我是小米,一个喜欢分享技术的29岁程序员。如果你喜欢我的文章,欢迎关注我的微信公众号“软件求生”,获取更多技术干货!
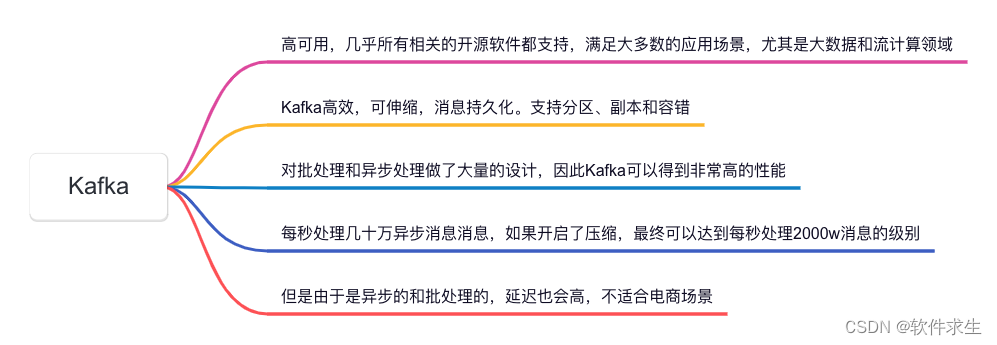
哈喽,大家好,我是小米,一个积极活泼、热爱技术分享的大哥哥!今天我们来聊聊在大数据和流计算领域备受推崇的消息系统——Kafka。Kafka以其高效、可伸缩、消息持久化的特性成为了许多企业的首选,特别是在需要处理大量数据和流数据的应用场景中。本文将深入探讨Kafka的高可用性,并分析其在批处理和异步处理方面的卓越设计。
Kafka的高可用架构
Kafka作为一个分布式流处理平台,主要由以下几个核心组件构成:
- Producer(生产者):负责将数据发送到Kafka集群。
- Consumer(消费者):负责从Kafka集群中读取数据。
- Broker(代理):Kafka集群中的每一个服务器称为一个Broker,负责存储数据并提供服务。
- Topic(主题):数据的逻辑分类单元,生产者和消费者通过主题来进行数据的发布和订阅。
- Partition(分区):每个主题可以划分为多个分区,以实现数据的并行处理和负载均衡。
- Repli