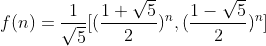frontiers in Neuroscience 2019
摘要
本文提出一种新的方法来构建深度SNN,并在复杂视觉识别问题上证明其有效性(如CIFAR10和ImageNet);该方法应用于VGG和残差网络结构,并获得最优精度;最后给出稀疏事件驱动计算的分析,证明在脉冲域操作时减少硬件开销。
背景
SNN比ANN有更好的生物学可解释性,并具有事件驱动硬件的前景,它只在接收到二进制脉冲信号时处理输入信息,使其功耗显著降低。但大多数SNN的研究局限于简单而浅层的网路结构,SNN性能有限的主要原因是其时间信息处理能力,SNN与ANN有很大不同,需要重新思考SNN的机制。
主要贡献
提出一种新的ANN-SNN转换方法,由于目前最先进技术;首次探索通过残差网络构建深度SNN;证明了随着网络层数增加,SNN的稀疏性显著增加,进一步促进对ANN-SNN的探索。
主要内容与做法
输入与输出的表示
本文使用rate-encoded,时间窗足够大时,输入的平均脉冲数量与源ANN输入大小成正比;使用泊松事件生成网络的脉冲输入序列,SNN操作的每个时间步都与一个生成的随机数关联,将其与对应输入进行比较:如果随机数小于对应像素值,则触发脉冲事件。这种网络的SNN操作是“伪同时的”,即某一层立即对来自前一层的传入峰值进行操作,而不需要等待多个时间步来积累来自前一层神经元的信息。给定一个泊松生成的脉冲序列送入网络,脉冲将在输出处产生;推理是基于在给定时间窗口内网络输出层神经元的累积脉冲数量。
ANN与SNN神经元
使用ReLU作为ANN激活函数是因为其功能与无泄漏无不应期的IF神经元功能相同。适当选择神经元阈值与突触权重的比值对于确保分类精度损失最小化至关重要:阈值过高导致延迟增加,阈值过低导致精度变差。
结构限制
- 对bias的处理:
ANN-SNN过程中通常不含bias,因此训练过程中不能使用正则化项(会加入bias),本文使用dropout进行正则化。 - 池化操作:
对SNN使用最大池化会导致下一层信息大量丢失,所以使用平均池化。
提出算法:Spike-Norm
在足够大的时间窗为训练集生成泊松脉冲序列并输入网络,泊松脉冲序列可以记录加权脉冲输入的最大总和;为了最小化神经元的时间延迟,同时确保神经元放电阈值不会太低,根据第一层接收到的最大脉冲输入对第一层进行权重归一化,在第一层的阈值设定之后,可以得到具有代表性的输出脉冲序列,传入下一层;循环这个过程对网络的所有层进行归一化。
与之前工作不同的是,本文提出的方法考虑了实际SNN的操作。

扩展残差结构
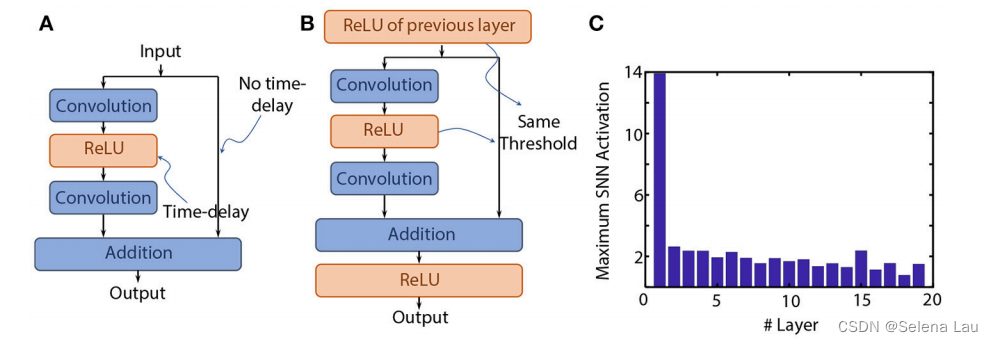
- 本文提出的spike-norm应用在残差结构上会有精度退化,假设退化是因为连接点上没有ReLU:每个ReLU转换为IF神经元时,会产生一定的时间延迟,但因为Shortcuts的存在,初始脉冲信息可以被迅速传递到后面的层,因此同一层的两条平行路径不平衡的时间延迟会导致网络传播脉冲信息失真。
如图B所示,在每个结点都设置ReLU,为并行路径提供时间平衡。 - 直接应用本文提出的阈值平衡方法无法达到与基准ANN相当的精度,非同一性路径中神经元层的脉冲阈值依赖于前一个结点上神经元层的活动,为解决这个问题本文启发式地将同一性ReLU与非同一性ReLU层的阈值都设为1。但仍无法使精度与基准ANN相当。
- 由图C可知,初始层的阈值平衡因子比整体要高很多,这可能时精度下降的主要原因。受VGG结构的启发,本文将第一个7 × 7卷积层替换为一系列3 × 3卷积,其中前两层不设置shortcuts;使用这样的初始非残差预处理层使初始层中可以应用本文提出的阈值平衡方法,同时对后面的层使用统一阈值平衡因子。
未来工作
- 探索具有bias的SNN
- 探索除了ReLU-IF之外的其他变体
- 进一步优化有残差结构的ANN-SNN的性能损失