文章目录
- 1 stack的介绍
- 2 stack的模拟实现
- 3 queue的介绍
- 4 queue的模拟实现
- 5 priority_queue(优先级队列)介绍
- 6 priority_queue 模拟实现
- 7 仿函数
- 8 deque的简单介绍
- 8.1 deque与vector list的比较
- 8.2 为什么选择deque作为stack和queue的底层默认容器
1 stack的介绍
①stack是一种容器适配器,用于后进先出的操作中,我们把允许插入和删除的一端称为栈顶,另一端称为栈底。
② stack是作为容器适配器被实现的,容器适配器即是对特定类封装作为其底层的容器,并提供一组特定的成员函数来访问其元素。
③ stack的底层容器可以是任何标准的容器类模板或者一些其他特定的容器类,这些容器类应该支持以下操作:
a empty:判空操作
b push_back:尾部插入元素操作
c pop_back:尾部删除元素操作
d back:获取尾部元素操作
④标准容器vector、deque、list均符合这些需求,默认情况下,如果没有为stack指定特定的底层容器,默认情况下使用deque。
2 stack的模拟实现
先来了解下容器适配器
适配器是一种设计模式(设计模式是一套被反复使用的、多数人知晓的、经过分类编目的、代码设计经验的总结),该种模式是将一个类的接口转换成客户希望的另外一个接口。

简单来说就是,stack封装好后是专门用在具有后进先出操作的环境中,但底层实现这种后进先出的操作可以是vector(顺序栈),list(链栈)以及deque。(deque后面会有讲解)
#include<deque>
namespace zbt
{
template<class T, class Container = deque<T>>
class stack
{
public:
void push(const T& x)//入栈
{
con.push_back(x);//假如con实例化为vector,那么这里调用的就是vector的尾插函数
}
void pop()//出栈
{
con.pop_back();
}
T& top()//返回栈顶元素
{
return con.back();
}
const T& top()const
{
return con.back();
}
bool empty()const//判空
{
return con.empty();
}
size_t size()const//返回元素个数
{
return con.size();
}
private:
Container con;//con模板实例化的时候可以为vector,list,deque等
};
}
3 queue的介绍
① 队列是一种容器适配器,专门用于先进先出的操作中,其中从容器一端插入元素,另一端删除元素。
② 队列作为容器适配器实现,容器适配器即将特定容器类封装作为其底层容器类,queue提供一组特定的成员函数来访问其元素。元素从队尾入队列,从队头出队列。
③ 底层容器可以是标准容器类模板之一,也可以是其他专门设计的容器类。该底层容器应至少支持以下操作:
a empty:检测队列是否为空
b size:返回队列中有效元素的个数
c front:返回队头元素的引用
d back:返回队尾元素的引用
e push_back:在队列尾部入队列
f pop_front:在队列头部出队列
④ 标准容器类deque和list满足这些要求。默认情况下,如果没有为queue实例化指定容器类,则使用标准容器deque。
4 queue的模拟实现
namespace zbt
{
template <class T, class Container = deque<T>>
class Queue
{
public:
void push(const T& x)//入队列
{
con.push_back(x);//尾插
}
void pop()//出队列
{
con.pop_front();//头删
}
T& front()//返回队头元素
{
return con.front();
}
const T& front()const//第一个const是函数的返回值不能修改,第二个const在该成员函数中不能对类的任何成员进行修改
{
return con.front();
}
T& back()//返回队尾元素
{
return con.back();
}
const T& back()const
{
return con.back();
}
bool empty()const//判空
{
return con.empty();
}
size_t size()const//返回元素个数
{
return con.size();
}
private:
Container con;
};
}
5 priority_queue(优先级队列)介绍
① 优先级队列是一种容器适配器,queue提供一组特定的成员函数来访问其元素。元素从特定容器的“尾部”弹出,其称为优先队列的顶部。
② 优先级队列的结构是堆,在堆中可以随时插入元素,并且只能检索最大堆元素(优先队列中位于顶部的元素)
③ 底层容器可以是任何标准容器类模板,也可以是其他特定设计的容器类。容器应该可以通过随机访问迭代器访问,并支持以下操作:
a empty():检测容器是否为空
b size():返回容器中有效元素个数
c front():返回容器中第一个元素的引用
d push_back():在容器尾部插入元素(插入元素后仍要保持堆的结构)
e pop_back():删除容器尾部元素(删除元素后仍要保持堆的结构)
④ 标准容器类vector和deque满足这些需求。默认情况下,如果没有为特定的priority_queue类实例化指定容器类,则使用vector
⑤需要支持随机访问迭代器,以便始终在内部保持堆结构。
6 priority_queue 模拟实现

优先级队列默认使用vector作为其底层存储数据的容器,在vector上又使用了堆算法将vector中元素构造成
堆的结构,因此priority_queue就是堆,所有需要用到堆的地方,都可以考虑使用priority_queue。

namespace zbt
{
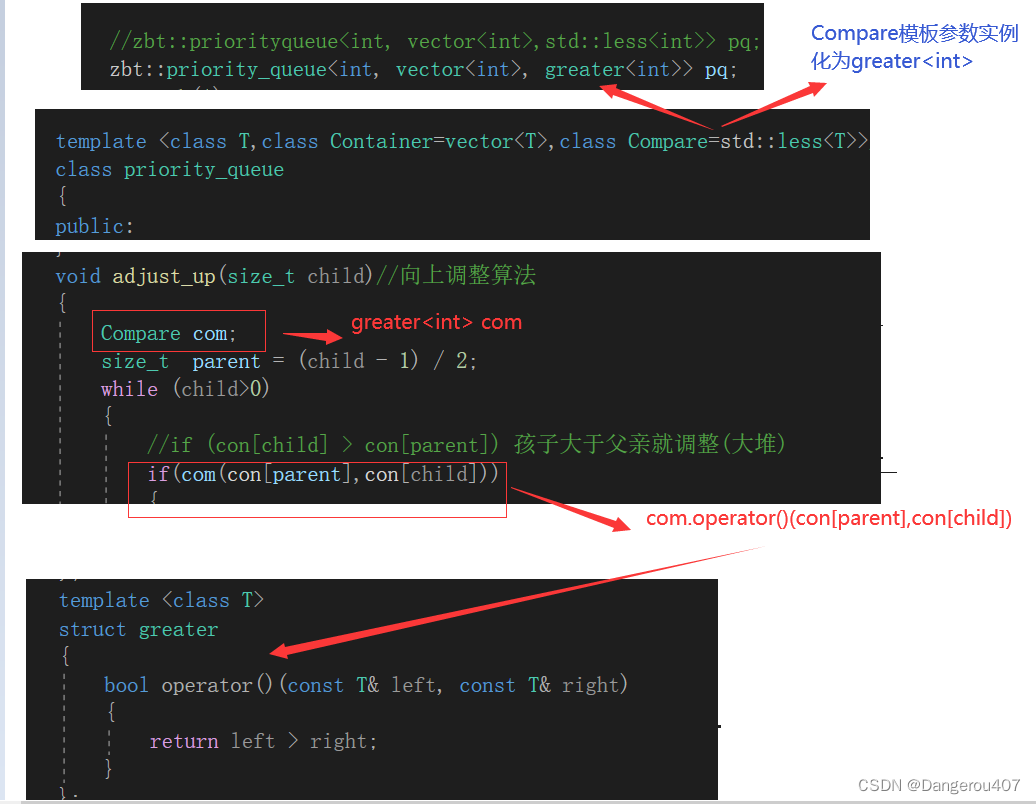
template <class T,class Container=vector<T>,class Compare=std::less<T>>//默认仿函数参数为less<T>,排大堆
class priority_queue
{
public:
priority_queue()
{
}
template<class InputIterator>
priority_queue(InputIterator first, InputIterator last)//用迭代器区间进行构造
{
while (first != last)
{
con.push_back(*first);
first++;
}
for (int i = (con.size() - 1 - 1) / 2; i >= 0; i--)//计算出最后一个非叶子结点的下标
{
adjust_down(i);//向下调整法建堆
}
}
void adjust_up(size_t child)//向上调整算法
{
Compare com;
size_t parent = (child - 1) / 2;
while (child>0)
{
//if (con[child] > con[parent]) 孩子大于父亲就调整(大堆)
if(com(con[parent],con[child]))
{
std::swap(con[child], con[parent]);
child = parent;
parent = (child - 1) / 2;
}
else
{
break;
}
}
}
void push(const T& x)//入队列,先尾插然后再依次向上调整,保持堆的结构
{
con.push_back(x);
adjust_up(con.size() - 1);
}
void adjust_down(size_t parent)//向下调整算法
{
Compare com;
size_t child = parent * 2 + 1;//左孩子
while (child < con.size())
{
//if (child + 1 < con.size() && con[child + 1] > con[child])选出左右孩子中较大的结点
if(child+1<con.size()&&com(con[child],con[child+1]))
{
child = child + 1;
}
//if (con[child] > con[parent])孩子大于父亲就调整(大堆)
if(com(con[parent],con[child]))
{
std::swap(con[child], con[parent]);
parent = child;
child = parent * 2 + 1;
}
else
{
break;
}
}
}
void pop()//删除堆顶元素
{
//为尽量完整保持堆的结构,先将堆顶和最后一个元素交换位置,删除最后一个位置的元素,此时除了堆顶元素,它的左右子树还保持
//堆的结构,只需调用向下调整算法调整堆
std::swap(con[0], con[con.size() - 1]);
con.pop_back();
adjust_down(0);
}
const T& top()const//返回堆顶元素
{
return con[0];
}
bool empty()const//判空
{
return con.empty();
}
size_t size()const//返回元素个数
{
return con.size();
}
private:
Container con;
};
7 仿函数
实现大堆和小堆的代码区别就是在向下和向上调整算法的比较代码
调整大堆是 if(con[child] > con [parent])
调整小堆是 if(con[parent]>con[child])
如何在一份代码里实现两种比较,此时就需要用到仿函数
仿函数 就是模仿函数的调用方式,通过在类里面重载操作符() ,然后实例化出对象并且调用该重载函数来实现具体的功能
template<class T>
struct less
{
bool operator()(const T& left, const T& right)
{
return left < right;
}
};
template <class T>
struct greater
{
bool operator()(const T& left, const T& right)
{
return left > right;
}
};
使用
zbt::less<int> ls;
cout << ls.operator()(5, 3) << endl;;
cout << ls(5, 3) << endl;
zbt::greater<int> gr;
cout << gr.operator()(5, 3) << endl;
cout << gr(5, 3) << endl;
8 deque的简单介绍
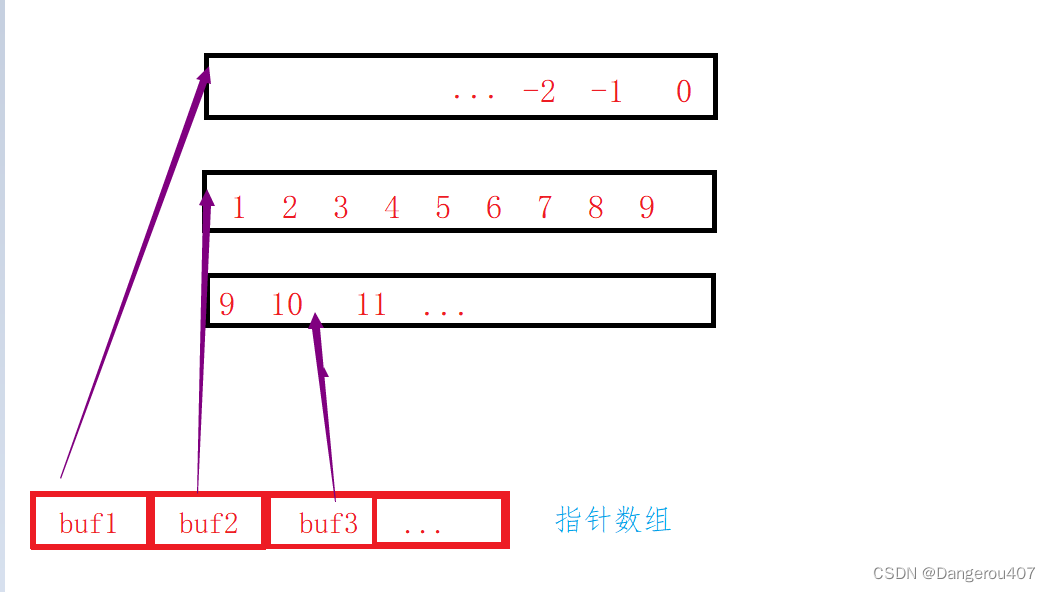
deque(双端队列):是一种双开口的"连续"空间的数据结构,双开口的含义是:可以在头尾两端进行插入和删除操作,且时间复杂度为O(1),与vector比较,头插效率高,不需要搬移元素;与list比较,空间利用率比较高。
deque的底层实现并不是真正连续的空间,而是由一段段连续的小空间拼接而成的,实际deque类似于一个动态的二维数组,其底层结构如下图所示
8.1 deque与vector list的比较
① 与vector比较
deque的优势是:头部插入和删除时,不需要搬移元素,效率特别高,而且在扩容时,也不
需要搬移大量的元素
② 与list比较
deque的优势是:其底层是连续空间,空间利用率比较高,不需要存储额外字段。
③ deque的缺点
不适合遍历,因为在遍历时,deque的迭代器要频繁的去检测其是否移动到某段小空间的边界,导致效率低下。
8.2 为什么选择deque作为stack和queue的底层默认容器
1.stack和queue不需要遍历(因此stack和queue没有迭代器),只需要在固定的一端或者两端进行插入删除操作。
2 在扩容时,相比vector效率会高,不需要搬移大量数据。