文章目录
- 前言
- 正文
前言
下面聊聊JDK1.7HashMap的死循环问题,在这之前首先要知道JDK1.7的HashMap底层是数组 + 链表的形式的
正文
下面给出JDK1.7的扩容代码
//扩容代码
void resize(int newCapacity) {
//旧的数组
Entry[] oldTable = table;
//旧的数组长度
int oldCapacity = oldTable.length;
//判断有没有达到了设定容量最大值,如果有那么把阈值改成最大就可以了
//没办法进行扩容了
if (oldCapacity == MAXIMUM_CAPACITY) {
threshold = Integer.MAX_VALUE;
return;
}
//根据新的容量创建出来一个新数组
Entry[] newTable = new Entry[newCapacity];
//对原来的数组进行一个转移
transfer(newTable, initHashSeedAsNeeded(newCapacity));
//设置新数组
table = newTable;
//设置新的扩容阈值
threshold = (int)Math.min(newCapacity * loadFactor, MAXIMUM_CAPACITY + 1);
}
下面是转移的代码,多线程问题就发生在这里面
void transfer(Entry[] newTable, boolean rehash) {
//新数组长度
int newCapacity = newTable.length;
for (Entry<K,V> e : table) {
//遍历整个table
while(null != e) {
//然后遍历上面的每一个节点链表
//记录当前节点的下一个
Entry<K,V> next = e.next;
//判断是不是再次要进行hash
if (rehash) {
e.hash = null == e.key ? 0 : hash(e.key);
}
//通过key值的hash值和新数组的大小算出在当前数组中的存放位置
int i = indexFor(e.hash, newCapacity);
//然后进行头插入
e.next = newTable[i];
newTable[i] = e;
e = next;
}
}
}
下面用一些图来说明这个过程,首先是正常的扩容,假设扩容前后都是在同一个下标:

然后下面是多线程下的线程安全问题,假设目前是线程t1和线程t2

从上面图中我们可以看到第一次进入的时候,e1和e2都是指向1,然后next都是指向2,然后假设线程2(e2和next2)都被阻塞住了,这时候假设线程 t2 被阻塞住,然后线程 t1 去进行扩容的操作。
下面就是线程t1执行完成之后的图片,这里我把e1和next1都省略了,因为多线程和这两个没关系了

然后接下来就是线程1被阻塞住,线程2开始执行扩容,这时候注意,线程2进行扩容的数组也是一个新数组,因为两个线程生成了两个数组,下面用新数组_1代表

执行 e2.next = newTable[i]

执行 newTable[i] = e2,e2 = next

上面一次循环结束了,下面第二次循环开始,e2.next = newTable[i];

newTable[i] = e2,e2 = next

第二次循环结束,结束之后e2指向1的位置,next指向null,然后进入第三次循环,接下来就要死循环了,e2.next = newTable[i],然后两个节点互相指上
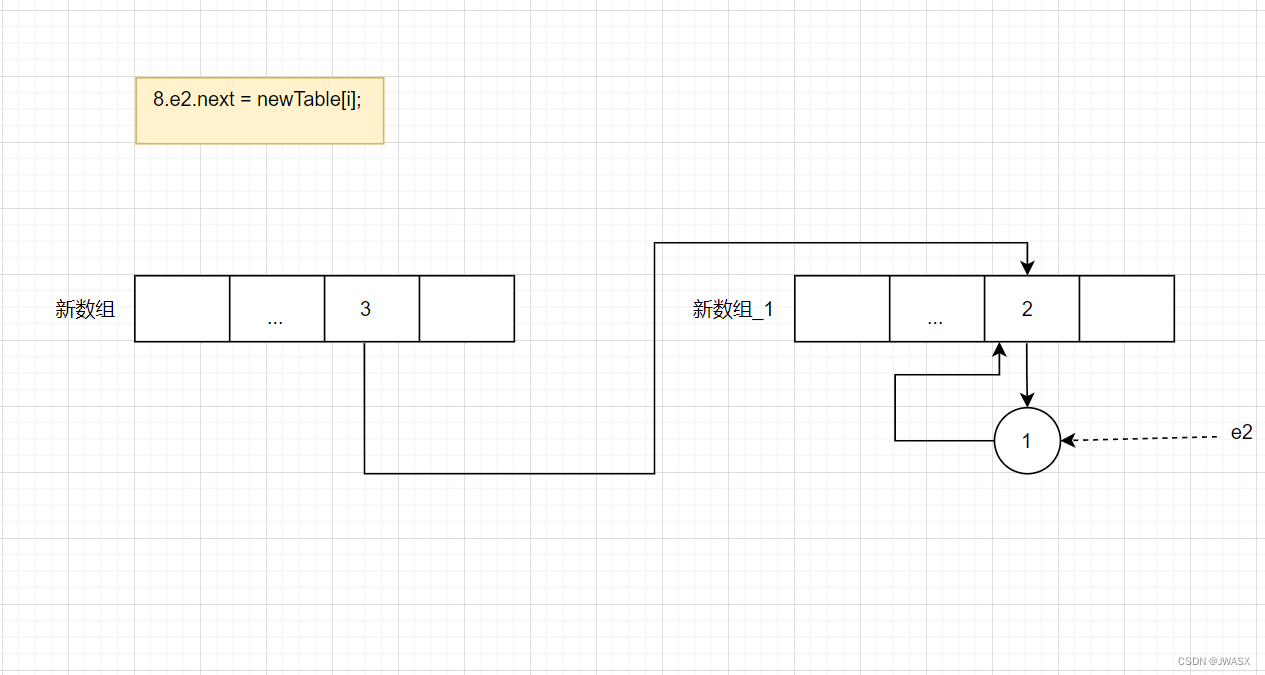
上面就是整个死循环的过程了,其实从上面的死循环过程可以看到死循环开端就是因为指针 e2 和 next2 指针不是真正意义的 e.next关系,我们想法就是 e2 能够沿着 1->2 -> 3来执行,但是经过线程1的扩容之后e2和next2变成了next2.next = e2了,所以接下来e2是不可能沿着next指针到节点3的,因为e2 = next2,但是next2的next又指向了e2,这就导致了死循环。所以死循环的原因就是:
JDK1.7中原来的数组进行扩容之后头插法导致数组的元素进行了反转,但是指针位置却不变,导致了原来的next是e.next,但是反转之后next.next = e了,所以e最终会和next节点进行死循环。