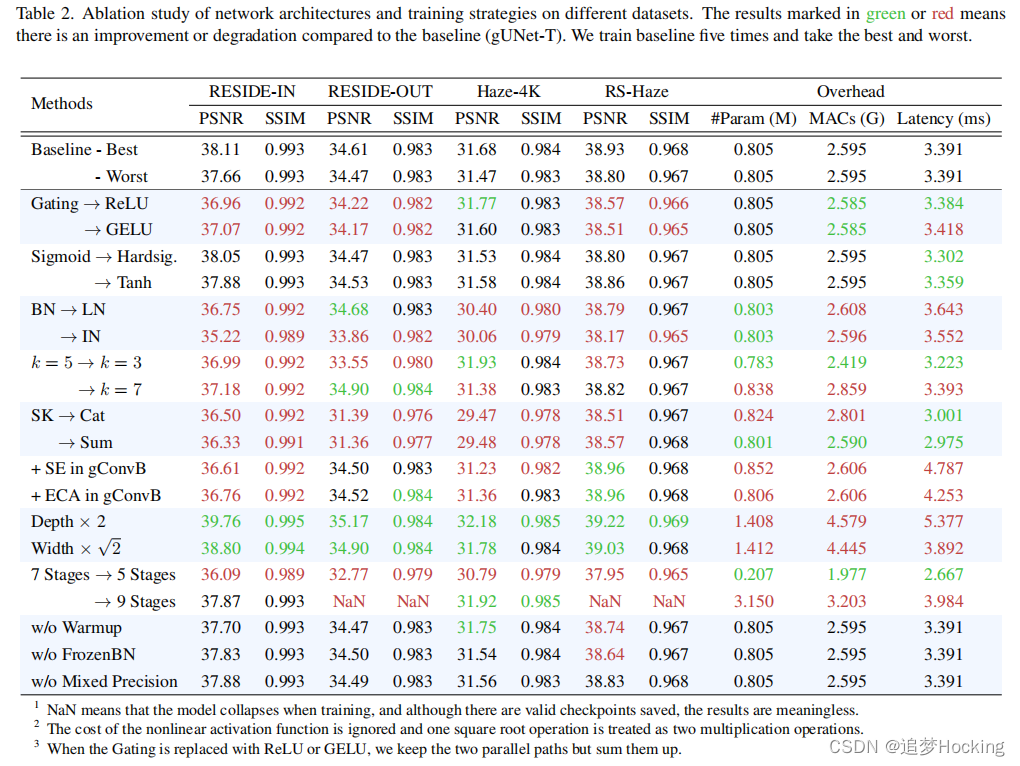
目录
1、导入库和手写数字数据集
2、 把数据可视化
3、把数据分成训练数据集和测试数据集
4、训练SVM模型
5、训练决策树模型
6、对所使用的模型进行评估
7、对手写数字图像进行预测
本项目实现了
第一个功能:可以通过导入库和数据集、通过对数据集的预处理、读取、可视化,将数据集划分为训练集和测试级,更换不同的模型,并对模型进行评估,多方面对比不同的机器学习方法,对数据模型的影响。
第二个功能:将训练出来的数据进行预测,通过图片预测直观的方式将模型进行可视化,方便对比不同的机器学习算法。
机器学习算法优缺点:
SVM:
优点
1、非线性间隔映射是SVM方法的理论基础,SVM利用内积核函数代替向高维空间的非线性映射。
2、SVM的目标是找到对特征空间划分的最优超平面,SVM方法的核心是最大化分类边际的思想。
3、SVM的训练结果是支持向量,在分类决策中起到决定性作用。
4、SVM是一种小样本的学习方法,从本质上看,它避开了从归纳到演绎的传统过程,实现了高效的从训练样本到预测样本的“转导推理”,简化了通常的分类和回归问题。
5、SVM最终的决策函数只由少数的支持向量决定,计算的复杂性取决于支持向量的数目,而不是样本空间的维数,在某种意义上避免了“维数灾难”。
6、有较好的鲁棒性:增删非支持向量样本对模型没有影响,SVM方法对核的选取不敏感。
不足
1、SVM算法对大规模训练样本难以实施。
2、SVM对解决多分类问题存在困难。
决策树:
优点
1、决策树易于理解和实现,通过解释人们都有能力去理解决策树表达的意义。
2、数据处理前应当去掉多余的或者空白的属性。
3、能够同时处理数据型和常规型的属性,可以接受数据属性的多样性。
4、对缺失值不敏感。
5、可以处理不相关的特征数据。
6、只需构建一次,便可以反复使用,每一次预测的最大计算次数不超过决策树的深度。
缺点
1、容易造成过拟合,即将训练集自身的一些特点作为所有数据的一般性质,导致过拟合,需要进行剪枝处理。
2、对于有时间顺序的数据,需要很多的预处理的工作。
3、当类别太多时,错误可能就会增加的比较快。
4、只能根据一个字段进行分类。
5、在处理特征关联性比较强的数据时,表现不好。
1、导入库和手写数字数据集
import matplotlib.pyplot as plt
from sklearn import datasets
from sklearn.model_selection import train_test_split
from sklearn import svm
from sklearn.metrics import accuracy_score
from sklearn.tree import DecisionTreeClassifier, export_graphviz
digits = datasets.load_digits()
X = digits.data
y = digits.target2、 把数据可视化
# 把数据所代表的图片显示出来
images_and_labels = list(zip(digits.images, digits.target))
plt.figure(figsize=(8, 8), dpi=200) #设置figsize为8*8,分辨率dpi为200
for index, (image, label) in enumerate(images_and_labels[:10]):
plt.subplot(2, 5, index + 1)
plt.imshow(image, cmap=plt.cm.gray_r, interpolation='nearest')
plt.title('Digit: %i' % label, fontsize=20)
plt.show() #操作环境在pycharm,所以放在循环外,绘制在同一张图片上
#打印图片的数量和尺寸,方便查看以及后续操作
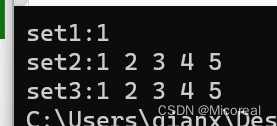
print("图片的数量和尺寸为: {0}".format(digits.images.shape))
print("图片数据的尺寸为: {0}".format(digits.data.shape))

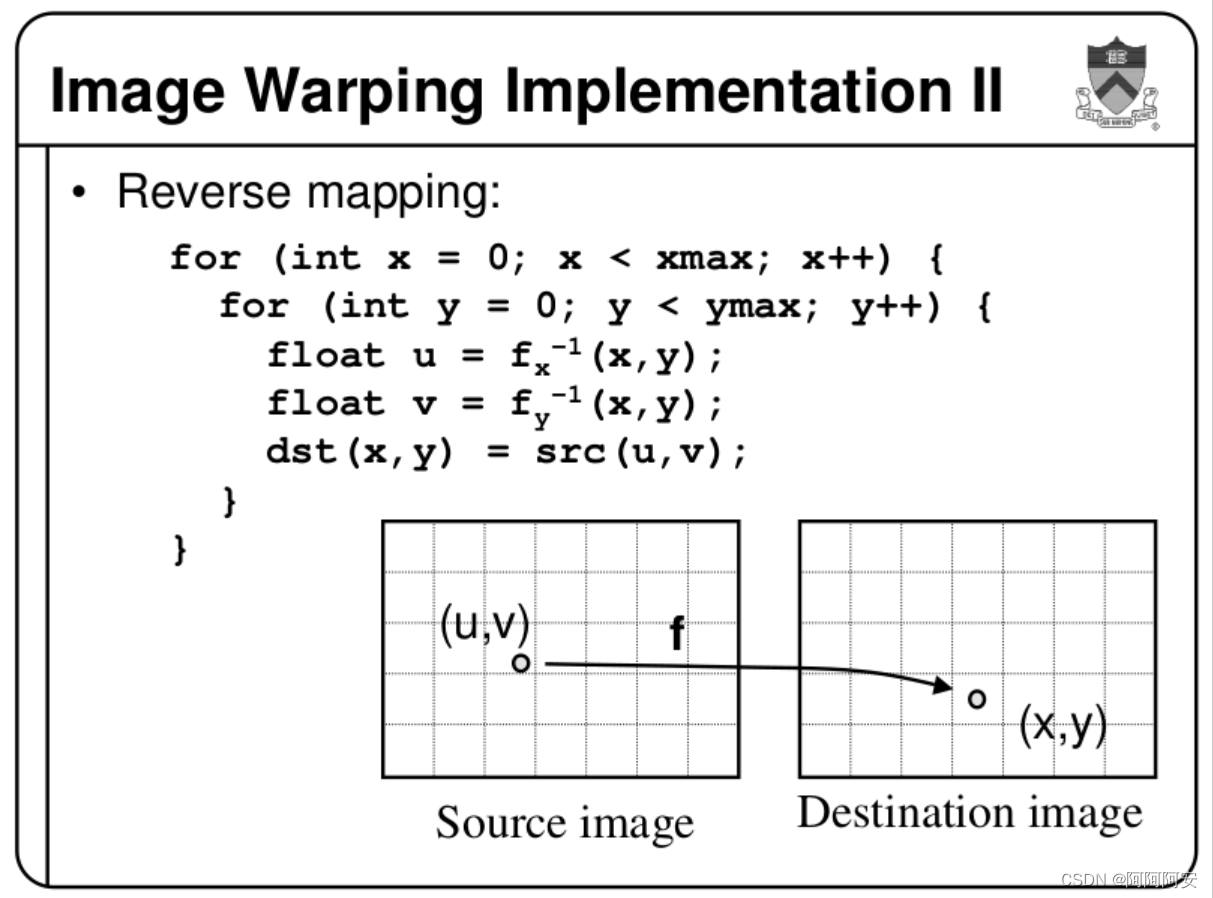
3、把数据分成训练数据集和测试数据集
# 把数据分成训练数据集和测试数据集
X_train, X_test, Y_train, Y_test = train_test_split(X, y, test_size=0.2, random_state=42)这一步是把数据分为百分之80的训练数据集和百分之20的测试数据集
4、训练SVM模型
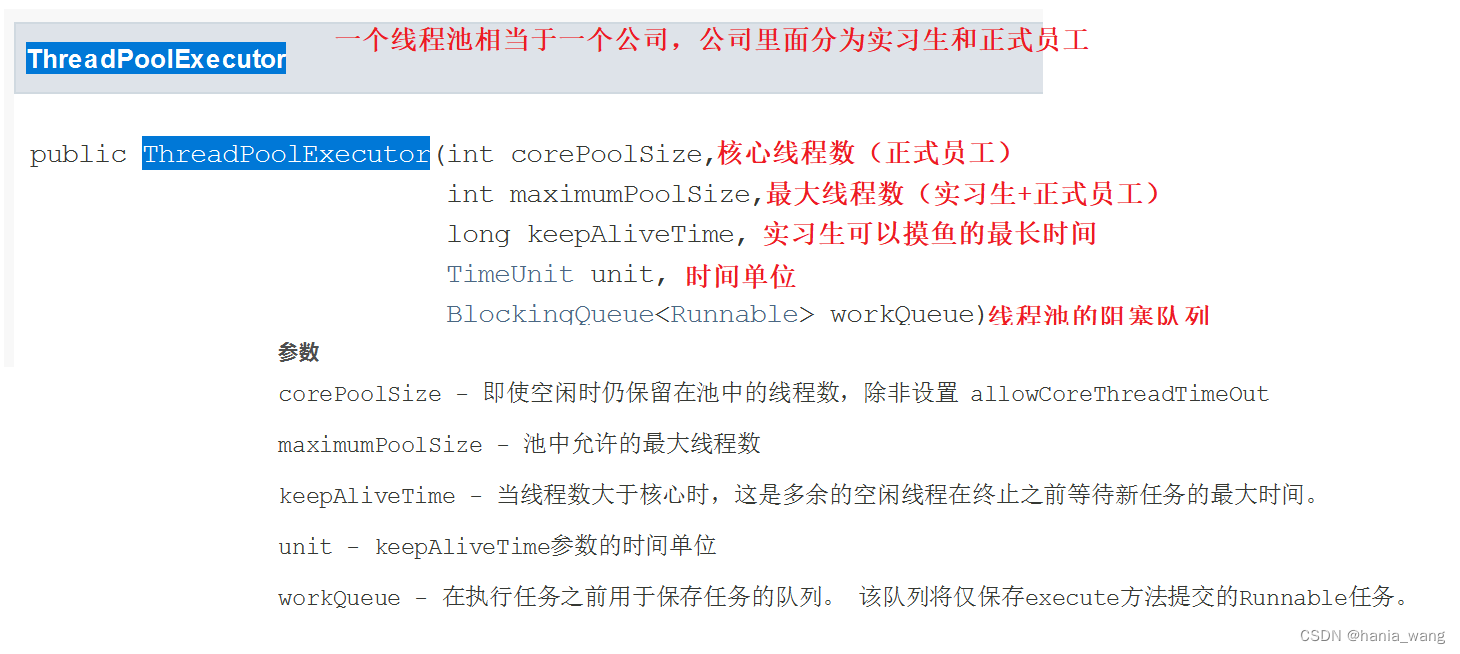
clf = svm.SVC(gamma=0.001, C=100., probability=True)
clf.fit(X_train, Y_train) 使用支持向量机来训练模型,这里调整了gamma值为0.001,参数C的值为100,probability设置为True
5、训练决策树模型
model = DecisionTreeClassifier(criterion="entropy")
model.fit(X_train, Y_train)决策树学习的目的是为了产生一棵泛化能力强,即处理未见实例能力强的决策树,其基本流程遵循简单且直观的“分而治之”的策略。决策树学习最关键的在于如何选择最优划分属性。
6、对所使用的模型进行评估
# 评估模型的准确度
Y_pre = clf.predict(X_test)
accuracy_score(Y_test, Y_pre)
# 打印模型的精确度
print(clf.score(X_test, Y_test))SVM模型的正确率为 0.9888888888888889
决策树模型的正确率为 0.8972222222222223
7、对手写数字图像进行预测
for i, ax in enumerate(axes.flat):
ax.imshow(X_test[i].reshape(8, 8), cmap=plt.cm.gray_r, interpolation='nearest')
#图像预测正确则数字为绿色,不正确的预测则为红色
ax.text(0.05, 0.05, str(Y_pre[i]), fontsize=32,
transform=ax.transAxes,
color='green' if Y_pre[i] == Y_test[i] else 'red')
#标签数据设置为黑色放在图像右下角
ax.text(0.8, 0.05, str(Y_test[i]), fontsize=32,
transform=ax.transAxes,
color='black')
ax.set_xticks([])
ax.set_yticks([])
plt.show()SVM模型的预测

决策树模型的预测

完整代码如下:
1、决策树模型
import matplotlib.pyplot as plt
from sklearn import datasets
from sklearn.model_selection import train_test_split
from sklearn import svm
from sklearn.metrics import accuracy_score
from sklearn.tree import DecisionTreeClassifier, export_graphviz
digits = datasets.load_digits()
X = digits.data
y = digits.target
# 把数据所代表的图片显示出来
images_and_labels = list(zip(digits.images, digits.target))
plt.figure(figsize=(8, 8), dpi=200) #设置figsize为8*8,分辨率dpi为200
for index, (image, label) in enumerate(images_and_labels[:10]):
plt.subplot(2, 5, index + 1)
plt.imshow(image, cmap=plt.cm.gray_r, interpolation='nearest')
plt.title('Digit: %i' % label, fontsize=20)
plt.show() #操作环境在pycharm,所以放在循环外,绘制在同一张图片上
#打印图片的数量和尺寸,方便查看以及后续操作
print("图片的数量和尺寸为: {0}".format(digits.images.shape))
print("图片数据的尺寸为: {0}".format(digits.data.shape))
# 把数据分成训练数据集和测试数据集
X_train, X_test, Y_train, Y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 使用决策树模型
model = DecisionTreeClassifier(criterion="entropy")
model.fit(X_train, Y_train)
# 评估模型的准确度
Y_pre = model.predict(X_test)
accuracy_score(Y_test, Y_pre)
# 打印模型的精确度
print(model.score(X_test, Y_test))
# 查看预测的情况,采用4*4张数据图片来预测和label对比
fig, axes = plt.subplots(4, 4, figsize=(8, 8))
fig.subplots_adjust(hspace=0.1, wspace=0.1)
for i, ax in enumerate(axes.flat):
ax.imshow(X_test[i].reshape(8, 8), cmap=plt.cm.gray_r, interpolation='nearest')
#图像预测正确则数字为绿色,不正确的预测则为红色
ax.text(0.05, 0.05, str(Y_pre[i]), fontsize=32,
transform=ax.transAxes,
color='green' if Y_pre[i] == Y_test[i] else 'red')
#标签数据设置为黑色放在图像右下角
ax.text(0.8, 0.05, str(Y_test[i]), fontsize=32,
transform=ax.transAxes,
color='black')
ax.set_xticks([])
ax.set_yticks([])
plt.show()
2、SVM支持向量机模型
import matplotlib.pyplot as plt
from sklearn import datasets
from sklearn.model_selection import train_test_split
from sklearn import svm
from sklearn.metrics import accuracy_score
digits = datasets.load_digits()
X = digits.data
y = digits.target
# 把数据所代表的图片显示出来
images_and_labels = list(zip(digits.images, digits.target))
plt.figure(figsize=(8, 8), dpi=200) #设置figsize为8*8,分辨率dpi为200
for index, (image, label) in enumerate(images_and_labels[:10]):
plt.subplot(2, 5, index + 1)
plt.imshow(image, cmap=plt.cm.gray_r, interpolation='nearest')
plt.title('Digit: %i' % label, fontsize=20)
plt.show() #操作环境在pycharm,所以放在循环外,绘制在同一张图片上
#打印图片的数量和尺寸,方便查看以及后续操作
print("图片的数量和尺寸为: {0}".format(digits.images.shape))
print("图片数据的尺寸为: {0}".format(digits.data.shape))
# 把数据分成训练数据集和测试数据集
X_train, X_test, Y_train, Y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 使用支持向量机来训练模型,这里调整了gamma值为0.001,参数C的值为100,probability设置为True
clf = svm.SVC(gamma=0.001, C=100., probability=True)
clf.fit(X_train, Y_train)
# 评估模型的准确度
Y_pre = clf.predict(X_test)
accuracy_score(Y_test, Y_pre)
# 打印模型的精确度
print(clf.score(X_test, Y_test))
# 查看预测的情况,采用4*4张数据图片来预测和label对比
fig, axes = plt.subplots(4, 4, figsize=(8, 8))
fig.subplots_adjust(hspace=0.1, wspace=0.1)
for i, ax in enumerate(axes.flat):
ax.imshow(X_test[i].reshape(8, 8), cmap=plt.cm.gray_r, interpolation='nearest')
#图像预测正确则数字为绿色,不正确的预测则为红色
ax.text(0.05, 0.05, str(Y_pre[i]), fontsize=32,
transform=ax.transAxes,
color='green' if Y_pre[i] == Y_test[i] else 'red')
#标签数据设置为黑色放在图像右下角
ax.text(0.8, 0.05, str(Y_test[i]), fontsize=32,
transform=ax.transAxes,
color='black')
ax.set_xticks([])
ax.set_yticks([])
plt.show()