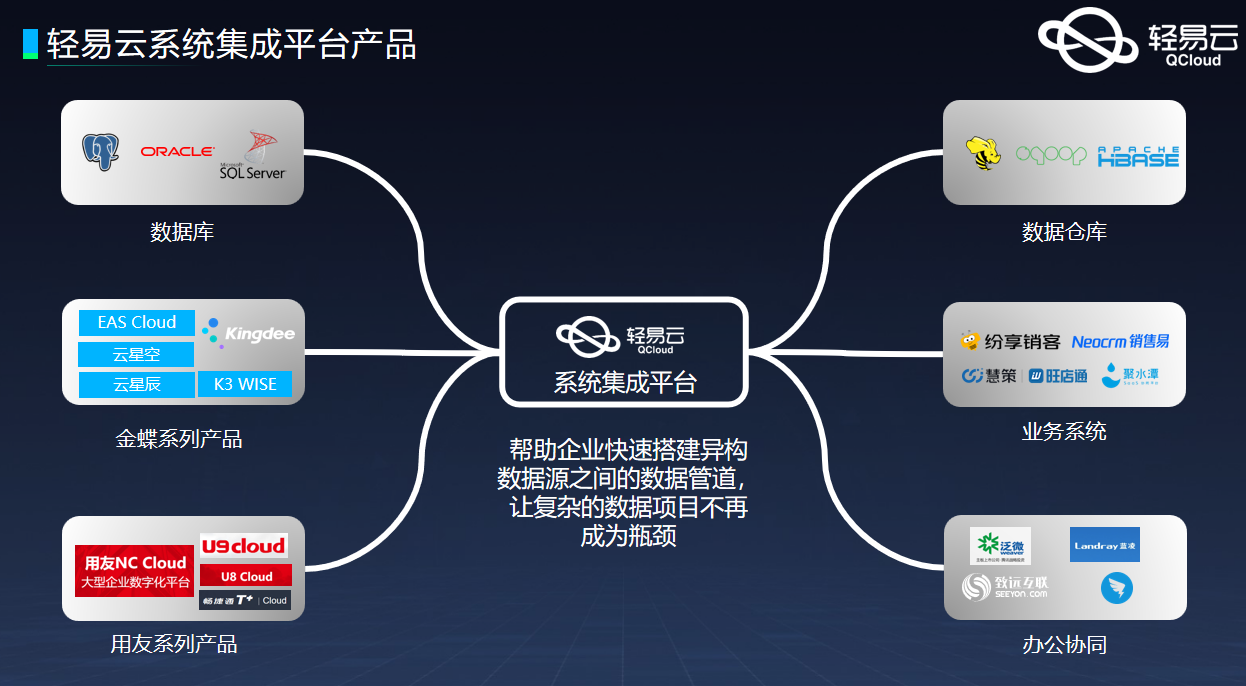
千呼万唤始出来,终于到多线程方面的学习了!
所用系统
Centos7.6本文的源码👉【传送门】
最近主要是在我的hexo个人博客上更新,csdn的更新会滞后
文章目录
- 1.线程的概念
- 1.1 执行流
- 1.2 线程创建时做了什么?
- 1.3 内核源码中的体现
- 1.4 线程的私有物
- 1.5 线程优缺点
- 1.5.1 缺点
- 1.5.2 优点
- 2.基础函数
- 2.1 pthread_create
- 2.2 pthread_join
- 2.2.1 基础的多线程操作
- 2.2.2 C++的多线程操作
- 2.3 线程退出
- 2.3.1 retval
- 2.3.2 pthread_exit
- 2.3.3 ptrhead_cancel
- 2.3.4 为什么进程退出不会向主进程发送信号?
- 2.3.5 exit
- 2.4 pthread_detach
- 2.4.1 实操
- 2.4.2 detach后join
- 2.4.3 线程分离后,主线程先退出
- 2.5 gettid/syscall
- 3.相关概念
- 3.1 线程id是什么?
- 3.2 pthread库
- 3.3 线程的局部存储
- 4.线程互斥问题
- 4.1 临界资源
- 4.2 原子/互斥性
- 4.3 线程加锁
- 4.3.1 pthread_mutex_init
- 4.3.2 加锁/解锁
- 4.3.3 加锁的注意事项
- 4.4 示例-倒水问题
- 4.4.1 只有一个线程在工作?
- 4.4.2 加锁-问题解决
- 4.5 加锁的进一步解释
- 4.5.1 加锁原子性的保证
- 4.5.2 总线锁
- 5.死锁
- 5.1 死锁情况演示
- 5.2 死锁的条件
- 5.3 避免死锁
- 6.线程安全
1.线程的概念
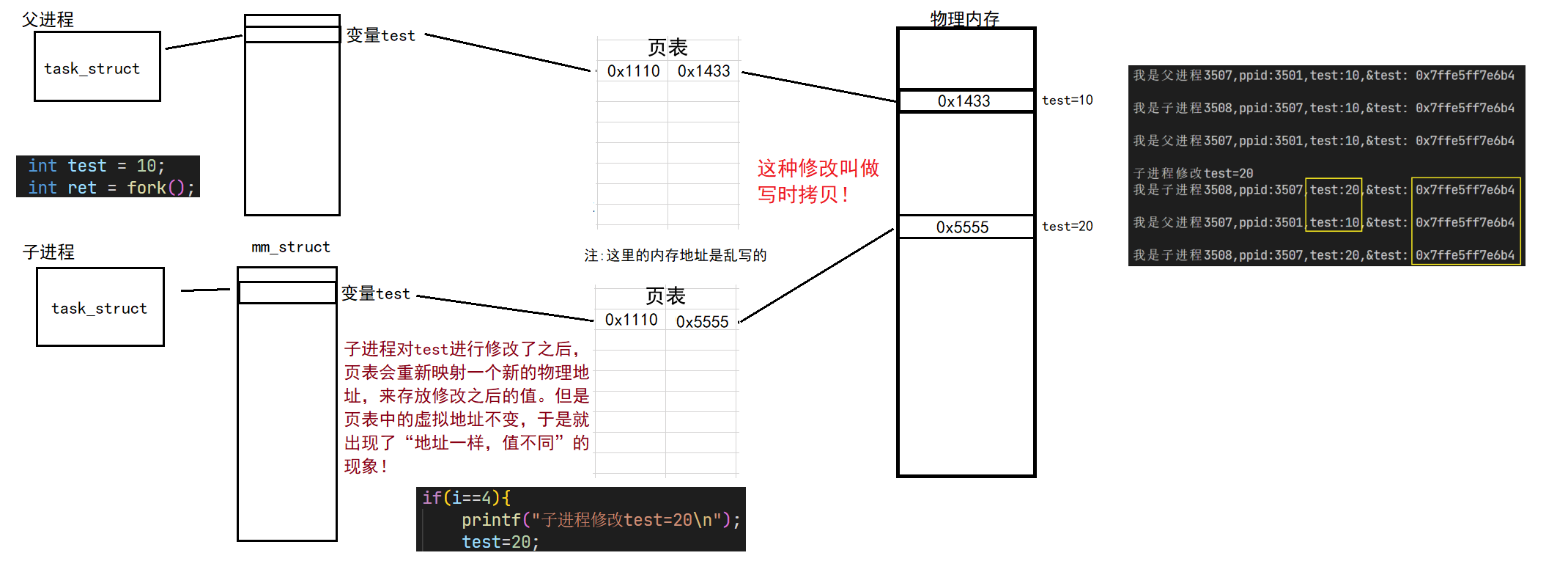
在之前的linux学习中,已经接触过了进程的概念,进程由一个task_struct结构体在操作系统中进行描述,CPU在执行的时候,会依照进程时间片进行轮询调度,让每一个进程的代码都得以推进,实现多个进程的同时运行
而线程,可以理解为是一种轻量化的进程,每一个进程都可以创建多个线程,并行执行不同的代码
进程:线程 = 1:N
在之前的多进程操作中,我们使用fork接口创建子进程,通过if/else语句判断,实现对特定执行流的划分
- 创建子进程时,需要拷贝一份
task_struct/mm_struct并创建页表 - 当子进程修改了一部分变量,会发生写时拷贝,修改页表在物理内存上的映射
可以看到,当我们需要创建一个新进程的时候,操作系统需要做不少的工作
1.1 执行流
让我们康康执行流这一概念:
- 单执行流进程:内部只有一个执行流的进程
- 多执行流进程:内部有多个执行流的进程
进程=内核数据结构+代码和数据,在内核视角中,进程是承担分配系统资源的基本实体(进程的基座属性)
- 进程:向系统申请资源的基本单位(系统分配)
- 线程:系统调度的基本单位
1.2 线程创建时做了什么?
那线程的创建需要做什么呢?
不同操作系统的实现不同,一般用
tcb指代描述线程的结构体
在linux中,没有进程和线程在概念上的区分,其以执行流为基础,线程只是简单的对task_strcut进行了二次封装;线程是在进程内部运行的执行流
- 说人话:linux下的线程是用进程模拟的
- 换句话:linux下的进程也是一种线程,但是其只有一个执行流
- 对于CPU而言,其看到的
task_struct都是一个执行流
而创建线程时也有说法,线程隶属于某一个进程下,并不是独立的子进程,所以不需要创建新的mm_struct和页表映射,创建的效率高于子进程。只需要将task_struct指向原有进程的mm_struct和页表即可。
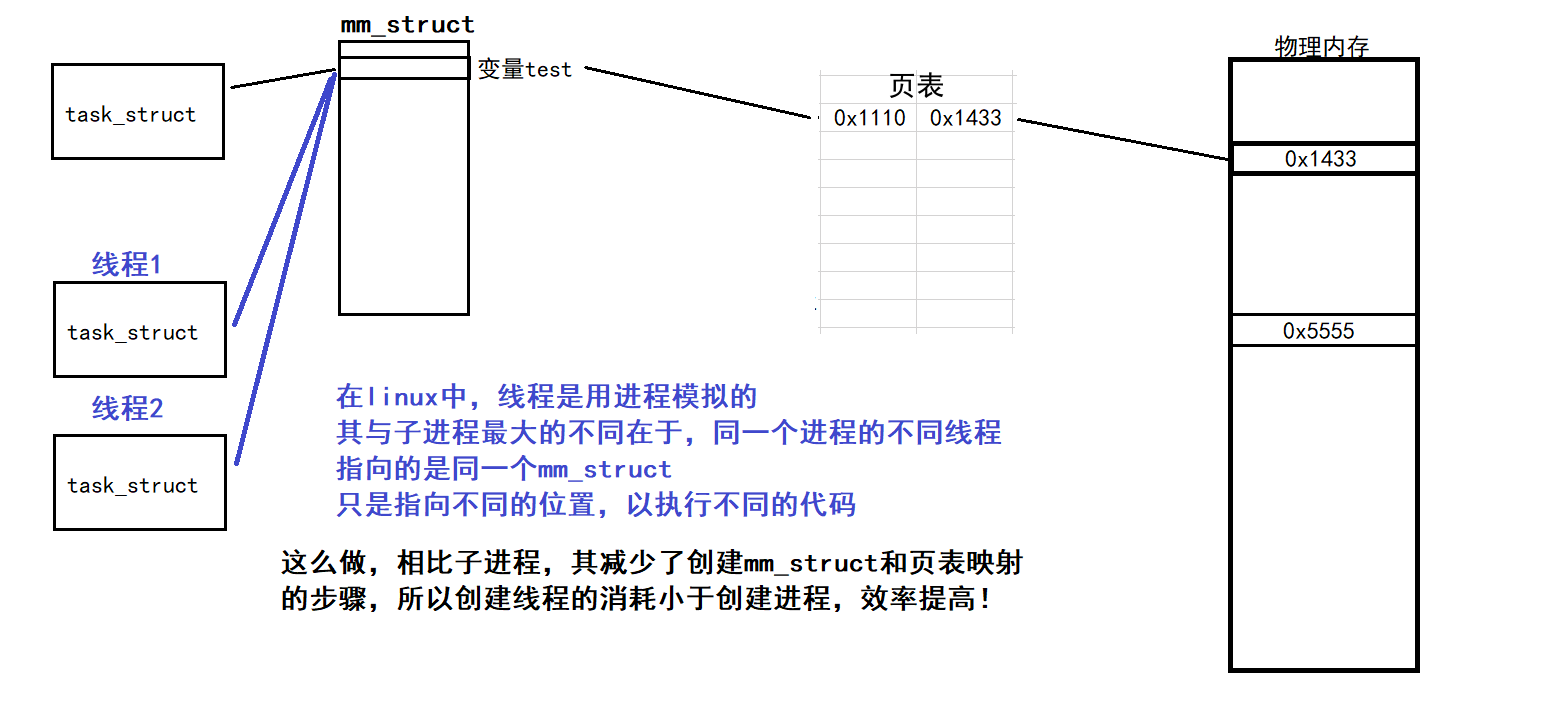
同样的,CPU在推行多线程操作的时候,无须执行pcb切换,就能实现单进程多个线程操作的同时进行,执行效率变高!
线程是一种
Light weight process 轻量级进程,简称LWP
1.3 内核源码中的体现
在task_strcut结构体中,有这么一个字段
/* CPU-specific state of this task */
struct thread_struct thread;
转到定义,其内部都是一些寄存器信息,用于标识这个线程的基本信息。这也是linux中没有单独实现线程tcb的体现,而是用task_struct来模拟的
struct thread_struct {
/* Cached TLS descriptors: */
struct desc_struct tls_array[GDT_ENTRY_TLS_ENTRIES];
unsigned long sp0;
unsigned long sp;
#ifdef CONFIG_X86_32
unsigned long sysenter_cs;
#else
unsigned long usersp; /* Copy from PDA */
unsigned short es;
unsigned short ds;
unsigned short fsindex;
unsigned short gsindex;
#endif
#ifdef CONFIG_X86_32
unsigned long ip;
#endif
#ifdef CONFIG_X86_64
unsigned long fs;
#endif
unsigned long gs;
/* Hardware debugging registers: */
unsigned long debugreg0;
unsigned long debugreg1;
unsigned long debugreg2;
unsigned long debugreg3;
unsigned long debugreg6;
unsigned long debugreg7;
/* Fault info: */
unsigned long cr2;
unsigned long trap_no;
unsigned long error_code;
/* floating point and extended processor state */
union thread_xstate *xstate;
#ifdef CONFIG_X86_32
/* Virtual 86 mode info */
struct vm86_struct __user *vm86_info;
unsigned long screen_bitmap;
unsigned long v86flags;
unsigned long v86mask;
unsigned long saved_sp0;
unsigned int saved_fs;
unsigned int saved_gs;
#endif
/* IO permissions: */
unsigned long *io_bitmap_ptr;
unsigned long iopl;
/* Max allowed port in the bitmap, in bytes: */
unsigned io_bitmap_max;
/* MSR_IA32_DEBUGCTLMSR value to switch in if TIF_DEBUGCTLMSR is set. */
unsigned long debugctlmsr;
/* Debug Store context; see asm/ds.h */
struct ds_context *ds_ctx;
};
1.4 线程的私有物
我们知道,一个进程是完全独立的。但是线程并不是,因为线程只是进程的一个执行流分支,它从进程继承了绝大部分属性(也可以理解为是共享的)
- 用户id和组id
- 进程id
- 进程工作目录
- 文件描述符表
- 信号的处理方式(如果进程有对某个信号进行自定义捕捉,那么线程会共用这个自定义捕捉)
- 和进程共用一个堆
但线程也会有自己的私有物!
- 线程id
- 线程独立的寄存器(因为线程也需要执行代码,有上下文数据)
- 栈(线程运行函数时也需要压栈和出栈,必须独立否则执行流会出问题)
- errno(单独的报错信息)
- 信号屏蔽字(可以单独针对某个信号处理)
- 线程调度优先级
1.5 线程优缺点
1.5.1 缺点
-
线程是缺乏保护的(不具备进程的独立性)这也被称为
健壮性;线程的健壮性低- 当进程被停止的时候,其下线程也会被停止
- 当有一个线程出bug了,会让整个进程退出
- 多线程中的全局变量问题
-
线程缺乏访问控制,在一个线程中调用某些操作系统的接口会影响整个进程
-
debug多线程较麻烦
-
如果同一个进程所用线程太多,可能会无法充分利用cpu性能而造成性能损失
1.5.2 优点
- 开辟的消耗低于进程,占用的资源低于进程
- 切换线程无须切换页表等结构,速度快
- 等待慢IO设备时,进程可以继续执行其他操作;将部分IO操作重叠,能让进程同时等待多个IO操作
- 能充分利用处理器的可并行数量
2.基础函数
linux下提供了pthread库来实现线程操作
2.1 pthread_create
人如其名,这个函数的作用是来创建新进程的
#include <pthread.h>
int pthread_create(pthread_t *thread, const pthread_attr_t *attr,
void *(*start_routine) (void *), void *arg);
//Compile and link with -pthread.
- 第一个参数是一个输出型参数,为该线程的id
- 第二个参数是用于指定线程的属性,暂时设置为
NULL使用默认属性 - 第三个参数是让该进程执行的函数,这是一个函数指针,参数和返回值都为
void* - 第四个参数是传给第三个执行函数的参数
创建正常后返回0,否则返回错误码
注意,使用了pthread库后,需要在编译的时候指定链接,-lpthread
typedef unsigned long int pthread_t;//线程id
创建线程后打印可以发现,线程id是一个非常大的值,并不像进程PID那么小
//cout << "pthread_create "<< t1 << " " << t2 << endl;
pthread_create 140689524995840 140689516603136
可以通过printf %x的方式来减少打印长度
//printf("0x%x 0x%x\n",t1,t2);
0x393d0700 0x38bcf700
2.2 pthread_join
光是创建进程还不够,我们还需要对进程进行等待
#include <pthread.h>
int pthread_join(pthread_t thread, void **retval);
//Compile and link with -pthread.
这里第一个参数是线程的id,第二个参数是进程的退出状态
等待成功后返回0,否则返回错误码
- join可以在线程退出后,释放线程的资源
- 同时获取线程对应的退出码
- join还能保证是新创建的线程退出后,主线程才退出
2.2.1 基础的多线程操作
有了这两个,我们就能写一个简单的多线程操作了
#include<iostream>
#include<pthread.h>
#include<unistd.h>
#include<sys/types.h>
using namespace std;
void* func1(void* arg)
{
while(1)
{
cout << "func1 thread:: " << (char*)arg << " :: " << getpid() << endl;
sleep(1);
}
}
void* func2(void* arg)
{
while(1)
{
cout << "func2 thread:: " << (char*)arg << " :: " << getpid() << endl;
sleep(1);
}
}
int main()
{
pthread_t t1,t2;
pthread_create(&t1,nullptr,func1,(void*)"1");
pthread_create(&t2,nullptr,func2,(void*)"2");
while(1)
{
cout << "this is main::" << getpid()<<endl;
sleep(1);
}
pthread_join(t1,nullptr);
pthread_join(t2,nullptr);
return 0;
}
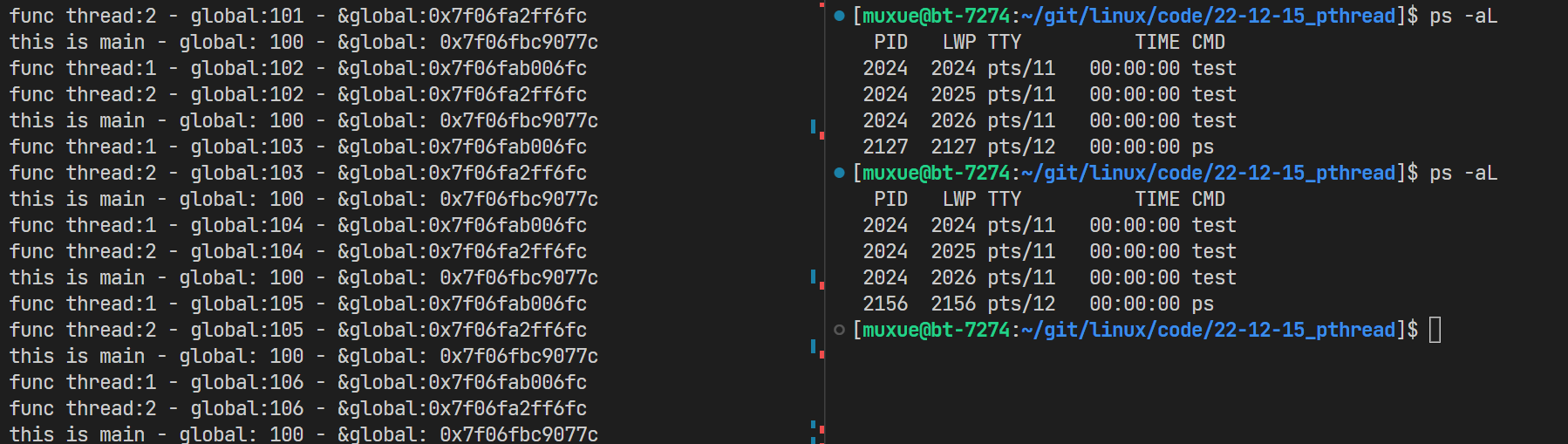
执行会发现,多线程操作成功启动,且打印的进程pid都是一样的,代表其隶属于同一个进程
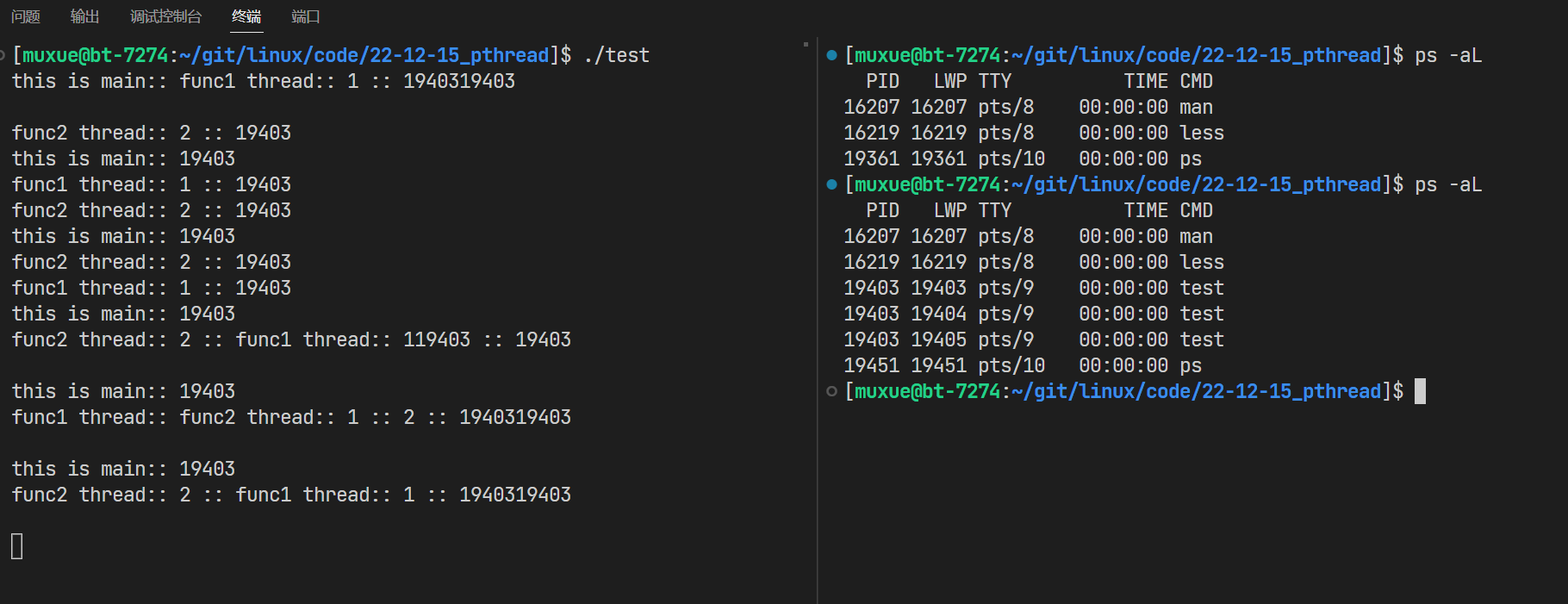
我们可以用下面的语句来查看轻量级进程
ps -aL
可以看到,执行了程序之后,出现了3个PID相同,LWP不同的轻量级进程,这就代表我们的多线程操作成功了;
同时也能看到,在多线程操作时,谁先运行是不确定的。这是由系统调度随机决定的
2.2.2 C++的多线程操作
C++11也支持了多线程操作,其封装了操作系统的pthread接口,基本的操作很相似
void test2()
{
thread t1(func1,(char*)"test1");
thread t2(func2,(char*)"test2");
while(1)
{
cout << "this is main:: " << getpid()<<endl;
sleep(1);
}
t1.join();
t2.join();
}
执行后的效果是一样的,C++的thread库还可以传入functional封装的可调用函数,和lambda表达式
2.3 线程退出
2.3.1 retval
int pthread_join(pthread_t thread, void **retval);
我们可以使用该函数的第二个参数来获取线程所执行方法的返回值。retval是一个二级指针,是一个输出型参数
#include<iostream>
#include<pthread.h>
#include<thread>
#include<unistd.h>
#include<sys/types.h>
using namespace std;
void* func1(void* arg)
{
int a = 5;
while(a--)
{
cout << "func1 thread:: " << (char*)arg << " :: " << getpid() << endl;
sleep(1);
}
cout << "func1 exit" << endl;
return (void*)100;
}
void* func2(void* arg)
{
int a = 10;
while(a--)
{
cout << "func2 thread:: " << (char*)arg << " :: " << getpid() << endl;
sleep(1);
}
cout << "func2 exit" << endl;
return (void*)10;
}
void test3()
{
pthread_t t1,t2;
pthread_create(&t1,nullptr,func1,(void*)"1");
pthread_create(&t2,nullptr,func2,(void*)"2");
int a = 15;
while(a--)
{
cout << "this is main:: " << getpid()<<endl;
sleep(1);
}
void* r1;
void* r2;
pthread_join(t1,&r1);
pthread_join(t2,&r2);
sleep(2);
cout << "retval 1 : " << (long long)r1 << endl;
cout << "retval 2 : " << (long long)r2 << endl;
}
int main()
{
test3();
return 0;
}
可以看到,当两个线程退出之后,主函数中成功打印出了他们的返回值
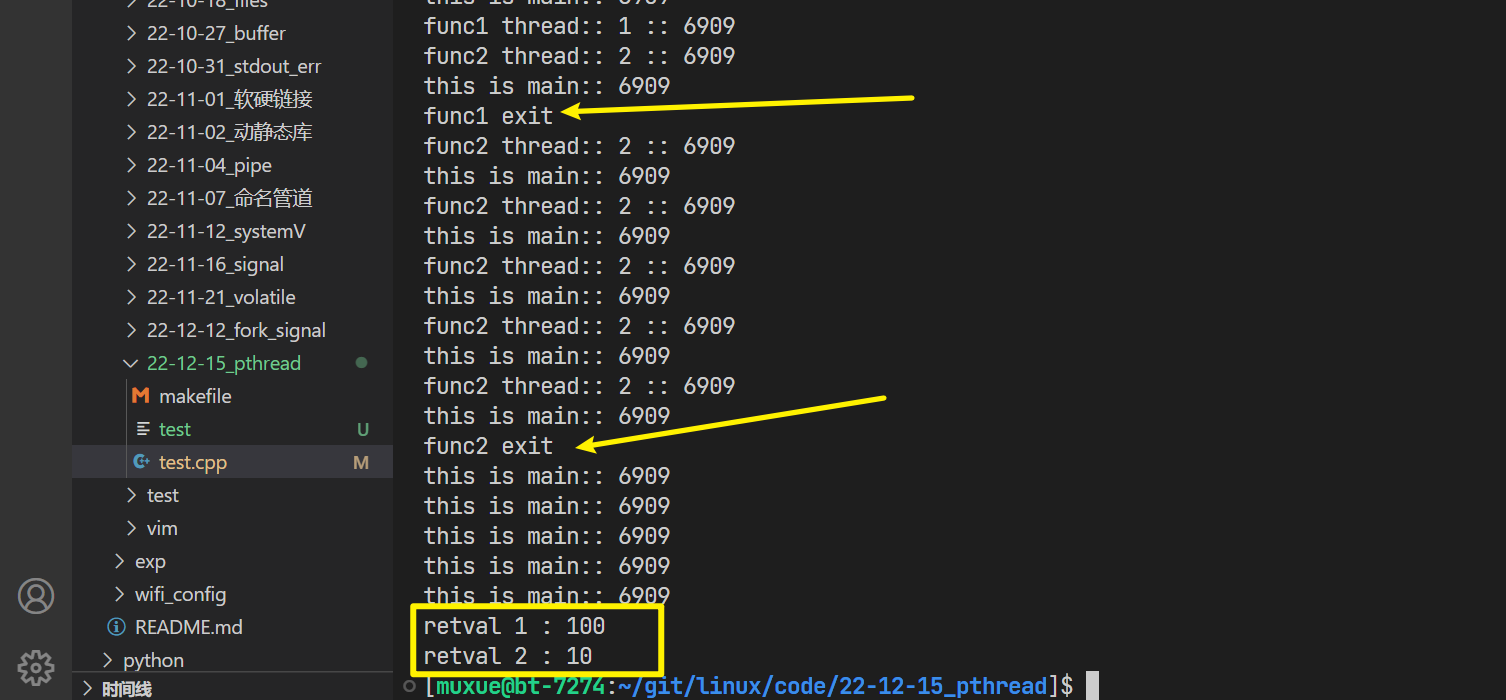
注意,因为我们是将void*的指针强转为int,如果在打印的时候强转为int,会出现精度丢失的报错,需要使用long long来规避报错
[muxue@bt-7274:~/git/linux/code/22-12-15_pthread]$ make
g++ test.cpp -o test -lpthread -std=c++11
.test.cpp: In function ‘void test3()’:
test.cpp:88:35: error: cast from ‘void*’ to ‘int’ loses precision [-fpermissive]
cout << "retval 1 : " << (int)r1 << endl;
^
make: *** [test] Error 1
2.3.2 pthread_exit
除了直接return,线程还可以调用pthread_exit函数实现退出
#include <pthread.h>
void pthread_exit(void *retval);
//Compile and link with -pthread.
效果完全一样
//return (void*)10;
pthread_exit((void*)10);
注意,主线程main中调用该函数,并不会导致进程退出
void* func2(void* arg)
{
int a = 10;
while(a--)
{
cout << "func2 thread:: " << (char*)arg << " :: " << getpid() << " tid: " << syscall(SYS_gettid) << endl;
sleep(1);
}
cout << "func2 exit" << endl;
pthread_exit((void*)10);
}
void test5()
{
pthread_t t1,t2;
//func2会执行10s
pthread_create(&t1,nullptr,func2,(void*)"1");
pthread_create(&t2,nullptr,func2,(void*)"2");
sleep(1);
pthread_detach(t1);
pthread_detach(t2);
sleep(1);
}
int main()
{
test5();
pthread_exit(0);//主线程提前退出
cout << "main exit" << endl;
return 0;
}
可以看到,主函数已经调用了pthread_exit退出了,但是线程还在跑
[muxue@bt-7274:~/git/linux/code/22-12-15_pthread]$ ./test
func2 thread:: 1 :: 9474 tid: 9475
func2 thread:: 2 :: 9474 tid: 9476
func2 thread:: 1 :: 9474 tid: 9475
func2 thread:: 2 :: 9474 tid: 9476
main exit
func2 thread:: 1 :: 9474 tid: 9475
func2 thread:: 2 :: 9474 tid: 9476
2.3.3 ptrhead_cancel
除了上面俩种方式,我们还可以在main里面直接把某一个线程给关掉
#include <pthread.h>
int pthread_cancel(pthread_t thread);
//Compile and link with -pthread.
void test3()
{
pthread_t t1,t2;
pthread_create(&t1,nullptr,func1,(void*)"1");
pthread_create(&t2,nullptr,func2,(void*)"2");
int a = 15;
while(a--)
{
cout << "this is main:: " << getpid()<<endl;
sleep(1);
if(a==11)
{
pthread_cancel(t1);
pthread_cancel(t2);
break;
}
}
void* r1;
void* r2;
pthread_join(t1,&r1);
pthread_join(t2,&r2);
sleep(2);
cout << "retval 1 : " << (long long)r1 << endl;
cout << "retval 2 : " << (long long)r2 << endl;
}
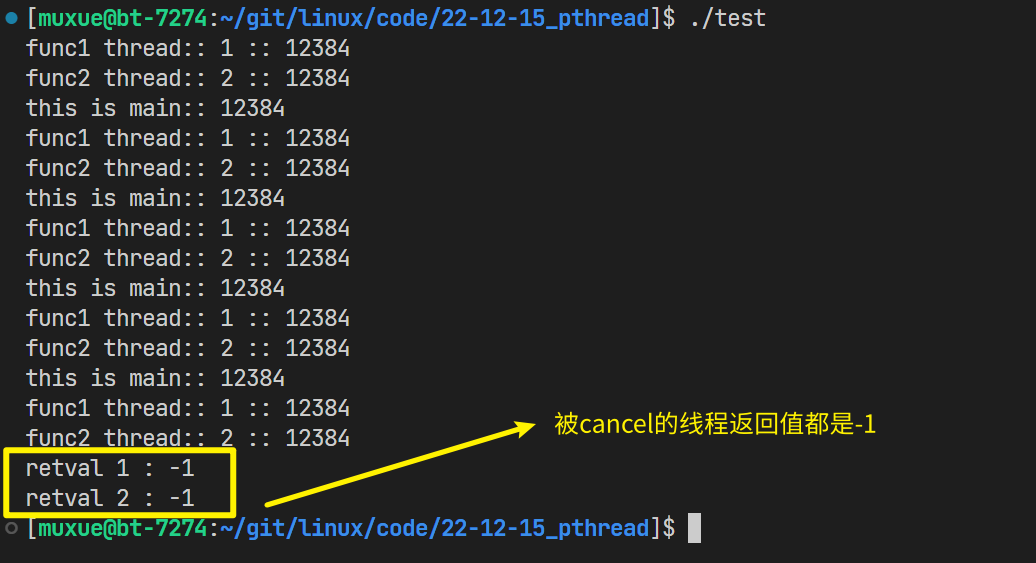
被提前终止的进程,返回值都为-1
2.3.4 为什么进程退出不会向主进程发送信号?
要理清楚这个问题,还是需要深知一个概念:线程是进程中的一个执行流,它并不是一个独立的进程。
先来回顾一下进程退出的几种情况:
- 代码跑完,结果正确
- 代码跑完,结果有问题
- 代码出错了,异常
线程退出的情况也是这样,但线程如果因为某些异常退出,进程也会同步退出!
[muxue@bt-7274:~/git/linux/code/22-12-15_pthread]$ ./test
this is main:: 13845
Floating point exception
[muxue@bt-7274:~/git/linux/code/22-12-15_pthread]$
由此可见,线程异常 = 进程异常
这里也就涉及到1.5.1中提到的线程健壮性问题,线程的异常会影响其他线程的运行,会导致进程整体异常退出。
所以在join等待线程退出的时候,我们只需要考虑线程正常退出的情况;
异常退出的时候恐怕也等不了😂因为进程也挂了
2.3.5 exit
任何一个线程执行exit()函数,都会导致整个进程退出
2.4 pthread_detach
等待是有性能损失的!默认创建的进程是joinable,也就是可以被主线程进行pthread_join等待的;
这个函数的作用是让主线程不管创建出来的子线程,也不用去等待它,相当于取消了它的joinable属性;
就好比父进程不想管子进程的时候,将SIGCHLD设置为SIG_IGN
#include <pthread.h>
int pthread_detach(pthread_t thread);
//Compile and link with -pthread.
一个线程是否应该等待,取决于是否需要获取该线程的返回值;如果无须获取返回值,则使用分离能提高运行效率
2.4.1 实操
使用也很简单,只需要指定线程的id就行了
void test4()
{
pthread_t t1,t2;
pthread_create(&t1,nullptr,func3,(void*)"1");
pthread_create(&t2,nullptr,func3,(void*)"2");
while(1)
{
cout << "this is main - global: " << global << " - &global: " << &global << endl;
sleep(1);
}
pthread_detach(t1);
pthread_detach(t2);
}
运行上也不会有什么区别,但是我们已无法获取到该线程的返回值
2.4.2 detach后join
但如果我们在detach之后又进行pthread_join会发生什么呢?
void* func3(void* arg)
{
pthread_detach(pthread_self());
int a = 7;
while(a--)
{
printf("func thread:%s - global:%d - &global:%p\n",(char*)arg,global,&global);
global++;
sleep(1);
}
cout << "func exit" << endl;
return (void*)10;
}
void test4()
{
pthread_t t1,t2;
pthread_create(&t1,nullptr,func3,(void*)"1");
pthread_create(&t2,nullptr,func3,(void*)"2");
void* r1=nullptr;
void* r2=nullptr;
pthread_join(t1,&r1);
pthread_join(t2,&r2);
sleep(2);
cout << "retval 1 : " << (long long)r1 << endl;
cout << "retval 2 : " << (long long)r2 << endl;
}
诶,这不还是获取到了返回值吗?这么说,他这个detach岂不是没用?
[muxue@bt-7274:~/git/linux/code/22-12-15_pthread]$ ./test
func thread:1 - global:103 - &global:0x7fb5648b06fc
func thread:2 - global:103 - &global:0x7fb5640af6fc
func thread:1 - global:104 - &global:0x7fb5648b06fc
func thread:2 - global:104 - &global:0x7fb5640af6fc
func exit
func exit
retval 1 : 10
retval 2 : 10
[muxue@bt-7274:~/git/linux/code/22-12-15_pthread]$
实际上,当我们create一个线程的时候,它会先去执行线程创建的相关代码,此时main又直接去执行后面的代码了;此时pthread_join的调用是成功的,因为线程自己的detach代码还没有被执行!
而如果我们在create之后,等线程开始运行了在执行detach,此时join就会失败
void test4()
{
pthread_t t1,t2;
pthread_create(&t1,nullptr,func3,(void*)"1");
pthread_create(&t2,nullptr,func3,(void*)"2");
sleep(2);
pthread_detach(t1);
pthread_detach(t2);
sleep(1);
void* r1=nullptr;
void* r2=nullptr;
int ret = pthread_join(t1,&r1);
cout << ret << ":" << strerror(ret) << endl;
ret = pthread_join(t2,&r2);
cout << ret << ":" << strerror(ret) << endl;
cout << "retval 1 : " << (long long)r1 << endl;
cout << "retval 2 : " << (long long)r2 << endl;
sleep(20);
}
打印错误码也能看到,系统提示我们给join传入了一个无效的参数,线程依旧在正常运行
[muxue@bt-7274:~/git/linux/code/22-12-15_pthread]$ ./test
func thread:1 - global:101 - &global:0x7f2d439136fc
func thread:2 - global:101 - &global:0x7f2d431126fc
func thread:2 - global:102 - &global:0x7f2d431126fc
func thread:1 - global:102 - &global:0x7f2d439136fc
22:Invalid argument
22:Invalid argument
retval 1 : 0
retval 2 : 0
func thread:2 - global:103 - &global:0x7f2d431126fc
func thread:1 - global:103 - &global:0x7f2d439136fc
所以正确的做法,应该是在主线程中分离线程,不要在线程自己的代码中执行detach,否则就会出现上面的分离失败的情况
2.4.3 线程分离后,主线程先退出
如果执行完毕pthread_detach后,主线程提前退出了,会发生什么?
void test5()
{
pthread_t t1,t2;
pthread_create(&t1,nullptr,func3,(void*)"1");
pthread_create(&t2,nullptr,func3,(void*)"2");
sleep(1);
pthread_detach(t1);
pthread_detach(t2);
sleep(2);
cout << "main exit" << endl;
}
显而易见,线程也跟着一并退出了
[muxue@bt-7274:~/git/linux/code/22-12-15_pthread]$ ./test
func thread:1 - global:100 - &global:0x7f01cd49a6fc
func thread:2 - global:100 - &global:0x7f01ccc996fc
func thread:2 - global:101 - &global:0x7f01ccc996fc
func thread:1 - global:101 - &global:0x7f01cd49a6fc
func thread:2 - global:102 - &global:0x7f01ccc996fc
func thread:1 - global:102 - &global:0x7f01cd49a6fc
main exit
[muxue@bt-7274:~/git/linux/code/22-12-15_pthread]$
因为线程没有独立性,完全属于这个进程。不可能出现你家房子塌了,你自己的房间还在的情况😂
进程退出的时候,操作系统就回收了这个进程的程序地址空间,连资源都被释放了,线程就没有办法继续运行,自然就退出了。
所以,为了避免这种问题,一般我们分离线程的时候,都倾向于让主线程保持在后台运行(常驻内存的程序)
2.5 gettid/syscall
该函数是一个系统接口,但它并不能直接运行
NAME
gettid - get thread identification
SYNOPSIS
#include <sys/types.h>
pid_t gettid(void);
Note: There is no glibc wrapper for this system call; see
NOTES.
我们需要用syscall函数来调用该接口,这也是第一次接触到syscall函数
#define _GNU_SOURCE /* See feature_test_macros(7) */
#include <unistd.h>
#include <sys/syscall.h> /* For SYS_xxx definitions */
int syscall(int number, ...);
在syscall的man手册中,我们就能看到获取线程id相关的示例
//EXAMPLE
#define _GNU_SOURCE
#include <unistd.h>
#include <sys/syscall.h>
#include <sys/types.h>
int main(int argc, char *argv[])
{
pid_t tid;
tid = syscall(SYS_gettid);
tid = syscall(SYS_tgkill, getpid(), tid);
}
用下面的代码进行测试
void* func2(void* arg)
{
int a = 10;
while(a--)
{
cout << "func2 thread:: " << (char*)arg << " :: " << getpid() << " tid: " << syscall(SYS_gettid) << endl;
sleep(1);
}
cout << "func2 exit" << endl;
pthread_exit((void*)10);
}
void test1()
{
pthread_t t1,t2;
pthread_create(&t1,nullptr,func2,(void*)"1");
pthread_create(&t2,nullptr,func2,(void*)"2");
while(1)
{
printf("tis is main - pid:%d - tid:%d\n",getpid(),syscall(SYS_gettid));
sleep(1);
}
pthread_join(t1,nullptr);
pthread_join(t2,nullptr);
}
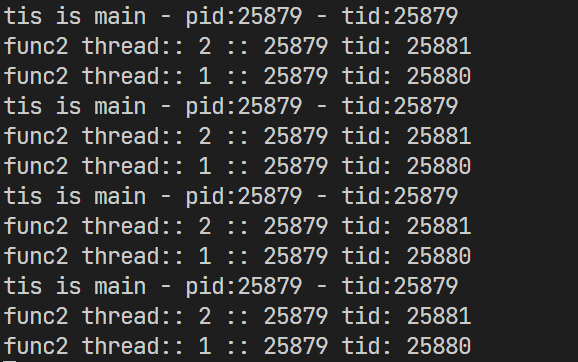
运行可以看到进程打印出了相同的PID和不同的TID,其TID对应的就是ps -aL中显示的LWP编号
3.相关概念
3.1 线程id是什么?
前面提到过,pthread_t是线程独立的id,本质上是一个无符号长整形,打印出来后,是一个很大的数字。这个数字有什么特别的含义吗?
先来回顾一下线程的基本概念:
- 线程是一个独立的执行流
- 线程在运行过程中,会产生自己的临时数据
- 线程调用函数的压栈出栈操作,有自己独立的栈结构
因此,既然有一个独立的栈结构,其就需要有一个标识符来指向这个栈结构,方便程序运行的时候进行调用!
所以,pthread_t本质上是一个地址!其指向的就是这个线程的控制块,其内部包含了这个线程的独立栈结构。
//printf("0x%x 0x%x\n",t1,t2);
0x393d0700 0x38bcf700 //打印出来的结果也很像地址
3.2 pthread库
pthread库并不是一个内核级的接口库,其实际上是封装了系统的clone/vfork等接口,从而为我们提供的用户级的线程库。
使用pthread库创建的进程,和内核中的LWP是1:1的

pthread是一个动态库,所以在编译的时候需要加上链接选项
g++ test.cpp -o test -lpthread
在我的 动静态库 的博客中有讲述过,动态库是在运行的时候动态链接的,其会将库中的代码映射到进程地址空间的共享区,从而调用动态库中的代码
举个例子,当我们调用
pthead_create的时候,进程会跳到共享区中,执行动态库中的代码,创建成功后返回自己的代码区,完成一个线程的创建
而线程所用的独立栈,也是pthread库帮我们管理的。因为有共享区的存在,我们能通过pthread_t直接访问到动态库中管理的线程的控制模块,从而完成线程的压栈、出栈等等操作
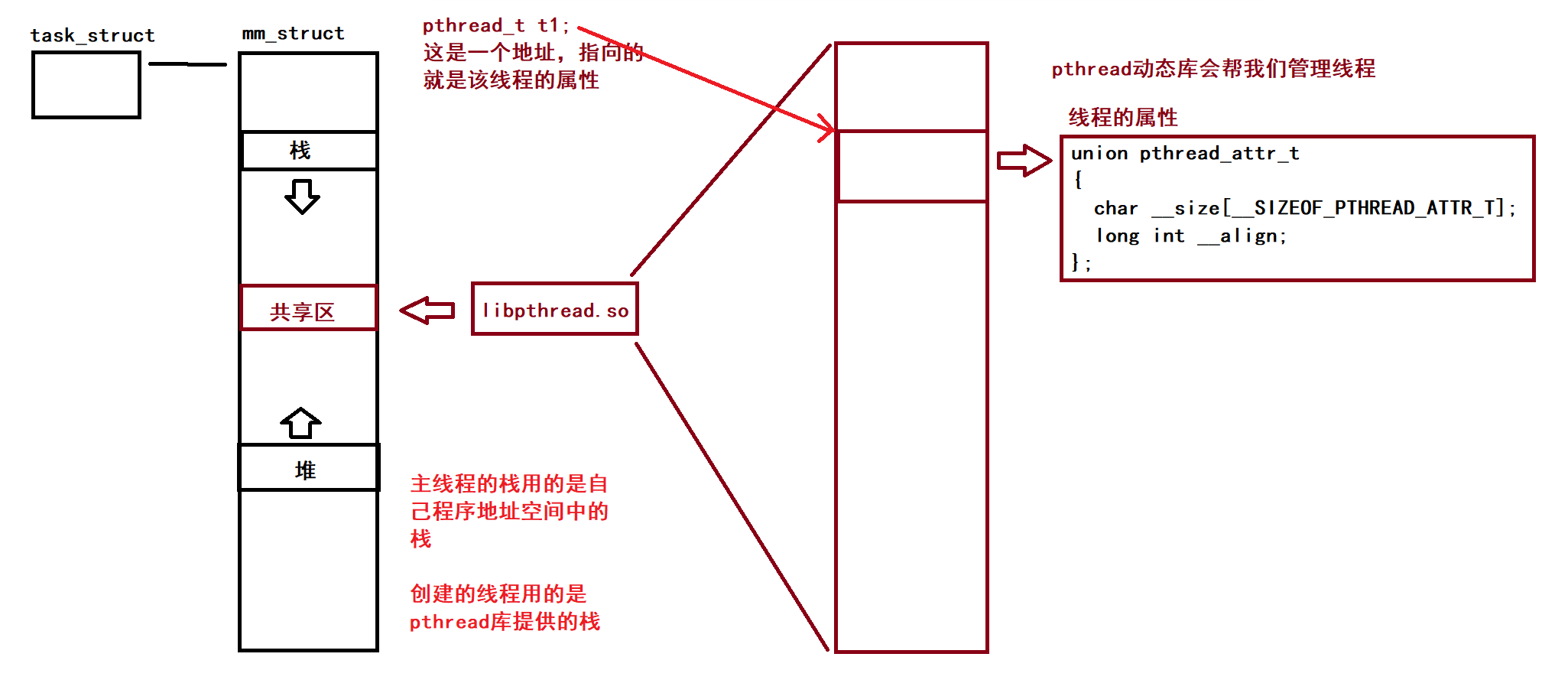
下为linux的pthreadtypes.h中的部分内容
# define __SIZEOF_PTHREAD_ATTR_T 36
typedef unsigned long int pthread_t;
union pthread_attr_t
{
char __size[__SIZEOF_PTHREAD_ATTR_T];
long int __align;
};
#ifndef __have_pthread_attr_t
typedef union pthread_attr_t pthread_attr_t;
# define __have_pthread_attr_t 1
#endif
3.3 线程的局部存储
假设我们有一个全局变量,我们想让创建出来的每一个线程,都能独立的使用这个全局变量,那就需要用到线程的局部存储
int global = 10;//全局变量
void* func3(void* arg)
{
int a = 10;
while(a--)
{
cout << "func thread " << (char*)arg << " - global: " << global << " - &global: " << &global << endl;
sleep(1);
}
cout << "func exit" << endl;
}
void test4()
{
pthread_t t1,t2;
pthread_create(&t1,nullptr,func3,(void*)"1");
pthread_create(&t2,nullptr,func3,(void*)"2");
while(1)
{
cout << "this is main - global: " << global << " - &global: " << &global << endl;
sleep(1);
}
pthread_join(t1,nullptr);
pthread_join(t2,nullptr);
}
执行,不管是主线程还是线程,都打印的是相同的值和地址
如果在执行的函数func3中添加一个global++,则能观察到所有线程都是公用的一个变量,这里的+是同步的。
如果我们想让int global变成局部变量,则需要在它之前加上一个__thread
__thread int global = 100;//可以让线程独立使用的全局变量
此时可以看到,两个线程和主线程打印的global变量地址不同,他们的++操作是独立的,变量的值也是独立的
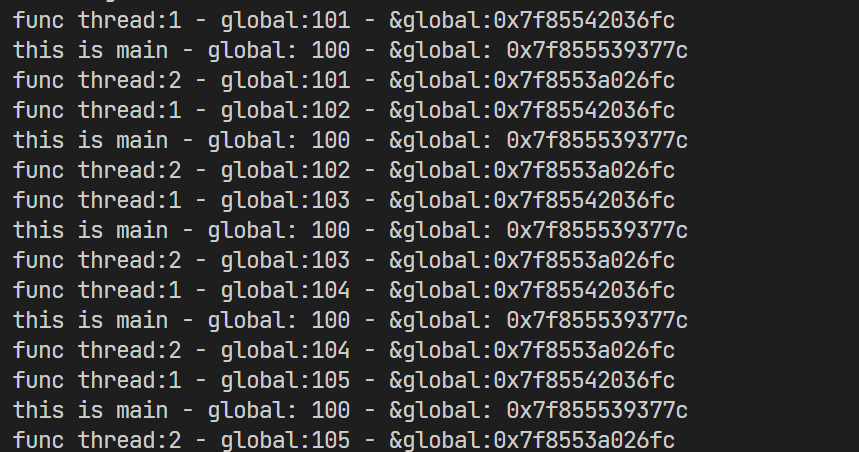
这就实现了将某一个变量划分给线程进行局部存储
4.线程互斥问题
4.1 临界资源
在先前共享内存 信号量的博客中,已经涉及到了这部分的内容;即关于操作原子性和访问临界资源/临界区的相关问题。
- 能被多个进程/线程看到的资源,被称为
临界资源 - 进程/线程访问临界资源的代码,被称为
临界区
在线程中,同样存在访问临界资源而导致的冲突:
- 线程A对一个全局变量val进行了
-1操作,当操作执行到放回内存那一步的时候,发生了线程切换,线程B开始工作 - 线程B同样访问了该全局变量val,对它进行了
-10操作,此时因为线程A的-1操作尚未写回内存,全局变量val还是保持初值。线程b将-10之后的全局变量val写回了内存 - 又发生了线程切换,跳转到线程A停止的线程上下文数据中开始执行,将全局变量写入内存
- 这时候,线程B的
-10操作就被A的写入覆盖了!
举个实际点的例子,以100为全局变量的初始值
- 线程A执行-1,
100-1=99,还未写入内存时,就线程切换 - 线程B取到的全局变量还是100,对其执行-10,并写入内存, 此时全局变量为90
- 返回线程A继续执行写入内存操作,全局变量又被复写成了99;相当于B的操作是无效的
这种条件下会产生很多问题,也是我们不希望看到的!
4.2 原子/互斥性
这种时候,我们就需要保证访问该全局变量的操作是原子的,不能出现中间状态;
也应该是互斥的,不能出现两个线程同时访问一份资源的情况
互斥性:任何时候都只有一个执行流在访问某一份资源

为了达成这一目的,我们需要给线程的操作加锁
4.3 线程加锁
线程加锁涉及到几个操作:
- 提供一把锁
- 在需要维持原子性(临界区)的位置加上锁
- 访问临界区结束后,打开锁
- 进程结束后,把锁丢了
接下来就让我们一一解决这些问题
4.3.1 pthread_mutex_init
pthread在设计之初就考虑到了这种问题,所以它便给我们提供了加锁相关的操作
#include <pthread.h>
int pthread_mutex_destroy(pthread_mutex_t *mutex);
int pthread_mutex_init(pthread_mutex_t *restrict mutex,
const pthread_mutexattr_t *restrict attr);
pthread_mutex_t mutex = PTHREAD_MUTEX_INITIALIZER;
首先我们需要定义一把锁,类型是pthread_mutex_t
- 如果我们需要的是一把全局变量的锁,则可以直接使用
PTHREAD_MUTEX_INITIALIZER给这把锁初始化 - 如果是一把局部的锁,则使用函数
pthread_mutex_init进行初始化
初始化的方法很简单,传入锁和对应的属性就行。此时我们忽略属性问题,设置为NULL使用默认属性
//使用默认属性的全局锁or静态static锁
//无须调用函数初始化,可以直接用
pthread_mutex_t mutex = PTHREAD_MUTEX_INITIALIZER;
//使用函数进行初始化局部的锁(当然也可以初始化全局锁)
pthread_mutex_t mutex;//定义一把锁
pthread_mutex_init(&mutex, nullptr);//初始化
pthread_mutex_destroy(&mutex);//销毁
4.3.2 加锁/解锁
有了锁,那么就可以在需要的位置加上这把锁
#include <pthread.h>
int pthread_mutex_lock(pthread_mutex_t *mutex);
int pthread_mutex_trylock(pthread_mutex_t *mutex);
int pthread_mutex_unlock(pthread_mutex_t *mutex);
其中lock是阻塞式加锁,如果你调用这个接口的时候,锁正在被别人使用,则会在这里等待;trylock是非阻塞加锁,如果你调用该接口时锁正被使用,则直接return返回
The pthread_mutex_trylock() function shall be equivalent to pthread_mutex_lock(), except that if the mutex object referenced by mutex is currently locked (by any thread, including the current thread), the call shall return immediately.
加了锁之后,在需要的位置unlock解锁;
- 加锁和解锁操作本身是原子的,不会出现冲突
- 加了锁之后,可以理解为加锁解锁操作中间的代码也是原子性的,必须要运行到解锁位置才能让另外一个线程/进程执行这里的代码
- 加锁的本质是让线程执行临界区的代码串行化
4.3.3 加锁的注意事项
- 只对临界区加锁;锁保护的就是临界区
- 加锁的粒度越细越好(即加锁的区域越小越好)
- 加锁是编程的一种规范;在实际问题中,我们要保证访问某一临界资源的所有操作都要加上锁。不能出现函数A加锁了,但是B没有加锁的情况(这样会导致A的加锁也没有意义)
4.4 示例-倒水问题

以倒水为示例,假设杯子容量为10000,装满了水就会溢出。我们使用多个线程对这个杯子加水,直到满了之后线程退出
#include<iostream>
#include<string.h>
#include<signal.h>
#include<pthread.h>
#include<thread>
#include<unistd.h>
#include<sys/types.h>
#include<sys/syscall.h>
using namespace std;
//临界资源
int water = 0;//全局变量
int cup = 10000;//杯子的容量
void* func(void* arg)
{
while(1)
{
if(water<cup)//临界区
{
cout << (char*)arg << " 水没有满:" << water << "\n";
water++;
}
else
{
cout << (char*)arg << " 水已经满了 " << water << "\n";
break;
}
}
cout << (char*)arg << " 线程退出" << "\n";
return (void*)0;
}
int main()
{
pthread_t t1,t2,t3,t4;//创建4个线程
pthread_create(&t1,nullptr,func,(void*)"t1");
pthread_create(&t2,nullptr,func,(void*)"t2");
pthread_create(&t3,nullptr,func,(void*)"t3");
pthread_create(&t4,nullptr,func,(void*)"t4");
//直接分离线程
pthread_detach(t1);
pthread_detach(t2);
pthread_detach(t3);
pthread_detach(t4);
while(1)
{
;//啥都不干
}
return 0;
}
输出的结果如下,明明水已经满了,但还是会有部分线程报告水还没有满,且数字有很严重的偏差
t3 水没有满:9993
t3 水没有满:9994
t3 水没有满:9995
t3 水没有满:9996
t3 水没有满:9997
t3 水没有满:9998
t3 水没有满:9999
t3 水已经满了
t3 线程退出
水没有满:2723
t4 水已经满了
t4 线程退出
0
t2 水已经满了
t2 线程退出
t1 水没有满:9668
t1 水已经满了
t1 线程退出
多运行几次,也能发现相同的问题
t2 水没有满:9997
t2 水没有满:9998
t2 水没有满:9999
t2 水已经满了 10000
t2 线程退出
t4 水没有满:1889
t4 水已经满了 10001
t4 线程退出
t3 水没有满:0
t3 水已经满了 10002
t3 线程退出
t1 水没有满:0
t1 水已经满了 10003
t1 线程退出
4.4.1 只有一个线程在工作?
除了偏差外,还有一个小问题,往前翻打印记录,会发现一直都是某一个线程在倒水,其他线程似乎啥事没有干?
t3 水没有满:9786
t3 水没有满:9787
t3 水没有满:9788
t3 水没有满:9789
t3 水没有满:9790
这是因为当运行t3的时候,t3在while循环中继续运行的消耗,小于切换到其他线程的消耗。所以控制块就让t3一直运行,直到它break退出循环
此时我们只需要加上一个usleep,增加每一个while循环中需要处理的负担,就能让所有线程都来倒水
//usleep功能把进程挂起一段时间, 单位是微秒(百万分之一秒)
#include <unistd.h>
int usleep(useconds_t usec);
这是因为线程切换同样也是时间片到了,从内核返回用户态的时候做检测,切换至其他线程。
添加usleep能创造更多内核/用户的中间态,从而增多切换线程的次数
void* func(void* arg)
{
while(1)
{
if(water<cup)
{
usleep(100);//休息100微秒
cout << (char*)arg << " 水没有满:" << water << "\n";
water++;
}
else
{
cout << (char*)arg << " 水已经满了" << "\n";
break;
}
}
cout << (char*)arg << " 线程退出" << "\n";
return (void*)0;
}
但是这还是没有解决数字出错的问题
t4 水没有满:9995
t3 水没有满:9996
t1 水没有满:9997
t2 水没有满:9998
t4 水没有满:9999
t4 水已经满了 10000
t4 线程退出
t3 水没有满:10000
t3 水已经满了 10001
t3 线程退出
t1 水没有满:10001
t1 水已经满了 10002
t1 线程退出
t2 水没有满:10002
t2 水已经满了 10003
t2 线程退出
4.4.2 加锁-问题解决
这时候就需要请出我们的锁了
//省略头文件
int water = 0;//全局变量
int cup = 10000;//杯子的容量
pthread_mutex_t mutex;
void* func(void* arg)
{
while(1)
{
pthread_mutex_lock(&mutex);
if(water<cup)
{
usleep(100);
cout << (char*)arg << " 水没有满:" << water << "\n";
water++;
pthread_mutex_unlock(&mutex);
usleep(100);//假装喝水
}
else
{
cout << (char*)arg << " 水已经满了 " << water << "\n";
pthread_mutex_unlock(&mutex);
//此处也需要加锁,否则break出去之后其他线程会因为没有解锁而挂起
break;
}
}
cout << (char*)arg << " 线程退出" << "\n";
return (void*)0;
}
// 如果遇到2号信号,就在销毁锁后退出进程
void des(int signo)
{
//销毁锁
pthread_mutex_destroy(&mutex);
cout << "pthread_mutex_destroy, exit" << endl;
exit(0);
}
int main()
{
signal(SIGINT,des);//自定义捕捉2号信号
pthread_mutex_init(&mutex,nullptr);//初始化锁
pthread_t t1,t2,t3,t4;//创建4个线程
pthread_create(&t1,nullptr,func,(void*)"t1");
pthread_create(&t2,nullptr,func,(void*)"t2");
pthread_create(&t3,nullptr,func,(void*)"t3");
pthread_create(&t4,nullptr,func,(void*)"t4");
//直接分离线程
pthread_detach(t1);
pthread_detach(t2);
pthread_detach(t3);
pthread_detach(t4);
while(1)
{
;//啥都不干
}
return 0;
}
运行可见,数字错误问题就没有出现了;但又出现了只有一个线程工作的问题
t1 水没有满:9996
t1 水没有满:9997
t1 水没有满:9998
t1 水没有满:9999
t1 水已经满了 10000
t1 线程退出
t3 水已经满了 10000
t3 线程退出
t4 水已经满了 10000
t4 线程退出
t2 水已经满了 10000
t2 线程退出
^Cpthread_mutex_destroy, exit
这还是因为线程切换的效率问题;也有可能是因为其它线程申请锁的时候,发现t1在用,就进行了阻塞等待而挂起
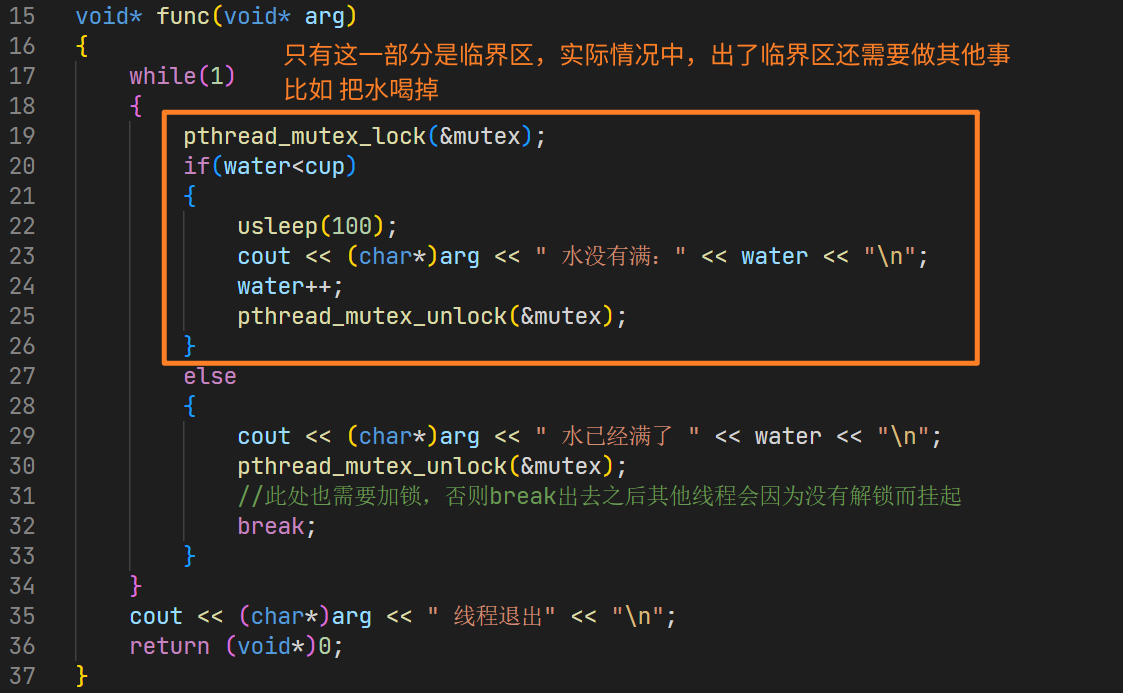
只需要在解锁之后添加一个usleep模拟其他工作,就能让所有线程都跑起来
pthread_mutex_lock(&mutex);
if(water<cup)
{
usleep(100);
cout << (char*)arg << " 水没有满:" << water << "\n";
water++;
pthread_mutex_unlock(&mutex);
usleep(100);//假装喝水
}
没有出现数据错误,加锁的目的成功达到!
t1 水没有满:9993
t3 水没有满:9994
t4 水没有满:9995
t2 水没有满:9996
t1 水没有满:9997
t3 水没有满:9998
t4 水没有满:9999
t2 水已经满了 10000
t2 线程退出
t1 水已经满了 10000
t1 线程退出
t3 水已经满了 10000
t3 线程退出
t4 水已经满了 10000
t4 线程退出
^Cpthread_mutex_destroy, exit
4.5 加锁的进一步解释
在这个代码示例中,我们给中间的几行代码加了锁;但这并不意味着执行中间这部分代码的时候,就不会发生线程切换
pthread_mutex_lock(&mutex);//加锁
if(water<cup)
{
cout << (char*)arg << " 水没有满:" << water << "\n";
water++;
}
pthread_mutex_unlock(&mutex);//解锁
事实上,代码执行的任何地方,都可能发生进程/线程的切换。但因为我们加了锁,切换的时候,其他线程要来访问这里的资源,就必须先申请锁
此时锁在被切走的进线程手上,所以其他线程无法访问临界区的资源,也就不会发生数据不一致的问题。

换言之,只要张三拿到了锁,那么它也就不担心自己的工作会被别人覆盖的问题;
而对其他线程而言,张三访问临界区的工作,只有还没进入临界区和访问完毕临界区两种状态
因此会导致一个问题,那就是线程切换的效率较低,其他线程出现了阻塞等待的情况;为了避免此问题,我们应该让访问临界区的操作快去快回,尽量不要在临界区里面干啥耗时的事情
4.5.1 加锁原子性的保证
备注:这部分仅供学习参考,若有错误,还请指出!
那么加锁这个操作,是如何保证其自身的原子性呢?在加锁的途中不会发生线程切换吗?

我找到了一张能大概说明汇编加锁过程的图片,其中movb的操作就是将al寄存器写为0,xchgb的操作是将al寄存器的内容和内存中mutex锁的值进行交换
- 开始的时候,锁被正常初始化,内存中mutex的值为1(锁只会被初始化一次)
- 线程A开始加锁,al寄存器和mutex的值发生交换,此时内存中的mutex为0,al为1
- 判断al不为0,代表获取锁成功,线程A加锁成功
- 线程B也来申请锁了,
movb将al寄存器写为0,再和内存中的mutex交换后,发现还是0,则代表锁在别人手上,此时就需要挂起等待
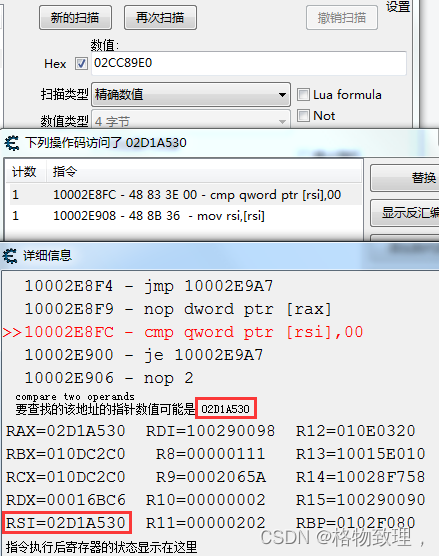
前面一直强调,线程是有自己独立的栈结构和上下文数据的,在加锁的这部分汇编操作中,同样可能会在任何地方发生线程切换。切换的时候,线程的上下文数据(图中寄存器的状态)会被保留下来,随这个线程一起被切换走
所以线程A被切换的时候,属于它上下文中那个值为1的al寄存器也被切走了(注意,这里切走的是数据,al寄存器本身作为硬件,有且只有一个)
由此看来,真正获取锁的操作,其实只有xchgb一条交换指令来完成,保证加锁操作只由一条汇编语句实现,就能保证该操作的原子性!
解锁的方法就很简单了,movb将1写回mutex变量即可,也是一条汇编完成;而且一般情况下,解锁是不会有执行流和你抢的。
其实加锁远不止一种方法,锁的种类有非常多,还有总线锁、旋转锁等等,每一个锁的实现都不太一样!上面提到的为
互斥锁
4.5.2 总线锁
现在的CPU一般都有自己的内部缓存,根据一些规则将内存中的数据读取到内部缓存中来,以加快频繁读取的速度。现在服务器通常是多 CPU,更普遍的是,每块CPU里有多个内核,而每个内核都维护了自己的缓存,那么这时候多线程并发就会存在缓存不一致性,这会导致严重问题。

总线锁就是将cpu和内存之间的通信锁住,使得在锁定期间,其他cpu处理器不能操作其他内存中数据,故总线锁开销比较大!
总线锁的实现是采用cpu提供的LOCK#信号,当一个cpu在总线上输出此信号时,其他cpu的请求将被阻塞,那么该cpu则独占共享内存,相当于锁住了
- 何为总线?
CPU总线是所有CPU与芯片组连接的主干道,负责CPU与外界所有部件的通信,包括高速缓存、内存、北桥,其控制总线向各个部件发送控制信号、通过地址总线发送地址信号指定其要访问的部件、通过数据总线双向传输

5.死锁
死锁就是一种因为两放都不会释放对方需要的资源,从而陷入的永久等待状态
5.1 死锁情况演示
举个例子,张三拿了锁A,申请锁B的时候,发现锁B无法申请,而进入等待;李四拿了锁B,接下来他想申请锁A,结果发现张三拿着锁A,那就只能进入等待。这就陷入了一个僵局,张三想要李四的,李四想要张三的,谁都不让谁
#include<iostream>
#include<string.h>
#include<signal.h>
#include<pthread.h>
#include<thread>
#include<unistd.h>
#include<sys/types.h>
#include<sys/syscall.h>
using namespace std;
pthread_mutex_t m1;//锁1
pthread_mutex_t m2;//锁2
void* func1(void*arg)
{
while(1)
{
pthread_mutex_lock(&m1);
pthread_mutex_lock(&m2);
cout << "func1 is running... " <<(const char*)arg<<endl;
pthread_mutex_unlock(&m1);
pthread_mutex_unlock(&m2);
}
}
void* func2(void*arg)
{
while(1)
{
pthread_mutex_lock(&m2);
pthread_mutex_lock(&m1);
cout << "func2 is running... " <<(const char*)arg<<endl;
pthread_mutex_unlock(&m1);
pthread_mutex_unlock(&m2);
}
}
int main()
{
pthread_mutex_init(&m1,nullptr);
pthread_mutex_init(&m2,nullptr);
pthread_t t1,t2;
pthread_create(&t1,nullptr,func1,(void*)"t1");
pthread_create(&t2,nullptr,func2,(void*)"t2");
//分离
pthread_detach(t1);
pthread_detach(t2);
while(1)
{
cout << "main running..." <<endl;
sleep(1);
}
pthread_mutex_destroy(&m1);
pthread_mutex_destroy(&m2);
return 0;
}
上面的这个代码便能模拟出这个情况,线程1先要了锁1,再要锁2;线程2先要锁2再要锁1,他们俩就容易打起来,造成死锁。
运行代码的时候我们却发现,似乎并不是这样的,线程1好像还是成功拿到了俩把锁,并运行了起来
[muxue@bt-7274:~/git/linux/code/22-12-23_线程死锁]$ ./test
main running...
func1 is running... t1
func1 is running... t1
main running...
func1 is running... t1
main running...
func1 is running... t1
main running...
那是因为我们没有执行其他一些工作,从而将线程1和2申请锁的时间错开
将代码改成下面这样,利用usleep让两个线程休眠不同时间,结果就不同了
void* func1(void*arg)
{
while(1)
{
pthread_mutex_lock(&m1);
usleep(200);
pthread_mutex_lock(&m2);
cout << "func1 is running... " <<(const char*)arg<<endl;
pthread_mutex_unlock(&m1);
pthread_mutex_unlock(&m2);
}
}
void* func2(void*arg)
{
while(1)
{
pthread_mutex_lock(&m2);
usleep(300);
pthread_mutex_lock(&m1);
cout << "func2 is running... " <<(const char*)arg<<endl;
pthread_mutex_unlock(&m1);
pthread_mutex_unlock(&m2);
}
}
可以看到,此时只有主线程在运行,线程t1和t2出现了死锁!
[muxue@bt-7274:~/git/linux/code/22-12-23_线程死锁]$ ./test
main running...
main running...
main running...
main running...

5.2 死锁的条件
- 互斥条件:某份资源同一时间只能由一个执行流访问
- 请求与保持:一个执行流因请求某种资源进入阻塞等待,而不释放自己的资源(好比上面代码例子中两个线程都不释放自己的锁,又想要别人的锁)
- 不剥夺条件:一个执行流已获得的资源,在未使用之前不能被剥夺(部分锁是允许被剥夺的)
- 循环等待:若干执行流之间形成一种头尾相接的循环等待资源的状态
一把锁也能造成死锁吗?答案是肯定的!
pthread_mutex_lock(&m1);
pthread_mutex_lock(&m1);
//两次申请同一把锁
如果有人写出这种bug代码,那就会出现一把锁把自己死锁了;死锁本来就是代码的bug,所以这种低级错误也是死锁的情况之一😂
5.3 避免死锁
避免死锁,其中最简单明了的办法,就是破坏上面提到的死锁的4个条件;其中互斥条件没啥好办法破坏(除非你不加锁),更主要的是看另外3个条件是否能破坏!
- 保持加锁顺序一致:不要出现上面代码中的线程a先申请锁1,线程b先申请锁2的情况。在不同的执行流中,按相同的顺序申请锁(比如线程a和b都是按锁1/2的顺序申请的)一定程度上能破坏
请求与保持条件 - 降低加锁的粒度:锁保护的区域变小,加锁的粒度减小,能一定程度上避免锁未释放
- 资源一次性分配:减少临时资源分开给的情况
- 允许抢占:线程之间依靠优先级抢夺锁,这种情况就是锁允许被剥夺
6.线程安全
线程安全:多个线程并发执行同一段代码的时候,不会出现不同的结果
线程不安全的情况:
- 不保护临界资源
- 在多线程操作中调用不可重入函数(概念见linux信号部分)
- 返回指向静态变量的指针的函数
线程安全:
- 每个线程只操作局部变量,或者只对全局、静态变量只读不写
- 接口对线程来说是原子操作(被锁保护)
- 多个线程切换不会使函数接口的结果出现二义性
- 多线程操作不调用不可重入函数
注意,绝大多数的系统自带的库(比如C++的STL库)都是不可重入的

不可重入是函数的一种性质,并不是它的缺点!如果一个库函数明明告知你了我是不可重入的,你还不加保护的在多线程操作中调用它,那么这段代码是有bug的,并不是库函数本身有问题