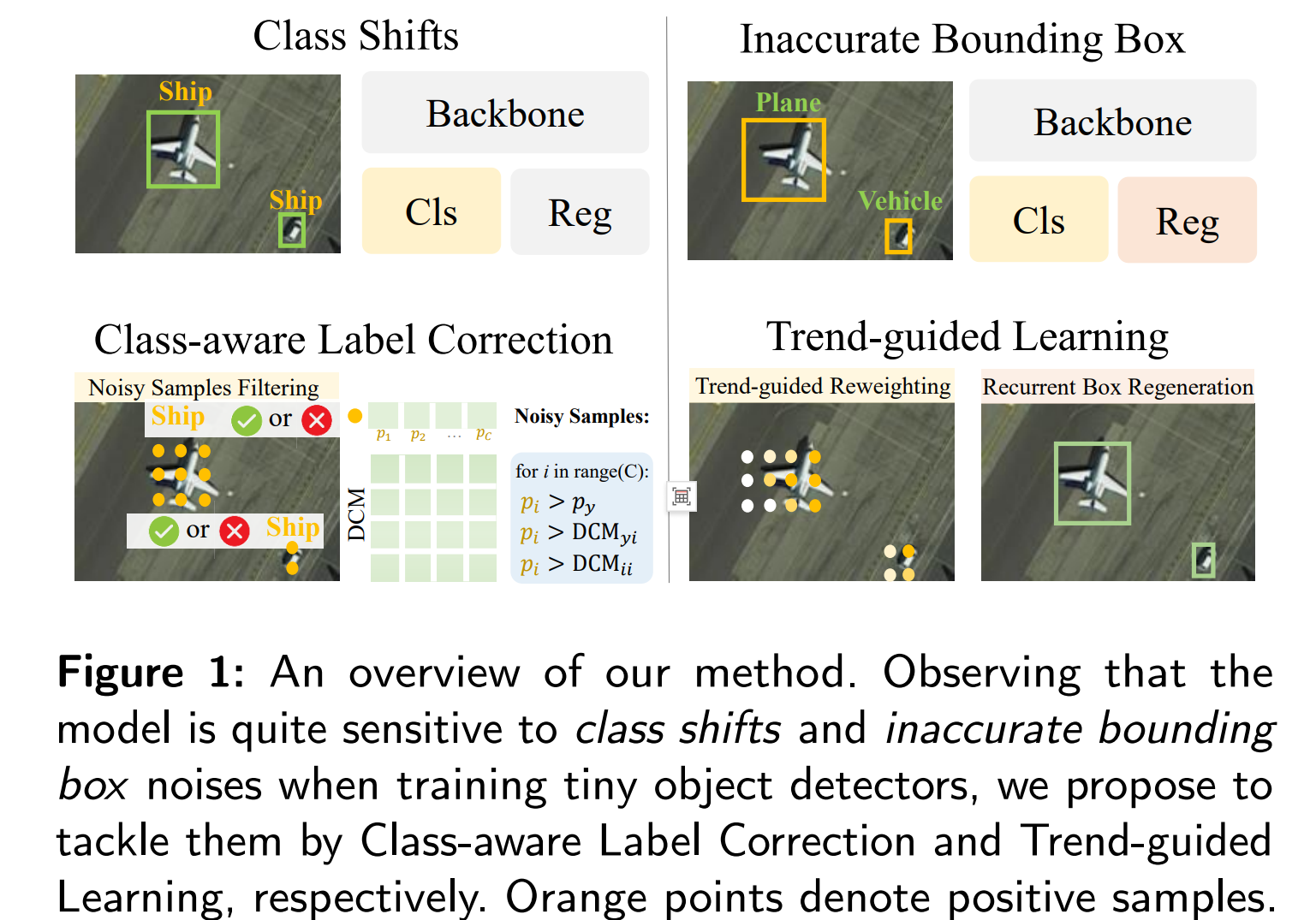
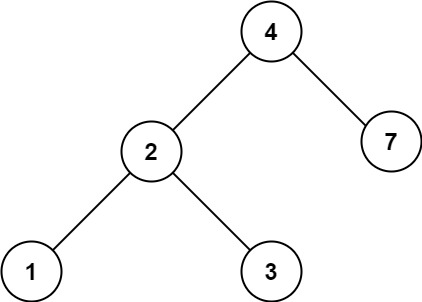
算法第15天| (二叉树part02)层序遍历、226.翻转二叉树(优先掌握递归)、101. 对称二叉树(优先掌握递归)
文章目录
- 算法第15天| (二叉树part02)层序遍历、226.翻转二叉树(优先掌握递归)、101. 对称二叉树(优先掌握递归)
- 一、层序遍历
- 二、226. 翻转二叉树(优先掌握递归)
- 三、101. 对称二叉树(优先掌握递归)
二叉树理论基础
一、层序遍历
代码随想录链接
二叉树中的层序遍历相当于图论中的广度优先搜索;
二叉树中的递归遍历相当于图论中的深度优先搜索。
二叉树本身只有父节点和子结点之间的连接,同一层之间的节点并无连接关系,也就没办法做到层序遍历,所以要借助一个队列,保存每一层中遍历过的元素。(图论中的广度优先搜索同样是依赖队列实现的,利用队列的先进先出)
每次弹出一个节点的时候,就把这个节点的左右孩子都加进去。这时候,队列里就会有上下两层的元素,就需要用size记录每一层有多少个元素,该层的元素是否遍历完了。当把上一层的元素弹出完,此时队列中还剩的元素个数就是本层的节点个数。
/**
* Definition for a binary tree node.
* struct TreeNode {
* int val;
* TreeNode *left;
* TreeNode *right;
* TreeNode() : val(0), left(nullptr), right(nullptr) {}
* TreeNode(int x) : val(x), left(nullptr), right(nullptr) {}
* TreeNode(int x, TreeNode *left, TreeNode *right) : val(x), left(left), right(right) {}
* };
*/
class Solution {
public:
vector<vector<int>> levelOrder(TreeNode* root) {
// 首先定义一个队列, 用于存储将要访问的节点,以按层次顺序处理它们
queue<TreeNode*> que;
// 不能直接把root加到队列里,首先要保证root不为空(第一个元素也有可能为空,极端情况必须考虑)
if (root != NULL) que.push(root);
// 最终的结果用二维数组result保存
// 每一个内层向量表示一层的节点值
vector<vector<int>> result;
// 遍历二叉树,终止条件是没有元素再添加到队列里
while (!que.empty()) {
// size用于记录当前层节点的个数,用于控制队列中弹出的节点数量
// 第一层节点数量为1(只有一个根节点)
int size = que.size();
// 定义一个一维数组,把每一层的元素放进一维数组,最终的结果应该是二维数组,包含每一层(每一层的元素存在一个一维数组);最终的结果用二维数组result保存
vector<int> vec;
// 这里一定要使用固定大小size,不要使用que.size(),因为que.size是不断变化的
//通过size控制本层的元素
for (int i = 0; i < size; i++) {
// 获取队列前端节点
TreeNode* node = que.front();
// 将节点弹出队列
que.pop();
// 将节点记录到一维数组里
vec.push_back(node->val);
// 将节点的左右孩子加入队列
if (node->left) que.push(node->left);
if (node->right) que.push(node->right);
}
result.push_back(vec);
}
return result;
}
};
为什么前中后序遍历用栈,层序遍历用队列???
因为,前中后序遍历需要栈的前进后出,层序遍历要利用队列的先进先出。
1.前序、中序和后序遍历都是深度优先搜索(DFS)方法。DFS 的特点是尽可能深地探索节点的子树,直到到达叶节点为止。在这些遍历方法中,栈(Stack)是一种非常合适的数据结构,因为它具有后进先出(LIFO)的特点,使用栈可以帮助我们回溯和记录访问过的节点,适合用于回溯到上一个节点。前序遍历递归实现很简单,但用栈可以避免递归的函数调用开销。
2.层序遍历(广度优先搜索,BFS)的顺序是按层次逐层访问节点,即:访问当前层的所有节点,然后再访问下一层的节点。队列(Queue)是一种适合这种访问顺序的数据结构,因为它具有先进先出(FIFO)的特点,能够保证我们按层次顺序处理节点。
二、226. 翻转二叉树(优先掌握递归)
翻转二叉树
代码随想录链接
这道题目如果想清楚就是送分题。用前序和后序最直接,中序比较绕;非递归和层序遍历方法也可以。
采用先序遍历的思路:(中左右)
- 确定递归函数的返回值和参数:
因为题目要求返回新的二叉树的根节点,所以函数的返回值类型就是节点的定义类型Tree Node*;定义函数invertTree,参数为传入的根节点。 - 确定终止条件:遇到空节点:if (root==Null) return root;(如果根节点原本就为空,直接return)
- 处理逻辑:交换此节点 root的左右孩子;(root在这里不是指的根节点,而是遍历的每一个节点)
swap(root->left,root->right);
前序递归代码:(后序只需要把swap放在左右后面)
class Solution {
public:
TreeNode* invertTree(TreeNode* root) {
if (root == NULL) return root;
swap(root->left, root->right); // 中
invertTree(root->left); // 左
invertTree(root->right); // 右
// swap(root->left, root->right); // 中 (后序)
return root;
}
};
后序递归代码:
class Solution {
public:
TreeNode* invertTree(TreeNode* root) {
if (root == NULL) return root;
invertTree(root->left); // 左
swap(root->left, root->right); // 中
invertTree(root->left); // 右 (注意这里依然要写->left,因为先处理了左,翻转了左,原来的左子树变成了右子树,如果再处理右,则实际上是处理了两遍左子树,而没有处理右子树)
return root;
}
};
迭代法前序遍历:
class Solution {
public:
TreeNode* invertTree(TreeNode* root) {
if (root == NULL) return root;
stack<TreeNode*> st;
st.push(root);
while(!st.empty()) {
TreeNode* node = st.top(); // 中
st.pop();
swap(node->left, node->right);
if(node->right) st.push(node->right); // 右
if(node->left) st.push(node->left); // 左
}
return root;
}
};
迭代法前中后序统一写法代码:
class Solution {
public:
TreeNode* invertTree(TreeNode* root) {
stack<TreeNode*> st;
if (root != NULL) st.push(root);
while (!st.empty()) {
TreeNode* node = st.top();
if (node != NULL) {
st.pop();
if (node->right) st.push(node->right); // 右
if (node->left) st.push(node->left); // 左
st.push(node); // 中
st.push(NULL);
} else {
st.pop();
node = st.top();
st.pop();
swap(node->left, node->right); // 节点处理逻辑
}
}
return root;
}
};
层序遍历(广度优先):
class Solution {
public:
TreeNode* invertTree(TreeNode* root) {
queue<TreeNode*> que;
if (root != NULL) que.push(root);
while (!que.empty()) {
int size = que.size();
for (int i = 0; i < size; i++) {
TreeNode* node = que.front();
que.pop();
swap(node->left, node->right); // 节点处理
if (node->left) que.push(node->left);
if (node->right) que.push(node->right);
}
}
return root;
}
};
三、101. 对称二叉树(优先掌握递归)
题目链接
代码随想录链接
二叉树类的题目,确定遍历顺序非常重要。
本题实际上是考察二叉树是否可以翻转的问题,考察的是同时处理两个二叉树的遍历过程,同时比较两个二叉树里边对应的节点的情况.
本题只能使用后序遍历;大体思路是,转换成判断该二叉树是否可以翻转的问题,如果左右子树翻转之后能够和原来相同,则该二叉树为对称二叉树。要先把左右子树都处理完了,都返回给根节点,根节点(中)才能直到左右子树是否可以翻转。
代码实现:定义一个函数,需要传入左子树和右子树,即把根节点的左子树的头节点和右子树的头节点传入进来,判断根节点的左子树和右子树是否是可以相互翻转的,如果可以的话,整个二叉树就是对称二叉树;
首先要想,什么情况下return true,什么情况下return false.
节点的左子树为空,右子树不为空;左子树不为空,右子树为空;左右子树均为空;左右子树均不为空且值不相等;左右子树均不为空且值相等,这时,需要继续向下遍历。
class Solution {
public:
bool compare(TreeNode* left, TreeNode* right) {
// 首先排除空节点的情况
if (left == NULL && right != NULL) return false;
else if (left != NULL && right == NULL) return false;
else if (left == NULL && right == NULL) return true;
// 排除了空节点,不必担心空指针异常了;再排除数值不相同的情况
else if (left->val != right->val) return false;
// 此时就是:左右节点都不为空,且数值相同的情况
// 此时才做递归,做下一层的判断
// 比较二叉树外侧的节点数值是否相等,也就是左节点的左孩子,右节点的右孩子
bool outside = compare(left->left, right->right); // 左子树:左、 右子树:右
// 比较二叉树内侧的节点数值是否相等,也就是左节点的右孩子,右节点的左孩子
bool inside = compare(left->right, right->left); // 左子树:右、 右子树:左
// 内外侧的节点数值均相等,才能说明下面的所有孩子是可以相互翻转的
bool isSame = outside && inside; // 左子树:中、 右子树:中 (逻辑处理)(所以是后序遍历)
return isSame;
}
bool isSymmetric(TreeNode* root) {
if (root == NULL) return true;
return compare(root->left, root->right);
}
};
看不出来前中后序遍历的简洁代码:
class Solution {
public:
bool compare(TreeNode* left, TreeNode* right) {
if (left == NULL && right != NULL) return false;
else if (left != NULL && right == NULL) return false;
else if (left == NULL && right == NULL) return true;
else if (left->val != right->val) return false;
else return compare(left->left, right->right) && compare(left->right, right->left);
}
bool isSymmetric(TreeNode* root) {
if (root == NULL) return true;
return compare(root->left, root->right);
}
};
使用队列
通过队列来判断根节点的左子树和右子树的内侧和外侧是否相等,如动画所示:

class Solution {
public:
bool isSymmetric(TreeNode* root) {
if (root == NULL) return true;
queue<TreeNode*> que;
que.push(root->left); // 将左子树头结点加入队列
que.push(root->right); // 将右子树头结点加入队列
while (!que.empty()) { // 接下来就要判断这两个树是否相互翻转
TreeNode* leftNode = que.front(); que.pop();
TreeNode* rightNode = que.front(); que.pop();
if (!leftNode && !rightNode) { // 左节点为空、右节点为空,此时说明是对称的
continue;
}
// 左右一个节点不为空,或者都不为空但数值不相同,返回false
if ((!leftNode || !rightNode || (leftNode->val != rightNode->val))) {
return false;
}
que.push(leftNode->left); // 加入左节点左孩子
que.push(rightNode->right); // 加入右节点右孩子
que.push(leftNode->right); // 加入左节点右孩子
que.push(rightNode->left); // 加入右节点左孩子
}
return true;
}
};
使用栈
细心的话,其实可以发现,这个迭代法,其实是把左右两个子树要比较的元素顺序放进一个容器,然后成对成对的取出来进行比较,那么其实使用栈也是可以的。只要把队列原封不动的改成栈就可以了.
class Solution {
public:
bool isSymmetric(TreeNode* root) {
if (root == NULL) return true;
stack<TreeNode*> st; // 这里改成了栈
st.push(root->left);
st.push(root->right);
while (!st.empty()) {
TreeNode* leftNode = st.top(); st.pop();
TreeNode* rightNode = st.top(); st.pop();
if (!leftNode && !rightNode) {
continue;
}
if ((!leftNode || !rightNode || (leftNode->val != rightNode->val))) {
return false;
}
st.push(leftNode->left);
st.push(rightNode->right);
st.push(leftNode->right);
st.push(rightNode->left);
}
return true;
}
};
PS:真正的把题目搞清楚其实并不简单,leetcode上accept了和真正掌握了还是有距离的。
在迭代法中我们使用了队列,需要注意的是这不是层序遍历,而且仅仅通过一个容器来成对的存放我们要比较的元素,知道这一本质之后就发现,用队列,用栈,甚至用数组,都是可以的。
参考链接:
作者:力扣官方题解
链接:
https://leetcode.cn/problems/binary-tree-level-order-traversal/solutions/241885/er-cha-shu-de-ceng-xu-bian-li-by-leetcode-solution/
https://leetcode.cn/problems/symmetric-tree/solutions/268109/dui-cheng-er-cha-shu-by-leetcode-solution/
来源:力扣(LeetCode)
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。