文章链接:https://arxiv.org/pdf/2405.14832
github链接:https://nju-3dv.github.io/projects/Direct3D/
从文本和图像生成高质量的3D资产一直是一项挑战,主要是由于缺乏能够捕捉复杂几何分布的可扩展3D表示。在这项工作中,介绍了Direct3D,这是一种可扩展到in-the-wild输入图像的原生3D生成模型,不需要多视角扩散模型或SDS优化。
方法包括两个主要组件:Direct 3D Variational Auto-Encoder(D3D-VAE)和 Direct 3D Diffusion Transformer (D3D-DiT)。D3D-VAE高效地将高分辨率3D形状编码到紧凑且连续的三平面潜在空间中。
值得注意的是,该方法直接使用半连续表面采样策略对解码的几何形状进行监督,区别于依赖渲染图像作为监督信号的先前方法。D3D-DiT对编码的3D潜在分布建模,专门设计用于融合来自三平面潜在空间的三个特征图的位置信息,从而实现一个可扩展到大规模3D数据集的原生3D生成模型。
此外,还引入了一种创新的图像到3D生成pipeline,结合了语义和像素级图像条件,使模型能够生成与提供的条件图像输入一致的3D形状。大量实验表明,大规模预训练的Direct3D相比以往的图像到3D方法具有显著的优势,显著提升了生成质量和泛化能力,从而确立了3D内容创建的新标杆。
介绍
近年来,通过利用扩散模型,3D形状生成取得了实质性进展。受文本到2D图像生成中高效性的启发,这些方法试图通过在多样化的3D数据集上进行广泛训练,将扩散模型的能力扩展到3D形状生成领域。各种方法探索了不同的3D表示形式,包括点云、体素和符号距离函数(SDFs),不仅旨在真实捕捉物体的外观,还要保留复杂的几何细节。然而,现有的大规模3D数据集,如ObjverseXL,在形状的数量和多样性上都受到了限制,相比之下,其2D对标数据集如Laion5B包含了50亿张图像,而ObjverseXL仅包含1000万个3D形状。
为了解决这一限制,许多现有方法采用了一个流程:首先使用多视图扩散模型从单张图像生成物体的多视图图像,然后应用稀疏视图重建方法或评分蒸馏采样(SDS)优化将这些多视图图像融合为3D形状。虽然这个流程可以产生高质量的3D形状,但通过多视图图像间接生成的方法引发了效率问题。此外,生成形状的质量严重依赖于多视图图像的保真度,往往导致细节丢失或重建失败。
本文摒弃了间接生成多视图图像的传统方法,转而倡导通过原生3D扩散模型直接从单视图图像生成3D形状。受到潜在扩散模型在2D图像生成中成功经验的启发,我们提出使用3D变分自编码器(VAE)将3D形状编码到潜在空间,然后使用diffusion transformer model(DiT)从该潜在空间生成3D形状,并以图像输入作为条件。然而,高效地将3D形状编码到适合扩散模型训练的潜在空间中,以及将潜在表示解码回3D几何形状,都是具有挑战性的任务。先前的方法通过可微渲染使用多视图图像作为间接监督,但仍然面临准确性和效率问题。
为了解决这些挑战,研究者们采用transformer模型将高分辨率点云编码为显式三平面潜在空间,这在3D重建方法中被广泛使用,因为其效率高。虽然三平面潜在空间的分辨率故意设置较低,但引入卷积神经网络来上采样潜在分辨率并将其解码为高分辨率的3D占用网格。此外,为了确保对3D占用网格的精确监督,我们采用半连续表面采样策略,能够在连续和离散方式下对表面点进行采样和监督。这种方法有助于在紧凑且连续的显式潜在空间中编码和重建3D形状。
在图像到3D生成方面,研究者们进一步利用图像作为3D扩散Transformer的条件输入,将3D潜在空间安排为3D形状的三个正交视图的组合。特别地,将像素级图像信息集成到每个DiT块中,以确保生成的3D模型与条件图像之间的高频细节对齐。在每个DiT块中引入了交叉注意力层,以融合语义级图像信息,从而促进生成与条件图像语义一致的高质量3D形状。
通过广泛的实验,展示了所提出的Direct3D方法的高质量3D生成和强大的泛化能力。下图1展示了我们的方法在野外图像生成的3D结果,这些图像来自Hunyuan-DiT。总结起来,

主要贡献:
- 提出了Direct3D,是第一个原生3D生成模型,能够扩展到in-the-wild 输入图像。这使得高保真度的图像到3D生成成为可能,而不需要多视图扩散模型或SDS优化。
- 提出了D3D-VAE,一种新颖的3D变分自编码器,有效地将3D点云编码为三平面潜在空间。我们不使用渲染图像作为监督信号,而是通过半连续表面采样策略直接监督解码几何形状,以保留潜在三平面中的详细3D信息。
- 提出了D3D-DiT,一种可扩展的图像条件3D Diffusion Transformer,能够生成与输入图像一致的3D形状。D3D-DiT特别设计为更好地融合来自潜在三平面的位置信息,并有效整合输入图像的像素级和语义级信息。
- 通过广泛的实验表明,大规模预训练Direct3D模型在生成质量和泛化能力方面超越了以往的图像到3D方法,为3D内容创建任务设立了新的标杆。
相关工作
3D生成的神经3D表示
神经3D表示对于3D生成任务至关重要。神经辐射场(NeRF)的引入显著推动了3D生成的发展。在此基础上,DreamFusion引入了评分蒸馏采样(SDS)方法,使用现成的2D扩散模型从任意文本提示生成3D形状。许多后续方法探索了各种表示形式,以提升3D生成的速度和质量。例如,Magic3D通过引入第二阶段使用DMtet表示来改善生成质量,该表示将符号距离函数(SDF)与四面体网格结合以表示3D形状。
除了基于SDS的方法,一些方法使用直接训练的网络生成不同的表示形式。例如,LRM使用三平面NeRF表示作为网络输出,显著加快了生成过程,尽管有一定的质量损失。另一种方法,One-2-3-45++,提出使用3D占用网格作为输出表示,以提升几何质量。
多视图扩散
在使用扩散模型进行新视图预测方法取得成功之后,如Zero123——该方法从单张图像和文本指导生成物体的不同未知视图——MVDream将新视图扩散扩展为一次生成物体的多个视图,从而提高了视图间的一致性。Imagedream通过引入新的图像条件模块进一步提升了生成质量。一些方法采用这种方法,先生成物体的多视图图像,然后使用稀疏重建从这些视图重建3D形状。Instant3D提出了一种重建模型,该模型以四个多视图图像作为输入,重建3D形状的NeRF表示。许多后续方法通过增强多视图或重建模型进行了改进。
直接3D扩散
尽管直接训练3D扩散模型面临诸多挑战——如缺乏可扩散的3D表示——各种策略已被探索。一类工作是拟合多个NeRF以获得3D数据集的神经表示,然后应用扩散模型从这种学习到的表示中生成NeRF。然而,NeRF的单独训练可能会阻碍扩散模型对更多样化的3D形状的泛化能力。3DGenNeural提出联合训练三平面拟合3D形状,并以占用为直接监督来训练三平面重建模型。
另一类工作利用VAE将3D形状编码到潜在空间,并在该潜在空间上训练扩散模型以生成3D形状。例如,Shap-E使用纯TransformerVAE将3D形状的点云和图像编码到隐式潜在空间,然后恢复为NeRF和SDF场。3DGen仅将3D形状的点云编码到显式三平面潜在空间,从而提高了生成效率。类似于之前拟合多个NeRF的工作,3DTopia拟合多个三平面NeRF并将其编码到潜在空间,为扩散模型生成3D形状进行训练。Michelangelo使用3D占用作为VAE的输出表示,但使用多个1D向量作为隐式潜在空间,而不是三平面。
然而,这些方法通常依赖渲染损失来监督VAE重建,导致次优的重建和生成质量。此外,使用未设计为高效编码的隐式潜在表示,并缺乏用于扩散的紧凑显式3D表示,进一步限制了它们的性能。我们的D3D-VAE结合了显式3D潜在表示和直接3D监督的优势,实现了高质量的VAE重建,确保了稳健的3D形状生成。此外,我们的扩散架构设计专门解决了条件3D潜在生成问题。我们的D3D-DiT促进了像素级和语义级的3D特定图像条件,使扩散过程能够生成与条件图像一致的高细节3D形状。
方法
受LDM的启发,在3D潜在空间内训练了一种潜在扩散模型用于3D生成。与通常依赖于1D隐式潜在空间的生成模型不同,本文的方法解决了两个关键限制:
- 1)隐式潜在表示难以捕捉3D空间中固有的结构化信息,导致解码出的3D形状质量欠佳;
- 2)隐式潜在空间缺乏结构和约束,训练和采样潜在分布具有挑战性。
为了缓解这些问题,采用了显式三平面潜在表示,利用三张特征图来表示3D几何潜在空间。这种设计的灵感来自LDM,它使用特征图来表示2D图像潜在空间。下图2展示了本文提出的方法的整体框架,包括两个步骤的训练过程:
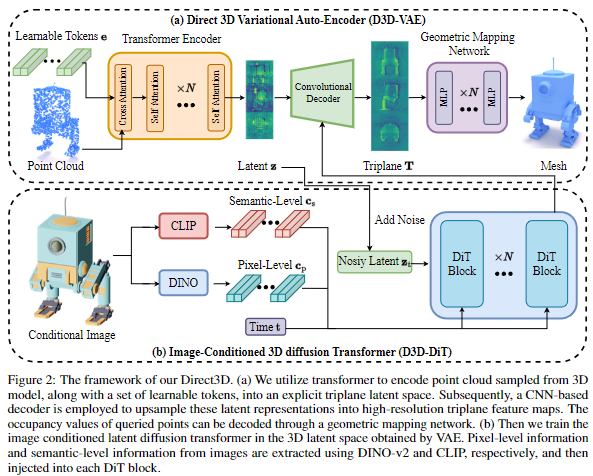
- 1)首先训练D3D-VAE将3D形状转换为3D潜在表示;
- 2)然后训练图像条件的D3D-DiT生成高质量的3D资产。
Direct 3D Variational Auto-Encoder
提出的D3D-VAE包含三个组件:点到潜在编码器、潜在到三平面解码器和几何映射网络。同时,设计了一种半连续表面采样策略,利用连续和离散监督确保解码的3D形状的高频几何细节。
点到潜在编码器。为了在潜在空间中获得能有效捕捉复杂几何的稳健表示,均匀地从3D对象的表面采样高分辨率点云,然后将其编码为显式潜在表示 $ z \in \mathbb{R}^{(3 \times r \times r) \times d_z}$,其中 r r r 和 d z d_z dz 分别表示潜在表示的分辨率和通道维度。具体来说,给定从3D模型中采样的一组点云 $ P \in \mathbb{R}^{N_P \times (3+3)}$,其中 $ N_P $ 表示点的数量,通道维度 (3+3) 包括每个点的归一化位置和法线,首先使用傅里叶特征来表示点云的位置结构。然后,引入一系列可学习的token $ e \in \mathbb{R}^{(3 \times r \times r) \times d_e} $ 来使用交叉注意力层查询点云特征,其中 d e d_e de 表示 $ e $ 的通道维度。这使得可以将点云中的3D信息注入到潜在token中。随后,使用多个自注意力层增强这些token的表示,最终生成潜在表示 $ z \in \mathbb{R}^{(3 \times r \times r) \times d_z} $,其中 d z d_z dz 表示 z z z 的通道维度。
潜在到三平面解码器。在获得潜在表示 z z z 后,将其重塑为三平面表示。受RODIN的启发,沿高度维度垂直连接三个平面,得到 $z \in \mathbb{R}^{r \times (3 \times r) \times d_z} $,以防止平面在通道维度上的错误混合。随后,潜在-三平面解码器将 $ z $ 上采样为高分辨率的三平面特征图,具有上采样因子 f f f。与编码器中使用的Transformer架构不同,我们的解码器模型采用卷积网络逐步上采样显式潜在表示,并获得最终的三平面 $ T = (T_{XY}, T_{YZ}, T_{XZ})$。
半连续表面采样。采用多层感知器(MLP)作为几何映射网络,通过从三平面插值的特征来预测查询点的占据情况。MLP包含多个具有ReLU激活的线性层。典型的占据情况由离散的二进制值0和1表示,以指示点是否在物体内部。然而,当查询点非常接近物体表面时,会导致梯度变化剧烈,从而影响模型优化。在本工作中,我们采用半连续占据,使用连续和离散监督以确保平滑梯度。具体来说,给定3D空间中的查询点 x x x,当其到表面的距离大于一个小阈值 s = 1 512 s = \frac{1}{512} s=5121 时,占据值保持为0或1。当距离小于 s s s 时,赋予其一个从0到1的连续值。半连续占据 o ( x ) o(x) o(x) 的公式如下:
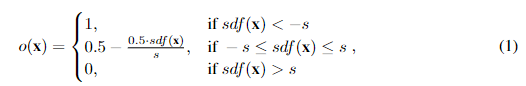
其中 sdf(x) 表示 x 的有符号距离函数(Signed Distance Function,SDF)值。
端到端优化。在训练过程中,从3D空间均匀采样点,并从物体表面附近采样点以预测它们的半连续占据情况。利用二元交叉熵(Binary Cross-Entropy,BCE)损失 L B C E L_{BCE} LBCE 监督预测。此外,使用 KL 损失 L K L L_{KL} LKL 防止潜在空间中的过度方差。因此, D3D-VAE 通过最小化以下损失进行优化:

其中 λ K L \lambda_{KL} λKL表示KL正则化的权重
基于图像条件的直接3D Diffusion Transformer
在训练完D3D-VAE之后,可以获得一个连续且紧凑的潜在空间,基于这个空间训练潜在扩散模型。由于3D数据相对于拥有数十亿图像的2D数据集来说非常稀缺,训练一个具有强大泛化能力的文本条件的3D扩散模型具有挑战性。此外,文本到图像的生成模型已经取得了显著的成熟度,因此选择训练一个图像条件的3D扩散模型,以获得更好的泛化能力和更高的质量。
由于获得的潜在embedding是一个显式的三平面表示,一个简单的方法是直接使用一个精心设计的2D U-Net作为扩散模型。然而,这样做会导致三个平面之间缺乏交流,从而无法捕捉生成3D所需的结构化和固有属性。因此,基于 Diffusion Transformer(DiT)的架构构建了生成模型,利用变换器更好地提取平面之间的空间位置信息。同时,我们建议在每个DiT块中合并图像的像素级和语义级信息,从而将图像特征空间和潜在空间对齐,以生成与条件图像内容一致的3D资产。我们的潜在扩散模型框架如前面图2(b)所示,每个DiT块的架构如下图3所示。
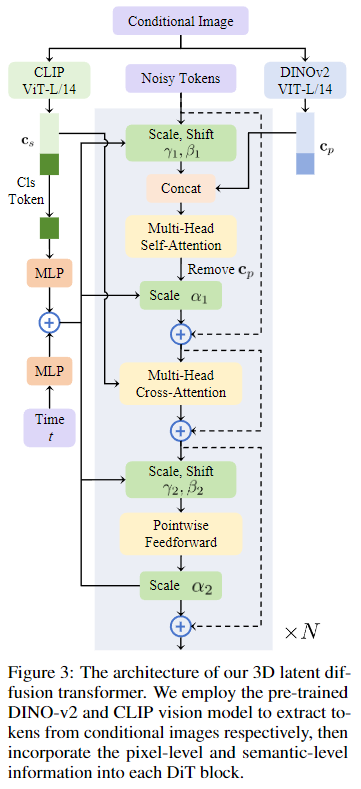
像素级对齐模块。为了确保扩散模型生成的3D资产的高频细节与条件图像对齐,设计了像素级对齐模块,将图像的像素级信息注入到潜在空间中。研究者们使用预训练的DINO-v2(ViT-L/14)作为像素级图像编码器,这在之前的工作中已经显示出优于其他预训练视觉模型提取结构信息的性能。具体地,首先使用两个具有GeLU激活的线性层将DINO-v2提取的图像token c p c_p cp 投影到与噪声潜在token z t z_t zt匹配的通道维度。然后在每个DiT块中,将它们与展平的 z t z_t zt 连接起来,并将它们馈送到一个自注意力层中,以建模 c p c_p cp 和 z t z_t zt 之间的内在关系。随后,消除图像token的部分,并仅保留噪声token的部分以输入到下一个模块中。
语义级对齐模块。研究者们设计了一个语义级对齐模块,以确保生成的3D模型与条件图像之间的语义一致性。使用预训练的CLIP视觉模型(ViT-L/14)从条件图像中提取语义图像token c s c_s cs,然后在每个DiT块中利用交叉注意力层促进 c s c_s cs 和噪声潜在token z t z_t zt 之间的交互。与原始的类别条件DiT不同,我们的图像条件扩散模型不再使用类别embedding。相反,使用语义图像token c s c_s cs 经过投影后的分类token,并将其添加到时间embedding中以增强语义特征。此外,为了减少参数数量和计算成本,采用PixArt中提出的adaLN-single,它使用时间embedding预测一组全局移位和缩放参数 $ P = [\gamma_1, \beta_1, \alpha_1, \gamma_2, \beta_2, \alpha_2]$ ,然后将一个可训练的embedding添加到 P P P 中以在每个块中进行调整。
训练。遵循LDM,3D潜在Diffusion Transformer模型在时间 t t t 上预测噪声潜在表示 z t z_t zt 的噪声 $ \varepsilon ,条件是图像 ,条件是图像 ,条件是图像C$。在训练扩散模型时,以10%的概率随机将条件输入 c p 和 c s c_p 和 c_s cp和cs 设为零,以在推理过程中使用无分类器的指导,从而提高条件生成的质量。
实验
实现细节
D3D-VAE。D3D-VAE以81,920个点云为输入,其中法线均匀采样自3D模型,还包括分辨率为 r = 32 和通道维度为 d e d_e de = 768 的可学习潜在token。编码器网络包括1个交叉注意力层和8个自注意力层,每个注意力层包含12个维度为64的头。潜在表示的通道维度为 dz = 16。解码器网络由5个ResNet块组成,将潜在表示上采样为分辨率为 256 × 256 和通道维度为 32 的三平面特征图。几何映射网络包括5个隐藏维度为64的线性层。在训练过程中,对20,480个均匀点和20,480个近表面点进行监督。KL正则化权重设置为 λ K L = 1 e − 6 \lambda_{KL} = 1e^{−6} λKL=1e−6。使用AdamW优化器,学习率为 1 e − 4 1e^{−4} 1e−4,每个GPU batch大小为16。在NVIDIA A100 (80G)上对D3D-VAE模型进行了100K步的训练。
D3D-DiT。扩散模型采用DiT-XL/2的网络配置,包括28层DiT块。每个注意力层包括16个维度为72的头。我们使用线性方差调度器,训练1000个去噪步骤,方差范围从 1 e − 4 到 2 e − 2 1e^{−4} 到 2e^{−2} 1e−4到2e−2。使用AdamW优化器,每个GPU batch大小为32,训练800K步。在推理过程中,应用了50步的DDIM,并将引导尺度设置为7.5。
图像和文本到3D生成
图像到3D。在GSO数据集上对Direct3D与其他基线方法进行了图像到3D任务的定性比较,如下图4所示。

Shap-E是一个在数百万个3D资产上训练的3D扩散模型,能够生成合理的几何形状,但在网格中存在伪影和孔洞。Michelangelo在一个1D隐式潜在空间上执行扩散过程,无法将生成的网格与条件图像的语义内容对齐。基于多视角的方法,如One-2-3-45和InstantMesh,严重依赖于多视角2D扩散模型的性能。One-2-3-45直接使用SparseNeuS进行重建,导致几何形状粗糙。InstantMesh生成的网格质量不错,但在某些细节上与输入图像的一致性缺失,比如水槽上的水龙头和校车的窗户。它还产生了一些失败案例,比如将马的后腿合并在一起,这是由于多视角扩散模型的限制。相比之下,Direct3D在大多数情况下都能产生与条件图像一致的高质量网格。
文本到3D。Direct3D可以通过结合像Hunyuan-DiT这样的文本到图像模型,从文本提示生成3D资产。下图5展示了Direct3D与其他基线方法在文本到3D任务上的定性比较。

为了确保公平比较,所有方法都使用相同的生成图像作为输入。可以看出,这些基线方法在几乎所有情况下都失败了,而Direct3D仍然能够生成高质量的网格,展示了本文方法的广泛适用性。研究者们还进行了用户研究,以定量比较D3D-DiT与其他方法。渲染了每种方法生成的网格旋转360度的视频,并请46名志愿者根据网格的质量和与输入图像的一致性进行评分。下表1的结果表明,D3D-DiT在网格质量和一致性方面优于其他基线方法。

生成纹理网格。得益于Direct3D生成的平滑和细致的几何形状,可以利用现有的纹理合成方法轻松装饰网格。如下图6所示,使用SyncMVD获得了精美的纹理网格。

结论
本文介绍了一种新颖的方法,可以直接从单个图像生成3D形状,无需多视角重建。利用混合架构,提出的D3D-VAE能够高效地将3D形状编码为紧凑的潜在空间,增强了生成形状的保真度。本文的图像条件3D Diffusion Transformer(D3D-DiT)通过在像素级和语义级别集成图像信息,进一步提高了生成质量,确保了生成的3D形状与条件图像的高一致性。在图像到3D和文本到3D任务上进行的大量实验表明,Direct3D在3D生成方面表现优异,优于现有方法的质量和泛化能力。
局限性。尽管Direct3D能够生成高保真度的3D资产,但目前仅限于生成单个或多个对象,无法生成大规模场景。
参考文献
[1] Direct3D: Scalable Image-to-3D Generation via 3D Latent Diffusion Transformer