文章目录
- 流式插入概述
- 一. Hudi流式插入案例1(datagen)
- 1.1 准备工作
- 1.2 源端准备
- 1.3 目标端表准备
- 1.4 ETL准备
- 1.5 数据验证
- 1.6 通过SPARK SQL查看数据
- 二. Hudi流式插入案例2(Kafka)
- 2.1 准备工作
- 2.2 源端准备
- 2.2.1 创建kafka的topic (hudi_flink)
- 2.2.2 Flink SQL Client消费kafka数据
- 2.3 目标端表准备
- 2.4 ETL准备
- 2.5 验证数据
- 参考:
流式插入概述
kafka (映射为一个flink table source_table)-> flink (insert into target_table select * from source_table) -> hudi (映射为一个 flink table target_table)
一. Hudi流式插入案例1(datagen)
1.1 准备工作
# 启动yarn session(非root账户)
/home/flink-1.14.5/bin/yarn-session.sh -d 2>&1 &
# 在yarn session模式下启动Flink SQL
/home/flink-1.14.5/bin/sql-client.sh embedded -s yarn-session
1.2 源端准备
这里我们使用了数据生成器,datagen,下面有参数控制数据生成的频率。
-- sets up the result mode to tableau to show the results directly in the CLI
set execution.result-mode=tableau;
-- 设置checkpoint,不然会一直卡住
set execution.checkpointing.interval=10sec;
create table my_sourceT_12 (
uuid varchar(200),
name varchar(100),
age int,
ts timestamp(3)
) with (
'connector' = 'datagen',
'rows-per-second' = '1'
)
;

1.3 目标端表准备
CREATE TABLE my_targetT_12(
uuid VARCHAR(20) PRIMARY KEY NOT ENFORCED,
name VARCHAR(10),
age INT,
ts TIMESTAMP(3)
)
WITH (
'connector' = 'hudi',
'path' = 'hdfs://hp5:8020/user/hudi_data/my_targetT_12',
'table.type' = 'MERGE_ON_READ' -- this creates a MERGE_ON_READ table, by default is COPY_ON_WRITE
);
1.4 ETL准备
insert into my_targetT_12 (uuid, name, age, ts)
select uuid, name, age, ts
from my_sourceT_12 ;
select * from my_targetT_12;

1.5 数据验证
在页面运行这个,依旧会有一个报错
select * from my_targetT_12;
报错:
这个报错是我测试环境的CPU资源不够导致的
org.apache.hadoop.yarn.server.nodemanager.containermanager.monitor.ContainersMonitorImpl: Skipping monitoring container since CPU usage is not yet available.
HDFS查看数据:
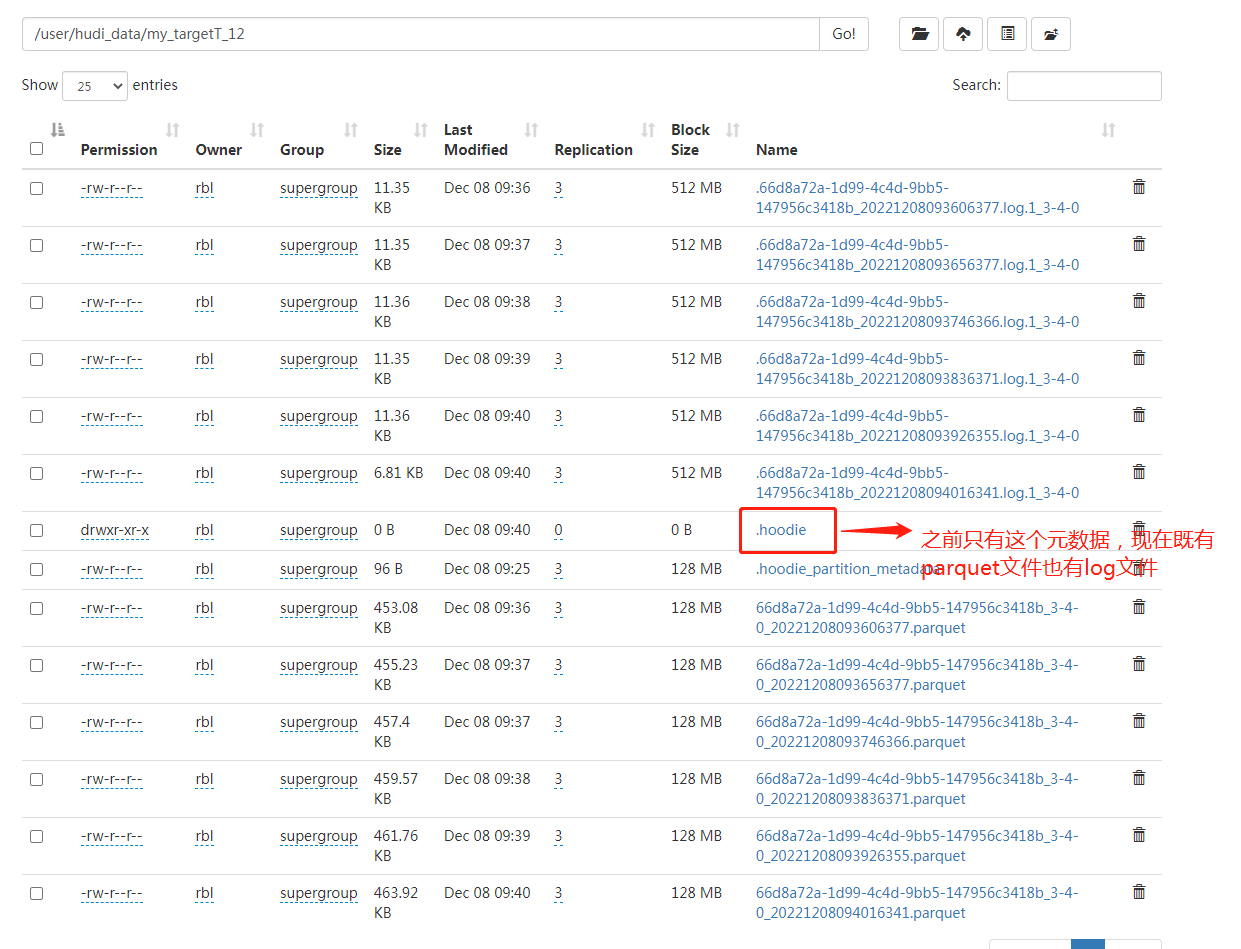
1.6 通过SPARK SQL查看数据
连接Spark SQL:
# Spark 3.3
spark-sql --packages org.apache.hudi:hudi-spark3.3-bundle_2.12:0.12.0 \
--conf 'spark.serializer=org.apache.spark.serializer.KryoSerializer' \
--conf 'spark.sql.extensions=org.apache.spark.sql.hudi.HoodieSparkSessionExtension' \
--conf 'spark.sql.catalog.spark_catalog=org.apache.spark.sql.hudi.catalog.HoodieCatalog'
创建Hudi表:
建表的语法存在差异,需要进行调整,有的字段类型都不对应
CREATE TABLE my_targetT_12(
uuid VARCHAR(20) ,
name VARCHAR(10),
age INT,
ts TIMESTAMP
)
using hudi
location 'hdfs://hp5:8020/user/hudi_data/my_targetT_12';
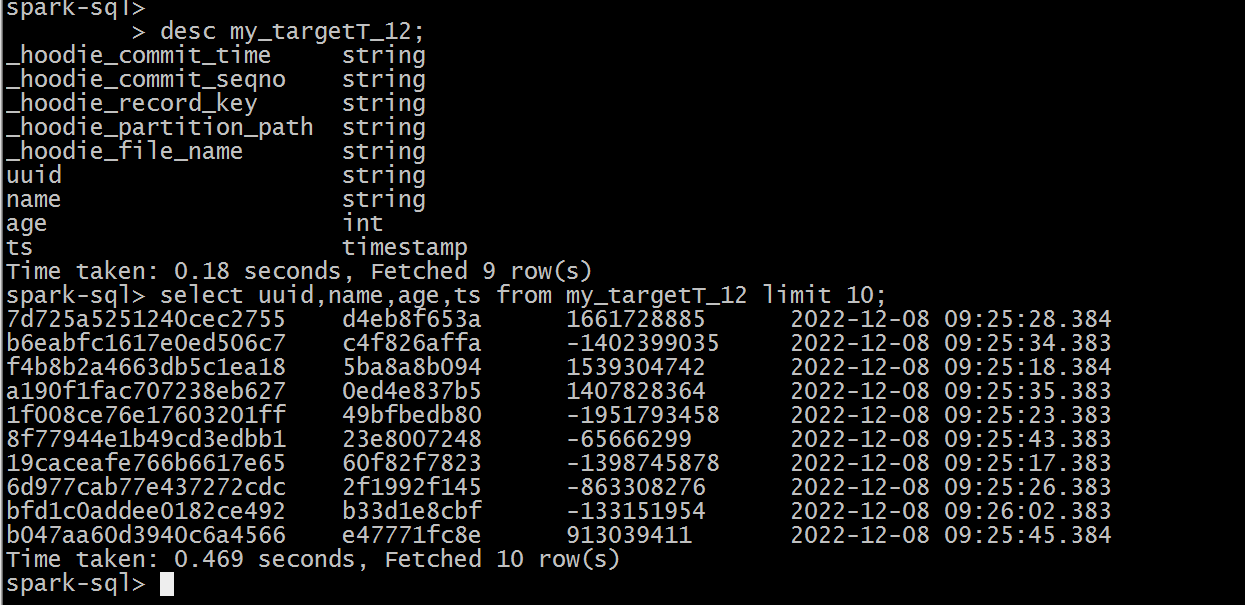
查询Hudi表数据:
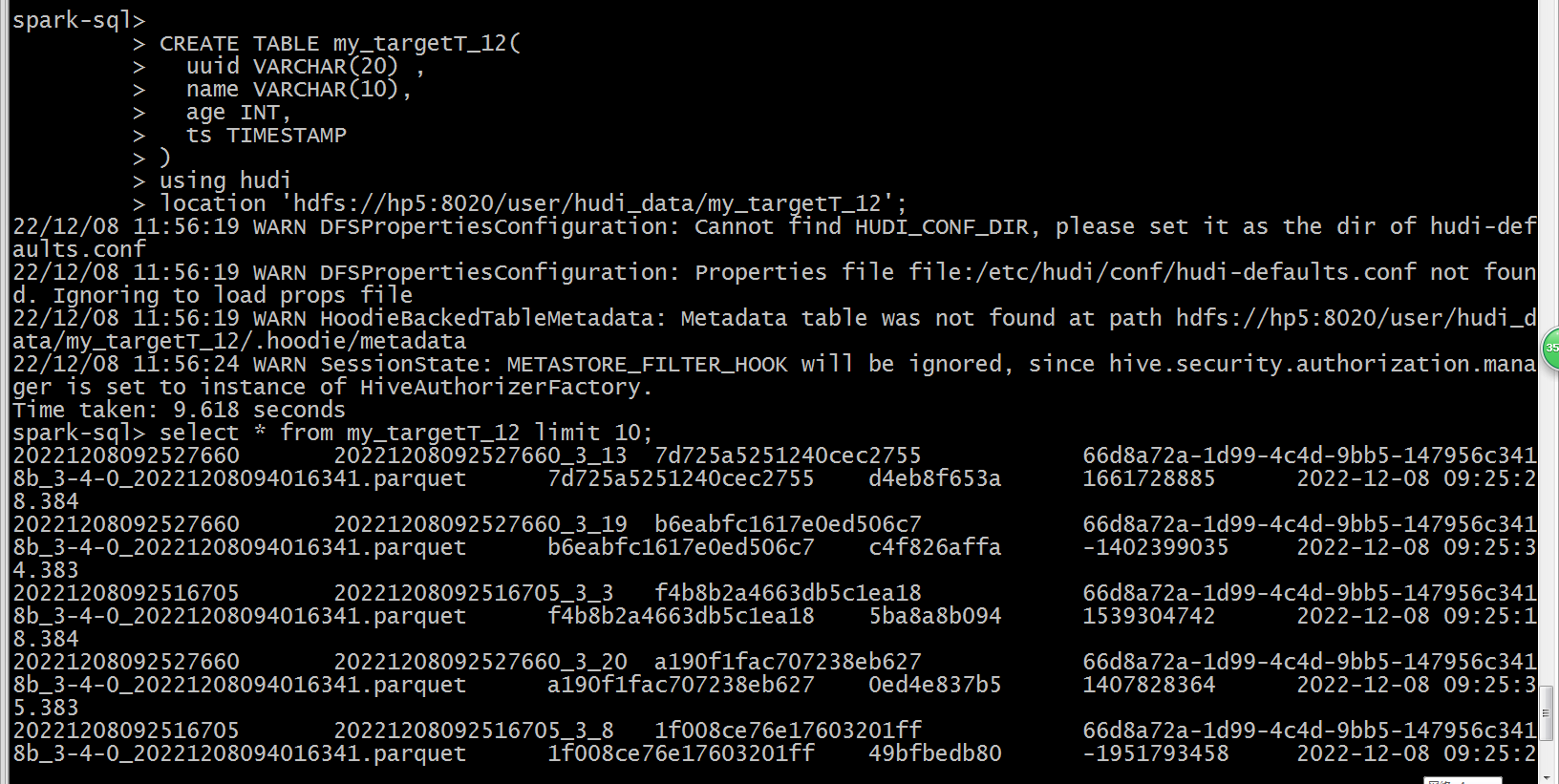
select * from my_targetT_12 limit 10;
测试记录:
二. Hudi流式插入案例2(Kafka)
2.1 准备工作
# 启动yarn session(非root账户)
/home/flink-1.15.2/bin/yarn-session.sh -d 2>&1 &
# 在yarn session模式下启动Flink SQL
/home/flink-1.15.2/bin/sql-client.sh embedded -s yarn-session
2.2 源端准备
这里我们使用Kafka作为源端
2.2.1 创建kafka的topic (hudi_flink)
cd /opt/cloudera/parcels/CDH-6.3.1-1.cdh6.3.1.p0.1470567/lib/kafka/bin/
./kafka-topics.sh --zookeeper hp2:2181 --create --replication-factor 3 --partitions 3 --topic hudi_flink4
2.2.2 Flink SQL Client消费kafka数据
-
将Flink连接Kafka的jar包放到Flink的lib目录
https://nightlies.apache.org/flink/flink-docs-release-1.15/docs/connectors/table/kafka/ -
创建kafka表
-- sets up the result mode to tableau to show the results directly in the CLI
set execution.result-mode=tableau;
-- 设置checkpoint,不然会一直卡住
set execution.checkpointing.interval=10sec;
CREATE TABLE hudi_flink_kafka_source4 (
orderId STRING,
userId STRING,
orderTime STRING,
ip STRING,
orderMoney DOUBLE,
orderStatus INT
) WITH (
'connector' = 'kafka',
'topic' = 'hudi_flink4',
'properties.bootstrap.servers' = 'hp2:9092',
'properties.group.id' = 'zqs-1004',
'scan.startup.mode' = 'latest-offset',
'format' = 'json',
'json.fail-on-missing-field' = 'false',
'json.ignore-parse-errors' = 'true'
);
- 往kafka的topic插入数据
/opt/cloudera/parcels/CDH-6.3.1-1.cdh6.3.1.p0.1470567/lib/kafka/bin/kafka-console-producer.sh --broker-list hp2:9092 --topic hudi_flink4
{"orderId": "20211122103434136000001","userId": "300000971","orderTime": "2021-11-22 10:34:34.136","ip": "123.232.118.98","orderMoney": 485.48,"orderStatus": 0}
{"orderId": "20211122103434136000002","userId": "300000972","orderTime": "2021-11-22 10:34:34.136","ip": "123.232.118.98","orderMoney": 485.48,"orderStatus": 0}
{"orderId": "20211122103434136000003","userId": "300000973","orderTime": "2021-11-22 10:34:34.136","ip": "123.232.118.98","orderMoney": 485.48,"orderStatus": 0}
- 在flink sql客户端查看数据消费
select * from hudi_flink_kafka_source4 ;

2.3 目标端表准备
CREATE TABLE hudi_flink_kafka_sink4 (
orderId STRING PRIMARY KEY NOT ENFORCED,
userId STRING,
orderTime STRING,
ip STRING,
orderMoney DOUBLE,
orderStatus INT,
ts STRING,
partition_day STRING
)
PARTITIONED BY (partition_day)
WITH (
'connector' = 'hudi',
'path' = 'hdfs://hp5:8020/user/hudi_data/hudi_flink_kafka_sink4',
'table.type' = 'MERGE_ON_READ',
'write.operation' = 'upsert',
'hoodie.datasource.write.recordkey.field'= 'orderId',
'write.precombine.field' = 'ts',
'write.tasks'= '1',
'compaction.tasks' = '1',
'compaction.async.enabled' = 'true',
'compaction.trigger.strategy' = 'num_commits',
'compaction.delta_commits' = '1'
);
2.4 ETL准备
INSERT INTO hudi_flink_kafka_sink4
SELECT
orderId, userId, orderTime, ip, orderMoney, orderStatus,
substring(orderId, 0, 17) AS ts, substring(orderTime, 0, 10) AS partition_day
FROM hudi_flink_kafka_source4 ;
2.5 验证数据
HDFS:
参考:
- https://blog.csdn.net/NC_NE/article/details/125705845