微服务架构
微服务架构是一种架构模式,它体长将单一应用程序划分成一组小的服务,服务之间相互协调,互相配合,为用户提供最终价值。每个服务运行在其独立的进程中,服务与服务之间采用轻量级的通信机制**(如HTTP)互相协作,每个服务都围绕着具体的业务进行构建,并且能够被独立的部署到生产环境中,另外,应尽量避免统一的,集中式的服务管理机制,对具体的一个服务而言,应根据业务上下文,选择合适的语言、工具(如Maven)**对其进行构建。
SpringCloud是关注全局的微服务协调整理治理框架,它将SpringBoot开发的一个个单体微服务,整合并管理起来,为各个微服务之间提供:配置管理、服务发现、断路器、路由、为代理、事件总栈、全局锁、决策竞选、分布式会话等等集成服务。
Spring Cloud是一个全家桶式的技术栈,包含了很多组件。本文先从其最核心的几个组件入手,来剖析一下其底层的工作原理。也就是Eureka、Ribbon、Feign、Hystrix、Zuul这几个组件。
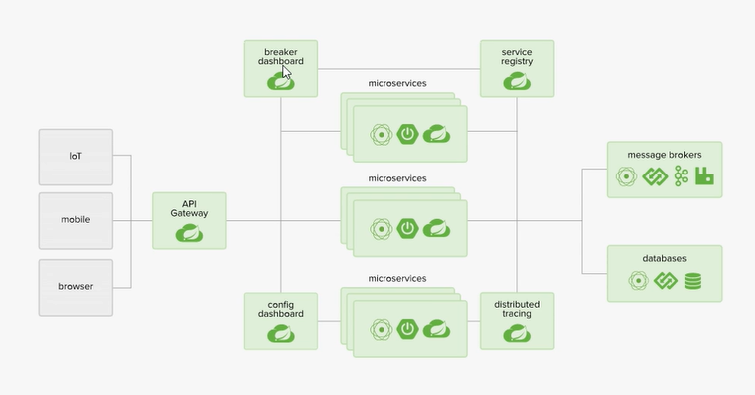
Spring Cloud核心组件:Eureka
Eureka Client:负责将这个服务的信息注册到Eureka Server中
Eureka Server:注册中心,里面有一个注册表,保存了各个服务所在的机器和端口号
Eureka Server注册中心,在主程序入口添加@EnableEurekaServer注解
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-netflix-eureka-server</artifactId>
<version>3.0.5</version>
</dependency>server:
port: 7000
#单机模式
eureka:
instance:
hostname: localhost #eureka服务端的实例名称
client:
register-with-eureka: false #是否向注册中心注册自己 ,因为自己就是注册中心 所以不用向自己注册自己
fetch-registry: false # 发现服务列表,因为自己是注册中心 所以不用发现
service-url:
#单机版注册地址,写自己的地址 如果是集群,则把后面的值改成 其它的 注册中心 对应的地址
defaultZone: http://${eureka.instance.hostname}:${server.port}/eureka/Eureka Client,在主程序入口添加@EnableEurekaClient注解
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-netflix-eureka-client</artifactId>
<version>3.1.4</version>
</dependency>server:
port: 8001
spring:
application:
name: provider
datasource:
url: jdbc:mysql://localhost:3306/myblog?characterEncoding=UTF-8&&serverTimezone=GMT
username: root
password: 123
driver-class-name: com.mysql.jdbc.Driver
eureka:
client:
register-with-eureka: true
fetch-registry: true
service-url:
defaultZone: http://localhost:7000/eureka
Spring Cloud核心组件:Ribbon
Ribbon作用是负载均衡,会帮你在每次请求时选择一台机器,均匀的把请求分发到各个机器上
Ribbon的负载均衡默认使用的最经典的Round Robin轮询算法
自定义Spring配置类配置负载均衡实现RestTemplate
@Configuration
public class RestTemplateConfiguration {
@Bean
@LoadBalanced
public org.springframework.web.client.RestTemplate restTemplate(){
return new org.springframework.web.client.RestTemplate();
}
}Spring Cloud核心组件:Hystrix
多个微服务之间调用的时候,假设微服务A调用微服务B和微服务C,微服务B和微服务C又调用其他的微服务,这就是所谓的“扇出”,如果扇出的链路上某个微服务的调用响应时间过长,或者不可用,对微服务A的调用就会占用越来越多的系统资源,进而引起系统崩溃,所谓的“雪崩效应”。对于高流量的应用来说,单一的后端依赖可能会导致所有服务器上的所有资源都在几十秒内饱和。比失败更糟糕的是,这些应用程序还可能导致服务之间的延迟增加,备份队列,线程和其他系统资源紧张,导致整个系统发生更多的级联故障,这些都表示需要对故障和延迟进行隔离和管理,以达到单个依赖关系的失败而不影响整个应用程序或系统运行。Hystrix是一个应用于处理分布式系统的延迟和容错的开源库,在分布式系统里,许多依赖不可避免的会调用失败,比如超时,异常等,Hystrix 能够保证在一个依赖出问题的情况下,不会导致整个体系服务失败,避免级联故障,以提高分布式系统的弹性。
熔断机制是赌赢雪崩效应的一种微服务链路保护机制。当扇出链路的某个微服务不可用或者响应时间太长时,会进行服务的降级,进而熔断该节点微服务的调用,快速返回错误的响应信息。检测到该节点微服务调用响应正常后恢复调用链路。在SpringCloud框架里熔断机制通过Hystrix实现。Hystrix会监控微服务间调用的状况,当失败的调用到一定阀值缺省是5秒内20次调用失败,就会启动熔断机制。熔断机制的注解是:@HystrixCommand。
服务降级是指 当服务器压力剧增的情况下,根据实际业务情况及流量,对一些服务和页面有策略的不处理,或换种简单的方式处理,从而释放服务器资源以保证核心业务正常运作或高效运作。说白了,就是尽可能的把系统资源让给优先级高的服务。
Spring Cloud核心组件:Zuul
Zull包含了对请求的路由(用来跳转的)和过滤两个最主要功能:其中路由功能负责将外部请求转发到具体的微服务实例上,是实现外部访问统一入口的基础,而过滤器功能则负责对请求的处理过程进行干预,是实现请求校验,服务聚合等功能的基础。Zuul和Eureka进行整合,将Zuul自身注册为Eureka服务治理下的应用,同时从Eureka中获得其他服务的消息,也即以后的访问微服务都是通过Zuul跳转后获得。
注:本文为学习狂神宝藏博主SpringCloud所作的笔记,更详细文章参考:https://www.kuangstudy.com/bbs/1374942542566551554


![【Kotlin】泛型 ② ( 可变参数 vararg 关键字与泛型结合使用 | 使用 [] 运算符获取指定可变参数对象 )](https://img-blog.csdnimg.cn/b2794bb397fa46dc9ea06696d9d64a6d.png)