基于TPU平台实现人群密度估计
队伍:SO-FAST
| 宋礼 算法工程师 京东科技 中国-北京 song200626@163.com | 柯嵩宇 计算机科学与技术专业 博士 上海交通大学 中国-上海 songyuke@sjtu.edu.cn | 包锴楠 计算机科学与技术 硕士 西南交通大学 中国-成都 baokainan123@gmail.com |
团队简介
SO-FAST的团队成员共3人,包括来自京东科技的算法工程师宋礼,他主要从事人工智能算法在城市场景的工程化落地。柯嵩宇,来自上海交通大学的在读博士生,他的主要研究是人工智能和数据挖掘领域,他对计算机硬件和并行计算等有深入了解。 包锴楠来自西南交通大学的在读硕士生,他主要研究深度学习、自动机器学习的应用。团队成员在深度学习和人工智能的工程化落地工作中具有丰富的经验,支持了JRTC中智能降噪技术在音视频会议场景下的优化等。团队成员追求速度的极致,曾致力于自动机器学习技术在城市场景中的加速优化,完成面向时空数据的自动机器学习算法库EAST等。
在本次竞赛的过程中,宋礼负责比赛方案的设计和模型的量化工作,柯嵩宇负责了模型量化后的模型优化工作,包锴楠负责模型部署过程中的推理加速工作。
摘要
基于TPU平台实现人群密度估计致力于人群密度估计任务在TPU平台的落地。人群密度估计是计算机视觉中的一项重要任务,在城市中的人群聚集预警、公共空间设计、城市规划等领域具有辅助意义。实际的应用场景通常面临功耗、成本、实时性等指标要求。基于TPU平台实现人群密度估计题目要求使用算能提供的低功耗的TPU算力实现精度更高、速度更快的人群密度估计算法。
为实现人群密度估计算法在TPU平台的部署,我们的实施步骤主要包括以下5个流程。
第一步,模型选择。通过对预训练模型的理论效果分析和实际模型推理效果在测试集上的指标评估,对比不同模型的最终得分,从而选定预训练模型。
第二步,模型量化。为了使用TPU平台的强大计算能力,需要使用算能的量化工具对模型进行量化,并评估量化后模型的精度。
第三步,精度调优。对量化后模型的精度进行调优,一般量化使用INT8类型的数据来替代FALOT32类型的数据从而加速计算,该过程会引入模型精度的损失。我们主要通过筛选图片构建用于量化的数据集来较少模型精度的损失。
第四步,推理加速。实现模型部署过程中的推理加速,通过分析模型推理过程中的核心耗时部分,我们针对性地使用了4N Batch和图片划分等方式,提升模型的推理速度。
最后,部署实测。我们将模型部署到BM1684平台,测试模型的实际性能,最终的评估结果表明我们的方案在A/B榜的测试数据上均获得了第一名。
关键词
人群密度估计,TPU,模型量化,模型部署
1 赛题介绍
基于TPU平台实现人群密度估计[1]要求参赛者使用预训练的模型,将模型部署到算能提供TPU平台[2]上。如图 1所示人群密度估计,输入一个高质量的图片,然后通过人群密度估计模型实现人群密度的估计。人群密度估计是计算机视

图 1 :人群密度估计任务
觉中的一项重要任务,在人群聚集预警、人群疏散、城市公共空间设计等任务中具有重要辅助作用。然而实际的模型部署依然面临很大的挑战,如推理的功耗、网络带宽、推理时延等。在模型部署的过程中需要兼顾模型的精度和模型的推理速度。本次任务采用以下综合评分:
其中, 是用于评估模型估计人群密度和真实人群密度的误差,要求误差越低越好。
是模型的平均推理时间,要求推理时间越低越好。
2 解题思路
我们的实施方案一共包含5个步骤,下面我们将分别介绍每部分的内容。
2.1 预训练模型评估
我们首先从理论上分析每个模型的精度上限,并选择未量化的模型在测试数据集(A榜)评估模型的实际效果。测试结果如图 2所示。
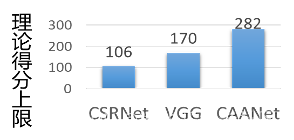
图 2 :人群密度估计任务
由于模型在部署的过程中除了要求考虑模型的精度,还要考虑模型的计算量,我们选择精度最高和精度最差的两个模型同时进行后续的量化和部署的过程。
2.2模型量化
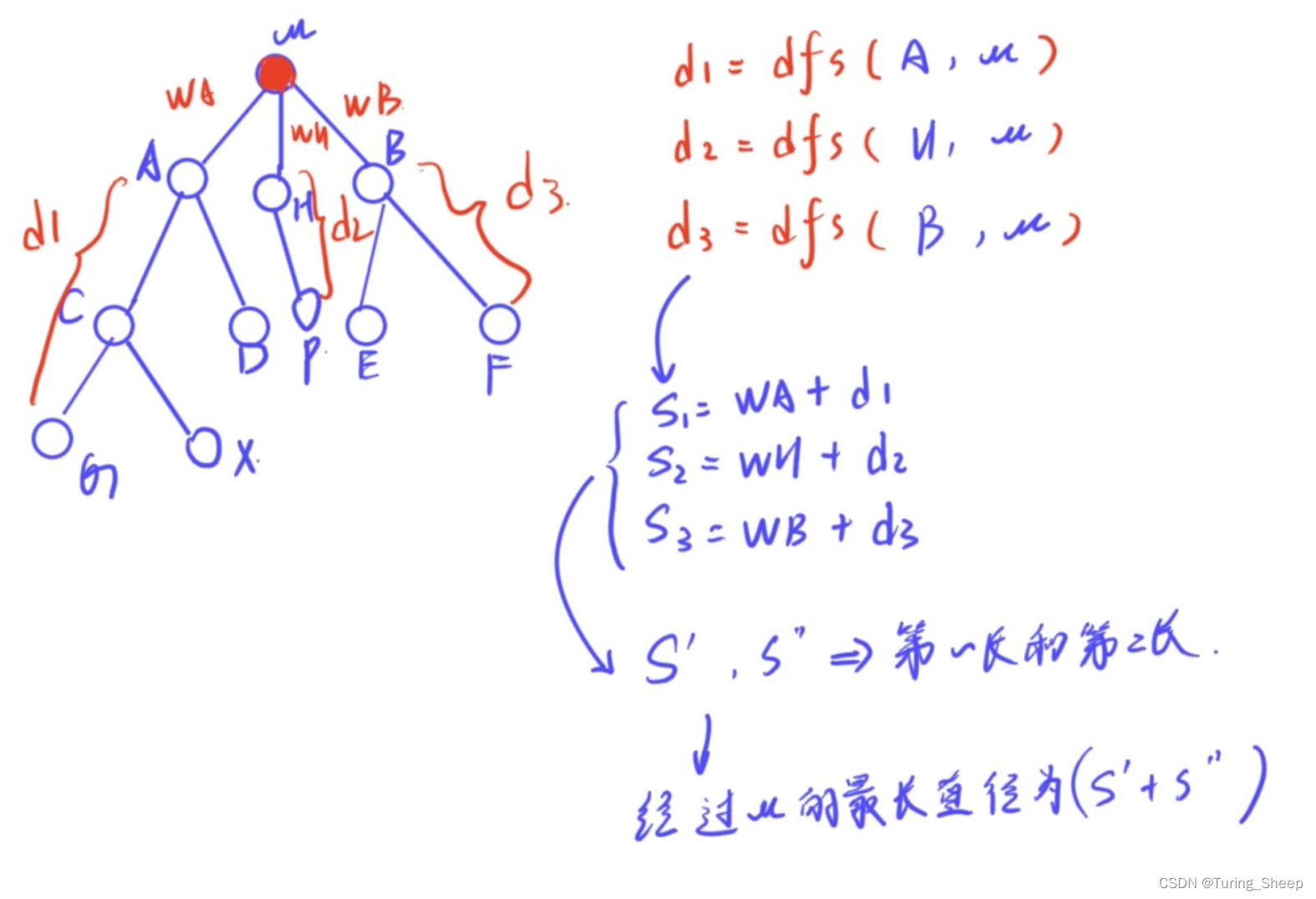
模型量化可以支持将模型量化成FLOAT32和INT8两种类型,其中,FLOAT32的数据类型可以实现更高的精度,但推理速度会慢很多。INT8的数据类型会损失一定的模型定都,但可以使用TPU提供的强大算力,极大的加速模型的推理过程。我们基于CSRNet[3]测试了模型量化成两种不同数据类型的最终评分情况,测试结果如图 3所示。从图中可以看出,虽然FP32模型的精度更高,但在实际的推理过程中消耗了太多的时间,导致最后评分不如INT8的模型。于是在后续的量化和优化过程中,我们选择使用INT8的数据类型。

图 3 :量化为不同数据类型性能对比
由于竞赛平台提供了模型量化的示例,我们不再赘述,具体的操作可以参考链接[4]。具体我们使用的量化和量化的过程参考链接[5]。值得注意的是,我们在量化过程中支持了4N batch推理模型,其中量化使用的命令如下。4N Batch对于模型推理的加速效果参考2.4推理加速。

图 4 :4N Batch量化指令
2.3 模型优化
由于将FLOAT32的数据类型,量化为了INT8的数据类型,这就导致计算过程中误差的累计,从而导致最终估计人群密度的精度降低。我们主要通过对量化图片的选择来提升量化后模型的性能。具体来说,传统的量化方式通过若干张图片作为输入,计算模型中间网络层的最大值和最小值,然后将该区间映射到INT8的范围内。由于可能选择的图片差距很大,这样会使得中间层网络需要表达的范围增大,从而使得在映射到INT8的时候数据的误差较大。基于上述考虑,我们在量化的过程中对输入的图片进行筛选,从而保证输入的图片尽可能相似。目前,我们主要通过手动的方式进行量化图片的选择(选择的准则是图片中包含大规模的人群,且具有更加广泛的色差),后续我们会考虑评估如何自动化的选择量化图片。具体来说,我们选择了NWPU-Crowd数据集中的第178张图片,如图 5所示。我们评估了量化方式对人群密度估计精度的提升,结果如图 6所示。可以看出,使用我们的量化方式,相比传统的量化方式具有明显的效果提升。

图 5 :用于模型量化的图片
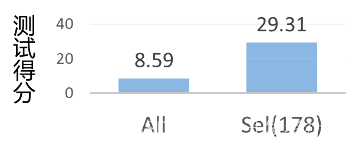
图 6 :CSRNet使用不同量化数据集的效果对比
2.4 推理加速
我们首先分析在模型推理过程中核心耗时的部分,然后进行针对性的优化。根据我们的测试和观察推理过程中的耗时主要在多次调用TPU进行推理。基于此,我们主要进行两个方面的优化,优化需要调用TPU的推理次数和增加单次调用推理图片的数量。
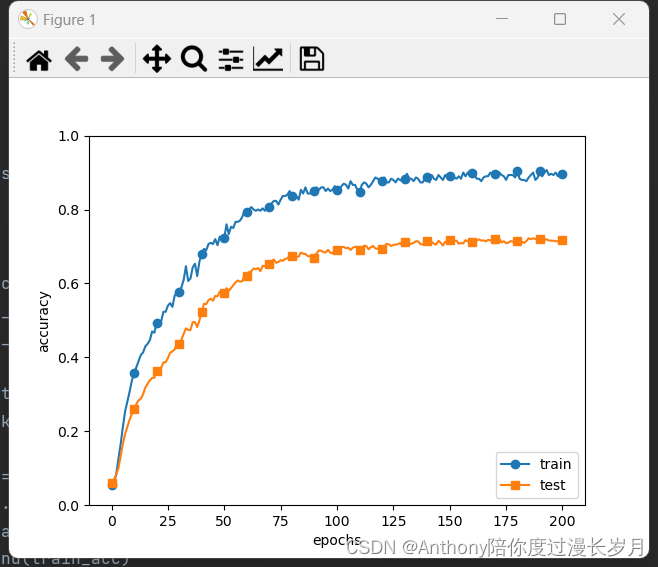
优化1:TPU的推理次数。如图 7所示,由于原始的输出图片的尺寸很大,最大为2048x2048像素,而我们模型的输入张量的大小为576x768像素,所以我们需要将原始一张输入图片进行划分多个输入传入模型,然后融合多个子图片的结果,得到最终的人群密度估计数据。一方面对于单张输入图片需要推理的次数很多,如图 7需要至少进行9次模型推理调用;另一方面,由于对于图片的划分是存在重叠的(不能丢弃子图片,否则丢失子图片中的人群密度没有估计,可能造成较大的误差),而右边区域和下边区域的利用率是不高的。于是,我们首先对输入图片进行尺寸变换(Resize)。具体地,我们测试了尺寸变换为1张图片和2x2=4张图片的评分变化,结果如图 8所示,从图中可以看出,当尺寸变换为1时,模型的精度具有很大程度的损失。尺寸变换为4时可以取得较好的精度和推理时间的平衡,其中推理精度部分的得分从14.9分降低为7.11分,但推理时间从平均1.07s降低到平均0.5s,总体分数的提升约50分。
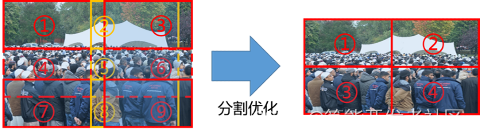
图 7 :优化的图像划分方式
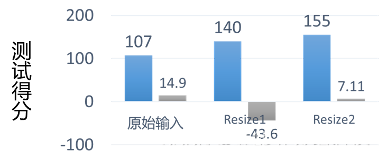
图 8 :不同划分方式的精度对比
优化2: 4N Batch推理模式。目前在人群密度估计时,对于每个子图均需要调用一次推理过程,其推理时间和调用次数是线性相关的。4N Batch模式利用INT8数据类型和INT32数据类型之间的关系,在推理的过程中一次使用4N个图片输入,加入模型的推理过程,其过程如图 9所示。经测试相比于单次的4次推理,4N Batch一次推理4张图片约可以降低一半的时间(以CSRNet为例,4张图片的推理时间约为0.51s,4N Batch单次推理4张图片的时间为0.27s)。

图 9 :4N Batch推理模式
除了上述的核心优化点外,我们还尝试了对推理代码的其他部分进行优化,包括使用的输入数据类型、读取图片的库的使用、后处理逻辑的优化等,具体实现参考[5]。
2.5 部署测试
将编译完成的模型和推理代码上传到算能TPU平台,即可完成推理测试。我们最终获得了A/B榜均为Top 1的性能,其中A榜得分229.73分,B榜得分263.78分。
致谢
感谢CCF大数据与计算智能大赛组委会、中国计算机学会和北京算能科技有限公司举办的第十届大赛,给我们提供了学习和实践的机会。感谢算能提供的TPU算力平台,让我们不断实践和完善想法。
参考
[1] DataFountain,基于TPU平台实现人群密度估计, https://www.datafountain.cn/competitions/583
[2] 算能,算能产品介绍,https://sophon.cn/product/index.html
[3] Li Yuhong and Zhang Xiaofan and Chen Deming, CSRNet: Dilated Convolutional Neural Networks for Understanding the Highly Congested Scenes, Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 1091-1100, 2018.
[4] 算能,CCF-Contest-Demo, https://github.com/sophon-ai-algo/contest-demos
[5] SO-FAST, 基于TPU平台实现人群密度估计 SO-FAST 题解, https://github.com/LeeSongt/SO-FAST