw.done:
case sw.result <- Event{
Type: Error,
Object: sw.reporter.AsObject(fmt.Errorf("unable to decode an event from the watch stream: %v", err)),
}:
}
}
}
return
}
select {
case <-sw.done:
return
case sw.result <- Event{ //watch结果
Type: action,
Object: obj,
}:
}
}
}这个sw的result的管道就会在cache.(*Reflector).ListAndWatch 的
watchHandler
写入deltafifo队列,队列POP就会触发handler和store存储
sw.source.Decode()一般情况数据是json数据,会使用json的Decoder处理,笔者本地的K8S是读取过程中阻塞,直到api-server有数据过来。
总结
实际上client-go的核心代码并不复杂,但是有比较长的流程,架构设计又有restClient的多重交付,后面的fifo队列,监听器回调,本地store等,demo案例的POD监听大概逻辑如下图:
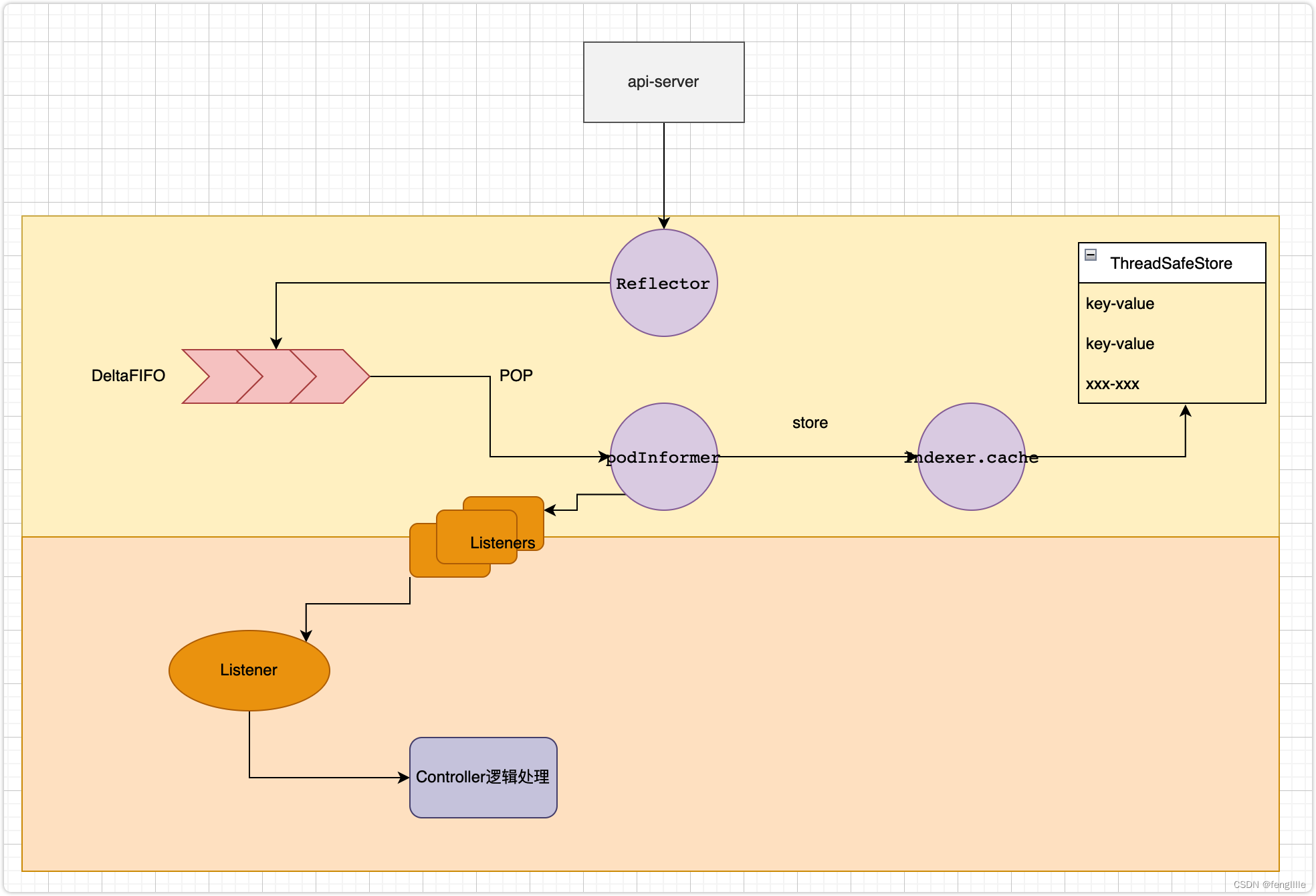
看起来很简单,但是细节很多,而且实现多样化,最难受的是匿名函数指针的传递,很难受,读懂代码需要结合上下文才行。
参考资料
如何通过抓包来查看Kubernetes API流量-阿里云开发者社区 (aliyun.com)
可能是史上最全的Kubernetes证书解析 (qingwave.github.io)