控制反转(Inversion of Control,IoC)与 面向切面编程(Aspect Oriented Programming,AOP)是 Spring Framework 中最重要的两个概念,本章会着重介绍前者,内容包括 IoC 容器以及容器中 Bean 的基础知识。容器为我们预留了不少扩展点,让我们能定制各种行为,本章的最后我会和大家一起了解一些容器提供的抽象机制。通过这些介绍,希望大家可以对 IoC 容器有个大概的认识。
2.1 IoC 容器基础知识
Spring Framework 为 Java 开发者提供了强大的支持,开发者可以把底层基础的杂事抛给 Spring Framework,自己则专心于业务逻辑。本节我们会聚焦在 Spring Framework 的核心能力上,着重了解 IoC 容器的基础知识。
2.1.1 什么是 IoC 容器
在介绍 Spring Framework 的 IoC 容器前,我们有必要先理解什么是“控制反转”。 控制反转 是一种决定容器如何装配组件的 模式。只要遵循这种模式,按照一定的规则,容器就能将组件组装起来。这里所谓的 容器,就是用来创建组件并对它们进行管理的地方。它牵扯到组件该如何定义、组件该何时创建、又该何时销毁、它们互相之间是什么关系等——这些本该在组件内部管理的东西,被从组件中剥离了出来。
需要着重指出一点,组件之间的依赖关系原先是由组件自己定义的,并在其内部维护,而现在这些依赖被定义在容器中,由容器来统一管理,并据此将其依赖的内容注入组件中。在好莱坞,演艺公司具有极大的控制权,艺人将简历投递给演艺公司后就只能等待,被动接受演艺公司的安排。这就是知名的好莱坞原则,它可以总结为这样的一句话“不要给我们打电话,我们会打给你的”(Don’t call us, we’ll call you)。IoC 容器背后的思想正是好莱坞原则,即所有的组件都要被动接受容器的控制。
Martin Fowler那篇著名的“Inversion of Control Containers and the Dependency Injection pattern” 中提到“控制反转”不能很好地描述这个模式,“依赖注入”(Dependency Injection)能更好地描述它的特点。正因如此,我们经常会看到这两个词一同出现。
Spring Framework、Google Guice、PicoContainer 都提供了这样的容器,后文中我们也会把 Spring Framework 的 IoC 容器称为 Spring 容器。
图 2-1 是 Spring Framework 的官方文档中的一幅图,它非常直观地表达了 Spring IoC 容器的作用,即将业务对象(也就是组件,在 Spring 中这些组件被称为 Bean,2.2 节会详细介绍 Bean 的内容)和关于组件的配置元数据(比如依赖关系)输入 Spring 容器中,容器就能为我们组装出一个可用的系统。
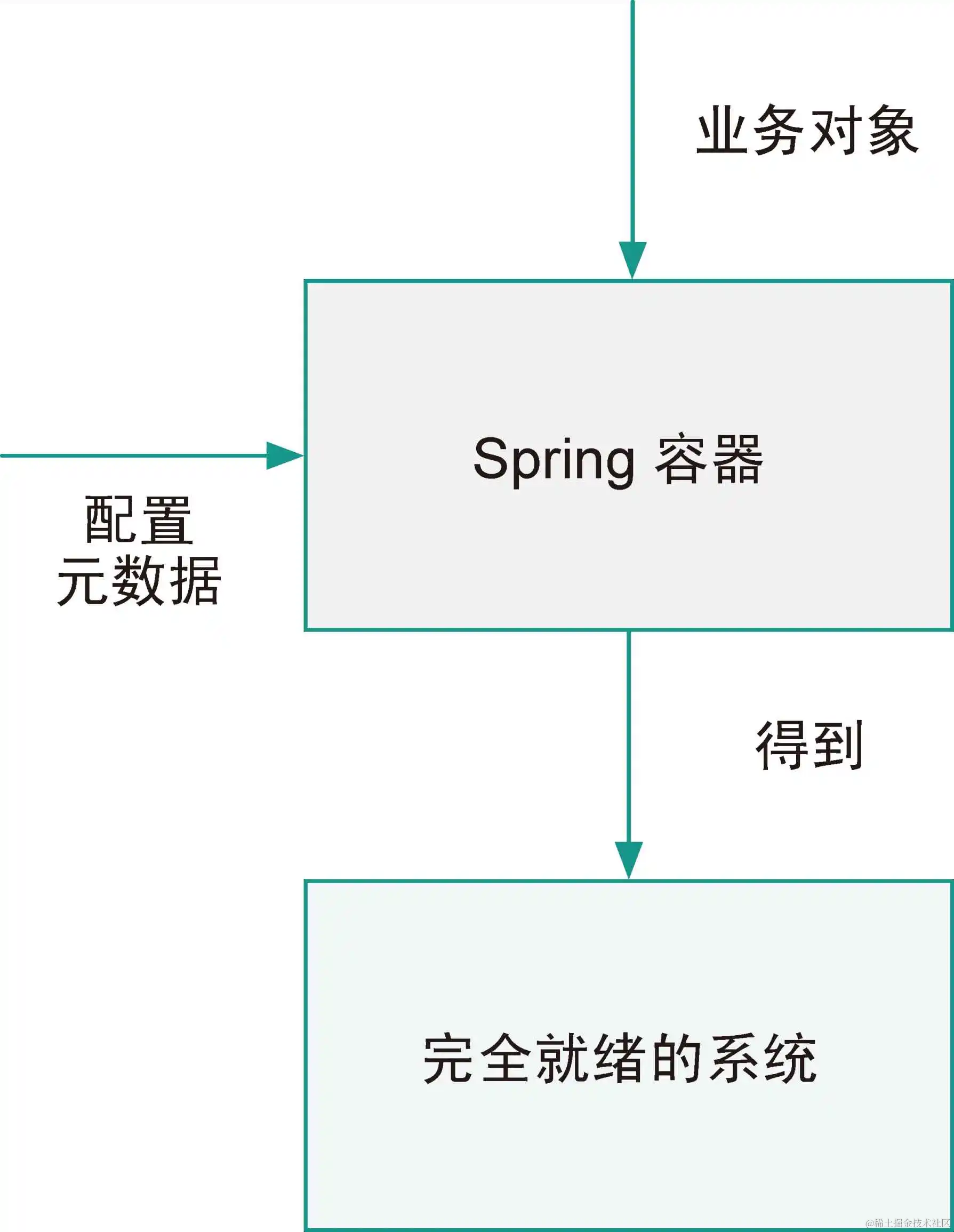
图 2-1 Spring IoC 容器
Spring Framework 的模块按功能进行了拆分,spring-core 和 spring-beans 模块提供了最基础的功能,其中就包含了 IoC 容器。 BeanFactory 是容器的基础接口,我们平时使用的各种容器都是它的实现,后文中会看到这些实现的具体用法与区别。
2.1.2 容器的初始化
从图 2-1 中可以看到,Spring 容器需要配置元数据和业务对象,因此在初始化容器时,我们需要提供这些信息。早期的配置元数据只能以 XML 配置文件的形式提供,从 2.5 版本开始,官方逐步提供了 XML 文件以外的配置方式,比如基于注解的配置和基于 Java 类的配置,本书中的大部分示例将采用后两种方式进行配置。
容器初始化的大致步骤如下(在本章后续的几节中,我们会分别介绍其中涉及的内容)。
(1) 从 XML 文件、Java 类或其他地方加载配置元数据。
(2) 通过 BeanFactoryPostProcessor 对配置元数据进行一轮处理。
(3) 初始化 Bean 实例,并根据给定的依赖关系组装对象。
(4) 通过 BeanPostProcessor 对 Bean 进行处理,期间还会触发 Bean 被构造后的回调方法。
比如,我们有一个如代码示例 2-1 所示的业务对象,它会返回一个字符串,可以看到它就是一个最普通的 Java 类。
代码示例 2-1 最基本的 Hello 类
package learning.spring.helloworld;
public class Hello {
public String hello() {
return "Hello World!";
}
}
在没有 IoC 容器时,我们需要像代码示例 2-2 那样自己管理 Hello 实例的生命周期,通常是在代码中用 new 关键字新建一个实例,然后把它传给具体要调用它的对象,下面的代码只是个示意,所以就使用 new 关键字创建实例后直接调用方法了。
代码示例 2-2 手动创建并调用 Hello.hello() 方法
public class Application {
public static void main(String[] args) {
Hello hello = new Hello();
System.out.println(hello.hello());
}
}
如果是把实例交给 Spring 容器托管,则可以将它配置到一个 XML 文件中,让容器来管理它的相关生命周期。可以看到代码示例 2-3 只是一个普通的 XML 文件,通过 <beans/> 这个 Schema 来配置 Spring 的 Bean(Bean 的配置会在 2.2.2 节详细展开)。为了使用 Spring 的容器,需要在 pom.xml 文件中引入 org.springframework:spring-beans 依赖。
代码示例 2-3 配置 hello Bean 的 beans.xml 文件
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://www.springframework.org/schema/beans
https://www.springframework.org/schema/beans/spring-beans.xsd">
<bean id="hello" class="learning.spring.helloworld.Hello" />
</beans>
最后像代码示例 2-4 那样,将配置文件载入容器。 BeanFactory 只是一个最基础的接口,我们需要选择一个合适的实现类——在实际工作中,更多情况下会用到 ApplicationContext 的各种实现。此处,我们使用 DefaultListableBeanFactory 这个实现类,它并不关心配置的方式, XmlBeanDefinitionReader 能读取 XML 文件中的元数据,我们通过它加载 CLASSPATH 中的 beans.xml 文件,将其保存到 DefaultListableBeanFactory 中,随后就可以通过 BeanFactory 的 getBean() 方法取得对应的 Bean 了。
getBean() 方法有很多不同的参数列表,例子里就有两种,一种是取出 Object 类型的 Bean,然后自己做类型转换;另一种则是在参数里指明返回 Bean 的类型,如果实际类型不同的话则会抛出 BeansException。
代码示例 2-4 加载配置文件并执行的 Application 类代码片段
public class Application {
private BeanFactory beanFactory;
public static void main(String[] args) {
Application application = new Application();
application.sayHello();
}
public Application() {
beanFactory = new DefaultListableBeanFactory();
XmlBeanDefinitionReader reader =
new XmlBeanDefinitionReader((DefaultListableBeanFactory) beanFactory);
reader.loadBeanDefinitions("beans.xml");
}
public void sayHello() {
// Hello hello = (Hello) beanFactory.getBean("hello");
Hello hello = beanFactory.getBean("hello", Hello.class);
System.out.println(hello.hello());
}
}
在这个例子的 sayHello() 方法中,我们完全不用关心 Hello 这个类的实例是如何创建的,只需获取实例对象然后使用即可。虽然看起来比代码示例 2-3 的行数要多,但当工程复杂度增加之后,IoC 托管 Bean 生命周期的优势就体现出来了。
2.1.3 BeanFactory 与 ApplicationContext
spring-context 模块在 spring-core 和 spring-beans 的基础上提供了更丰富的功能,例如事件传播、资源加载、国际化支持等。前面说过, BeanFactory 是容器的基础接口, ApplicationContext 接口继承了 BeanFactory,在它的基础上增加了更多企业级应用所需要的特性,通过这个接口,我们可以最大化地发挥 Spring 上下文的能力。表 2-1 列举了常见的一些 ApplicationContext 实现。
表 2-1 常见的 ApplicationContext 实现
| 类名 | 说明 |
|---|---|
| ClassPathXmlApplicationContext | 从 CLASSPATH 中加载 XML 文件来配置ApplicationContext |
| FileSystemXmlApplicationContext | 从文件系统中加载 XML文件来配置ApplicationContext |
| AnnotationConfigApplicationContext | 根据注解和 Java 类配置ApplicationContext |
相比 BeanFactory,使用 ApplicationContext 也会更加方便一些,因为我们无须自己去注册很多内容,例如 AnnotationConfigApplicationContext 把常用的一些后置处理器都直接注册好了,为我们省去了不少麻烦。所以,在绝大多数情况下,建议大家使用 ApplicationContext 的实现类。
如果要将代码示例 2-4 中的 Application.java 从使用 BeanFactory 修改为使用 ApplicationContext,只需做两处改动:
(1) 在 pom.xml 文件中,把引入的 org.springframework:spring-beans 修改为 org.springframework: spring-context;
(2) 在 Application.java 中,使用 ClassPathXmlApplicationContext 代替 DefaultListableBeanFactory 和 XmlBeanDefinitionReader 的组合,具体见代码示例 2-5。
代码示例 2-5 调整后的 Application 类代码片段
public class Application {
private ApplicationContext applicationContext;
public static void main(String[] args) {
Application application = new Application();
application.sayHello();
}
public Application() {
applicationContext = new ClassPathXmlApplicationContext("beans.xml");
}
public void sayHello() {
Hello hello = applicationContext.getBean("hello", Hello.class);
System.out.println(hello.hello());
}
}
2.1.4 容器的继承关系
Java 类之间有继承的关系,子类能够继承父类的属性和方法。同样地,Spring 的容器之间也存在类似的继承关系,子容器可以继承父容器中配置的组件。在使用 Spring MVC 时就会涉及容器的继承。
先来看一个例子,如代码示例 2-6 所示(修改自上一节的 HelloWorld), Hello 类在输出的字符串中加入一段注入的信息。
代码示例 2-6 可以输出特定信息的 Hello 类
package learning.spring.helloworld;
public class Hello {
private String name;
public String hello() {
return "Hello World! by " + name;
}
public void setName(String name) {
this.name = name;
}
}
随后,我们也要调整一下 XML 配置文件,父容器与子容器分别用不同的配置,ID 既有相同的,也有不同的,具体如代码示例 2-7 与代码示例 2-8 所示。
代码示例 2-7 父容器配置 parent-beans.xml 文件
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://www.springframework.org/schema/beans
https://www.springframework.org/schema/beans/spring-beans.xsd">
<bean id="parentHello" class="learning.spring.helloworld.Hello">
<property name="name" value="PARENT" />
</bean>
<bean id="hello" class="learning.spring.helloworld.Hello">
<property name="name" value="PARENT" />
</bean>
</beans>
代码示例 2-8 子容器配置 child-beans.xml 文件
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://www.springframework.org/schema/beans
https://www.springframework.org/schema/beans/spring-beans.xsd">
<bean id="childHello" class="learning.spring.helloworld.Hello">
<property name="name" value="CHILD" />
</bean>
<bean id="hello" class="learning.spring.helloworld.Hello">
<property name="name" value="CHILD" />
</bean>
</beans>
在 Application 类中,我们尝试从不同的容器中获取不同的 Bean(关于 Bean 的内容,我们会在 2.2 节展开),以测试继承容器中 Bean 的可见性和覆盖情况,具体如代码示例 2-9 所示。
代码示例 2-9 修改后的 Application 类代码片段
public class Application {
private ClassPathXmlApplicationContext parentContext;
private ClassPathXmlApplicationContext childContext;
public static void main(String[] args) {
new Application().runTests();
}
public Application() {
parentContext = new ClassPathXmlApplicationContext("parent-beans.xml");
childContext = new ClassPathXmlApplicationContext(
new String[] {"child-beans.xml"}, true, parentContext);
parentContext.setId("ParentContext");
childContext.setId("ChildContext");
}
public void runTests() {
testVisibility(parentContext, "parentHello");
testVisibility(childContext, "parentHello");
testVisibility(parentContext, "childHello");
testVisibility(childContext, "childHello");
testOverridden(parentContext, "hello");
testOverridden(childContext, "hello");
}
private void testVisibility(ApplicationContext context, String beanName) {
System.out.println(context.getId() + " can see " + beanName + ": "
+ context.containsBean(beanName));
}
private void testOverridden(ApplicationContext context, String beanName) {
System.out.println("sayHello from " + context.getId() +": "
+ context.getBean(beanName, Hello.class).hello());
}
}
这段程序的运行结果如下:
ParentContext can see parentHello: true
ChildContext can see parentHello: true
ParentContext can see childHello: false
ChildContext can see childHello: true
sayHello from ParentContext: Hello World! by PARENT
sayHello from ChildContext: Hello World! by CHILD
通过这个示例,我们可以得出如下关于容器继承的通用结论——它们和 Java 类的继承非常相似,二者的对比如表 2-2 所示。
表 2-2 容器继承 vs . Java 类继承
| 容器继承 | Java 类继承 |
|---|---|
| 子上下文可以看到父上下文中定义的 Bean,反之则不行 | 子类可以看到父类的 protected 和 public 属性和方法,父类看不到子类的 |
| 子上下文中可以定义与父上下文同 ID 的 Bean,各自都能获取自己定义的 Bean | 子类可以覆盖父类定义的属性和方法 |
关于同 ID 覆盖 Bean,有时也会引发一些意料之外的问题。如果希望关闭这个特性,也可以考虑禁止覆盖,通过容器的 setAllowBeanDefinitionOverriding() 方法可以控制这一行为。
2.2 Bean 基础知识
Bean 是 Spring 容器中的重要概念,这一节就让我们来着重了解一下 Bean 的概念、如何注入 Bean 的依赖,以及如何在容器中进行 Bean 的配置。
2.2.1 什么是 Bean
Java 中有个比较重要的概念叫做“JavaBeans”,维基百科中有如下描述:
JavaBeans 是 Java 中一种特殊的类,可以将多个对象封装到一个对象(Bean)中。特点是可序列化,提供无参构造器,提供
Getter方法和Setter方法访问对象的属性。名称中的 Bean 是用于 Java 的可重用软件组件的惯用叫法。
从中可以看到: Bean 是指 Java 中的 可重用软件组件,Spring 容器也 遵循 这一惯例,因此将容器中管理的可重用组件称为 Bean。容器会根据所提供的元数据来创建并管理这些 Bean,其中也包括它们之间的依赖关系。Spring 容器对 Bean 并没有太多的要求,无须实现特定接口或依赖特定库,只要是最普通的 Java 对象即可,这类对象也被称为 POJO(Plain Old Java Object)。
一个 Bean 的定义中,会包含如下部分:
- Bean 的名称,一般是 Bean 的
id,也可以为 Bean 指定别名(alias); - Bean 的具体类信息,这是一个全限定类名;
- Bean 的作用域,是单例(singleton)还是原型(prototype);
- 依赖注入相关信息,构造方法参数、属性以及自动织入(autowire)方式;
- 创建销毁相关信息,懒加载模式、初始化回调方法与销毁回调方法。
我们可以自行设定 Bean 的名字,也可以让 Spring 容器帮我们设置名称。Spring 容器的命名方式为类名的首字母小写,搭配驼峰(camel-cased)规则。比如类型为 HelloService 的 Bean,自动生成的名称就为 helloService。
2.2.2 Bean 的依赖关系
所谓“依赖注入”,很重要的一块就是管理依赖。在 Spring 容器中,“管理依赖”主要就是管理 Bean 之间的依赖。有两种基本的注入方式——基于构造方法的注入和基于 Setter 方法的注入。
所谓基于构造方法的注入,就是通过构造方法来注入依赖。仍旧以 HelloWorld 为例,如代码示例 2-10 所示。
代码示例 2-10 通过构造方法传入字符串的 Hello 类
package learning.spring.helloworld;
public class Hello {
private String name;
public Hello(String name) {
this.name = name;
}
public String hello() {
return "Hello World! by " + name;
}
}
对应的 XML 配置文件需要使用 <constructor-arg/> 传入构造方法所需的内容,如代码示例 2-11 所示。
代码示例 2-11 通过构造方法配置 Bean 的 XML 文件
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://www.springframework.org/schema/beans
https://www.springframework.org/schema/beans/spring-beans.xsd">
<bean id="hello" class="learning.spring.helloworld.Hello">
<constructor-arg value="Spring"/>
</bean>
</beans>
<constructor-arg> 中有不少属性可以配置,具体如表 2-3 所示。
表 2-3 <constructor-arg/> 的可配置属性
| 属性 | 作用 |
|---|---|
| value | 要传给构造方法参数的值 |
| ref | 要传给构造方法参数的 Bean ID |
| type | 构造方法参数对应的类型 |
| index | 构造方法参数对应的位置,从 0 开始计算 |
| name | 构造方法参数对应的名称 |
基于 Setter 方法的注入,顾名思义,就是通过 Bean 的 Setter 方法来注入依赖。我们在第 2.1.4 节已经看到了对应的例子,具体可以参考代码示例 2-6 与代码示例 2-7。 <property/> 中的 value 属性是直接注入的值,用 ref 属性则可注入其他 Bean。也可以像代码示例 2-12 这样来为属性注入依赖。
代码示例 2-12 <property/> 的用法演示
<bean id="..." class="...">
<property name="xxx">
<!-- 直接定义一个内部的Bean -->
<bean class="..."/>
</property>
<property name="yyy">
<!-- 定义依赖的Bean -->
<ref bean="..."/>
</property>
<property name="zzz">
<!-- 定义一个列表 -->
<list>
<value>aaa</value>
<value>bbb</value>
</list>
</property>
</bean>
手动配置依赖在 Bean 少时还能接受,当 Bean 的数量变多后,这种配置就会变得非常繁琐。在合适的场合,可以让 Spring 容器替我们自动进行依赖注入,这种机制称为 自动织入。自动织入有几种模式,具体见表 2-4。
表 2-4 自动织入的模式
| 名称 | 说明 |
|---|---|
no | 不进行自动织入 |
byName | 根据属性名查找对应的 Bean 进行自动织入 |
byType | 根据属性类型查找对应的 Bean 进行自动织入 |
constructor | 同 byType,但用于构造方法注入 |
在 <bean/> 中可以通过 autowire 属性来设置使用何种自动织入方式,也可以在 <beans/> 中设置 default-autowire 属性指定默认的自动织入方式。在使用自动织入时,需要注意以下事项:
- 开启自动织入后,仍可以手动设置依赖,手动设置的依赖优先级高于自动织入;
- 自动织入无法注入基本类型和字符串;
- 对于集合类型的属性,自动织入会把上下文里找到的 Bean 都放进去,但如果属性不是集合类型,有多个候选 Bean 就会有问题。
为了避免第三点中说到的问题,可以将 <bean/> 的 autowire-candidate 属性设置为 false,也可以在你所期望的候选 Bean 的 <bean/> 中将 primary 设置为 true,这就表明在多个候选 Bean 中该 Bean 是主要的(如果使用基于 Java 类的配置方式,我们可以通过选择 @Primary 注解实现一样的功能)。
最后,再简单提一下如何指定 Bean 的初始化顺序。一般情况下,Spring 容器会根据依赖情况自动调整 Bean 的初始化顺序。不过,有时 Bean 之间的依赖并不明显,容器可能无法按照我们的预期进行初始化,这时我们可以自己来指定 Bean 的依赖顺序。 <bean/> 的 depends-on 属性可以指定当前 Bean 还要依赖哪些 Bean(如果使用基于 Java 类的配置方式, @DependsOn 注解也能实现一样的功能)。
2.2.3 Bean 的三种配置方式
Spring Framework 提供了多种不同风格的配置方式,早期仅支持 XML 配置文件的方式,Spring Framework 2.0 引入了基于注解的配置方式,到了 3.0 则又增加了基于 Java 类的配置方式。这几种方式没有明确的优劣之分,选择合适的或者喜欢的方式就好,很多时候我们也会混合使用这几种配置方式。
鉴于 Spring 容器的元数据配置本质上就是配置 Bean(AOP 和事务的配置背后也是配置各种 Bean),因此我们会在本节中详细展开说明如何配置 Bean。
-
基于 XML 文件的配置
Spring Framework 提供了
<beans/>这个 Schema来配置 Bean,前文中已经用过了 XML 文件方式的配置,这里再简单回顾一下。我们通过
<bean/>可以配置一个 Bean,id指定 Bean 的标识,class指定 Bean 的全限定类名,一般会通过类的构造方法来创建 Bean,但也可以使用一个静态的factory-method,比如下面就使用了create()静态方法:
<bean id="xxx" class="learning.spring.Yyy" factory-method="create" />
<constructor-arg/> 和 <property/> 用来注入所需的内容。如果是另一个 Bean 的依赖,一般会用 ref 属性,2.2.3 节中已经有过说明,此处就不再赘述了。
<bean/> 中还有几个重要的属性, scope 表明当前 Bean 是单例还是原型, lazy-init 是指当前 Bean 是否是懒加载的, depends-on 明确指定当前 Bean 的初始化顺序,就像下面这样:
<bean id="..." class="..." scope="singleton" lazy-init="true" depends-on="xxx"/>
-
基于注解的配置
Spring Framework 2.0 引入了
@Required注解,Spring Framework 2.5 又引入了@Autowired、@Component、@Service和@Repository等重要的注解,使用这些注解能简化 Bean 的配置。我们可以像代码示例 2-13 那样开启对这些注解的支持。
代码示例 2-13 启用基于注解的配置
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:context="http://www.springframework.org/schema/context"
xsi:schemaLocation="http://www.springframework.org/schema/beans
https://www.springframework.org/schema/beans/spring-beans.xsd
http://www.springframework.org/schema/context
https://www.springframework.org/schema/context/spring-context.xsd">
<context:component-scan base-package="learning.spring"/>
</beans>
上述配置会扫描 learning.spring 包内的类,在类上添加如下四个注解都能让 Spring 容器把它们配置为 Bean,如表 2-5 所示。
| 注释 | 说明 |
|---|---|
@Component | 将类标识为普通的组件,即一个 Bean |
@Service | 将类标识为服务层的服务 |
@Repository | 将类标识为数据层的数据仓库,一般是 DAO(Data Access Object) |
@Controller | 将类标识为 Web 层的 Web 控制器(后来针对 REST 服务又增加了一个 @RestController 注解) |
如果不指定 Bean 的名称,Spring 容器会自动生成一个名称,当然,也可以明确指定名称,比如:
@Component("helloBean")
public class Hello {...}
如果要注入依赖,可以使用如下的注解,如表 2-6 所示。
表 2-6 可注入依赖的注解
| 注解 | 说明 |
|---|---|
@Autowired | 根据类型注入依赖,可用于构造方法、 Setter 方法和成员变量 |
@Resource | JSR-250 的注解,根据名称注入依赖 |
@Inject | JSR-330 的注解,同 @Autowired |
从 Spring Framework 6.0 开始,
@Resource、@PostConstruct和@PreDestroy注解都换了新的包名,建议使用jakarta.annotation 包里的注解,但也兼容 javax.annotation 包中的注解;@Inject 注解则是建议使用jakarta.inject 包里的,但也兼容 javax.inject 包中的。
@Autowired 注解比较常用,下面的例子中可以指定是否必须存在依赖项,并指定目标依赖的 Bean ID:
@Autowired(required = false)
@Qualifier("helloBean")
public void setHello(Hello hello) {...}
除此之外,还可以使用 @Value 注解注入环境变量、Properties 或 YAML 中配置的属性和 SpEL 表达式的计算结果。JSR-250 中还有 @PostConstruct 和 @PreDestroy 注解,把这两个注解加在方法上用来表示该方法要在初始化后调用或者是在销毁前调用,在聊到 Bean 的生命周期时我们还会看到它们。
-
基于 Java 类的配置
从 Spring Framework 3.0 开始,我们可以使用 Java 类代替 XML 文件,使用
@Configuration、@Bean和@ComponentScan等一系列注解,基本可以满足日常所需。通过
AnnotationConfigApplicationContext可以构建一个支持基于注解和 Java 类的 Spring 上下文:
ApplicationContext ctx = new AnnotationConfigApplicationContext(Config.class);
其中的 Config 类就是一个加了 @Configuration 注解的 Java 类,它可以是代码示例 2-14 这样的。
代码示例 2-14 Java 配置类示例
@Configuration
@ComponentScan("learning.spring")
public class Config {
@Bean
@Lazy
@Scope("prototype")
public Hello helloBean() {
return new Hello();
}
}
类上的 @Configuration 注解表明这是一个 Java 配置类, @ComponentScan 注解指定了类扫描的包名,作用与 <context:component-scan/> 类似。在 @ComponentScan 中, includeFilters 和 excludeFilters 可以用来指定包含和排除的组件,例如官方文档中就有如下示例:
@Configuration
@ComponentScan(basePackages = "org.example",
includeFilters = @Filter(type = FilterType.REGEX,
pattern = ".*Stub.*Repository"),
excludeFilters = @Filter(Repository.class))
public class AppConfig { ... }
如果 @Configuration 没有指定扫描的基础包路径或者类,默认就从该配置类的包开始扫描。
Config 类中的 helloBean() 方法上添加了 @Bean 注解,该方法的返回对象会被当做容器中的一个 Bean, @Lazy 注解说明这个 Bean 是延时加载的, @Scope 注解则指定了它是原型 Bean。 @Bean 注解有如下属性,如表 2-7 所示。
表 2-7 @Bean 注解的属性
| 属性 | 默认值 | 说明 |
|---|---|---|
name | {} | Bean 的名称,默认同方法名 |
value | {} | 同 name |
autowire | Autowire.NO | 自动织入方式 |
autowireCandidate | true | 是否是自动织入的候选 Bean |
initMethod | "" | 初始化方法名 |
destroyMethod | AbstractBeanDefinition.INFER_METHOD | 销毁方法名 |
自动推测销毁 Bean 时该调用的方法,会自动去调用修饰符为
public、没有参数且方法名是close或shutdown的方法。如果类实现了java.lang.AutoCloseable或java.io.Closeable接口,也会调用其中的close()方法。
在 Java 配置类中指定 Bean 之间的依赖关系有两种方式,通过方法的参数注入依赖,或者直接调用类中带有 @Bean 注解的方法。
代码示例 2-15 中, foo() 创建了一个名为 foo 的 Bean, bar() 方法通过参数 foo 注入了 foo 这个 Bean, baz() 方法内则通过调用 foo() 获得了同一个 Bean。
代码示例 2-15 依赖示例
@Configuration
public class Config {
@Bean
public Foo foo() {
return new Foo();
}
@Bean
public Bar bar(Foo foo) {
return new Bar(foo);
}
@Bean
public Baz baz() {
return new Baz(foo());
}
}
需要重点说明的是,Spring Framework 针对 @Configuration 类中带有 @Bean 注解的方法通过 CGLIB(Code Generation Library)做了特殊处理,针对返回单例类型 Bean 的方法,调用多次返回的结果是一样的,并不会真的执行多次。
在配置类中也可以导入其他配置,例如,用 @Import 导入其他配置类,用 @ImportResource 导入配置文件,就像下面这样:
@Configuration
@Import({ CongfigA.class, ConfigB.class })
@ImportResource("classpath:/spring/*-applicationContext.xml")
public class Config {}
2.3 定制容器与 Bean 的行为
通常,Spring Framework 包揽了大部分工作,替我们管理 Bean 的创建与依赖,将各种组件装配成一个可运行的应用。然而,有些情况下,我们会有自己的特殊需求。例如,在 Bean 的依赖被注入后,我们想要触发 Bean 的回调方法做一些初始化;在 Bean 销毁前,我们想要执行一些清理工作;我们想要 Bean 感知容器的一些信息,拿到当前的上下文自行进行判断或处理……
这时候,怎么做?Spring Framework 为我们预留了发挥空间。本节我们就来探讨一下如何根据自己的需求来定制容器与 Bean 的行为。
2.3.1 Bean 的生命周期
Spring 容器接管了 Bean 的整个生命周期管理,具体如图 2-2 所示。一个 Bean 先要经过 Java 对象的创建(也就是通过 new 关键字创建一个对象),随后根据容器里的配置注入所需的依赖,最后调用初始化的回调方法,经过这三个步骤才算完成了 Bean 的初始化。若不再需要这个 Bean,则要进行销毁操作,在正式销毁对象前,会先调用容器的销毁回调方法。
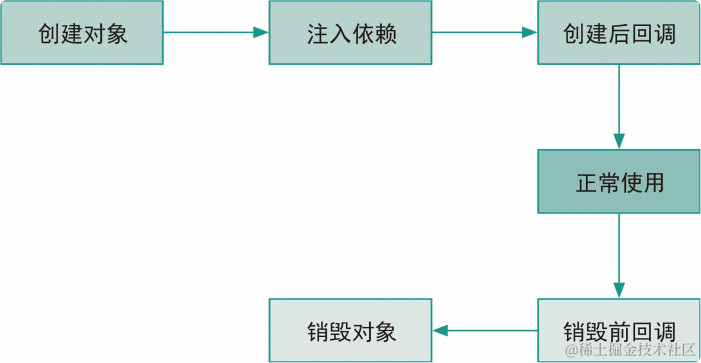
图 2-2 Bean 的生命周期
由于一切都是由 Spring 容器管理的,所以我们无法像自己控制这些动作时那样任意地在 Bean 创建后 或 Bean 销毁前 增加某些操作。为此,Spring Framework 为我们提供了几种途径,在这两个时间点调用我们提供给容器的回调方法。可以根据不同情况选择以下三种方式之一:
-
实现
InitializingBean和DisposableBean接口; -
使用 JSR-250 的
@PostConstruct和@PreDestroy注解; -
在
<bean/>或@Bean里配置初始化和销毁方法。 -
创建 Bean 后的回调动作
如果我们希望在创建 Bean 后做一些特别的操作,比如查询数据库初始化缓存等,Spring Framework 可以提供一个初始化方法。
InitializingBean接口有一个afterPropertiesSet()方法——顾名思义,就是在所有依赖都注入后自动调用该方法。在方法上添加@PostConstruct注解也有相同的效果。也可以像下面这样,在 XML 文件中进行配置
<bean id="hello" class="learning.spring.helloworld.Hello" init-method="init" />或者在 Java 配置中指定:
@Bean(initMethod="init") public Hello hello() {...} -
销毁 Bean 前的回调动作
Spring Framework 既然有创建 Bean 后的回调动作,自然也有销毁 Bean 前的触发操作。
DisposableBean接口中的destroy()方法和添加了@PreDestroy注解的方法都能实现这个目的,如代码示例 2-16 所示。代码示例 2-16 实现了
DisposableBean接口的类package learning.spring.helloworld; import org.springframework.beans.factory.DisposableBean; public class Hello implements DisposableBean { public String hello() { return "Hello World!"; } @Override public void destroy() throws Exception { System.out.println("See you next time."); } }当然,也可以在
<bean/>中指定destroy-method,或者在@Bean中指定destroyMethod。 -
生命周期动作的组合
如果我们混合使用上文提到的几种不同的方式,而且这些方式指定的方法还不尽相同,那就需要明确它们的执行顺序了。
无论是初始化还是销毁,Spring 都会按照如下顺序依次进行调用:
(1) 添加了
@PostConstruct或@PreDestroy的方法;(2) 实现了
InitializingBean的afterPropertiesSet()方法,或DisposableBean的destroy()方法;(3) 在
<bean/>中配置的init-method或destroy-method,@Bean中配置的initMethod或destroyMethod。在代码示例 2-17 的 Java 类中,同时提供了三个销毁的方法。
代码示例 2-17 添加了多个销毁方法的
Hello类package learning.spring.helloworld; import javax.annotation.PreDestroy; import org.springframework.beans.factory.DisposableBean; public class Hello implements DisposableBean { public String hello() { return "Hello World!"; } @Override public void destroy() throws Exception { System.out.println("destroy()"); } public void close() { System.out.println("close()"); } @PreDestroy public void shutdown() { System.out.println("shutdown()"); } }在对应的 XML 文件中配置
destroy-method,要用<context:annotation-config />开启注解支持,如代码示例 2-18 所示。代码示例 2-18 对应的 beans.xml 文件
<?xml version="1.0" encoding="UTF-8"?> <beans xmlns="http://www.springframework.org/schema/beans" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xmlns:context="http://www.springframework.org/schema/context" xsi:schemaLocation="http://www.springframework.org/schema/beans https://www.springframework.org/schema/beans/spring-beans.xsd http://www.springframework.org/schema/context https://www.springframework.org/schema/context/spring-context.xsd"> <context:annotation-config /> <bean id="hello" class="learning.spring.helloworld.Hello" destroy-method="close" /> </beans>代码示例 2-19 对运行类简单做了些调整,增加了关闭容器的动作,以便能让我们观察到 Bean 销毁的动作。
代码示例 2-19 启动用的
Application类代码片段public class Application { private ClassPathXmlApplicationContext applicationContext; public static void main(String[] args) { Application application = new Application(); application.sayHello(); application.close(); } public Application() { applicationContext = new ClassPathXmlApplicationContext("beans.xml"); } public void sayHello() { Hello hello = (Hello) applicationContext.getBean("hello"); System.out.println(hello.hello()); } public void close() { applicationContext.close(); } }这段代码运行后的输出即代表了三个方法的调用顺序,是与上述顺序一致的:
Hello World! shutdown() destroy() close()当然,在一般情况下,我们并不会在一个 Bean 上写几个作用不同的初始化或销毁方法。这种情况并不常见,大家了解即可。
2.3.2 Aware 接口的应用
在大部分情况下,我们的 Bean 感知不到 Spring 容器的存在,也无须感知。但总有那么一些场景中我们要用到容器的一些特殊功能,这时就可以使用 Spring Framework 提供的很多 Aware 接口,让 Bean 能感知到容器的诸多信息。此外,有些容器相关的 Bean 不能由我们自己来创建,必须由容器创建后注入我们的 Bean 中。
例如,如果希望在 Bean 中获取容器信息,可以通过如下两种方式:
- 实现
BeanFactoryAware或ApplicationContextAware接口; - 用
@Autowired注解来注入BeanFactory或ApplicationContext。
两种方式的本质都是一样的,即让容器注入一个 BeanFactory 或 ApplicationContext 对象。 ApplicationContextAware 是下面这样的:
public interface ApplicationContextAware {
void setApplicationContext(ApplicationContext applicationContext) throws BeansException;
}
在拿到 ApplicationContext 后,就能操作该对象,比如调用 getBean() 方法取得想要的 Bean。能直接操作 ApplicationContext 有时可以带来很多便利,因此这个接口相比其他的 Aware 接口“出镜率”更高一些。
如果 Bean 希望获得自己在容器中定义的 Bean 名称,可以实现 BeanNameAware 接口。这个接口的 setBeanName() 方法就是注入一个代表名称的字符串,也算是一个依赖,因此会在 2.3.1 节提到的初始化方法前被执行。
在 2.3.3 节中会提到 Spring 容器的事件机制,这时就会用到 ApplicationEventPublisher 来发送事件,可以实现 ApplicationEventPublisherAware 接口,从容器中获得 ApplicationEventPublisher 实例。
Spring Framework 中还有很多其他 Aware 接口,感兴趣的话,大家可以查阅官方文档了解更多详情。
2.3.3 事件机制
ApplicationContext 提供了一套事件机制,在容器发生变动时我们可以通过 ApplicationEvent 的子类通知到 ApplicationListener 接口的实现类,做对应的处理。例如, ApplicationContext 在启动、停止、关闭和刷新时,分别会发出 ContextStartedEvent、 ContextStoppedEvent、 ContextClosedEvent 和 ContextRefreshedEvent 事件,这些事件就让我们有机会感知当前容器的状态。
我们也可以自己监听这些事件,只需实现 ApplicationListener 接口或者在某个 Bean 的方法上增加 @EventListener 注解即可,例如代码示例 2-20 和代码示例 2-21就用以上两种方式分别处理了 ContextClosedEvent 事件。
代码示例 2-20 用 ApplicationListener 接口处理 ContextClosedEvent 事件的 ContextClosedEventListener 类代码片段
@Component
@Order(1)
public class ContextClosedEventListener implements ApplicationListener<ContextClosedEvent> {
@Override
public void onApplicationEvent(ContextClosedEvent event) {
System.out.println("[ApplicationListener]ApplicationContext closed.");
}
}
代码示例 2-21 用 @EventListener 注解处理 ContextClosedEvent 事件的 ContextClosedEventAnnotationListener 类代码片段
@Component
public class ContextClosedEventAnnotationListener {
@EventListener
@Order(2)
public void onEvent(ContextClosedEvent event) {
System.out.println("[@EventListener]ApplicationContext closed.");
}
}
在运行 ch2/helloworld-event 中的 Application 后会得到如下输出:
上略……
[ApplicationListener]ApplicationContext closed.
[@EventListener]ApplicationContext closed.
可以看到两个类都处理了 ContextClosedEvent 事件,我们通过 @Order 可以指定处理的顺序。
这套机制不仅适用于 Spring Framework 的内置事件,也非常方便我们定义自己的事件,不过该事件必须继承 ApplicationEvent,而且产生事件的类需要实现 ApplicationEventPublisherAware,还要从上下文中获取到 ApplicationEventPublisher,用它来发送事件。代码示例 2-22 是事件生产者 CustomEventPublisher 类的代码片段。
代码示例 2-22 生产事件的 CustomEventPublisher 类代码片段
@Component
public class CustomEventPublisher implements ApplicationEventPublisherAware {
private ApplicationEventPublisher publisher;
public void fire() {
publisher.publishEvent(new CustomEvent("Hello"));
}
@Override
public void setApplicationEventPublisher( ApplicationEventPublisher applicationEventPublisher) {
this.publisher = applicationEventPublisher;
}
}
对应的事件监听代码也非常简单,对应方法如下:
@EventListener
public void onEvent(CustomEvent customEvent) {
System.out.println("CustomEvent Source: " + customEvent.getSource());
}
在运行 ch2/helloworld-event 中的 Application 后会得到如下输出:
上略……
CustomEvent Source: Hello
下略……
@EventListener 还有一些其他的用法,比如,在监听到事件后希望再发出另一个事件,这时可以将方法返回值从 void 修改为对应事件的类型; @EventListener 也可以与 @Async 注解结合,实现在另一个线程中处理事件。关于 @Async 注解,我们会在 2.4.2 节中进行说明。
2.3.4 容器的扩展点
Spring 容器是非常灵活的,Spring Framework 中有很多机制是通过容器自身的扩展点来实现的,比如 Spring AOP 等。如果我们想在 Spring Framework 上封装自己的框架或功能,也可以充分利用容器的扩展点。
BeanPostProcessor 接口是用来定制 Bean 的,顾名思义,这个接口是 Bean 的后置处理器,在 Spring 容器初始化 Bean 时可以加入我们自己的逻辑。该接口中有两个方法, postProcessBeforeInitialization() 方法在 Bean 初始化前执行, postProcessAfterInitialization() 方法在 Bean 初始化之后执行。如果有多个 BeanPostProcessor,可以通过 Ordered 接口或者 @Order 注解来指定运行的顺序。代码示例 2-23 演示了 BeanPostProcessor 的基本用法。
代码示例 2-23 打印信息的 HelloBeanPostProcessor 类代码片段
public class HelloBeanPostProcessor implements BeanPostProcessor {
@Override
public Object postProcessBeforeInitialization(Object bean, String beanName) throws BeansException {
if ("hello".equals(beanName)) {
System.out.println("Hello postProcessBeforeInitialization");
}
return bean;
}
@Override
public Object postProcessAfterInitialization(Object bean, String beanName) throws BeansException {
if ("hello".equals(beanName)) {
System.out.println("Hello postProcessAfterInitialization");
}
return bean;
}
}
我们在对应的 Hello 中,也增加一个带 @PostConstruct 注解的方法,执行 ch2/helloworld-processor 中的 Application 类,验证一下方法的执行顺序是否与大家预想的一样:
Hello postProcessBeforeInitialization
Hello PostConstruct
Hello postProcessAfterInitialization
如果说 BeanPostProcessor 是 Bean 的后置处理器,那 BeanFactoryPostProcessor 就是 BeanFactory 的后置处理器,我们可以通过它来定制 Bean 的配置元数据,其中的 postProcessBeanFactory() 方法会在 BeanFactory 加载所有 Bean 定义但尚未对其进行初始化时介入。它的用法与 BeanPostProcessor 类似,此处就不再赘述了。需要注意的是,如果用 Java 配置类来注册,那么方法需要声明为 static。2.4.1 节中会讲到的 PropertySourcesPlaceholderConfigurer 就是一个 BeanFactoryPostProcessor 的实现。
需要重点说明一下,由于 Spring AOP 也是通过 BeanPostProcessor 实现的,因此实现该接口的类,以及其中直接引用的 Bean 都会被特殊对待, 不会 被 AOP 增强。此外, BeanPostProcessor 和 BeanFactoryPostProcessor 都仅对当前容器上下文的 Bean 有效,不会去处理其他上下文。
2.3.5 优雅地关闭容器
Java 进程在退出时,我们可以通过 Runtime.getRuntime().addShutdownHook() 方法添加一些钩子,在关闭进程时执行特定的操作。如果是 Spring 应用,在进程退出时也要能正确地执行一些清理的方法。
ConfigurableApplicationContext 接口扩展自 ApplicationContext,其中提供了一个 registerShutdownHook()。 AbstractApplicationContext 类实现了该方法,正是调用了前面说到的 Runtime.getRuntime().addShutdownHook(),并且在其内部调用了 doClose() 方法。
设想在生产代码里有这么一种情况:一个 Bean 通过 ApplicationContextAware 注入了 ApplicationContext,业务代码根据逻辑判断从 ApplicationContext 中取出对应名称的 Bean,再进行调用;问题出现在应用程序关闭时,容器已经开始销毁 Bean 了,可是这段业务代码还在执行,仍在继续尝试从容器中获取 Bean,而且代码还没正确处理此处的异常……这该如何是好?
针对这种情况,我们可以借助 Spring Framework 提供的 Lifecycle 来感知容器的启动和停止,容器会将启动和停止的信号传播给实现了该接口的组件和上下文。为了让例子能够简单一些,我们把问题简化一下: Hello.hello() 在容器关闭前后返回不同的内容,如代码示例 2-2423 所示。
代码示例 2-24 实现了 Lifecycle 接口的 Hello 类代码片段
public class Hello implements Lifecycle {
private boolean flag = false;
public String hello() {
return flag ? "Hello World!" : "Bye!";
}
@Override
public void start() {
System.out.println("Context Started.");
flag = true;
}
@Override
public void stop() {
System.out.println("Context Stopped.");
flag = false;
}
@Override
public boolean isRunning() {
return flag;
}
}
我们将对应的 Application 类也做相应调整,具体如代码示例 2-25 所示。
代码示例 2-25 调整后的 Application 类代码片段
@Configuration
public class Application {
public static void main(String[] args) {
AnnotationConfigApplicationContext applicationContext =
new AnnotationConfigApplicationContext(Application.class);
applicationContext.start(); // 这会触发Lifecycle的start()
Hello hello = applicationContext.getBean("hello", Hello.class);
System.out.println(hello.hello());
applicationContext.close(); // 这会触发Lifecycle的stop()
System.out.println(hello.hello());
}
@Bean
public Hello hello() {
return new Hello();
}
}
上述代码的执行结果如下:
Context Started.
Hello World!
Context Stopped.
Bye!
除此之外,我们还可以借助 Spring Framework 的事件机制,在上下文关闭时会发出 ContextClosedEvent,监听该事件也可以触发业务代码做对应的操作。
茶歇时间:Linux 环境下如何关闭进程
在 Linux 环境下,大家常用
kill命令来关闭进程,其实是kill命令给进程发送了一个信号(通过kill -l命令可以查看信号列表)。不带参数的“kill 进程号”发送的是SIGTERM(15),一般程序在收到这个信号后都会先释放资源,再停止;但有时程序可能还是无法退出,这时就可以使用“kill -9 进程号”,发送SIGKILL(9),直接杀死进程。一般不建议直接使用
-9,因为非正常地中断程序可能会造成一些意料之外的情况,比如业务逻辑处理到一半,恢复手段不够健全的话,可能需要人工介入处理那些执行到一半的内容。
2.4 容器中的几种抽象
Spring Framework 针对研发和运维过程中的很多常见场景做了抽象处理,比如本节中会讲到的针对运行环境的抽象,后续章节中会聊到的事务抽象等。正是因为存在这些抽象层,Spring Framework 才能为我们屏蔽底层的很多细节。
2.4.1 环境抽象
自诞生之日起,Java 程序就一直宣传自己是“Write once, run anywhere”,但往往现实并非如此——虽然有 JVM 这层隔离,但我们的程序还是需要应对不同的运行环境细节:比如使用了 WebLogic 的某些特性会导致程序很难迁移到 Tomcat 上;此外,程序还要面对开发、测试、预发布、生产等环境的配置差异;在云上,不同可用区(availability zone)可能也有细微的差异。Spring Framework 的环境抽象可以简化大家在处理这些问题时的复杂度,代表程序运行环境的 Environment 接口包含两个关键信息——Profile 和 Properties,下面我们将详细展开这两项内容。
-
Profile 抽象
假设我们的系统在测试环境中不需要加载监控相关的 Bean,而在生产环境中则需要加载;亦或者针对不同的客户要求,A 客户要求我们部署的系统直接配置数据库连接池,而 B 客户要求通过 JNDI 获取连接池。此时,就可以利用 Profile 帮我们解决这些问题。
如果使用 XML 进行配置,可以在
<beans/>的profile属性中进行设置。如果使用 Java 类的配置方式,可以在带有@Configuration注解的类上,或者在带有@Bean注解的方法上添加@Profile注解,并在其中指定该配置生效的具体 Profile,就像代码示例 2-26 那样。代码示例 2-26 针对开发和测试环境的不同 Java 配置
@Configuration @Profile("dev") public class DevConfig { @Bean public Hello hello() { Hello hello = new Hello(); hello.setName("dev"); return hello; } } @Configuration @Profile("test") public class TestConfig { @Bean public Hello hello() { Hello hello = new Hello(); hello.setName("test"); return hello; } }通过如下两种方式可以指定要激活的 Profile(多个 Profile 用逗号分隔):
ConfigurableEnvironment.setActiveProfiles()方法指定要激活的 Profile(通过ApplicationContext.getEnvironment()方法可获得Environment);spring.profiles.active属性指定要激活的 Profile(可以用系统环境变量、JVM 参数等方式指定,能通过PropertySource找到即可,在第 4 章会详细介绍 Spring Boot 的属性加载机制)。
例如,启动程序时,在命令行中增加 spring.profiles.active:
▸ java -Dspring.profiles.active="dev" -jar xxx.jar
Spring Framework 还提供了默认的 Profile,一般名为 default,但也可以通过 ConfigurableEnvironment.setDefaultProfiles() 和 spring.profiles.default 来修改这个名称。
-
PropertySource 抽象
Spring Framework 中会频繁用到属性值,而这些属性又来自于很多地方,
PropertySource抽象就屏蔽了这层差异,例如,可以从 JNDI、JVM 系统属性(-D命令行参数,System.getProperties()方法能取得系统属性)和操作系统环境变量中加载属性。在 Spring 中,一般属性用小写单词表示并用点分隔,比如
foo.bar,如果是从环境变量中获取属性,会按照foo.bar、foo_bar、FOO.BAR和FOO_BAR的顺序来查找。4.3.2 节还有加载属性相关的内容,届时还会进一步说明。我们可以像下面这样来获得属性
foo.bar:public class Hello { @Autowired private Environment environment; public void hello() { System.out.println("foo.bar: " + environment.getProperty("foo.bar")); } }我们在 2.2.3 节中看到过
@Value注解,它也能获取属性,获取不到时则返回默认值:public class Hello { @Value("$") // :后是默认值 private String value; public void hello() { System.out.println("foo.bar: " + value); } }${}占位符可以出现在 Java 类配置或 XML 文件中,Spring 容器会试图从各种已经配置了的来源中解析属性。要添加属性来源,可以在@Configuration类上增加@PropertySource注解,例如:@Configuration @PropertySource("classpath:/META-INF/resources/app.properties") public class Config {...}如果使用 XML 进行配置,可以像下面这样:
<context:property-placeholder location="classpath:/META-INF/resources/app.properties" />通常我们的预期是一定能找到需要的属性,但也有这个属性可有可无的情况,这时将注解的
ignoreResourceNotFound或者 XML 文件的ignore-resource-not-found设置为true即可。如果存在多个配置,则可以通过@Order注解或 XML 文件的order属性来指定顺序。也许大家会好奇,Spring Framework 是如何实现占位符解析的,这一切要归功于
PropertySourcesPlaceholderConfigurer这个BeanFactoryPostProcessor。如果使用<context:property-placeholder/>,Spring Framework 会自动注册一个PropertySourcesPlaceholderConfigurer,如果是 Java 配置,则需要我们自己用@Bean来注册一个,例如:@Bean public static PropertySourcesPlaceholderConfigurer configurer() { return new PropertySourcesPlaceholderConfigurer(); }在它的
postProcessBeanFactory()方法中,Spring 会尝试用找到的属性值来替换上下文中的对应占位符,这样在 Bean 正式初始化时我们就不会再看到占位符,而是实际替换后的值。我们也可以定义自己的
PropertySource实现,将它添加到ConfigurableEnvironment.getPropertySources()返回的PropertySources中即可,Spring Cloud Config 其实就使用了这种方式。
2.4.2 任务抽象
看过了与环境相关的抽象后,我们再来看看与任务执行相关的内容。Spring Framework 通过 TaskExecutor 和 TaskScheduler 这两个接口分别对任务的异步执行与定时执行进行了抽象,接下来就让我们一起来了解一下。
-
异步执行
Spring Framework 的
TaskExecutor抽象是在 2.0 版本时引入的,Executor是 Java 5 对线程池概念的抽象,如果了解 JUC(java.util.concurrent)的话,一定会知道java.util.concurrent.Executor这个接口,而TaskExecutor就是在它的基础上又做了一层封装,让我们可以方便地在 Spring 容器中配置多线程相关的细节。TaskExecutor有很多实现,例如,同步的SyncTaskExecutor;每次创建一个新线程的SimpleAsyncTaskExecutor;内部封装了Executor,非常灵活的ConcurrentTaskExecutor;还有我们用的最多的ThreadPoolTaskExecutor。我们可以像下面这样直接配置一个
ThreadPoolTaskExecutor:<bean id="taskExecutor" class="org.springframework.scheduling.concurrent.ThreadPoolTaskExecutor"> <property name="corePoolSize" value="4"/> <property name="maxPoolSize" value="8"/> <property name="queueCapacity" value="32"/> </bean>也可使用
<task:executor/>,下面是一个等价的配置:<task:executor id="taskExecutor" pool-size="4-8" queue-capacity="32"/>茶歇时间:该怎么配置线程池
如果要在程序中使用线程,请不要自行创建
Thread,而应该尽可能考虑使用线程池,并且明确线程池的大小—不能无限制地创建线程。网上有这样的建议,对于 CPU 密集型的系统,要尽可能减少线程数,建议线程池大小配置为“CPU 核数 +1”;对于 IO 密集型系统,为了避免 CPU 浪费在等待 IO 上,建议线程池大小为“CPU 核数 ×2”。当然,这只是一个建议值,具体还是可以根据情况来做调整的。
线程池的等待队列默认为
Integer.MAX_VALUE,这样可能会造成任务的大量堆积,所以设置一个合理的等待队列大小后,就要应对“队列满”的情况。“队列满”时的处理策略是由RejectedExecutionHandler决定的,默认是ThreadPoolExecutor.AbortPolicy,即直接抛出一个RejectedExecutionException异常。如果我们能接受直接抛弃任务,也可以将策略设置为ThreadPoolExecutor.DiscardPolicy或ThreadPoolExecutor.DiscardOldestPolicy。此外,
ThreadPoolTaskExecutor还有一个keepAliveSeconds的属性,通过它可以调整空闲状态线程的存活时间。如果当前线程数大于核心线程数,到存活时间后就会清理线程。在配置好了
TaskExecutor后,可以直接调用它的execute()方法,传入一个Runnable对象;也可以在方法上使用@Async注解,这个方法可以是空返回值,也可以返回一个Future:@Async public void runAsynchronous() {...}为了让该注解生效,需要在配置类上增加
@EnableAsync注解,或者在 XML 文件中增加<task:annotation-driven/>配置,开启对它的支持。默认情况下,Spring 会为
@Async寻找合适的线程池定义:例如上下文里唯一的TaskExecutor;如果存在多个,则用 ID 为taskExecutor的那个;前面两个都找不到的话会降级使用SimpleAsyncTaskExecutor。当然,也可以在@Async注解中指定一个。请注意 对于异步执行的方法,由于在触发时主线程就返回了,我们的代码在遇到异常时可能根本无法感知,而且抛出的异常也不会被捕获,因此最好我们能自己实现一个
AsyncUncaughtExceptionHandler对象来处理这些异常,最起码打印一个异常日志,方便问题排查。 -
定时任务
定时任务,顾名思义,就是在特定的时间执行的任务,既可以是在某个特定的时间点执行一次的任务,也可以是多次重复执行的任务。
TaskScheduler对两者都有很好的支持,其中的几个schedule()方法是处理单次任务的,而scheduleAtFixedRate()和scheduleWithFixedDelay()则是处理多次任务的。scheduleAtFixedRate()按固定频率触发任务执行,scheduleWithFixedDelay()在第一次任务执行完毕后等待指定的时间后再触发第二次任务。TaskScheduler.schedule()可以通过Trigger来指定触发的时间,其中最常用的就是接收 Cron 表达式的CronTrigger了,可以像下面这样在周一到周五的下午 3 点 15 分触发任务:scheduler.schedule(task, new CronTrigger("0 15 15 * * 1-5"));与
TaskExecutor类似,Spring Framework 也提供了不少TaskScheduler的实现,其中最常用的也是ThreadPoolTaskScheduler。上述例子中的scheduler就可以是一个注入的ThreadPoolTaskSchedulerBean。我们可以选择用
<task:scheduler/>来配置TaskScheduler:<task:scheduler id="taskScheduler" pool-size="10" />也可以使用注解,默认情况下,Spring 会在同一上下文中寻找唯一的
TaskSchedulerBean,有多个的话用 ID 是taskScheduler的,再不行就用一个单线程的TaskScheduler。在配置任务前,需要先在配置类上添加@EnableScheduling注解或在 XML 文件中添加<task:annotation-driven/>开启注解支持:@Configuration @EnableScheduling public class Config {...}随后,在方法上添加
@Scheduled注解就能让方法定时执行,例如:@Scheduled(fixedRate=1000) // 每隔1000ms执行 public void task1() {...} @Scheduled(fixedDelay=1000) // 每次执行完后等待1000ms再执行下一次 public void task2() {...} @Scheduled(initialDelay=5000, fixedRate=1000) // 先等待5000ms开始执行第一次,后续每隔1000ms执行一次 public void task3() {...} @Scheduled(cron="0 15 15 * * 1-5") // 按Cron表达式执行 public void task4() {...}茶歇时间:本地调度 vs. 分布式调度
上文提到的调度任务都是在一个 JVM 内部执行的,一般我们的系统都是以集群方式部署的,因此并非所有任务都需要在每台服务器上执行,同一时间,集群中的一台服务器能执行就够了。这时,仅有本节所提供的调度任务支持是不够的,我们还可以借助其他调度服务来实现我们的需求,例如,当当开源的 ElasticJob。
举个例子,为了提升性能,我们会使用多级缓存,代码优先读取 JVM 本地缓存,没有命中的话再去读取 Redis 分布式缓存。缓存要靠定时任务来刷新,此时本地调度任务就用来刷新 JVM 缓存,而分布式调度任务就用来刷新 Redis 缓存。当然,我们也可以通过分布式调度来管理每台机器上的调度任务。
甚至在一些场景中我们还需要对调度任务进行复杂的拆分:一台机器接收到任务被触发,接着进行一系列的准备工作,随后将任务分发到集群中的其他节点上进行后续处理,以此充分发挥集群的作用。
总之,调度任务可以是非常复杂的,本节只是简单地引入这个话题,感兴趣的话,大家可以再深入研究。
2.5 小结
通过本章的学习,我们对 Spring Framework 的核心容器及 Bean 的概念已经有了一个大概的了解。不仅知道了如何去使用它们,更是深入了解了如何对一些特性进行定制,如何通过类似事件通知这样的机制来应对某些问题。
Spring Framework 为了让大家专心于业务逻辑,为我们提供了很多抽象来屏蔽底层的实现。本章中的环境抽象和任务抽象就是很好的例子。
下一章,我们将看到 Spring Framework 中的另一个重要内容——AOP 支持。