目录
1嵌套子查询
1.1月均完成试卷数不小于3的用户爱作答的类别
1.2月均完成试卷数不小于3的用户爱作答的类别
编辑1.3 作答试卷得分大于过80的人的用户等级分布
2合并查询
2.1每个题目和每份试卷被作答的人数和次数
2.2分别满足两个活动的人
3连接查询
3.1满足条件的用户的试卷完成数和题目练习数
3.2 每个6/7级用户活跃情况
1嵌套子查询
1.1月均完成试卷数不小于3的用户爱作答的类别

我的代码:思路就是这么个思路,反正没有搞出来当月均完成试卷数
select tag,count(submit_time) tag_cnt
from exam_record er join examination_info ei
on er.exam_id = ei.exam_id
where uid in (当月均完成试卷数>=3)
group by tag
order by tag_cnt desc反正没有搞出来当月均完成试卷数,报错:

大佬正确答案:
居然和我的差不多,我就分组的时候少了uid,还有按照uid进行分组。此外,作答次数=count(start_time),而不是提交次数。
select tag, count(start_time) as tag_cnt
from exam_record er inner join examination_info ei
on er.exam_id = ei.exam_id
where uid in
(select uid
from exam_record er
group by uid, month(start_time)
having count(submit_time) >= 3)
group by tag
order by tag_cnt desc复盘:
(1)uid,month(submit_time)是啥呢,如果原来只是按照month(submit_time)进行分组,1002,1003,1005都有多个

(2)如果按照uid,month(submit_time)进行分组,情况如下

(3)这么如果只是按照month(submit_time) 分组,uid,month(submit_time)只有9和null两种情况,当使用GROUP BY子句时,NULL值将被视为一个独立的分组,并在结果集中显示一个额外的分组来表示它。
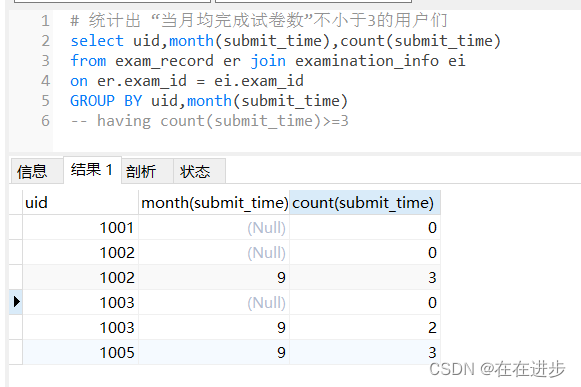
(4)结果显示只有1002,1005这两个用户满足要求,然后查找这两个用户的作答的类别及作答次数。

(5)验证:where uid =1002 or uid = 1005 等价于 子查询的效果

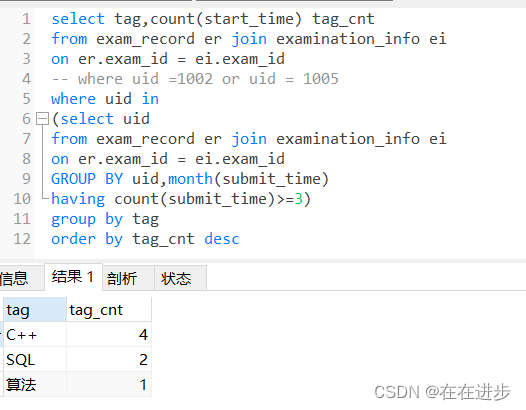
还有一种大佬做法是:
select tag,count(start_time) tag_cnt
from exam_record er join examination_info ei
on er.exam_id = ei.exam_id
-- where uid =1002 or uid = 1005
WHERE er.uid IN (
SELECT uid
FROM exam_record
GROUP BY uid
HAVING COUNT(submit_time) / COUNT(DISTINCT DATE_FORMAT(submit_time, "%Y%m")) >= 3
)
group by tag
order by tag_cnt desc这样出来的两个用户也是1002和1005:
- 相当于:月均完成试卷数 = 总完成次数/哪些月份提交了数据
COUNT(DISTINCT DATE_FORMAT(submit_time, "%Y%m"))=1,所以答案一样的。

COUNT(DISTINCT DATE_FORMAT(submit_time, "%Y%m"))中的distinct很重要:

1.2月均完成试卷数不小于3的用户爱作答的类别

我的代码:答案错误,但是我能发现的的改了,
(1)SQL类,(2)当天,(3)作答人数
select er.exam_id,
any_value(count(er.submit_time)) uv,
round(avg(er.score),1) avg_score
from examination_info ei join exam_record er
on ei.exam_id = er.exam_id
where ei.tag = "SQL"
and day(submit_time)=day(release_time)
and er.uid in
(select uid
from user_info
where level > 5)
group by er.exam_id
order by uv desc,avg_score asc
正确代码:
select er.exam_id,
any_value(count(distinct er.uid)) uv,
round(avg(er.score),1) avg_score
from examination_info ei join exam_record er
on ei.exam_id = er.exam_id
where ei.tag = "SQL"
and date_format(submit_time,'%Y%m%d')=date_format(release_time,'%Y%m%d')
and er.uid in
(select uid
from user_info
where level > 5)
group by er.exam_id
order by uv desc,avg_score asc复盘:
(1)同一天,不能用day函数,0901和0201的day都是1,但是不是同一天。
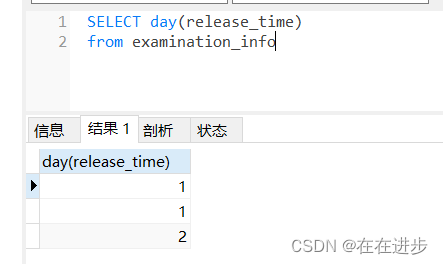

(2)计算人数时,要加distinct才对:
原数据有这种离谱的情况??
 1.3 作答试卷得分大于过80的人的用户等级分布
1.3 作答试卷得分大于过80的人的用户等级分布

我的正确代码:直接三表连接
select level,count(level) level_cnt
from user_info u
join exam_record er
on u.uid = er.uid
join examination_info ei
on ei.exam_id = er.exam_id
where ei.tag = 'SQL'
and er.score>80
group by level嵌套子查询的方法代码:
SELECT level,
COUNT(level) AS level_cnt
FROM user_info
WHERE uid IN (
SELECT DISTINCT uid
FROM exam_record
WHERE score > 80
AND exam_id IN (
SELECT exam_id
FROM examination_info
WHERE tag = 'SQL'
)
)
GROUP BY level
ORDER BY level_cnt DESC;2合并查询
2.1每个题目和每份试卷被作答的人数和次数
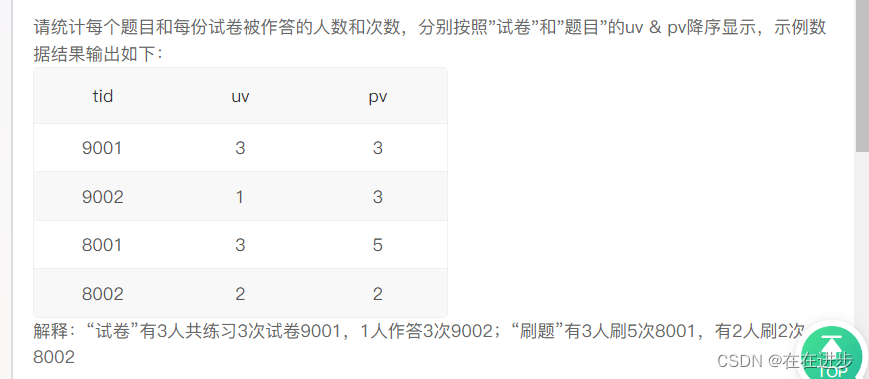
我的代码:分别查询然后用union all合并起来,但是答案错了
select exam_id tid,
count(distinct er.uid) uv,
count(distinct pr.submit_time) pv
from exam_record er join practice_record pr
using(uid)
group by exam_id
union all
select question_id tid,
count(distinct er.uid) uv,
count(distinct pr.submit_time) pv
from exam_record er join practice_record pr
using(uid)
group by question_id正确答案:
select * from
(SELECT exam_id tid,count(DISTINCT uid) uv,count(uid) pv from exam_record
group by exam_id
order by uv desc,pv desc)a
UNION ALL
SELECT * FROM
(SELECT question_id tid,count(DISTINCT uid) uv,count(uid) pv from practice_record
GROUP BY question_id
order by uv desc,pv desc)b我的代码改正:这个题最后不要合并,题目和试卷在不同的表里,分别查询在合并就好了
select exam_id tid,
count(distinct er.uid) uv,
count(er.uid) pv
from exam_record er
group by exam_id
union all
select question_id tid,
count(distinct pr.uid) uv,
count(pr.uid) pv
from practice_record pr
group by question_id还没排序:
但是使用 union 和 多个order by 不加括号 【报错】,order by 在 union 连接的子句不起作用,但是在子句的子句中起作用。
方法一:所以加两个order的话正确要这样写:
#正确代码
select * from
(
select
exam_id as tid,
count(distinct uid) as uv,
count(uid) as pv
from exam_record a
group by exam_id
order by uv desc, pv desc
) a
union
select * from
(
select
question_id as tid,
count(distinct uid) as uv,
count(uid) as pv
from practice_record b
group by question_id
order by uv desc, pv desc
) attr方法二:或者利用left(str,length) 函数: str左边开始的长度为 length 的子字符串,在本例中为‘9’和‘8’。
order by left(tid,1) desc,uv desc,pv desc
解释:试卷编号以‘9’开头、题目编号以‘8’开头,对编号进行降序就是对"试卷"和"题目"分别进行排序。
(
#每份试卷被作答的人数和次数
select
exam_id as tid,
count(distinct uid) as uv,
count(*) as pv
from exam_record
group by exam_id
)
union
(
#每个题目被作答的人数和次数
select
question_id as tid,
count(distinct uid) as uv,
count(*) as pv
from practice_record
group by question_id
)
#分别按照"试卷"和"题目"的uv & pv降序显示
order by left(tid,1) desc,uv desc,pv desc2.2分别满足两个活动的人
我的垃圾代码:不知道新的值怎么弄
(
select uid
from exam_record
group by 1001
having score>85
)t
select uid t.activity
from examination_info ei join exam_record er
on ei.exam_id = er.exam_id
大佬代码:
(select uid,'activity1' as activity
from exam_record er
where year(start_time)='2021'
group by uid
having min(score)>=85)
union ALL
(select uid,'activity2' as activity
from exam_record er left join examination_info ei on er.exam_id=ei.exam_id
where year(start_time)='2021' and ei.difficulty='hard' and score>=80
and timestampdiff(second,er.start_time,er.submit_time)<= ei.duration*30
group by uid)
order by uid;复盘:
(1)select uid,'activity1' as activity...,这样就把activity这一列就设置出来了。
(2)时间差函数:timestampdiff,如计算差多少分钟,timestampdiff(minute,时间1,时间2),是时间2-时间1,单位是minute。
这里是至少有一次用了一半时间就完成:
完成时间<=考试时长/2 (单位为分钟minute)
完成时间<=考试时长*60/2 =考试时长*30(单位为秒second)
timestampdiff(second,er.start_time,er.submit_time)<= ei.duration*30
(3)每次试卷得分都能到85分,相当于最低分min>=85
3连接查询
3.1满足条件的用户的试卷完成数和题目练习数

我的报错代码:看来不是这么简单粗暴的事情
select u.uid,
count(er.submit_time) exam_cnt,
count(pr.submit_time) question_cnt
from user_info u join exam_record er
on u.uid = er.uid
join practice_record pr
on pr.uid = u.uid
join examination_info ei
on ei.exam_id = er.exam_id
where year(er.submit_time)='2021'
group by u.uid
having ei.tag = 'SQL'
and ei.difficulty = 'hard'
and u.level = 7
and avg(er.score)>80正确代码:
# select er.uid as uid,
# count(distinct er.submit_time) as exam_cnt,
# count(distinct pr.submit_time) as question_cnt
select er.uid as uid,
count(distinct er.exam_id) as exam_cnt,
count(distinct pr.id) as question_cnt
from exam_record er
left join practice_record pr
on er.uid=pr.uid
and year(er.submit_time)=2021
and year(pr.submit_time)=2021
where er.uid in(
select er.uid
from exam_record er
left join examination_info ei
on er.exam_id = ei.exam_id
left join user_info ui
on er.uid = ui.uid
where tag='SQL'
and difficulty='hard'
and level = 7
group by er.uid
having avg(score) > 80
)
group by er.uid
order by exam_cnt,question_cnt desc复盘:
有4个表,很多个条件
(1)先通过子查询中连接,er,ui和ei筛选出高难度SQL试卷得分平均值大于80并且是7级的红名大佬(返回用户uid)

(2) 再统计这些大佬的2021年试卷总完成次数,和题目总练习次数
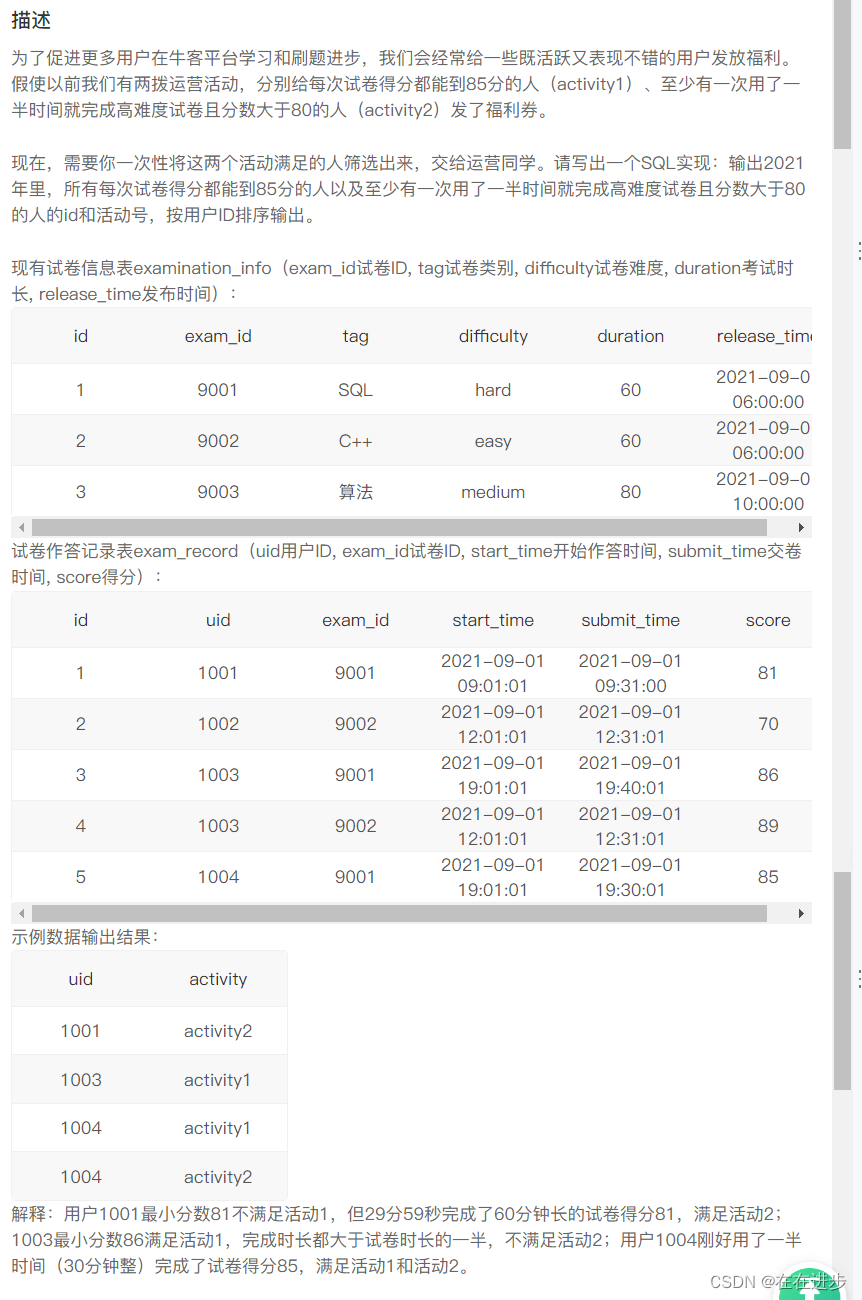
(3)注意第(2)步中连接是左连接,不应该出现试卷为null,题目不为null的情况!
from exam_record er left join practice_record pr
(4)不懂为什么不能用 er.submit_time, pr.submit_time来计算
# select er.uid as uid,
# count(distinct er.submit_time) as exam_cnt,
# count(distinct pr.submit_time) as question_cnt
select er.uid as uid,
count(distinct er.exam_id) as exam_cnt,
count(distinct pr.id) as question_cnt
3.2 每个6/7级用户活跃情况

我的错误代码:
总活跃月份数?其他都是2021年的,活跃是啥意思?
select er.uid,
# act_month_total,
count(er.start_time) act_days_2021,
count(er.submit_time) act_days_2021_exam,
count(pr.submit_time) act_days_2021_question
from exam_record er left join practice_record pr
on er.uid=pr.uid
where year(er.submit_time)=2021
and er.uid in
(select uid
from user_info
where level = 7 or level = 6)
group by er.uid正确代码
select
user_info.uid,
count(distinct act_month) as act_month_total,
count(
distinct case
when year (act_time) = '2021' then act_day
end
) as act_days_2021,
count(
distinct case
when year (act_time) = '2021'
and tag = 'exam' then act_day
end
) as act_days_2021_exam,
count(
distinct case
when year (act_time) = '2021'
and tag = 'question' then act_day
end
) as act_days_2021_question
from
(
SELECT
uid,
exam_id as ans_id,
start_time as act_time,
date_format (start_time, '%Y%m') as act_month,
date_format (start_time, '%Y%m%d') as act_day,
'exam' as tag
from
exam_record
UNION ALL
select
uid,
question_id as ans_id,
submit_time as act_time,
date_format (submit_time, '%Y%m') as act_month,
date_format (submit_time, '%Y%m%d') as act_day,
'question' as tag
from
practice_record
) total
right join user_info
on total.uid = user_info.uid
where
user_info.level in (6, 7)
group by
user_info.uid
order by
act_month_total desc,
act_days_2021 desc
复盘
(1)case when是关键
(2)2021年活跃天数 = 2021年试卷作答活跃天数 + 2021年答题活跃天数
则 exam as tag 和 practice as tag,自定义一列,为了区分是考试还是练习,便于区别计算
(3)右连接 total right join user_info on total.uid = user_info.uid
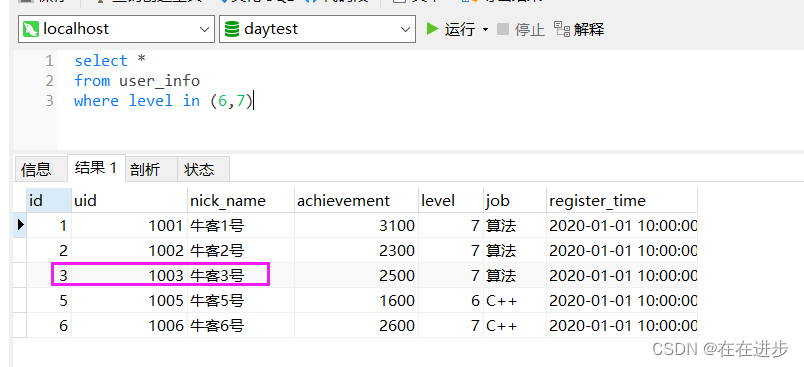
因为自组合的total表:没有1003

原本的user_info表:

但是6/7级的大佬中是有1003的









![[第五空间 2021]WebFTP、[HCTF 2018]Warmup](https://img-blog.csdnimg.cn/direct/2f7534d5deef4261aa6b0a45e5b9dbdc.png)
