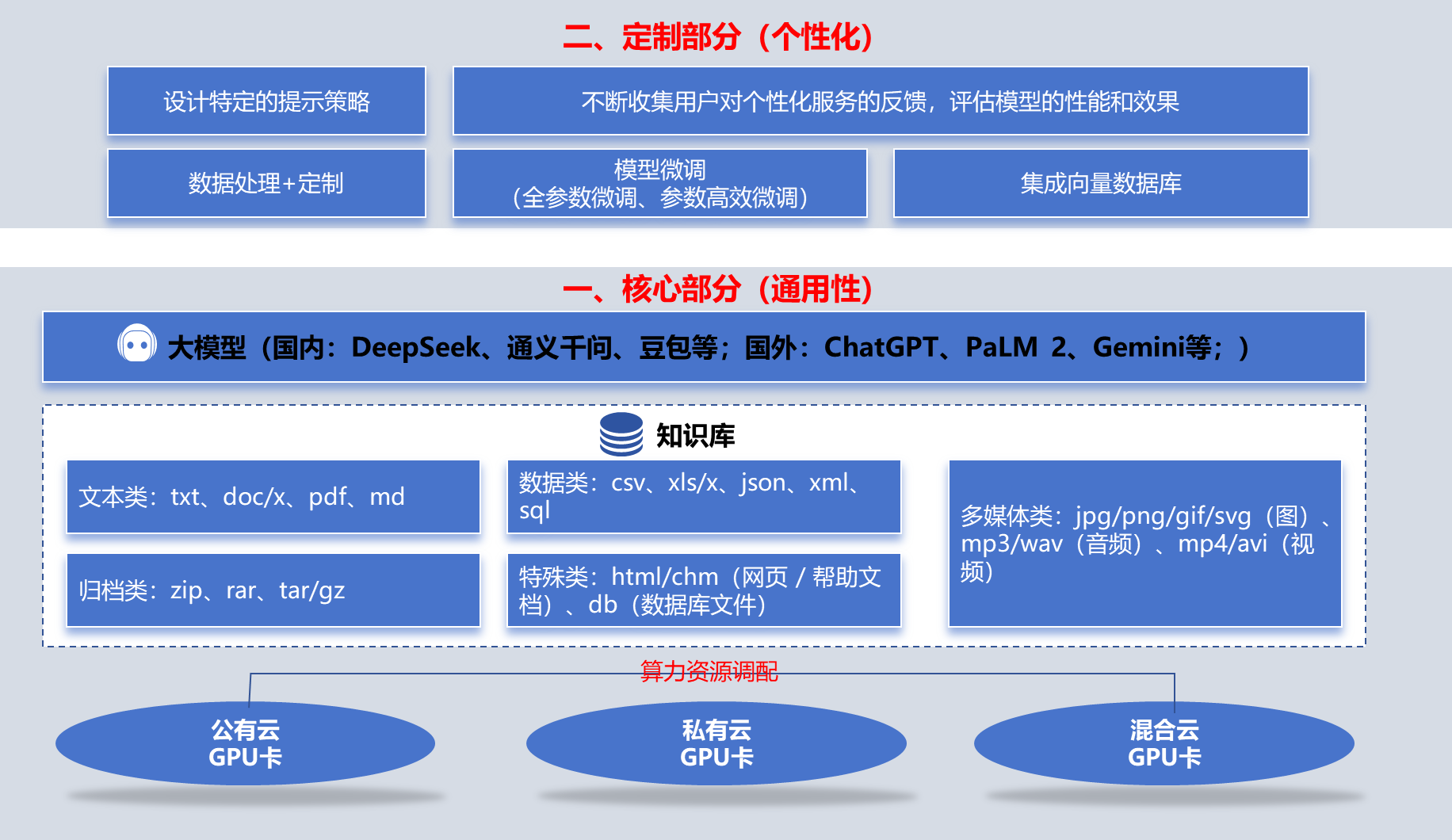
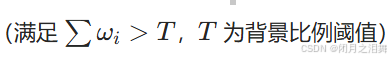通过Tesseract进行OCR识别
前提:安装好Tesseract并下载好简体中文语言包,本文在Windows上验证过,需要安装包可以关注 公号 easy4java获取
1.配置maven依赖
<!-- pdf 解析-->
<dependency>
<groupId>org.apache.pdfbox</groupId>
<artifactId>pdfbox</artifactId>
<version>2.0.1</version>
</dependency>
<dependency>
<groupId>org.apache.pdfbox</groupId>
<artifactId>fontbox</artifactId>
<version>2.0.0</version>
</dependency>
<dependency>
<groupId>org.apache.pdfbox</groupId>
<artifactId>jempbox</artifactId>
<version>1.8.11</version>
</dependency>
<dependency>
<groupId>org.apache.pdfbox</groupId>
<artifactId>xmpbox</artifactId>
<version>2.0.0</version>
</dependency>
<dependency>
<groupId>org.apache.pdfbox</groupId>
<artifactId>preflight</artifactId>
<version>2.0.0</version>
</dependency>
<dependency>
<groupId>org.apache.pdfbox</groupId>
<artifactId>pdfbox-tools</artifactId>
<version>2.0.0</version>
</dependency>
<!-- Tesseract OCR-->
<dependency>
<groupId>net.sourceforge.tess4j</groupId>
<artifactId>tess4j</artifactId>
<version>4.5.4</version>
</dependency>2.Java代码实现
/**
* @Author:admin
* @Date: 2025/4/21 15:53
* @Description admin
* @Version 1.0.0
*/
import net.sourceforge.tess4j.Tesseract;
import net.sourceforge.tess4j.TesseractException;
import org.apache.pdfbox.cos.COSName;
import org.apache.pdfbox.pdmodel.PDDocument;
import org.apache.pdfbox.pdmodel.PDPage;
import org.apache.pdfbox.pdmodel.PDResources;
import org.apache.pdfbox.pdmodel.graphics.image.PDImageXObject;
import java.awt.image.BufferedImage;
import java.io.File;
import java.io.IOException;
import java.util.Iterator;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class PDFTextRecognition {
public static void main(String[] args) {
try {
long start = System.currentTimeMillis();
// 1. 读取PDF文件
PDDocument document = PDDocument.load(new File("C:\\Users\\admin\\Desktop\\test.pdf"));
PDPage page = document.getPage(0);
PDResources resource = page.getResources();
Iterable<COSName> xobjects = resource.getXObjectNames();
if (xobjects != null) {
Iterator<COSName> imageItr = xobjects.iterator();
while (imageItr.hasNext()) {
COSName imageName = imageItr.next();
boolean isImage = resource.isImageXObject(imageName);
if (isImage) {
PDImageXObject ixt = (PDImageXObject) resource.getXObject(imageName);
// 3. 使用OCR识别图像中的文字
Tesseract tesseract = new Tesseract();
//从官网下载简体中文语言包
tesseract.setLanguage("chi_sim");
//要语言包放在安装目录下tessdata目录下
tesseract.setDatapath("E:\\software\\tesseract\\tessdata"); // 设置Tesseract的语言数据文件路径
//截取要识别的图片区域,减少无效区域的识别,如果有需要可以进行放大操作(提高识别的准确率)
BufferedImage image = ixt.getImage();
BufferedImage subImage = image.getSubimage(0, 0, 2000, 800);
String text = tesseract.doOCR(subImage);
extractContractNumber(text);
System.out.println(text);
}
}
}
// 关闭PDF文档
document.close();
long end = System.currentTimeMillis();
System.out.println("消费时长" + (end - start) / 1000 + "s");
} catch (IOException | TesseractException e) {
e.printStackTrace();
}
}
/**
* 通过正则解析识别出的内容
*
* @param text
*/
public static void extractContractNumber(String text) {
// 正则表达式模式
Pattern supplierPattern = Pattern.compile("供\\s*方\\s*[::]\\s*(.*?)\\s*合\\s*同\\s*编\\s*号");
Pattern contractNoPattern = Pattern.compile("合\\s*同\\s*编\\s*号\\s*[::]\\s*(\\w+)");
Pattern buyerPattern = Pattern.compile("需\\s*方\\s*[,,]\\s*(.*?)\\s*签\\s*订\\s*日\\s*期");
// 匹配供方
Matcher supplierMatcher = supplierPattern.matcher(text);
if (supplierMatcher.find()) {
String supplier = supplierMatcher.group(1).replaceAll("\\s+", "");
System.out.println("供方: " + supplier);
}
// 匹配合同编号
Matcher contractNoMatcher = contractNoPattern.matcher(text);
if (contractNoMatcher.find()) {
String contractNo = contractNoMatcher.group(1);
System.out.println("合同编号: " + contractNo);
}
// 匹配需方
Matcher buyerMatcher = buyerPattern.matcher(text);
if (buyerMatcher.find()) {
String buyer = buyerMatcher.group(1).replaceAll("\\s+", "");
System.out.println("需方: " + buyer);
}
}
}
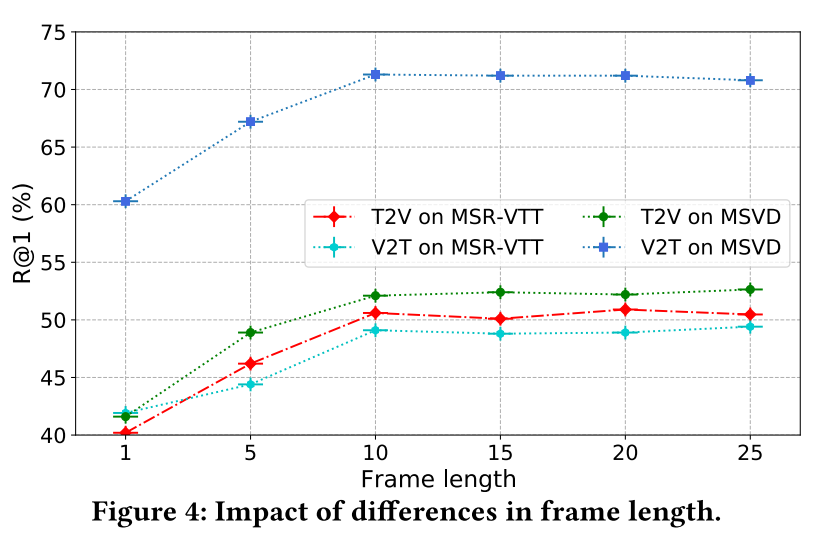
![BUUCTF-[GWCTF 2019]re3](https://i-blog.csdnimg.cn/img_convert/730b9bfcf31517e9d5835f9bdcf201f9.png)