迁移学习通过利用数据、任务或模型之间的相似性,将在旧领域学习过的模型应用于新领域来求解新问题。生活中常用的“举一反三”、“照猫画虎”就很好地体现了迁移学习的思想。利用迁移学习的思想,可以将已有的一些训练好的模型,迁移到我们的任务中,针对具体的任务进行微调来降低学习和训练的成本,此外还可以考虑不同任务之间的相似性和差异性,采用自适应学习,对模型进行灵活的调整,以满足不同需求。
迁移学习的基本概念
迁移学习简介
迁移学习(transfer learning)就是运用已有的知识来学习新的知识,核心是找到已有知识和新知识之间的相似性,由于直接对目标域从头开始学习成本太高,我们故而转向运用已有的相关知识来辅助尽快地学习新知识。比如,已经会下中国象棋,就可以类比着来学习国际象棋;已经学会骑自行车,就可以类比着来学习骑电动车;已经学会英语,就可以类比着来学习法语;等等。世间万事万物皆有共性,如何合理地找寻它们之间的相似性和差异性,进而利用这种相似性或差异性来帮助学习新知识,是迁移学习的核心问题[1]。
为什么要进行迁移
在文献[2]中,王晋东等人将为什么要进行迁移学习的原因总结为四个方面:
大数据与少标注之间的矛盾:我们所处的大数据时代每时每刻产生着海量的数据,但是这些数据缺乏完善的数据标注,而机器学习模型的训练和更新都依赖于数据的标注,目前只有很少的数据被标注和利用,这给机器学习和深度学习的模型训练和更新带来了挑战。
大数据与弱计算之间的矛盾:海量的数据需要强计算能力的设备进行存储和计算,强计算能力通常是非常昂贵的,此外使用海量数据来训练模型是非常耗时的,这就导致了大数据与弱计算之间的矛盾。
普适化模型与个性化需求之间的矛盾:机器学习的目的是构建尽可能通用的模型来满足不同用户、不同设备、不同环境的不同需求,这就要求模型有高的泛化能力,但是实际中普世化的通用模型无法满足个性化、差异化的需求,这就导致了模型同个性化需求之间的矛盾。
特定应用的需求:现实中往往存在着一些特定的应用,比如推荐系统的冷启动问题,这就需要我们尽可能利用已有的模型或知识来求解问题。
传统机器学习的方法不能解决这些矛盾,迁移学习则为这些矛盾的解决提供了思路,迁移学习的优点通常可以被总结为以下三个方面:
更高的起点。在微调之前,源模型的初始性能要比不使用迁移学习来的高。
更高的斜率。在训练的过程中源模型提升的速率要比不使用迁移学习来得快。
更高的渐进。训练得到的模型的收敛性能要比不使用迁移学习更好。

迁移学习与传统机器学习的区别

迁移学习是机器学习的一类,但是与传统机器学习又有所不同。传统迁移学习针对不同的学习任务建立不同的模型,迁移学习利用源域中的数据将知识迁移到目标与,完成模型的建立。
比较项目 | 传统机器学习 | 迁移学习 |
数据分布 | 训练和测试数据服从相同的分布 | 训练和测试数据服从不同的分布 |
数据标注 | 需要足够的数据标注来训练模型 | 可以在数据标注不足的情况下进行学习 |
模型 | 多个任务分别建模 | 模型可以在不同任务之间迁移 |
迁移学习的基本方法
迁移学习问题建模
迁移学习中有两个基本的概念,领域(Domain)和任务(Task)。
领域(Domain)是进行学习的主体,由数据和生成这些数据的概率分布组成。迁移学习涉及到两个基本的领域:源领域(Source Domain)和目标领域(Target Domain),源领域就是有知识以及大量数据标注的领域,是迁移的对象,目标领域是要赋予知识、赋予标注的对象。知识从源领域传递到目标领域就完成了迁移。
任务(Task)是学习的目标,任务由标签和标签对应的函数组成。
迁移学习(Transfer Learning):给定一个有标记的源域和一个无标记的目标域,这两个领域的数据分布不同,迁移学习的目的就是要借助源域的知识,来学习目标域的知识。
迁移学习需要考虑一下几个因素:
源域和目标域的特征空间的异同;
源域和目标域的类别空间的异同;
源域和目标域条件概率分布的异同;
迁移学习方法分类
迁移学习可以根据目标域有无标签、学习方法、特征以及离线与在线形式进行划分。
按目标域标签进行分类
类比机器学习,按照目标领域有无标签,迁移学习可以分为以下三类:
监督迁移学习(Supervised Transfer Learning)
半监督迁移学习(Semi-Supervised Transfer Learning)
无监督迁移学习(Unsupervised Transfer Learning)
其中半监督和无监督迁移学习,是研究的热点和难点。
按学习方法进行分类
在文献[1]中,Pan and Yang等人根据学习方法的不同将迁移学习分为以下四类。
基于样本的迁移学习方法(Instance based Transfer Learning):通过对源域中有标记样本加权利用完成知识迁移,例如相似的样本就给高的权重;
假设:源域中的一些数据和目标域会共享很多共同的特征
方法:对源域进行样本重新加权,筛选出与目标域数据相似度高的数据,然后进行训练学习
优点:方法较简单,容易实现
缺点:权重选择与相似度度量依赖经验;源域和目标域的数据分布往往不同
基于特征的迁移学习方法(Feature based Transfer Learning):通过将源域和目标域特征变换到相同的空间,并最小化源域和目标域的距离来完成知识迁移
假设:源域与目标域仅有一些交叉特征
方法:通过特征变换,将两个域的数据变换到同一个特征空间,然后进行传统的机器学习
优点:效果较好,目前大多数方法采用
缺点:转化为优化问题后难以求解
基于模型的迁移学习方法(Model based Transfer Learning):将源域和目标域的模型与样本结合起来调整模型的参数
假设:源域和目标域可以共享一些模型参数
方法:由源域学习到的模型运用到目标与上,再根据目标域学习新的模型
优点:可以利用模型间的相似性
缺点;模型参数不易收敛
基于关系的迁移学习方法(Relation based Transfer Learning):基于关系的迁移:通过在源域中学习概念之间的关系,然后将其类比到目标域中,完成知识的迁移。
假设:如果两个域是相似的,name他们会具有某种相似关系
利用源域学习逻辑关系网络,在应用于目标域上
这种分类比较直观。
按照特征进行分类
文献[3]中,按照特征属性,将迁移学习分为以下两类:
同构迁移学习(Homogeneous Transfer Learning):特征维度相同分布不同
异构迁移学习(Heterogeneous Transfer Learning):特性维度不同或特征本身就不同,如图片到文字
如果特征语义和维度相同,则认为是同构迁移学习,反之,如果特征完全不同,则认为是异构迁移学习,例如不同图片的迁移认为是同构的,而图片到文本的迁移是异构的。

按照离线与在线形式进行划分
按照离线学习与在线学习的方式,迁移学习可以被分为
离线迁移学习(Offline Transfer Learning)
在线迁移学习(Online Transfer Learning)
离线是指源域和目标域均是给定的,只需要迁移一次,目前绝大多数迁移学习都属于离线迁移。采用在线迁移学习时,随着数据的动态加入,迁移学习算法也可以不断地进行更新。
迁移学习应用
迁移学习是机器学习的重要分支,迁移学习的应用领域包括计算机视觉、文本分类、行为识别、自然语言处理、舆情分析等。
计算机视觉
在计算机视觉中,迁移学习方法被称为Domain Adaptation。Domain Adaptation的应用场景很多,比如图片分类等。
文本分类
文本数据具有特殊的领域属性,因此一种领域上的分类器不能直接的应用于另一种领域,例如电影评论文本数据集上训练好的分类器不能直接用于图书评论的预测。这就需要进行迁移。下图所示为一个电子产品评论迁移到DVD评论的迁移学习任务。

时间序列
随着智能设备的兴起,我们可以通过佩戴在人体不同部位的传感器,来研究用户的行为。用户的不同、环境的不同、所处位置的不同、设备的不同都会导致时间序列数据的分布发生变化,如下图所示,文章[6]对迁移学习在行为识别领域的应用进行了深入的研究。

深度迁移学习
随着深度学习方法的大行其道,越来越多的研究人员使用深度神经网络进行迁移学习。对比传统的非深度迁移学习方法,深度迁移学习直接提升了在不同任务上的学习效果。
近年来,以生成对抗网络 (Generative Adversarial Nets, GAN) 为代表的对抗学习也吸引了很多研究者的目光。基于 GAN 的各种变体网络不断涌现。对抗学习网络对比传统的深度神经网络,极大地提升了学习效果。因此,基于对抗网络的迁移学习,也是一个热门的研究点。
为什么深度网络可以进行迁移
近年来,深度学习在几区学习的研究和应用领域大放异彩,但是神经网络具有难以解释的特点,由于神经网络具有层次的结构,因此可以通过对每层的作用进行模型的解释。换句话说,可以认为神经网络的前面几层学习到的是通用特征,随着网络的加深,后面的网络更偏重于学习到任务相关的特定特征,因此可以利用这种通用特征和任务相关的特定特征进行知识迁移。根据这个思想,文献[4]中把ImageNet的1000种类别分为两类A和B,每类500种,然后针对A和B分别训练了一个AlexNet[5],每个AlexNet分别有8层,出去最后一层是类别相关的网络无法迁移外,作者在1到7层上逐层进行finetune实验,对深度网络的可迁移性进行了探索。实验结果表明,该网络的前三层基本都是通用特征,进行迁移的效果比较好;此外深度网络中加入finetune进行迁移,效果会比较好,结果甚至比原网络的效果更好,另一方面,该实验也证明了深度迁移网络的效果比随机初始化参数要好,同时还证明了网络层数的迁移可以加速网络的学习和优化。
深度迁移:Finetune
Finetune是指利用别人训练好的网络,针对自己的新的任务进行调整,从而提高训练效率,境地训练成本,同时可以克服训练数据不足的缺点。
举例来说,加入我们需要训练一个猫狗图像二分类的神经网络,一个比较好的做法就是利用CIFAR-100上寻好的网络,但是CIFAR-100上有100个类别,而我们只需要2个类别,此时我们可以固定网络的相关层,修改网络的输出层,这样可以极大地加快网络训练速度,而且对网络的表现也有促进作用,此时Finetune示意如下图所示

深度网络自适应
Finetune可以节省训练时间和降低训练成本,但是Finetune假设训练数据和测试数据具有相同的分布,而这种假设并不总是成立的。因此,一些深度网络引入了自适应层来完成源域和目标域数据的自适应。自适应层能够是的源域和目标域的数据分布更加接近,从而使得网络的效果更好。
大多数深度迁移网络将损失参数定义如下
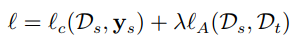
表示最终的网络损失为源域上的损失和自适应损失的和,其中lambda表示二者的权重参数,不同的方法对自适应损失的定义有所不同。
Deep Domain Confusion
Tzeng等人于2014年提出了DDC(Deep Domain Confusion)方法,在ImageNet上训练好的AlexNet网络上进行自适应迁移。如下图所示,DDC固定了AlexNet的前7层,在第八层上加入了自适应度量,其自适应度量方法采用了MMD准则。

同时迁移领域和任务
Tzeng在2015年扩展了DDC方法,将源任务和目标任务之间的联系考虑进来,在Domain Confusion的基础上引入了soft label loss[8],其网络如下图所示

Adaptation Batch Normalization
北京大学Haoyang Li等人提出AdaBNN(Adaptation Batch Normalization)通过在归一化层加入了统计特征的适配完成从源任务到目标任务的迁移[9],其网络结构如下图所示。

AdaBN对比其他方法,实现比较简单。并且没有引入额外的参数。在许多公开数据集上都取得了很好的效果。
深度对抗网络迁移
生成对抗网络GAN是人工智能领域的研究热点之一。GAN主要包括生成器 (Generator)和判别器 (Discriminator)。生成器和判别器的互相博弈,就完成了对抗训练。深度对抗网络迁移中生成器的职能发生变化,不再生成新样本,而是扮演了特征提取的功能:不断学习领域数据的特征,使得判别器无法对两个领域进行分辨,从而达到迁移的目的。
与深度网络自适应迁移方法类似,深度对抗网络的损失也由两部分构成:网络训练的损失和领域判别的损失
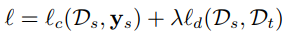
Domain-Adversarial Neural Network
Yaroslav Ganin 等人[10]首先在神经网络的训练中加入了对抗机制,提出DANN(Domain-Adversarial Neural Network)。在此研究中,网络的学习目标是: 生成的特征尽可能帮助区分两个领域的特征,同时使得判别器无法对两个领域的差异进行判别。
Domain Separation Networks
Bousmalis 等人通过提出 DSN 网络 (Domain Separation Networks) 对 DANN 进行了扩展[11]。 DSN 认为,源域和目标域都由两部
分构成:公共部分和私有部分。公共部分可以学习公共的特征,私有部分用来保持各个领域独立的特性。 DSN 定义损失函数为:
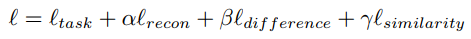
分别表示常规训练的损失、重构损失、公共部分和私有部分的差异损失和源域同目标于公共部分的相似性损失。其网络结构示意如图

Selective Adversarial Networks
针对源域数据通常比目标域丰富,且源域中可能存在对迁移结果存在负迁移影响的类别的问题,Cao等人提出了SAN(Selective Adversarial Networks)[12]
Dynamic Adversarial Adaptation Networks
Yu 等人将动态分布适配的概念进一步扩展到了对抗网络中,证明了对抗网络中同样存在边缘分布和条件分布不匹配的问题,提出一个动态对
抗适配网络 DAAN (Dynamic Adversarial Adaptation Networks) 来解决对抗网络中的动态分布适配问题,取得了当前的最好效果,DAAN架构如下图所示

总结
迁移学习是近年来机器学习领域研究热点之一,在本文中,简明地介绍了迁移学习的基本概念、研究领域和迁移学习的基本方法。针对目前强化学习接入、训练都比价耗时的情况,利用预训练的模型可以显著的降低训练工作量,提升训练效果,预训练的模型在计算机视觉、NLP领域都取得了很大的成功,但是在强化学习领域,仍然是一个亟待研究的问题,后续我们可以考虑通用模型建模和预训练模型,从而进一步提升强化学习的训练效率和模型表现。
![【Kotlin】泛型 ② ( 可变参数 vararg 关键字与泛型结合使用 | 使用 [] 运算符获取指定可变参数对象 )](https://img-blog.csdnimg.cn/b2794bb397fa46dc9ea06696d9d64a6d.png)