题目
如何得到一个数据流中的中位数?如果从数据流中读出奇数个数值,那么中位数就是所有数值排序之后位于中间的数值。如果从数据流中读出偶数个数值,那么中位数就是所有数值排序之后中间两个数的平均值。
例如,
[2,3,4] 的中位数是 3
[2,3] 的中位数是 (2 + 3) / 2 = 2.5
设计一个支持以下两种操作的数据结构:
- void addNum(int num) - 从数据流中添加一个整数到数据结构中。
- double findMedian() - 返回目前所有元素的中位数。
示例 1:
输入:
["MedianFinder","addNum","addNum","findMedian","addNum","findMedian"]
[[],[1],[2],[],[3],[]]
输出:[null,null,null,1.50000,null,2.00000]
示例 2:
输入:
["MedianFinder","addNum","findMedian","addNum","findMedian"]
[[],[2],[],[3],[]]
输出:[null,null,2.00000,null,2.50000]
限制:最多会对 addNum、findMedian 进行 50000 次调用。
思路
维护两个堆,若n是偶数,它们保存的元素的数目都是n / 2;若n是奇数,大根堆比小根堆多保存一个元素。
一个是大根堆:保存较小的那一部分数;
一个是小根堆:保存较大的那一部分数。
要求中位数:
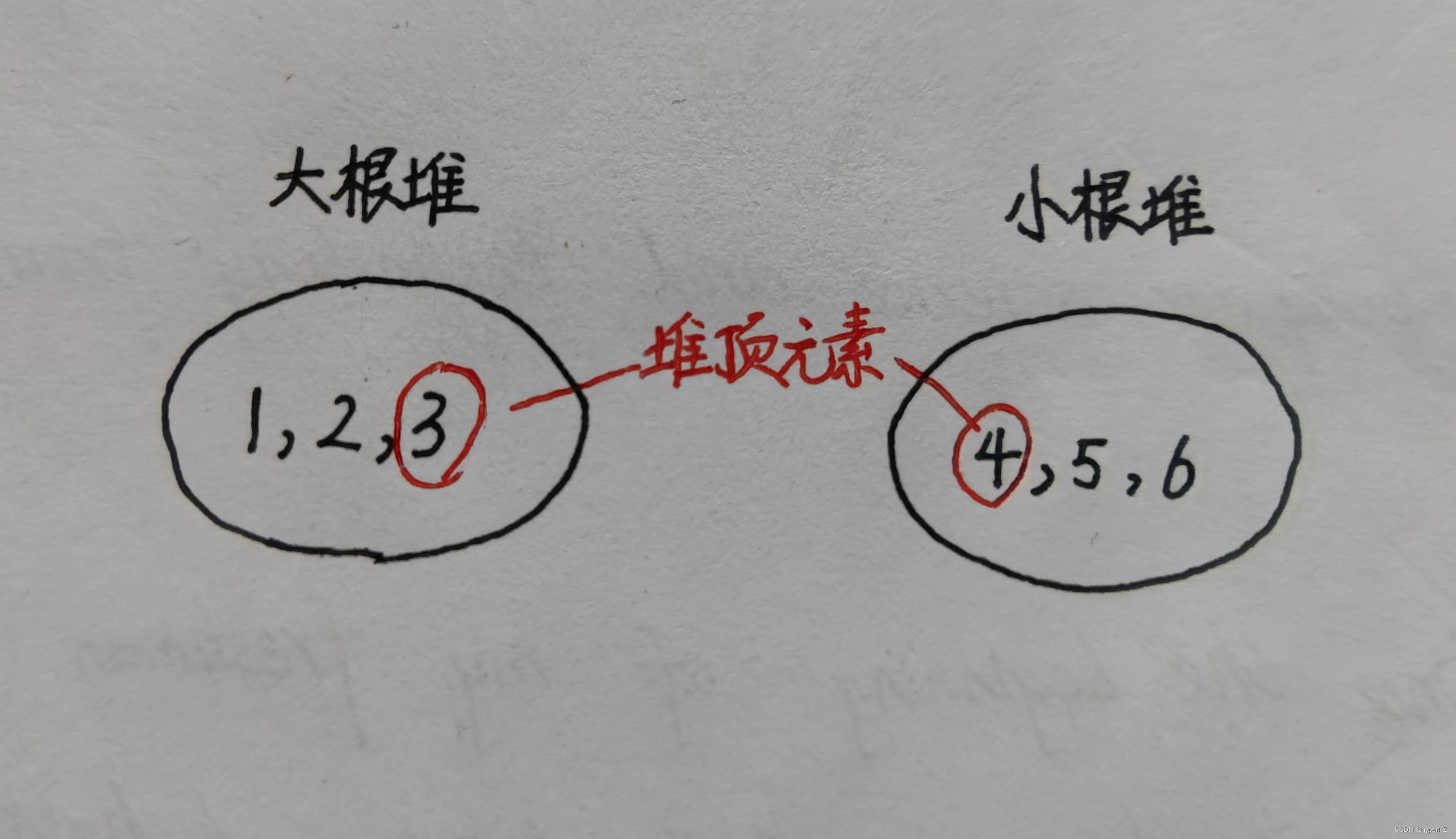
若n是偶数:直接将两个堆的堆顶元素取出,相加除以2即可。
例:[1,2,3,4,5,6]
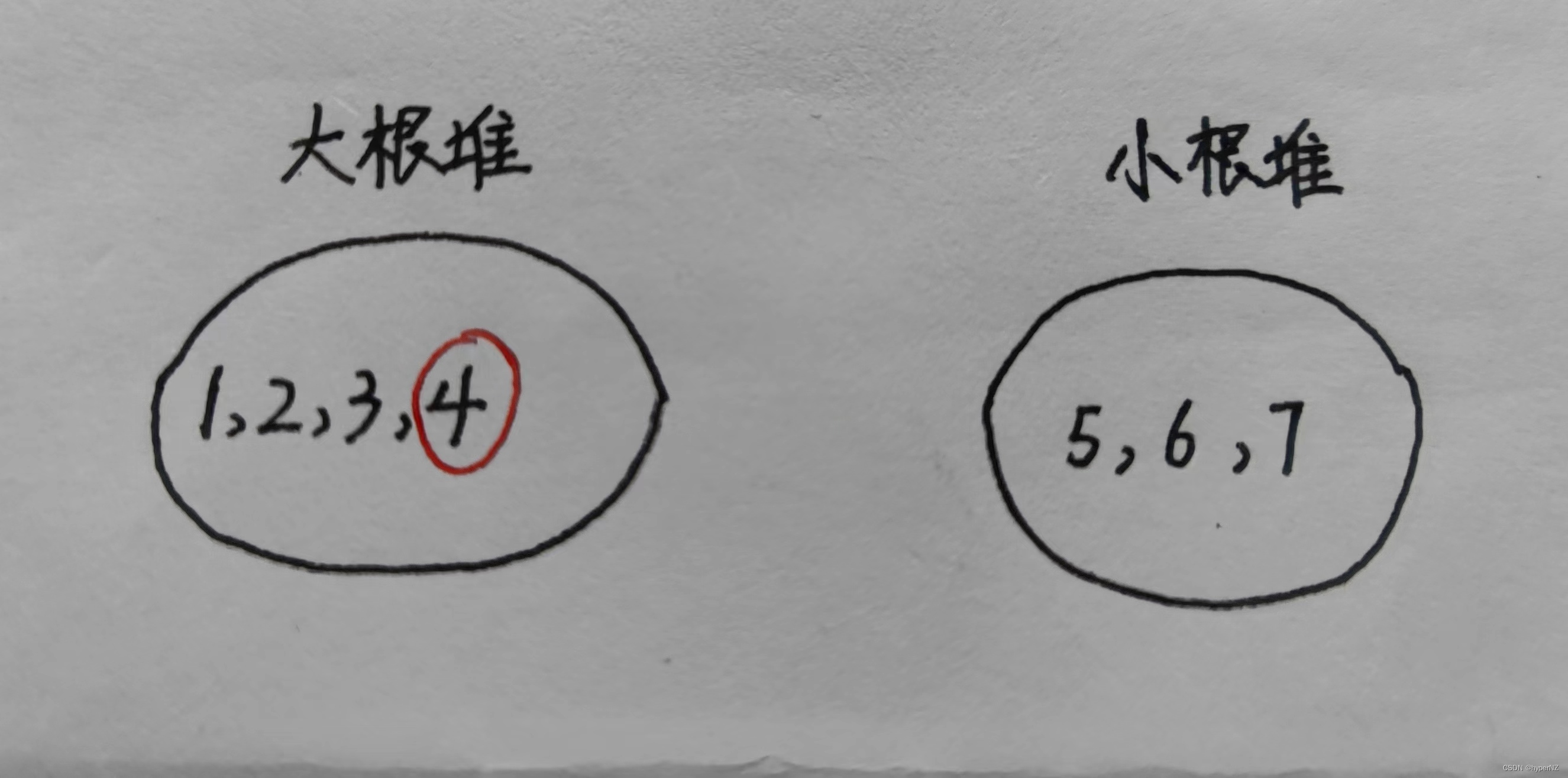
若n是奇数:(规定大根堆多保存一个元素)直接将大根堆堆顶元素取出即可。
例:[1,2,3,4,5,6,7]
时间复杂度:O(1);
空间复杂度:O(n)。
动态维护(插入操作):
当插入时:
若n是偶数:将要插入的元素添加到小根堆里,再把小根堆堆顶的元素放到大根堆里,这样就进行了动态维护,插入后n为奇数,直接将大根堆堆顶元素取出即可。
若n是奇数:将要插入的元素添加到大根堆里,再把大根堆堆顶的元素放到小根堆里,这样就进行了动态维护,插入后n为偶数,直接将两个堆的堆顶元素取出,相加除以2即可。
时间复杂度:O(logn);
空间复杂度:O(n)。
java使用优先队列实现大根堆和小根堆,默认是小根堆。
小根堆创建
PriorityQueue<Integer> minHeap = new PriorityQueue<>(k, (a, b) -> a - b);大根堆创建
PriorityQueue<Integer> maxHeap = new PriorityQueue<>(k, (a, b) -> b - a);其中构造器中的k表示创建堆的大小,之后用Lambda表达式快速实现自定义排序。
Lambda语法
表达式:
(parameters) -> expression代码块:
(parameters) -> {statements;}Lambda表达式由三部分组成:
1、paramaters:类似方法中的形参列表,这里的参数是函数式接口里的参数。这里的参数类型可以明确的声明也可不声明而由JVM隐含的推断。另外当只有一个推断类型时可以省略掉圆括号。
2、->:可理解为“被用于”的意思。
3、方法体:可以是表达式也可以代码块,是函数式接口里方法的实现。代码块可返回一个值或者什么都不反回,这里的代码块块等同于方法的方法体。如果是表达式,也可以返回一个值或者什么都不反回。
代码
class MedianFinder {
Queue<Integer> min, max;
public MedianFinder() {
min = new PriorityQueue<>(); //优先级队列默认是小根堆,保存较大的数值
max = new PriorityQueue<>((x, y) -> (y - x)); //大根堆需要进行重写,保存较小的数值
}
public void addNum(int num) {
//是偶数
if(min.size() == max.size()) {
min.add(num);
max.add(min.poll());
} else { //是奇数
max.add(num);
min.add(max.poll());
}
}
public double findMedian() {
//是偶数
if(min.size() == max.size()) {
return (min.peek() + max.peek()) / 2.0;
} else {
return max.peek() * 1.0;
}
}
}