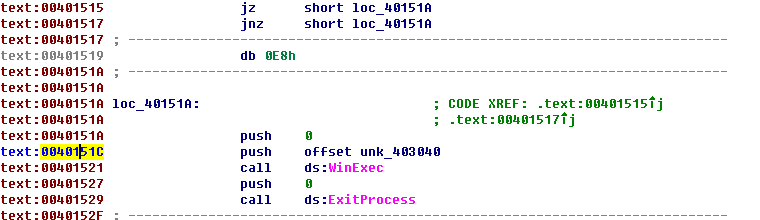
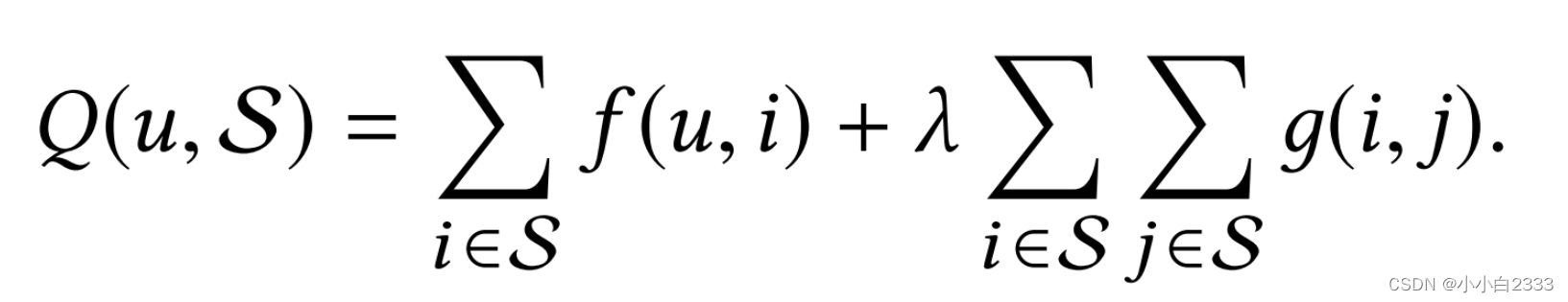对于深度学习或机器学习模型而言,我们不仅要求它对训练数据集有很好的拟合(训练误差),同时也希望它可以对未知数据集(测试集)有很好的拟合结果(泛化能力),所产生的测试误差被称为泛化误差。度量泛化能力的好坏,最直观的表现就是模型的过拟合(overfitting)和欠拟合(underfitting)。过拟合和欠拟合是用于描述模型在训练过程中的两种状态。一般来说,训练过程会是如下所示的一个曲线图。
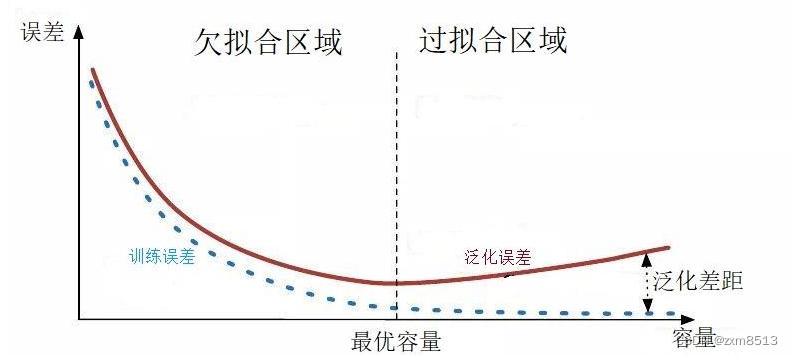
对于深度学习或机器学习模型而言,我们不仅要求它对训练数据集有很好的拟合(训练误差),同时也希望它可以对未知数据集(测试集)有很好的拟合结果(泛化能力),所产生的测试误差被称为泛化误差。度量泛化能力的好坏,最直观的表现就是模型的过拟合(overfitting)和欠拟合(underfitting)。过拟合和欠拟合是用于描述模型在训练过程中的两种状态。一般来说,训练过程会是如下所示的一个曲线图。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如若转载,请注明出处:http://www.coloradmin.cn/o/179648.html
如若内容造成侵权/违法违规/事实不符,请联系多彩编程网进行投诉反馈,一经查实,立即删除!