1. 简介
1.1. 近期工作
- 研究工作鼓励运行大量小任务
小任务能提高并行性,减少端到端耗时 - 工程经验反对运行过多的任务
过多的task在shuffle阶段会引入大量IO开销,根本原因在于map和reduce阶段之间的shuffle IO请求数量随着任务数量的增长呈现指数级的增长,每个request的平均大小在线性下降;又因为shuffle期间的数据需要保存在HDD磁盘上(为了容错),因此在shuffle期间存在大量小的随机IO导致耗时变长。执行task数量多的job时会拆分IO请求,进一步加剧问题。
1.2. Riffle解决方案
显著提高IO效率,扩展到pb级别数据处理,Riffle通过大量随机小IO转换为更少的连续的大IO提高shuffle性能和资源效率;核心是由一个集中的调度程序 scheduler 和一个shuffle merge service组成,前者跟踪中间shuffle文件并动态协调合并操作,后者运行在每个物理集群节点上,以很少的资源开销将小文件合并为大文件。
1.3. 挑战和解决方案
- Riffle节省计算和存储资源
- 易于配置,适用不同的存储系统和硬件设备
- 容错性强:Riffle跟踪合并和未合并格式的中间文件,一旦出现故障,返回未合并格式的文件(放弃本次合并操作)
- 开销小
2. 背景和动机
2.1. shuffle简介
宽依赖:子task会接受来自多个父task的输出
窄依赖:只依赖于一个父task
shuffle是资源密集型操作,从map任务传输到reduce任务的每个数据块都是需要经过数据序列化、磁盘和网络IO以及数据反序列化。
2.2. 中间数据的高效存储
- 磁盘溢写IO
- shuffle IO
2.3. 当前实践与现有解决方案(现有服务的缺陷)
-
减少每个stage的task数量
-
为reducer聚合服务器
3. 系统概述
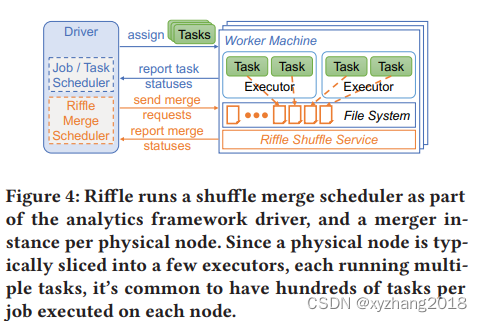
3.1 Shuffle Merge scheduler
spark框架中的task由driver分配,driver将一个job转换成DAG有向无环图,被shuffle分割成几个stage;来自同一个stage的task可以并行执行,而下一个stage的task需要在shuffle完成后才能执行,中间的shuffle文件需要持久化在本地或HDFS(GFS)等
Riffle跟踪任务执行进度,根据配置策略调度合并操作。Riffle手机所有task生成的中间文件状态和块大小,并在shuffle文件满足合并标准时发出和并请求。
3.2 Shuffle service with merging
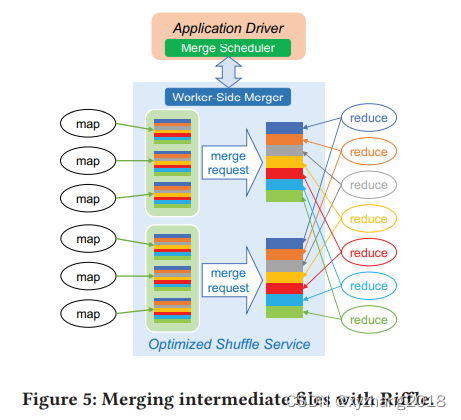
大数据计算框架会提供外部shuffle服务管理shuffle输出文件(例如Spark中的ESS)
上图展示了Riffle对于文件合并的优化:每个mapper输出数据以便将数据分配到所需的reducer中,原有请求下每个reducer都需要到每个mapper处请求数据,通过Riffle合并后,reducer秩序从合并后的中间文件中读取数据即可。显著提高shuffle IO的效率
4. 系统设计
4.1. 合并shuffle中间文件
当map操作和merge完成后,driver会启动reducer任务,将全部map输出的元数据(位置,执行器id,task id)广播给executors节点。通过Riffle,driver可以发送已合并文件的metadata,而不是原始的map输出文件,因此reducer可以更高效的从合并后的文件中提取相应的部分。
4.1.1. 合并调度策略
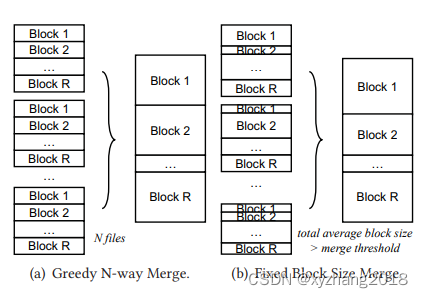
- Merge with fixed number of files. 见下图a
- Merge with fixed block size. 见下图b
- 配置合并策略
4.1.2. 高效Worker-Side合并(重点 参照原文)

4.2. Best-Effort合并(最小化合并开销)
导致部分任务超时的原因:
- 最后几个mapper生成的shuffle需要等待mapper任务完成后在开始合并
- worker节点crush重启
best-effort merge实现思想:
driver会将mapper阶段标记为已完成,在worker完成大多数merge操作时就开始启动reducer,剩余未完成的merge操作都由driver取消,直接进入reduce阶段。
Riffle的driver对于合并成功的文件直接发送已合并文件的metadata,对于合并失败的文件发送源文件的metadata。
4.3. 异常处理
为保证计算结果的正确性并加快发生异常时的恢复速度,Riffle将原始的未合并文件、合并后的文件都保存在磁盘上。若出现上述异常,Riffle会返回到原始未合并的文件,从而避免map阶段的延迟。
Spark和Hadoop在处理shuffle数据丢失和损坏时,只会重新计算丢失部分的mapper任务。Riffle遵循这种设计,若未合并的文件丢失,只计算这部分对应的mapper任务,若合并后的文件丢失则进行降级。
*sailfish对于数据丢失会导致大量任务的重计算,相对Riffle造成更高的耗时
4.4. 分布式系统中的负载均衡
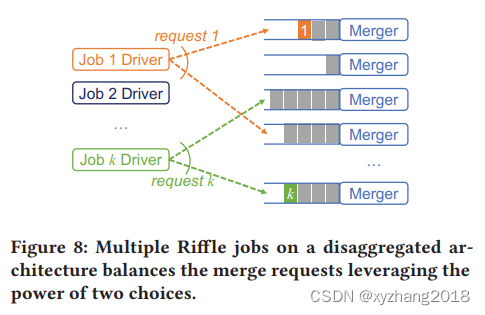
“power of two choices”可以有效平衡动态合并负载,driver随机挑选两个merger,选择其中pending数量更少的一个。既可以减少探测开销,又可以平衡负载。
4.5 讨论
4.5.1. IO操作节省分析
原生的shuffleIO request数量:MR
对于N路合并,生成M/N个合并文件,最终的shuffle request数量为M/NR;
对于合并操作可能会引起额外的IO,完整的合并需要对全部数据(T)增加一次读写操作,由于Riffle合并只产生连续的磁盘IO,因此总IO请求数为2* T/s,其中s为缓冲区大小。
总IO请求数为 M/N * R + 2 * T/s
举个栗子,总数据量为100G其中使用了1000个mappper,1000个reducer,则shuffle期间的IO请求为10001000,若使用Riffle合并,配置10MB的缓冲区,使用40路合并,IO请求的总数为: 1000/401000 + 2*100GB/10MB = 45000,请求量减少了22倍。
上述计算没有考虑磁盘溢出的影响,Riffle的高效merge缓解了shuffle IO的二次增长,进一步降低了由于磁盘的溢出导致对磁盘IOPS的要求;
*与sailfish对比IO相同,但容错性更强,更适合大规模集群的部署。
4.5.2. 部署在不同集群上
每台物理机上有多个executor时,Riffle最适合;
Riffle更适合存算分离的行业趋势;