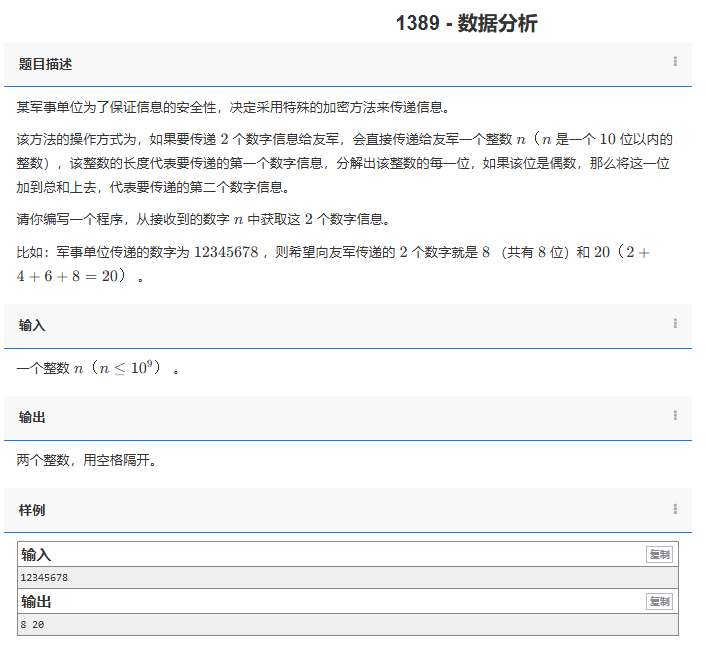
想好好熟悉一下llvm开发一个新后端都要干什么,于是参考了老师的系列文章:
LLVM 后端实践笔记
代码在这里(还没来得及准备,先用网盘暂存一下):
链接: https://pan.baidu.com/s/1yLAtXs9XwtyEzYSlDCSlqw?pwd=vd6s 提取码: vd6s
一、第一节 汇编器
独立汇编器可以理解为依赖于 LLVM 后端提供的接口实现的一个独立软件,因为 LLVM 和 gcc 在这个地方的实现逻辑不一样。
在 gcc 中,编译器和汇编器是两个独立的工具,编译器,也就是 cc,只能生成汇编代码,而汇编器 as,才用来将汇编代码翻译为二进制目标代码,gcc 驱动软件 gcc 将这些工具按顺序驱动起来(还包括预处理器、链接器等),最终实现从 C 语言到二进制目标代码的功能。但是,这样的设计有个缺点,每个工具都需要先对输入文件做 parse,然后再输出时写入文件,反复多次的磁盘读写一定程度影响了编译的效率。
而在 LLVM 中,编译器后端本身就可以将中间代码(对应 gcc 中 cc 的中间表示)翻译成二进制目标文件,而不需要发射汇编代码到文件中,再重新 parse 汇编文件。当然它也可以通过配置命令行参数指定将中间代码翻译成汇编代码,方便展示底层程序逻辑。
但我们目前已经实现的这些功能,却无法支持输入汇编代码,输出二进制目标文件,虽然通常情况下已经不再需要手工编写汇编代码,但在特殊情况下,比如引导程序、调试特殊功能、需要优化性能等场合下,还是需要编写汇编代码,所以一个汇编器依然是很重要的。
显然,我们之前的章节已经把和指令相关的汇编表示都在 TableGen 中实现了,这一节中,最核心的就是实现一个汇编器的 parser,并将其注册到 LLVM 后端框架中,并使能汇编功能。并且,汇编器的核心功能在 LLVM 中也已经实现了,原理其实就是一个语法制导的翻译,我们要做的只是重写其中部分和后端架构相关的接口。
我还实现了一个额外的特性。当我们仅使用汇编器时,编译器占用的寄存器 $sw,就可以被释放出来当做普通寄存器用了,所以我们重新定义一下 GPROut 这个寄存器类别,并将 Cpu0.td 拆分成两份,将它拆分为 Cpu0Asm.td 和 Cpu0Other.td,前者会在调用汇编器时被使用到,而后者保持和之前一样的设计。
因为 $sw 寄存器是编译器用来记录状态的,如果只编写汇编代码,我们认为程序员有义务去维护这个寄存器中的值什么时候是有效的,进而程序员就可以在认为这个寄存器中值无效时,把它当做普通寄存器来使用。我们的标量寄存器有很多,多这样一个寄存器的意义并不是很大,这里依然这么做,其实是想展示一下 TableGen 机制的灵活性。
在 Cpu0 的后端代码路径下,新建一个子目录 AsmParser,在这个路径下新建 Cpu0AsmParser.cpp 用来实现绝大多数功能。
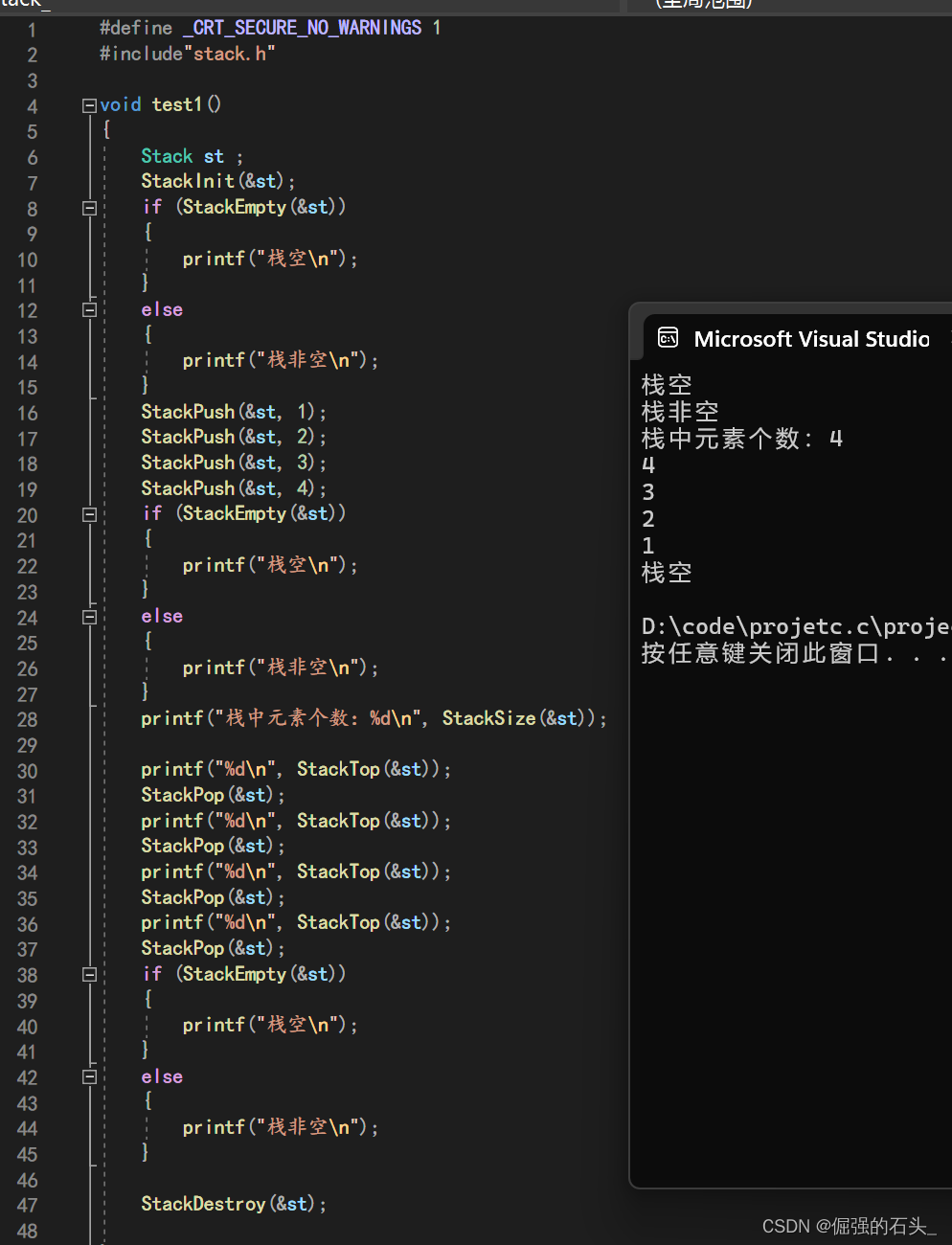
1.1 修改前的效果
llvm-mc -triple=cpu0 -filetype=obj test.s -o test.o
提示我们当前的汇编器不支持cpu0架构。llvm-mc是llvm的汇编器,能够将汇编文件.s编成目标文件.o。
1.2 修改
1.2.1 AsmParser/Cpu0AsmParser.cpp
作为一个独立的功能模块,使能它的 DEBUG 信息名称为 cpu0-asm-parser,声明一些新的 class: Cpu0AsmParser 作为核心类,用来处理所有汇编 parser 的工作,我们稍后介绍;Cpu0AssemblerOptions 这个类用来做汇编器参数的管理;Cpu0Operand 类用来解析指令操作数,因为指令操作数可能有各种不同的类型,所以将这部分单独抽出来实现。
Cpu0AsmParser 类继承了基类 MCTargetAsmParser,并重写了部分接口,而有关于汇编 parser 的详细逻辑可以参考 AsmParser.cpp 中的实现。两个比较重要的重写函数:ParseInstruction() 和MatchAndEmitInstruction()。汇编器在做 parser 时,要先做 Parse,然后再对符合语法规范的指令做指令匹配,前者的关键函数就是ParseInstruction(),后者的关键函数就是MatchAndEmitInstruction()。
在 ParseInstruction() 中,根据传入的词法记号,解析指令助记符存入 Operands 容器中,然后在后边依次解析每个操作数,也存入 Operands 中。对于不满足语法规范的输入,比如操作数之间缺逗号等这种问题,直接报错并退出。在解析操作数时,调用了 ParseOperand() 接口,这也是一个很重要的接口,专用来解析操作数,我们也重写了这个接口以适应我们的类型,尤其是地址运算符。ParseInstruction() 执行完毕后会返回到 AsmParser.cpp 中的 parseStatement 方法中,并在做一些分析后,再调用到 MatchAndEmitInstruction() 方法。
在 MatchAndEmitInstruction() 函数中,将 Operands 容器对象传入。首先调用 MatchInstructionImpl 函数,这个函数是 TableGen 参考我们的指令 td 文件生成的 Cpu0GenAsmMatcher.inc 文件自动生成的。匹配之后如果成功了,还需要做额外的处理,如果这个是伪指令,需要汇编器展开,这种指令我们设计了几条,在之后会提到,这种指令需要调用 expandInstruction() 函数来展开,后者根据对应指令调用对应的展开函数,如果不是伪指令,就调用 EmitInstruction() 接口来发射编码,这个函数与我们前边章节设计指令输出的接口是同一个,也就是说在汇编 parser 之后的代码,是复用了之前的代码。匹配如果失败了,则做简单处理并返回,这里我们只实现了几种简单的情况,如果你的后端有一些 TableGen 支持不了的指令形式,也可以在这里做额外的处理,不过还是尽量去依赖 TableGen 的匹配表为好。
在 ParseOperand() 函数中,将前边 parse 出来的 Operands 容器对象传入。首先调用 MatchOperandParserImpl() 函数来 parse 操作数,这个函数也是 Cpu0GenAsmMatcher.inc 文件中定义好的。如果这个函数 parse 成功,就返回, 否则继续在下边完成一些自定义的 parse 动作,在一个 switch 分支中,根据词法 token 的类型来分别处理。其中,对于 Token,可能是一个寄存器,调用 tryParseRegisterOperand() 函数来处理,如果没有解析成功,则按照标识符处理;对于标识符、加减运算符和数字等 Token 的情况,统一调用 parseExpression() 来处理;对于百分号 Token,表示可能是一个重定位信息,比如 %hi($r1),则调用 parseRelocOperand() 函数来处理。
其他函数就不一一说明了,其中包括很多在 parse 操作数时,不同的操作数下的特殊处理,还有伪指令的展开动作,重定位操作数的格式解析以及生成重定位表达式,寄存器、立即数的 parse,还有汇编宏指令的解析(比如 .macro, .cpload 这一类)。
在最后,这些代码都实现完毕后,需要调用 RegisterMCAsmParser 接口将汇编 parser 注册到 LLVM 中,这个步骤写入到 LLVMInitializeCpu0AsmParser() 函数中。
1.2.2 Cpu0RegisterInfoGPROutForAsm.td
在这个文件中,我们定义的 GPROut 类别是支持完整的 CPURegs 的。
1.2.3 Cpu0RegisterInfoGPROutForOther.td
在这个文件中,我们定义的 GPROut 类别不包含 $sw 寄存器。
1.2.4 Cpu0Asm.td
由 Cpu0.td 拆分出来的文件,和 Cpu0Other.td 对应。
1.2.5 Cpu0Other.td
由 Cpu0.td 拆分出来的文件,和 Cpu0Asm.td 对应。
1.2.6 Cpu0.td
删掉 Target.td、Cpu0RegisterInfo.td 文件的包含。添加汇编器 parser 在 td 中的定义,并注册到 Cpu0 的属性中。这些都是常规操作。
1.2.7 Cpu0InstrFormats.td
增加针对伪指令的描述性 class,继承自 Cpu0Pseudo 类。
1.2.8 Cpu0InstrInfo.td
增加 Operand 操作数 class 中 ParserMatchClass 和 ParserMethod 属性的描述,只有这样,td 中的操作数才会支持汇编 parse。
定义伪指令 LoadImm32Reg, LoadAddr32Reg, LoadAddr32Imm,这几个指令会在 Cpu0AsmParser.cpp 中实现对应的展开函数 expandLoadImm(), expandLoadAddressImm 和 expandLoadAddressReg,这些函数统一放到 expandInstruction() 中管理,后者在 MatchAndEmitInstruction() 函数中被调用。
1.2.9 Cpu0RegisterInfo.td
将 GPROut 的定义移动到 Cpu0RegisterInfoGPROutForAsm.td 和 Cpu0RegisterInfoGPROutForOther.td 中。
1.3 修改后效果
用上述命令能正确生成.o文件,我们还可以使用之前适配的反汇编器进行反汇编查看。