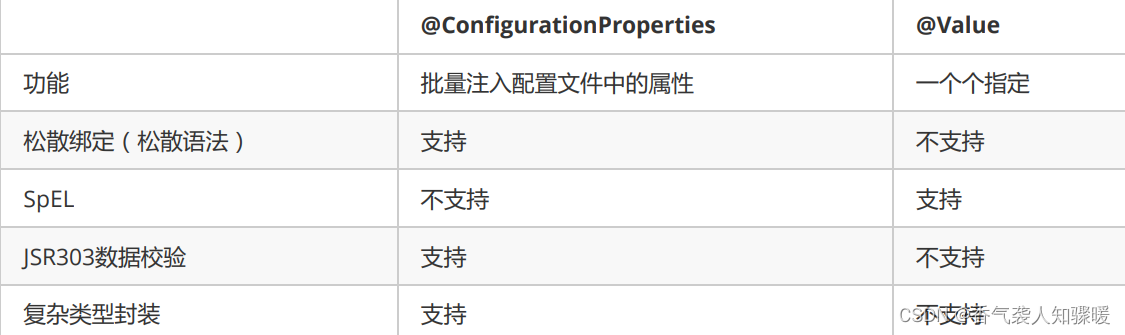
一、NAND基本原理
目前NAND已经从SLC发展到PLC,但是PLC离大规模上市还有一段距离,我们暂时先略过。市面上主要流通的就是4种NAND类型:SLC、MLC、TLC、QLC。随着每个寿命从高到低依次是SLC>MLC>TLC>QLC.

随着单个cell含有的bit数越多,NAND的可靠性也会有所降低。同时写延迟也在不断地增加。SLC写延迟在0.5ms级别,到QLC写延迟达到10-20ms,40倍的差距。这也导致QLC SSD性能出现很大的下降。

介绍完NAND cell的状态,再来show一下NAND的基本操作(以最简单的SLC为例)。
读(Read):
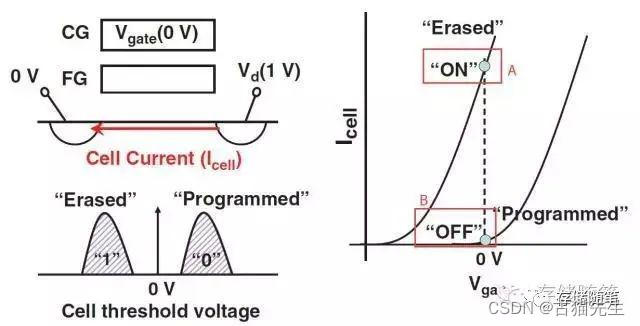
如上图所示,这是对单一cell进行read的基本操作。在控制栅极(CG, 也是WL)加上0V的电压,源极(Source)端加上0V以及漏极(Drain, 也是BL)加上1V,然后通过源极与漏极之间电流Icell的大小来判断cell的状态(0或者1)。
A点的状态代表存在Icell,所以Cell处于“开态”(ON),称为Erased;
B点的状态代表不存在Icell或者Icell很小且可忽略,所以Cell处于“关态”(OFF),称为Programmed。
如果对NAND cell阵列操作,原理图如下:
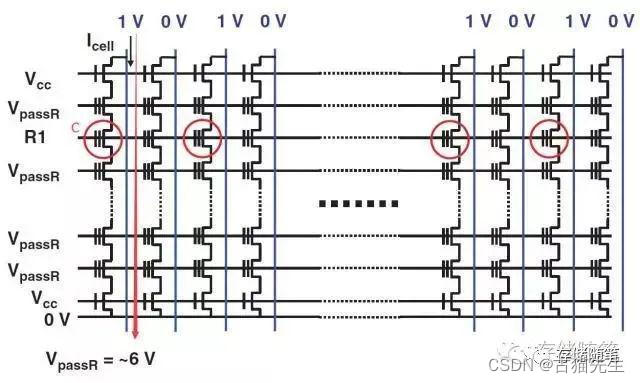
如果Cell C处于Erased, 对应BL的Sense电路会感应到有电流;
在需要read的target Page的WL上面加一个R1(一个较小的电压),其他WL的加VpassR, BL方向加1V,
如果Cell C处于Programmed, 对应BL的Sense电路不会感应到有电流。
写(Program):
在控制栅CG加上一个高压20V,基底接0V, 由于电场的存在以及隧穿效应,电子会被俘获在浮栅FG,也就完成了单个Cell的Program操作。Program之后cell的状态为“0”。


擦除(Erase):
在控制栅CG接0V,基底加上一个高压20V, 由于电场的存在以及隧穿效应,电子逃离浮栅FG,也就完成了单个Cell的Erase操作。Erase之后cell的状态为“1”。
需要注意的是,Read、Program都是以Page为最小基本操作单位,而Erase以Block为最小基本操作单位。

二、SSD基本原理
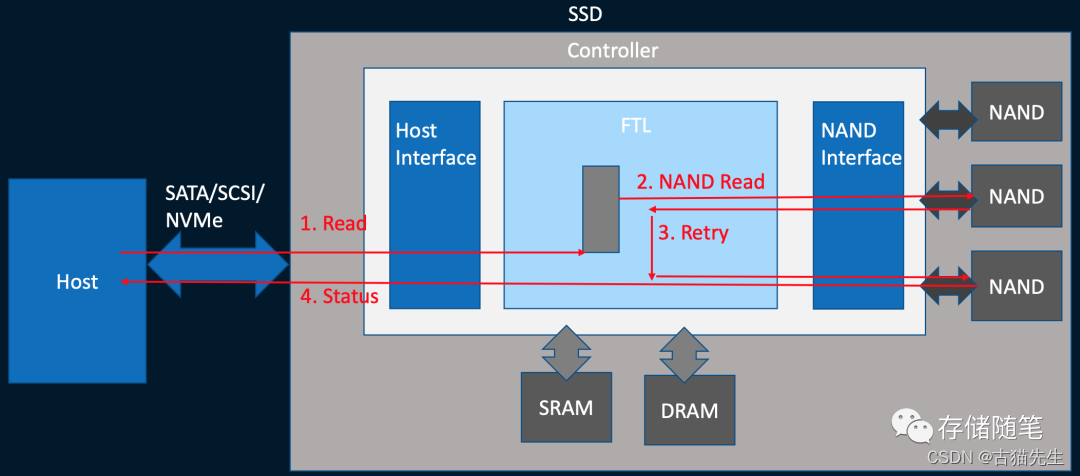
目前主流SSD主控架构如下图:

主要由三大部分组成:与Host对接的界面(Host interface), 闪存转换层FTL以及闪存对接界面(Flash interface)。
Host interface采用的协议(protocol)包括SATA,PCIe/NVMe SSD协议。
闪存转换层FTL是主控的核心部分,主要实现磨损平衡(Wear-leveling), 垃圾数据回收(Garbage Collection), 坏块管理(Bad Block Management)和数据纠错处理(ECC, Error Correction Code)。
Flash interface包括了SSD主控的flash controller,用来控制主控与NAND闪存之间的数据传输。

SSD IO数据写入的过程:
写入过程中,host写入数据给到缓存,再由缓存下刷到NAND存储,需要注意的是写入数据后的垃圾回收GC。

SSD IO数据读取的过程:
读取过程中,host发送数据读取请求,数据从NAND读取,这个过程可能会有因为NAND读取异常发送Read Retry。
三、SSD QoS性能优化
SSD性能评估中,QoS(Quality of Service, 服务质量)是重中之重,代表SSD性能的稳定性的指标。QoS评价参数中,有平均延迟、99% QoS,99.9% QoS,99.99% QoS,99.999% QoS等,9越多,说明对延迟的稳定性要求就越高。影响QoS的主要因素总结如下:

1.Host端的影响因素
Host端CPU/缓存的资源对IO质量QoS也有比较大的影响,这块通常不是瓶颈,在部分特殊场景,比如CPU soft lockup,内存资源溢出OOM等,系统的IO响应也会出现很大的波动。
同时内核block层的IO调度器的设定,决定IO的响应策略差异:
NOOP算法,是内核IO调度算法中最简单的一种,也被称作电梯算法,这些 FIFO先进先出策略,这个过程会适当对连续的IO进行简单的合并。
CFQ算法,全称Completely Fair Queuing,最大的特点就是尽可能把每个IO进程响应做到公平。从内核2.6.18也成为了linux默认的算法。
Deadline算法,主要的特别是确保每个IO进程在一段时间内被处理完,防止单个IO被等待太久没有影响。

在Linux内核中,修改IO调度的算法也比较简单,简单例子参考:
1.查看当前调度算法是NOOP
$ cat /sys/block/nvme0n1/queue/scheduler
[noop] deadline cfq
2.将NOOP算法调整为CFQ
$ echo 'cfq'>/sys/block/nvme0n1/queue/scheduler
3.查看修改后的算法为CFQ
$ cat /sys/block/nvme0n1/queue/scheduler
noop deadline [cfq]
对于Host接口协议,在信息爆炸时代之前,SATA在AHCI的领导下可谓是风生水起,青史留名。但是,SATA/AHCI其实是为机械硬盘HDD而生的,其致命的缺陷就是传输速度有瓶颈,最大不超过600MB/s。后来,AHCI也意识到了自身的危机,并高薪挖来了另一位得力干将PCIe。
PCIe是一种高速串行计算机扩展总线标准,与SATA相比,具有很多改进的地方,比如更高的最大系统总线吞吐量,较少的IO引脚数,更小的物理占位面积和更好的总线设备性能扩展。PCIe总线是高速差分总线,采用端对端的数据传输方式。随着PCIe技术不断发展与进步,目前市场上应用最多的还是2015年发布的PCIe Gen3。在2017年6月份的时候,PCIe Gen4已经发布,市场上目前也可以买到Gen4的固态硬盘了。在2019年的时候,Gen5也正式发布,速度更是达到128GB/s, 性能越来越强劲,

PCIe呢,光芒万丈,AHCI根本就驾驭不了,PCIe对AHCI也是心生抱怨,AHCI不能为PCIe提供施展才华的平台。在与AHCI搭档了很短的时间之后,PCIe就萌生退意。正当PCIe对这个世界开始失望的时候,PCIe遇到了NVMe。郁郁不得志之后,PCIe终于等到了自己的伯乐。PCIe/NVMe这对搭档在结合之后,展现了前所未有的能量,正在用他们的实力征服这个世界。
上面的一段"废话"叙述了AHCI,NVME,SATA,PCIe相互之间的关系,画了张图,方便大家理解:

2.Device端影响因素
(1)NAND Read Page时间影响SSD读性能
Host从SSD读数据,最终数据的来源也是要从NAND die上读取,对NAND die发送Read Page操作,数据返回。这个过程的耗时直接决定了SSD读性能的好坏。下图是某个比较老的NAND SPEC相关读操作的示意图,仅供参考。


如果tR下降10%,Read QoS将会降低26%,Write QoS下降12%。

(2)NAND Program Page时间影响SSD写性能
Host向SSD写入数据,数据最终的归宿是NAND die。数据写入NAND的时间依赖NAND Channel和Plane的设计,更重要的是需要依赖NAND die本身program page的时间,这个过程的耗时直接决定了SSD写性能的好坏。下图是某个比较老的NAND SPEC相关写操作的示意图,仅供参考。

比如下图是在去年ISSCC展示的不同场景QLC SSD性能的对比。其中,我们可以关注到Program Latency(tPROG)的时间,跟Program Throughput写带宽有直接的关系。同样的Plane配置下,Program Latency(tPROG)的时间越小,Program Throughput写带宽就会越大。

(3)NAND Block Erase的时间也会影响SSD读写性能
下图是SSD写入page的简单示意图。当数据以4KB大小随机写入时,最左边的die的第一个block已经写满了,包括了有用数据或者invalid无效数据。
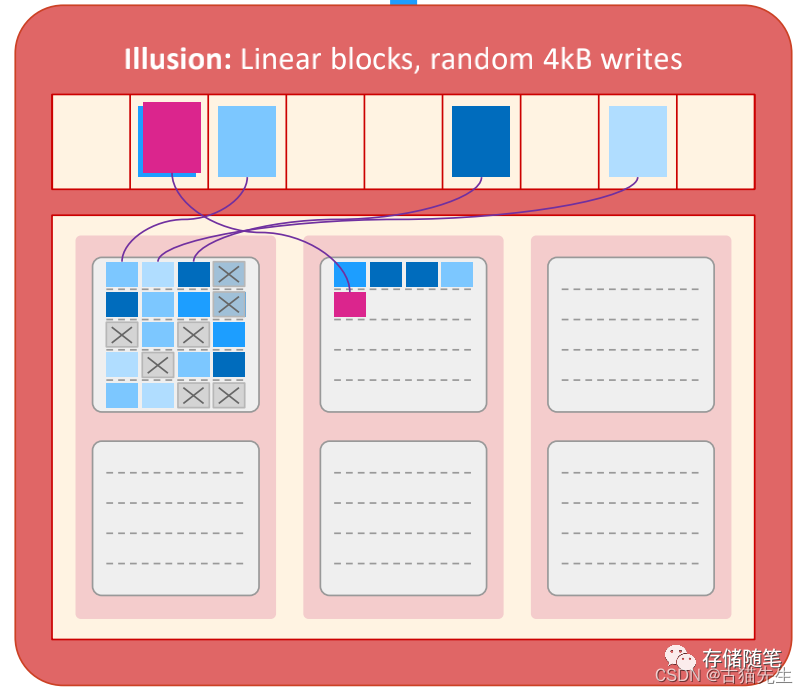
在SSD FW内部GC启动的策略下,最左边die的第一block的有效数据被搬迁到空闲的数据块block。同时该block开始执行Erase操作。此时,如果我们要读取在这个die的数据A的时候,因为同一颗die正在进行erase操作,就会导致A数据读操作无法执行(同时,如果同一个die或者plane有读操作进行,此时读取同一个die和plane,也会产生冲突,影响读性能),需要等待erase操作完成。最终导致读的延迟里面有多了一个erase block的操作,读性能就会看到一个抖动。

在GC的另外一种状态,SSD内部没有空闲的block,需要等待GC搬迁数据和擦除数据,腾出空闲的数据块,这个过程,erase的操作也影响到写性能。假如我要写入一个4KB的数据Z覆盖A,并恰好目标块没有空余的页区,需要进行GC回收。这个时候就需要把B、C、D、E、F五分数据都搬走,然后擦除整个数据块,擦除完成后再整体写入6个数据页。这个整个过程,Host虽然只写了4KB的数据,但实际过程中,由于GC的问题,NAND最终写入了24KB。那么写放大WAF=24KB/4KB=6. 这整个过程写延迟和写放大都收到了很大的影响。
(4)NAND其他特性对SSD读写性能的影响
比如要增加写性能,做法是在NAND array Bit Line方向增加plane的并发度,多个page一起写。另外,也可以通过减少Bit line的长度来降低RC延迟,这样可以提升读的性能。同时,NAND ONFI接口的速率也会影响性能,目前常见的接口速率2400MT/s

另外,多通道之间的Interleaving也是性能优化非常关键的因素。在一个通道上的操作是可以有交错的。当一个NAND闪存处在被占用状态Busy时,可以让第一个NAND闪存自己忙着,主控可以访问同一个通道上的第二个NAND闪存。
举个例子,主控需要连续对一个通道上所有的NAND闪存进行写入(Write)操作,在Interleave功能的帮助下,同一个通道上的NAND闪存形成了一个最大通道利用率的流水线(Pipeline)

Die Size从256Gb提升到512Gb,因为降低的了Interleaving的效果,最终导致Read QoS将会降低44%,Write QoS下降32%。

(5) ECC纠错对SSD读性能的影响
在host读取数据过程中,最理想的情况是一个Page Read Time的时间就可以直接返回数据。但显示的情况是,我们可能会因为一些不想看到的问题,导致性能受损。
比如读写之间的温度差、Data Retention、读干扰、写干扰等。导致出现数据翻转,需要启动Read Retry重读机制、LDPC纠错、RAID纠错等修复机制。这个过程就会导致性能出现跌落或者延迟抖动。
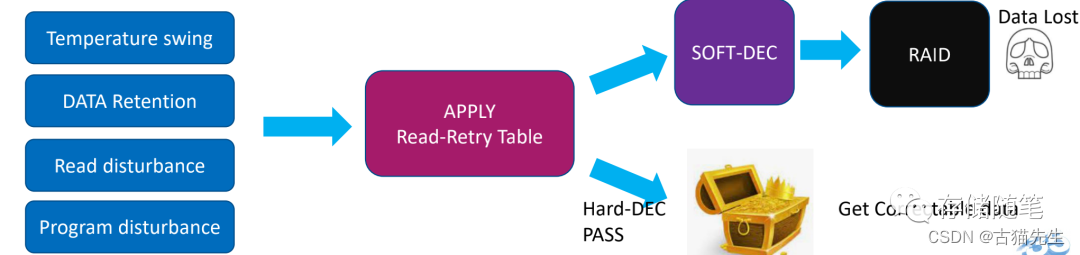
在QLC SSD中,因为Vt level之间的电压差更狭小,访问同一个区域的扫描电压影响会更大,更容易引发读干扰的问题。

同样的,Data Retention也比较明显,读写温度差异对QLC NAND的更加敏感。

(6) 3D-NAND工艺对SSD性能的影响
目前业内3D-NAND工艺架构主要分为两个阵营,一个阵营,以Solidigm(Intel NAND卖给海力士后新成立的公司)为首,采用Floating Gate(FG)浮栅,另外一个阵营三星/WD等,采用Change Trap Flash。FG浮栅将电荷存储在导体中,而CTF将电荷存储于绝缘体中,这消除了单元之间的干扰,提高了读写性能,同时与浮栅技术相比减少了单元面积。不过,FG浮栅对read disturb和program disturb的抗干扰比CTF要好。

FG浮栅架构在Program过程,采用4-16 program算法,这个过程可以减少program disturb写干扰。

CTF架构,或者叫做RG架构,采用16-16 progam算法,两次program都要求所有page直接写入NAND,第一次program电压是放置在最终电压附近。CTF的Data Retention相对比较严重。

在写性能方面的对比,不同的架构有不同的表现。
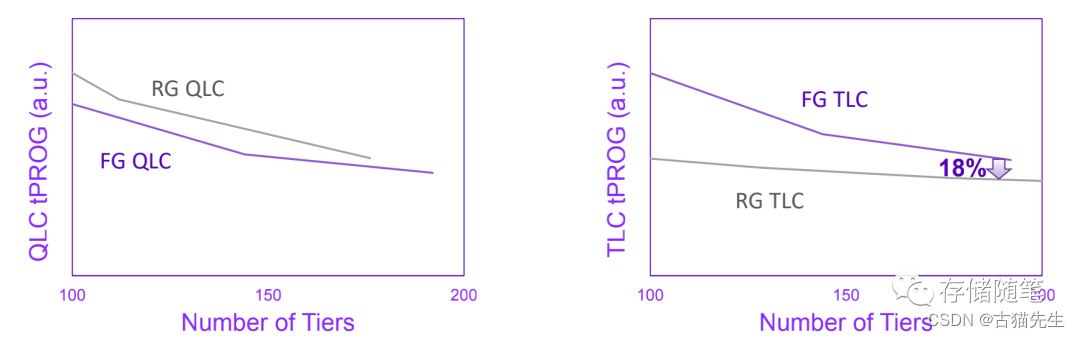
在TLC NAND中,CTF架构tPROG比FG浮栅低18%,所以在TLC SSD中,CTF架构TLC NAND SSD的性能比FG架构TLC NAND SSD性能要好。
在QLC NAND中,由于program算法差异的影响,FG浮栅表现更好,FG架构QLC NAND SSD性能比CTF架构QLC NAND SSD性能要好。
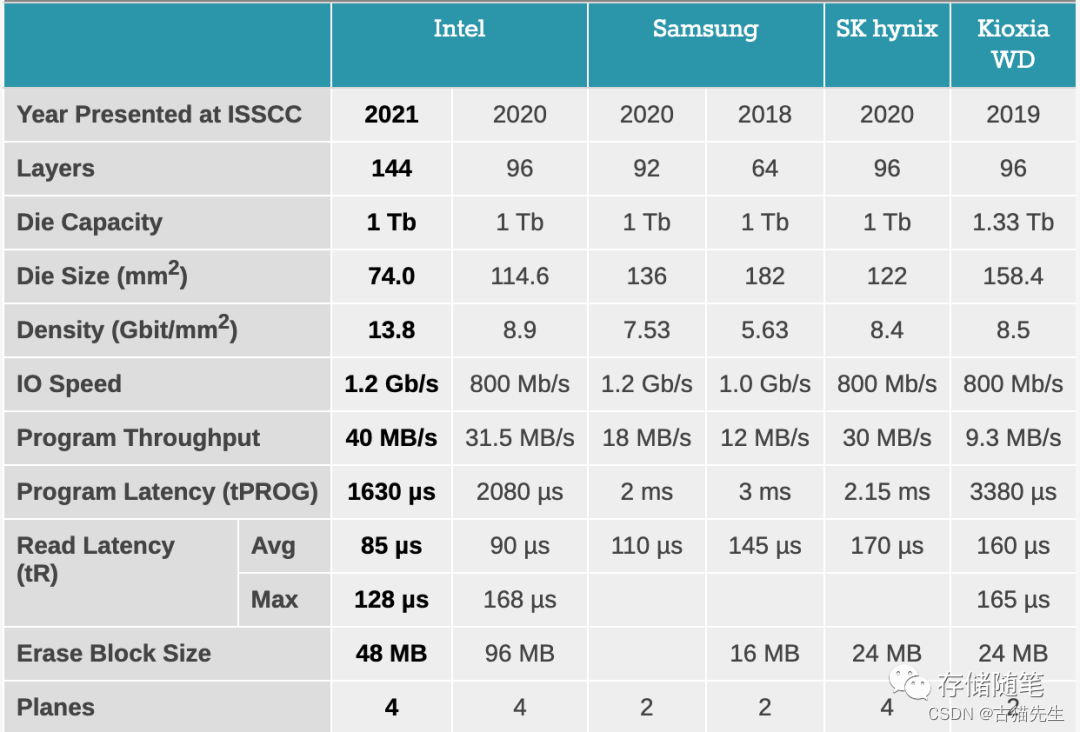
再搬出这个QLC SSD性能对比图,同样4plane的QLC SSD,采用FG架构的Intel QLC SSD写延迟tPROG=1.63ms比采用CTF架构的SK Hynix写延迟tPROG=2.15ms要低。
不同的NAND工艺架构,在不同的维度各有千秋,对维度对比,供大家参考。

(7)OP对性能的影响
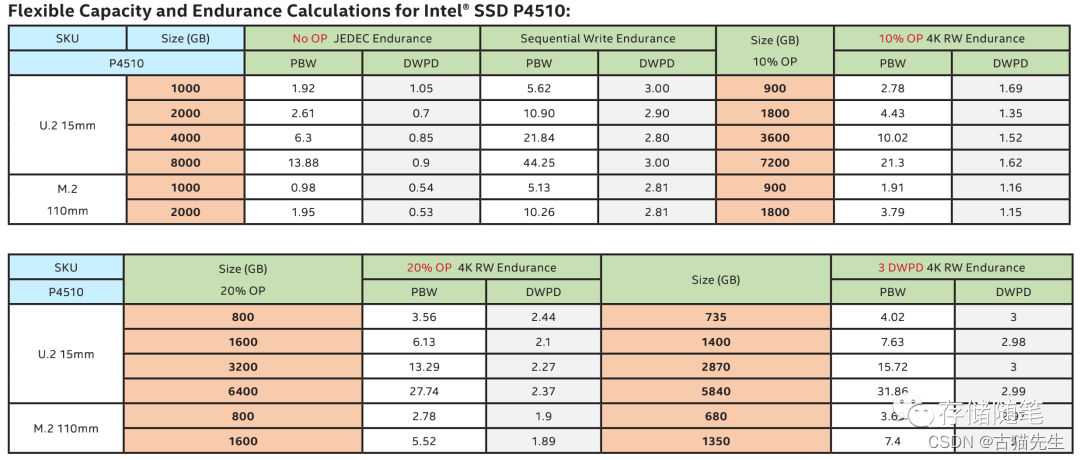
Over-Provisioning,OP冗余空间会影响NAND写入的比例,影响写放大,减少GC启动的频率,增大性能的稳定性QoS。比如根据Intel的白皮书信息来看,以P4510 4T为例
没有OP情况下,JEDEC标准压力下的DWPD=0.85
在OP 10%情况下,容量3.6T,DWPD上升到1.52,几乎翻了一倍。
在OP 20%情况下,容量3.2T,DWPD上升到2.27,接近原始容量的3倍。
JEDEC标准压力如下:
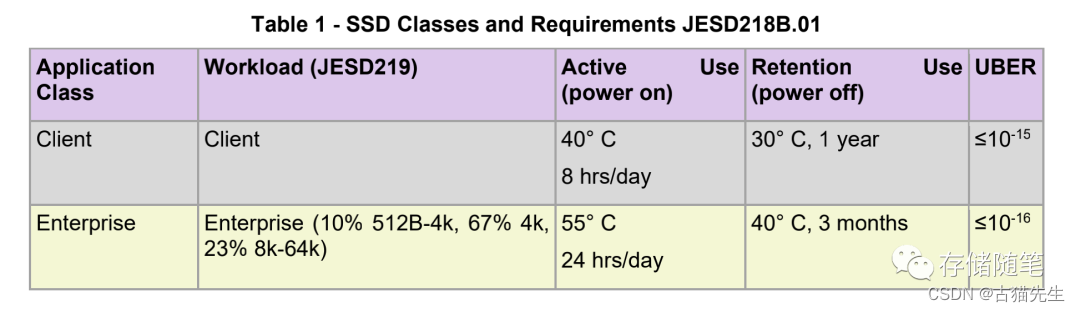
(8)PLP掉电保护对性能的影响
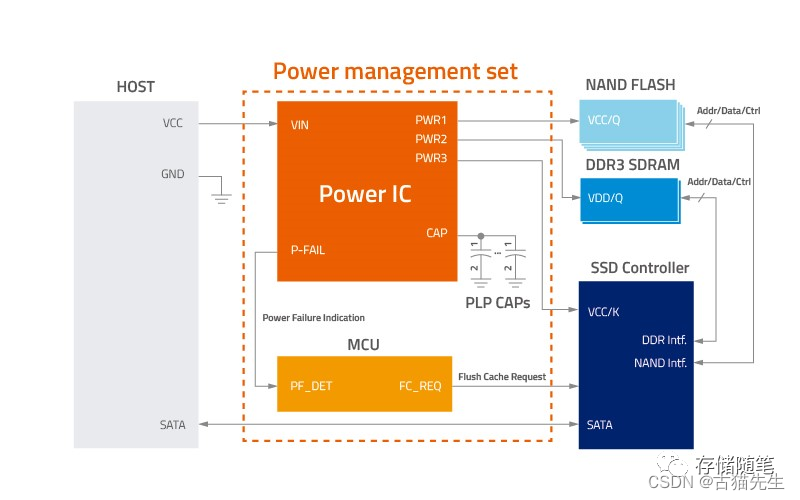
PLP,Power Loss Protection,掉电保护机制,目的是确保在异常掉电时刻,在缓存的数据可以有足够的能量保证数据落盘,确保数据安全。PLP通常在企业级SSD中是必备的,基于这个机制,在企业级SSD中,一旦发生电容故障,很多FW的算法会把前端IO处理限速,保证落盘的数据安全(也有一些做法是电容故障后盘进入写保护,防止新数据写入)。
(9)Erase/Program Suspend
在NAND的操作中,数据块Block Erase时间通常在ms级别,Program在几百us,Read操作在几十us,为了防止一些高优先级的读操作被Erase/Program堵塞,NAND提供了一种Erase/Program Suspend接口,允许可以先将erase/program暂停,优先影响读操作。


四、SSD设计背后的思考
一块固态硬盘设计背后,有硬件控制器,NAND闪存颗粒、DRAM,还有固件FTL算法等。SSD设计的本身其实是一件特别复杂的过程,需要考虑各种客户需求且要保证可靠性、性能、稳定性。

针对SSD的相关性能测试,SNIA也有专门针对SSD相关测试SPEC,同时各个SSD厂商也有很多独有的测试用例(一家SSD厂商的测试用例很多也是靠多年的填坑积累完善的)。现在看似SSD行业门槛很低,随便买个主控、NAND/DRAM颗粒就可以组装了(的确市场上有鱼龙混杂,有投机倒把之辈)。但是,如何真心要做出一款性能稳定的SSD,不但需要强大的技术实力,更需要丰富的经验积累。

不同的FW架构设计、FTL算法设计、NAND die plane/速率等的差异,都会直接影响SSD的性能与延迟,设计一块性能优越且稳定的SSD,是一项繁琐但具有很强艺术性的工程。
如果你有不同的想法与思路,欢迎留言交流,非常感谢!
精彩推荐:
NVMe IO数据传输如何选择PRP or SGL?
存储随笔2022年度最受欢迎文章榜单TOP15
从主流企业级PCIe Gen4 SSD性能对比,畅谈SSD性能调优的思考
浅析nvme原子写的应用场景
YMTC X3 NAND 232L 终露真容,全球领先
芯片级解密YMTC NAND Xtacking 3.0技术
Backblaze 2022 Q3 硬盘故障质量报告解读
漫谈云数据中心的前世今生
多维度深入剖析QLC SSD硬件延迟的来源
漫谈固态硬盘SSD全生命周期的质量管理
汽车存储SSD面临的挑战与机遇
超大规模云数据中心对存储的诉求有哪些?
SSD写放大的优化策略要统一标准了吗?
“后Optane时代”的替代存储方案有哪些?
浅析PCIe链路LTSSM状态机
浅析Relaxed Ordering对PCIe系统稳定性的影响
实战篇|浅析MPS对PCIe系统稳定性的影响
浅析PCI配置空间
浅析PCIe系统性能
PLC SSD虽来但远,QLC SSD火力全开
最全电脑固态硬盘SSD入门级白皮书
存储随笔《NVMe专题》大合集及PDF版正式发布!
加权循环仲裁WRR特性对NVME SSD性能有什么影响?
Linux NVMe Driver学习笔记之9: nvme_reset_work压轴大戏