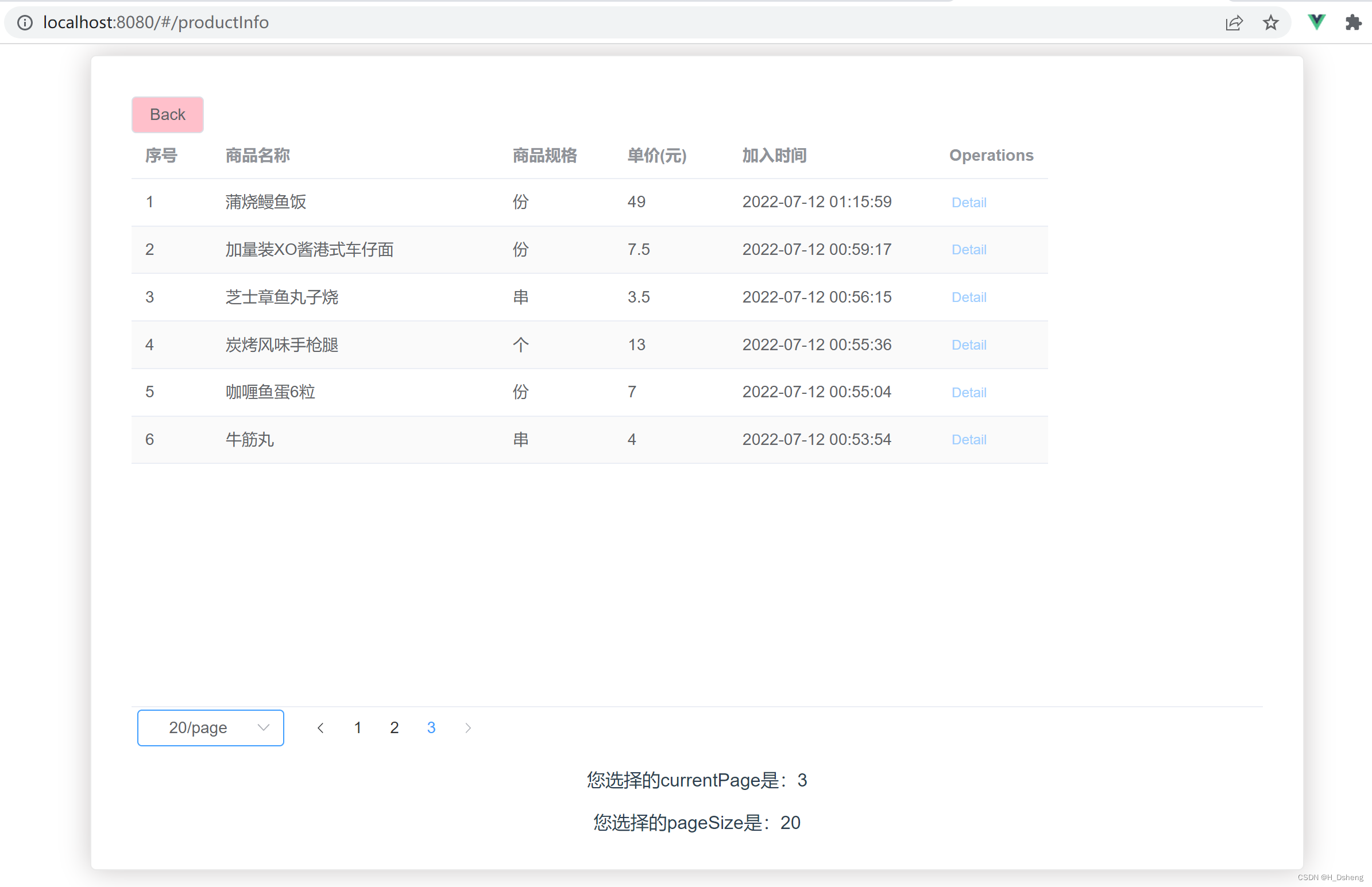
论文源码:
https://download.csdn.net/download/zhouaho2010/87393184
Abstract
图像去雾是低层视觉中的一个活跃话题,随着深度学习的快速发展,许多图像去雾网络被提出。尽管这些网络的工作良好,但提高图像去雾性能的关键机制仍不清楚。出于这个原因,我们不打算提出一个具有奇特模块的去雾网络;相反,我们对流行的U-Net进行最小的修改以获得紧凑的去雾网络。具体来说,我们将U-Net中的卷积块交换为具有门控机制的残差块,融合主路径的特征映射,并使用选择核跳过连接,并调用得到的U-Net变体gUNet。因此,gUNet以显著降低的开销,在多个图像去雾数据集上优于最先进的方法。最后,通过广泛的消融研究验证了这些关键设计对图像去雾网络性能增益的影响。
1. Introduction
图像去雾化长期以来一直是低级视野讨论的话题,因为雾霾是一种常见的大气现象,对公共安全和个人生活造成损害。在恶劣天气下获得更好的照片是供个人使用的图像脱雾的主要用例,这些功能经常包含在照片编辑软件中。此外,图像去模糊通常被认为是工业使用高级视觉任务的先决条件。例如,使用图像去模糊模块作为预处理模块来提高自动驾驶系统的鲁棒性是可行的。这使得图像去模糊成为低水平视觉的代表性任务之一,越来越受到研究人员和关注的关注。
图像去模糊的目标是从模糊图像中恢复无雾图像。研究人员经常使用大气散射模型[36,39,40]来表征模糊图像的退化过程:

一般来说,图像去模糊化方法可以大致分为基于先验的方法和基于学习的方法。早期的图像脱雾方法主要是基于手工先验的[3,13,16,62]。近年来,由于基于学习的方法的优越性能,许多研究人员正在研究图像脱模糊网络[4,24,42,47]。虽然许多令人印象深刻的图像脱雾网络,但提高脱雾性能的关键仍不清楚。在本文中,我们着重探讨了图像去模糊网络的关键设计。我们回顾了著名的图像去雾网络,并发现了两个显著的性能提高的时刻。第一个是GCANet [5]和GridDehazeNet [29],它们都引入了提取多尺度信息,不再分别预测A和t (x),而是用来预测潜在的无雾图像或无雾图像与模糊图像之间的残差。第二个是FFA-Net [42],提出了一种引入像素注意模块和通道注意模块的深度网络。其他作品也提出了合理的修改建议。然而,这些修改只带来适度的性能提高,但使网络更加复杂和难以部署。
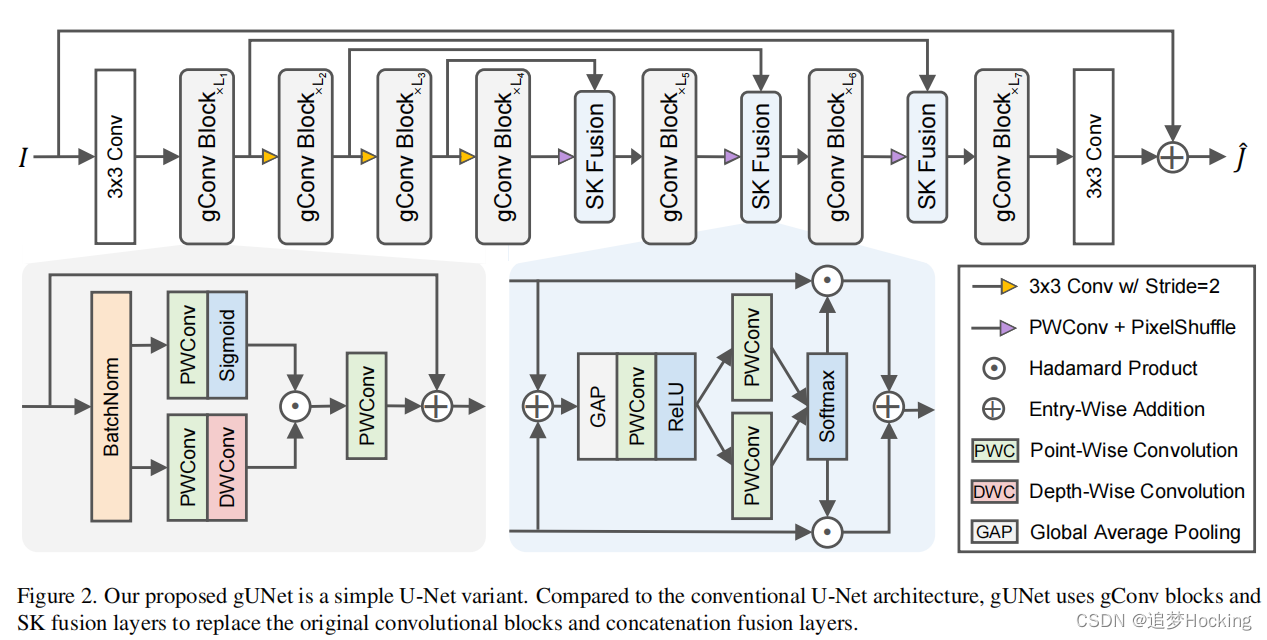
我们试图创建一个最小的实现,它基于上面提到的观察结果来合并这些关键的设计。具体来说,我们首先使用经典的具有局部残差[17]和全局残差[59]的U-Net [32]作为我们的基础架构来提取多尺度信息。然后,我们使用深度可分离的卷积层[21,45]来聚合空间信息并有效地变换特征。此外,我们将全局信息的提取分配给基于SK模块[26]的模块,该模块通过通道动态地融合来自不同路径的特征映射。最后,我们在卷积块中引入了门控单元,这些门控单元作为像素注意模块和非线性激活函数。提出了两个关键模块,即门控机制为gConv块的剩余块模块和通道注意机制的融合模块为SK融合层模块。这里我们将我们的模型命名为gUNet,因为它是一个带有门控的简单U-Net变体。
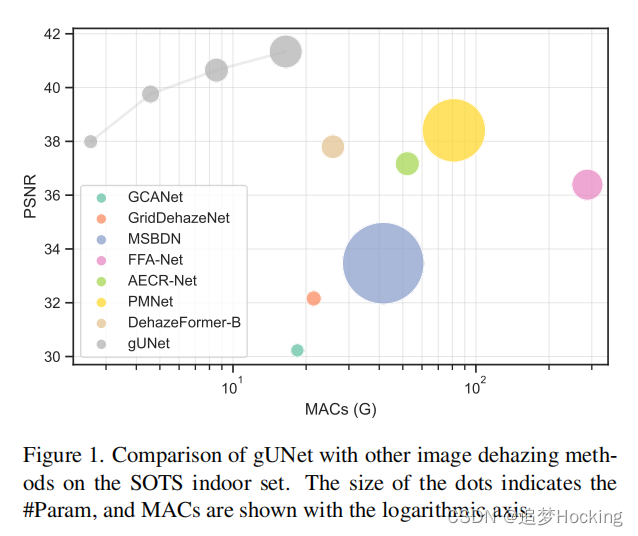
我们评估了gUNet在四个图像去模糊数据集上的性能,对于每个数据集,我们训练了四个不同深度的变体。实验结果表明,gUNet可以在显著较低的开销下大大优于同期方法。图1显示了在最常用的SOTS室内集合上,gUNet与其他图像除雾方法的比较。可以看出,gUNet的四种变体都在图表的左上角,这意味着它们在较低的计算成本下优于所有的图像脱模糊方法。特别是,微型模型gUNet-T优于DehazeFormerB,依赖于10%的计算成本和32%的参数,而小模型gUNet-S优于PMNet,仅使用5.6%的计算成本和7.4%的参数。更重要的是,我们对所有四个数据集进行了广泛的消融研究,以验证这些关键设计。实验结果表明,该模块在图像去模糊处理方面可以获得一致的性能提高。
2. Related Work
图像去模糊方法大致分为基于先验的方法和基于学习的方法两类。早期的图像脱雾方法通常是基于手工先验,并产生具有良好能见度的图像。随着深度学习的发展,基于学习的方法近年来主导了图像模糊。
Prior-based image dehazing
基于先验的图像去雾。基于先验的方法通常从无雾图像和模糊图像之间的统计差异开始。暗通道先验(DCP)[16]可能是最著名的基于先验的方法之一。DCP认为,对于户外图像,在无雾霾图像的局部斑块中,至少有一个颜色通道的强度接近于0。在此基础上,DCP从模糊的图像中估计透射图,并结合一个简单的全球大气光估计,得到一个生动的去雾图像。此外,色线[13]和雾霾线[3]从不同的角度分析了RGB颜色空间中无雾霾通道之间的线性关系,从而估算了传输图。相比之下,颜色衰减先验(CAP)[62]分析了模糊图像在HSV颜色空间中的S-V通道差异与场景深度之间的关系,从而推导出传输图。最近,
rank-one 先验[28]考虑了接近秩一矩阵的传输映射,这可以通过计算图像在统一辐射上的投影来得到。然而,
由于这些先验是基于经验统计数据的,当场景不满足这些先验时,它们可能会导致不现实的结果。最著名的情况是,DCP在大的白色区域(如天空)中表现不佳。
Learning-based image dehazing
基于学习的图像去雾。基于学习的方法通常从大规模数据集估计无雾图像。
DehazeNet[4]和MSCNN [43]是基于学习的图像脱雾方法的先驱。由于它们的结构非常浅,而且全球大气光仍然可以用传统的方法来估计,所以它们的性能并没有远远超过基于先前的方法。DCPDN [58]使用两个子网络分别估计透射图和全球大气光。通过重写等式(1),AODNet [24]只预测一个输出,并且只通过一个非常轻量级的主干网络获得良好的脱雾性能。
GridDehazeNet[29]提出了一种
具有大量跳过连接的网格状网络架构。
更重要的是,它提出学习直接恢复图像,因为它可以获得更好的性能。在此之后,图像去模糊网络倾向于估计无雾图像或无雾图像与模糊图像之间的残差。目前,大多数基于学习的方法倾向于设计复杂的网络架构来提高网络的表达能力
the expressive capability of the network,一些引入了注意机制[8,11,42,52],而一些引入了多尺度特征[5,10,50]。最近,一些基于ViT的[12]脱雾网络被提出,如HyLoG-ViT [61]、
DehazeFormer[47]和DeHamer [15]。然而,ViT的管道要比CNN复杂得多,对其部署造成了相当大的障碍。
与以前的方法不同,我们的目标并不是一个复杂的网络架构,而是提出了一个具有最小更改的U-Net变体,以方便部署。而且我们提出的方法可以优于以前的方法,尽管它看起来相当简单。
3. gUNet
图2显示了gUNet的整体架构。我们的模型,gUNet,可以看作是一个7级的U-Net变体,其每个阶段由一堆提议的gConv块组成。此外,gUNet没有采用U-Net采用的卷积层后连接融合跳跃连接和主路径的策略。相反,我们建议使用SK融合模块来
动态地融合来自不同路径的特征映射。给定图像对{I (x),J (x)},我们让gUNet预测全局残差[5,42,59],即R(x)=Jˆ(x)−I(x),然后计算L1损失来训练我们的模型。
3.1. Motivation
我们首先描述了gUNet的动机,它是基于从以前的工作中获得的关键设计。第一个是多尺度信息的提取,我们使用经典的U-Net [32]作为我们的基础架构,它生成不同大小的特征图,从而提取多尺度特征。然后,我们将局部残差[17]加入卷积块,将全局残差[59]加入网络。为了在不显著增加参数数量和计算成本的情况下使网络更深入,我们使用深度可分离卷积[21,45]来有效地聚合信息和变换特征。现在网络设计的关键是如何利用注意机制来提高网络的表达能力。我们还记得等式(1)并发现大气光A是一个共享的全局变量,而t (x)是一个与位置相关的局部变量。在FFA-Net中,信道注意模块是唯一能够有效提取全局信息的模块。我们认为,通道注意机制有效地提取了编码A所需的信息,这也是FFA-Net正常工作的原因之一。然而,虽然信道注意模块的计算成本很小,但它所引入的参数的数量和延迟时间是不可忽略不计的。我们认为估计应该是一个简单的任务,因为有很多方法[4,16,43,58]分配大部分的计算资源来估计t (x)但使用轻量级模块来估计。因此我们只分配这个任务的融合模块基于SK模块[26],动态融合特征地图从不同的路径。相应地,像素注意模块的目的是使网络更加关注信息特征。我们发现GLU [7,46]中的门电机制也起着类似的作用。为此,我们在卷积块中引入了门控机制,并使其作为像素注意模块和非线性激活函数。
3.2. gConv Block
我们的gConv主要基于gMLP [27]和GLU [7,46]。假设x是特征映射,我们首先通过xˆ=批规范(x)使用批规范[23]对其进行归一化。为了进行推断,批处理规范使用了在训练集上跟踪的统计数据的指数移动平均值。它可以与相邻的线性层合并,更符合轻量级网络的要求。此外,批规范没有LayerNorm [2]的缺点,它打破了前[47]中提到的空间相关性。
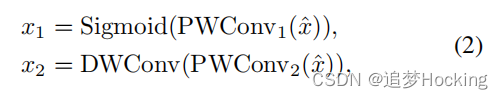
其中,PWConv为点向卷积层,DWConv为深度向卷积层。然后我们使用x1作为x2的门控信号,然后使用另一个PWConv进行投影,输出用恒等快捷方式x求和,可以表述为:
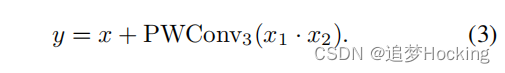
在其他图像恢复任务[6,48,56]中,使用门控机制来提高网络的表达能力并不是一个新想法。与我们的工作最相似的工作是NAFNet [6],考虑到我们俩都不使用传统的非线性激活函数,如ReLU和GELU,而只依赖于门控机制来实现非线性。相比之下,NAFNet使用GLU的双线性变体(即没有任何非线性激活函数),我们使用原始版本的GLU版本(即使用sigmoid作为门控函数)。
3.3. SK Fusion
SK融合层是对SK模块[26]的一个简单修改。类似的想法也可以在MIRNet [55,57]和脱前者中找到。设两个特征映射分别为x1和x2,其中x1是来自跳过连接的特征映射,x2是来自主路径的特征映射。我们首先使用PWConv层f(·)将x1投影到xˆ1=f(x1),这在图2中没有说明。我们使用全局平均池化GAP(·)、MLP(PWConv-ReLU-PWConv)Fmlp(·)、softmax函数和分割操作来获得融合权值:
最后,我们通过y=a1xˆ1+a2x2融合xˆ1,x2。为了减少参数的数量,MLP的两个PWConv层分别是降维维和增维层,这与传统的通道注意机制[22]一致。
3.4. Training Strategy
我们使用了几种训练图像恢复网络的技术来训练gUNet。
SyncBN. 在BatchNorm的标准实现中,对每个GPU分别执行归一化,这导致规范化批处理大小[53]比数据并行训练中的小批处理大小更小。因此,我们使用SyncBN [41],这是一个批规范的实现,使规范化批处理大小达到小批处理大小。我们发现在规范化批处理大小为16或更大时可以达到最好的性能,所以我们只在规范化批处理大小小于16时启用SyncBN。SyncBN引入了额外的开销,因为它共享多个gpu之间的平均值和方差。
FrozenBN. FrozenBN是一个常数仿射变换,因为它使用了之前在训练时计算出的总体统计量。一旦跟踪的总体统计量被固定,那么来自归一化层的优化获益就会丢失,但它可以保持训练测试的一致性。我们在过去的几个时代启用了FrozenBN,因为学习率很低,而且没有必要担心梯度爆炸。结果表明,我们发现当训练期总数或归一化批处理规模较小时,FrozenBN可以显著提高模型的性能。
Mixed Precision Training. 混合精度训练可以在训练过程中对某些层进行低精度的训练,从而在不降低模型性能的情况下降低计算成本和内存使用。即使在一些高级视觉任务中,混合精度训练也能略微提高模型[18]的精度。我们使混合精度训练能够减少训练时间,增加小批量训练的大小。
Warmup. 线性热身经常被用于高级视觉任务,以帮助优化。由于我们的初始学习率相对较大,并且启用了混合精度训练,我们发现该模型在训练过程中可能产生NaN。为了降低崩溃的风险,我们采用了热身策略。
3.5. Implementation Details
为简单起见,我们将每级gConv块数设置为{M、M、M、2M、M、M、M},信道数设置为{N、2N、4N、8N、4N、2N、N},其中M为基块数,N为基信道数。为了验证gUNet的可伸缩性,我们提出了四种gUNet变体(-T、-S、-B和-D,分别适用于微小、小、基本和深)。我们将所有变体的DWConv的宽度和核大小k设置为相同的,特别是N = 24和k = 5。这四种变体只在深度上有所不同,我们将它们的基块数M设置为{2、4、8、16}。
我们使用4张卡的RTX-3090来训练我们的模型。在训练时,图像被随机裁剪到256个×256个补丁中。考虑到不同的数据集有不同的样本数,我们将每个纪元的样本数设置为16384,总周期为1000,其前50个用于预热,最后200个用于FrozenBN。这样,我们就可以排除训练迭代的影响,更好地分析不同数据集上的消融研究的差异。受GPU内存的限制,我们将{-T、-S、-B、-D}的小批处理大小分别设置为{128、128、64、32}。对于gUNet-D,它的规范化批处理大小小于16,所以我们启用了SyncBN。基于线性缩放规则[14],我们将{-T、S、B、D}的初始学习速率设置为{16、16、8、4}×10−4。我们使用AdamW优化器[34](β1 = 0.9,β2 = 0.999)和余弦退火策略[33]对模型进行训练,其中学习率从初始学习率逐渐下降到{16,16,8,4}×10−6。
4. Experiments
4.1. Experimental Setup
我们在驻留的[25]、Haze4K [30]和RS-Haze [47]数据集上进行了实验。对于驻留数据集,我们遵循FFA-Net [42]的设置,它包含两个主要的实验设置,驻留在内和驻留在out。具体来说,我们使用ITS(13990对图像对)和OTS(313950对图像对)来训练模型,并分别在SOTS的室内(500对)和室外(500对图像对)上进行测试。对于Haze4K数据集,我们遵循PMNet [54]的设置。Haze4K包含4000对图像对,其中3000对用于训练,其余1000对用于测试。与居住者相比,Haze4K混合了室内和室外场景的图像,合成管道更加逼真。对于RS-Haze数据集,我们遵循去haze前[47]的设置。它由54,000对图像对组成,其中51,300对用于训练,其余2,700对用于测试。RS-Haze是一个场景较为单调的遥感去雾图像数据集,但其雾霾高度不均匀,与居住者和Haze4K完全相反。所有的模型都使用它们的原始策略进行训练,我们复制了在之前的工作中报告的最佳结果。
4.2. Quantitative Comparison
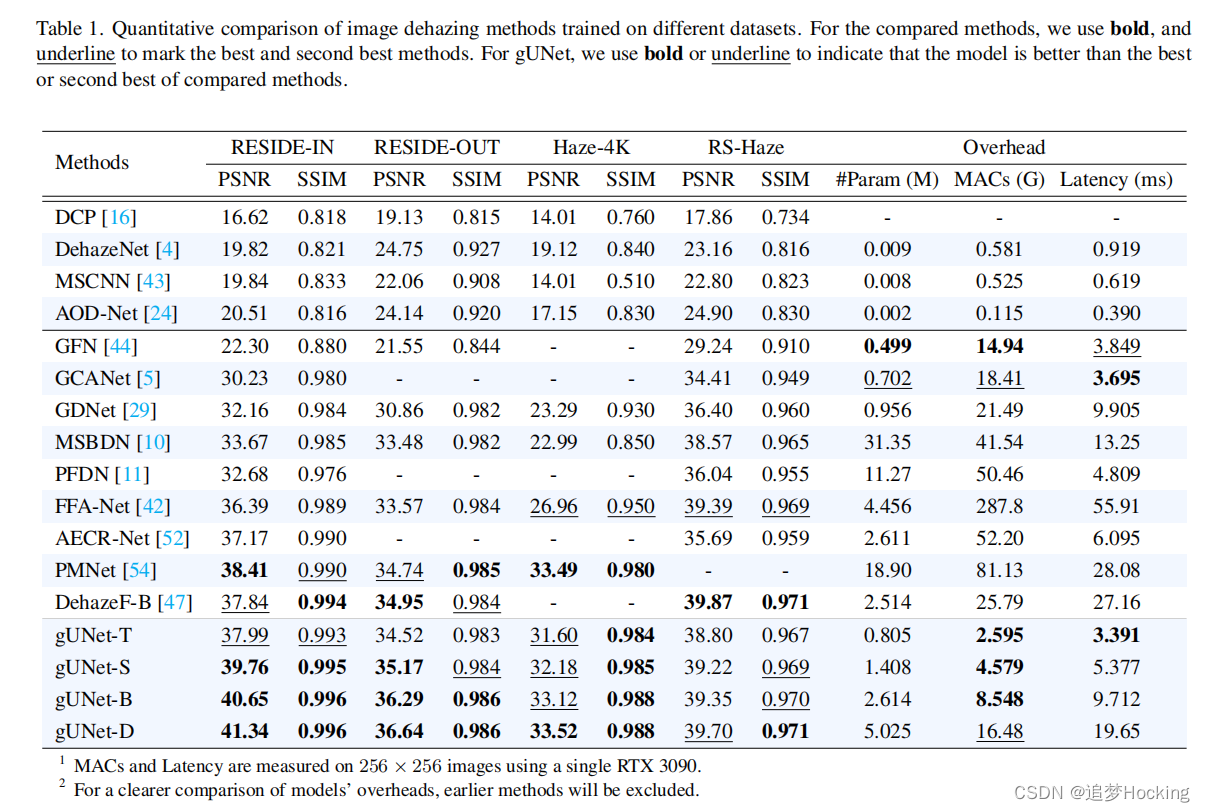
我们定量地比较了gUNet和基线的性能,结果如表1所示。我们提出的gUNet是一个更好的图像去模糊网络。具体来说,我们提出的小模型(gUNet-S)在最广泛使用的驻留数据集上优于以前的所有方法。在Haze-4K和RS-Haze数据集上,gUNet也以更高的效率实现了与最先进的模型相当的性能。最后,gUnet的所有变体都很好,我们相信这是一种可扩展的方法。对于驻留数据集,gUNet-S在最广泛使用的室内集合上优于PMNet,在室外集合上超过了dehaze-b。对于Haze-4K,由于Haze-4K的样本量较小,训练模型的性能变化很大。我们认为,gUNet-D和PMNet之间的性能差距大部分源于实验的随机性。对于RS-Haze,虽然gUNet-D比前者-b更有效,但前者仍然是最好的方法。我们认为这是因为RSHaze数据集中的图像包含了许多更适合自我注意[37]的重复场景。最后,可以发现gUNet虽然不够快,但它的架构紧凑,计算成本低,这是由于DWConv的内存访问成本是高的[9]。幸运的是,在边缘设备中运行深度网络受计算容量的限制比受内存带宽的限制更大。
4.3. Qualitative Comparison
我们选择了两个具有代表性的驻留数据集样本,以定性地分析每种方法的性能。图3显示了我们的gUNet-D与一些脱雾网络的定性比较。对于室内场景,我们可以发现GCANet、PFDN和FFA-Net都产生文物,而AOD-Net不产生文物,但对墙壁的影响太大,对地面的影响太少。相比之下,gUNet-D不产生伪影,其恢复图像的每个区域的亮度和色调都非常接近地面事实。此外,gUNet还可以更好地区分浅色物体和被雾霾遮蔽的暗色物体,从而产生更令人满意的结果。对于户外场景,gUNet的脱雾效果比所有的比较方法都更接近于一个干净的图像。然而,合成数据集中(驻留和Haze4K)中户外场景样本的干净图像都包含雾霾,所有经过训练的模型都无法去除,说明合成雾霾不够真实。

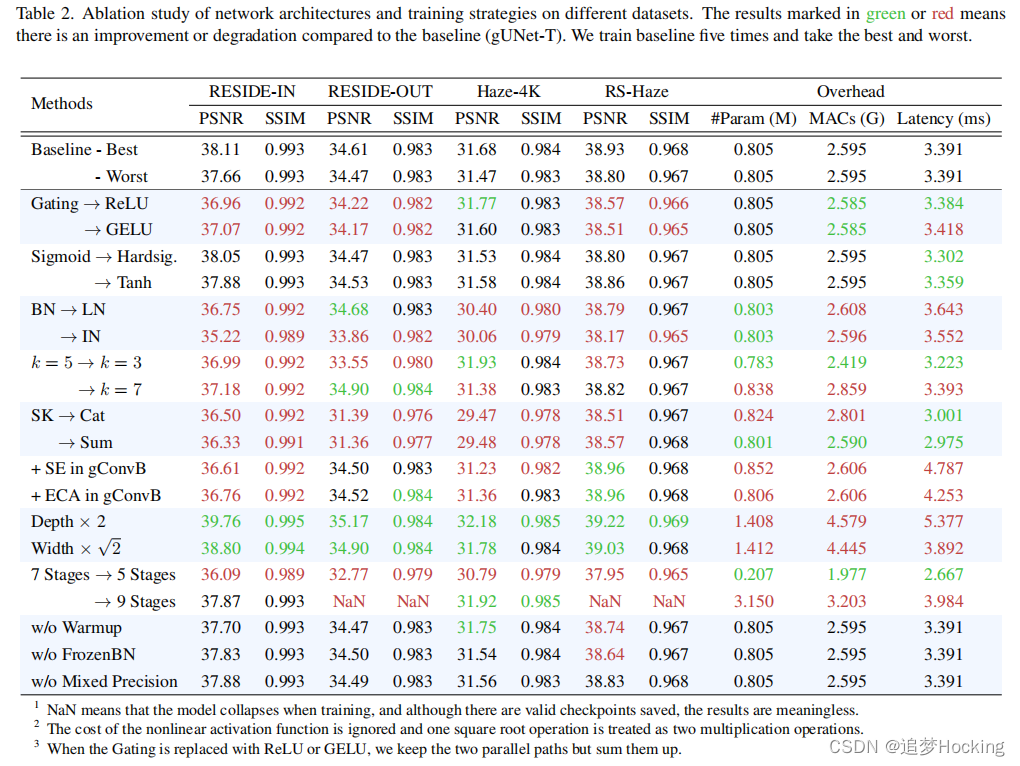
4.4. Ablation Study
我们认为,消融研究可以更好地揭示模型中的关键设计,因此我们对本文中涉及的所有数据集进行了消融研究,
考虑到每个数据集的特征不同,因此消融研究的结果可能不一致。我们还发现,以往一些工作的绩效提高更多的是
由于训练的随机性。因此,我们多次训练基线,并记录了最好和最差的表现。对于消融研究中的模型,如果它们的性能介于两者之间,那么相应的设计就被认为不是关键设计。
Gating Mechanism.我们通过用门控机制取代传统的非线性激活函数来验证这一改进。可以看出,除了在Haze-4K数据集上外,门控机制的引入带来了一致的性能改进。此外,我们发现ReLU [38]和GELU [19]的性能具有可比性,这与dehaze前者的建议不同,可能是由于网络架构的不同。此外,门控函数的选择似乎并不重要,而且它足以确保其输出是有上界和下界的。我们也试图删除门控功能,但网络的梯度在训练过程中总是爆炸。
Normalization Layer. 我们用
LayerNorm和
InstanceNorm[49]替换
BatchNorm。可以看出,层规范和实例规范比批规范要慢得多,因为它们在推理过程中仍然计算特征映射的平均值和方差。在性能方面,批规范略好于LayerNorm(特别是在驻留在和Haze-4K数据集上)。考虑到其有效性和效率,批处理规范应该是一个更好的方法选择比版面规范和安装规范的gUNet。我们也试图删除归一化层,但它遭受梯度爆炸。
Normalization Batch Size. 如果引入了SyncBN,则标准化批处理大小可以等于小批处理大小。结合GhostBN [20]和SyncBN,我们可以设置该消融研究所需的大部分标准化批大小。图4显示了结果。由于列车测试的不一致性太大,一个小的标准化批大小(例如,1、2或4)的性能很差。当标准化批处理大小大于8时,模型的性能没有显著变化。令人惊讶的是,在Haze-4K上,较大的标准化批处理大小会导致性能下降,这可能是因为Haze-4K数据集比其他几个数据集要小得多。因此,较小的归一化批量大小提供了更多的噪声,以避免过拟合。
Kernel Size of DWConv. ConvNext [31]提出,内核大小过大或过小的DWConv会导致性能下降。对于gUNet,k = 5是一个很好的选择。此外,我们发现较大的数据集更喜欢较大的内核大小。具体来说,重出的样本数比其他数据集大得多,因此大内核不会导致过拟合,但提高了网络的表达能力。相比之下,Haze-4K的样本要少得多,所以设置k = 3提供了一个额外的正则化来抑制过拟合。
Fusion Layer。 如果SK核聚变被更常见的求和或串联融合所取代,gUNet的性能将会急剧下降。我们认为这主要是因为: 1) SK融合对不同阶段的信息进行动态融合,放宽了各阶段之间信息相关性的约束;2) SK Fusion可以提取全局信息,这对估计全球大气光至关重要。虽然在gUNet中SK融合层的开销可以忽略不计,但由于有太多的元素级操作[35],它会使网络稍微减慢。
Channel Attention Mechanism. 通道注意机制。我们尝试在gConv块的PWConv3之后插入SE模块[22]和ECA模块[51],就像许多图像恢复网络[1,42,60]所做的那样。令人惊讶的是,更多的渠道注意模块并没有带来令人满意的改善。相反,它们甚至导致居住和Haze-4K的性能显著下降。我们相信SK Fusion的目的是提取全局信息,添加更多的通道注意模块不会带来任何实质性的变化。相反,门控机制可以被认为是一种特殊的注意机制,而在同一残差块中使用两个注意模块会增加不稳定性。
Deeper vs. Wider. 考虑到参数的数量和计算成本,一个更深的网络比一个更宽的网络表现得更好,但代价是速度更慢。然而,一个广泛的网络也有负面影响,因为它生成更大的中间特征图,消耗更多的GPU内存,并且不利于边缘设备的推断。因此,在本文中,我们增加了网络的深度来扩展网络。
Stage Number。我们探讨了不同阶段数对模型性能的影响。可以看出,减少阶段的数量可以降低开销。然而,它降低了性能,其中受影响最大的是参数的数量,因为参数的数量由中间阶段的块贡献最多。然而,如果引入更多的阶段,该模型只与基线进行比较,并在两个数据集上生成NaN。我们认为这是因为更多的阶段引入了更多的参数,导致了网络训练过程中的不稳定,而引入一种更合理的初始化方法有助于克服这一缺点。
Training Stratagies. 因此,这些技术的性能提高幅度很小。我们使用的附加训练技术主要是为了提高模型在训练过程中的稳定性,减少训练费用。这些技术中对模型性能最重要的是SyncBN,这对于不能保证每个gpu批大小足够大的设备是必不可少的。此外,虽然混合精度训练似乎不会影响模型的性能,但它使训练更加不稳定,因为我们在消融研究中发现了一些变体产生NaN。
Training Epochs. 我们发现,之前的工作并没有讨论训练期的数量对网络性能的影响。图5显示了我们的实验结果,每条曲线都是训练期间模型在验证集上的PNSR。可以预期,如果网络没有过度安装,更长时间的训练将带来进一步的网络改进。此外,我们在Haze-4K上观察到过拟合,这应该是由于其样本数较小。我们注意到,由于不同模型的训练方案不同,研究人员倾向于复制在以前的工作中报告的结果,以进行比较。然而,很明显,即使在最常用的驻留数据集上,大多数模型也没有被训练到收敛。我们猜测,之前的一些脱雾模型所获得的性能提高很可能仅仅是因为它们被训练了更长的时间。
5. Conclusion
本文探讨了图像去雾网络的关键设计。除了常用的多尺度结构和残差学习外,注意机制的有效利用是提高绩效的关键。具体来说,本文提出了gUNet,它利用特征融合模块中的信道注意机制来提取全局信息,利用门机制来代替像素注意和非线性激活函数来建模空间变化的传输映射。我们评估了gUNet在四个图像去雾数据集上的性能,结果表明,gUNet与最先进的方法相当,甚至更好,但开销要小得多。更重要的是,我们进行了大规模的消融研究,结果表明,图像去模糊网络的性能增益主要来自于注意机制、非线性激活函数、全局信息的提取、归一化层和训练时期的数量。