前言:日志分析管理平台对于平时的规模化运维占的权重非常大,这一章涉及的程序较多,会将每个程序的基础使用和模块分开梳理,基础概念会分布在每小节开头,最后串联成一个完整的工作环境。
1、ELK架构
ELK 是一个非常流行的开源日志管理解决方案,它由三个核心组件组成:Elasticsearch、Logstash 和 Kibana。这三个组件协同工作,以便收集、存储、搜索、分析和可视化大量的日志数据。
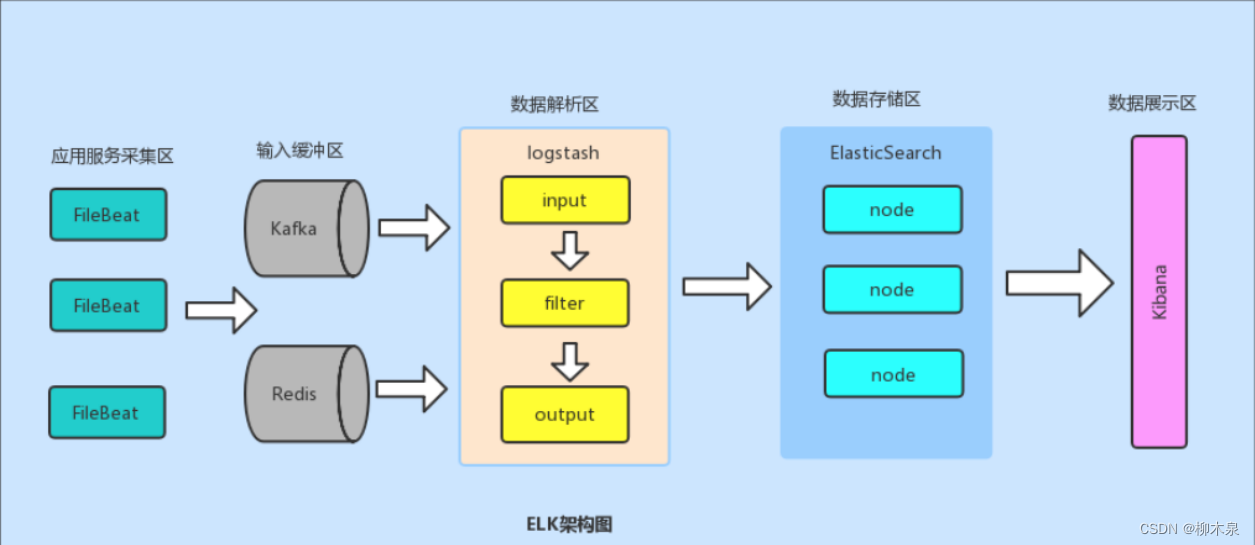
E:Elasticsearch(弹性搜索负责存日志)
L:logstash(负责日志收集,需要装在每一台业务主机上)
K:kibana(日志的展示与交互,负责形成网页,去E上获得数据更直观的展示出来)
kafka、redis作为消息队列和缓冲程序,加入后可以解决elk的拥塞问题
Filebeat:logstash平替,形成EFK架构。
2、Filebeat
使用 Filebeat 可以收集各种日志,之后发送到指定的目标系统上,但是同一时间只能配置一个输出目标。
Filebeat 会对配置好的日志内容进行收集,第一次会从每个文件的开头一直读到当前文件的最后一行。 每一行称为一个事件,格式是一个包含很多字段的大字典,也就是 JSON 格式的数据。
在 Filebeat中负责完成这个 动作的官方称它为 Harvester (收割机)。 每个事件将来会被保存到 Elasticsearch 中 在收割机读到文件的最后,会停止工作。直到文件有新的内容写入才继续工作
2.1、Filebeat安装部署
基础环境配置阿里源,epel源,域名解析,关闭防火墙与selinux
| IP | 角色 |
|---|---|
| 192.168.188.128 | ela1 |
| 192.168.188.129 | ela2 |
| 192.168.188.130 | ela3 |
下载地址建议使用谷歌浏览器访问,把这几个软件常用版本下载好保存
(上述地址有问题,直接删除后半部分url官网主页下载即可,按照下图选择产品及版本号,elk版本需要相同,本次使用的为filebeat-7.13.2-linux-x86_64.tar.gz )
注意前面标记的执行主机名
[root@ela1 ~]# tar zxf filebeat-7.13.2-linux-x86_64.tar.gz -C /usr/local/
[root@ela1 ~]# mv /usr/local/filebeat-7.13.2-linux-x86_64 /usr/local/filebeatFilebeat启动形式
1)前台运行 采用前台运行的方式查看Filebeat获取的日志结果
2)后台运行 使用nohup方式启动Filebeat到后台,日志输出会默认保存到当前目录下的 nohup.out 文件中,这样即使当前终端关闭,也能够继续记录Filebeat的输出日志。
3)通过 systemd 后台启动 Filebeat 时,Filebeat 的标准输出和标准错误输出通常会由 systemd 收集并记录在系统的日志中,而不是直接输出到一个特定文件中,因此不能像使用 nohup 那样简单地查看 nohup.out 文件来查看输出日志。
配置systemd方式的Filebeat启动管理文件
[root@ela1 ~]# vim /usr/lib/systemd/system/filebeat.service
[root@ela1 ~]# cat /usr/lib/systemd/system/filebeat.service
[Unit]
Description=Filebeat sends log files to Logstash or directly to Elasticsearch.
Wants=network‐online.target
After=network‐online.target
[Service]
User=root
Group=root
Environment="BEAT_CONFIG_OPTS=‐c /usr/local/filebeat/filebeat.yml"
ExecStart=/usr/local/filebeat/filebeat $BEAT_CONFIG_OPTS
Restart=always
[Install]
WantedBy=multi‐user.target
#以下为注释部分,基本所有机器配置都是一样的
[Unit] 部分
Description: 描述了服务的作用,这里是指 Filebeat 用于发送日志文件到 Logstash 或 Elasticsearch。
Wants: 指定了服务依赖的目标,这里是 network‐online.target,表示服务需要在网络在线时启动。
After: 指定了服务启动的顺序,在 network‐online.target 之后启动。
[Service] 部分
User 和 Group: 指定了服务运行的用户和用户组,这里是 root 用户和 root 用户组,表示 Filebeat 以 root 用户身份运行。
Environment: 定义了一个环境变量 BEAT_CONFIG_OPTS,设置了 Filebeat 的配置选项 -c /usr/local/filebeat/filebeat.yml,告诉 Filebeat 使用指定的配置文件。
ExecStart: 指定了服务启动时执行的命令,这里是 /usr/local/filebeat/filebeat$BEAT_CONFIG_OPTS,启动 Filebeat 并传递之前定义的配置选项。
Restart: 设置了服务异常退出时自动重启 (Restart=always),确保 Filebeat 总是运行。
加载 systemd 的配置文件,启动filebeat
[root@ela1 ~]# systemctl daemon-reload
[root@ela1 ~]# systemctl start filebeat2.2、Filebeat简单使用
准备测试使用的日志
[root@ela1 ~]# vim /tmp/access.log
[root@ela1 ~]# cat /tmp/access.log
123.127.39.50 ‐ ‐ [04/Mar/2021:10:50:28 +0800] "GET /logo.jpg HTTP/1.1" 200 14137 "http://81.68.233.173/" "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.192 Safari/537.36" "‐"
配置filebeat的输入输出
[root@ela1 ~]# vim /usr/local/filebeat/filebeat.yml
[root@ela1 ~]# cat /usr/local/filebeat/filebeat.yml
filebeat.inputs:
‐ type: log
enabled: true #改
paths:
‐ /tmp/*.log #改 指定需要收集日志的路径,支持通配符可以写多个
注释掉其他输出方式!!!!!
output.console: #添加 输出到终端即屏幕上
pretty: true
yml文件对缩进要求非常严格!!!!运行filebeat观察
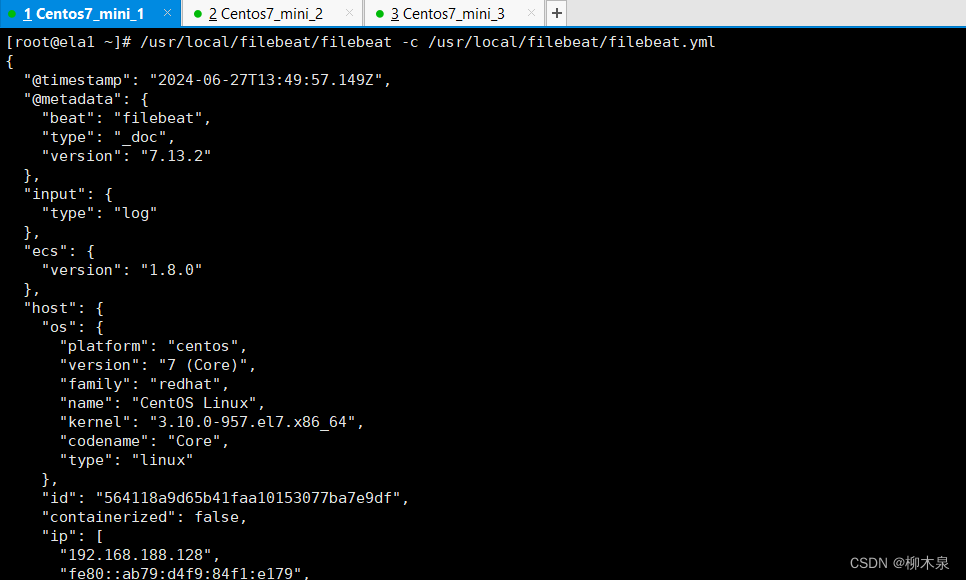
[root@ela1 ~]# /usr/local/filebeat/filebeat -c /usr/local/filebeat/filebeat.yml
#初始化指向刚刚配置的yml文件
排错方法:filebeat本身运行日志默认位置 /usr/local/filebeat/logs/filebeat
输出收集的日志到屏幕
证明收集的连续性如下图所示,另开一个窗口在/tmp/access.log添加一行日志保存退出

收集到新的日志并输出到屏幕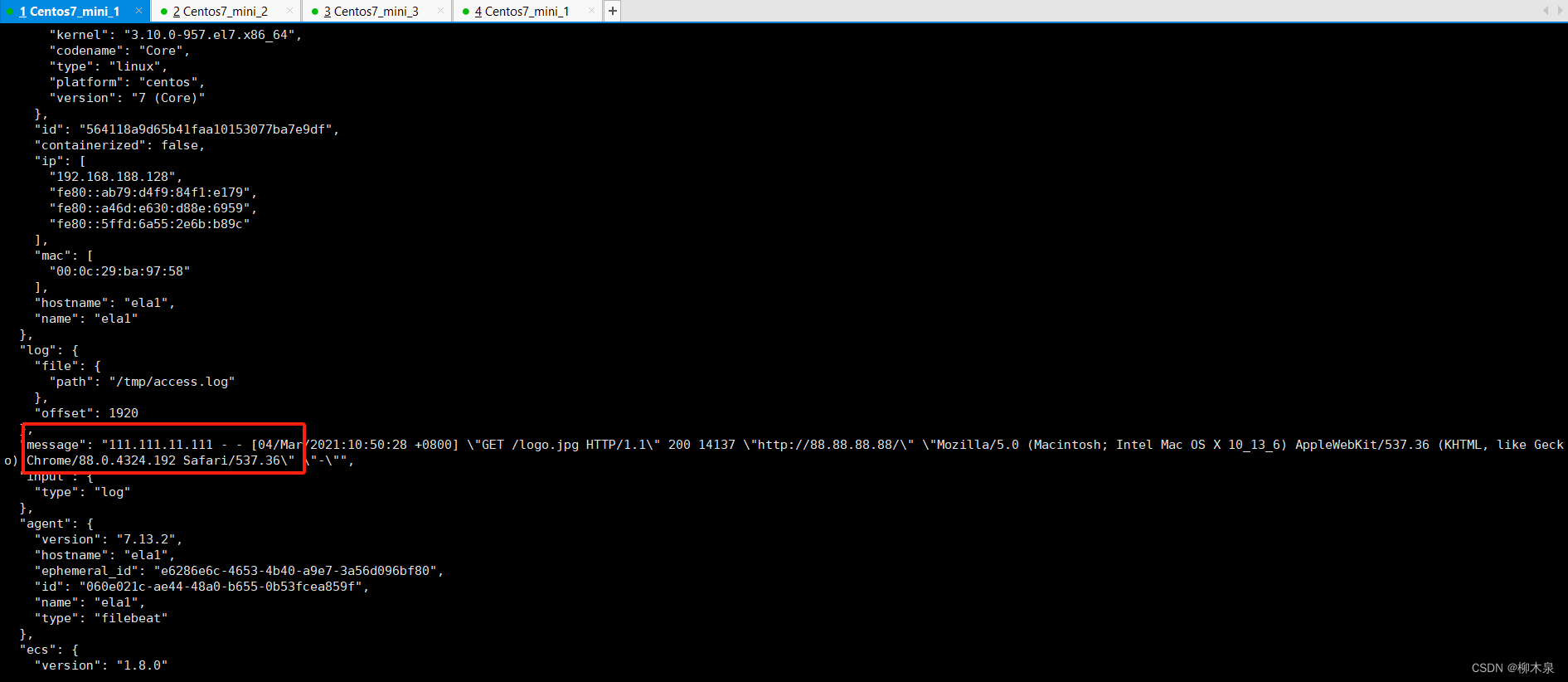
2.3、专用日志收集模块
查看可用的模块列表
[root@ela1 ~]# /usr/local/filebeat/filebeat modules list -c /usr/local/filebeat/filebeat.yml效果如下
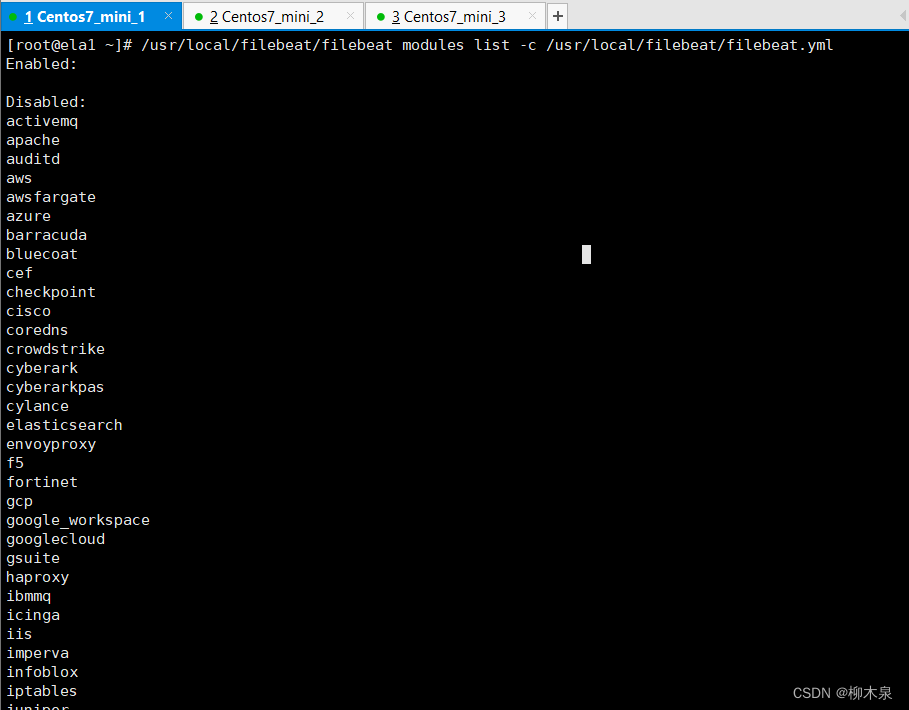
启用模块的方法
第一种方式,删除下方文件的.disabled后缀重启filebeat即可开启该模块
[root@ela1 ~]# ls /usr/local/filebeat/modules.d/
activemq.yml.disabled haproxy.yml.disabled osquery.yml.disabled
apache.yml.disabled ibmmq.yml.disabled panw.yml.disabled
auditd.yml.disabled icinga.yml.disabled pensando.yml.disabled
awsfargate.yml.disabled iis.yml.disabled postgresql.yml.disabled
aws.yml.disabled imperva.yml.disabled proofpoint.yml.disabled
azure.yml.disabled infoblox.yml.disabled rabbitmq.yml.disabled
barracuda.yml.disabled iptables.yml.disabled radware.yml.disabled
bluecoat.yml.disabled juniper.yml.disabled redis.yml.disabled
cef.yml.disabled kafka.yml.disabled santa.yml.disabled
checkpoint.yml.disabled kibana.yml.disabled snort.yml.disabled
cisco.yml.disabled logstash.yml.disabled snyk.yml.disabled
coredns.yml.disabled microsoft.yml.disabled sonicwall.yml.disabled
crowdstrike.yml.disabled misp.yml.disabled sophos.yml.disabled
cyberarkpas.yml.disabled mongodb.yml.disabled squid.yml.disabled
cyberark.yml.disabled mssql.yml.disabled suricata.yml.disabled
cylance.yml.disabled mysqlenterprise.yml.disabled system.yml.disabled
elasticsearch.yml.disabled mysql.yml.disabled threatintel.yml.disabled
envoyproxy.yml.disabled nats.yml.disabled tomcat.yml.disabled
f5.yml.disabled netflow.yml.disabled traefik.yml.disabled
fortinet.yml.disabled netscout.yml.disabled zeek.yml.disabled
gcp.yml.disabled nginx.yml.disabled zoom.yml.disabled
googlecloud.yml.disabled o365.yml.disabled zscaler.yml.disabled
google_workspace.yml.disabled okta.yml.disabled
gsuite.yml.disabled oracle.yml.disabled
第二种方式,使用命令启用模块
禁用模块
/usr/local/filebeat/filebeat modules disable 模块名
启用模块
/usr/local/filebeat/filebeat modules enable 模块名2.4、nginx模块使用演示
正常情况下不需要配置日志路径,这里修改一下nginx日志位置,演示非默认情况下收集模块的修改方式
创造两个日志文件
[root@ela1 ~]# vim /var/log/access.log
[root@ela1 ~]# cat /var/log/access.log
111.111.111.111 ‐ ‐ [11/Mar/2011:11:11:11 +0800] "GET /logo.jpg HTTP/1.1" 200 14137 "http://11.11.111.111/" "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.192 Safari/537.36" "‐"
[root@ela1 ~]# vim /var/log/error.log
[root@ela1 ~]# cat /var/log/error.log
2011/11/11 11:11:11 [error] 11396#0: *5 open() "/farm/bg.jpg" failed (2: No such file or directory), client: 111.111.11.11, server: localhost, request: "GET /bg.jpg HTTP/1.1", host: "11.11.111.111", referrer: "http://11.11.111.111/"
[root@ela1 ~]#
开启nginx日志收集模块
[root@ela1 ~]# /usr/local/filebeat/filebeat modules enable nginx -c /usr/local/filebeat/filebeat.yml
Enabled nginx
但此时nginx日志并不在默认位置上,所以还要添加var.paths
[root@ela1 ~]# vim /usr/local/filebeat/modules.d/nginx.yml
[root@ela1 ~]# cat /usr/local/filebeat/modules.d/nginx.yml
# Module: nginx
# Docs: https://www.elastic.co/guide/en/beats/filebeat/7.13/filebeat-module-nginx.html
- module: nginx
# Access logs
access:
enabled: true
var.paths: ["/var/log/access.log*","/var/log/error.log*"]
# Set custom paths for the log files. If left empty,
# Filebeat will choose the paths depending on your OS.
#var.paths:
# Error logs
error:
enabled: true
# Set custom paths for the log files. If left empty,
# Filebeat will choose the paths depending on your OS.
#var.paths:
# Ingress-nginx controller logs. This is disabled by default. It could be used in Kubernetes environments to parse ingress-nginx logs
ingress_controller:
enabled: false
# Set custom paths for the log files. If left empty,
# Filebeat will choose the paths depending on your OS.
#var.paths:注:这里添加路径后filebeat仍然会去寻找原有的默认路径,将默认路径和新增路径的日志都会进行收集
启动fliebeat观察结果
[root@ela1 ~]# /usr/local/filebeat/filebeat -c /usr/local/filebeat/filebeat.yml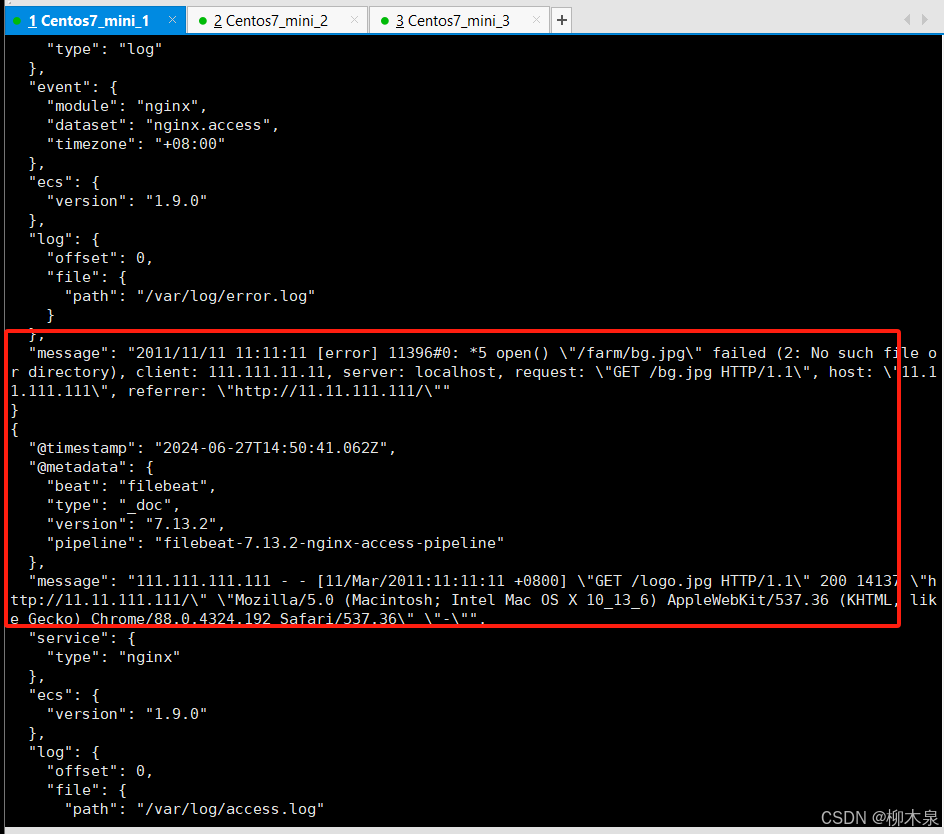
日志收集成功
2.5、配置output
Filebeat 是用于搜集日志,之后把日志推送到某个接收的系统中的,这些系统或者装置在 Filebeat 中称为output 。
output 类型:
- console 终端屏幕
- elasticsearch 存放日志,并提供查询
- logstash 进一步对日志数据进行处理
- kafka 消息队列
filebeat 运行的时候,以上的 output 只可配置其中的一种
如果只想输出完整Json数据中的某些字段
output.console:
codec.format:
string: '%{[@timestamp]} %{[message]}'2.6、重读日志文件
假如出现如下报错,请删除安装目录中的 data 文件夹
Exiting: data path already locked by another beat. Please make sure that multiple beats are not sharing the same data path (path.data).
查看一下是否有一个进程已经处于运行状态,尝试杀死此进程,之后重新运行 filebeat
2.7、过滤和增强数据
1)去重日志中的某些行,配置位置在 filebeat.yml 文件中
要求:删除所有以 DBG: 开头的行
processors:
- drop_event:
when:
regexp:
message: "^DBG:"
2)向输出的数据中添加某些自定义字段
- add_fields:
target: project # 要添加的自定义字段key名称
fields:
name: liumuquanproject
id: '11111111111111111111'3)从事件中删除某些字段
processors:
‐ drop_fields:
fields: ["field1", "field2", ...]
ignore_missing: false以上配置,将删除字段: field1 和 field2 。
ignore_missing 的值为 false 表示,字段名不存在则会返回错误。为 true 不会返回错误。
注意: 事件中的 "@timestamp 和 type 字段是无法删除的。
下面的配置示例是删除顶级字段 input 和 顶级字段 ecs 中的 version 字段。
‐ drop_fields:
fields: ['input', "ecs.version"]
3、logstash
Logstash 是一个开源的数据收集引擎,专门设计用于处理大量的日志数据、指标数据和事件数据。它作为 Elastic Stack 中的一部分,与 Elasticsearch、Kibana 和 Beats 协同工作,用于实时数据流处理和数据转换。
实验环境继续使用上个示例的环境即可
3.1、logstash安装部署
下载地址同上
[root@ela1 ~]# tar xf logstash-7.13.2-linux-x86_64.tar.gz -C /usr/local/
[root@ela1 ~]# mv /usr/local/logstash-7.13.2/ /usr/local/logstash
3.2、logstash简单使用
运行最基本的Logstash管道来测试Logstash安装。 Logstash管道具有两个必需元素input和output,以及一个可选元素filter。输入插件使用来自源的数据,过滤器插 件根据你的指定修改数据,输出插件将数据写入目标。
[root@ela1 ~]# /usr/local/logstash/bin/logstash -e 'input { stdin { type => stdin } } output { stdout { codec => rubydebug } }'
# 启动 Logstash,并配置它从标准输入接收数据(通常是用户手动输入),然后将处理后的数据以 rubydebug 格式输出到命令行。等待启动,java程序启动时间较长,效果如下
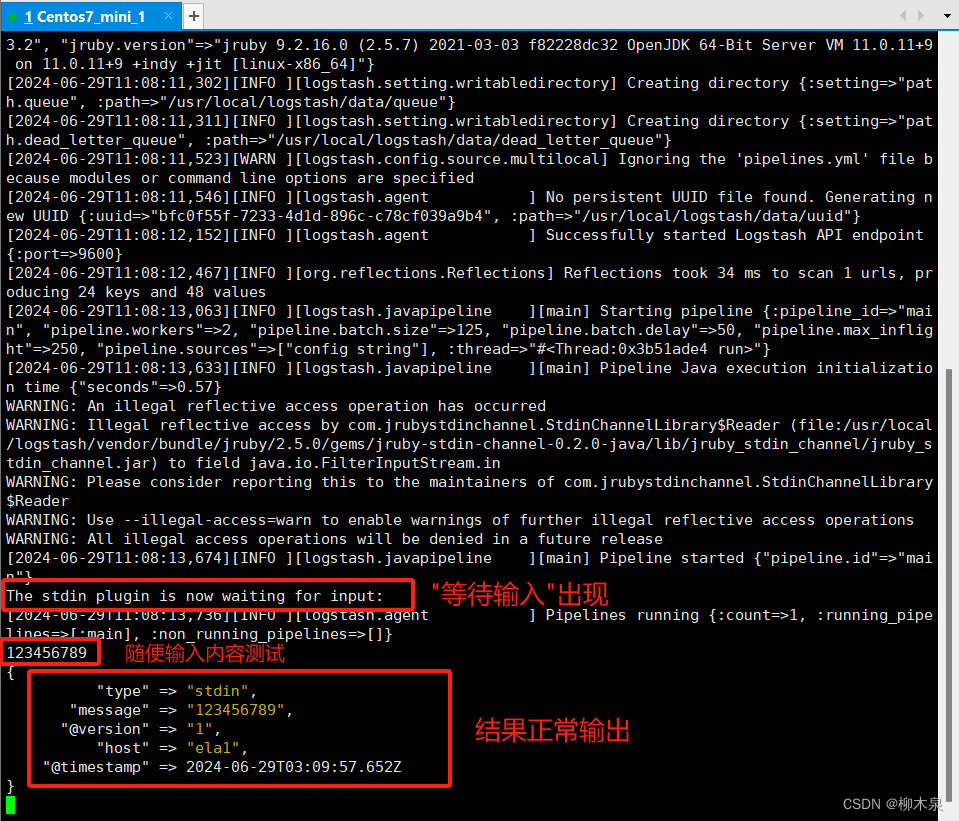
3.3、配置输入和输出
工作中Logstash管道要复杂一些:它通常具有一个或多个输入和过滤器和输出插件。 下面将创建一个Logstash管道,该管道使用标准输入来获取Apache Web日志作为输入,解析这些日志以从日志中创建特定的命名字段,然后将解析的数据输出到标准输出(屏幕上)。并且这次是在配置文件中定义管道。 创建一个文件,作为 Logstash 的管道配置文件。
[root@ela1 ~]# vim /usr/local/logstash/config/first-pipeline.conf
[root@ela1 ~]# cat /usr/local/logstash/config/first-pipeline.conf
input { stdin { } }
output { stdout { } }测试文件配置是否正确
[root@ela1 ~]# /usr/local/logstash/bin/logstash -f /usr/local/logstash/config/first-pipeline.conf --config.test_and_exit
Using bundled JDK: /usr/local/logstash/jdk
OpenJDK 64-Bit Server VM warning: Option UseConcMarkSweepGC was deprecated in version 9.0 and will likely be removed in a future release.
Sending Logstash logs to /usr/local/logstash/logs which is now configured via log4j2.properties
[2024-06-29T15:30:38,167][INFO ][logstash.runner ] Log4j configuration path used is: /usr/local/logstash/config/log4j2.properties
[2024-06-29T15:30:38,172][INFO ][logstash.runner ] Starting Logstash {"logstash.version"=>"7.13.2", "jruby.version"=>"jruby 9.2.16.0 (2.5.7) 2021-03-03 f82228dc32 OpenJDK 64-Bit Server VM 11.0.11+9 on 11.0.11+9 +indy +jit [linux-x86_64]"}
[2024-06-29T15:30:38,436][WARN ][logstash.config.source.multilocal] Ignoring the 'pipelines.yml' file because modules or command line options are specified
[2024-06-29T15:30:39,035][INFO ][org.reflections.Reflections] Reflections took 49 ms to scan 1 urls, producing 24 keys and 48 values
Configuration OK
[2024-06-29T15:30:39,678][INFO ][logstash.runner ] Using config.test_and_exit mode. Config Validation Result: OK. Exiting Logstash
以配置的文件正常启动logstasth,输入apache日志(运行http生成)观察logstash输出
[root@ela1 ~]# /usr/local/logstash/bin/logstash -f /usr/local/logstash/config/first-pipeline.conf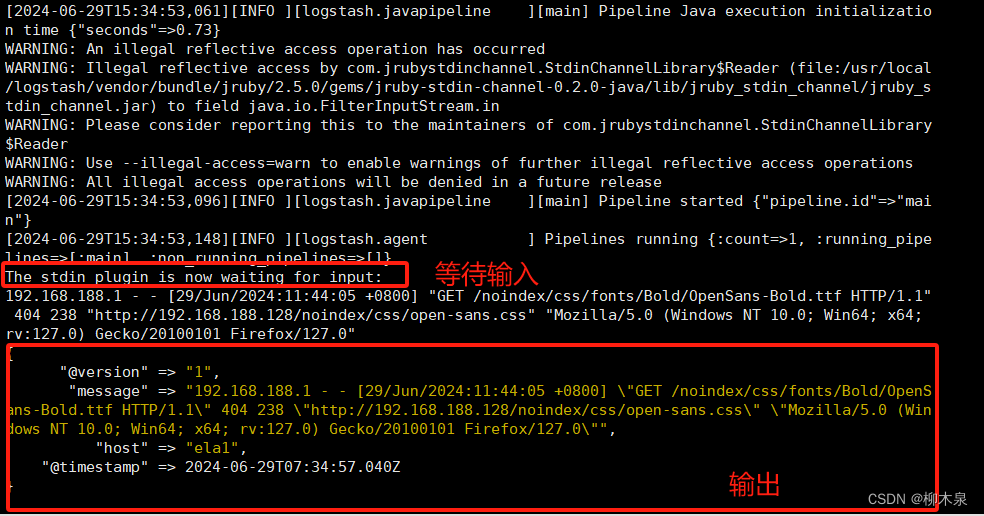
3.4、Grok过滤器解析Web日志
现在有了一个工作管道,但是日志消息的格式不够简洁,需要解析日志消息,以便能从日志中创建特定的命名字段,更加直观的展示日志内容。为此,应该使用grok过滤器插件。 使用grok过滤器插件,可以将非结构化日志数据转化为结构化和可查询的内容。通过自己预定义的模式来识别感兴趣的字段的。这个可以通过给其配置不同的模式来实现。
以apache日志为例,可以转化为COMBINEDAPACHELOG
COMBINEDAPACHELOG 使用以下字段将apache日志拆分为多行
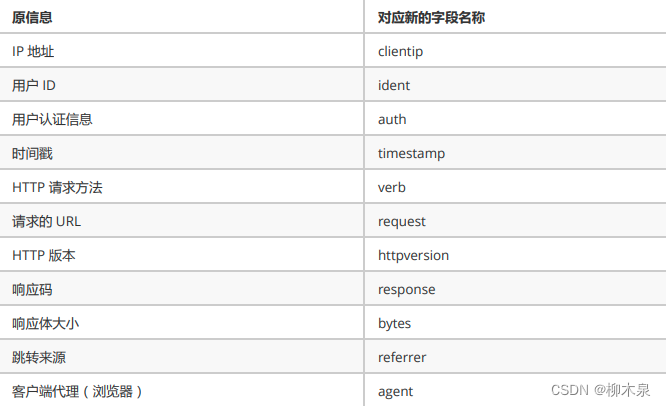
操作如下
3.4.1、创建一个web日志
[root@ela1 ~]# vim /var/log/httpd.log
[root@ela1 ~]# cat /var/log/httpd.log
192.168.188.1 - - [29/Jun/2024:17:09:54 +0800] "GET /noindex/css/open-sans.css HTTP/1.1" 200 5081 "http://192.168.188.128/" "Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:127.0) Gecko/20100101 Firefox/127.0"
3.4.2、清理缓存信息
[root@ela1 ~]# ls -al /usr/local/logstash/data/plugins/input/file
ls: 无法访问/usr/local/logstash/data/plugins/input/file: 没有那个文件或目录
# 此时为正常状态,无缓存文件干扰3.4.3、配置管道文件
[root@ela1 ~]# vim /usr/local/logstash/config/first-pipeline.conf
[root@ela1 ~]# cat /usr/local/logstash/config/first-pipeline.conf
input {
file {
path => ["/var/log/httpd.log"]
start_position => "beginning"
}
}
filter {
grok {
match => { "message" => "%{COMBINEDAPACHELOG}" }
}
}
output {
stdout {}
}
[root@ela1 ~]# /usr/local/logstash/bin/logstash -f /usr/local/logstash/config/first-pipeline.conf --config.test_and_exit
Using bundled JDK: /usr/local/logstash/jdk
OpenJDK 64-Bit Server VM warning: Option UseConcMarkSweepGC was deprecated in version 9.0 and will likely be removed in a future release.
Sending Logstash logs to /usr/local/logstash/logs which is now configured via log4j2.properties
[2024-06-29T16:08:38,041][INFO ][logstash.runner ] Log4j configuration path used is: /usr/local/logstash/config/log4j2.properties
[2024-06-29T16:08:38,046][INFO ][logstash.runner ] Starting Logstash {"logstash.version"=>"7.13.2", "jruby.version"=>"jruby 9.2.16.0 (2.5.7) 2021-03-03 f82228dc32 OpenJDK 64-Bit Server VM 11.0.11+9 on 11.0.11+9 +indy +jit [linux-x86_64]"}
[2024-06-29T16:08:38,250][WARN ][logstash.config.source.multilocal] Ignoring the 'pipelines.yml' file because modules or command line options are specified
[2024-06-29T16:08:38,842][INFO ][org.reflections.Reflections] Reflections took 49 ms to scan 1 urls, producing 24 keys and 48 values
Configuration OK
[2024-06-29T16:08:39,421][INFO ][logstash.runner ] Using config.test_and_exit mode. Config Validation Result: OK. Exiting Logstash
3.4.4、观察解析结果
一行的日志被解析为多行,方便运维人员查看
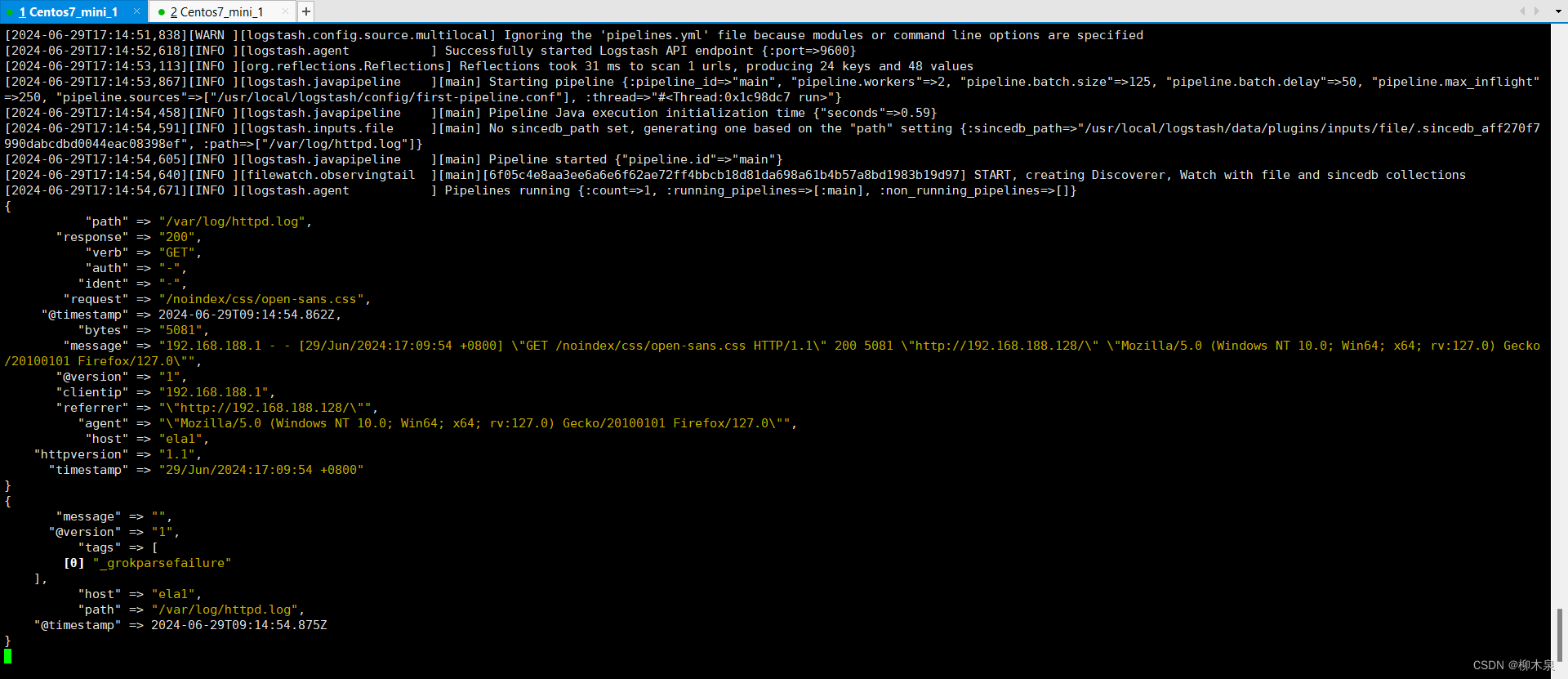
3.4.5、字段配置
观察上图发现内容为日志原文的message字段还在,且有些字段不够望文知意,可以使用remove_filed 来移除这个字段。 remove_field 可以移除任意的字段,它可以接收的值是一个数组。 rename可以重新命名字段
操作如下:
[root@ela1 ~]# vim /usr/local/logstash/config/first-pipeline.conf
[root@ela1 ~]# rm -rf /usr/local/logstash/data/plugins/inputs/file/.sincedb_aff270f7990dabcdbd0044eac08398ef
[root@ela1 ~]# cat /usr/local/logstash/config/first-pipeline.conf
input {
file {
path => ["/var/log/httpd.log"]
start_position => "beginning"
}
}
filter {
grok { match => { "message" => "%{COMBINEDAPACHELOG}" } }
mutate { rename => { "clientip" => "client_ip" } }
mutate { remove_field => ["message","@version"] }
}
output {
stdout {}
}观察输出结果,字段修改已完成
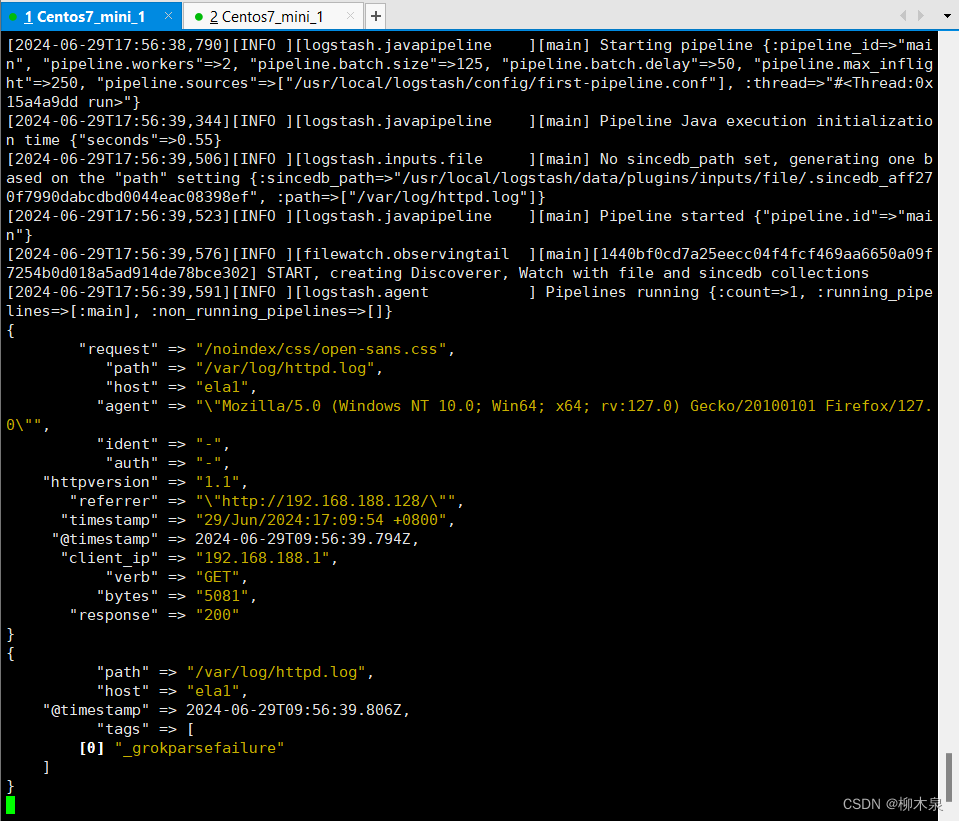
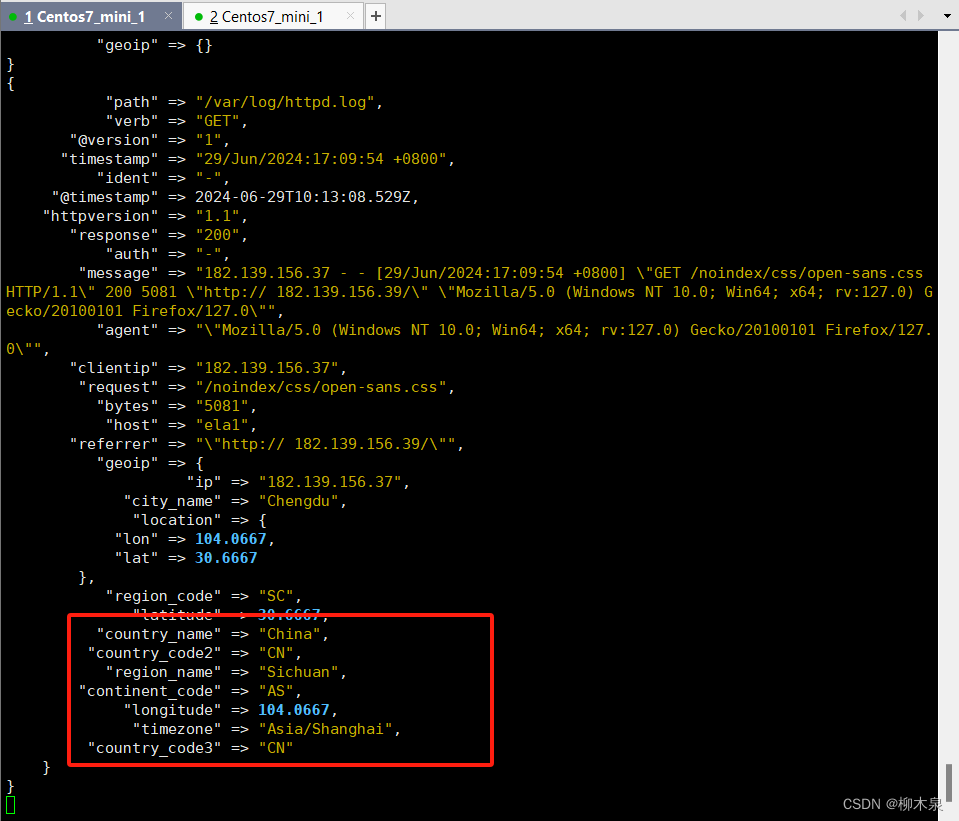
3.4.6、Geoip插件增强数据
除解析日志数据以进行更好的搜索外,筛选器插件还可以从现有数据中获取补充信息。例如, geoip 插件可以通过查找到IP地址,并从自己自带的数据库中找到地址对应的地理位置信息,然后将该位置信息添加到日志中。 该geoip插件配置要求您指定包含IP地址来查找源字段的名称。在此示例中,该clientip字段包含IP地址。
[root@ela1 ~]# vim /usr/local/logstash/config/first-pipeline.conf
[root@ela1 ~]# cat /usr/local/logstash/config/first-pipeline.conf
input {
file {
path => ["/var/log/httpd.log"]
start_position => "beginning"
}
}
filter {
grok { match => { "message" => "%{COMBINEDAPACHELOG}" } }
geoip { source => "clientip" }
}
output {
stdout {}
}
启动logstash观察输出结果
[root@ela1 ~]# rm -rf /usr/local/logstash/data/plugins/inputs/file/.sincedb_aff270f7990dabcdbd0044eac08398ef
[root@ela1 ~]# cat /var/log/httpd.log
192.168.188.1 - - [29/Jun/2024:17:09:54 +0800] "GET /noindex/css/open-sans.css HTTP/1.1" 200 5081 "http://192.168.188.128/" "Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:127.0) Gecko/20100101 Firefox/127.0"
182.139.156.37 - - [29/Jun/2024:17:09:54 +0800] "GET /noindex/css/open-sans.css HTTP/1.1" 200 5081 "http:// 182.139.156.39/" "Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:127.0) Gecko/20100101 Firefox/127.0"
# 这个位置尽量把日志里面的ip改成公网ip,这样显示结果更明显
[root@ela1 ~]# /usr/local/logstash/bin/logstash -f /usr/local/logstash/config/first-pipeline.conf
3.5、配置接收filebeat输入
[root@ela1 ~]# vim /usr/local/logstash/config/first-pipeline.conf
[root@ela1 ~]# cat /usr/local/logstash/config/first-pipeline.conf
input {
beats { port => 5044 }
}
filter {
grok { match => { "message" => "%{COMBINEDAPACHELOG}" } }
}
output {
stdout {}
}
[root@ela1 ~]# /usr/local/logstash/bin/logstash -f /usr/local/logstash/config/first-pipeline.conf
运行logstash之后,另开一个窗口修改filebeat的yml文件输出目标如下
取消output.logstash注释,注释掉其他输出选项
# ------------------------------ Logstash Output -------------------------------
output.logstash:
# The Logstash hosts
hosts: ["localhost:5044"]
# Optional SSL. By default is off.
# List of root certificates for HTTPS server verifications
#ssl.certificate_authorities: ["/etc/pki/root/ca.pem"]
# Certificate for SSL client authentication
#ssl.certificate: "/etc/pki/client/cert.pem"
# Client Certificate Key
#ssl.key: "/etc/pki/client/cert.key"
# ------------------------------ Console Output -------------------------------
#output.console:
#pretty: true修改上个示例编写的日志文件供filebeat收集,保存退出,清除filebeat缓存,启动filebeat,观察logstash输出
[root@ela1 ~]# vim /tmp/access.log
[root@ela1 ~]# cat /tmp/access.log
192.168.188.1 - - [29/Jun/2024:17:09:54 +0800] "GET /images/apache_pb.gif HTTP/1.1" 200 2326 "http://192.168.188.128/" "Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:127.0) Gecko/20100101 Firefox/127.0"
192.168.188.1 - - [29/Jun/2024:17:09:54 +0800] "GET /images/apache_pb.gif HTTP/1.1" 200 2326 "http://192.168.188.128/" "Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:127.0) Gecko/20100101 Firefox/127.0"
192.168.188.1 - - [29/Jun/2024:17:09:54 +0800] "GET /images/apache_pb.gif HTTP/1.1" 200 2326 "http://192.168.188.128/" "Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:127.0) Gecko/20100101 Firefox/127.0"
[root@ela1 ~]# rm -rf /usr/local/filebeat/data/
[root@ela1 ~]# /usr/local/filebeat/filebeat -c /usr/local/filebeat/filebeat.yml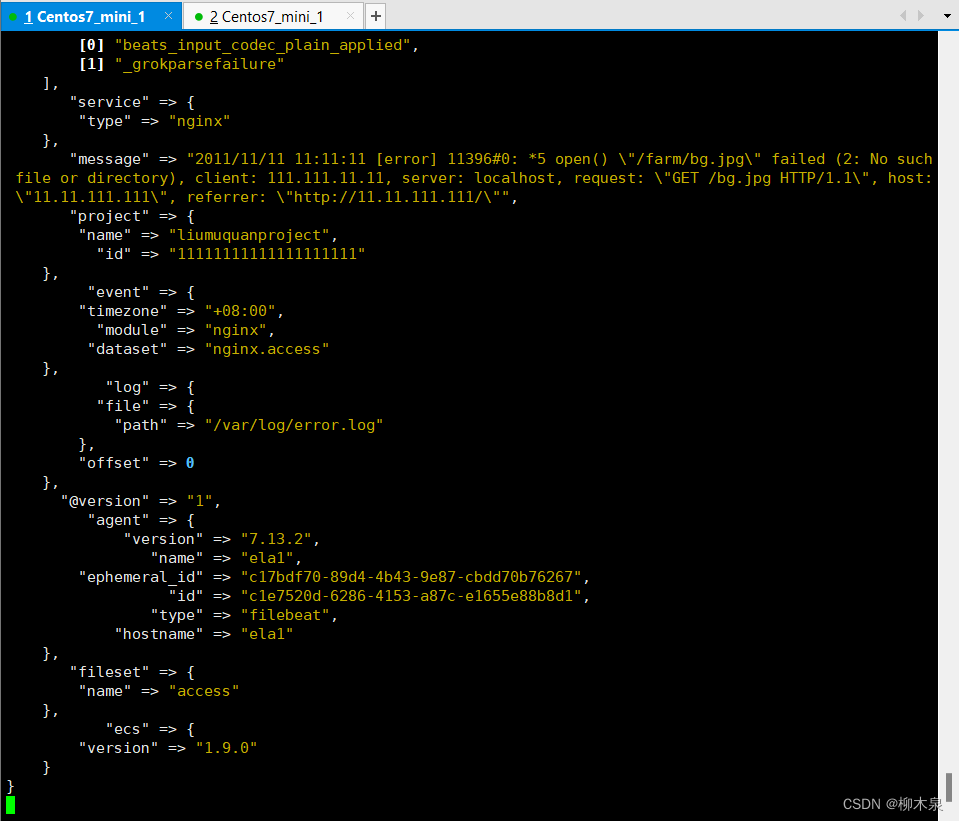
4、Elasticsearch集群
Elasticsearch:存储、搜索和分析
Elasticsearch是Elastic Stack核心的分布式搜索和分析引擎。Logstash和Beats有助于收集,聚合和丰富你的数据 并将其存储在Elasticsearch中。使用Kibana,你可以交互式地探索,可视化和共享对数据的见解,并管理和监视堆 栈。Elasticsearch是发生索引,搜索和分析数据的地方。 Elasticsearch为所有类型的数据提供近乎实时的搜索和分析。
支持的数据类型: 结构化文本 非结构化文本 数字数据 地理空间数据
Elasticsearch是面向文档的,文档是所有可搜索的最小单位
文档会被序列化成json格式,保存在Elasticsearch中
每个文档都有一个自己的id,可以是自定义的,可以是Elasticsearch自动生成的
使用Elasticsearch时,元数据和索引是两个关键概念,它们在理解和使用Elasticsearch时非常重要。
-
索引(Index):
- 形象解释:索引就像是一个巨大的书库,里面有很多书籍。
- 详细说明:在Elasticsearch中,索引是文档的集合,每个文档都是一个JSON对象。可以将索引想象成一个非常大的数据库,它包含了相关联的文档数据。比如,如果你在Elasticsearch中存储日志数据,你可以为每天的日志数据创建一个新的索引。索引允许你对文档进行存储、检索和分析。
-
元数据(Metadata):
- 形象解释:元数据就像是每本书的目录页,提供了关于书籍的基本信息和组织结构。
- 详细说明:在Elasticsearch中,元数据是描述索引和文档的信息。它包括索引的配置、映射(字段类型和属性)、分片和副本的分布、文档的版本信息等。元数据不存储实际的文档数据,而是存储有关如何解释和处理这些数据的信息。
总结来说,索引就像是存放具体数据的仓库,而元数据则是描述这些仓库及其内容的信息。索引帮助组织和存储数据,而元数据则定义了数据的结构和特性,帮助Elasticsearch有效地管理和操作数据。
4.1、Elasticsearch部署
安装Elastic Stack 在安装Elastic Stack时,你必须确保整个堆栈使用相同的版本。例如,如果你使用的是Elasticsearch 7.13.2,你需要安装Beats 7.13.2、APM Server 7.13.2、Elasticsearch Hadoop 7.13.2、Kibana 7.13.2和Logstash 7.13.2。
导入Elasticsearch的GPG密钥
# rpm --import https://artifacts.elastic.co/GPG-KEY-elasticsearch在基于RedHat的发行版中,创建一个名为elasticsearch.repo的文件,并将其保存在/etc/yum.repos.d/目录中:
[elasticsearch]
name=Elasticsearch repository for 7.x packages
baseurl=https://artifacts.elastic.co/packages/7.x/yum
gpgcheck=1
gpgkey=https://artifacts.elastic.co/GPG-KEY-elasticsearch
enabled=0
autorefresh=1
type=rpm-md
然后使用以下命令安装Elasticsearch(确保启用了elasticsearch仓库):
# yum install --enablerepo=elasticsearch elasticsearch
安装
[root@ela1 ~]# yum install -y elasticsearch-7.13.2-x86_64.rpm
自启动elasticsearch(先不要启动)
[root@ela1 ~]# systemctl daemon-reload
[root@ela1 ~]# systemctl enable elasticsearch.service
Created symlink from /etc/systemd/system/multi-user.target.wants/elasticsearch.service to /usr/lib/systemd/system/elasticsearch.service.
4.2、Es集群部署
在三台主机上安装elasticsearch,分别修改配置文件,参数详解和修改文件如下
cluster.name: elk
# 集群名称,各节点配置相同的名称。
node.name: ela1
# 节点名称,各节点配置不同的名称。
node.data: true
# 指示节点是否为数据节点。数据节点包含并管理索引的一部分。
network.host: 0.0.0.0
# 绑定节点的IP地址。
http.port: 9200
# Elasticsearch HTTP API监听的端口。
path.data: /path/to/data
# 数据存储目录的路径。
path.logs: /path/to/logs
# 日志存储目录的路径。
discovery.seed_hosts:
- ela1
- 192.168.122.106:9300
- 192.168.122.218
# 指定用于集群成员发现的主机列表,包括自身节点。所有节点应使用相同的列表。
cluster.initial_master_nodes: ["ela1", "ela2", "ela3"]
# 初始主节点列表,用于启动集群时确定第一个主节点。
http.cors.enabled: true
# 启用允许跨域请求(CORS)功能,允许其他源访问Elasticsearch。
http.cors.allow-origin: "*"
# 允许访问Elasticsearch的源地址,这里配置为允许所有源。
ela1
[root@ela1 ~]# vim /etc/elasticsearch/elasticsearch.yml
cluster.name: elk
node.name: ela1
node.data: true
network.host: 0.0.0.0
http.port: 9200
discovery.seed_hosts:
- ela1
- 192.168.188.129
- 192.168.188.130:9300 # 这里使用了三种写法,都是正确的
cluster.initial_master_nodes: ["ela1", "ela2", "ela3"]
ela2
[root@ela2 ~]# vim /etc/elasticsearch/elasticsearch.yml
cluster.name: elk
node.name: ela2
node.data: true
network.host: 0.0.0.0
http.port: 9200
discovery.seed_hosts:
- ela1
- 192.168.188.129
- 192.168.188.130:9300 # 这里使用了三种写法,都是正确的
cluster.initial_master_nodes: ["ela1", "ela2", "ela3"]ela3
[root@ela3 ~]# vim /etc/elasticsearch/elasticsearch.yml
cluster.name: elk
node.name: ela3
node.data: true
network.host: 0.0.0.0
http.port: 9200
discovery.seed_hosts:
- ela1
- 192.168.188.129
- 192.168.188.130:9300 # 这里使用了三种写法,都是正确的
cluster.initial_master_nodes: ["ela1", "ela2", "ela3"]启动三台主机
[root@ela1 ~]# systemctl start elasticsearch.service
[root@ela2 ~]# systemctl start elasticsearch.service
[root@ela3 ~]# systemctl start elasticsearch.service查看集群健康状态
[root@ela1 ~]# curl -X GET "localhost:9200/_cat/health?v"
epoch timestamp cluster status node.total node.data shards pri relo init unassign pending_tasks max_task_wait_time active_shards_percent
1719733562 07:46:02 elk green 3 3 0 0 0 0 0 0 - 100.0%
[root@ela1 ~]# curl -X GET "localhost:9200/_cat/nodes?v"
ip heap.percent ram.percent cpu load_1m load_5m load_15m node.role master name
192.168.188.129 37 66 1 0.00 0.05 0.05 cdfhilmrstw - ela2
192.168.188.128 43 66 1 0.00 0.06 0.07 cdfhilmrstw * ela1
192.168.188.130 37 66 1 0.01 0.07 0.07 cdfhilmrstw - ela3
4.3、集群部署排错
4.3.1、源代码部署启动
cd /usr/local/elasticsearch‐7.10.0
./bin/elasticsearch ‐d ‐p /tmp/elasticsearch.pid
-d 后台运行 -p 指定一个文件,用于存放进程的 pid
默认端口号是 :
9200 用于外部访问的监听端口,比如查看集群状态,向其传输数据,查询数据等
9300 用户集群中节点之间的互相通信,比如主节点的选举,集群节点信息的通告等。
查看端口的命令如下:
ss ‐ntal4.3.2、日志位置
日志消息可以在 $ES_HOME/logs/ 目录中找到
YUM安装的日志:cat /var/log/elasticsearch/elasticsearch.log
假如启动失败,从这个日志中查询报错信息4.3.3、启动异常
一般报错,常出现之前使用 root 用户启动,之后又使用普通用户启动的情况。 还有集群节点的 IP 地址变化的情况。
# 找到进程
[ela@ela1 elasticsearch‐7.10.0]$ jdk/bin/jps
8244 Jps
7526 Elasticsearch
# 杀死进程
[ela@ela1 elasticsearch‐7.10.0]$ kill ‐9 7526
查看相关日志 logs/elk.log 根据日志修改相关配置信息 解决完成后执行如下操作
# 删除数据目录中的所有文件
[ela@ela1 elasticsearch‐7.10.0]$ rm ‐rf data/*
# 删除日志
[ela@ela1 elasticsearch‐7.10.0]$ rm ‐rf logs/*
# 删除 keystore 文件
[ela@ela1 elasticsearch‐7.10.0]$ rm ‐rf config/elasticsearch.keystore
# 重新启动进程
[ela@ela1 elasticsearch‐7.10.0]$ bin/elasticsearch ‐d ‐p /tmp/elk.pid
关闭 Elasticsearch 进程
# 二进制方式
# pkill ‐F /tmp/elasticsearch.pid
4.3.4、无报错启动异常
elasticsearch启动失败,es日志和systemctl状态查询只报错,系统日志只声明启动失败,无详细原因
目前解决办法有一个,原理不详,从解决办法反推可能是es安装时全局变量未刷新导致(只是猜测),知道的大佬可以来说一下。
解决办法:
使用yum卸载elasticsearch,卸载后会将配置文件保存为/etc/elasticsearch/elasticsearch.yml.rpmsave,将这个文件保存下来重装es,然后使用原文件替换新装的yml文件,按照正常步骤启动即可。
4.4、Es集群测试
4.4.1、配置步骤
Logstash配置
[root@ela1 ~]# vim /usr/local/logstash/config/first-pipeline.conf
[root@ela1 ~]# cat /usr/local/logstash/config/first-pipeline.conf
input {
beats { port => 5044 }
}
filter {
grok { match => { "message" => "%{COMBINEDAPACHELOG}" } }
}
output {
stdout {}
elasticsearch {
hosts => ["192.168.188.128:9200","192.168.188.129:9200","192.168.188.130:9200"]
}
}
配置Filebeat输出数据到logstash(前面已经配置)
启动 Logstash,Filebeat
[root@ela1 ~]# /usr/local/logstash/bin/logstash -f /usr/local/logstash/config/first-pipeline.conf
[root@ela1 ~]# /usr/local/filebeat/filebeat -c /usr/local/filebeat/filebeat.yml新增示例日志观察效果
[root@ela1 ~]# vim /tmp/access.log
[root@ela1 ~]# tail -1 /tmp/access.log
192.168.188.9999 - - [29/Jun/2024:17:09:54 +0800] "GET /images/apache_pb.gif HTTP/1.1" 200 2326 "http://192.168.188.128/" "Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:127.0) Gecko/20100101 Firefox/127.0"
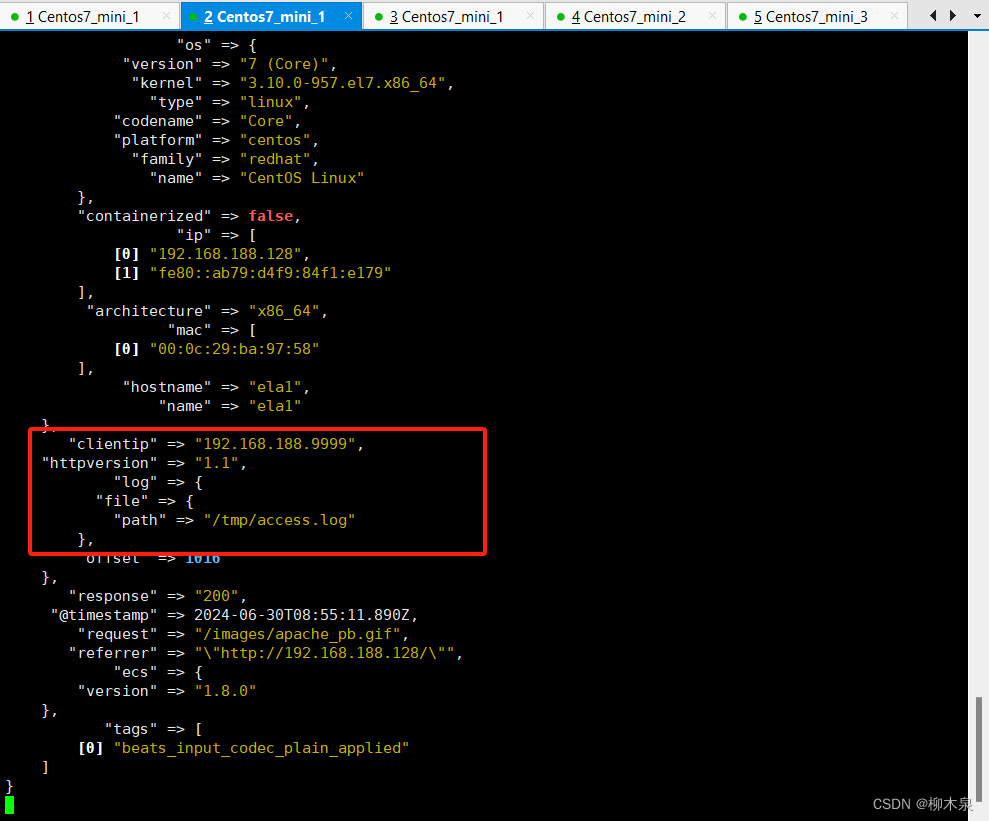
4.4.2、 验证索引
[root@ela1 ~]# curl ‐X GET "192.168.188.128:9200/_cat/indices"
# 这个位置有时会出现未知错误,不用理会,下方即为正确的索引信息
green open logstash-2024.06.30-000001 OevwWDSuSHifTRmct6WWDw 1 1 3 0 60.4kb 30.2kb4.5、自定义索引
使用index自定义索引,这里使用日志文件路径定义索引类别
[root@ela1 ~]# vim /usr/local/logstash/config/first-pipeline.conf
[root@ela1 ~]# cat /usr/local/logstash/config/first-pipeline.conf
input {
beats { port => 5044 }
}
filter {
grok { match => { "message" => "%{COMBINEDAPACHELOG}" } }
}
output {
stdout {}
if [log][file][path] == "/var/log/access.log" {
elasticsearch {
hosts => ["192.168.188.128:9200","192.168.188.129:9200","192.168.188.130:9200"]
index => "%{[host][hostname]}‐nginx‐access‐%{+YYYY.MM.dd}"
}
} else if [log][file][path] == "/var/log/error.log" {
elasticsearch {
hosts => ["192.168.188.128:9200","192.168.188.129:9200","192.168.188.130:9200"]
index => "%{[host][hostname]}‐nginx‐error‐%{+YYYY.MM.dd}"
}
}
}启动filebeat、logstash,向示例日志添加内容
[root@ela1 ~]# vim /var/log/access.log
[root@ela1 ~]# vim /var/log/error.log 查看es索引情况
[root@ela1 ~]# curl ‐X GET "192.168.188.128:9200/_cat/indices"
green open ela1‐nginx‐access‐2024.06.30 XpFFs4DhSgmN8OvzBOVuxA 1 1 3 0 85.4kb 54.9kb
green open ela1‐nginx‐error‐2024.06.30 zcpNHRS0RWq4gI5BgTwgDg 1 1 4 0 60.8kb 30.4kb
green open logstash-2024.06.30-000001 OevwWDSuSHifTRmct6WWDw 1 1 3 0 60.6kb 30.3kb
# 前两个索引即为刚刚自定义名称后的索引实验完成
补充:使用filebeat模块名称定义索引类别
。。。。。。。。。。。。。
if [event][dataset] == "nginx.access" {
。。。。。。。。。。。。。。
} else if [event][dataset] == "nginx.error" {
。。。。。。。。。。。。。。5、Kibana
Kibana 是进入 Elastic 的窗口。利用 Kibana可以:
- 搜索、观察和保护数据。从发现文档到分析日志,再到发现安全漏洞,Kibana 提供了访问这些功能及其他功能的门户。
- 可视化和分析数据。搜索深藏的见解,将发现的内容可视化在图表、仪表盘和地图中,并将它们组合成仪表板。
- 管理、监视和保护 Elastic Stack。管理索引和数据提取管道,监视 Elastic Stack 集群的运行状况,并控制用户对功能的访问权限。
5.1、Kibana部署
[root@ela1 ~]# curl ‐L ‐O https://artifacts.elastic.co/downloads/kibana/kibana‐7.13.2‐linux‐x86_64.tar.gz
[root@ela1 ~]# tar xzvf kibana‐7.13.2‐linux‐x86_64.tar.gz ‐C /usr/local/
# 这个建议使用v显示详情,解压时间有点长
[root@ela1 ~]# mv /usr/local/kibana-7.13.2-linux-x86_64 /usr/local/kibana
5.2、Kibana配置
[root@ela1 ~]# vim /usr/local/kibana/config/kibana.yml
server.port: 5601
server.host: "0.0.0.0"
elasticsearch.hosts: ["http://ela1:9200"]
logging.dest: /var/log/kibana/kibana.log
i18n.locale: "zh-CN"创建用户
[root@ela1 ~]# useradd ela
[root@ela1 ~]# mkdir /run/kibana
[root@ela1 ~]# mkdir /var/log/kibana
[root@ela1 ~]# chown ela.ela /run/kibana /var/log/kibana/ /usr/local/kibana -R
5.3、启动测试kibana
[root@ela1 ~]# su - ela
[ela@ela1 ~]$ nohup /usr/local/kibana/bin/kibana &
[1] 11760
[ela@ela1 ~]$ nohup: 忽略输入并把输出追加到"nohup.out"
[ela@ela1 ~]$ exit
登出
使用网页访问
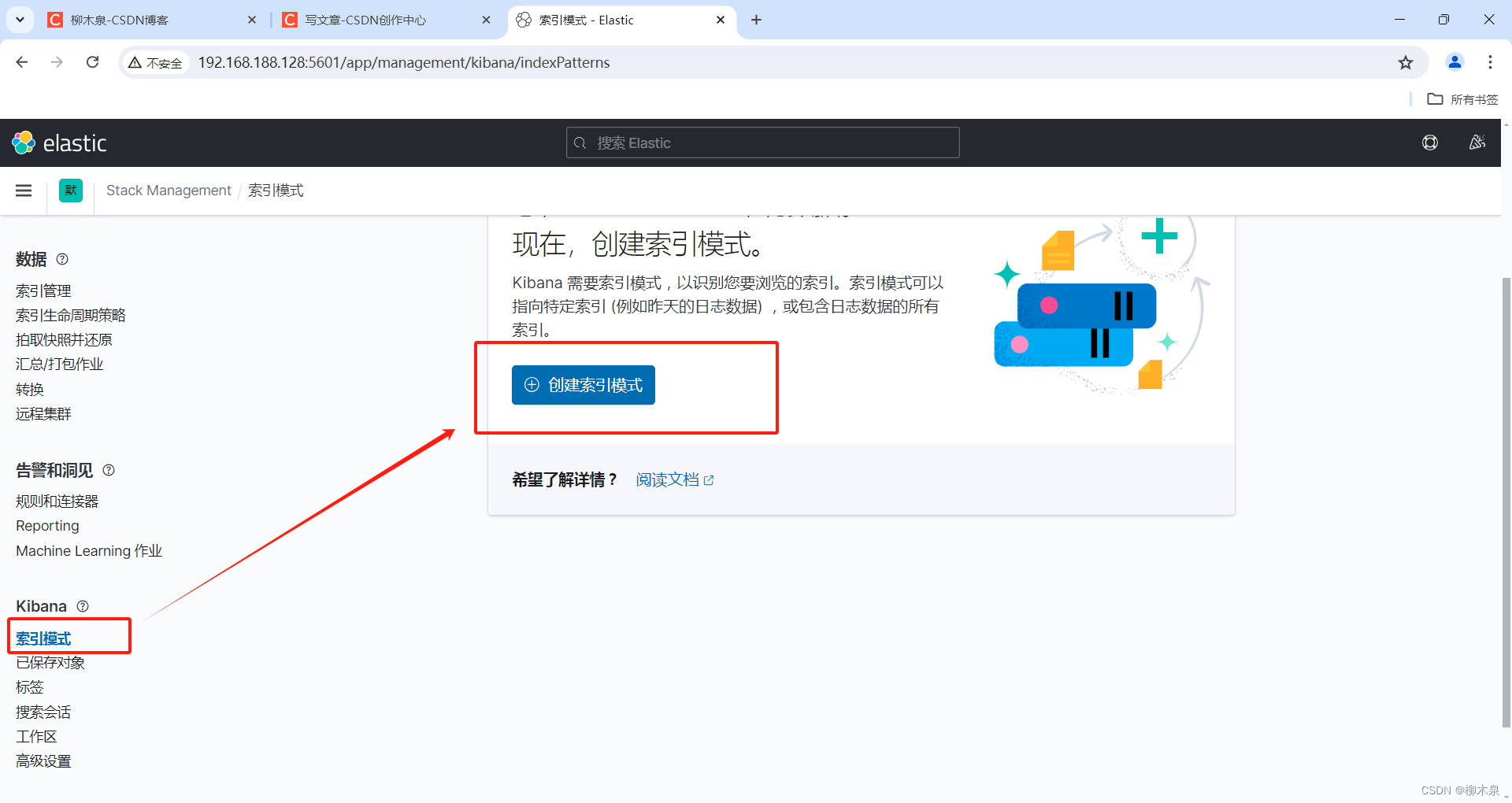
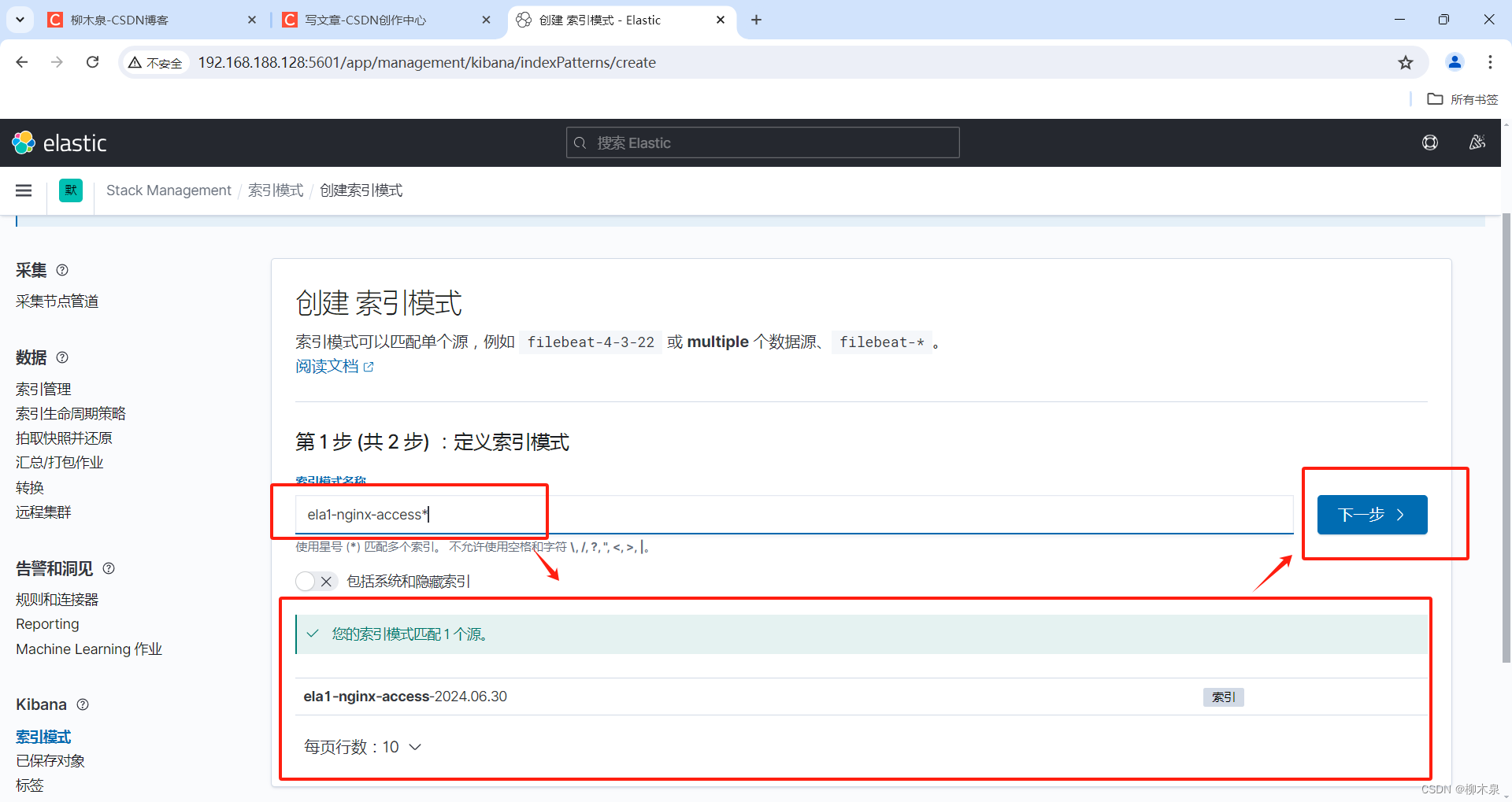
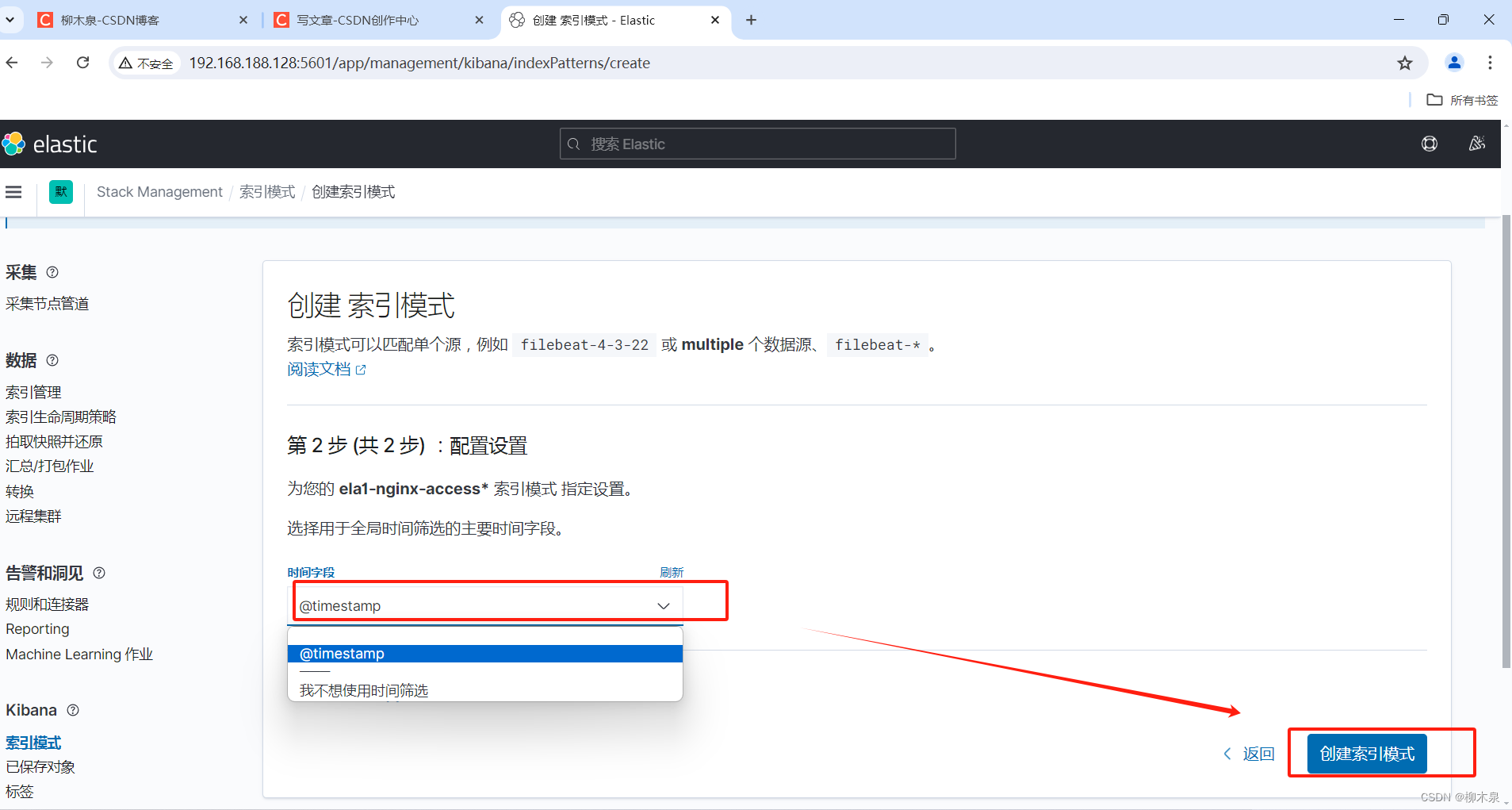
5.3、创建索引模式
Kibana需要使用索引模式来访问要浏览的Elasticsearch数据。索引模式选择要使用的数据,并允许您定义字段的属 性。 索引模式可以指向特定索引,例如,昨天的日志数据或包含您的数据的所有索引。它还可以指向数据流或索引别名.

5.4、查询数据
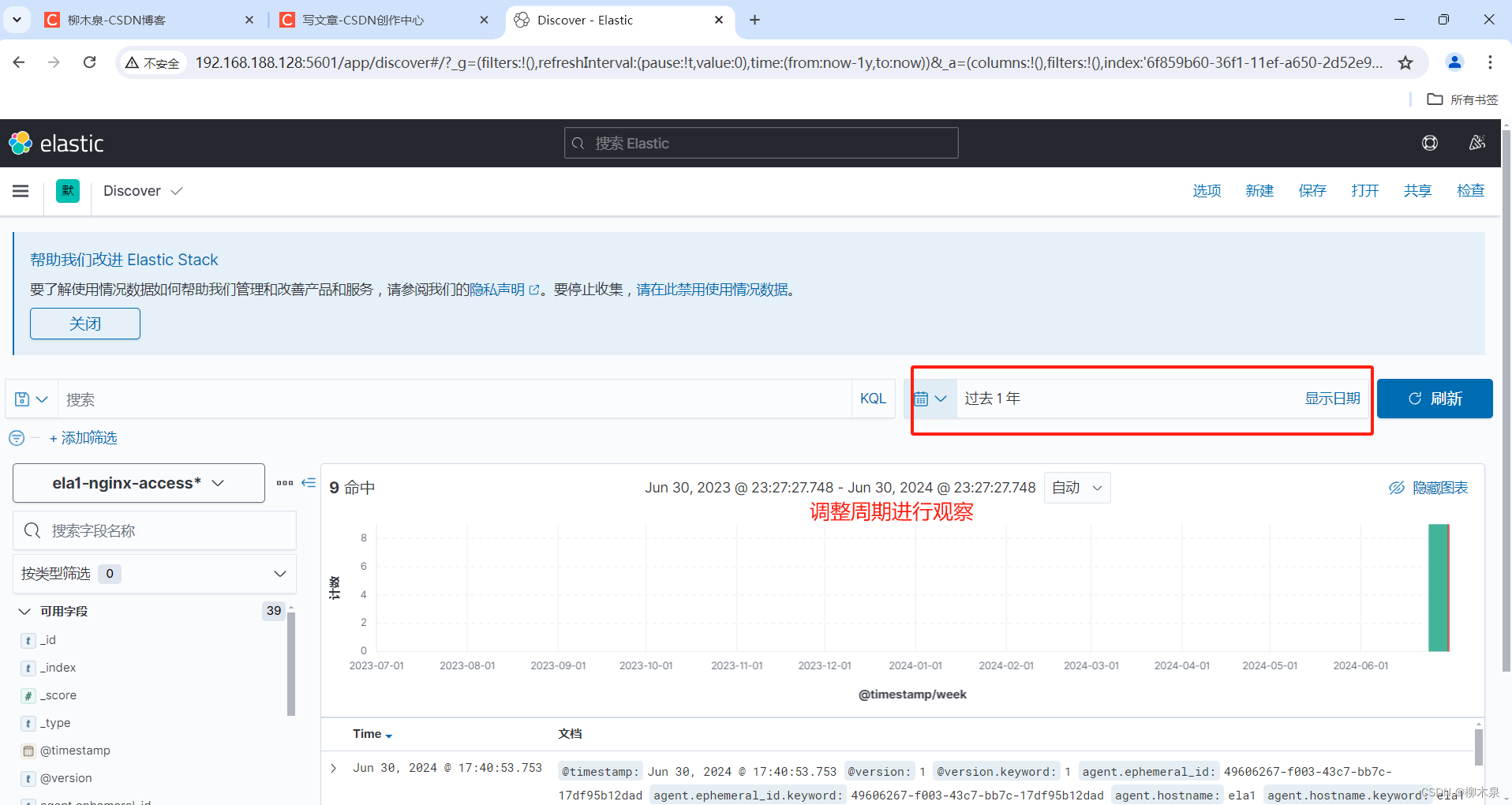
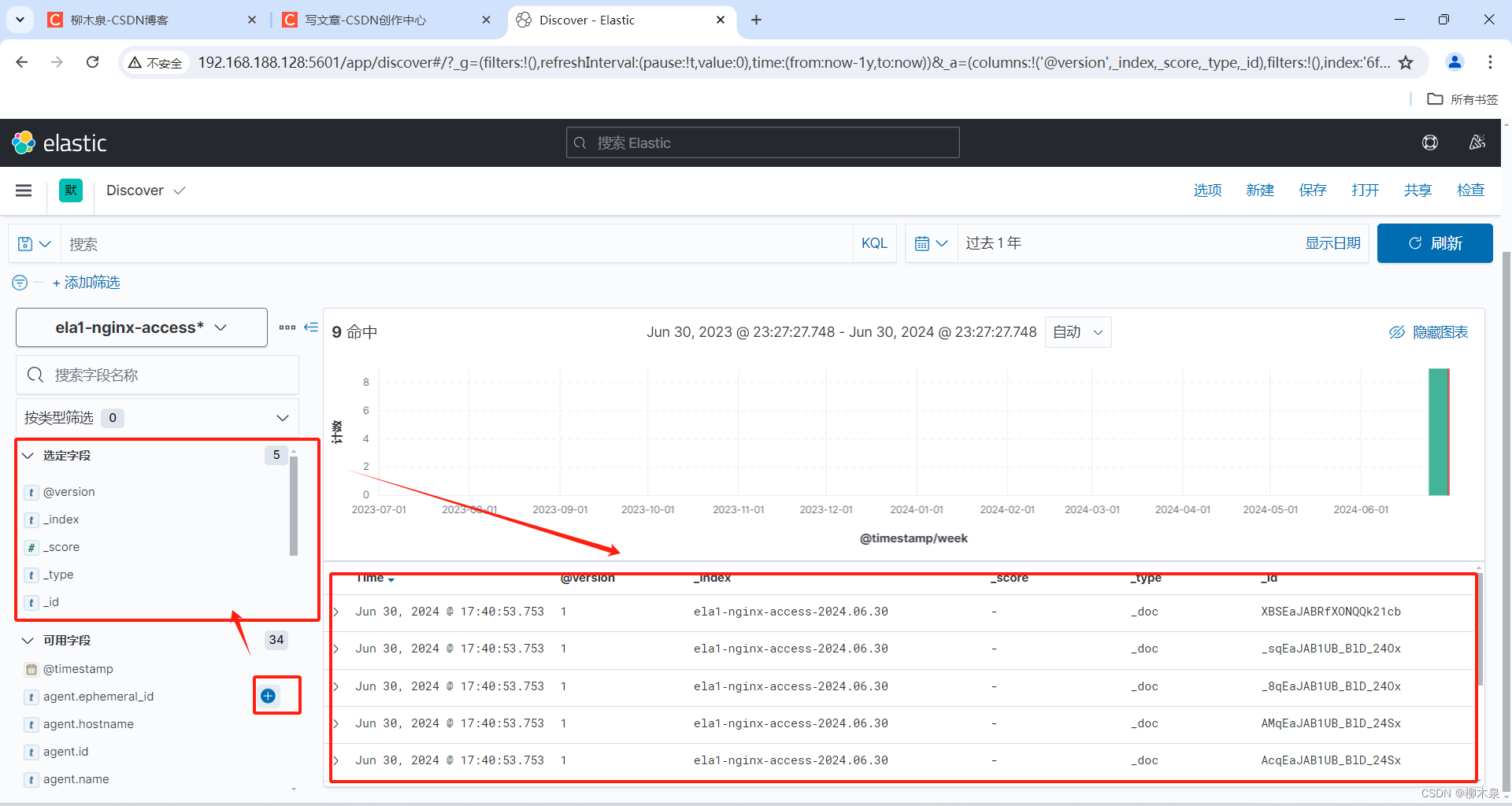
通过添加字段完成筛选
6、Kafka集群
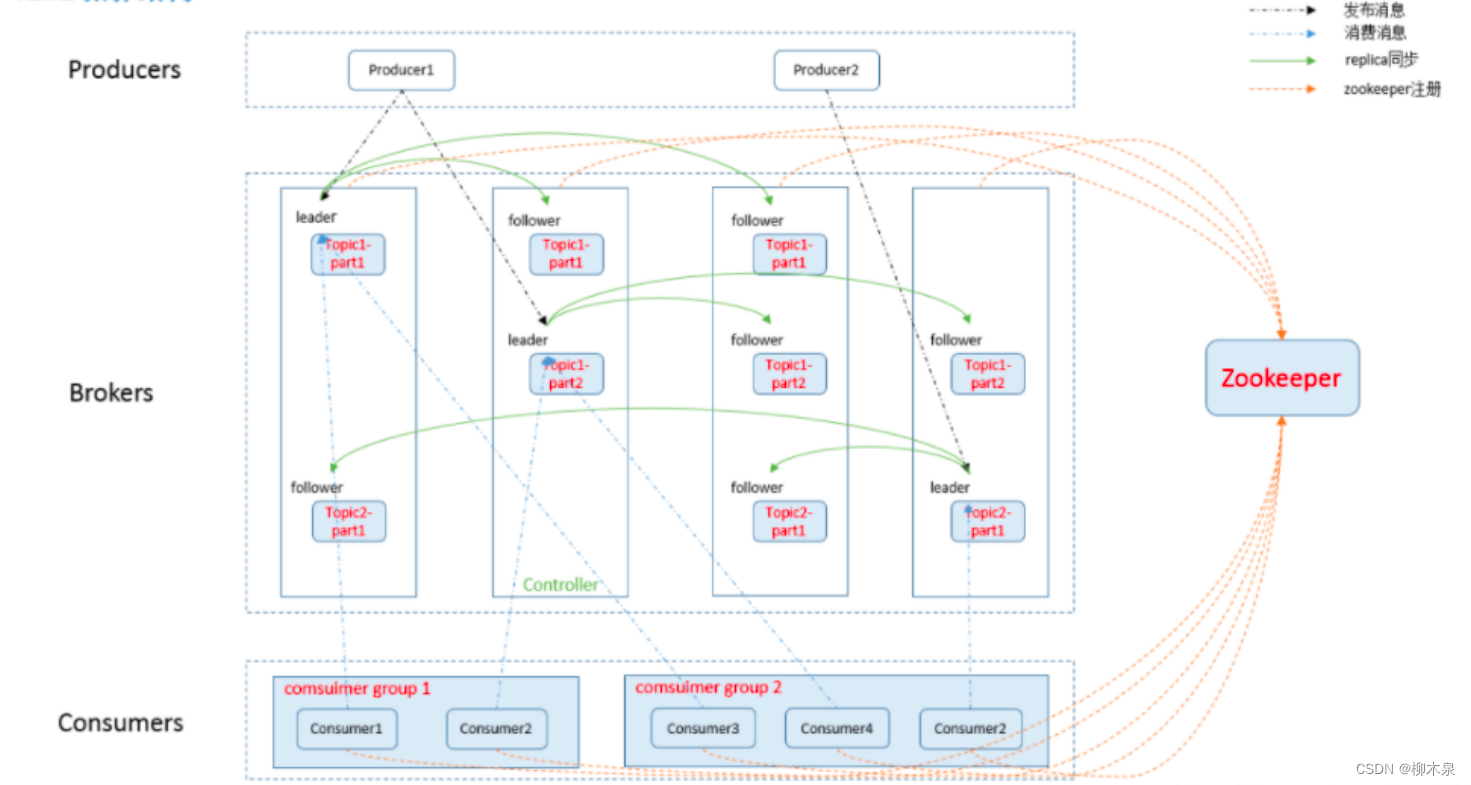
Kafka是一个分布式、支持分区、多副本的消息系统,基于ZooKeeper协调。它具有数据缓冲队列的功能,提高了可扩展性和峰值处理能力。使用消息队列可以帮助关键组件在突发访问压力下保持稳定,避免因突发超负荷请求而完全崩溃。Kafka的最大特性之一是能够实时处理大量数据,满足各种需求场景,例如基于Hadoop的批处理系统、低延迟的实时系统、Web/Nginx日志、访问日志和消息服务等。
应用服务日志采集后(工作环境中这个量十分庞大)不送到es而是先缓冲到kafka中,Kafka在这里做到缓冲水池作用,redis,rabbitmq也有相同功能。
kafka特性:
- 高吞吐量:kafka每秒可以处理几十万条消息。
- 可扩展性:kafka集群支持热扩展- 持久性
- 可靠性:消息被持久化到本地磁盘,并且支持数据备份防止数据丢失
- 容错性:允许集群中节点失败(若副本数量为n,则允许n-1个节点失败)
- 高并发:支持数千个客户端同时读写
下面这个表必须要背下来!!!
| 名称 | 详解 |
|---|---|
| 话题(Topic) | 在Kafka中,话题指的是消息的类别或者类型,可以理解为一种消息流的抽象。每个发布到Kafka集群的消息都属于某个特定的话题。话题定义了消息流的逻辑标识,它是Kafka消息发布的核心机制之一 |
| 生产者(Producer) | 生产者(Producer)在Kafka中是指能够向话题(Topic)发布消息的客户端应用程序或服务。 |
| 消费者(Consumer) | 用于实时或者批量地处理和分析大规模的数据流 |
| 服务代理(Broker) | 负责管理和存储消息数据,中间人。kafka的物理机被称为Broker |
| partition(区) | Kafka 中的每个主题(Topic)可以被分为一个或多个分区(Partition) |
| replication | partition 的副本,保障 partition 的高可用。 和上面配合使用,分片存储,同时保留与自己不同片的副本。 |
| leader | 领导者是分区中副本(Replica)的一个角色,它负责处理所有的读写请求 |
| follower | 追随者是副本中的一种角色,其主要任务是从领导者(Leader)那里复制数据,并保持与领导者的数据同步。 |
| zookeeper | kafka 通过 zookeeper 来存储集群的信息,集群管理员。 |
Kafka集群原理图
zookeeper内容参考前面Hadoop第二章
6.1、集群部署
继续使用上面的环境,但是域名解析需要增加配置
[root@ela1 ~]# echo 192.168.188.128 es01 >> /etc/hosts
[root@ela1 ~]# echo 192.168.188.129 es02 >> /etc/hosts
[root@ela1 ~]# echo 192.168.188.130 es03 >> /etc/hosts
[root@ela1 ~]# scp /etc/hosts 192.168.188.129:/etc/
[root@ela1 ~]# scp /etc/hosts 192.168.188.130:/etc/安装java环境
[root@ela1 ~]# yum install -y java-1.8.0-openjdk6.1.1、安装zookeeper
Kafka运行依赖zookeeper,Kafka官网提供的tar包中,已经包含了zookeeper,这里不再额外下载ZK程序。
[root@ela1 ~]#wget https://mirrors.tuna.tsinghua.edu.cn/apache/kafka/2.8.0/kafka_2.12-2.8.0.tgz
[root@ela1 ~]# tar xzvf kafka_2.12-2.8.0.tgz -C /usr/local/
[root@ela1 ~]# mv /usr/local/kafka_2.12-2.8.0/ /usr/local/kafka/
# 三台都要装6.1.2、配置zookeeper
es01
[root@ela1 ~]# sed -i 's/^[^#]/#&/' /usr/local/kafka/config/zookeeper.properties
# 将文件内所有行注释
[root@ela1 ~]# vim /usr/local/kafka/config/zookeeper.properties
# 在文件内添加
dataDir=/opt/data/zookeeper/data
dataLogDir=/opt/data/zookeeper/logs
clientPort=2181
tickTime=2000
initLimit=20
syncLimit=10
server.1=192.168.188.128:2888:3888
server.2=192.168.188.129:2888:3888
server.3=192.168.188.130:2888:3888
[root@ela1 ~]# mkdir -p /opt/data/zookeeper/{data,logs}
[root@ela1 ~]# echo 1 > /opt/data/zookeeper/data/myid
es02
[root@ela2 ~]# sed -i 's/^[^#]/#&/' /usr/local/kafka/config/zookeeper.properties
[root@ela2 ~]# vim /usr/local/kafka/config/zookeeper.properties
# 同上
[root@ela2 ~]# mkdir -p /opt/data/zookeeper/{data,logs}
[root@ela2 ~]# echo 2 > /opt/data/zookeeper/data/myid
es03
[root@ela3 ~]# sed -i 's/^[^#]/#&/' /usr/local/kafka/config/zookeeper.properties
[root@ela3 ~]# vim /usr/local/kafka/config/zookeeper.properties
# 同上
[root@ela3 ~]# mkdir -p /opt/data/zookeeper/{data,logs}
[root@ela3 ~]# echo 3 > /opt/data/zookeeper/data/myid
配置项含义
dataDir: ZK数据存放目录。
dataLogDir: ZK日志存放目录。
clientPort: 客户端连接ZK服务的端口。
tickTime: ZK服务器之间或客户端与服务器之间维持心跳的时间间隔。
initLimit: 允许follower连接并同步到Leader的初始化连接时间。当初始化连接时间超过该值,则表示连接失败。
syncLimit: Leader与Follower之间发送消息时,如果follower在设置时间内不能与leader通信,那follower将会被丢弃。
server.1=192.168.19.20:2888:3888:
2888: follower与leader交换信息的端口。
3888: 当leader挂了时用来执行选举时服务器相互通信的端口。
6.1.3、配置Kafka
es01
[root@ela1 ~]# sed -i 's/^[^#]/#&/' /usr/local/kafka/config/server.properties
[root@ela1 ~]# vim /usr/local/kafka/config/server.properties
# 添加如下内容,记得改ip,粘贴后删除注释
broker.id=1 #主机序号
listeners=PLAINTEXT://192.168.188.128:9092 #监听地址(这里生产者为本机)
num.network.threads=3 #开启3个网络进程,处理消息
num.io.threads=8 #处理磁盘IO的线程数,这个数字需要大于磁盘
socket.send.buffer.bytes=102400 #发送缓冲区多少字节
socket.receive.buffer.bytes=102400 #接受缓冲区
socket.request.max.bytes=104857600 #socket请求最大数值
log.dirs=/opt/data/kafka/logs #日志文件目录
num.partitions=6 #分区数量
num.recovery.threads.per.data.dir=1 #数据恢复时进程数量
offsets.topic.replication.factor=2 #数据副本数量,一个数据分成六份,每份复制两遍
transaction.state.log.replication.factor=1 #事务状态日志的副本数量
transaction.state.log.min.isr=1
log.retention.hours=168 #日志保留时间,单位小时
log.segment.bytes=536870912 #日志段文件的大小,单位字节
log.retention.check.interval.ms=300000 #日志保留检查间隔时间,单位毫秒
zookeeper.connect=192.168.188.128:2181,192.168.188.129:2181,192.168.188.130:2181 #Zookeeper连接地址列表
zookeeper.connection.timeout.ms=6000 #Zookeeper连接超时时间,单位毫秒
group.initial.rebalance.delay.ms=0 #初始重平衡延迟时间,单位毫秒
[root@ela1 ~]# mkdir -p /opt/data/kafka/logses02
[root@ela2 ~]# sed -i 's/^[^#]/#&/' /usr/local/kafka/config/server.properties
[root@ela2 ~]# vim /usr/local/kafka/config/server.properties
# 添加如下内容,记得改ip,粘贴后删除注释
broker.id=2 #主机序号
listeners=PLAINTEXT://192.168.188.129:9092 #监听地址(这里生产者为本机)
num.network.threads=3 #开启3个网络进程,处理消息
num.io.threads=8 #处理磁盘IO的线程数,这个数字需要大于磁盘
socket.send.buffer.bytes=102400 #发送缓冲区多少字节
socket.receive.buffer.bytes=102400 #接受缓冲区
socket.request.max.bytes=104857600 #socket请求最大数值
log.dirs=/opt/data/kafka/logs #日志文件目录
num.partitions=6 #分区数量
num.recovery.threads.per.data.dir=1 #数据恢复时进程数量
offsets.topic.replication.factor=2 #数据副本数量,一个数据分成六份,每份复制两遍
transaction.state.log.replication.factor=1 #事务状态日志的副本数量
transaction.state.log.min.isr=1
log.retention.hours=168 #日志保留时间,单位小时
log.segment.bytes=536870912 #日志段文件的大小,单位字节
log.retention.check.interval.ms=300000 #日志保留检查间隔时间,单位毫秒
zookeeper.connect=192.168.188.128:2181,192.168.188.129:2181,192.168.188.130:2181 #Zookeeper连接地址列表
zookeeper.connection.timeout.ms=6000 #Zookeeper连接超时时间,单位毫秒
group.initial.rebalance.delay.ms=0 #初始重平衡延迟时间,单位毫秒
[root@ela2 ~]# mkdir -p /opt/data/kafka/logses03
参考es02修改即可
6.2、启动Kafka集群
先开zookeeper再开Kafka,关闭先关Kafka,三个节点依次执行
[root@ela1 ~]# nohup /usr/local/kafka/bin/zookeeper-server-start.sh /usr/local/kafka/config/zookeeper.properties &
[1] 11587
[root@ela1 ~]# nohup: 忽略输入并把输出追加到"nohup.out"
[root@ela1 ~]# jobs
[1]+ 运行中 nohup /usr/local/kafka/bin/zookeeper-server-start.sh /usr/local/kafka/config/zookeeper.properties &
# 查看端口
[root@ela1 ~]# netstat -lntp | grep 2181
tcp6 0 0 :::2181 :::* LISTEN 11575/java 启动Kafka,三个节点依次执行
[root@ela1 ~]# nohup /usr/local/kafka/bin/kafka-server-start.sh /usr/local/kafka/config/server.properties &6.3、测试集群
创建topic,注意此处执行命令的主机
# 使用es02创建
[root@ela2 ~]# /usr/local/kafka/bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic testtopic
Created topic testtopic.
# 使用 kafka-topics.sh 工具。
# 向本地主机上运行的 Zookeeper 实例发送请求(通过 --zookeeper 参数指定)。
# 创建了一个名为 testtopic 的主题。
# 主题只有一个分区,并且该分区的数据只会在单个 Kafka Broker 上保存(因为副本因子设置为 1)。
# 使用es01查看
[root@ela1 ~]# /usr/local/kafka/bin/kafka-topics.sh --zookeeper 192.168.188.129:2181 --list
testtopic
模拟消息的生产和消费
es01
[root@ela1 ~]# /usr/local/kafka/bin/kafka-console-producer.sh --broker-list 192.168.188.129:9092 --topic testtopic
>hello
>liumuquan
>柳木泉
>
es02
[root@ela2 ~]# /usr/local/kafka/bin/kafka-console-consumer.sh --bootstrap-server 192.168.188.129:9092 --topic testtopic --from-beginning
hello
liumuquan
柳木泉7、完整集群演示
此处用来完成开篇的这个拓扑图
以前面实验为基础
logstash服务器从kafka获取数据并输出到es集群(改输入)
[root@ela1 ~]# vim /usr/local/logstash/config/first-pipeline.conf
[root@ela1 ~]# cat /usr/local/logstash/config/first-pipeline.conf
input {
kafka {
type => "nginx_log"
codec => "json"
topics => ["nginx"]
decorate_events => true
bootstrap_servers => "192.168.188.128:9092,192.168.188.129:9092.192.168.188.130:9092"
}
}
filter {
grok { match => { "message" => "%{COMBINEDAPACHELOG}" } }
}
output {
stdout {}
if [type] == "nginx_log"{
elasticsearch {
index => "nginx-%{+YYYY.MM.dd}"
codec => "json"
hosts => ["192.168.188.128:9200","192.168.188.129:9200","192.168.188.130:9200"]
}
}
}
[root@ela1 ~]#
默认情况下,decorate_events => true 是 false。设置为 true 时,将向 Logstash 事件添加一个名为 kafka 的字段,其中包含以下属性:
topic:与消息相关联的主题。
consumer_group:用于读取该事件的消费者群组。
partition:消息所在的分区。
offset:消息在分区中的偏移量。
key:包含消息键的 ByteBuffer。
启动logstash
[root@ela1 ~]# /usr/local/logstash/bin/logstash -f /usr/local/logstash/config/first-pipeline.conf --config.reload.automatic配置 Filebeat 输出到 kafka(改输出)
[root@ela1 ~]# vim /usr/local/filebeat/filebeat.yml
#注释掉所有输出
#添加部分如下
output.kafka:
hosts: ["192.168.188.128:9092","192.168.188.129:9092","192.168.188.130:9092"]
topic: 'nginx'
partition.round_robin:
reachable_only: false
required_acks: 1
compression: gzip
max_message_bytes: 1000000
partition.round_robin
这个部分指定了如何将消息分发到 Kafka 的分区(partitions)。round_robin 表示使用轮询方式,即按照顺序依次将消息发送到每个分区。reachable_only: false 表示如果某个分区不可达,Filebeat 不会等待,而是继续尝试发送到其他分区。
required_acks
指定了发送数据时要求的确认机制。这里设置为 1,表示只需要 leader broker 在接收到消息后立即发送确认。这是最常见的设置,可以在不牺牲太多性能的情况下确保消息的传递。
compression
指定了数据压缩的算法。这里设置为 gzip,表示 Filebeat 将使用 gzip 压缩传输到 Kafka 的消息,以减少网络带宽的使用。
max_message_bytes
指定了单个消息的最大字节数。这里设置为 1000000 字节(即 1MB),超过这个大小的消息将被拆分或丢弃,以防止 Kafka 处理过大的消息导致性能问题。启动filebeat
[root@ela1 ~]# /usr/local/filebeat/filebeat -c /usr/local/filebeat/filebeat.ymlkafka集群上验证kafka是否生成topic
[root@ela3 ~]# /usr/local/kafka/bin/kafka-topics.sh --zookeeper 192.168.188.130:2181 --list
__consumer_offsets
nginx
testtopic
此处已生成新的topic:“nginx”
在es集群上查看索引现在的状态
[root@ela3 ~]# curl ‐X GET "192.168.188.130:9200/_cat/indices"
green open .kibana_7.13.2_001 vp7CDeP1T8mS0sCph-0u0A 1 1 27 1 4.2mb 2.1mb
green open ela1‐nginx‐error‐2024.06.30 zcpNHRS0RWq4gI5BgTwgDg 1 1 4 0 61kb 30.5kb
green open ela1‐nginx‐access‐2024.06.30 XpFFs4DhSgmN8OvzBOVuxA 1 1 9 0 154.3kb 64.8kb
green open .apm-custom-link sgP9vaINR-W4q7vZiNYhyQ 1 1 0 0 416b 208b
green open .kibana-event-log-7.13.2-000001 M2JHaqFxRRqsPa-s2Ic1cg 1 1 1 0 11.2kb 5.6kb
green open .apm-agent-configuration u3-3QG-6QAWQQmX14wJYAQ 1 1 0 0 416b 208b
green open .async-search _Yzp1tluSG-UpimnoKmyvg 1 1 0 0 456b 228b
green open .kibana_task_manager_7.13.2_001 NiLGZK15QESIc26BL0dm6g 1 1 10 4615 1017.9kb 508.9kb
green open logstash-2024.06.30-000001 OevwWDSuSHifTRmct6WWDw 1 1 3 0 60.6kb 30.3kb修改示例日志
[root@ela1 ~]# vim /tmp/access.log
[root@ela1 ~]# vim /var/log/access.log
[root@ela1 ~]# vim /var/log/error.log logstash已收到新抓取的日志
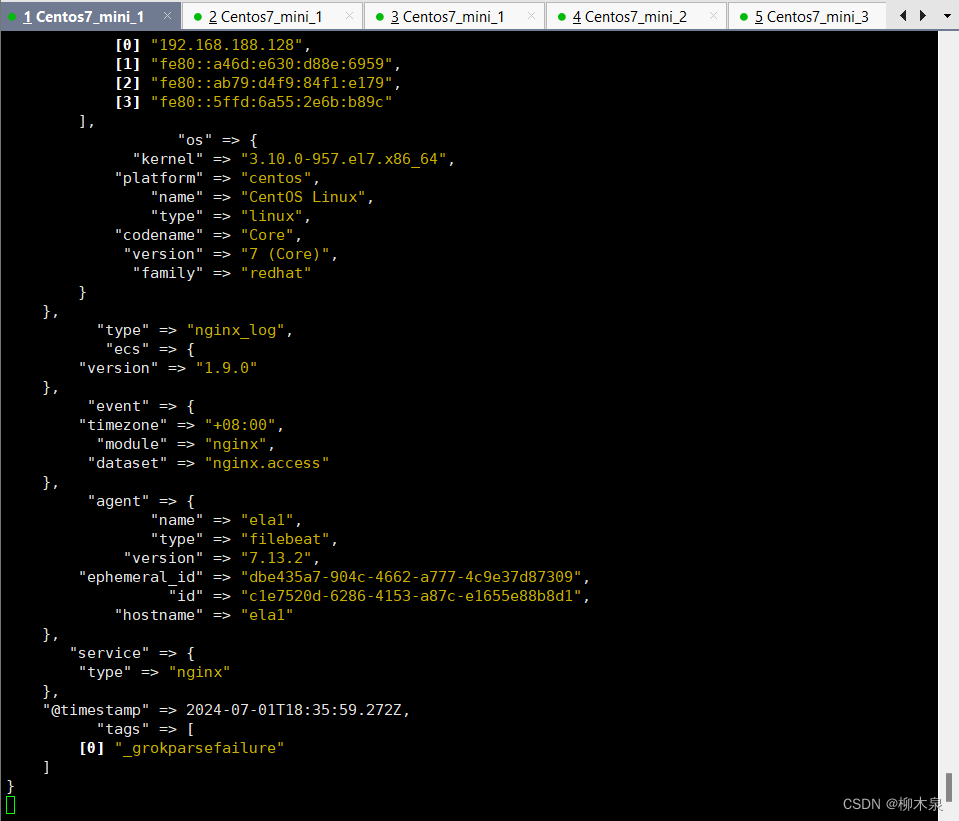
在es集群上查看索引的状态
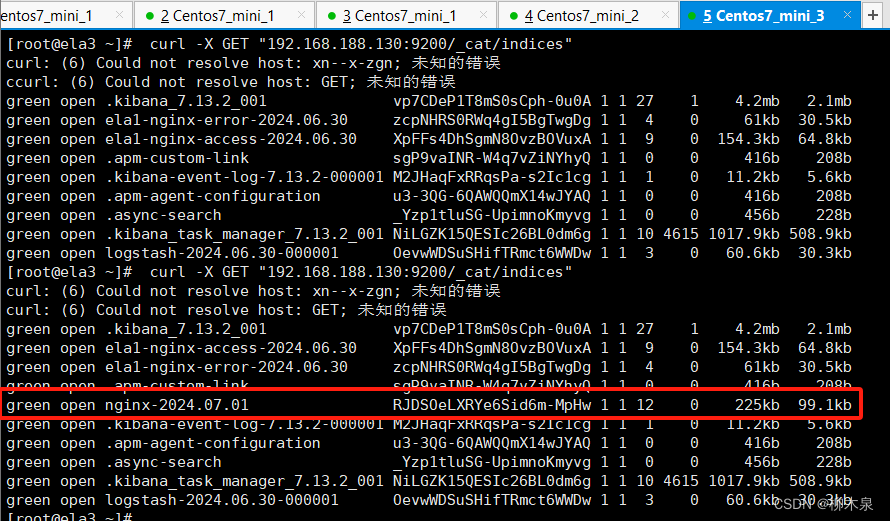
按照工作中的流程已经可以使用kibana的web页面进行管理
后记:
到这里ELK这一章就完全结束了,与工作环境不同的只有一些ip的配置,这篇文章保存后,在工作环境中可以直接复制对应配置写入,稍加修改即可。
全文33000字,感谢自己能坚持到今天还不崩溃Y(^_^)Y