一、目的
如今2023了,大多数javaweb架构都是springboot微服务,一个前端功能请求后台可能是多个不同的服务共同协做完成的。例如用户下单功能,js转发到后台网关gateway服务,然后到鉴权spring-sercurity服务,然后到业务订单服务,然后到支付服务,后续还有发货、客户标签等等服务。
其中每个服务会启动多个实例做负载均衡,这样一来我们想看这个功能的完成流程日志,需要找到对应的服务器ip,日志文件在哪,其中又要确定具体负载转发到哪些台服务器上了。 如果是生产问题想要快速定位原因,需要一套解决方案!
二、涉及技术栈
- 基本架构:
spring cloud(springBoot+服务发现+网关+负载熔断等netflex)。本人目前使用的是springboot+eureka+gateway+springSercurity+openfeign+springConfig 配合业务功能涉及中间件redis、quartz、kafka、mysql、elasticsearch - 日志采集处理展现:ELK
- elasticsearch:海量json数据存储即席查询
- logstash: 源头采集数据(tcp、file、redis、mq)、格式化处理、推送es存储
- kibana: 官方es可视化交互curd工具
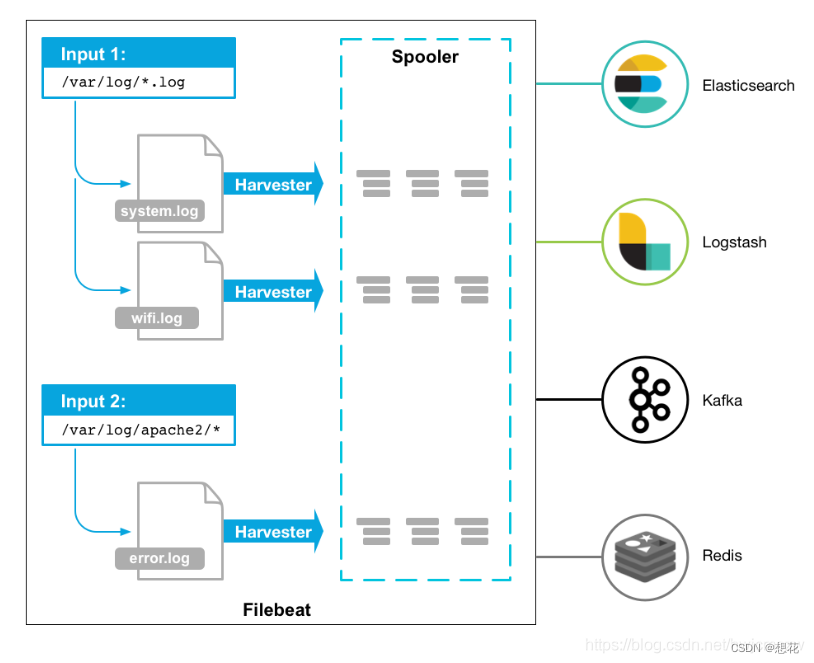
- 高效轻量数据采集工具: filebeat。 监控日志文件实时获取,可以推送到kafka
- kafka:接收filebeat数据,供logstash消费
- 多服务链路追踪:sleuth-zipkin。无代码侵入。简单来说就是打印的日志内容新增了tranceId、spanId。例如

三、流程
-
js发起ajax请求后台网关服务
-
网关服务集成了maven
<artifactId>spring-cloud-starter-zipkin</artifactId>依赖,会自动给当前的请求header中添加tranceId字段和spanId字段。这两个字段值随机生成。其中tranceId等于spanId在header中没有这两个字段的时候:例如tranceId=123a,spanId=123a 并添加到header中。并且打印日志的时候会把这个信息打印出来 -
之后网关根据请求路径转发到业务服务A,A服务的zipkin发现header中有tranceId信息,就只生成spanId,例如tranceId=123a,spanId=231b 并添加到header中。并且打印日志的时候会把这个信息打印出来。
-
A服务又rpc调用了B服务。B服务的zipkin发现header中有tranceId信息,就只生成spanId,例如tranceId=123a,spanId=342h 并添加到header中。并且打印日志的时候会把这个信息打印出来。
-
调用完结返回前端响应。
-
到此服务器的日志文件就会新增上述的日志。然后
filebeat工具监听到了各个服务的新日志,读取并推送到kafka -
消息队列的topic下生产新数据,
logstash工具提前配置并启动消费kafka, 处理并保存数据到elasticsearch。这里好奇为什么不直接通过filebeat直接推送es,或者springboot的log框架直接通过appender直接推送es呢?- 使用filebeat解耦,不影响springboot性能。并且轻量
- 使用kafka是应对大量并发数据,减少logstash压力
- 最终经过logstash推送es是为了加工格式化源数据,再保存到es,这样更加方便es查询日志
-
持久化es之后,通过
kibana查询日志,查询条件是tranceId=123a即可查询出完整的日志。
四、整合配置filebeat、kafka、logstash例子
我分了两部分,有些是部署在服务器上的jar,我就通过filebeat采集;有些是部署到本地笔记本上的服务,直接在logback.xml配置一个appender输出到kafka,不经过filebeat。
logstash.conf
input {
kafka{
bootstrap_servers => "node101:30701"
client_id => "logstash_kafka_consumer_id"
group_id => "logstash_kafka_consumer_group"
auto_offset_reset => "latest"
consumer_threads => 1
decorate_events => true
topics => ["logstash"]
}
}
filter{
}
output{
elasticsearch{
hosts => ["node101:30600"]
index => "logstash-%{+YYYY.MM.dd}"
}
}
filebeat.yml
filebeat.modules:
filebeat.prospectors:
- type: log
enabled: true
paths:
- /spring-boot-logs/*/user.*.log
#include_lines: ["^ERR", "^WARN"]
# 适用于日志中每一条日志占据多行的情况,比如各种语言的报错信息调用栈
multiline:
pattern: '^[[:space:]]'
negate: false
match: after
processors:
- drop_fields:
fields: ["metadata", "prospector", "offset", "beat", "source","type"]
output.kafka:
hosts: ["node101:30701"]
topic: logstash
k8s的yaml
apiVersion: apps/v1
kind: Deployment
metadata:
labels:
app: elk
name: ssx-elk-dm
namespace: ssx
spec:
replicas: 1
selector: #标签选择器,与上面的标签共同作用
matchLabels: #选择包含标签app:mysql的资源
app: elk
template: #这是选择或创建的Pod的模板
metadata: #Pod的元数据
labels: #Pod的标签,上面的selector即选择包含标签app:mysql的Pod
app: elk
spec: #期望Pod实现的功能(即在pod中部署)
hostAliases: #给pod添加hosts网络
- ip: "192.168.0.101"
hostnames:
- "node101"
- ip: "192.168.0.102"
hostnames:
- "node102"
- ip: "192.168.0.103"
hostnames:
- "node103"
containers: #生成container,与docker中的container是同一种
- name: ssx-elasticsearch6-c
image: 9d77v/elasticsearch:6.2.4 #配置阿里的镜像,直接pull即可
ports:
- containerPort: 9200 # 开启本容器的80端口可访问
- containerPort: 9300 # 开启本容器的80端口可访问
env: #容器运行前需设置的环境变量列表
- name: discovery.type #环境变量名称
value: "single-node" #环境变量的值 这是mysqlroot的密码 因为是纯数字,需要添加双引号 不然编译报错
volumeMounts:
- mountPath: /usr/share/elasticsearch/data #这是mysql容器内保存数据的默认路径
name: c-v-path-elasticsearch-data
- mountPath: /usr/share/elasticsearch/logs #这是mysql容器内保存数据的默认路径
name: c-v-path-elasticsearch-logs
- mountPath: /usr/share/elasticsearch/.cache #这是mysql容器内保存数据的默认路径
name: c-v-path-elasticsearch-cache
- mountPath: /etc/localtime #时间同步
name: c-v-path-lt
- name: ssx-kibana-c
image: wangxiaopeng65/kibana:6.2.4 #配置阿里的镜像,直接pull即可
ports:
- containerPort: 5601 # 开启本容器的80端口可访问
env: #容器运行前需设置的环境变量列表
- name: ELASTICSEARCH_URL #环境变量名称
value: "http://localhost:9200" #环境变量的值 这是mysqlroot的密码 因为是纯数字,需要添加双引号 不然编译报错
volumeMounts:
- mountPath: /usr/share/kibana/data2 #无用,我先看看那些挂载需要
name: c-v-path-kibana
- mountPath: /etc/localtime #时间同步
name: c-v-path-lt
- name: ssx-logstash-c
image: docker.elastic.co/logstash/logstash:6.2.4 #配置阿里的镜像,直接pull即可
env: #容器运行前需设置的环境变量列表
- name: "xpack.monitoring.enabled" #禁用登录验证
value: "false" #环境变量的值 这是mysqlroot的密码 因为是纯数字,需要添加双引号 不然编译报错
args: ["-f","/myconf/logstash.conf"]
volumeMounts:
- mountPath: /myconf #配置
name: c-v-path-logstash-conf
- mountPath: /usr/share/logstash/data #data
name: c-v-path-logstash-data
- mountPath: /etc/localtime #时间同步
name: c-v-path-lt
- name: ssx-filebeat-c
image: elastic/filebeat:6.2.4 #配置阿里的镜像,直接pull即可
env: #容器运行前需设置的环境变量列表
volumeMounts:
- mountPath: /usr/share/filebeat/filebeat.yml #配置
name: c-v-path-filebeat-conf
- mountPath: /usr/share/filebeat/data #配置
name: c-v-path-filebeat-data
- mountPath: /spring-boot-logs #data
name: c-v-path-filebeat-spring-logs
- mountPath: /etc/localtime #时间同步
name: c-v-path-lt
volumes:
- name: c-v-path-elasticsearch-data #和上面保持一致 这是本地的文件路径,上面是容器内部的路径
hostPath:
path: /home/app/apps/k8s/for_docker_volume/elk/elasticsearch6/data #此路径需要实现创建 注意要给此路径授权777权限 不然pod访问不到
- name: c-v-path-elasticsearch-logs #和上面保持一致 这是本地的文件路径,上面是容器内部的路径
hostPath:
path: /home/app/apps/k8s/for_docker_volume/elk/elasticsearch6/logs #此路径需要实现创建 注意要给此路径授权777权限 不然pod访问不到
- name: c-v-path-elasticsearch-cache #和上面保持一致 这是本地的文件路径,上面是容器内部的路径
hostPath:
path: /home/app/apps/k8s/for_docker_volume/elk/elasticsearch6/.cache #此路径需要实现创建 注意要给此路径授权777权限 不然pod访问不到
- name: c-v-path-kibana #和上面保持一致 这是本地的文件路径,上面是容器内部的路径
hostPath:
path: /home/app/apps/k8s/for_docker_volume/elk/kibana #此路径需要实现创建 注意要给此路径授权777权限 不然pod访问不到
- name: c-v-path-logstash-conf
hostPath:
path: /home/app/apps/k8s/for_docker_volume/elk/logstash/myconf
- name: c-v-path-logstash-data
hostPath:
path: /home/app/apps/k8s/for_docker_volume/elk/logstash/data
- name: c-v-path-lt
hostPath:
path: /etc/localtime #时间同步
- name: c-v-path-filebeat-conf
hostPath:
path: /home/app/apps/k8s/for_docker_volume/elk/filebeat/myconf/filebeat.yml
- name: c-v-path-filebeat-data
hostPath:
path: /home/app/apps/k8s/for_docker_volume/elk/filebeat/data
- name: c-v-path-filebeat-spring-logs
hostPath:
path: /home/ssx/appdata/ssx-log/docker-log
nodeSelector: #把此pod部署到指定的node标签上
kubernetes.io/hostname: node101
---
apiVersion: v1
kind: Service
metadata:
labels:
app: elk
name: ssx-elk-sv
namespace: ssx
spec:
ports:
- port: 9000 #我暂时不理解,这个设置 明明没用到?
name: ssx-elk-last9200
protocol: TCP
targetPort: 9200 # 容器nginx对外开放的端口 上面的dm已经指定了
nodePort: 30600 #外网访问的端口
- port: 9010 #我暂时不理解,这个设置 明明没用到?
name: ssx-elk-last9300
protocol: TCP
targetPort: 9300 # 容器nginx对外开放的端口 上面的dm已经指定了
nodePort: 30601 #外网访问的端口
- port: 9011 #我暂时不理解,这个设置 明明没用到?
name: ssx-kibana
protocol: TCP
targetPort: 5601 # 容器nginx对外开放的端口 上面的dm已经指定了
nodePort: 30602 #外网访问的端口
selector:
app: elk
type: NodePort