接口超时的原因:
一、网络抖动
有可能是你的网络出现抖动、网页请求API接口、接口返回数据给网页丢包了。
二、被带宽占满
用户量暴增,服务器网络带宽被占满。
服务器带宽:一定时间内传输数据的大小,如:1s传输10M的数据
用户请求量增多,1s传输了100M,导致1s内,有90M的数据延迟传输,导致接口超时。
如何增加服务器带宽?
以NIGNX为例:
修改nginx配置文件中图片访问的配置部分
对于正常小图的访问不限制,把正常图的大小限定为 100K 以内,超出时就进行限速,速度限定为最大 100k/s
location ~ .*\.(gif|jpg|jpeg|png|bmp)$
{
expires 30d;
limit_rate_after 100k;
limit_rate 100k;
}
三、线程池满了
有时候为了性能考虑,可能会使用线程池异步查询数据,最后把查询结果进行汇总,然后返回。
public UserInfo getUserInfo(Long id) throws InterruptedException, ExecutionException {
final UserInfo userInfo = new UserInfo();
CompletableFuture userFuture = CompletableFuture.supplyAsync(() -> {
getRemoteUserAndFill(id, userInfo);
return Boolean.TRUE;
}, executor);
CompletableFuture bonusFuture = CompletableFuture.supplyAsync(() -> {
getRemoteBonusAndFill(id, userInfo);
return Boolean.TRUE;
}, executor);
CompletableFuture growthFuture = CompletableFuture.supplyAsync(() -> {
getRemoteGrowthAndFill(id, userInfo);
return Boolean.TRUE;
}, executor);
CompletableFuture.allOf(userFuture, bonusFuture, growthFuture).join();
userFuture.get();
bonusFuture.get();
growthFuture.get();
return userInfo;
}executor,表示自定义的线程池,为了防止高并发场景下,出现线程过多的问题。
但如果用户请求太多,线程池中已有的线程处理不过来,线程池会把多余的请求,放到队列中排队,等待空闲线程的去处理。
如果队列中排队的任务非常多,某次API请求一直在等待,没办法得到及时处理,就会出现接口超时问题。
如何解决?
1、是否核心线程数设置太小了?
corePoolSize=>线程池里的核心线程数量maximumPoolSize=> 线程池里允许有的最大线程数量
2、有多种业务场景共用了同一个线程池?
四、数据库死锁
你提供的API接口中通过某个id更新某条数据,此时,正好线上在手动执行一个批量更新数据的sql语句。
该sql语句在一个事务当中,并且刚好也在更新那条数据,可能会出现死锁的情况
五、传入参数太多
如果接口调用方,一次性传入几千个,甚至几万个id,批量查询分类,也可能会出现接口超时问题。
查询条件太多,有可能走全表扫描更快。所以这种情况下sql语句可能会丢失索引,让执行时间变慢,出现接口超时问题
因此我们在设计批量接口的时候,建议要限制传入的集合的大小,比如:500。
六、API超时设置
monitor:
rest-template:
readTimeout: 10000
connectTimeout: 10000
connectionRequestTimeout: 1000
http-request:
socketTimeout: 10000
connectTimeout: 10000
connectionRequestTimeout: 10000
如何做不同业务场景超时时间不同?
七、一次性返回数据太多
我们有个job,每天定时调用第三方API查询接口,获取昨天更新的数据,然后更新到我们自己的数据库表中。
如何解决?
第三方这种根据日期查询增量数据的接口,建议做成分页查询的,不然后面没准哪一天,遇到批量更新的操作,就可能出现接口超时的问题。
八、死循环
普通死循环:

无限死循环:
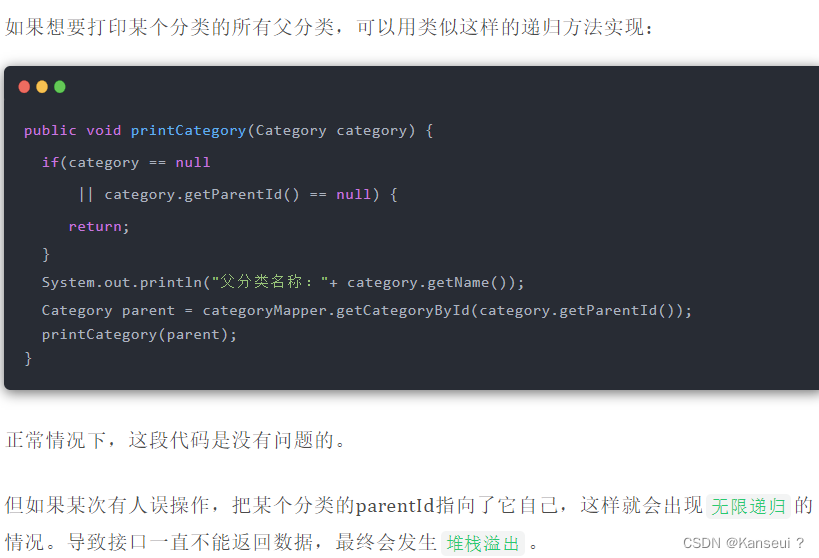 九、数据库没有走索引
九、数据库没有走索引
如何解决?
必要时可以使用force index来强制查询sql走某个索引。
十、服务OOM
API所在的服务OOM了,挂了一段时间,导致所有接口都请求超时
如何解决?
在Prometheus的服务内存监控中,查到了OOM问题。然后K8S集群有监控,它自动会将挂掉的服务节点kill掉,并且在容器中重新部署了一个新的服务节点,先不要对用户造成影响。
然后排查是什么OOM了