看着篇文章之前先看我的前一章:MySQL基础进阶速成1
函数:
每个字段使用一个函数:select +函数(字段名)+from +表名
upper:将字符串中的字母大写
lower:将字符串中的字符小写
max:得到最大值
min:得到最小值
count:计数
avg:平均数
length:获取字符串长度
........
select upper(name) from student;
select lower(name) from student;
select min(age) from student;
select max(age) from student;
select count(age) from student;
条件函数:IF(字段,true返回值,else返回值) select+字段名+逗号隔开+if(字段条件,真返回值,假返回值)+from+表名
CASE value WHEN [value1] THEN result1 [WHEN [value2] THEN result2 ...] [ELSE result] END 如果value等于value1,则返回result1,···,否则返回result
CASE WHEN [condition1] THEN result1 [WHEN [condition2] THEN result2 ...] [ELSE result] END 如果条件condition1为真,则返回result1,···,否则返回result
select age,if(age>=18,'成年人','未成年') from student;
select age,name, case name when '张三' then '法外狂徒'
when '李四' then '受害者' else '旁观者' end '成员';group by 分组
select +字段名+from+表名+group by +靠那个字段分组的字段名
配合排序order by使用:
select +字段名+from+表名+group by +靠那个字段分组的字段名+order by+对那个字段排序
// 对年龄分组并排序
select age,name from student group by age orderby age desc;分组筛选having:
select +字段名+from+表名+group by +靠那个字段分组的字段名+having +筛选条件
//对年龄分组后筛选出大于18的组
select age from student group by age having age>=18;多表查询:
对于多张表查询需要这些表之间有外键连接
或者先将两张表连接起来在查询
交叉连接cross join:有两个表,左表有m条数据记录,x个字段,右表有n条数据记录,y个字段,则执行交叉连接后将返回m*n条数据记录,x+y个字段
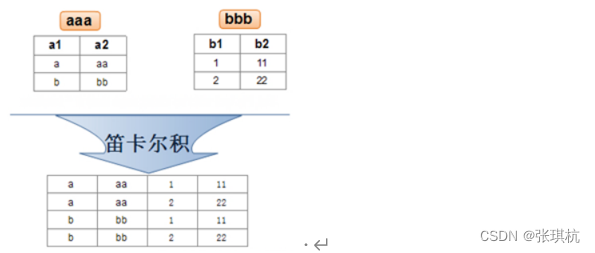
select + 字段名+from+表名+cross join +第二张表
自然连接natural join:自动匹配所有相同的字段名,同一个字段名只展现一次
select +字段名+from +表名+natural join +第二张表名
内连接:select+字段名+from+表名+inner join +另外一张表名+on(A表连接字段=B表连接字段)
# 交叉连接
select * from student1 cross join student2;
# 自然连接:
select * from student2 natural join student2;
# 内连接:
select * from student1 inner join student2 on (student1.id=student2.id);外连接查询:inner join on 于内连接差不多
select * from student1 inner join student2 on student1.id=student2.id左连接left outer join和右连接right outer join:这两个连接即使两个表没有相同的字段也可以连接
# 左连接
select * from student1 left outer join student2 on (student1.id=student2.id);
# 右连接
select * from student1 right outer join student2 on (student1.id=student2.id);自连接查询:就是自己和自己连接后在查询,将连接的两个表都写成自己就是自连接了
# 左自连接
select * from student1 left outer join student1 on (student1.id=student1.id);
# 右自连接
select * from student1 right outer join student1 on (student1.id=student1.id);子查询:也就是一个sql语句里有多个select
select + 字段名字+from+表名+where+条件,
例子的意思:查找年龄大于张三的人员信息
select * from student where age>(select age from student where name='张三');数据库对象:
事务:简单来说就是要几个数据库一起操作。举个栗子:你和好友正在斗地主,输家要向赢家发红包,输家的账户余额减少的时候,赢家的账户余额增加
用sql来表示:先创建一个账户表
create table account(
id int primary key auto increment,
name varchar(10) not null,
blance double
);在表中插入你们的账户数据
insert into account values(null,'张三',200),(null,'李四',300),(null,'王五',400);张三地主输了20分别给了李四和王五,那么三个人的账户都得一起变动
# 开启事务:
start transaction;
# 从这里开始数据库开启缓存,缓存下面任务执行后的变化
# 要执行的任务:
updata account set balance=balance-20 where id=1;
updata account set balance=balance+10 where id=2;
updata account set balance=balance+10 where id=3;
# 回滚:从开始到这里执行的任务全部取消,缓存清空
rollback;
# 提交:如果报错那么上边执行的所有任务全部不成功,否则全部成功,缓存清空
commit;
事务并发问题:
脏读:当一个事务正在访问数据并且对数据进行了修改,而这种修改还没有提交到数据库中,这时另外一个事务也访问了这个数据,然后使用了这个数据。因为这个数据是还没有提交的数据,那么另外一个事务读到的这个数据是“脏数据”,
不可重复读:指在一个事务内多次读同一数据。在这个事务还没有结束时,另一个事务也访问该数据。那么,在第一个事务中的两次读数据之间,由于第二个事务的修改导致第一个事务两次读取的数据可能不太一样。这就发生了在一个事务内两次读到的数据是不一样的情况,因此称为不可重复读。
幻读:幻读与不可重复读类似。它发生在一个事务(T1)读取了几行数据,接着另一个并发事务(T2)插入了一些数据时。在随后的查询中,第一个事务(T1)就会发现多了一些原本不存在的记录,就好像发生了幻觉一样,所以称为幻读
事务隔离:用来解决以上问题:
read uncommitted:解决不了
read committed:解决脏读:
repeatable read:解决脏读和不重复读:
serializable:全部解决
设置当前会话的事务隔离(数据库默认的是repeatable read):
set session transaction isolation level read uncommitted;
set session transaction isolation level read committed;
set session transaction isolation level repeatable read;
set session transaction isolation level serializable;
好了,到这里数据库的使用就基本完成了!!!大家点个赞在走呗!!!





![[第五空间 2021]WebFTP、[HCTF 2018]Warmup](https://img-blog.csdnimg.cn/direct/2f7534d5deef4261aa6b0a45e5b9dbdc.png)