go test
go 集成了比较好用的test测试命令,该命令可以测试Go代码的可用性。
前奏
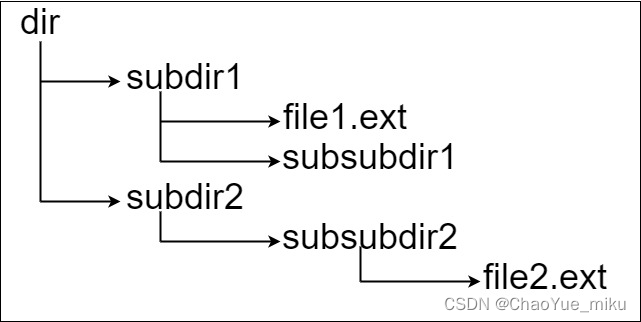
该文所需的项目目录结构为:
example
|
|---------function.go
|
|---------function_test.go
|
|---------go.mod
function.go文件是我们写用户代码的地方,function_test.go文件中写function.go的测试用例。
这是一种规范:xxx.go的测试文件为xxx_test.go。
Test 单元测试
向function.go文件中添加代码
func AddOne(num int) int {
return num + 1
}
向function_test.go文件中添加代码
func TestAddOne(t *testing.T) {
var (
in = 1
expected = 2
)
actual := AddOne(in)
if actual != expected {
t.Errorf("AddOne(%d), expected = %d, actual = %d", in, expected, actual)
}
}
若为goland,可以直接点击TestAddOne左侧的绿色三角按钮进行执行测试。执行结果如下:
=== RUN TestAddOne
--- PASS: TestAddOne (0.00s)
PASS
将鼠标光标定位到左侧绿色三角按钮位置,单击一下,可以查看测试的一些指标

如以执行或调试的方式运行,测试代码覆盖率,CPU分析,内存分析,阻塞分析,锁分析。
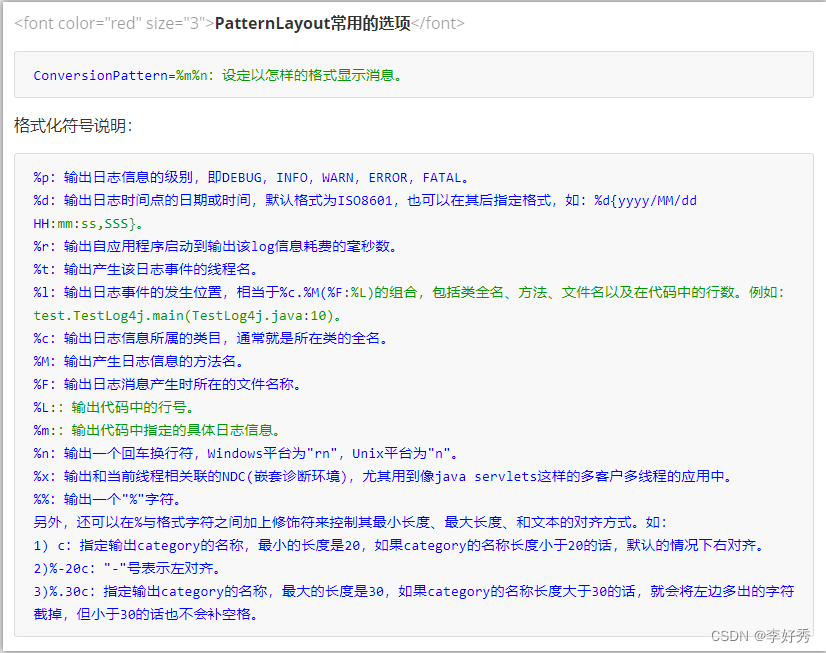
代码覆盖率描述了方法中哪些片段执行到了,哪些片段没有执行到。
用命令行的方式测试代码覆盖率:
...\example>go test -coverprofile=coverage.out
PASS
coverage: 100.0% of statements
ok example 0.295s
该命令要指定生成覆盖率数据的文件,若命令中的coverage.out。
执行完该命令,项目的目录结构为:
example
|
|---------coverage.out
|
|---------function.go
|
|---------function_test.go
|
|---------go.mod
打开.out文件,有如下数据。
mode: set
example/function.go:3.26,5.2 1 1
该数据不方便查看,可以使用:
go tool cover -html=coverage.out 命令可视化查看上述指标。该命令会自动打开浏览器。

可以看出,左上角example/function.go (100.0%) 表示代码覆盖率为100%,若有多个测试文件,还可以选择其他文件查看。
not tracked可以先不看,它用于跟踪代码。
not covered表示未执行到的代码,会标红色。
covered表示执行过的代码,会标绿色。
向function.go文件中追加如下代码:
func AddOne2(num int) int {
if 1 > 10 {
fmt.Println("1 > 10")
}
return num + 1
}
if 1 > 10 的条件永远不会成立。
向function_test.go文件中追加如下代码:
func TestAddOne2(t *testing.T) {
var (
in = 1
expected = 2
)
actual := AddOne2(in)
if actual != expected {
t.Errorf("AddOne2(%d), expected = %d, actual = %d", in, expected, actual)
}
}
然后执行如下命令:
...\example>go test -coverprofile=coverage.out
PASS
coverage: 75.0% of statements
ok example 0.312s
用可视化的方式查看一下结果:
go tool cover -html=coverage.out
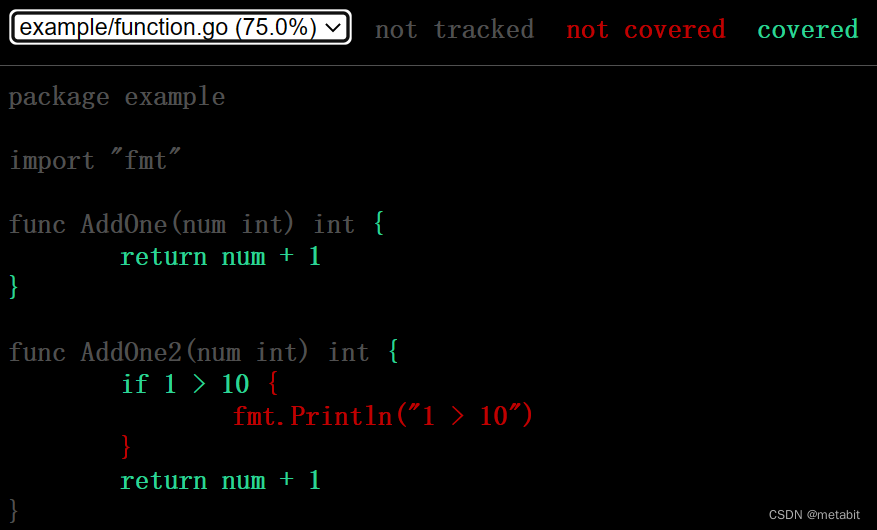
可以发现,整个if分支后的代码块都标记成了红色。
以表的形式,完成多组测试用例测试。
修改function_test.go文件的TestOne函数
func TestAddOne(t *testing.T) {
testCase := []struct {
in int
expected int
}{
{1, 2},
{2, 3},
{3, 4},
{4, 5},
{5, 6},
}
for _, tc := range testCase {
actual := AddOne(tc.in)
if actual != tc.expected {
t.Errorf("AddOne(%d), expected = %d, actual = %d", tc.in, tc.expected, actual)
}
}
}
执行结果:
=== RUN TestAddOne
--- PASS: TestAddOne (0.00s)
PASS
ExampleTest 示例测试
向function_test.go文件中追加代码:
func ExampleHello() {
fmt.Println("hello")
// Output: hello
}
执行结果为:
=== RUN ExampleHello
--- PASS: ExampleHello (0.00s)
PASS
修改fmt.Println(“hello”) hello为hello world
执行结果为:
=== RUN ExampleHello
--- FAIL: ExampleHello (0.00s)
got:
hello world
want:
hello
FAIL
可以发现,测试结果是与// Output: 之后的值是紧密相关的。
BenckmarkTest 基准测试
向function_test.go中追加如下代码:
func BenchmarkStringAppend(b *testing.B) {
str := ""
for i := 0; i < b.N; i++ {
str += "hello"
}
}
func BenchmarkStringBuilderAppend(b *testing.B) {
bld := strings.Builder{}
for i := 0; i < b.N; i++ {
bld.WriteString("hello")
}
}
其执行结果分别为:
goos: windows
goarch: amd64
pkg: example
cpu: Intel(R) Core(TM) i5-7200U CPU @ 2.50GHz
BenchmarkStringAppend
BenchmarkStringAppend-4 152083 143699 ns/op
PASS
每次操作143699ns,共执行152083次
goos: windows
goarch: amd64
pkg: example
cpu: Intel(R) Core(TM) i5-7200U CPU @ 2.50GHz
BenchmarkStringBuilderAppend
BenchmarkStringBuilderAppend-4 93936404 12.35 ns/op
PASS
每次操作12.35ns,共执行93936404次
可以发现,strings.Builder的追加性能要明显优于直接用"+"号进行string 的 追加
FuzzTest 模糊测试
func FuzzHex(f *testing.F) {
for _, seed := range [][]byte{{}, {0}, {9}, {0xa}, {0xf}, {1, 2, 3, 4}} {
f.Add(seed)
}
f.Fuzz(func(t *testing.T, in []byte) {
enc := hex.EncodeToString(in)
out, err := hex.DecodeString(enc)
if err != nil {
t.Fatalf("%v: decode: %v", in, err)
}
if !bytes.Equal(in, out) {
t.Fatalf("%v: not equal after round trip: %v", in, out)
}
})
}
建议阅读一下src/testing/testing.go文件中的注释
// Package testing provides support for automated testing of Go packages.
// It is intended to be used in concert with the "go test" command, which automates
// execution of any function of the form
//
// func TestXxx(*testing.T)
//
// where Xxx does not start with a lowercase letter. The function name
// serves to identify the test routine.
//
// Within these functions, use the Error, Fail or related methods to signal failure.
//
// To write a new test suite, create a file whose name ends _test.go that
// contains the TestXxx functions as described here. Put the file in the same
// package as the one being tested. The file will be excluded from regular
// package builds but will be included when the "go test" command is run.
// For more detail, run "go help test" and "go help testflag".
//
// A simple test function looks like this:
//
// func TestAbs(t *testing.T) {
// got := Abs(-1)
// if got != 1 {
// t.Errorf("Abs(-1) = %d; want 1", got)
// }
// }
//
// # Benchmarks
//
// Functions of the form
//
// func BenchmarkXxx(*testing.B)
//
// are considered benchmarks, and are executed by the "go test" command when
// its -bench flag is provided. Benchmarks are run sequentially.
//
// For a description of the testing flags, see
// https://golang.org/cmd/go/#hdr-Testing_flags.
//
// A sample benchmark function looks like this:
//
// func BenchmarkRandInt(b *testing.B) {
// for i := 0; i < b.N; i++ {
// rand.Int()
// }
// }
//
// The benchmark function must run the target code b.N times.
// During benchmark execution, b.N is adjusted until the benchmark function lasts
// long enough to be timed reliably. The output
//
// BenchmarkRandInt-8 68453040 17.8 ns/op
//
// means that the loop ran 68453040 times at a speed of 17.8 ns per loop.
//
// If a benchmark needs some expensive setup before running, the timer
// may be reset:
//
// func BenchmarkBigLen(b *testing.B) {
// big := NewBig()
// b.ResetTimer()
// for i := 0; i < b.N; i++ {
// big.Len()
// }
// }
//
// If a benchmark needs to test performance in a parallel setting, it may use
// the RunParallel helper function; such benchmarks are intended to be used with
// the go test -cpu flag:
//
// func BenchmarkTemplateParallel(b *testing.B) {
// templ := template.Must(template.New("test").Parse("Hello, {{.}}!"))
// b.RunParallel(func(pb *testing.PB) {
// var buf bytes.Buffer
// for pb.Next() {
// buf.Reset()
// templ.Execute(&buf, "World")
// }
// })
// }
//
// A detailed specification of the benchmark results format is given
// in https://golang.org/design/14313-benchmark-format.
//
// There are standard tools for working with benchmark results at
// https://golang.org/x/perf/cmd.
// In particular, https://golang.org/x/perf/cmd/benchstat performs
// statistically robust A/B comparisons.
//
// # Examples
//
// The package also runs and verifies example code. Example functions may
// include a concluding line comment that begins with "Output:" and is compared with
// the standard output of the function when the tests are run. (The comparison
// ignores leading and trailing space.) These are examples of an example:
//
// func ExampleHello() {
// fmt.Println("hello")
// // Output: hello
// }
//
// func ExampleSalutations() {
// fmt.Println("hello, and")
// fmt.Println("goodbye")
// // Output:
// // hello, and
// // goodbye
// }
//
// The comment prefix "Unordered output:" is like "Output:", but matches any
// line order:
//
// func ExamplePerm() {
// for _, value := range Perm(5) {
// fmt.Println(value)
// }
// // Unordered output: 4
// // 2
// // 1
// // 3
// // 0
// }
//
// Example functions without output comments are compiled but not executed.
//
// The naming convention to declare examples for the package, a function F, a type T and
// method M on type T are:
//
// func Example() { ... }
// func ExampleF() { ... }
// func ExampleT() { ... }
// func ExampleT_M() { ... }
//
// Multiple example functions for a package/type/function/method may be provided by
// appending a distinct suffix to the name. The suffix must start with a
// lower-case letter.
//
// func Example_suffix() { ... }
// func ExampleF_suffix() { ... }
// func ExampleT_suffix() { ... }
// func ExampleT_M_suffix() { ... }
//
// The entire test file is presented as the example when it contains a single
// example function, at least one other function, type, variable, or constant
// declaration, and no test or benchmark functions.
//
// # Fuzzing
//
// 'go test' and the testing package support fuzzing, a testing technique where
// a function is called with randomly generated inputs to find bugs not
// anticipated by unit tests.
//
// Functions of the form
//
// func FuzzXxx(*testing.F)
//
// are considered fuzz tests.
//
// For example:
//
// func FuzzHex(f *testing.F) {
// for _, seed := range [][]byte{{}, {0}, {9}, {0xa}, {0xf}, {1, 2, 3, 4}} {
// f.Add(seed)
// }
// f.Fuzz(func(t *testing.T, in []byte) {
// enc := hex.EncodeToString(in)
// out, err := hex.DecodeString(enc)
// if err != nil {
// t.Fatalf("%v: decode: %v", in, err)
// }
// if !bytes.Equal(in, out) {
// t.Fatalf("%v: not equal after round trip: %v", in, out)
// }
// })
// }
//
// A fuzz test maintains a seed corpus, or a set of inputs which are run by
// default, and can seed input generation. Seed inputs may be registered by
// calling (*F).Add or by storing files in the directory testdata/fuzz/<Name>
// (where <Name> is the name of the fuzz test) within the package containing
// the fuzz test. Seed inputs are optional, but the fuzzing engine may find
// bugs more efficiently when provided with a set of small seed inputs with good
// code coverage. These seed inputs can also serve as regression tests for bugs
// identified through fuzzing.
//
// The function passed to (*F).Fuzz within the fuzz test is considered the fuzz
// target. A fuzz target must accept a *T parameter, followed by one or more
// parameters for random inputs. The types of arguments passed to (*F).Add must
// be identical to the types of these parameters. The fuzz target may signal
// that it's found a problem the same way tests do: by calling T.Fail (or any
// method that calls it like T.Error or T.Fatal) or by panicking.
//
// When fuzzing is enabled (by setting the -fuzz flag to a regular expression
// that matches a specific fuzz test), the fuzz target is called with arguments
// generated by repeatedly making random changes to the seed inputs. On
// supported platforms, 'go test' compiles the test executable with fuzzing
// coverage instrumentation. The fuzzing engine uses that instrumentation to
// find and cache inputs that expand coverage, increasing the likelihood of
// finding bugs. If the fuzz target fails for a given input, the fuzzing engine
// writes the inputs that caused the failure to a file in the directory
// testdata/fuzz/<Name> within the package directory. This file later serves as
// a seed input. If the file can't be written at that location (for example,
// because the directory is read-only), the fuzzing engine writes the file to
// the fuzz cache directory within the build cache instead.
//
// When fuzzing is disabled, the fuzz target is called with the seed inputs
// registered with F.Add and seed inputs from testdata/fuzz/<Name>. In this
// mode, the fuzz test acts much like a regular test, with subtests started
// with F.Fuzz instead of T.Run.
//
// See https://go.dev/doc/fuzz for documentation about fuzzing.
//
// # Skipping
//
// Tests or benchmarks may be skipped at run time with a call to
// the Skip method of *T or *B:
//
// func TestTimeConsuming(t *testing.T) {
// if testing.Short() {
// t.Skip("skipping test in short mode.")
// }
// ...
// }
//
// The Skip method of *T can be used in a fuzz target if the input is invalid,
// but should not be considered a failing input. For example:
//
// func FuzzJSONMarshaling(f *testing.F) {
// f.Fuzz(func(t *testing.T, b []byte) {
// var v interface{}
// if err := json.Unmarshal(b, &v); err != nil {
// t.Skip()
// }
// if _, err := json.Marshal(v); err != nil {
// t.Error("Marshal: %v", err)
// }
// })
// }
//
// # Subtests and Sub-benchmarks
//
// The Run methods of T and B allow defining subtests and sub-benchmarks,
// without having to define separate functions for each. This enables uses
// like table-driven benchmarks and creating hierarchical tests.
// It also provides a way to share common setup and tear-down code:
//
// func TestFoo(t *testing.T) {
// // <setup code>
// t.Run("A=1", func(t *testing.T) { ... })
// t.Run("A=2", func(t *testing.T) { ... })
// t.Run("B=1", func(t *testing.T) { ... })
// // <tear-down code>
// }
//
// Each subtest and sub-benchmark has a unique name: the combination of the name
// of the top-level test and the sequence of names passed to Run, separated by
// slashes, with an optional trailing sequence number for disambiguation.
//
// The argument to the -run, -bench, and -fuzz command-line flags is an unanchored regular
// expression that matches the test's name. For tests with multiple slash-separated
// elements, such as subtests, the argument is itself slash-separated, with
// expressions matching each name element in turn. Because it is unanchored, an
// empty expression matches any string.
// For example, using "matching" to mean "whose name contains":
//
// go test -run '' # Run all tests.
// go test -run Foo # Run top-level tests matching "Foo", such as "TestFooBar".
// go test -run Foo/A= # For top-level tests matching "Foo", run subtests matching "A=".
// go test -run /A=1 # For all top-level tests, run subtests matching "A=1".
// go test -fuzz FuzzFoo # Fuzz the target matching "FuzzFoo"
//
// The -run argument can also be used to run a specific value in the seed
// corpus, for debugging. For example:
//
// go test -run=FuzzFoo/9ddb952d9814
//
// The -fuzz and -run flags can both be set, in order to fuzz a target but
// skip the execution of all other tests.
//
// Subtests can also be used to control parallelism. A parent test will only
// complete once all of its subtests complete. In this example, all tests are
// run in parallel with each other, and only with each other, regardless of
// other top-level tests that may be defined:
//
// func TestGroupedParallel(t *testing.T) {
// for _, tc := range tests {
// tc := tc // capture range variable
// t.Run(tc.Name, func(t *testing.T) {
// t.Parallel()
// ...
// })
// }
// }
//
// Run does not return until parallel subtests have completed, providing a way
// to clean up after a group of parallel tests:
//
// func TestTeardownParallel(t *testing.T) {
// // This Run will not return until the parallel tests finish.
// t.Run("group", func(t *testing.T) {
// t.Run("Test1", parallelTest1)
// t.Run("Test2", parallelTest2)
// t.Run("Test3", parallelTest3)
// })
// // <tear-down code>
// }
//
// # Main
//
// It is sometimes necessary for a test or benchmark program to do extra setup or teardown
// before or after it executes. It is also sometimes necessary to control
// which code runs on the main thread. To support these and other cases,
// if a test file contains a function:
//
// func TestMain(m *testing.M)
//
// then the generated test will call TestMain(m) instead of running the tests or benchmarks
// directly. TestMain runs in the main goroutine and can do whatever setup
// and teardown is necessary around a call to m.Run. m.Run will return an exit
// code that may be passed to os.Exit. If TestMain returns, the test wrapper
// will pass the result of m.Run to os.Exit itself.
//
// When TestMain is called, flag.Parse has not been run. If TestMain depends on
// command-line flags, including those of the testing package, it should call
// flag.Parse explicitly. Command line flags are always parsed by the time test
// or benchmark functions run.
//
// A simple implementation of TestMain is:
//
// func TestMain(m *testing.M) {
// // call flag.Parse() here if TestMain uses flags
// os.Exit(m.Run())
// }
//
// TestMain is a low-level primitive and should not be necessary for casual
// testing needs, where ordinary test functions suffice.