Keras 是一个用于深度学习的 Python 库,它封装了强大的数值库 Theano 和 TensorFlow。
在本文中,你将了解如何在 Keras 中开发和评估用于图像识别的深度学习模型。完成本文后,你将了解:
- 关于 CIFAR-10 对象分类数据集以及如何在 Keras 中加载和使用它
- 如何创建用于对象识别的简单卷积神经网络
- 如何通过创建更深的卷积神经网络来提升性能
让我们开始吧。
文章目录
- 技术交流
- CIFAR-10 问题描述
- 在 Keras 中加载 CIFAR-10 数据集
- CIFAR-10 的简单卷积神经网络
- CIFAR-10 的更大的卷积神经网络
- 提高模型性能的扩展
- 总结
技术交流
技术要学会分享、交流,不建议闭门造车。 本文技术由粉丝群小伙伴推荐。源码、数据、技术交流提升,均可加交流群获取,群友已超过2000人,添加时最好的备注方式为:来源+兴趣方向,方便找到志同道合的朋友。
方式①、添加微信号:dkl88191,备注:来自CSDN +技术交流
方式②、微信搜索公众号:Python学习与数据挖掘,后台回复:加群
CIFAR-10 问题描述
CIFAR -10 数据集包含 60,000 张照片,分为 10 个类别(因此得名 CIFAR-10)。类包括飞机、汽车、鸟、猫等常见对象。数据集以标准方式拆分,其中 50,000 张图像用于训练模型,其余 10,000 张图像用于评估其性能。
这些照片是彩色的,包含红色、绿色和蓝色成分,但很小,尺寸为 32 x 32 像素正方形。
最先进的结果是使用非常大的卷积神经网络实现的。你可以在 Rodrigo Benenson 的网页上了解 CIFAR-10的最新成果。模型性能以分类精度报告,性能非常好,超过 90%,在撰写本文时,人类在该问题上的性能为 94%,最先进的结果为 96%。
在 Keras 中加载 CIFAR-10 数据集
CIFAR-10 数据集可以很容易地加载到 Keras 中。
Keras 可以自动下载 CIFAR-10 等标准数据集,并使用 cifar10.load_data() 函数将它们存储在 ~/.keras/datasets 目录中。此数据集很大,因此下载可能需要几分钟时间。
下载后,对该函数的后续调用将加载准备好使用的数据集。
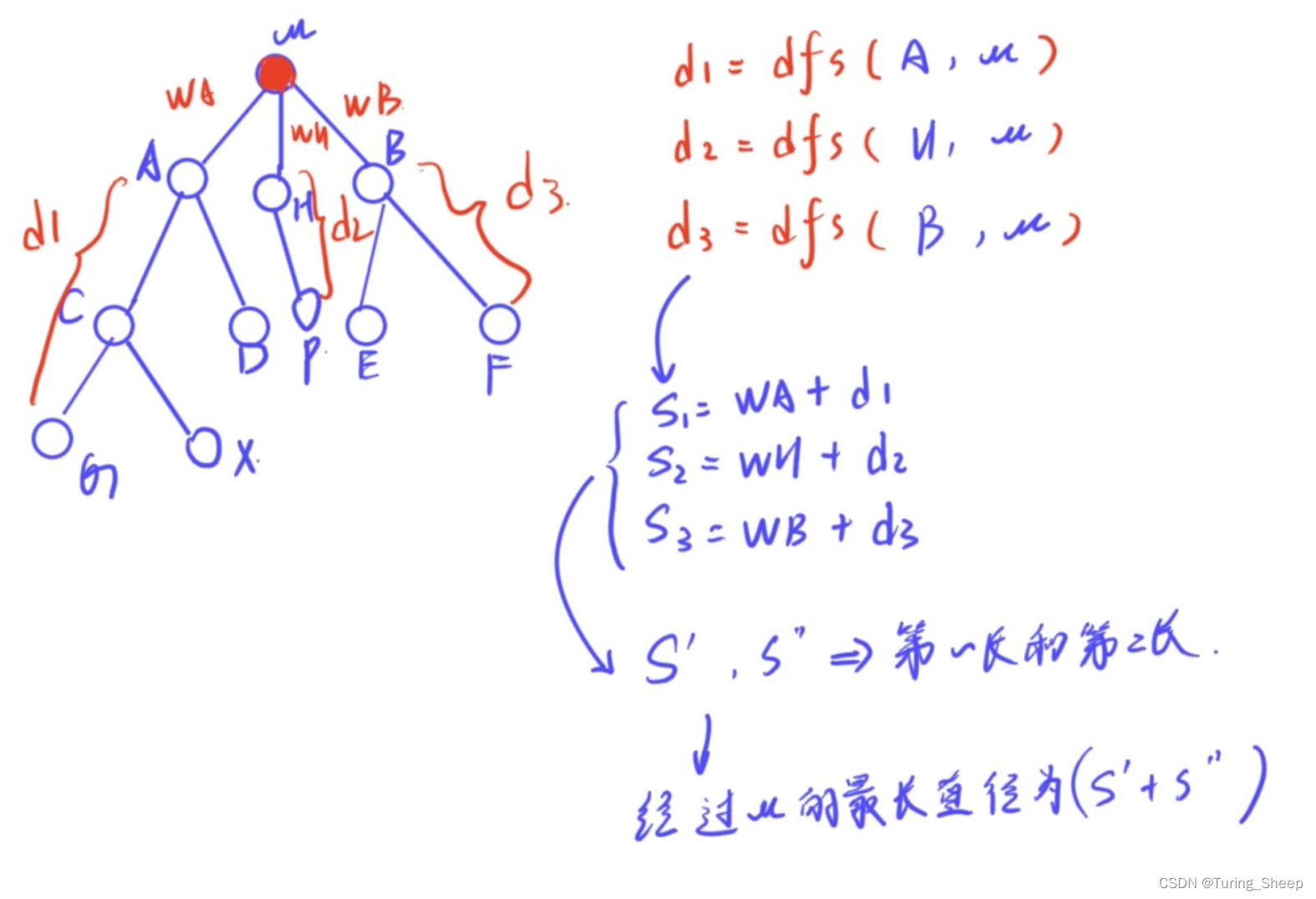
数据集存储为 pickled 训练集和测试集,可以在 Keras 中使用。每个图像都表示为一个三维矩阵,具有红色、绿色、蓝色、宽度和高度的尺寸。我们可以直接使用 matplotlib 绘制图像。
# Plot ad hoc CIFAR10 instances
from tensorflow.keras.datasets import cifar10
import matplotlib.pyplot as plt
# load data
(X_train, y_train), (X_test, y_test) = cifar10.load_data()
# create a grid of 3x3 images
for i in range(0, 9):
plt.subplot(330 + 1 + i)
plt.imshow(X_train[i])
# show the plot
plt.show()
运行代码会创建一个 3×3 的照片图。这些图像已从 32×32 的小尺寸按比例放大,但你可以清楚地看到卡车、马匹和汽车。你还可以在某些强制为方形宽高比的图像中看到一些失真。

CIFAR-10 的简单卷积神经网络
CIFAR-10 问题最好使用卷积神经网络 (CNN) 来解决。
你可以通过定义本示例中需要的所有类和函数来快速开始。
# Simple CNN model for CIFAR-10
from tensorflow.keras.datasets import cifar10
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense
from tensorflow.keras.layers import Dropout
from tensorflow.keras.layers import Flatten
from tensorflow.keras.constraints import MaxNorm
from tensorflow.keras.optimizers import SGD
from tensorflow.keras.layers import Conv2D
from tensorflow.keras.layers import MaxPooling2D
from tensorflow.keras.utils import to_categorical
...
接下来,你可以加载 CIFAR-10 数据集。
...
# load data
(X_train, y_train), (X_test, y_test) = cifar10.load_data()
对于每个红色、绿色和蓝色通道,像素值的范围从 0 到 255。
使用规范化数据是一种很好的做法。因为输入值很好理解,所以你可以通过将每个值除以最大观察值(255)轻松标准化到 0 到 1 的范围。
请注意,数据以整数形式加载,因此你必须将其转换为浮点值才能执行除法。
...
# normalize inputs from 0-255 to 0.0-1.0
X_train = X_train.astype('float32')
X_test = X_test.astype('float32')
X_train = X_train / 255.0
X_test = X_test / 255.0
输出变量被定义为每个类的从 0 到 1 的整数向量。
你可以使用单热编码将它们转换为二进制矩阵,以最好地模拟分类问题。这个问题有 10 个类别,因此你可以预期二进制矩阵的宽度为 10。
...
# one hot encode outputs
y_train = to_categorical(y_train)
y_test = to_categorical(y_test)
num_classes = y_test.shape[1]
让我们首先定义一个简单的 CNN 结构作为基线,并评估它在问题上的表现。
你将使用具有两个卷积层的结构,然后是最大池化和将网络展平到完全连接的层以进行预测。
基线网络结构可以总结如下:
- 卷积输入层,32个大小为3×3的特征图,一个整流器激活函数,最大范数设置为3的权重约束
辍学率设置为 20% - 卷积层,32个大小为3×3的特征图,一个整流器激活函数,最大范数设置为3的权重约束
大小为 2×2 的 Max Pool 层 - 展平层
具有 512 个单元和整流器激活函数的全连接层 - 辍学率设置为 50%
- 具有 10 个单元和 softmax 激活函数的全连接输出层
对数损失函数与随机梯度下降优化算法一起使用,该算法配置有大动量和权重衰减,学习率为 0.01。
...
# Create the model
model = Sequential()
model.add(Conv2D(32, (3, 3), input_shape=(32, 32, 3), padding='same', activation='relu', kernel_constraint=MaxNorm(3)))
model.add(Dropout(0.2))
model.add(Conv2D(32, (3, 3), activation='relu', padding='same', kernel_constraint=MaxNorm(3)))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Flatten())
model.add(Dense(512, activation='relu', kernel_constraint=MaxNorm(3)))
model.add(Dropout(0.5))
model.add(Dense(num_classes, activation='softmax'))
# Compile model
epochs = 25
lrate = 0.01
decay = lrate/epochs
sgd = SGD(learning_rate=lrate, momentum=0.9, decay=decay, nesterov=False)
model.compile(loss='categorical_crossentropy', optimizer=sgd, metrics=['accuracy'])
print(model.summary())
你可以使用 25 个 epoch 和 32 的批量大小来拟合此模型。
选择了少量的 epoch 来帮助保持本教程的进展。通常,对于这个问题,epoch 的数量会大一到两个数量级。
一旦模型适合,你就可以在测试数据集上对其进行评估并打印出分类准确性。
...
# Fit the model
model.fit(X_train, y_train, validation_data=(X_test, y_test), epochs=epochs, batch_size=32)
# Final evaluation of the model
scores = model.evaluate(X_test, y_test, verbose=0)
print("Accuracy: %.2f%%" % (scores[1]*100))
将所有这些结合在一起,下面列出了完整的示例。
# Simple CNN model for the CIFAR-10 Dataset
from tensorflow.keras.datasets import cifar10
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense
from tensorflow.keras.layers import Dropout
from tensorflow.keras.layers import Flatten
from tensorflow.keras.constraints import MaxNorm
from tensorflow.keras.optimizers import SGD
from tensorflow.keras.layers import Conv2D
from tensorflow.keras.layers import MaxPooling2D
from tensorflow.keras.utils import to_categorical
# load data
(X_train, y_train), (X_test, y_test) = cifar10.load_data()
# normalize inputs from 0-255 to 0.0-1.0
X_train = X_train.astype('float32')
X_test = X_test.astype('float32')
X_train = X_train / 255.0
X_test = X_test / 255.0
# one hot encode outputs
y_train = to_categorical(y_train)
y_test = to_categorical(y_test)
num_classes = y_test.shape[1]
# Create the model
model = Sequential()
model.add(Conv2D(32, (3, 3), input_shape=(32, 32, 3), padding='same', activation='relu', kernel_constraint=MaxNorm(3)))
model.add(Dropout(0.2))
model.add(Conv2D(32, (3, 3), activation='relu', padding='same', kernel_constraint=MaxNorm(3)))
model.add(MaxPooling2D())
model.add(Flatten())
model.add(Dense(512, activation='relu', kernel_constraint=MaxNorm(3)))
model.add(Dropout(0.5))
model.add(Dense(num_classes, activation='softmax'))
# Compile model
epochs = 25
lrate = 0.01
decay = lrate/epochs
sgd = SGD(learning_rate=lrate, momentum=0.9, decay=decay, nesterov=False)
model.compile(loss='categorical_crossentropy', optimizer=sgd, metrics=['accuracy'])
model.summary()
# Fit the model
model.fit(X_train, y_train, validation_data=(X_test, y_test), epochs=epochs, batch_size=32)
# Final evaluation of the model
scores = model.evaluate(X_test, y_test, verbose=0)
print("Accuracy: %.2f%%" % (scores[1]*100))
运行此示例可提供以下结果。首先,总结网络结构,确认设计已正确实施。
Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
conv2d (Conv2D) (None, 32, 32, 32) 896
dropout (Dropout) (None, 32, 32, 32) 0
conv2d_1 (Conv2D) (None, 32, 32, 32) 9248
max_pooling2d (MaxPooling2D (None, 16, 16, 32) 0
)
flatten (Flatten) (None, 8192) 0
dense (Dense) (None, 512) 4194816
dropout_1 (Dropout) (None, 512) 0
dense_1 (Dense) (None, 10) 5130
=================================================================
Total params: 4,210,090
Trainable params: 4,210,090
Non-trainable params: 0
_________________________________________________________________
分类准确度和损失在训练和测试数据集的每个时期之后打印。
该模型在测试集上进行了评估,达到了 70.5% 的准确率,算不上优秀。
...
Epoch 20/25
1563/1563 [==============================] - 34s 22ms/step - loss: 0.3001 - accuracy: 0.8944 - val_loss: 1.0160 - val_accuracy: 0.6984
Epoch 21/25
1563/1563 [==============================] - 35s 23ms/step - loss: 0.2783 - accuracy: 0.9021 - val_loss: 1.0339 - val_accuracy: 0.6980
Epoch 22/25
1563/1563 [==============================] - 35s 22ms/step - loss: 0.2623 - accuracy: 0.9084 - val_loss: 1.0271 - val_accuracy: 0.7014
Epoch 23/25
1563/1563 [==============================] - 33s 21ms/step - loss: 0.2536 - accuracy: 0.9104 - val_loss: 1.0441 - val_accuracy: 0.7011
Epoch 24/25
1563/1563 [==============================] - 34s 22ms/step - loss: 0.2383 - accuracy: 0.9180 - val_loss: 1.0576 - val_accuracy: 0.7012
Epoch 25/25
1563/1563 [==============================] - 37s 24ms/step - loss: 0.2245 - accuracy: 0.9219 - val_loss: 1.0544 - val_accuracy: 0.7050
Accuracy: 70.50%
你可以通过创建更深的网络来显着提高准确性。这就是你将在下一节中看到的内容。
CIFAR-10 的更大的卷积神经网络
你已经看到一个简单的 CNN 在这个复杂的问题上表现不佳。在本节中,你将着眼于扩大模型的大小和复杂性。
让我们设计一个深度版本的上面的简单 CNN。你可以引入具有更多特征图的额外一轮卷积。你将使用相同模式的卷积层、丢弃层、卷积层和最大池化层。
该模式将使用 32、64 和 128 个特征图重复三次。在给定最大池化层的情况下,效果是越来越多的特征图具有越来越小的尺寸。最后,将在网络的输出端使用一个额外的更大的 Dense 层,以试图更好地将大量特征映射转换为类值。
新网络架构总结如下:
- 卷积输入层,32个大小为3×3的特征图,以及一个整流器激活函数
20% 的丢弃层 - 卷积层,32个大小为3×3的特征图,以及一个整流器激活函数
大小为 2×2 的 Max Pool 层 - 卷积层,64个大小为3×3的特征图,以及一个整流器激活函数
20% 的丢弃层。 - 卷积层,64个大小为3×3的特征图,以及一个整流器激活函数
大小为 2×2 的 Max Pool 层 - 卷积层,128个大小为3×3的特征图,以及一个整流器激活函数
20% 的丢弃层 - 卷积层,128个大小为3×3的特征图,以及一个整流器激活函数
大小为 2×2 的 Max Pool 层 - 展平层
20% 的丢弃层 - 具有 1024 个单元和整流器激活函数的全连接层
20% 的丢弃层 - 具有 512 个单元和整流器激活函数的全连接层
20% 的丢弃层 - 具有 10 个单元和 softmax 激活函数的全连接输出层
你可以非常轻松地在 Keras 中定义此网络拓扑,如下所示:
...
# Create the model
model = Sequential()
model.add(Conv2D(32, (3, 3), input_shape=(32, 32, 3), activation='relu', padding='same'))
model.add(Dropout(0.2))
model.add(Conv2D(32, (3, 3), activation='relu', padding='same'))
model.add(MaxPooling2D())
model.add(Conv2D(64, (3, 3), activation='relu', padding='same'))
model.add(Dropout(0.2))
model.add(Conv2D(64, (3, 3), activation='relu', padding='same'))
model.add(MaxPooling2D())
model.add(Conv2D(128, (3, 3), activation='relu', padding='same'))
model.add(Dropout(0.2))
model.add(Conv2D(128, (3, 3), activation='relu', padding='same'))
model.add(MaxPooling2D())
model.add(Flatten())
model.add(Dropout(0.2))
model.add(Dense(1024, activation='relu', kernel_constraint=MaxNorm(3)))
model.add(Dropout(0.2))
model.add(Dense(512, activation='relu', kernel_constraint=MaxNorm(3)))
model.add(Dropout(0.2))
model.add(Dense(num_classes, activation='softmax'))
# Compile model
epochs = 25
lrate = 0.01
decay = lrate/epochs
sgd = SGD(learning_rate=lrate, momentum=0.9, decay=decay, nesterov=False)
model.compile(loss='categorical_crossentropy', optimizer=sgd, metrics=['accuracy'])
model.summary()
...
你可以使用与上述相同的程序和相同数量的时期来拟合和评估该模型,但通过一些小的实验发现更大的批量大小 64。
...
model.fit(X_train, y_train, validation_data=(X_test, y_test), epochs=epochs, batch_size=64)
# Final evaluation of the model
scores = model.evaluate(X_test, y_test, verbose=0)
print("Accuracy: %.2f%%" % (scores[1]*100))
将所有这些结合在一起,下面列出了完整的示例。
# Large CNN model for the CIFAR-10 Dataset
from tensorflow.keras.datasets import cifar10
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense
from tensorflow.keras.layers import Dropout
from tensorflow.keras.layers import Flatten
from tensorflow.keras.constraints import MaxNorm
from tensorflow.keras.optimizers import SGD
from tensorflow.keras.layers import Conv2D
from tensorflow.keras.layers import MaxPooling2D
from tensorflow.keras.utils import to_categorical
# load data
(X_train, y_train), (X_test, y_test) = cifar10.load_data()
# normalize inputs from 0-255 to 0.0-1.0
X_train = X_train.astype('float32')
X_test = X_test.astype('float32')
X_train = X_train / 255.0
X_test = X_test / 255.0
# one hot encode outputs
y_train = to_categorical(y_train)
y_test = to_categorical(y_test)
num_classes = y_test.shape[1]
# Create the model
model = Sequential()
model.add(Conv2D(32, (3, 3), input_shape=(32, 32, 3), activation='relu', padding='same'))
model.add(Dropout(0.2))
model.add(Conv2D(32, (3, 3), activation='relu', padding='same'))
model.add(MaxPooling2D())
model.add(Conv2D(64, (3, 3), activation='relu', padding='same'))
model.add(Dropout(0.2))
model.add(Conv2D(64, (3, 3), activation='relu', padding='same'))
model.add(MaxPooling2D())
model.add(Conv2D(128, (3, 3), activation='relu', padding='same'))
model.add(Dropout(0.2))
model.add(Conv2D(128, (3, 3), activation='relu', padding='same'))
model.add(MaxPooling2D())
model.add(Flatten())
model.add(Dropout(0.2))
model.add(Dense(1024, activation='relu', kernel_constraint=MaxNorm(3)))
model.add(Dropout(0.2))
model.add(Dense(512, activation='relu', kernel_constraint=MaxNorm(3)))
model.add(Dropout(0.2))
model.add(Dense(num_classes, activation='softmax'))
# Compile model
epochs = 25
lrate = 0.01
decay = lrate/epochs
sgd = SGD(learning_rate=lrate, momentum=0.9, decay=decay, nesterov=False)
model.compile(loss='categorical_crossentropy', optimizer=sgd, metrics=['accuracy'])
model.summary()
# Fit the model
model.fit(X_train, y_train, validation_data=(X_test, y_test), epochs=epochs, batch_size=64)
# Final evaluation of the model
scores = model.evaluate(X_test, y_test, verbose=0)
print("Accuracy: %.2f%%" % (scores[1]*100))
运行此示例会打印每个时期的训练和测试数据集的分类准确度和损失。
最终模型的分类准确率估计为 79.5%,比我们的简单模型高 9 个百分点。
...
Epoch 20/25
782/782 [==============================] - 50s 64ms/step - loss: 0.4949 - accuracy: 0.8237 - val_loss: 0.6161 - val_accuracy: 0.7864
Epoch 21/25
782/782 [==============================] - 51s 65ms/step - loss: 0.4794 - accuracy: 0.8308 - val_loss: 0.6184 - val_accuracy: 0.7866
Epoch 22/25
782/782 [==============================] - 50s 64ms/step - loss: 0.4660 - accuracy: 0.8347 - val_loss: 0.6158 - val_accuracy: 0.7901
Epoch 23/25
782/782 [==============================] - 50s 64ms/step - loss: 0.4523 - accuracy: 0.8395 - val_loss: 0.6112 - val_accuracy: 0.7919
Epoch 24/25
782/782 [==============================] - 50s 64ms/step - loss: 0.4344 - accuracy: 0.8454 - val_loss: 0.6080 - val_accuracy: 0.7886
Epoch 25/25
782/782 [==============================] - 50s 64ms/step - loss: 0.4231 - accuracy: 0.8487 - val_loss: 0.6076 - val_accuracy: 0.7950
Accuracy: 79.50%
提高模型性能的扩展
可以尝试扩展模型并提高模型性能的一些想法。
- 训练更多时代。每个模型都训练了非常少的 epoch,即 25 个。训练大型卷积神经网络数百或数千个 epoch 是很常见的。你应该期望可以通过显着增加训练时期的数量来实现性能提升。
- 图像数据增强。图像中的物体位置不同。通过使用一些数据扩充,可以实现模型性能的另一个提升。标准化、随机移动或水平图像翻转等方法可能会有所帮助。
- 更深层次的网络拓扑。呈现的较大网络很深,但可以针对该问题设计更大的网络。这可能涉及更接近输入的更多特征图,并且可能涉及不那么激进的池化。此外,可以采用已证明有用的标准卷积网络拓扑结构并对其进行评估。
总结
在本文中,了解了如何在 Keras 中创建用于照片中对象识别的深度学习模型。
- 关于 CIFAR-10 数据集以及如何将其加载到 Keras 中并绘制数据集中的临时示例
- 如何在问题上训练和评估一个简单的卷积神经网络
- 如何将简单的卷积神经网络扩展为深度卷积神经网络,以提高难题的性能
- 如何使用数据增强来进一步提升困难的物体识别问题
你对物体识别或这篇文章有任何疑问吗?在评论中提出你的问题,我会尽力回答。