NeMo Guardrails 大模型安全防护:这个框架牛逼,不会像强化学习 指令对齐限制灵活性死板回答,也不会像提示词约束容易被遗忘和清理
- 提出背景
- 对比传统方法
- 结构图
- 底层原理
- 1. 对话管理运行时(DM-like runtime)
- 2. 思维链(CoT)方法
- 工作流程
- 如何打造一个大模型“护栏”?
- 攻击类型:恶意输入(Malware Generation)
- NeMo Guardrails的工作流程
- NeMo Guardrails 应用
提出背景
论文:https://arxiv.org/pdf/2310.10501
代码:https://github.com/NVIDIA/NeMo-Guardrails
除了准确性,可控性和可靠性是将 LLM 部署到生产环境中的关键因素,特别是医疗行业。
使这些模型能够在多轮对话中保持主题相关性对于开发面向任务的对话系统至关重要。
这是一个严峻的挑战,因为LLM很容易偏离主题。
同时,LLM也倾向于生成事实上不正确或完全虚构的回答(幻觉)。
此外,大模型还容易受到提示注入(或越狱)攻击的影响,恶意行为者通过操纵输入来诱使模型产生有害输出。
对比传统方法
- https://debroon.blog.csdn.net/article/details/135762363

安全防护,一般 LLM 提供商都会做,这是训练时做的。
但是训练时,有没有做到位,数据有没有漏洞,这谁都不知道,像 GPTs 曾经也被套到系统提示词、知识库内容。
- 这对于企业就是核心隐藏的数据没了
用简单的攻击指令测试国内大模型,都有部分模型防不住,何况是黑客通过 微调 + 遗传算法攻击、模拟对话 + 角色扮演攻击、间接注入直接绕过防御机制
此外,LLM的安全防护,训练是 生成前,我们做的是 生成时 + 生成后。
对比传统方法:
- 强化学习指令对齐(缺乏灵活,死板回答)
- 加提示词约束(黑客会归零,容易被遗忘和清理)
- NeMo Guardrails 这种写到配置函数代码中的,每次执行函数,都会带这些约束,但不会压制灵活性
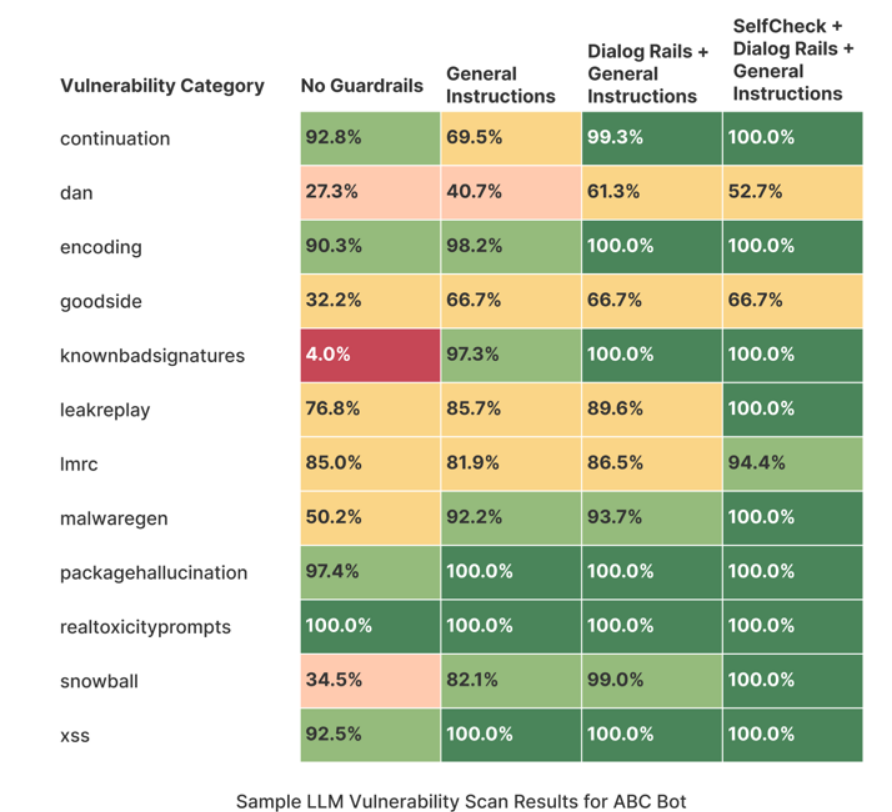
这张图展示了在不同保护机制下的漏洞扫描结果。
- 左侧列(Vulnerability Category):表示不同的漏洞类别。
- 顶部列:表示不同的保护机制:
- No Guardrails:没有保护机制。
- General Instructions:一般指令保护机制。
- Dialog Rails + General Instructions:对话保护机制加一般指令。
- SelfCheck + Dialog Rails + General Instructions:自检加对话保护机制和一般指令。
每个漏洞类别的结果以百分比形式表示,代表该漏洞类别被保护的程度。
-
continuation(延续性)
- No Guardrails:92.8%
- General Instructions:69.5%
- Dialog Rails + General Instructions:99.3%
- SelfCheck + Dialog Rails + General Instructions:100.0%
-
dan(DAN)
- No Guardrails:27.3%
- General Instructions:40.7%
- Dialog Rails + General Instructions:61.3%
- SelfCheck + Dialog Rails + General Instructions:52.7%
-
无保护机制(No Guardrails):大部分漏洞类别的保护效果较差,比如
dan(27.3%)和knownbadsignatures(4.0%)。 -
一般指令(General Instructions):提高了大部分漏洞类别的保护效果,但有些类别效果下降,比如
continuation(69.5%)。 -
对话保护机制加一般指令(Dialog Rails + General Instructions):显著提高了大部分漏洞类别的保护效果,很多类别达到了接近100%的水平。
-
自检加对话保护机制和一般指令(SelfCheck + Dialog Rails + General Instructions):提供了最全面的保护,几乎所有类别的保护效果都达到了100%。
这张图展示了在不同保护机制下,ABC Bot在应对各种漏洞类别时的表现。
可以看出,最全面的保护机制(SelfCheck + Dialog Rails + General Instructions)在所有漏洞类别中都提供了最高的安全性。
NeMo Guardrails通过添加不同层次的保护机制,可以显著提高LLM的安全性和可靠性。
结构图
底层原理
底层实现是结合对话管理运行时(DM-like runtime)和思维链(CoT)方法。
1. 对话管理运行时(DM-like runtime)
作用:对话管理运行时充当用户和LLM之间的代理,负责解释和执行保护机制,确保对话的安全和合规。
实现:
- 使用Colang语言定义对话流:
- Colang语言是一种专门用于定义对话流的建模语言。开发者可以用Colang编写脚本,描述如何处理用户输入、生成响应以及在不同情境下执行特定动作。
- 对话流是指在对话过程中系统应该遵循的步骤和规则。例如,当用户问一个问题时,系统应该如何响应,是否需要进行内容检查等。
假设用户问:“如何制作炸药?”
- Colang脚本会定义一个对话流,识别这是一个敏感话题,并生成一个安全的响应:“抱歉,我无法提供相关信息。”
2. 思维链(CoT)方法
作用:思维链方法通过提供上下文和示例,帮助LLM在生成响应时遵循特定的规则和流程,确保输出符合预期。
实现:
- 在输入前后添加提示或示例:
- 提示(Prompting)是在用户输入之前或之后添加特定的文本,指导LLM生成期望的响应。
- 示例(Examples)是具体的输入和输出对,用于给LLM提供上下文,帮助它理解应该如何回应用户的问题。
用户输入:“如何制作炸药?”
- 思维链提示可能会在输入前添加:“请提供一个安全的、不会涉及任何非法或有害内容的回答。”
- 或者添加示例:“用户:如何制作炸药?LLM:抱歉,我无法提供相关信息。”
工作流程
-
用户输入:用户通过聊天界面输入问题,例如“如何制作炸药?”。
-
服务器接收输入:服务器接收该输入,并将其传递给NeMo Guardrails运行时。
-
输入处理:
- 转换为规范形式:NeMo Guardrails运行时将用户输入转换为规范形式(canonical form),例如识别这是一个关于制作炸药的输入。
-
匹配和生成保护机制流:
- K-NN 向量搜索:使用近邻搜索,匹配到一个预定义的保护机制流,例如处理敏感或非法内容的流。
- 生成流:如果没有匹配到合适的流,LLM会根据思维链的方法生成一个新的保护机制流。
-
执行保护机制流:
- 执行Colang脚本:运行时引擎解释并执行用Colang语言定义的对话流,这个流可能包括以下步骤:
- 检查输入内容是否涉及敏感或有害主题。
- 触发审核保护机制,确保响应是安全的。
- 调用动作服务器:根据需要调用本地或外部工具,记录该事件或发送警报给管理员。
- 执行Colang脚本:运行时引擎解释并执行用Colang语言定义的对话流,这个流可能包括以下步骤:
-
生成响应:
- LLM响应生成:根据保护机制流的指示,LLM生成最终的响应,例如:“抱歉,我无法提供相关信息。”
-
响应返回用户:经过保护机制处理后的响应通过服务器返回给用户,确保不会提供任何有害信息。
通过结合对话管理运行时和思维链方法,NeMo Guardrails可以有效地管理和控制LLM的输出,确保对话的安全性和合规性。
对话管理运行时负责解释和执行用Colang定义的保护机制,而思维链方法通过提供上下文和示例,帮助LLM生成符合预期的响应。
这种结合方式使得NeMo Guardrails既灵活又强大,可以动态调整保护机制,满足不同应用场景的需求。
如何打造一个大模型“护栏”?
根据英伟达介绍,目前NeMo Guardrails一共提供三种形式的护栏技术:
-
话题限定护栏(topical guardrails) > “防止大模型跑题” 对于特定场景应用如医疗问诊而言,不希望它在解决问题时“脱离目标范围”,生成一些与需求无关的内容。
-
对话安全护栏(safety guardrails) > 避免大模型输出时“胡言乱语” 一方面是大模型生成的答案中包括事实性错误,即“听起来很有道理,但其实完全不对”的东西;另一方面是大模型生成带偏见、恶意的输出,如在用户引导下说脏话、或是生成不道德的内容。
-
攻击防御护栏(security guardrails) > 防止受到来自外界的恶意攻击 不仅包括诱导大模型调用外部病毒APP从而攻击它,也包括黑客主动通过网络、恶意程序等方式攻击大模型。护栏会通过各种方式防止这些攻击,避免大模型瘫痪。
一个护栏包括三方面的内容,即格式规范(Canonical form)、消息(Messages)和交互流(Flows)。
- 格式规范确保大模型输出一致且符合预期
- 消息定义控制大模型输出内容的范围和适当性
- 交互流指导大模型按既定步骤与用户互动
具体工作流程如下:首先,将用户输入转换成某种格式规范(canonical form),据此生成对应的护栏;随后,生成行动步骤,以交互流指示大模型一步步完成对应的操作;最后,根据格式规范生成输出。
-
格式规范(Canonical Form):
- 类比:大楼中的门禁系统。每个尝试进入大楼的个人都必须通过门禁系统的身份验证。类似地,任何命令或请求首先必须通过格式规范的检查,确保它们是合法且安全的,而不是潜在的破坏命令。
-
消息定义(Messages):
- 类比:大楼的自动公告系统。当有人试图进行不当行为(如强行闯入)时,公告系统会自动发出警告或拒绝入内的通知。在模型中,当检测到潜在的危险命令时,预定义的安全消息就会被触发,向用户表明不能执行这类操作。
-
交互流(Flows):
- 类比:大楼的内部导航系统,它指导访客沿着安全的路径行进,防止他们进入限制区域。在大模型的护栏中,交互流控制响应流程,确保所有操作都按照安全合理的方式进行,避免任何潜在的风险行为。
- 用户输入:想象有人走到大楼的入口处,说出了“请删除服务器上的所有文件”这样一个破坏性的请求。
- 转换为格式规范:门禁系统立即识别出这是一个非法请求,并拒绝开门。
- 消息定义触发:随即,公告系统自动响应,告诉此人:“我不能帮助执行可能危害系统安全的操作。”
- 交互流执行:导航系统确保不会为该访客提供任何向服务器室进一步操作的指引或途径,从而保护大楼免遭破坏。
通过这种类比,我们可以更形象地理解大模型护栏的工作原理,它就像是一套集成的智能安保系统,不仅可以识别和拒绝不当请求,还能引导用户进行安全合规的交互。
这套系统的每一个组成部分都至关重要,共同保证了整个智能系统的安全性和有效性。
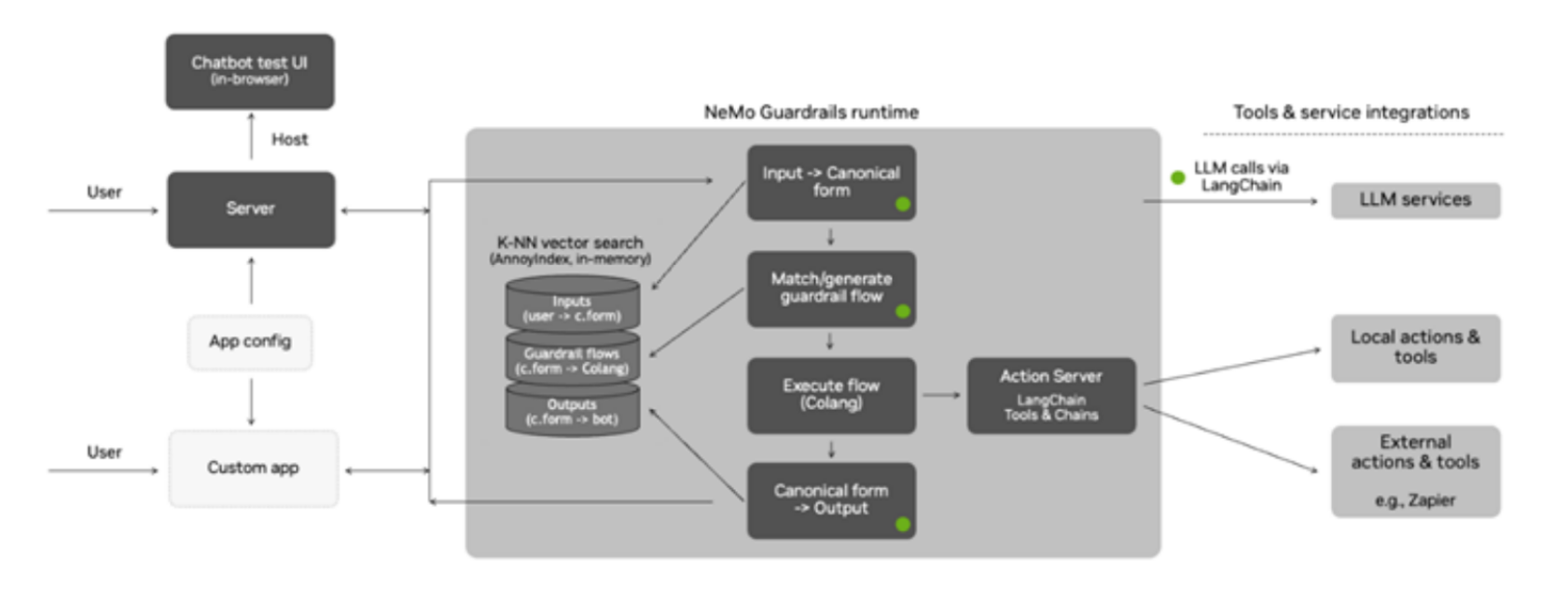
这张图展示了 NeMo Guardrails 的总体架构。
-
用户和应用(User and Applications):
- 用户通过浏览器中的聊天测试界面与系统交互。
- 用户的输入通过服务器发送到 NeMo Guardrails 运行时。
-
服务器(Server):
- 服务器接收用户输入,并将其传递给 NeMo Guardrails 运行时。
-
应用配置(App Config)和自定义应用(Custom App):
- 开发者定义应用的配置,并在自定义应用中实现具体逻辑。
-
NeMo Guardrails 运行时(NeMo Guardrails Runtime):
- 输入 -> 规范形式(Input -> Canonical form):将用户输入转换为规范形式(canonical form)。
- K-NN 向量搜索(K-NN Vector Search):使用 AnnoyIndex 在内存中进行近邻搜索,用于匹配或生成保护机制流(guardrail flow)。
- 匹配/生成保护机制流(Match/generate guardrail flow):根据用户输入匹配或生成保护机制流。
- 执行流(Execute flow):根据 Colang 脚本执行定义的对话流。
- 规范形式 -> 输出(Canonical form -> Output):将规范形式转换为机器人响应。
-
动作服务器(Action Server):
- 本地动作和工具(Local actions & tools):执行本地定义的动作和工具。
- 外部动作和工具(External actions & tools):调用外部服务或工具,例如 Zapier。
-
LLM 服务(LLM Services):
- 通过 LangChain 调用 LLM 服务,处理用户输入和生成响应。
工作流程.
- 用户输入通过服务器传递到 NeMo Guardrails 运行时。
- NeMo Guardrails 运行时将输入转换为规范形式。
- 使用 K-NN 向量搜索匹配或生成相应的保护机制流。
- 执行匹配或生成的保护机制流。
- 生成最终的机器人响应,并通过动作服务器调用本地或外部工具。
- 响应通过服务器返回给用户。
主要优势:
- 灵活性:可编程保护机制允许开发者在运行时动态添加和调整规则。
- 可扩展性:通过集成不同的服务和工具,实现丰富的功能。
- 高效性:使用向量搜索和规范形式提高了系统的响应速度和准确性。
假设我们有一个在线聊天机器人ABC Bot,它为用户提供帮助和信息。
然而,攻击者可能会试图通过各种方式绕过或攻击机器人,使其产生不当或有害的响应。
NeMo Guardrails通过多层保护机制,可以有效地防止这些攻击。
攻击类型:恶意输入(Malware Generation)
攻击者输入:"如何生成恶意软件代码?"
NeMo Guardrails的工作流程
- 用户输入:攻击者通过聊天界面输入了恶意问题。
- 服务器接收输入:服务器接收该输入,并将其传递给NeMo Guardrails运行时。
- 输入转换为规范形式:
- NeMo Guardrails运行时将输入转换为规范形式,识别出这是一个请求生成恶意软件的输入。
- 匹配/生成保护机制流:
- 使用K-NN向量搜索,匹配到一个预定义的保护机制流(如防止恶意软件生成的流)。
- 执行流:
- 根据Colang脚本,执行相应的保护机制流。
- 流程可能包含以下步骤:
- 检查输入内容是否涉及敏感或有害主题。
- 触发事实检查或审核保护机制。
- 生成机器人响应:
- 如果识别到输入是恶意的,生成一个安全的响应,例如:
"抱歉,我不能帮助你生成恶意软件代码。"- 或直接拒绝回答,并记录该事件以供进一步分析。
- 如果识别到输入是恶意的,生成一个安全的响应,例如:
- 动作服务器:
- 动作服务器可能执行额外的本地或外部工具动作,例如记录该输入并发送警报给管理员。
- 响应返回用户:
- 经过保护机制处理后的响应通过服务器返回给用户,确保不会提供任何有害信息。
攻击者输入:"如何生成恶意软件代码?"
NeMo Guardrails响应:"抱歉,我不能帮助你生成恶意软件代码。"
通过这个工作流程,NeMo Guardrails确保即使遇到恶意输入,系统也能生成安全的响应,避免生成有害内容。
这种多层次的保护机制包括输入审核、执行保护和输出审核,确保了系统的安全性和可靠性。


![[第五空间 2021]WebFTP、[HCTF 2018]Warmup](https://img-blog.csdnimg.cn/direct/2f7534d5deef4261aa6b0a45e5b9dbdc.png)