目录
1.导入必要的库
2.导入数据与数据预处理
3.查看数据分布
4.特征选择
5.模型建立与训练
6.训练集预测结果
7.模型评估
8.预测新数据
9.贝叶斯优化超参数
1.导入必要的库
# 导入所需的库
from sklearn.model_selection import cross_val_score
import pandas as pd
import numpy as np
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestRegressor
from sklearn.feature_selection import SelectKBest, f_regression
from sklearn.metrics import mean_squared_error, r2_score
from bayes_opt import BayesianOptimization
import matplotlib.pyplot as plt 2.导入数据与数据预处理
# 加载数据
data = pd.read_excel('train1.xlsx')
test_data = pd.read_excel('test1.xlsx')
# 假设所有列都用于训练,除了最后一列是目标变量
X = data.iloc[:, :-1]
y = data.iloc[:, -1]
# 如果有缺失值,可以选择填充或删除
X.fillna(X.mean(), inplace=True)
test_data.fillna(test_data.mean(), inplace=True)3.查看数据分布
# 注意:distplot 在 seaborn 0.11.0+ 中已被移除
# 你可以分别使用 histplot 和 kdeplot
plt.figure(figsize=(50, 50))
for i, feature in enumerate(data.columns, 1):
plt.subplot(6, int(len(data.columns)/6), i)
sns.histplot(data[feature], kde=True, bins=30, label=feature,color='cyan')
plt.title(f'QQ plot of {feature}', fontsize=40, color='black')
# 如果需要设置坐标轴标签的字体大小和颜色
plt.xlabel('X-axis Label', fontsize=35, color='black') # 设置x轴标签的字体大小和颜色
plt.ylabel('Y-axis Label', fontsize=40, color='black') # 设置y轴标签的字体大小和颜色
# 还可以调整刻度线的长度、宽度等属性
plt.tick_params(axis='x', labelsize=40, colors='black', length=5, width=1) # 设置x轴刻度线、刻度标签的更多属性
plt.tick_params(axis='y', labelsize=40, colors='black', length=5, width=1) # 设置y轴刻度线、刻度标签的更多属性
plt.tight_layout()
plt.subplots_adjust(wspace=0.2, hspace=0.3)
plt.show()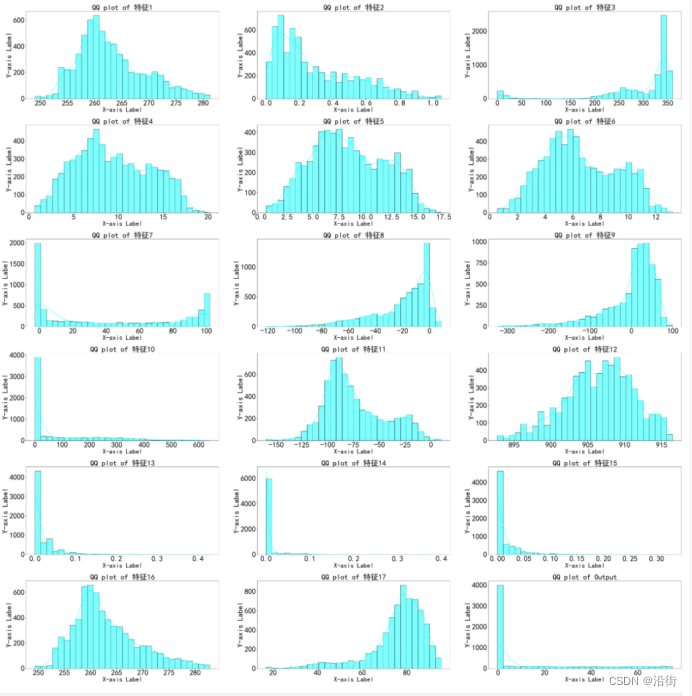
图1
4.特征选择
# 特征选择
# 使用SelectKBest选择K个最佳特征
selector = SelectKBest(score_func=f_regression, k=8) # 选择8个最佳特征
X_new = selector.fit_transform(X, y) 5.模型建立与训练
rf = RandomForestRegressor()
rf.fit(X_new, y)6.训练集预测结果
y_pred = rf.predict(X_new)
plt.figure(figsize=(10, 5))
plt.plot(y, label='Actual',c='g')
plt.plot(y_pred, label='RF Prediction',c='r')
plt.legend() 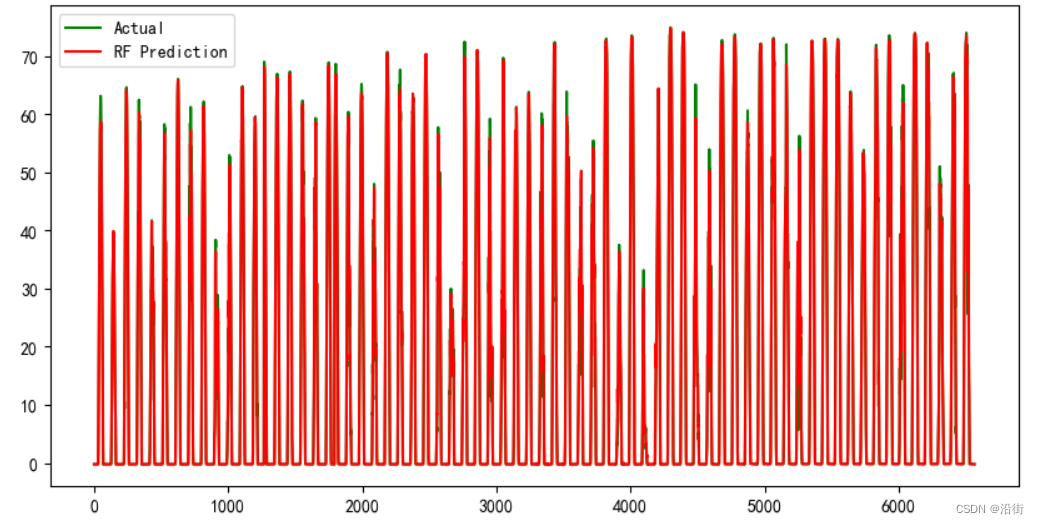
图2
7.模型评估
print("MSE:", mean_squared_error(y, y_pred))
print("R2 Score:", r2_score(y, y_pred))MSE: 1.969590155695453 R2 Score: 0.996235507229591
8.预测新数据
# 测试集预测
test_pred = rf.predict(selector.transform(test_data))
# 测试集预测结果可视化
plt.figure(figsize=(12, 6))
plt.plot(test_pred, label='RF Test Prediction',c='black')
plt.legend() 
图3
9.贝叶斯优化超参数
# 导入所需的库
from sklearn.model_selection import cross_val_score
import pandas as pd
import numpy as np
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestRegressor
from sklearn.feature_selection import SelectKBest, f_regression
from sklearn.metrics import mean_squared_error, r2_score
from bayes_opt import BayesianOptimization
import matplotlib.pyplot as plt
# 加载数据
data = pd.read_excel('train1.xlsx')
test_data = pd.read_excel('test1.xlsx')
# 假设所有列都用于训练,除了最后一列是目标变量
X = data.iloc[:, :-1]
y = data.iloc[:, -1]
# 如果有缺失值,可以选择填充或删除
X.fillna(X.mean(), inplace=True)
test_data.fillna(test_data.mean(), inplace=True)
# 特征选择
# 使用SelectKBest选择K个最佳特征
selector = SelectKBest(score_func=f_regression, k=8) # 假设选择8个最佳特征
X_new = selector.fit_transform(X, y)
# 定义随机森林模型
def rf_model(n_estimators, max_depth, min_samples_split, min_samples_leaf, random_state):
model = RandomForestRegressor(n_estimators=int(n_estimators),
max_depth=int(max_depth),
min_samples_split=int(min_samples_split),
min_samples_leaf=int(min_samples_leaf),
random_state=int(random_state))
return model
# 使用贝叶斯优化进行超参数调优
def rf_evaluate(n_estimators, max_depth, min_samples_split, min_samples_leaf, random_state):
model = rf_model(n_estimators, max_depth, min_samples_split, min_samples_leaf, random_state)
scores = -cross_val_score(model, X_new, y, cv=5, scoring='neg_mean_squared_error').mean()
return scores
rf_bo = BayesianOptimization(rf_evaluate, {
'n_estimators': (100, 300),
'max_depth': (5, 30),
'min_samples_split': (2, 10),
'min_samples_leaf': (1, 5),
'random_state': (0, 100)
})
# 执行优化过程
rf_bo.maximize(init_points=5, n_iter=3)
# 根据最优超参数训练模型
best_rf = rf_model(rf_bo.max['params']['n_estimators'],
rf_bo.max['params']['max_depth'],
rf_bo.max['params']['min_samples_split'],
rf_bo.max['params']['min_samples_leaf'],
rf_bo.max['params']['random_state'])
best_rf.fit(X_new, y)
# 未优化的随机森林模型
unoptimized_rf = RandomForestRegressor()
unoptimized_rf.fit(X_new, y)
# 进行预测
y_pred = unoptimized_rf.predict(X_new)
y_pred_best = best_rf.predict(X_new)
# 测试集预测
test_pred = unoptimized_rf.predict(selector.transform(test_data))
test_pred_best = best_rf.predict(selector.transform(test_data))
# 可视化预测结果
plt.figure(figsize=(10, 5))
plt.plot(y, label='Actual')
plt.plot(y_pred, label='Unoptimized RF Prediction')
plt.plot(y_pred_best, label='Optimized RF Prediction')
plt.legend()
plt.show()
# 测试集预测结果可视化
plt.figure(figsize=(10, 5))
plt.plot(test_pred, label='Unoptimized RF Test Prediction')
plt.plot(test_pred_best, label='Optimized RF Test Prediction')
plt.legend()
plt.show()
# 评估模型
print("未优化的随机森林:")
print("MSE:", mean_squared_error(y, y_pred))
print("R2 Score:", r2_score(y, y_pred))
print("\n优化的随机森林:")
print("MSE:", mean_squared_error(y, y_pred_best))
print("R2 Score:", r2_score(y, y_pred_best))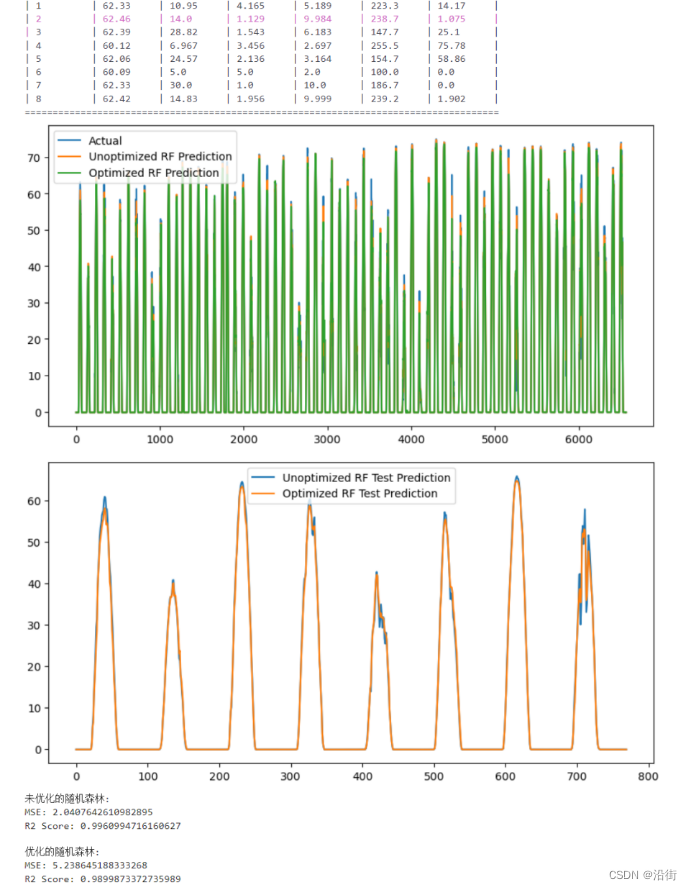
图4
从结果上看,优化了个寂寞,这和本身随机森林训练效果就好且迭代次数较少有直接关系。