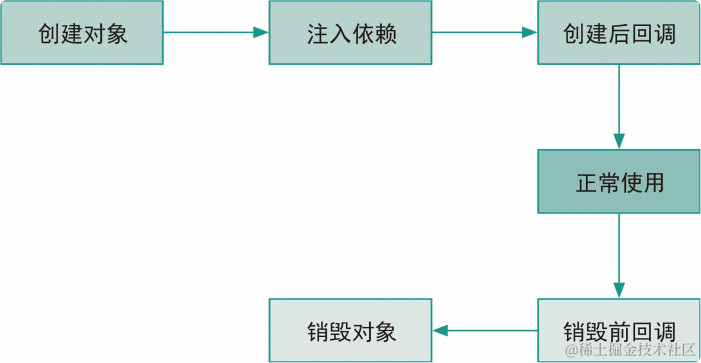
小罗碎碎念
文献主题:人工智能在【数字病理】领域的最新进展
今天在写这篇推文的时候,脑子里就一个念头——大模型的风,终于还是卷到了病理学领域。
这是一个好事哈,如果我们搞病理研究的,也能有一个像Chatgpt一样的工具,那么我们的效率会得到极大的提升,并且大家入门的门槛也会降低不少,这对于我们这种缺乏临床基础的工科生来说,是很好的一个消息。
除了把大模型与计算机视觉结合起来,其实还有一个方向一直没有得到攻破——无监督学习。前期打标注的工作,一直为人诟病,所以很多老师/同学都在致力于开发弱监督/无监督的算法,例如今天推荐的第三、四篇文献。
最后一个想提一嘴的方向是——多模态/多组学。我们知道,每一个癌种,都是存在一定几率发生复发/转移的,参考临床的诊断流程,我们要想对一个患者下明确的诊断意见,需要患者做很多检查,然后医生再根据这些检查结果来给出下一步的诊断意见。因此,要想利用AI解决这一类复杂的问题,必须要引入病理组学、影像组学、基因组学、代谢组学、蛋白组学以及肠道菌群等多模态的数据,才能提升模型的诊断效率。

还有,我们都是经历过大模型迭代的人,不要着急去追热点(毕竟我们也没有资金去购入大量的服务器),还不如好好的守好自己的护城河,毕竟上面提到的多模态的数据,他们一时半会儿弄不到,懂了吧。
一、PathChat|病理学领域专用的多模态生成式人工智能(AI)辅助系统

文献概述
这篇文章介绍的一种专门为病理学领域设计的,名为
PathChat的多模态生成性人工智能(AI)辅助系统。
PathChat由一个基础视觉编码器、一个预训练的大型语言模型以及一个多模态投影模块组成,通过在超过456,000条视觉语言指令上的微调来构建。这些指令包括999,202个问答转换,覆盖了多种组织来源和疾病模型的多项选择诊断问题。
研究者们比较了PathChat与其他几种多模态视觉语言AI辅助系统以及GPT4V(驱动商业化多模态通用AI助手ChatGPT-4的模型)的性能。结果显示,PathChat在多项选择诊断问题上达到了最先进的性能,并且在开放式问题和人类专家评估中,PathChat生成的回应更为准确,更受病理学家的偏好。
PathChat作为一个交互式的、通用的视觉-语言AI辅助系统,能够灵活处理视觉和自然语言输入,有潜力在病理学教育、研究和临床决策中发挥重要作用。例如,PathChat能够摄取组织病理学图像,提供形态学外观的初步评估,识别恶性肿瘤的潜在特征,并根据用户提供的临床参数和组织部位提供鉴别诊断建议。此外,PathChat还能够根据这些测试结果做出最终的诊断推断。
文章还讨论了计算病理学领域的进展
包括数字切片扫描的增加、AI研究的快速进展、大型数据集的易用性以及高性能计算资源的显著提升。这些进展推动了深度学习在以下方面的应用:
- 癌症亚型和分级
- 转移检测
- 生存和治疗反应预测
- 肿瘤起源预测
- 突变预测
- 生物标志物筛查
PathChat的开发和评估为计算病理学领域提供了新的方向
PathChat强调除了强大的视觉处理能力之外,自然语言和人类交互也应该作为AI模型设计和用户体验的关键组成部分。
未来的研究可能会进一步提高PathChat和基于MLLM的AI助手的能力,例如通过支持输入整个千兆像素WSI或多个WSI,以及通过持续训练与最新知识保持同步,或使用检索增强生成技术与不断更新的知识数据库结合。
重点关注
PathChat系统两个主要方面的概览:
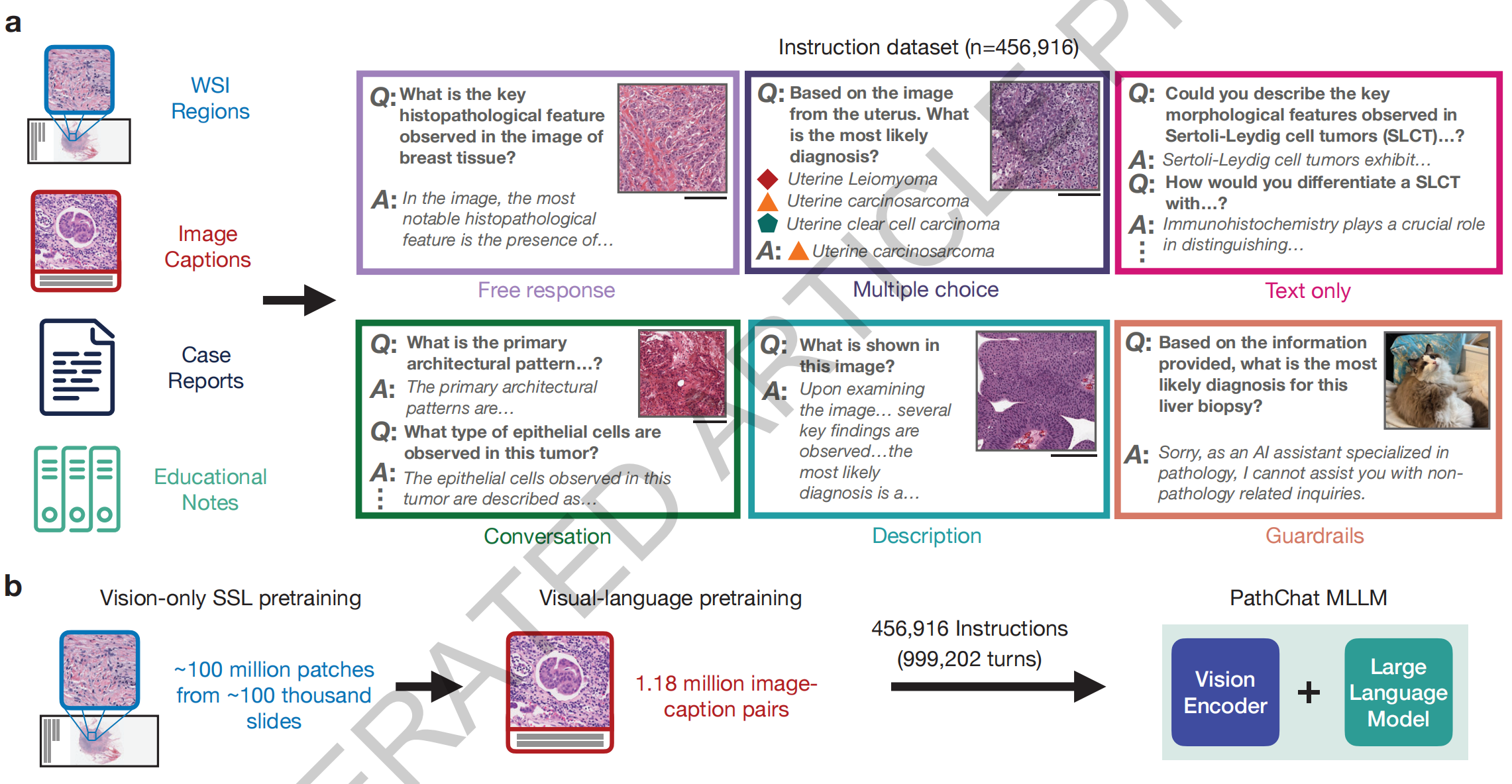
a. 指令遵循数据集的策划:
研究团队创建了目前最大的专门针对病理学领域的指令微调数据集,包含456,916条指令和相应的回应。这些指令和回应覆盖了多种形式,例如多轮对话、多项选择问题和简短回答。这些数据来自不同的来源,并且多样化,以确保PathChat能够处理各种类型的查询。
b. PathChat的构建:
为了构建一个基于多模态大型语言模型(MLLM)的视觉语言AI助手,研究团队采用了以下步骤:
- 从最先进的仅视觉自监督预训练基础编码器模型UNI开始,进行进一步的视觉-语言预训练,类似于CONCH模型。
- 将由此产生的视觉编码器与一个拥有130亿参数的预训练Llama 2大型语言模型(LLM)相连,通过一个多模态投影模块(图中未显示)形成完整的MLLM架构。
- 使用策划的指令遵循数据集对MLLM进行微调,构建了PathChat,这是一个专门用于人类病理学的视觉语言AI助手。
总的来说,Figure 1 展示了PathChat如何通过结合大规模的指令数据集和先进的MLLM架构,成为一个能够理解和回应病理学相关问题的AI系统。
二、“医学AI”如何与“人类价值观”和谐共存?

文献概述
这篇文章是一篇关于医学人工智能和人类价值的综述文章,发表在《新英格兰医学杂志》上。
文章讨论了生成性人工智能(AI)的最新进展,特别是大型语言模型(LLMs)在医学领域的应用,以及这些技术在实际使用中可能涉及的伦理困境和人类价值问题。
文章指出,尽管LLMs在撰写论文、通过专业能力考试以及撰写患者友好的信息方面展现出了令人印象深刻的能力,但人们对其在医学和保健领域的使用表达了担忧,包括编造事实、脆弱性和事实不准确等已知风险。文章强调,随着这些风险被衡量和缓解,一些悬而未决的问题开始显现,特别是关于AI模型中将嵌入的“人类价值”,以及这些“LLM的价值观”可能与人类价值观不一致的问题。
文章通过一个临床案例,讨论了价值判断如何进入预测模型,并且指出,即使是简单的临床方程式(如估算肾小球滤过率[eGFR])也展示了人类价值观和概率推理的许多原则。此外,文章还探讨了在AI模型开发和部署过程中,人类价值观如何通过不同的途径嵌入,以及如何在设计高性能和安全的AI模型时解决这些挑战。
文章还讨论了医疗决策分析的教训,以及如何通过测量人类价值观来指导AI在医学中的实施。作者提出了一些关键问题,包括应该在模型中编码哪些价值观、数据集变化如何影响AI模型的准确性和可靠性,以及除了直接测量效用之外的方法。
最后,文章得出结论,AI模型在训练和部署的每个阶段都会涉及人类价值观,这些价值观可能会随着个体患者和社会价值观的变化而变化。作者呼吁确保我们部署的AI模型能够准确并明确地反映患者的价值观和目标,并强调了负责任的医疗AI发展原则的重要性。
重点关注
人类价值观是如何在传统临床领域和AI模型中的不同阶段嵌入的。
这个框架强调了在数据训练、模型开发和模型使用过程中,人类决策的各个环节都可能引入价值观的考量。
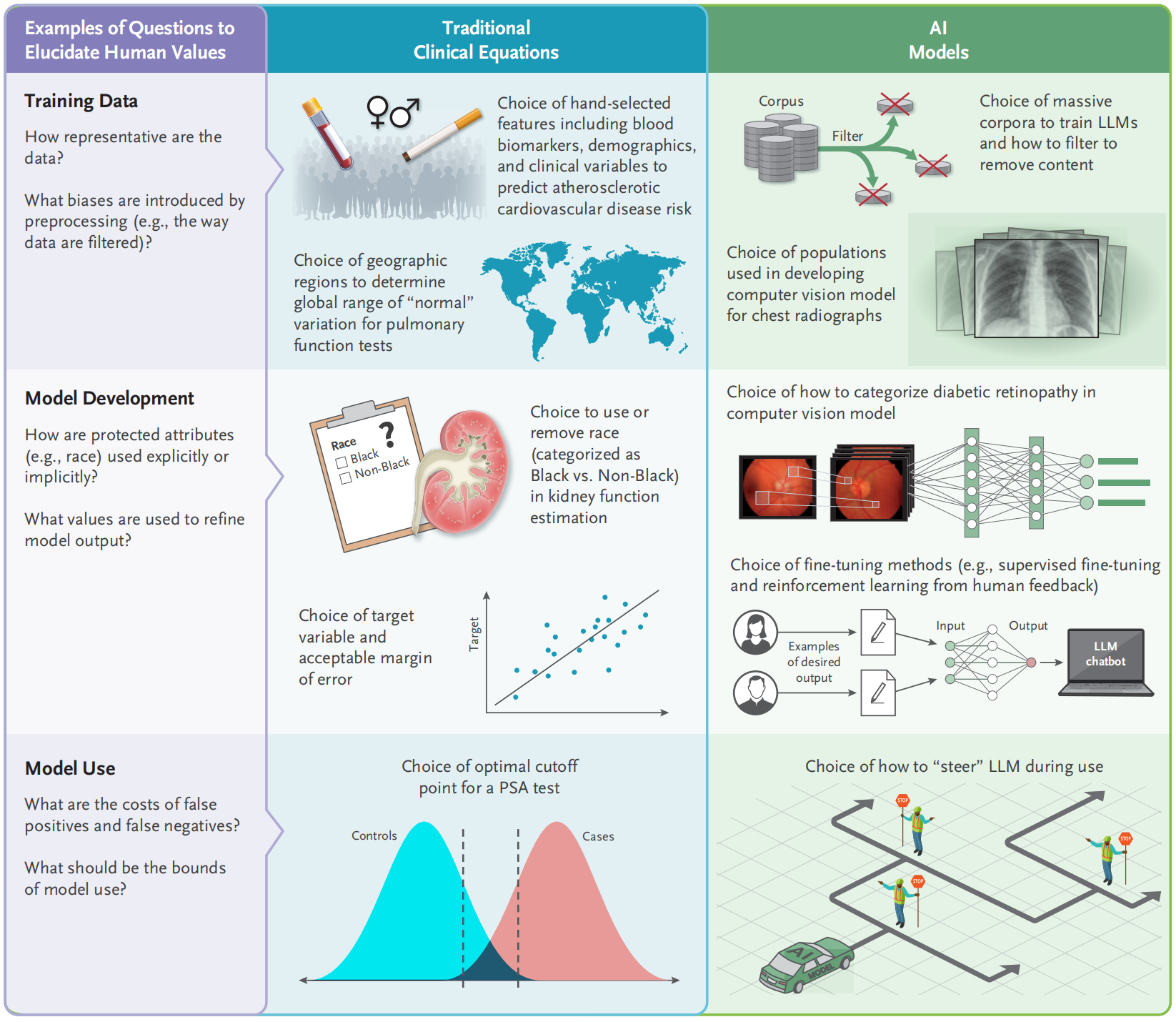
以下是对 Figure 2 的分析:
-
训练数据选择(Training Data):
- 传统临床方程式和AI模型都需要选择合适的训练数据集。在这一阶段,人类价值观可能会影响数据的选择和预处理方式,例如决定是否在eGFR方程中使用种族作为变量,或者在LLMs的训练语料库中过滤掉不当内容。
-
模型开发(Model Development):
- 在模型开发阶段,需要做出多个决策,这些决策可能会受到人类价值观的影响。例如,选择特定的生物标志物、人口统计数据和临床变量来预测动脉粥样硬化性心血管疾病风险;或者选择用于开发胸部X光计算机视觉模型的人群。
-
模型使用(Model Use):
- 模型使用阶段涉及到如何应用模型来做出临床决策。这可能包括选择目标变量、可接受的误差范围、如何根据模型输出进行“转向”(例如,LLMs在实际使用中的调整)等。
-
效用评估(Utility Elicitation):
- 效用评估是决策分析中的一个关键组成部分,它涉及到量化与特定健康状态或结果相关的价值。在传统方程式和AI模型中,都需要确定如何测量和量化效用,这可能涉及到个体患者或群体的偏好。
-
问题和决策点(Examples of Questions to Elucidate Human Values):
- 文章列出了一系列问题,这些问题可以帮助揭示在模型开发和使用过程中涉及的人类价值观。这些问题包括数据的代表性、预处理引入的偏差、特征选择、目标变量的选择、误差范围的确定等。
-
前列腺特异性抗原(PSA):
- 作为例子,PSA测试的阈值选择反映了人类价值观的考量,因为它涉及到对测试的敏感性和特异性的权衡。
Figure 2 强调了在医疗AI的整个生命周期中,从数据选择到模型部署,都需要考虑和明确人类价值观的角色。这有助于确保AI模型的开发和应用能够符合伦理标准,并且能够尊重和反映患者及社会的价值和偏好。
三、跨癌种自监督学习方法,利用未标注的病理切片区分不同亚型

文献概述
这篇文章介绍了一种名为“Histomorphological Phenotype Learning (HPL)”的自监督学习方法,用于在未经标注的病理切片上映射组织形态学癌症表型的景观。
这种方法不需要专家的标注即可自动识别图像瓦片中的区分性特征,并将瓦片聚类成形态学相似的集群,构成组织形态学表型图谱(HP-Atlas)。这些集群具有独特的特征,可以通过正交方法识别,并与组织学、分子和临床表型联系起来。
研究者将HPL应用于肺癌,发现这些集群与患者生存率、组织病理学认可的肿瘤类型和生长模式以及基于转录组的免疫表型测量紧密相关。这些属性在多癌种研究中得以保持。
文章还讨论了在组织学图像解释中减少人为偏差和提高效率的潜力,以及HPL在发现新的生物标记物和理解肿瘤微环境中复杂相互作用方面的潜力。此外,HPL方法的可解释性,允许病理学家检视组织模式及其与注释(如癌症类型、总生存率、无复发生存率或分子表型)的关系,为临床决策提供了有力的支持。
研究使用了来自癌症基因组图谱(The Cancer Genome Atlas, TCGA)的大量全切片图像(Whole Slide Images, WSIs),并结合了纽约大学(NYU)的独立队列,进行了多中心的数据验证。通过对这些图像的分析,研究者能够识别出与肺癌相关的多种组织形态学表型,并进一步将这些表型与临床结果相联系。
最后,文章还探讨了HPL在多癌种分析中的应用,展示了如何使用特定的分子特征来区分癌症亚型,或识别在多癌种分析中预测总生存率的通用癌症表型。
研究结果表明,HPL是一个强大的工具,可以在不同的癌症类型中识别和量化组织形态学表型,为癌症的诊断和管理提供了新的视角。
重点关注
组织形态学表型学习(HPL)框架架构概述
这个框架是一个自监督学习方法,用于分析未经标注的病理切片(Whole Slide Images, WSIs)。
下面是对图1中描述的HPL框架各部分的分析:
A. WSI处理和瓦片提取:
全切片图像首先被分割成固定大小的瓦片(tile),这些瓦片是图像的小块,用于后续的处理和分析。同时,对瓦片进行染色标准化处理,以确保不同图像之间的一致性。

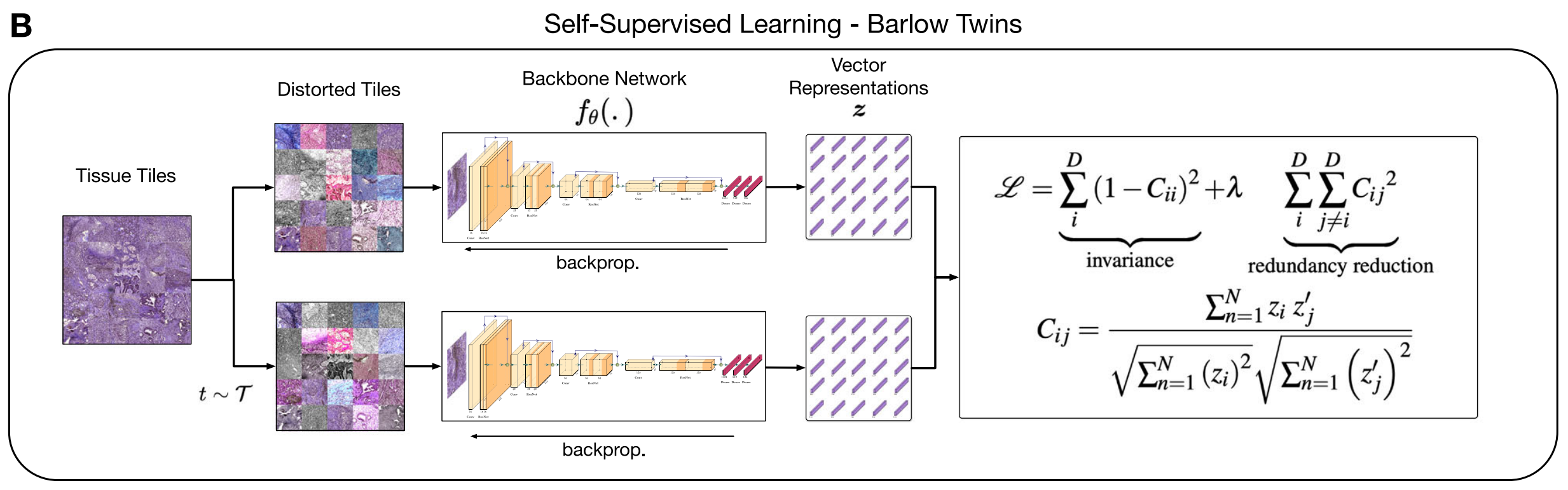
B. 自监督训练:
使用一个称为fθ的背景网络进行自监督训练。这个过程不需要病理学家的标注,而是通过设计好的预训练任务来学习图像瓦片的特征表示。这些特征表示被转换成向量形式,称为瓦片向量表示,它们捕捉了组织的视觉特征(例如纹理)。
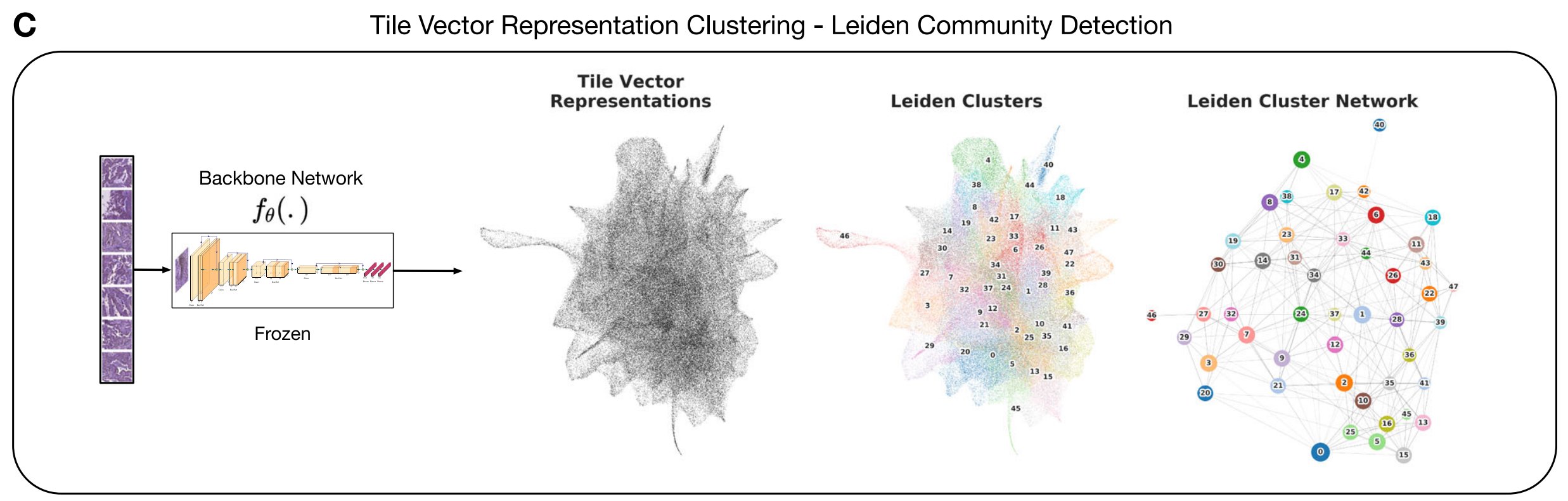
C. 瓦片向量表示和聚类:
通过使用训练好的背景网络fθ,将每个瓦片投影到一个固定维度的向量空间中,形成z向量表示。然后,基于这些z向量表示,使用最近邻图和Leiden社群检测算法来识别组织形态学表型聚类(Histomorphological Phenotype Clusters, HPCs)。这些聚类代表了具有共同形态学特征的瓦片集合。
D. WSI和患者向量表示:
每个WSI或患者(可能包含多个WSIs)通过一个组合向量来定义,这个向量的维度等于HPCs的数量,并且每个维度表示相应HPC在总组织面积中所占的百分比。这样,HPL创建了WSI和患者的组合向量表示,这些表示可以很容易地用于可解释的模型,如逻辑回归或Cox回归分析,从而将组织表型与临床注释相关联。
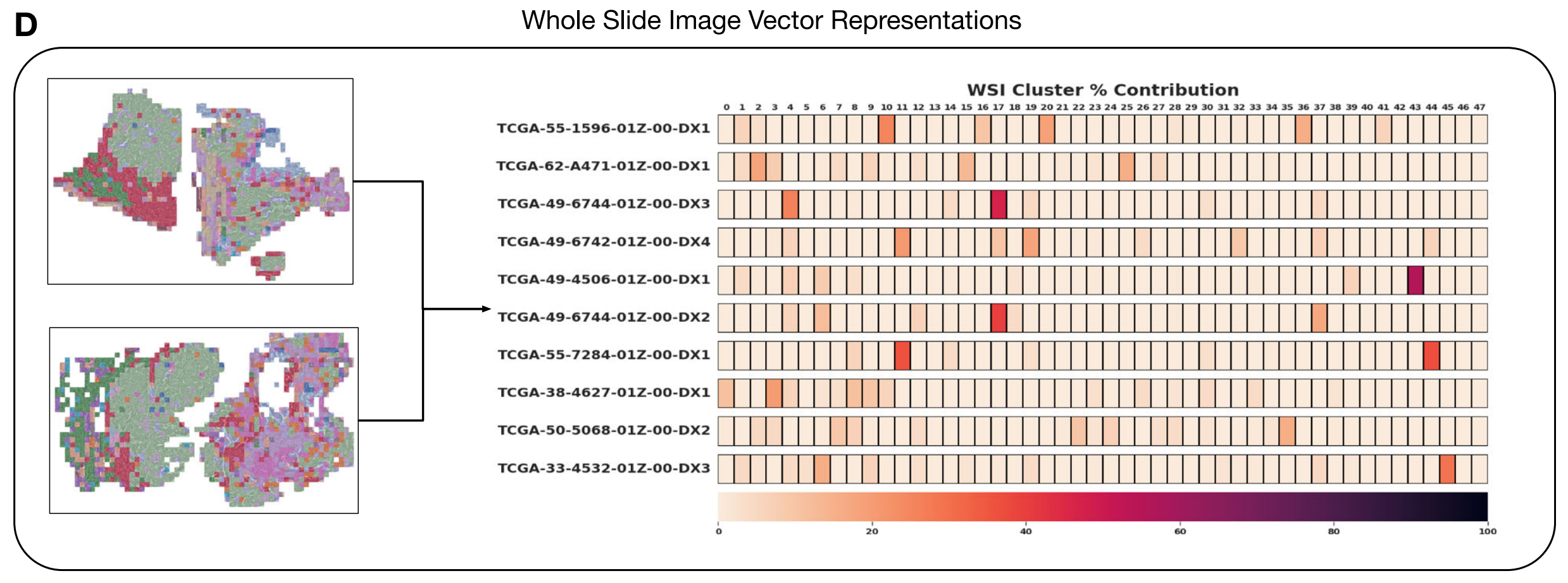
整个HPL框架的设计允许从大量未标注的病理图像中自动发现和量化组织形态学表型,并将这些表型与临床结果联系起来,为病理诊断和癌症管理提供了一种新的分析方法。此外,提供的数据源文件包含了用于生成这些结果的原始数据。
四、一种基于“互学习变换器”的完全无监督病理切片分类方法

文献概述
这篇文章是关于一种新型的无监督学习算法,用于对多千兆像素级别的全切片图像(Whole Slide Images, WSIs)进行分类。
这种算法特别适用于计算病理学领域,尤其是癌症检测或预测细胞突变等临床应用。由于大多数现有的监督学习方法需要专家病理学家进行昂贵且耗时的手动注释,因此这项研究提出了一种基于互学习变换器(mutual transformer learning)的完全无监督的WSI分类算法。
该算法将来自千兆像素WSIs的实例(即图像块)转换到潜在空间,然后逆变换回原始空间。通过变换损失生成伪标签,并使用变换器标签清洁器进行清洁。所提出的基于变换器的伪标签生成器和清洁器模块以无监督的方式相互迭代训练。此外,引入了一种判别学习机制来提高正常与癌细胞实例标记的性能。
文章还展示了该框架在弱监督学习和癌症亚型分类作为下游分析方面的有效性。通过在四个公开可用的数据集上进行广泛的实验,证明了所提出算法与现有最先进方法相比具有更好的性能。
重点关注
用于 WSI 分类任务的不同类型监督方法之间的比较。
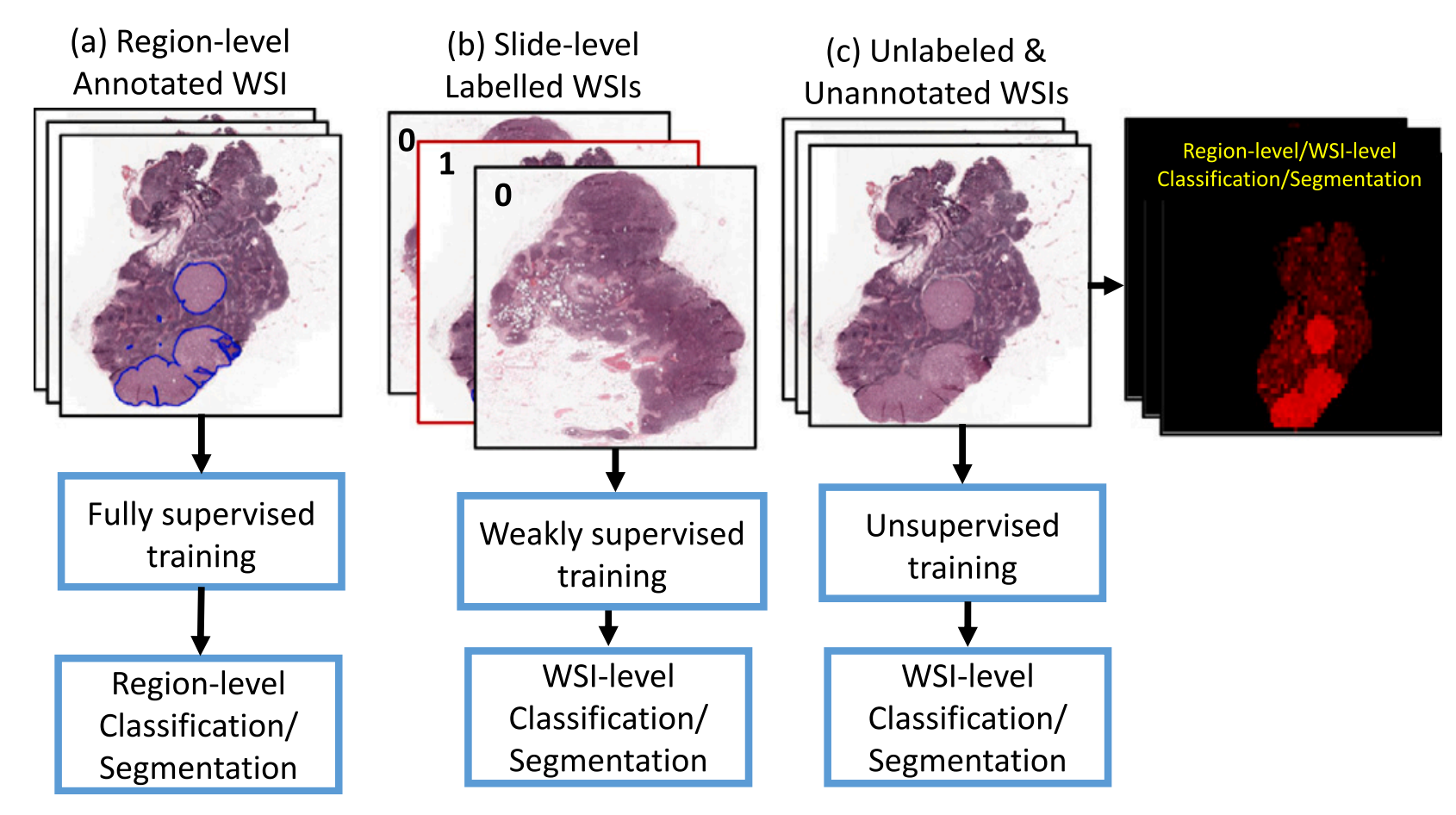
图中分为三个部分:
(a) 完全监督训练:
需要对正常或肿瘤区域进行区域级别的注释。这意味着在训练过程中,需要专家精确地标记出图像中每个区域是正常组织还是肿瘤组织。这种方法在训练深度学习模型时能够提供非常精确的监督信号,但同时也需要大量的专家工作,因此成本较高。
(b) 弱监督训练:
只需要切片级别的标签。在这种方法中,不需要对每个区域进行详细的注释,只需要为整个切片提供一个总体的标签,例如是否包含肿瘤。这减少了专家的工作量,但仍然提供了一定程度的监督信息,使得模型能够在较低的成本下进行训练。
© 所提出的无监督训练:
不需要区域级别的注释,也不需要切片级别的标签。这是本文研究的重点,即开发一种完全不需要人工注释的 WSI 分类算法。该算法能够自动从未标记的数据中学习,并预测肿瘤区域。图中检测图中的红色区域表示使用所提出的无监督算法预测的肿瘤区域,这显示了算法在没有人工标注的情况下识别肿瘤的能力。
总的来说,Fig. 1 强调了从完全监督到弱监督再到无监督训练的转变,以及每种方法在数据标注需求和可能的分类性能之间的权衡。无监督训练方法的发展,特别是本文提出的算法,旨在减少对专家标注的依赖,从而降低成本并提高病理图像分析的可扩展性。
五、AI的历史、主要研究领域、发展以及应用

文献概述
这篇文章提供了对人工智能(AI)领域的全面概述,包括其历史、主要研究领域、发展以及应用。
文章首先定义了AI作为一门科学和工程学科,它涉及开发表现出人类智能行为特征的系统,例如感知、自然语言处理、问题解决、规划、学习和适应,以及对环境的行动。AI的目标是理解使人类、动物和人工代理表现出智能行为的原理,这直接支持了多个工程目标,如开发智能代理、在人类所有领域中形式化知识和机械化推理、使与计算机的协作变得像与人合作一样容易,以及开发利用人类和自动化推理互补性的人工智能系统。
文章接着简要回顾了AI的历史,从1956年达特茅斯会议开始,早期的AI研究集中在简单的“玩具”领域,并取得了一些令人印象深刻的成果。然而,尝试将这些方法应用于复杂现实世界问题时,却屡屡遭遇失败,导致了所谓的“AI冬天”,即AI研究资金的大幅削减。
文章随后详细介绍了AI的几个主要研究领域,包括知识表示、问题解决和规划、知识获取和学习、自然语言处理、视觉、行动处理和机器人技术。每个领域都有其特定的方法和应用,例如,知识表示关注代理如何通过操作内部表示来推理环境;问题解决和规划包括搜索和启发式方法,用于在大问题空间中寻找解决方案;知识获取和学习涉及从用户、数据或自身经验中获取知识,以提高代理解决问题的能力。
文章还讨论了AI系统如何使用代理隐喻来描述,并指出虽然大多数当前的AI代理没有图1中所有组件,或者某些组件功能有限,但它们通过各种方式为复杂应用添加智能。此外,文章强调了AI技术的跨学科特性,它与计算学科、数学、语言学、心理学、神经科学、机械工程、统计学、经济学、控制理论和控制论、哲学等多个领域都有交集。
最后,文章总结了智能代理的重要性,指出它们可以帮助人类克服注意力有限、分析能力有限或受压力、疲劳或时间限制影响的记忆等局限。智能代理能够快速、严谨、精确、明确和客观地工作,但它们缺乏常识和处理新情况的能力。
相比之下,人类虽慢、易犯错、健忘、含蓄和主观,但具有常识和直觉,能在新情况下找到创造性的解决方案。人类和代理可以进行混合主动推理,利用它们互补的优势和推理风格。因此,智能代理使我们能够更好地执行任务,并帮助我们应对全球化和向知识经济快速发展所带来的日益增长的挑战。
重点关注
基于知识的智能代理的主要模块。
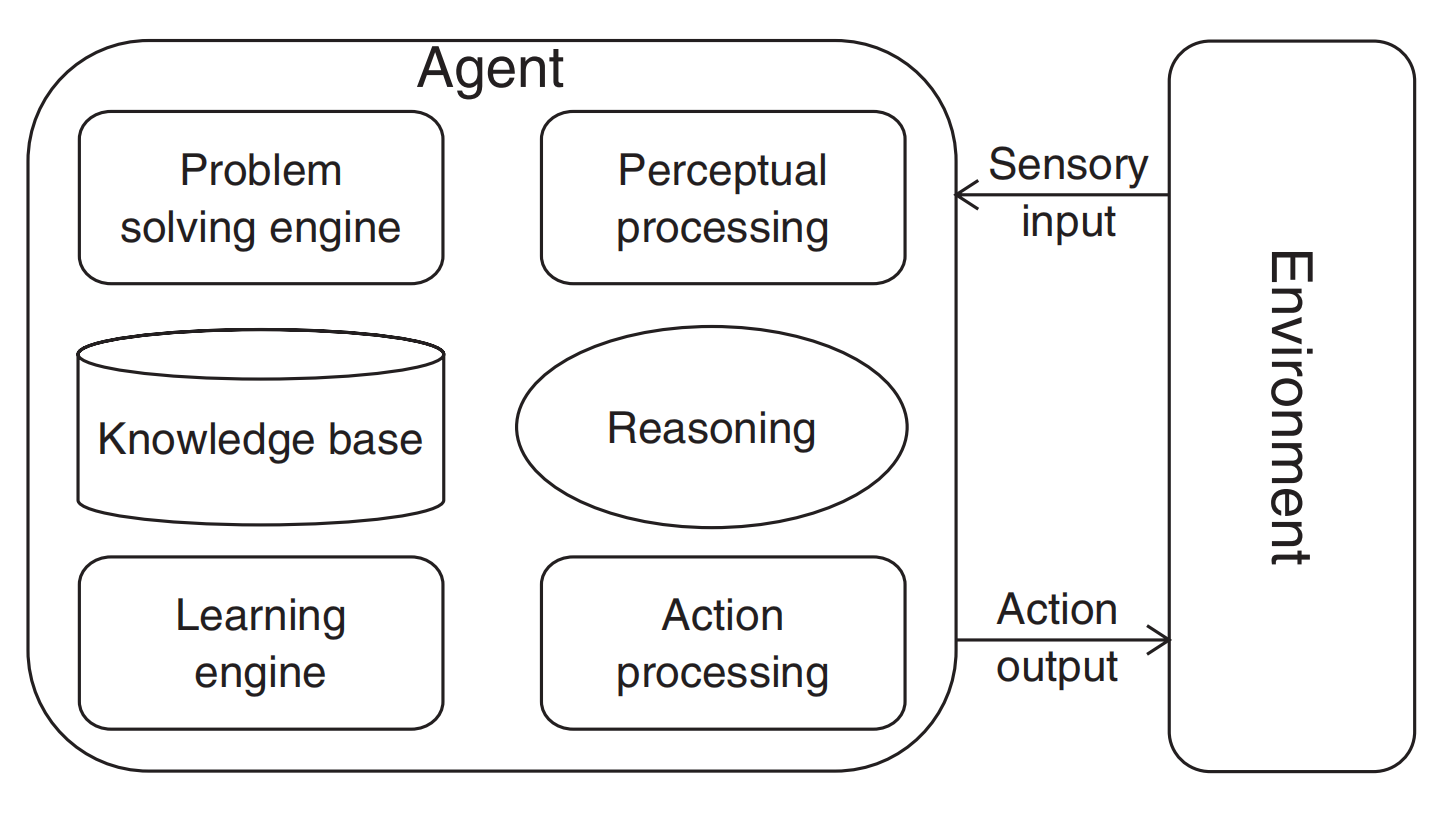
智能代理是一个能够感知环境、推理解释感知、解决问题、确定行动,并在环境中实现目标或任务的系统。
以下是对图1中智能代理主要模块的分析:
-
感知处理(Perceptual processing):代理使用传感器接收来自环境的输入,这些输入可以是物理世界的数据,用户通过图形用户界面的输入,或其他代理、互联网等的信息。
-
知识库(Knowledge base):代理存储有关环境的知识,包括对象、关系、规则等。知识库是代理进行推理和解决问题的基础。
-
推理(Reasoning):代理使用知识库中的知识进行逻辑推理,解释感知输入,并从中得出结论。
-
问题解决引擎(Problem solving engine):这个引擎使用知识库和推理能力来解决具体问题,寻找满足目标或任务的解决方案。
-
学习引擎(Learning engine):代理通过这个引擎从输入数据、用户交互、其他代理或自身的问题解决经验中学习,不断改进其知识和性能。
-
行动处理(Action processing):代理决定并执行行动来影响环境,实现其目标或任务。
-
传感器输入(Sensory input):代理通过传感器接收外部环境的信息。
-
行动输出(Action output):代理通过执行器对环境产生影响,如移动机器人臂或发送命令。
-
环境(Environment):代理与之交互的外部世界或系统。
智能代理的架构体现了知识与控制的分离,知识库负责存储数据结构,而问题解决引擎则负责实施基于知识库知识的通用问题解决方法。
这种分离允许更有效地组织和使用知识,同时也支持代理的自主性和适应性。通过持续学习和改进,智能代理能够更好地理解和响应其环境,实现更加复杂和动态的任务。
六、HECTOR|用于预测子宫内膜癌患者远处复发风险的多模态模型

文献概述
这篇文章是发表在《Nature Medicine》上的一项研究,我前两天的推文也推荐过这篇文章,为什么要再次拿出来说呢?因为……我明天有一篇推文就是关于这篇文献的精析。
研究团队开发了一个名为HECTOR(histopathology-based endometrial cancer tailored outcome risk)的多模态深度学习预测模型,用于预测子宫内膜癌患者的远处复发风险。
HECTOR模型利用苏木精-伊红染色的全切片图像(whole-slide images, WSIs)和肿瘤分期作为输入,对来自八个子宫内膜癌队列的2072名患者进行了训练和测试,包括PORTEC-1/-2/-3随机试验。
HECTOR模型在内部测试集(353名患者)和两个外部测试集(分别为160名和151名患者)上展示了出色的预测性能,C指数(concordance index, C-index)分别为0.789、0.828和0.815,超过了当前的金标准。此外,HECTOR模型还能更好地预测辅助化疗的效果。通过对形态学和基因组特征的提取,研究团队发现了与HECTOR风险组相关的因素,其中一些具有治疗潜力。
HECTOR模型的开发为个性化治疗提供了新的工具,有助于改善子宫内膜癌患者的治疗决策。研究还探讨了HECTOR模型的解释性,通过分析模型风险评分与已知预后因素的关联,以及输入数据对预测的贡献,为理解HECTOR模型提供了更深入的生物学见解。
研究结果表明,HECTOR模型在预测远处复发风险方面具有潜力,并且可能成为未来临床实践中的一个有效工具。
重点关注
HECTOR模型的概览
a部分:
- 描述了从
子宫内膜癌(EC)的苏木精-伊红染色全切片图像(H&E WSI)中分割组织,并将其划分为180微米大小的区域(称为patches)的过程。 - 使用
多阶段视觉变换器(multistage vision transformer),通过自监督学习的方法,从1862名患者的WSIs中随机抽取图像块进行训练,这些患者不包括在内部和外部测试集中。 - 从变换器的最后八个块中提取图像块级别的特征。
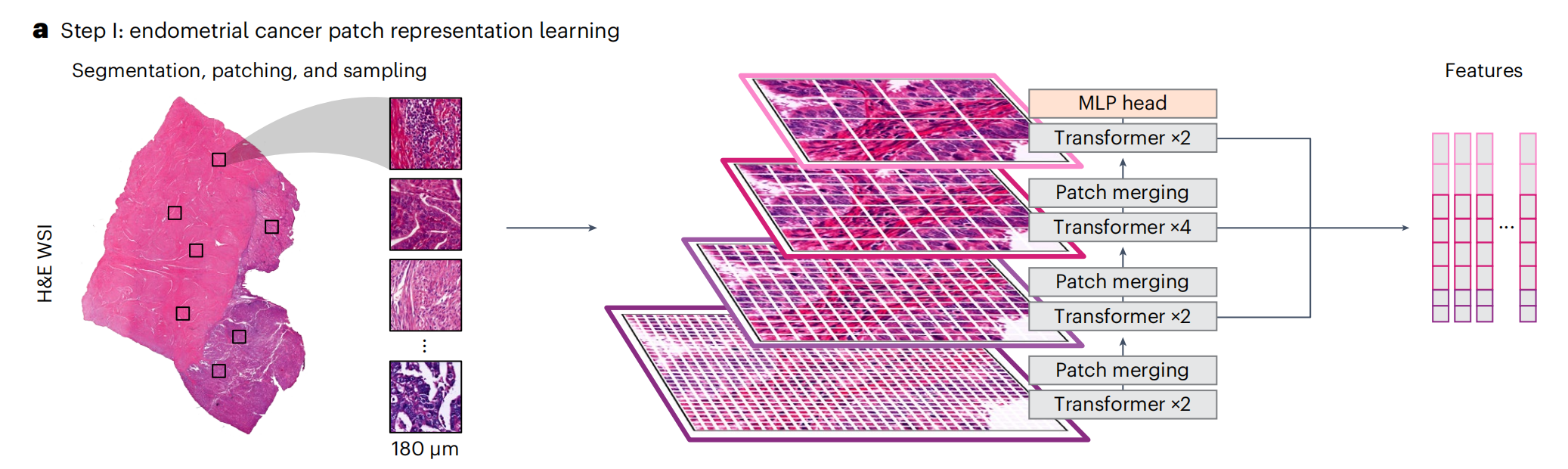
b部分:
- 展示了HECTOR模型如何接受H&E WSI和根据FIGO 2009标准分类的解剖学分期(I-III期)作为输入。
- 提取的图像块级特征在空间和语义上进行了平均处理。
- 这些特征被输入到一个
基于注意力机制的多重实例学习模型(attention-based multiple instance learning model)和im4MEC深度学习模型中(所有层都是冻结的),后者能够从H&E WSI预测分子类别,如imPOLEmut、imMMRd、imNSMP或imp53abn。 - 解剖学分期和基于图像的分子类别都通过嵌入层(Embedding layers)进行处理。
- 使用
基于门控的注意力机制(gating-based attention)对这三个嵌入结果进行加权,然后通过Kronecker积进行融合。 - 使用
负对数似然损失函数(−log(likelihood loss))来预测在离散时间上的无远处复发概率函数。 - 风险评分定义为综合预测概率。
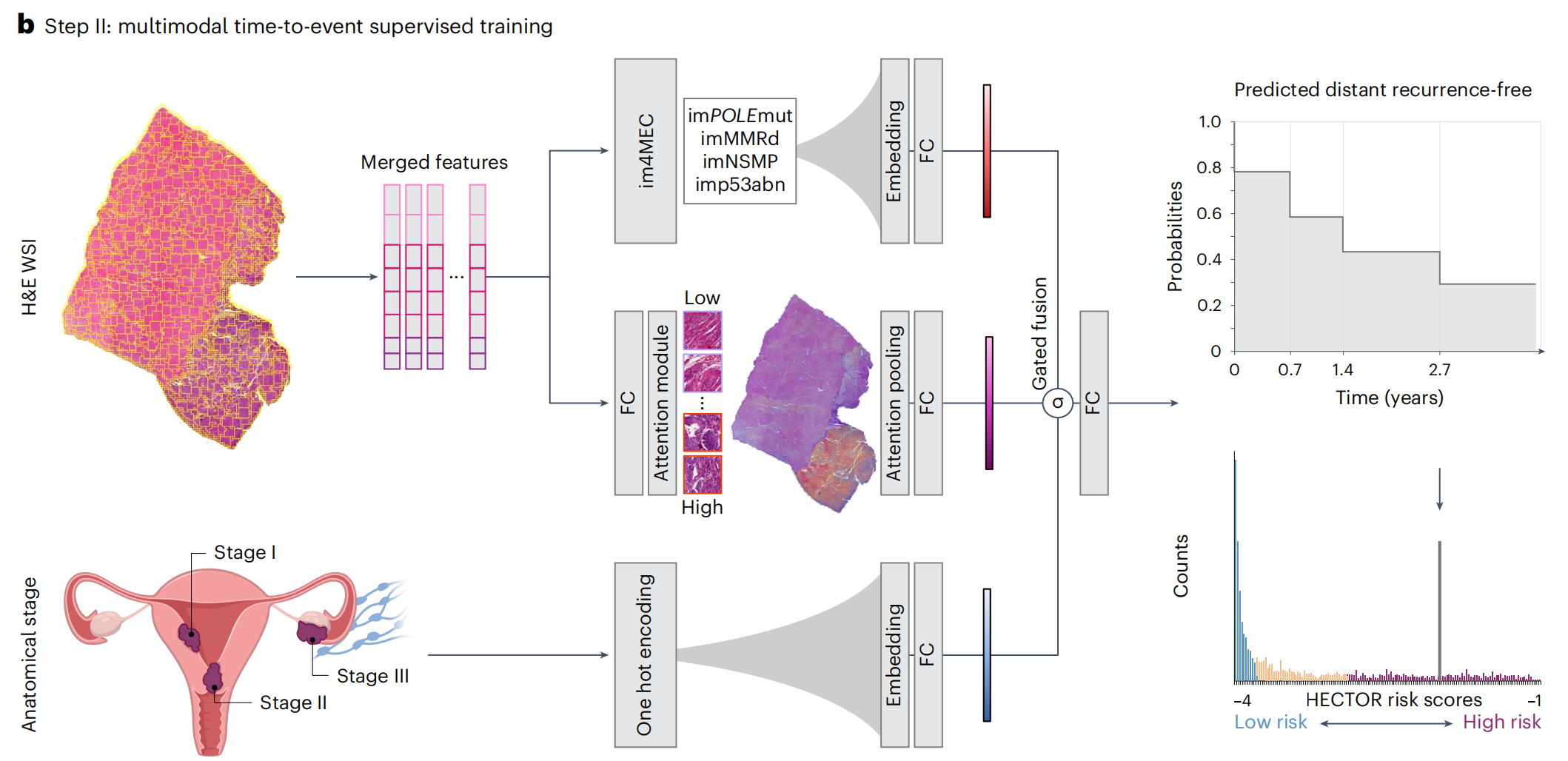
此外,图1还提到了多层面感知器(MLP, multilayer perceptron)和全连接层(FC, Fully Connected layer),这些是深度学习中常见的网络结构,用于处理和学习数据特征。
总体而言,HECTOR模型通过结合组织形态学特征、分子类别和解剖学分期信息,使用深度学习技术来预测子宫内膜癌患者的远处复发风险。