文章目录
- 什么是JVM
- 内存结构
- 程序计数器(Program Counter Register)
- 虚拟机栈(Java Virtual Machine Stacks)
- 概述
- 栈内存溢出
- 本地方法栈
- 堆(Heap)
- 堆内存溢出
- 堆内存诊断
- 方法区
- 方法区内存溢出
- 常量池
- 运行时常量池
- StringTable_常量池与串池的关系
- StringTable_字符串变量拼接
- StringTable_编译器优化
- StringTable_字符串延迟加载
- StringTable_intern
- StringTable特性
- StringTable位置
- StringTable_垃圾回收
- StringTable性能调优
- 直接内存(Direct Memory)
- 直接内存分配和释放原理
- 禁止显示回收对直接内存的影响
什么是JVM
Java 虚拟机(JVM)是运行 Java 二进制字节码的虚拟机。JVM 有针对不同系统的特定实现(Windows,Linux,macOS),目的是使用相同的字节码,它们都会给出相同的结果。字节码和不同系统的 JVM 实现是 Java 语言“一次编译,随处可以运行”的关键所在。
JVM 并不是只有一种!只要满足 JVM 规范,每个公司、组织或者个人都可以开发自己的专属 JVM。 也就是说我们平时接触到的 HotSpot VM 仅仅是是 JVM 规范的一种实现而已。
好处:
- 一次编写,到处运行
- 自动内存管理,垃圾回收功能
- 数组下标越界检查
- 多态
jvm、jre、jdk比较
我们先看这张图:
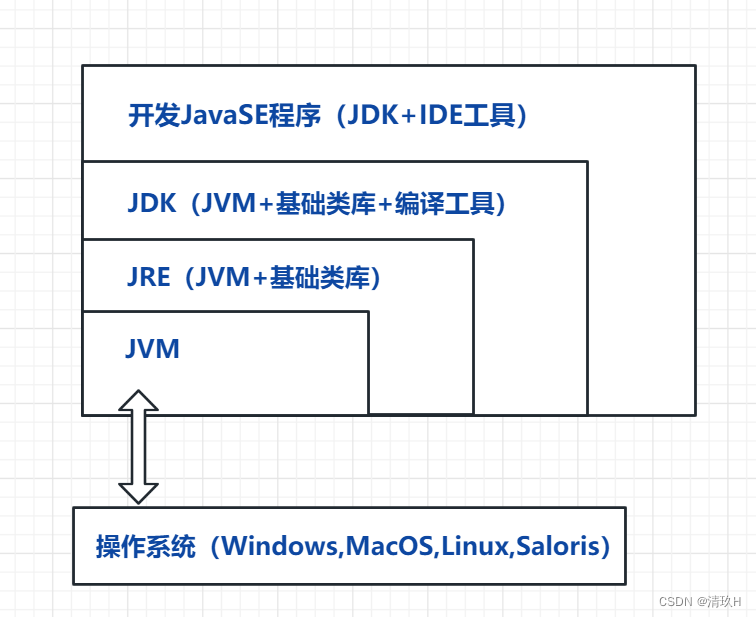
JRE 是 Java 运行时环境。它是运行已编译 Java 程序所需的所有内容的集合,包括 Java 虚拟机(JVM),Java 类库,java 命令和其他的一些基础构件。但是,它不能用于创建新程序。
JDK 是 Java Development Kit 缩写,它是功能齐全的 Java SDK。它拥有 JRE 所拥有的一切,还有编译器(javac)和工具(如 javadoc 和 jdb)。它能够创建和编译程序。
这里大概介绍了三者的区别以及关系,下面具体来看看jvm的原理
内存结构
程序计数器(Program Counter Register)
定义
Program Counter Register 程序计数器(寄存器)
- 作用,是记住下一条jvm指令的执行地址
- 特点
- 是线程私有的
每个线程都有自己的程序计数器,随着线程创建而创建,随着线程销毁而销毁 - 不会存在内存溢出
- 是线程私有的
作用

java虚拟机跨平台的基础就是这套jvm指令,对所有平台都是一致的,这套指令不能直接交给CPU来执行,需要交给解释器,经过解释器解释称为机器码,然后才能把机器码交给CPU来执行
拿到第一条0地址指令时交给解释器,解释器把它变成机器码,然后交给CPU执行,与此同时,会把下一条指令的地址3放入程序计数器,第一天指令执行完以后,解释器到程序计数器中找到下一条指令的地址
虚拟机栈(Java Virtual Machine Stacks)
概述
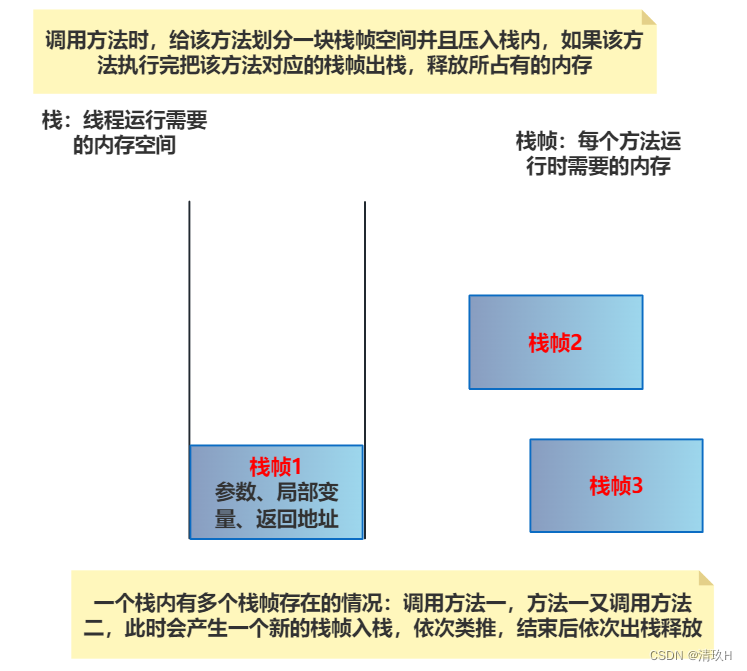
Java Virtual Machine Stacks (Java 虚拟机栈)
- 每个线程运行时所需要的内存,称为虚拟机栈
- 每个栈由多个栈帧(Frame)组成,对应着每次方法调用时所占用的内存
- 每个线程只能有一个活动栈帧,对应着当前正在执行的那个方法
代表当前线程正在执行的方法对应的栈帧
垃圾回收是否涉及栈内存
答案是否,因为栈内存就是一次次的方法调用产生的栈帧内存,栈帧内存在每次方法结束后都会弹出栈,会被自动回收掉
栈内存分配越大越好吗
栈内存变大会让线程数减少,因为物理内存大小一定
方法内的局部变量是否线程安全
- 如果方法内局部变量没有逃离方法的作用访问,它是线程安全的
- 如果是局部变量引用了对象,并逃离方法的作用范围,需要考虑线程安全
怎么理解呢,接下来看两个例子:
static void m1(){
int x = 0;
for (int i = 0; i < 5000; i++) {
x++;
}
System.out.println(x);
}
以这段代码为例,一个线程对应一个栈帧,对应一个栈,线程内每一次方法调用都会产生新的栈帧,每个线程都有自己私有的局部变量x,互不干扰,因此不会产生线程安全问题
但是如果该变量是static时,就会产生线程安全问题
//是线程安全,和上面那个例子相似
public static void m1(){
StringBuilder sb = new StringBuilder();
sb.append(1);
sb.append(2);
sb.append(3);
System.out.println(sb.toString());
}
//不安全,sb对象是作为方法的参数传进来,有可能有其他的线程能访问到它,对多个线程是共享的
public static void m2(StringBuilder sb){
sb.append(1);
sb.append(2);
sb.append(3);
System.out.println(sb.toString());
}
//不安全,把对象返回了,意味着其他线程可以拿到这个对象操作
public static StringBuilder m3(){
StringBuilder sb = new StringBuilder();
sb.append(1);
sb.append(2);
sb.append(3);
return sb;
}
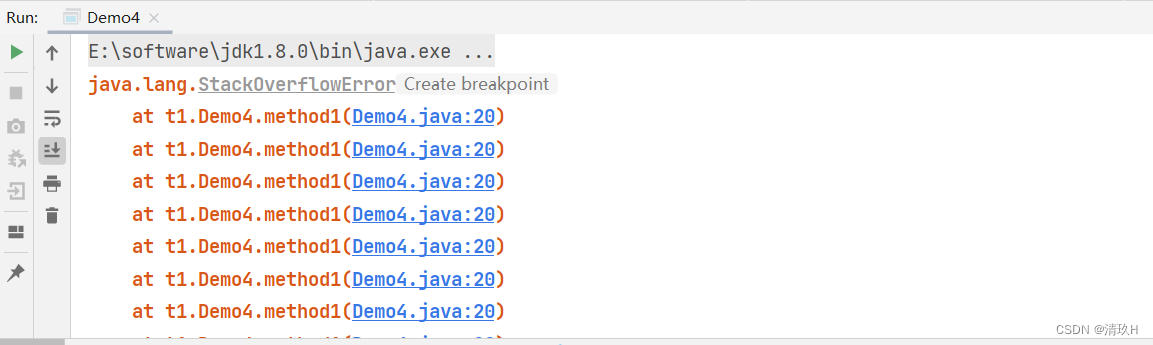
栈内存溢出
- 栈帧过多导致栈内存溢出
- 栈帧过大导致栈内存溢出
/**
* 演示栈内存溢出 java.lang.StackOverflowError
*/
public class Demo4 {
private static int count;
public static void main(String[] args){
try {
method1();
}catch (Throwable e){
e.printStackTrace();
System.out.println(count);
}
}
private static void method1(){
count++;
method1();
}
}
/**
* json 数据转换
*/
public class Demo5 {
public static void main(String[] args) throws JsonProcessingException {
Dept d = new Dept();
d.setName("Market");
Emp e1 = new Emp();
e1.setName("zhang");
e1.setDept(d);
Emp e2 = new Emp();
e2.setName("li");
e2.setDept(d);
d.setEmps(Arrays.asList(e1, e2));
/**
* {
* name: 'Market',
* emps: [
* { name:'zhang',
* dept:{ name:'',
* emps: [ {}]
* }
* },
* ]
* }
* 会无限循环
*/
ObjectMapper mapper = new ObjectMapper();
System.out.println(mapper.writeValueAsString(d));
}
}
class Emp {
private String name;
//@JsonIgnore
private Dept dept;
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public Dept getDept() {
return dept;
}
public void setDept(Dept dept) {
this.dept = dept;
}
}
class Dept {
private String name;
private List<Emp> emps;
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public List<Emp> getEmps() {
return emps;
}
public void setEmps(List<Emp> emps) {
this.emps = emps;
}
}
此时运行会出现错误

这是由于两个类之间的循环引用,导致json解析是一直循环,加上@JsonIgnore注解后进行中断
线程运行诊断案例
案例一:cpu占用过多
定位
- 用top定位哪个进程对cpu的占用过高
- ps H -eo pid,tid,%cpu | grep 进程id (用ps命令进一步定位是哪个线程引起的cpu占用过高)
- jstack 进程id
- 可以根据线程id 找到有问题的线程,进一步定位到问题代码的源码行号
案例二:程序运行很长时间没有结果
还是用jstack命令
本地方法栈
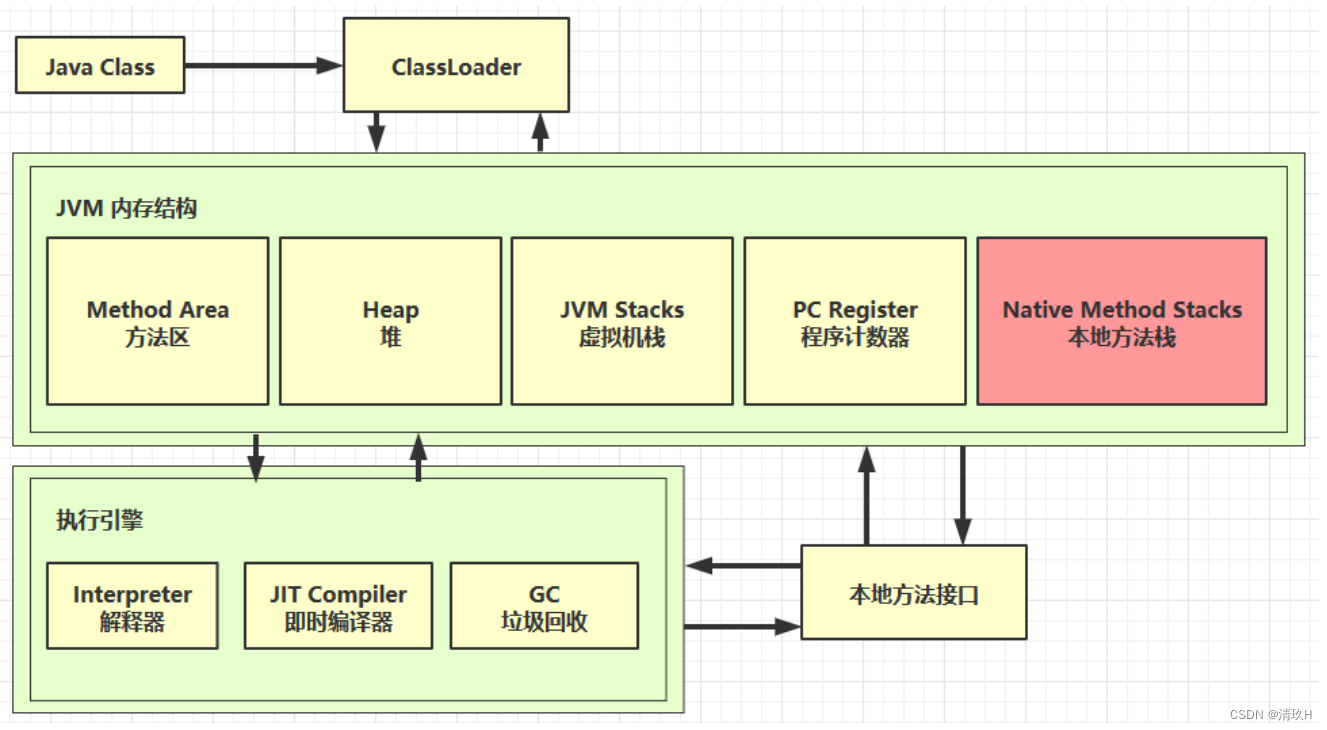
本地方法:指不是由java代码编写的方法,java代码有时候不能直接和操作系统底层打交道,需要一些用c/c++编写的本地方法,java代码可以间接通过本地方法来调用底层功能,这些本地方法运行的时候使用的就是本地方法栈

堆(Heap)
Heap 堆
- 通过 new 关键字,创建对象都会使用堆内存
特点
- 它是线程共享的,堆中对象都需要考虑线程安全的问题
- 有垃圾回收机制
堆内存溢出
/**
* 演示堆内存溢出 java.lang.OutOfMemoryError: Java heap space
*/
public class Demo6 {
public static void main(String[] args) {
int i = 0;
try {
List<String> list = new ArrayList<>();
String a = "hello";
while (true){
list.add(a);
a = a + a;
i++;
}
}catch (Throwable e){
e.printStackTrace();
System.out.println(i);
}
}
}

堆内存诊断
- jps 工具
查看当前系统中有哪些 java 进程 - jmap 工具
查看堆内存占用情况 jmap - heap 进程id - jconsole 工具
图形界面的,多功能的监测工具,可以连续监测
测试代码
public class Demo7 {
public static void main(String[] args) throws InterruptedException {
System.out.println("1..."); //创建对象之前
Thread.sleep(30000);
byte[] array = new byte[1024 * 1024 * 10]; //创建对象 10MB
System.out.println("2..."); //创建对象后
Thread.sleep(30000);
array = null;
System.gc();
System.out.println("3..."); //垃圾回收后
Thread.sleep(30000);
}
}
查看进程id

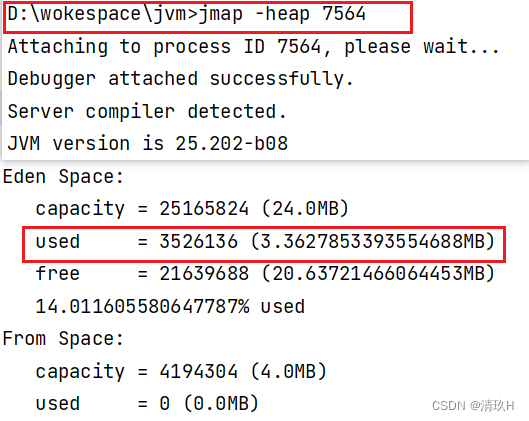
程序打印出1… 时执行,查看创建对象之前使用的堆内存
程序打印出2… 时执行,查看创建对象之后使用的堆内存
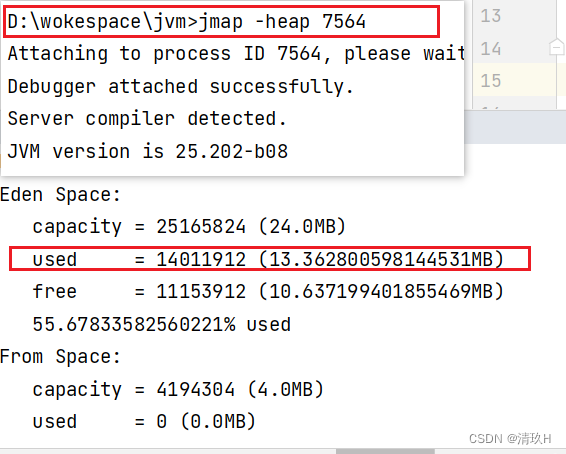
可见多了10MB左右
程序打印出3… 时执行,查看垃圾回收之后使用的堆内存
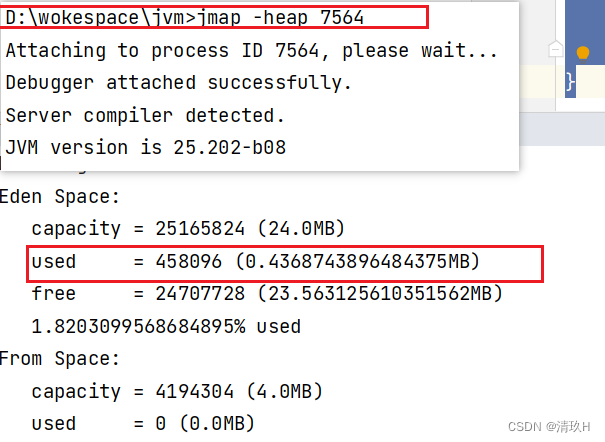
jconsole 工具
运行程序后,在控制台输入jconsole会弹出一个可视化窗口,里面可检测到变化
jvisualvm 工具
运行程序后,在控制台输入jconsole会弹出一个可视化窗口,里面可检测到变化
案例:垃圾回收后,内存占用仍然很高
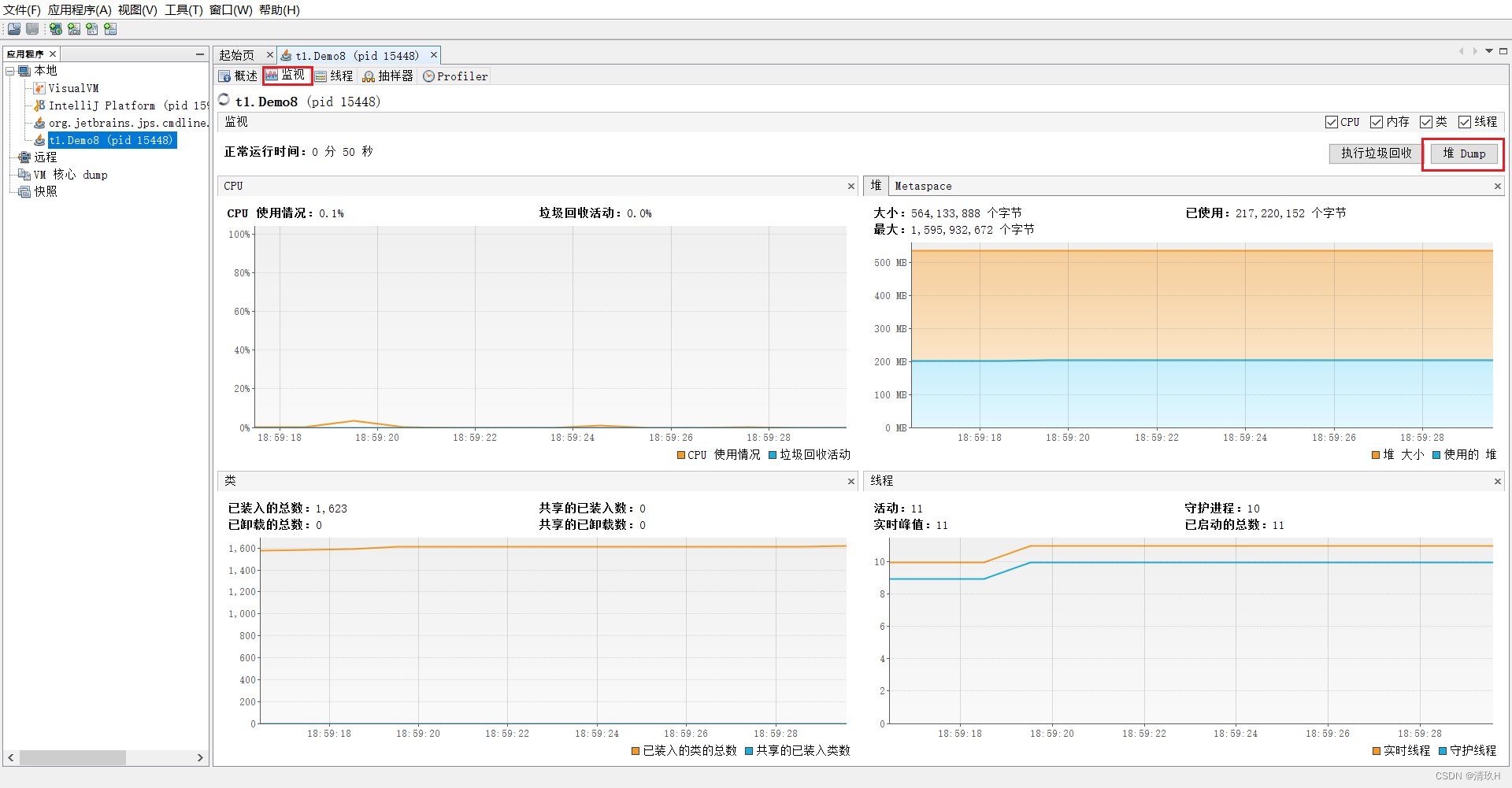
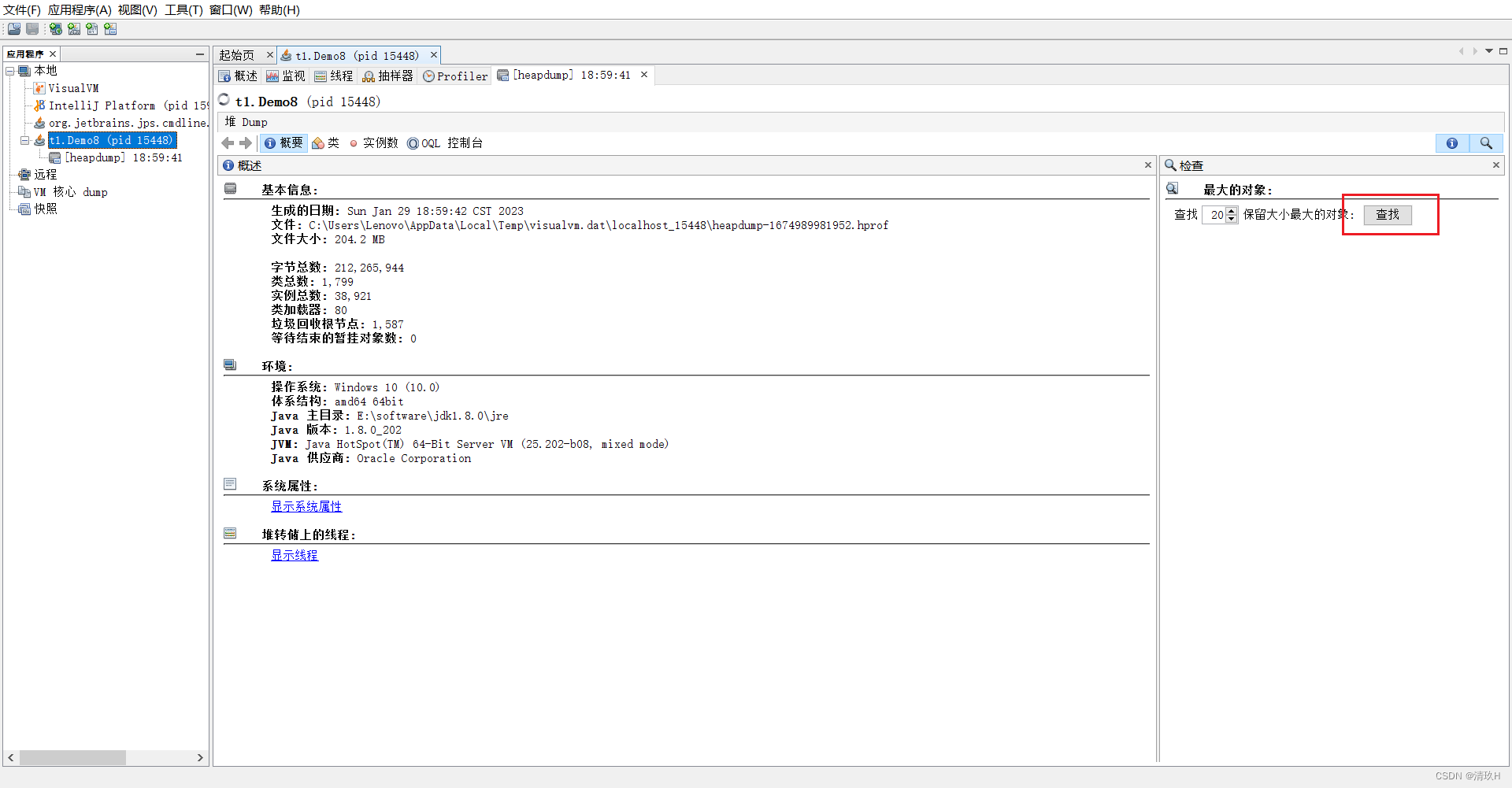
这样就可以查看占用内存的原因
方法区
方法区属于是 JVM 运行时数据区域的一块逻辑区域,是各个线程共享的内存区域。
《Java 虚拟机规范》只是规定了有方法区这么个概念和它的作用,方法区到底要如何实现那就是虚拟机自己要考虑的事情了。也就是说,在不同的虚拟机实现上,方法区的实现是不同的。
当虚拟机要使用一个类时,它需要读取并解析 Class 文件获取相关信息,再将信息存入到方法区。方法区会存储已被虚拟机加载的类信息、字段信息、方法信息、常量、静态变量、即时编译器编译后的代码缓存等数据。
方法区和永久代以及元空间是什么关系呢? 方法区和永久代以及元空间的关系很像 Java 中接口和类的关系,类实现了接口,这里的类就可以看作是永久代和元空间,接口可以看作是方法区,也就是说永久代以及元空间是 HotSpot 虚拟机对虚拟机规范中方法区的两种实现方式。并且,永久代是 JDK 1.8 之前的方法区实现,JDK 1.8 及以后方法区的实现变成了元空间。
JDK1.8以前组成
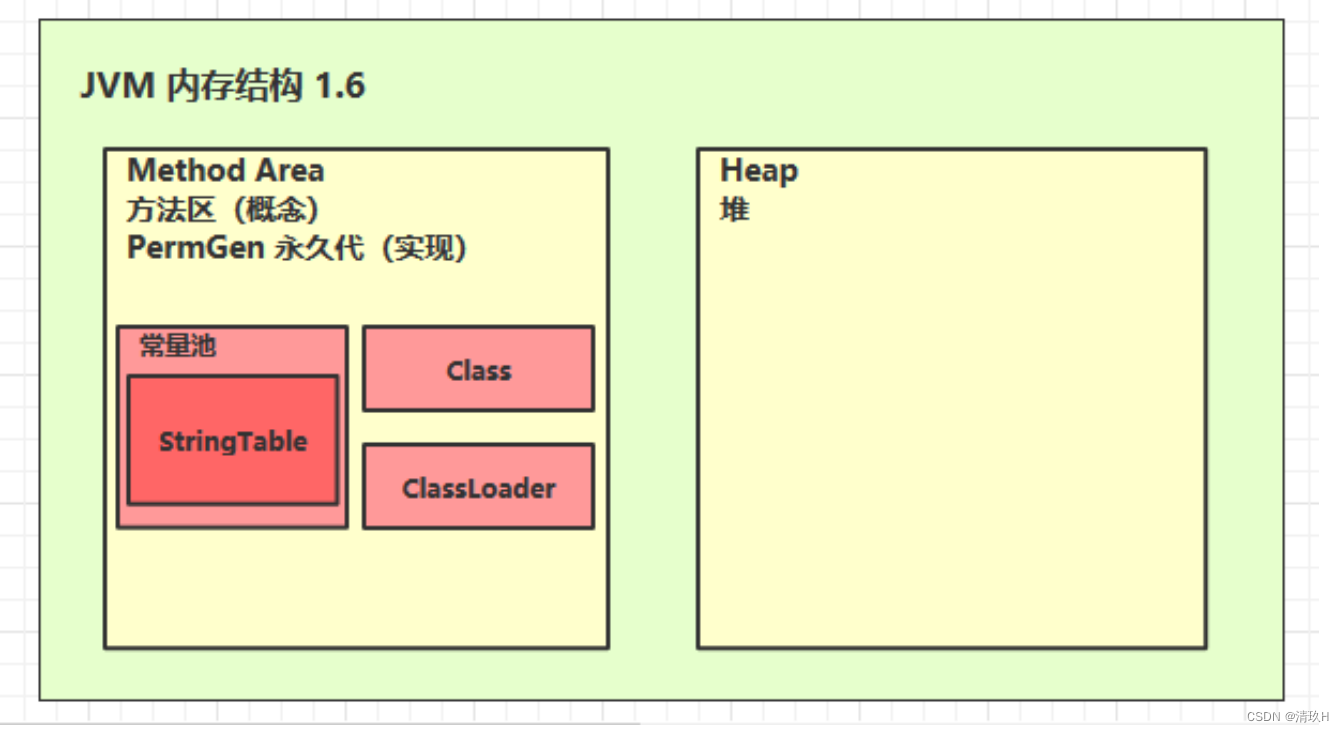
JDK1.8组成
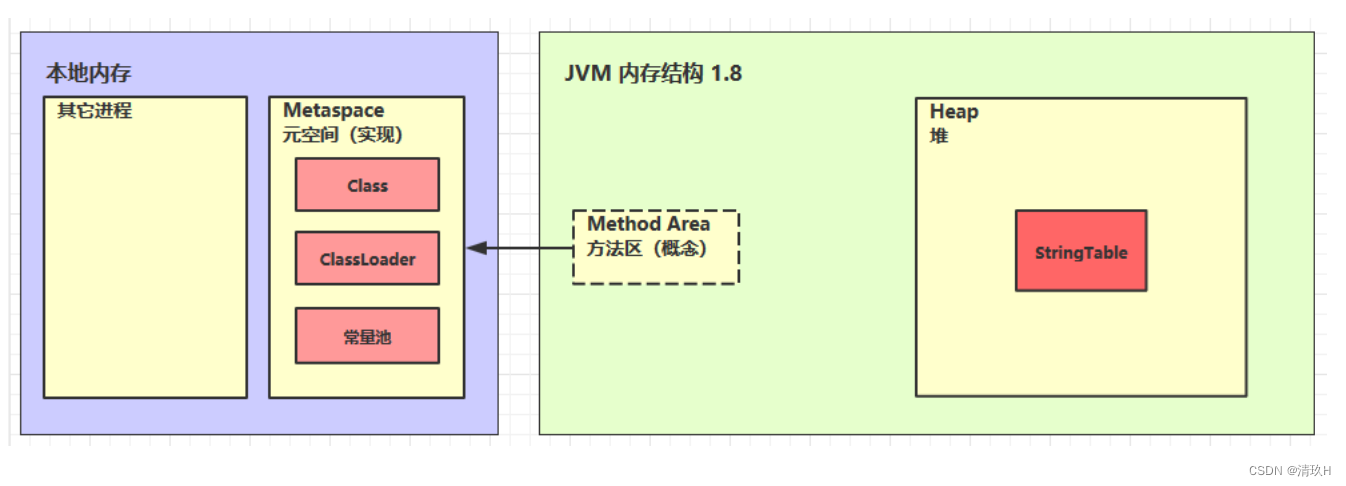
方法区内存溢出
测试代码
/**
* 演示元空间内存溢出 java.lang.OutOfMemoryError: Metaspace
* 设置虚拟机参数:VM -XX:MaxMetaspaceSize=8m
*/
public class Demo9 extends ClassLoader { // 可以用来加载类的二进制字节码
public static void main(String[] args) {
int j = 0;
try {
Demo9 test = new Demo9();
for (int i = 0; i < 10000; i++, j++) {
// ClassWriter 作用是生成类的二进制字节码
ClassWriter cw = new ClassWriter(0);
// 版本号, public, 类名, 包名, 父类, 接口
cw.visit(Opcodes.V1_8, Opcodes.ACC_PUBLIC, "Class" + i, null, "java/lang/Object", null);
// 返回 byte[]
byte[] code = cw.toByteArray();
// 执行了类的加载
test.defineClass("Class" + i, code, 0, code.length); // Class 对象
}
} finally {
System.out.println(j);
}
}
}

场景:
在Spring和MyBatis等等的一些框架中都用到了字节码技术,用到cglib技术,Spring用它生成代理类,MyBatis用它产生Mapper接口的是实现类
所以实际情况中,我们在用到这些框架时,在运行期间生成的类还是很容易导致永久代的内存溢出的,在1.8以后,元空间使用的是系统内存,相对的充裕了很多
常量池
我们先来通过一个测试大概了解常量池的作用
//二进制字节码(类基本信息、常量池、类方法定义(包含了虚拟机指令))
public class Demo10 {
public static void main(String[] args) {
System.out.println("hello world");
}
}
运行代码会生成一个字节码文件,我们通过反编译这个字节码文件来看看里面的内容
进入字节码文件的目录中运行此命令
第一部分就是类的基本信息
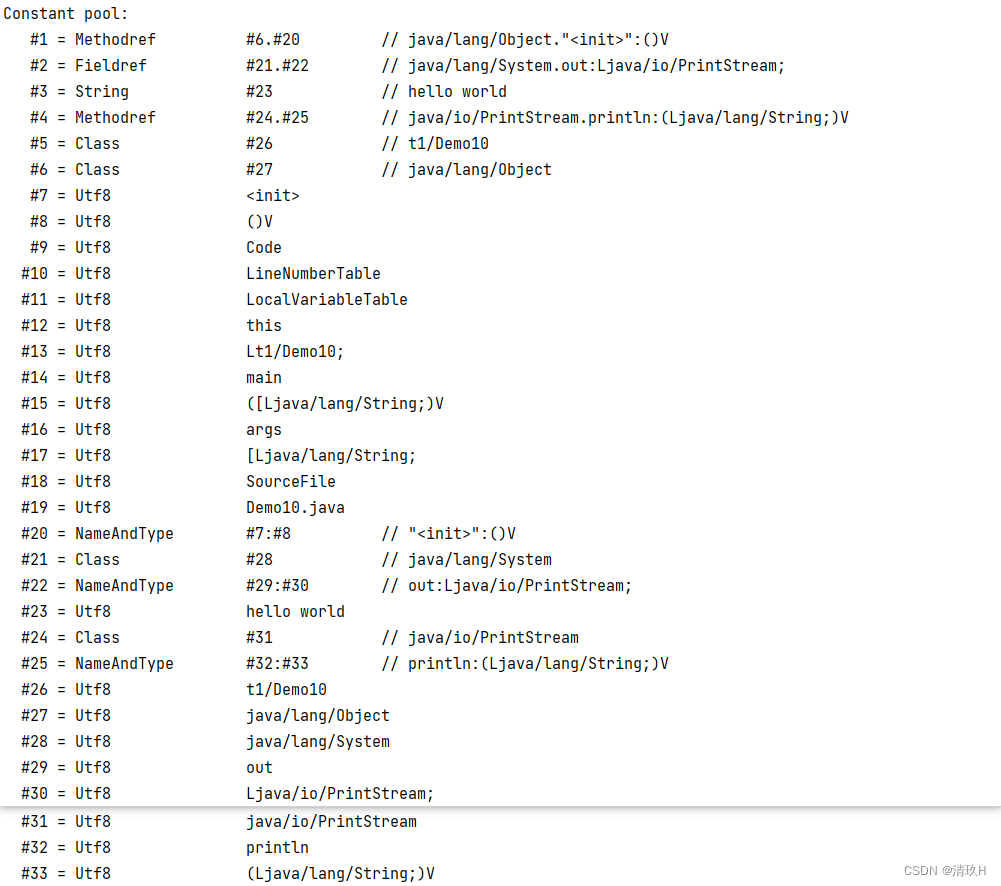
然后基本信息下面是类的常量池
目前可能看不明白,下面介绍完组成后会具体介绍执行流程中常量池发挥的作用
然后常量池下面就是类方法定义
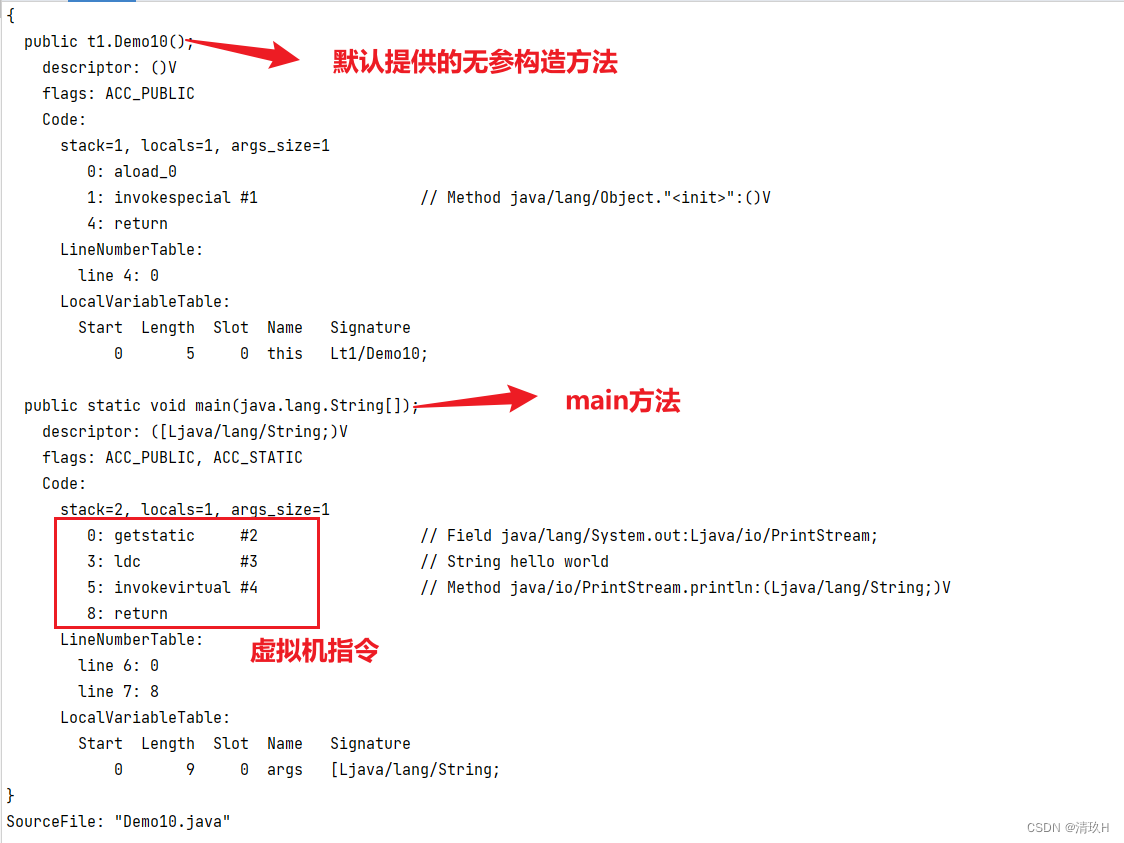
接下来我们来看具体的执行流程
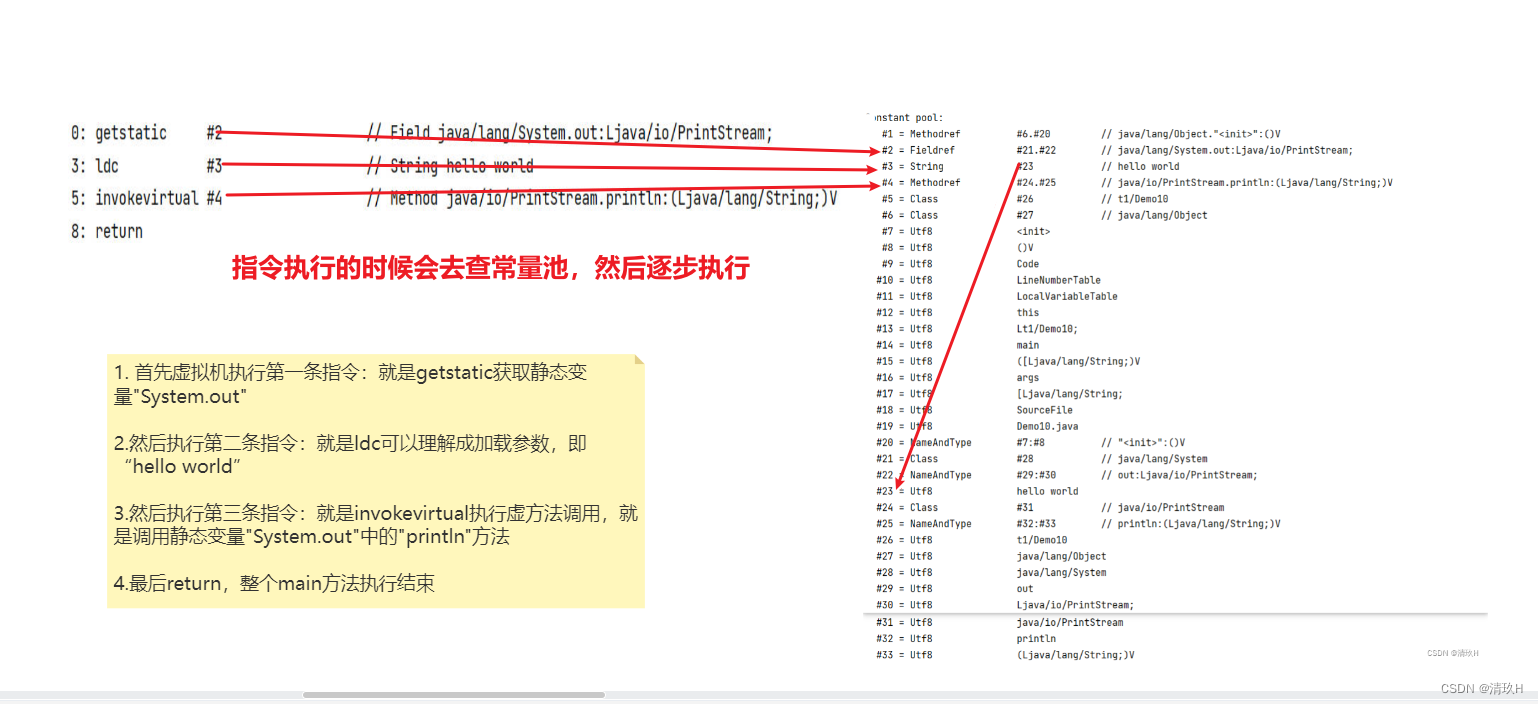
至此,我们就已经大概了解到了常量池的作用了
运行时常量池
- 常量池,就是一张表,虚拟机指令根据这张常量表找到要执行的类名、方法名、参数类型、字面量
等信息 - 运行时常量池,常量池是 *.class 文件中的,当该类被加载,它的常量池信息就会放入运行时常量
池,并把里面的符号地址变为真实地址
当运行时就要放在内存,放在内存中的位置就是运行时常量池
StringTable_常量池与串池的关系
//串池StringTable[ ] (哈希表,长度固定并不能扩容)
public class Demo11 {
//常量池中的信息,都会被加载到运行时常量池中,这时,a b ab 都是常量池中的符号
//还没有变为 java 中的字符串对象
//ldc #2 会把 a 符号变为 "a" 字符串对象,会把它作为 key 到 StringTable中找看有没有取值相同的 key
//没有,会把该对象放入串池
//StringTable[ "a" ]
//ldc #3 会把 b 符号变为 "b" 字符串对象,会把它作为 key 到 StringTable中找看有没有取值相同的 key
//没有,会把该对象放入串池
//StringTable[ "a","b" ]
//ldc #4 会把 ab 符号变为 "ab" 字符串对象,会把它作为 key 到 StringTable中找看有没有取值相同的 key
//没有,会把该对象放入串池
//StringTable[ "a","b","ab" ]
public static void main(String[] args) {
String s1 = "a"; //用到的时候才会开始创建,懒惰的
String s2 = "b";
String s3 = "ab";
}
}

StringTable_字符串变量拼接
String s1 = "a";
String s2 = "b";
String s3 = "ab";
String s4 = s1 + s2; //new StringBuilder()
System.out.println(s3 == s4); //false s3在串池中,s4在堆中
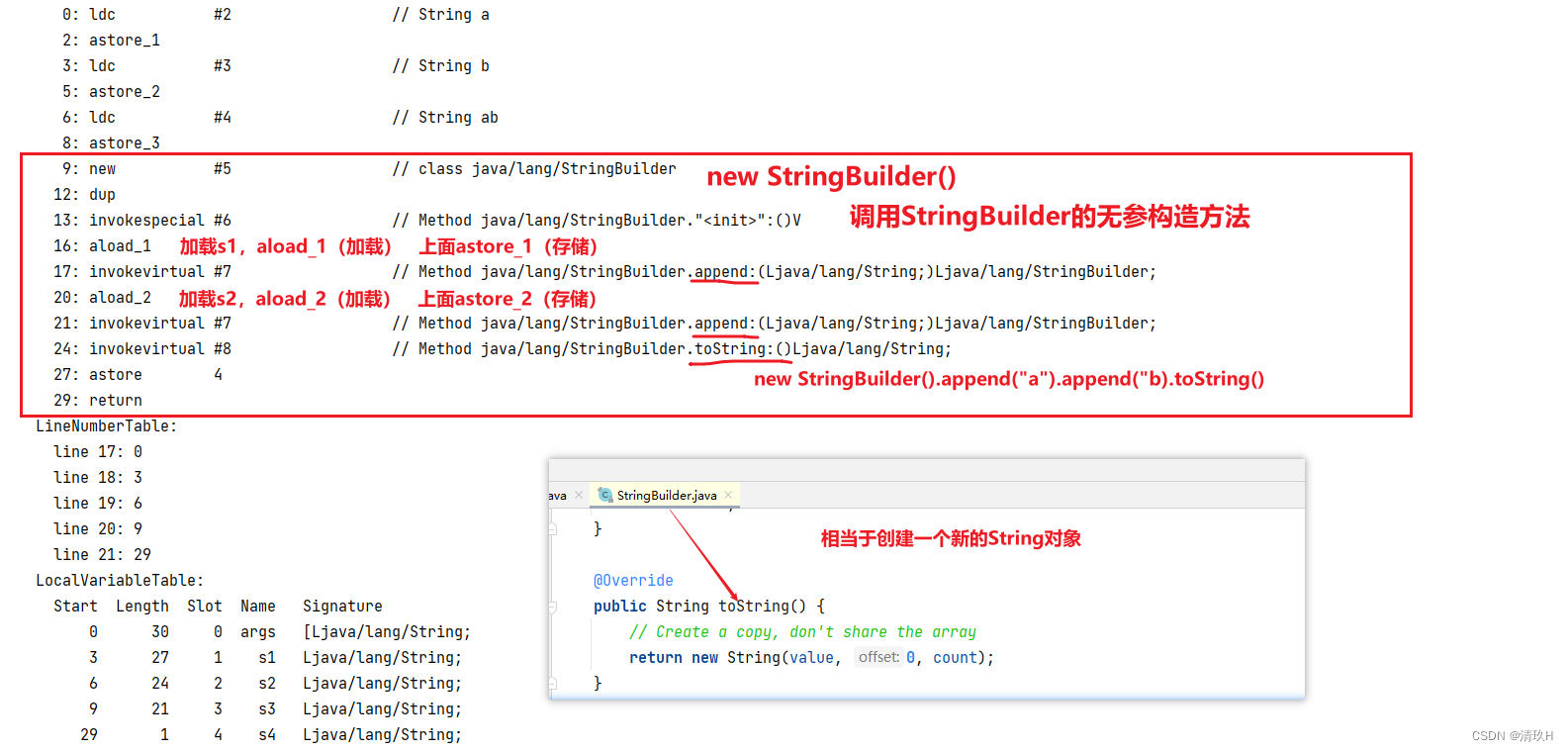
StringTable_编译器优化
String s1 = "a";
String s2 = "b";
String s3 = "ab";
String s4 = s1 + s2; //new StringBuilder()
//System.out.println(s3 == s4);
String s5 = "a" + "b";
System.out.println(s3 == s5); //true

这实际上是javac 在编译时的优化,“a” 和 “b” 都是常量,内容不会变了,所以拼接的结果是确定的,既然是确定的,在编译期间就能知道结果肯定就是 “ab” 了,不可能是别的值,与上不同的是,s1 和s2是变量
StringTable_字符串延迟加载
/**
* 演示字符串字面量也是【延迟】成为对象的
*/
public class Demo12 {
public static void main(String[] args) {
int x = args.length;
System.out.println(); // 字符串个数 2146
System.out.print("1");
System.out.print("2");
System.out.print("3");
System.out.print("4");
System.out.print("5");
System.out.print("6");
System.out.print("7");
System.out.print("8");
System.out.print("9");
System.out.print("0");
System.out.print("1"); // 字符串个数 2146
System.out.print("2");
System.out.print("3");
System.out.print("4");
System.out.print("5");
System.out.print("6");
System.out.print("7");
System.out.print("8");
System.out.print("9");
System.out.print("0");
System.out.print(x); // 字符串个数 2146
}
}
此时的字符串数量为2146
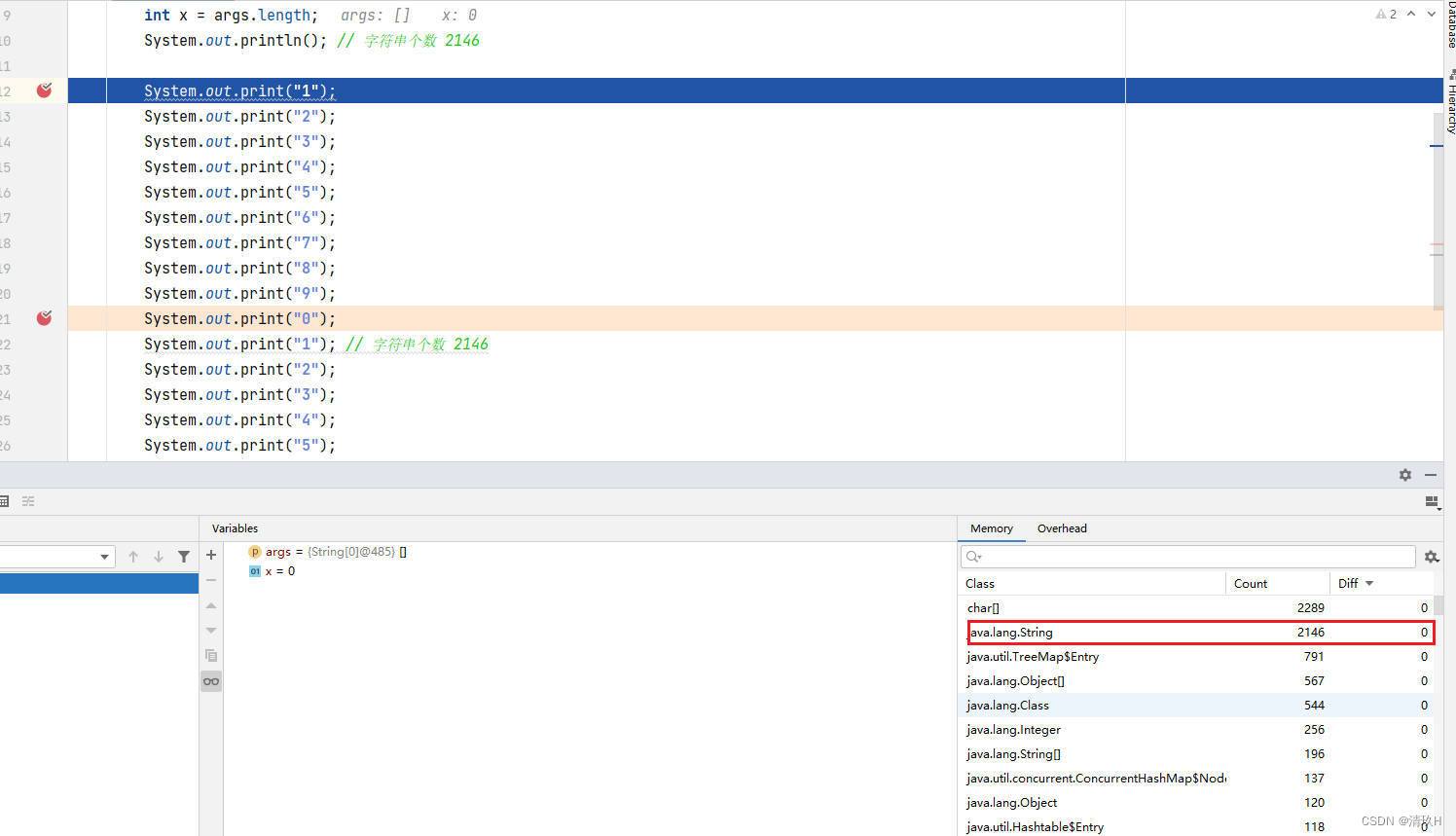
接下来每走一步,该数值就会加一
此时的字符串数量为2156
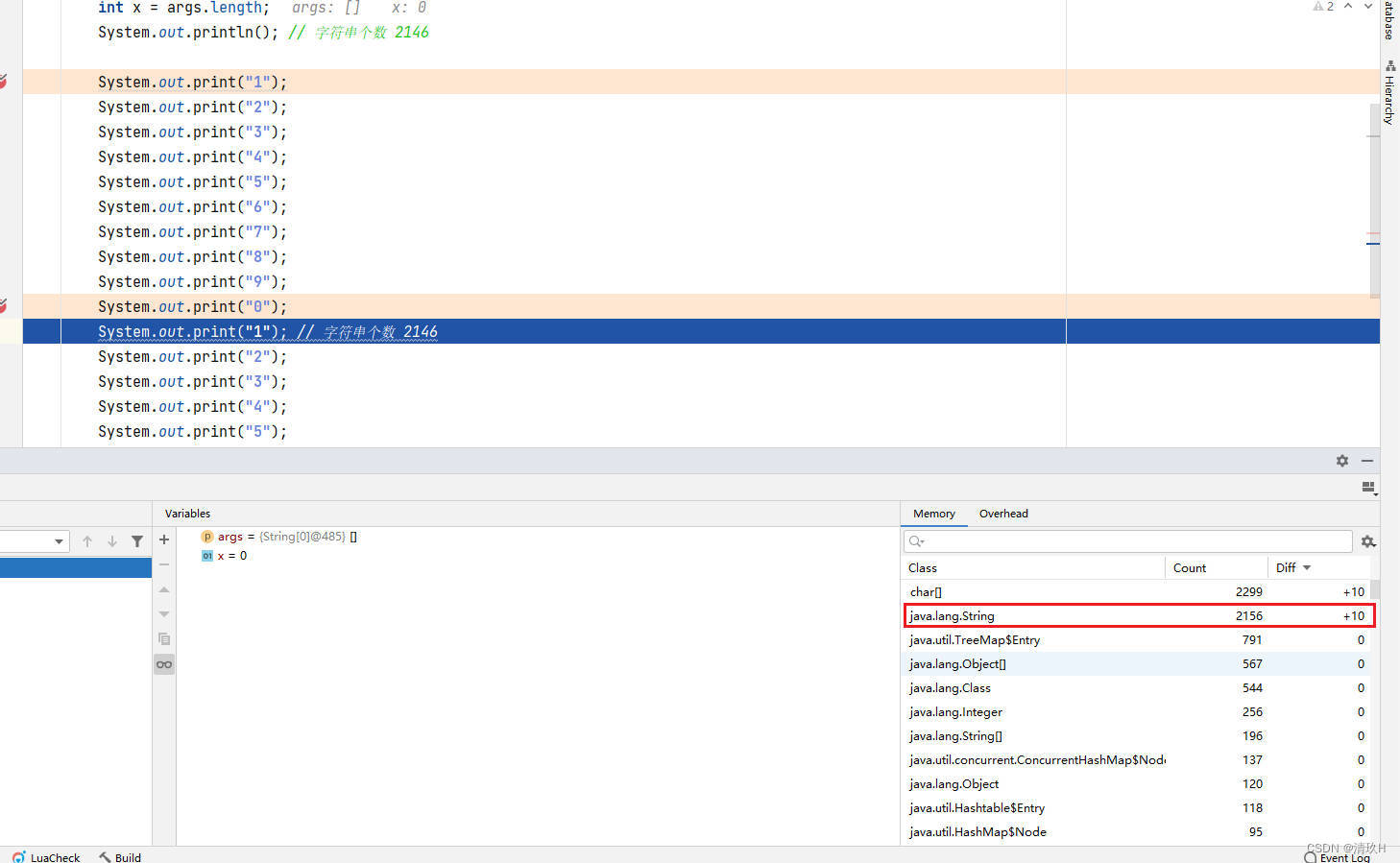
再往后走则不会有变化
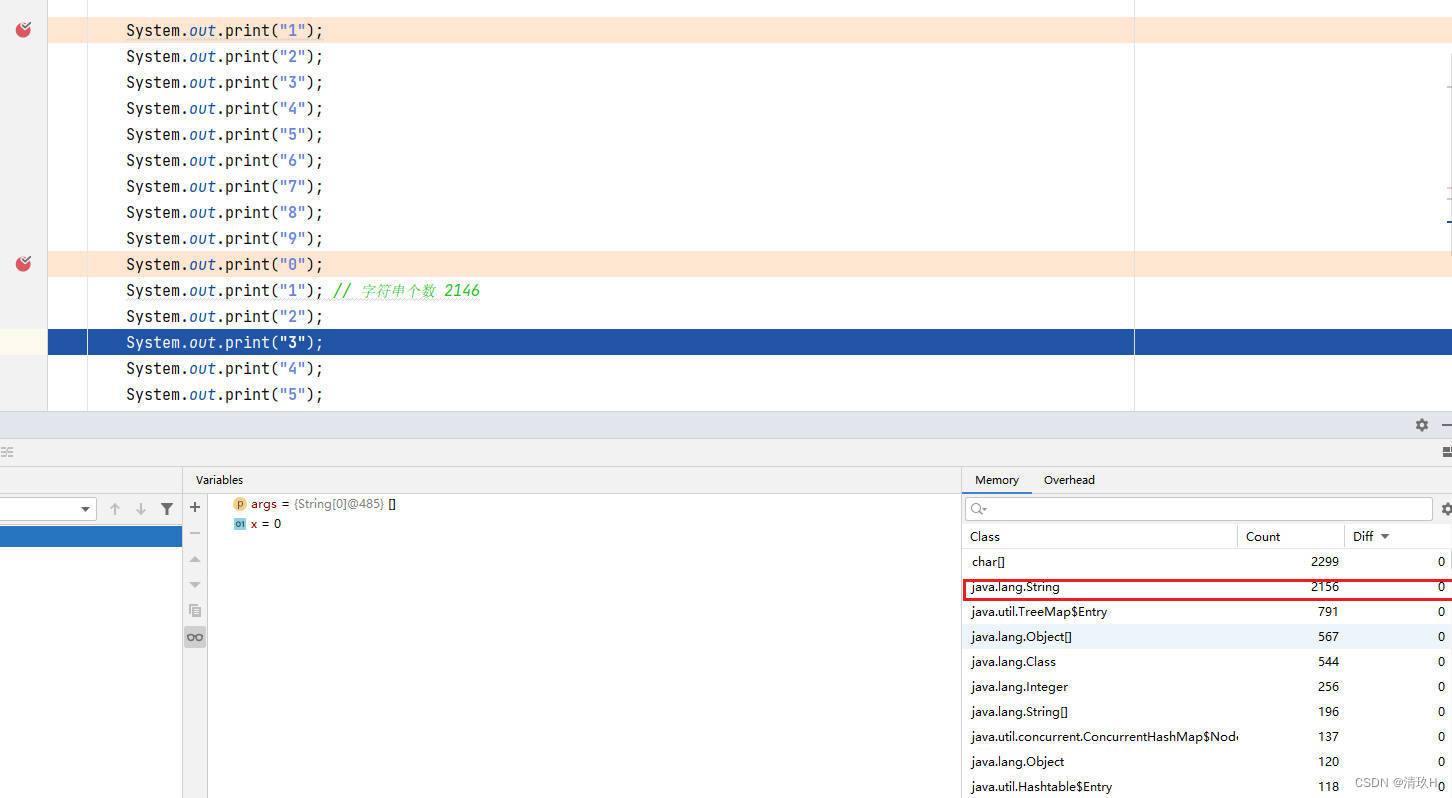
因为这几个字符串对象在串池中就已经存在了
StringTable_intern
public static void main(String[] args) {
String s = new String("a") + new String("b"); //new String("ab")
//堆 new String("a") new String("b") new String("ab")
String s2 = s.intern(); //将这个字符串对象尝试放入串池,
//如果有则并不会放入,如果没有则放入串池,会把串池中的对象返回
System.out.println(s2 == "ab"); //true
System.out.println(s == "ab"); //true
}
public static void main(String[] args) {
String x = "ab";
String s = new String("a") + new String("b"); //new String("ab")
//堆 new String("a") new String("b") new String("ab")
String s2 = s.intern(); //将这个字符串对象尝试放入串池,
//如果有则并不会放入,如果没有则放入串池,会把串池中的对象返回
System.out.println(s2 == x); //true
System.out.println(s == x); //false
//此时s并没有放进去,因为串池中的已经存在 "ab",因此x 和 s并不是一个对象
}
StringTable特性
- 常量池中的字符串仅是符号,第一次用到时才变为对象
- 利用串池的机制,来避免重复创建字符串对象
- 字符串变量拼接的原理是 StringBuilder (1.8)
- 字符串常量拼接的原理是编译期优化
- 可以使用 intern 方法,主动将串池中还没有的字符串对象放入串池
- 1.8 将这个字符串对象尝试放入串池,如果有则并不会放入,如果没有则放入串池, 会把串
池中的对象返回 - 1.6 将这个字符串对象尝试放入串池,如果有则并不会放入,如果没有会把此对象复制一份,
放入串池, 会把串池中的对象返回
- 1.8 将这个字符串对象尝试放入串池,如果有则并不会放入,如果没有则放入串池, 会把串
StringTable位置
在JVM1.6的时候StringTable是在常量池,随着常量池存储在永久代中,从1.7开始,把StringTable 转移到了堆中,因为永久代内存的回收效率很低,永久代需要Full GC才会触发垃圾回收,StringTable存着字符串常量,使用很频繁,会占用大量内存,需要回收效率高,因此转移到了堆
StringTable_垃圾回收
演示:
/**
* 演示StringTable垃圾回收
* 设置虚拟机堆内存最大值:-Xmx10m
* 打印字符串表的统计信息:-XX:+PrintStringTableStatistics
* 打印垃圾回收详细信息:-XX:+PrintGCDetails -verbose:gc
*/
public class Demo1 {
public static void main(String[] args) {
int i = 0;
try {
}catch (Throwable e){
e.printStackTrace();
}finally {
System.out.println(i);
}
}
}
运行

此时什么都没做,里面已经有一千多个字符串对象,因为java程序运行时类名、方法名这些数据也是以字符串常量的形式表示的,存在串池当中
public static void main(String[] args) {
int i = 0;
try {
for (int j = 0; j < 10000; j++) {
String.valueOf(j).intern();
i++;
}
}catch (Throwable e){
e.printStackTrace();
}finally {
System.out.println(i);
}
}
执行这段代码时,可以看到下面的结果:
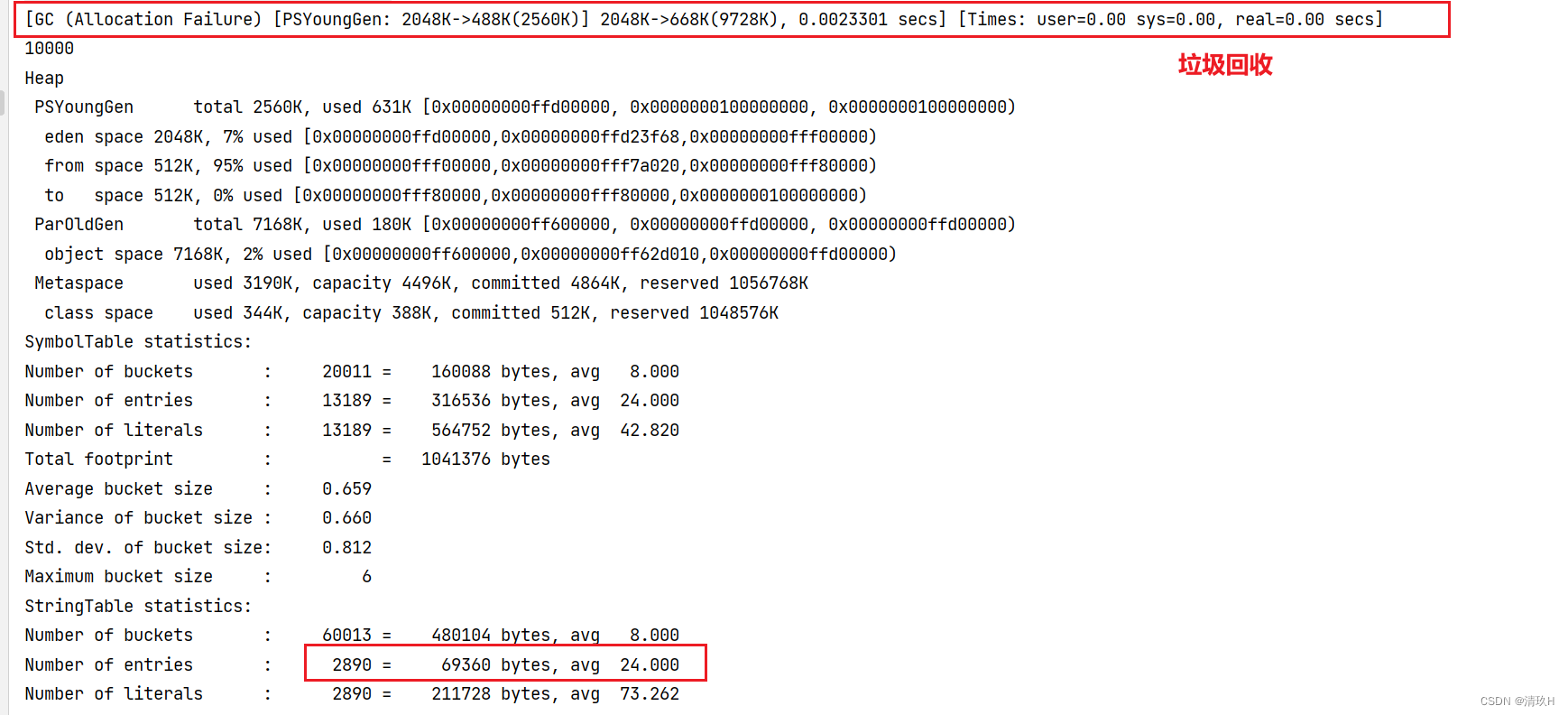
发生了垃圾回收,把一些无用的对象清除掉,StringTable中只是创建了新的字符串,但是没有人用,没有什么list集合去引用,所以无用的就被回收掉了
StringTable性能调优
- 调整虚拟机参数,
-XX:StringTableSize=桶个数 - 考虑将字符串对象是否入池
首先演示第一个
在这里演示一下读取linux.words,是一个单词表,里面大约存储了48万个单词,通过改变串池大小查看读取时间变化
/**
* 演示串池大小对性能的影响
* -Xms500m -Xmx500m -XX:+PrintStringTableStatistics
* 串表其实是哈希表,设置桶的个数:-XX:StringTableSize=20000
*/
public class Demo2 {
public static void main(String[] args) throws IOException {
try (BufferedReader reader = new BufferedReader(new InputStreamReader(new FileInputStream("linux.words"), "utf-8"))) {
String line = null;
long start = System.nanoTime();
while (true) {
line = reader.readLine();
if (line == null) {
break;
}
line.intern();
}
System.out.println("cost:" + (System.nanoTime() - start) / 1000000);
}
}
}
首先配置虚拟机参数
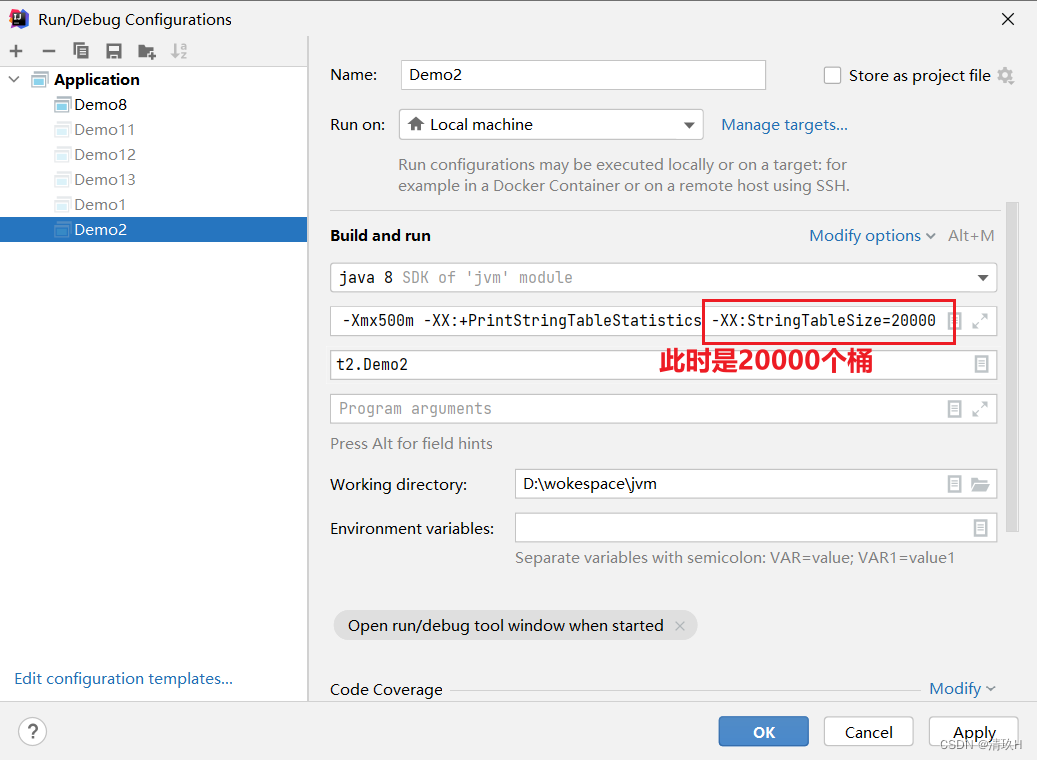
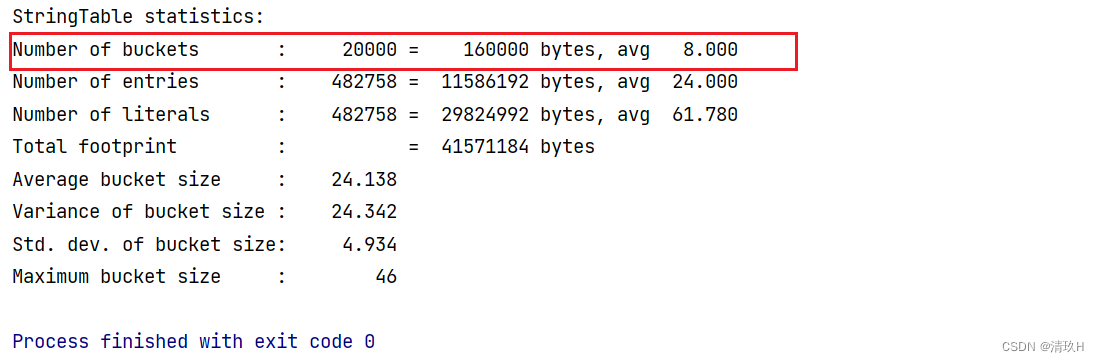
从这里也能看出来
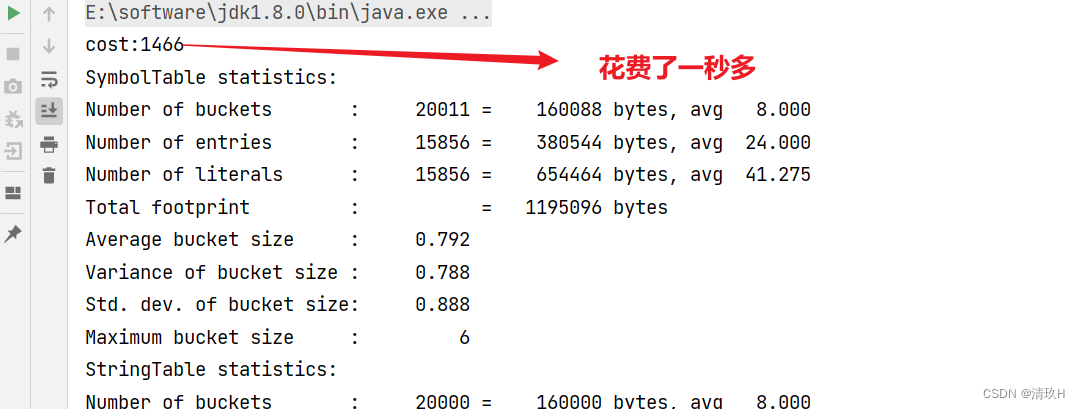
当我们比改变桶大小,使用系统默认的时:
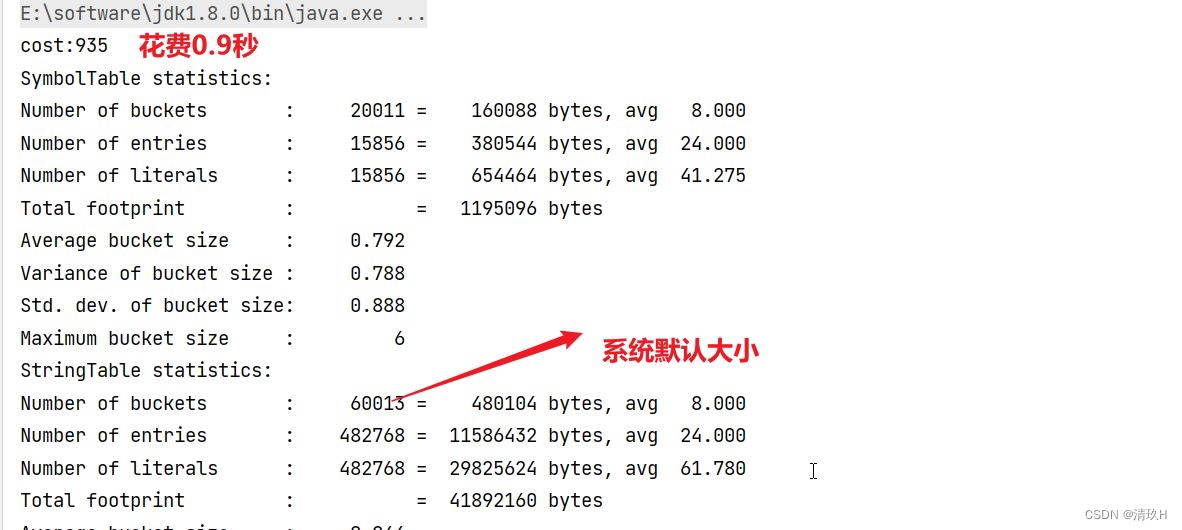
把大小改为2000时:
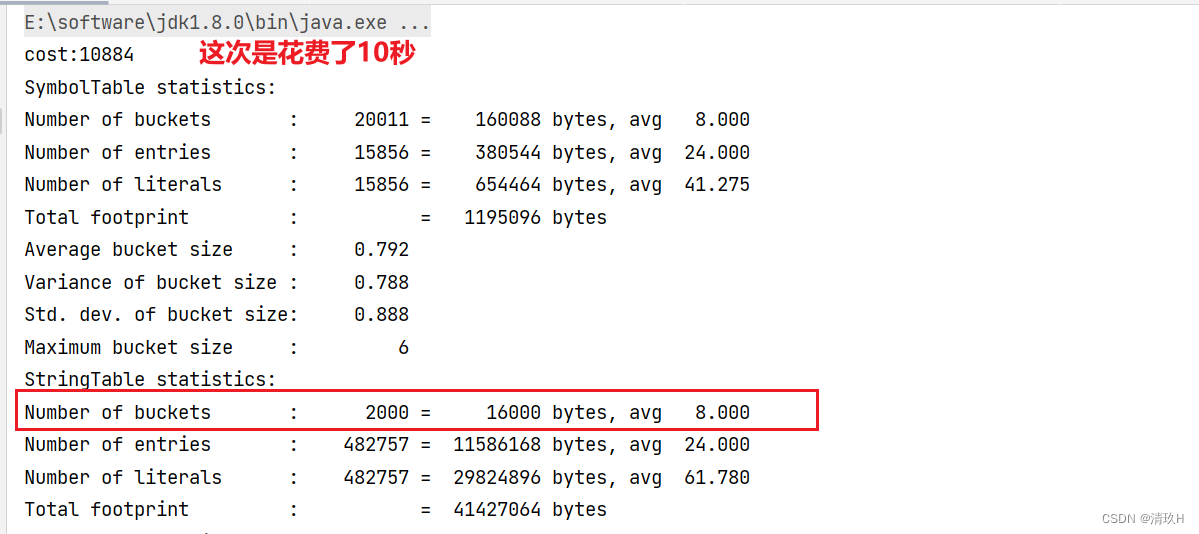
因此,如果系统中字符串常量个数非常多,可以适当把StringTable中桶的个数调的大一些,减少哈希冲突
接下来来演示第二个
public class Demo2 {
public static void main(String[] args) throws IOException {
List<String> list = new ArrayList<>();
System.in.read(); //回车程序可继续运行
for (int i = 0; i < 10; i++) {
try (BufferedReader reader = new BufferedReader(new InputStreamReader(new FileInputStream("linux.words"), "utf-8"))) {
String line = null;
long start = System.nanoTime();
while (true) {
line = reader.readLine();
if (line == null) {
break;
}
list.add(line); //加入list,防止被回收
}
System.out.println("cost:" + (System.nanoTime() - start) / 1000000);
}
}
System.in.read();
}
}
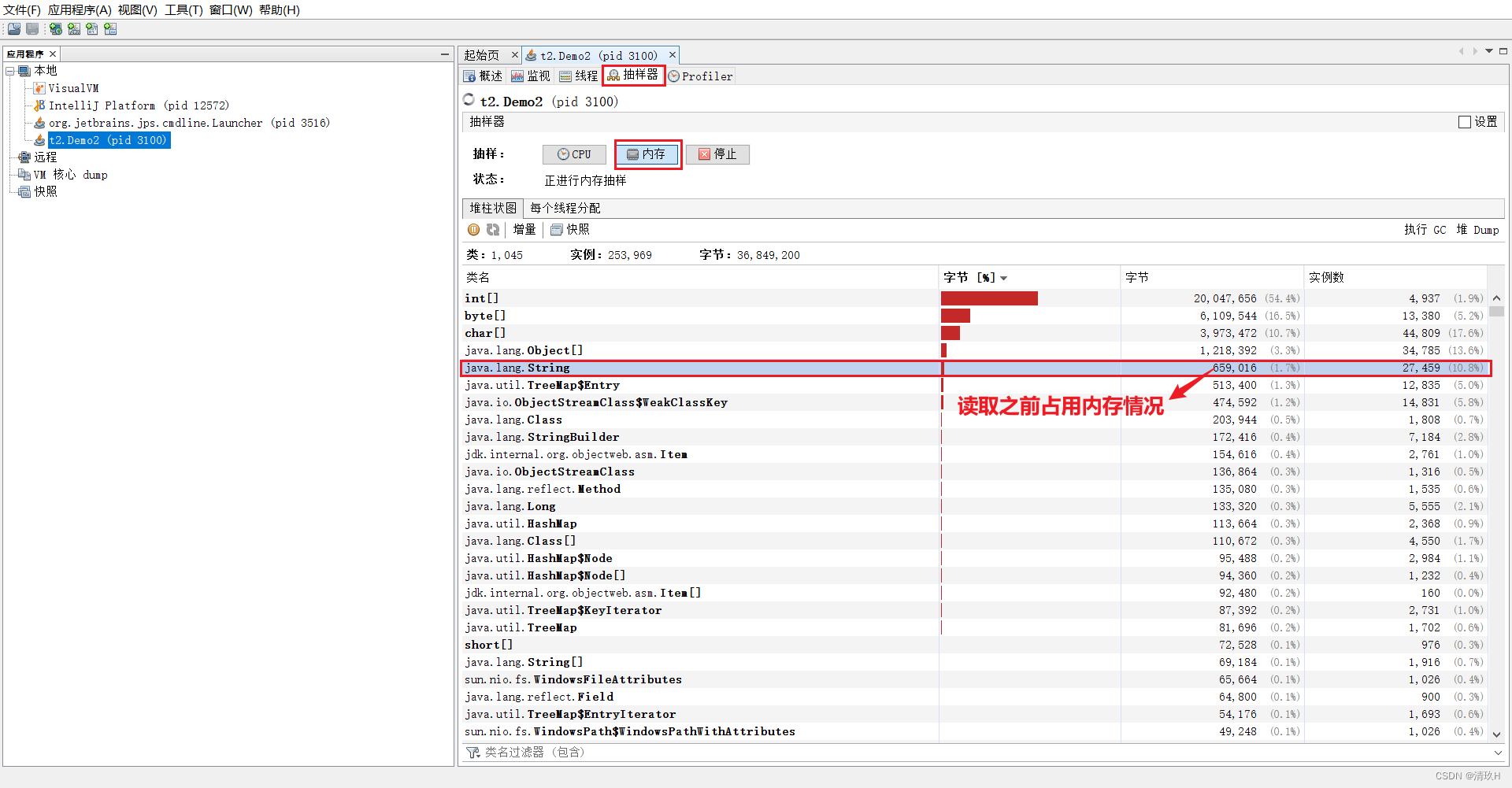
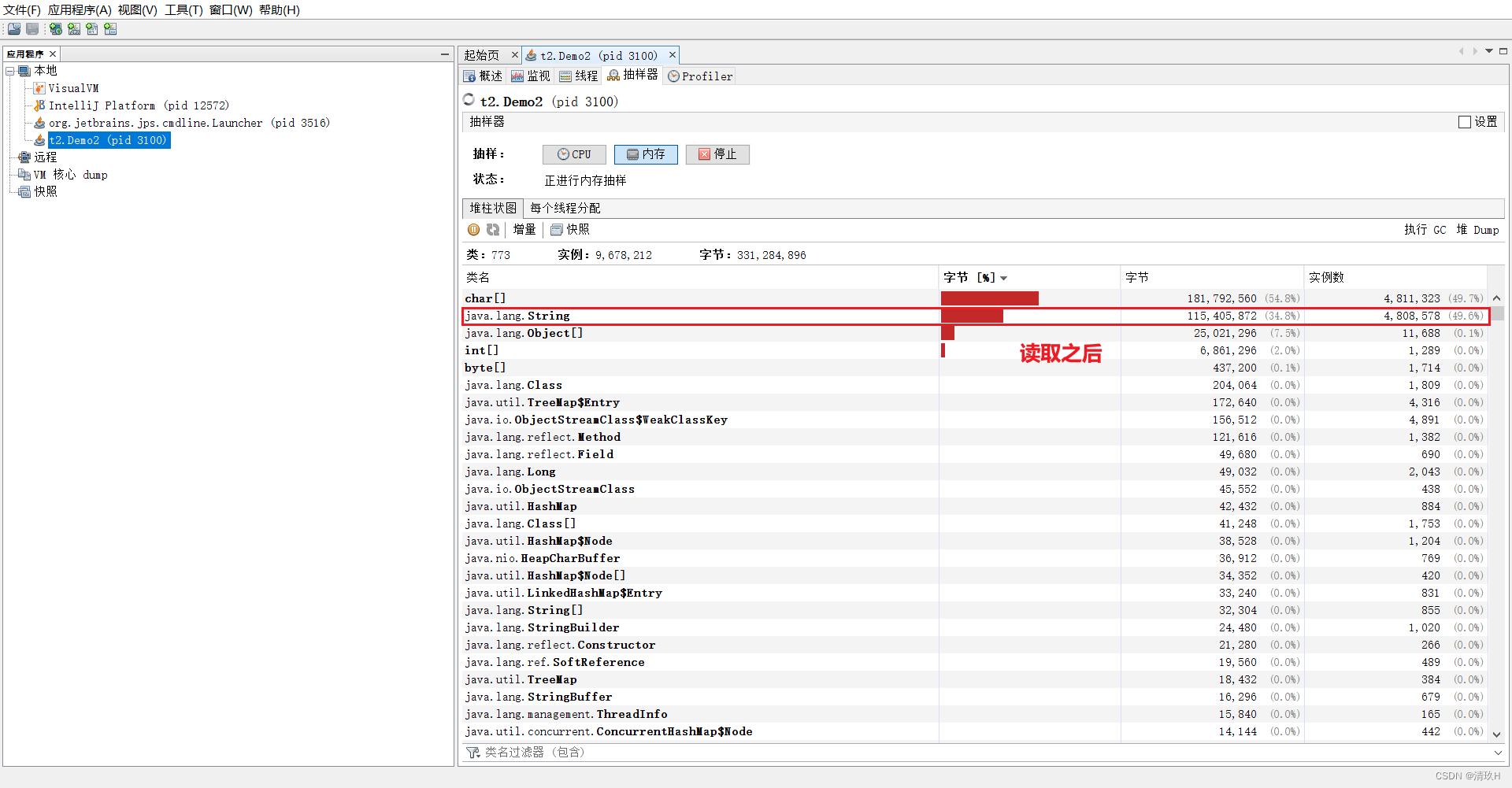
然后让字符串入池再观察
list.add(line.intern()); //加入list,防止被回收
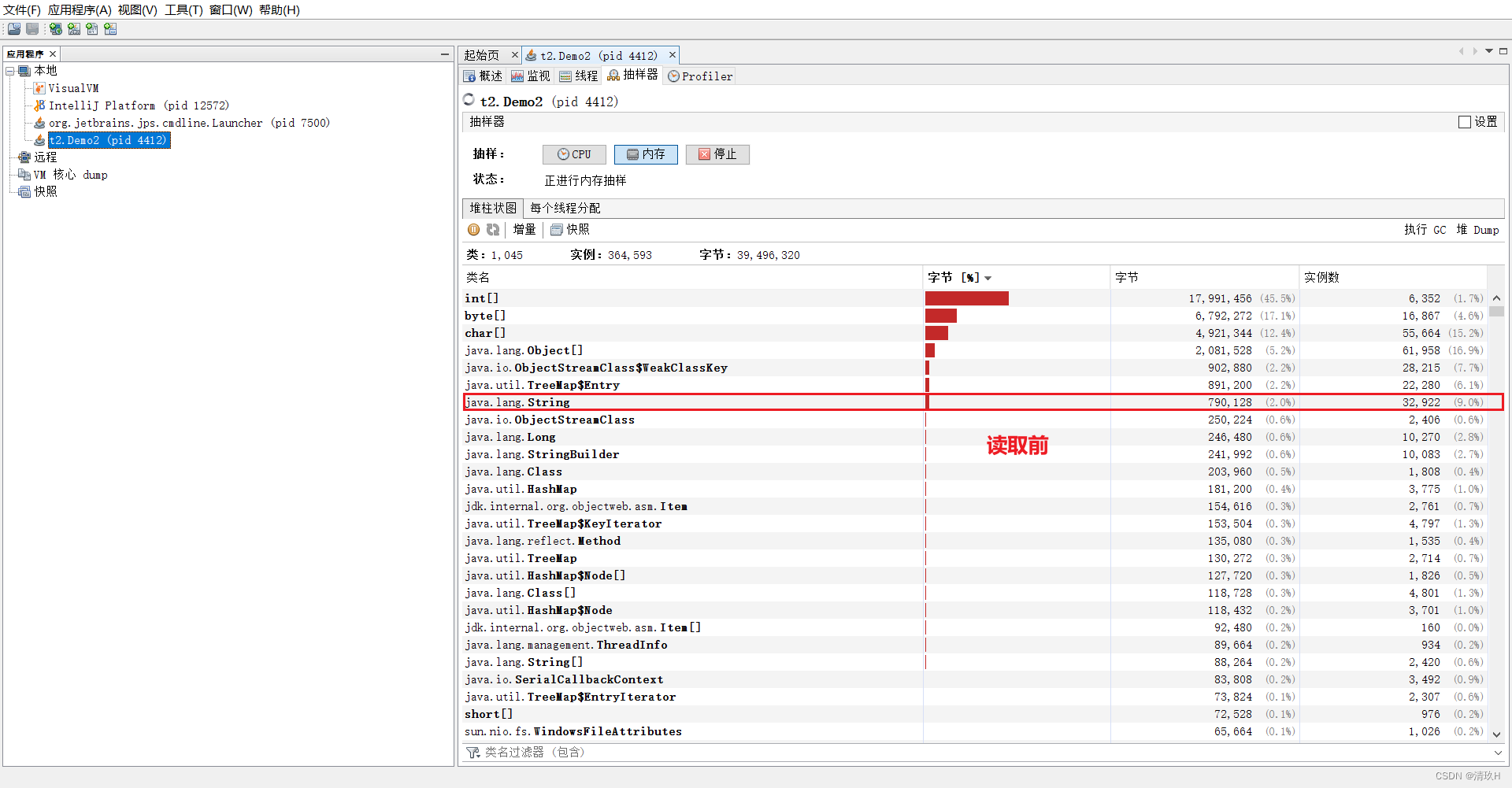
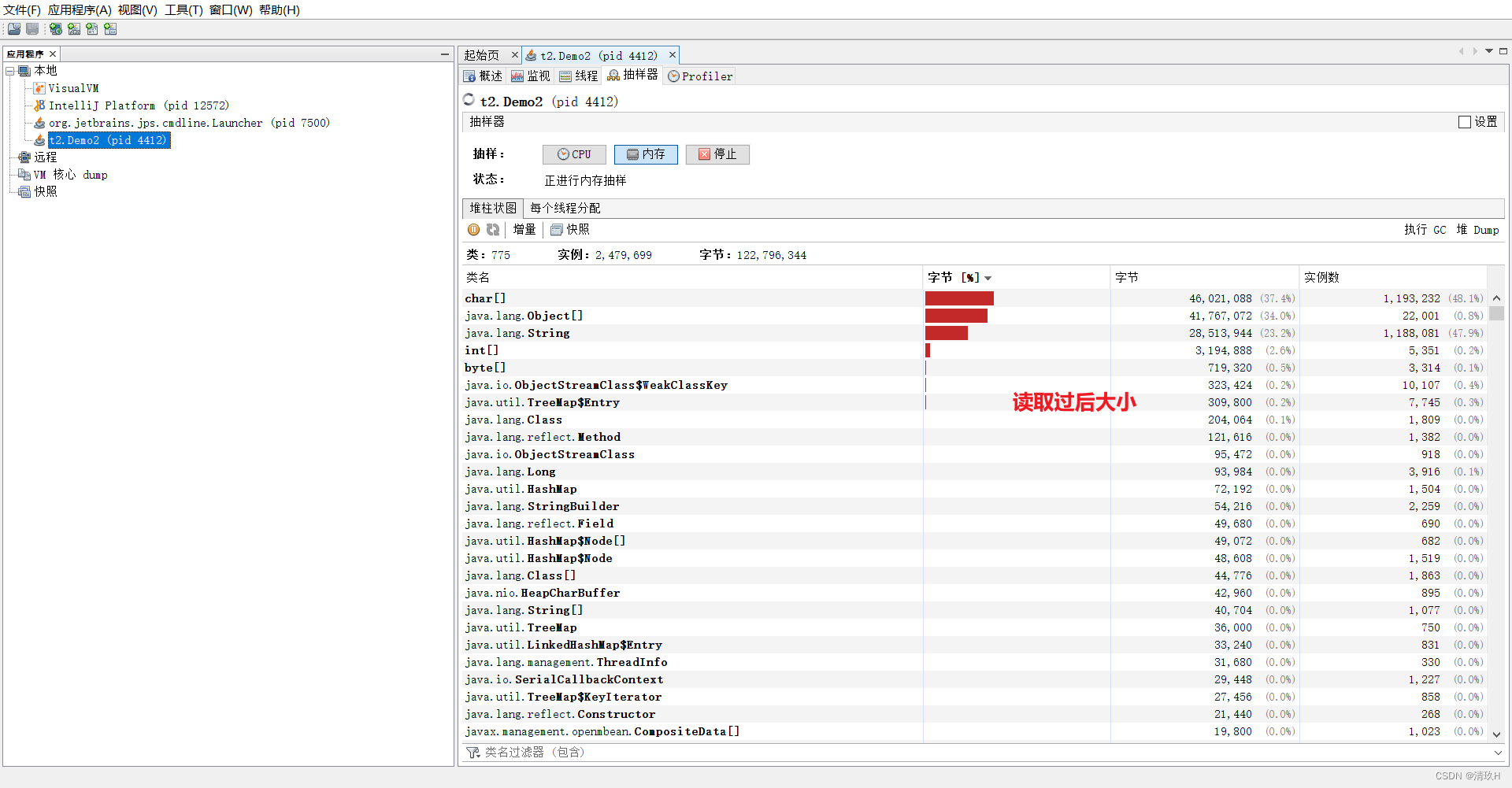
进行了入池前后内存占用的比较可以,看出来入池后会减少内存占用,所以应用中有大量字符串而且字符串会存在重复的问题,我们可以让字符串入池来减少字符串对象个数,减少内存使用
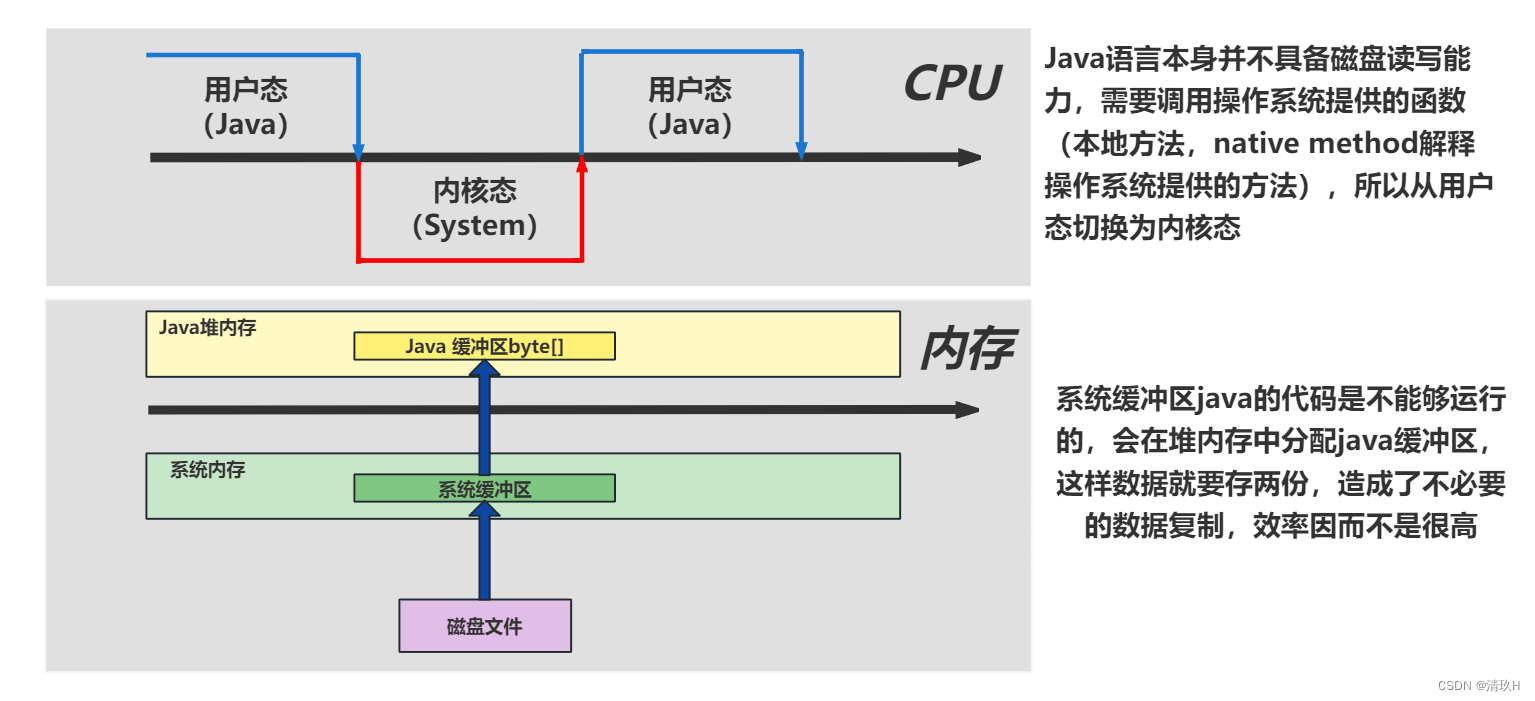
直接内存(Direct Memory)
属于操作系统内存,不属于java虚拟机管理
- 常见于 NIO 操作时,用于数据缓冲区
- 分配回收成本较高,但读写性能高
- 不受 JVM 内存回收管理
没有使用直接内存的情况
使用了直接内存的情况
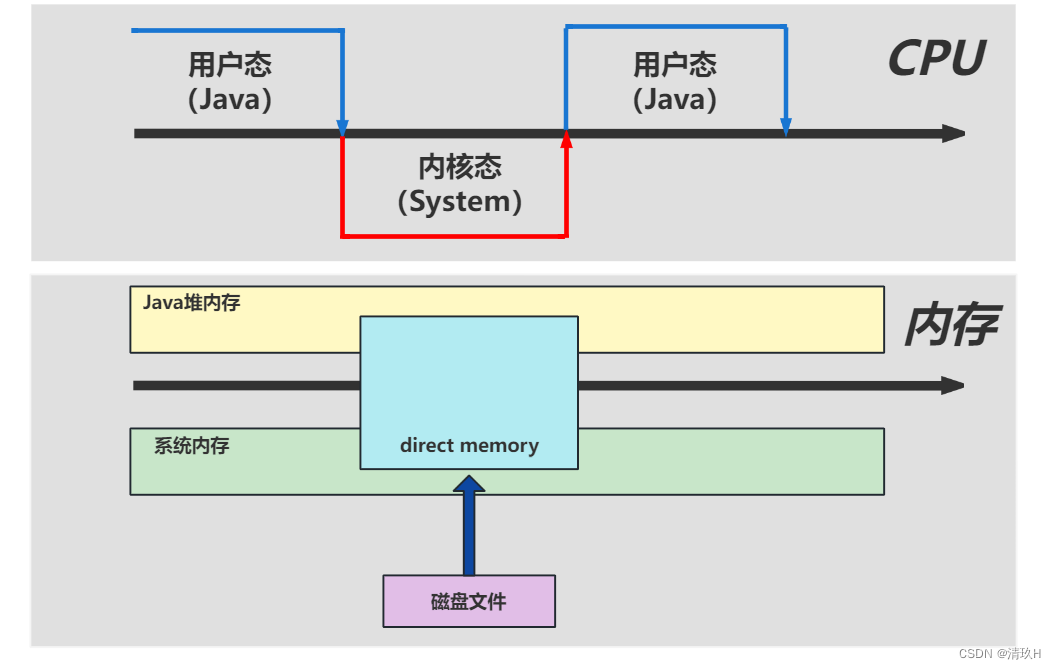
少了一次数据拷贝,读取速度得到提升
直接内存分配和释放原理
- 使用了 Unsafe 对象完成直接内存的分配回收,并且回收需要主动调用 freeMemory 方法
- ByteBuffer 的实现类内部,使用了 Cleaner (虚引用)来监测 ByteBuffer 对象,一旦
ByteBuffer 对象被垃圾回收,那么就会由 ReferenceHandler 线程通过 Cleaner 的 clean 方法调
用 freeMemory
禁止显示回收对直接内存的影响
/**
* 禁用显式回收对直接内存的影响
* -XX:+DisableExplicitGC 加了这个参数后 System.gc()就是无用的
*/
public class Demo1_26 {
static int _1Gb = 1024 * 1024 * 1024;
/*
* -XX:+DisableExplicitGC 显式的
*/
public static void main(String[] args) throws IOException {
ByteBuffer byteBuffer = ByteBuffer.allocateDirect(_1Gb);
System.out.println("分配完毕...");
System.in.read();
System.out.println("开始释放...");
byteBuffer = null;
System.gc(); // 显式的垃圾回收,Full GC
System.in.read();
}
}
System.gc(); 触发的是一次Full GC,是一种比较影响性能的垃圾回收,不仅要回收新生代,还要回收老年代
这样ByteBuffer不被回收,会导致直接内存占用内存过大长时间得不到释放,也会影响性能
可以直接用unsafe对象直接调用freeMemory()