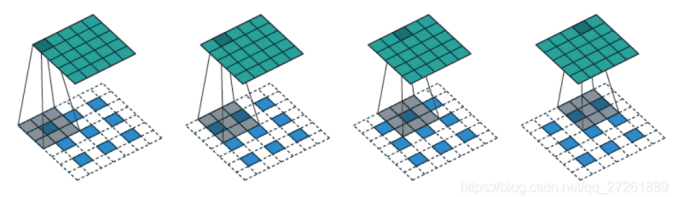
回溯法解决的问题
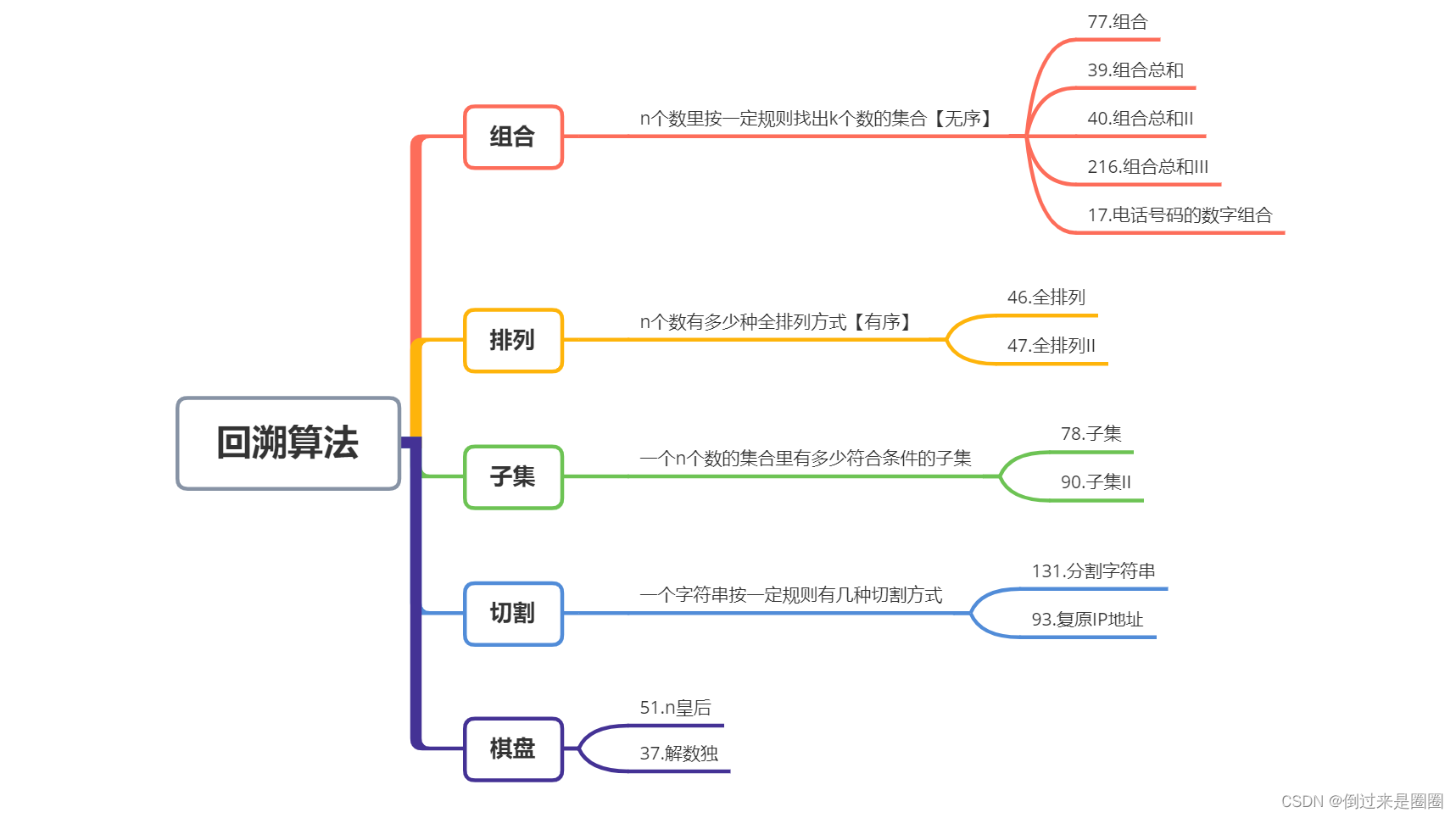
回溯法模板
- 返回值:一般为void
- 参数:先写逻辑,用到啥参数,再填啥参数
- 终止条件:到达叶子节点,保存当前结果,返回
- 遍历过程:回溯法一般在集合中递归搜索,集合的大小构成了树的宽度,递归的深度构成了树的深度
如图:
横向中for遍历集合区间,有几个子集合for循环就执行多少次
纵向中backtracking自己调用自己,实现递归,多少层递归树的深度就是多少
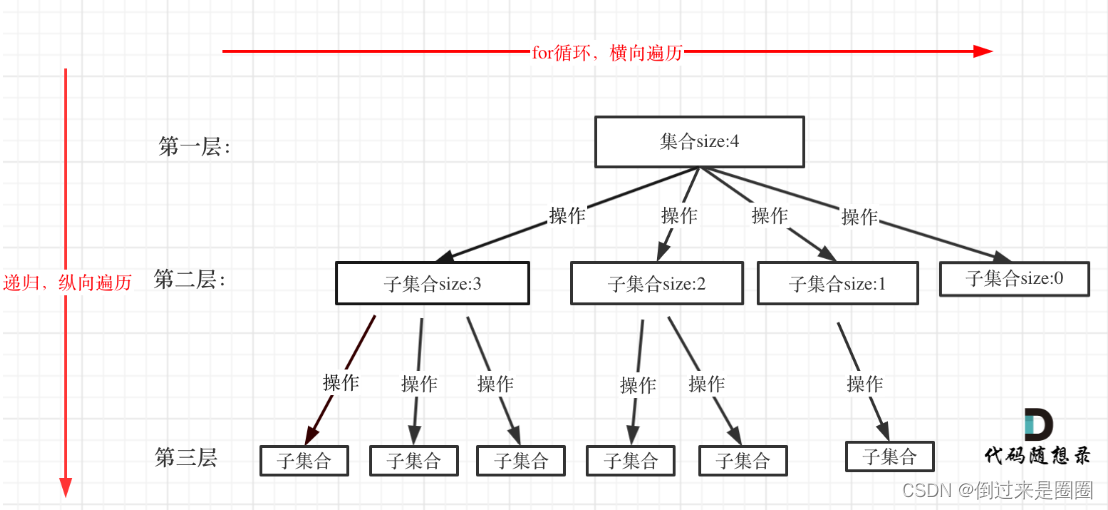
- 回溯算法的模板框架:
void backtracking(参数) {
if (终止条件) {
存放结果;
return;
}
for (选择:本层集合中元素(树中节点孩子的数量就是集合的大小)) {
处理节点;
backtracking(路径,选择列表); // 递归
回溯,撤销处理结果
}
}
组合问题
1. 组合
77.组合
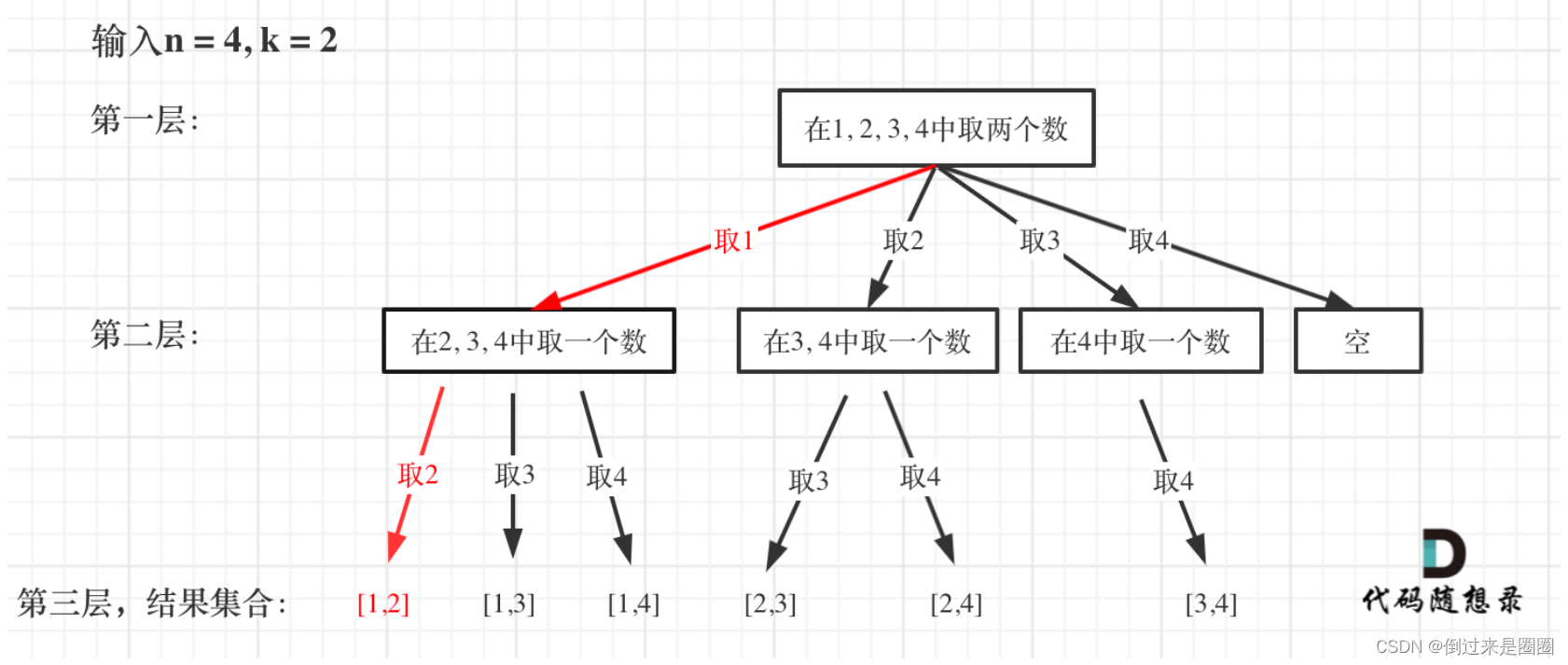
给定两个整数 n 和 k,返回 1 … n 中所有可能的 k 个数的组合。
递归树
- 最开始集合为1,2,3,4,从左向右取数,取过的数不再重复
- 第一次取1,集合变为2,3,4,因为k为2,只需再取一个数就行,分别取2,3,4,得到集合[1,2],[1,3],[1,4],以此类推
- 每次从集合中选取元素,可选择的范围随着选择的进行而收缩,调整可选择的范围
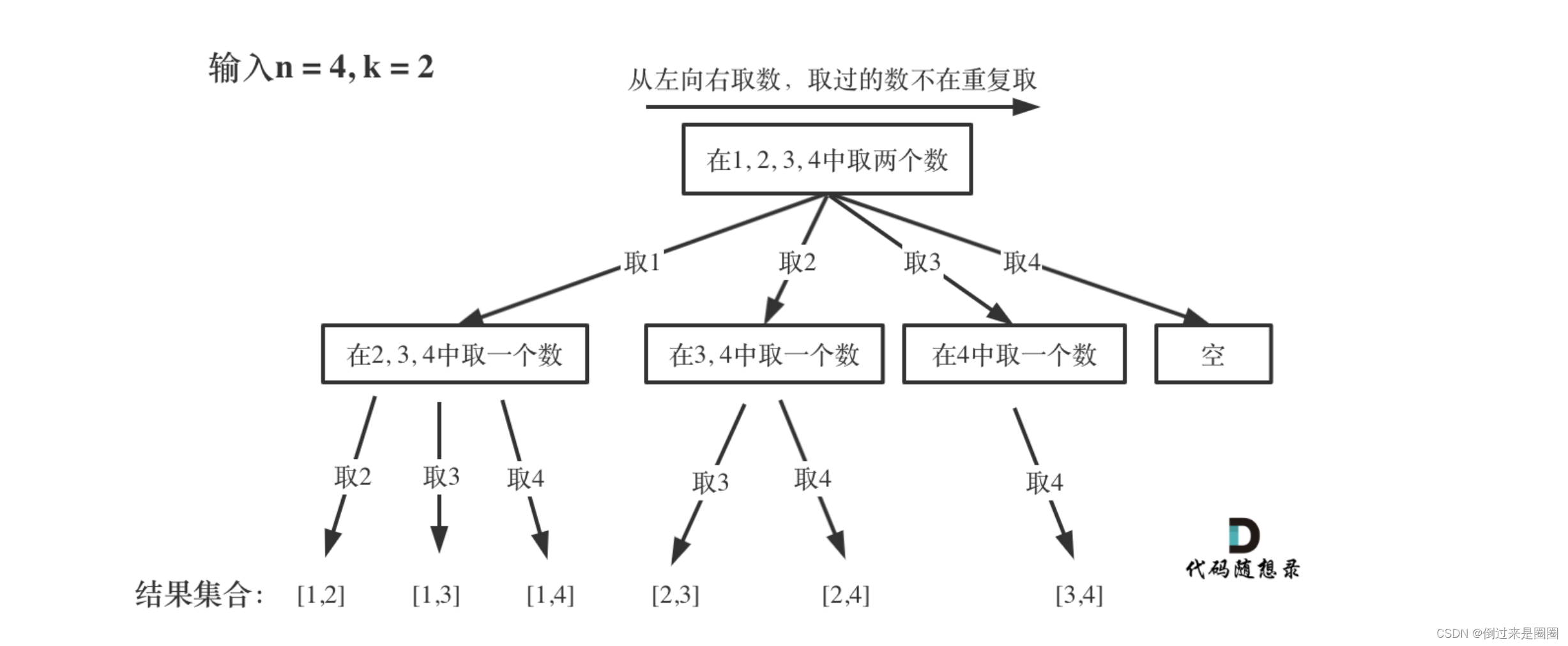
画递归树是解决回溯问题最重要的步骤
回溯法三部曲
- 递归函数参数
两个全局变量,一个用来存放符合条件单一结果,一个用来存放符合条件结果的集合
List<Integer>path=new ArrayList<>();//某次结果
List<List<Integer>>res=new ArrayList<>();//所有结果
函数里一定有n和k两个参数,另外还需要一个参数 index,用来记录本层递归中,集合从哪里开始遍历(集合即[1,…,n])。
index就是为了防止重复的组合,需要其记录下一层递归,搜索的起始位置。
因此递归函数参数如下:public void backtracking(int n,int k,int start)
- 终止条件
如果path数组大小达到k,说明找到了一个子集大小为k的组合了,图中path存的就是根节点到叶子节点的路径,如图红色部分:
此时用res数组保存path,然后return。
所以终止条件代码如下:
if(path.size()==k){
res.add(new ArrayList<>(path));
return;
}
- 单层搜索过程
for循环横向遍历,递归纵向遍历,代码如下:
for(int i=index;i<=n;i++){
path.add(i);
backtrack(n,k,i+1);//递归,下一层搜索从i+1开始
path.remove(path.size()-1);//回溯,撤销处理的节点
}
剪枝优化
仔细看遍历过程代码,其中遍历范围是可以剪枝优化的
for(int i=index;i<=n;i++){
path.add(i);
backtrack(n,k,i+1);//递归,下一层搜索从i+1开始
path.remove(path.size()-1);//回溯,撤销处理的节点
}
举例n=4,k=4,第一层for循环时,从元素2开始子集大小肯定达不到4,因此之后都没有意义了。在第二层for循环,从元素3开始的遍历都没有意义了。
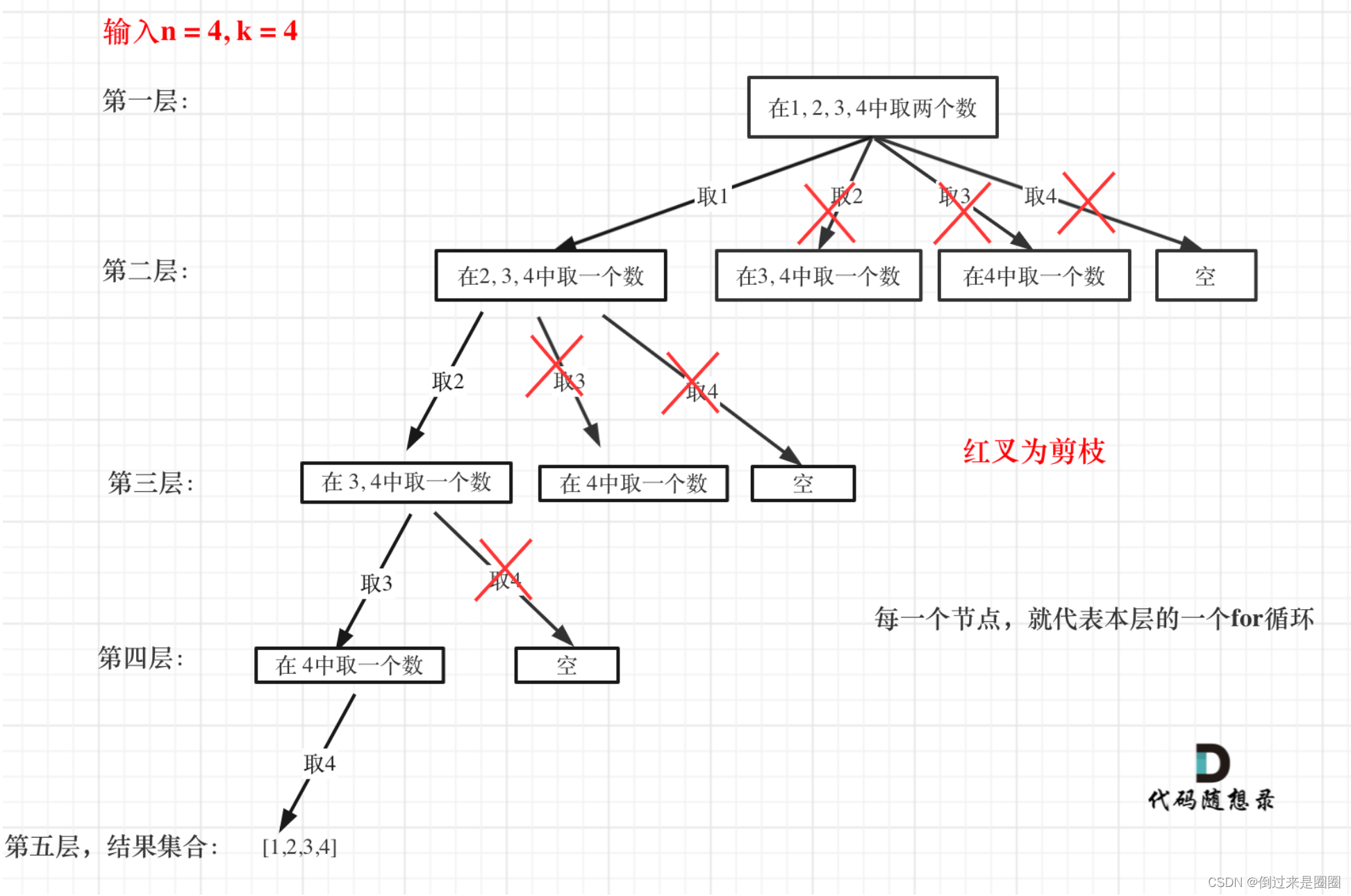
所以,如果for循环选择的起始位置之后的元素个数 已经不足 我们需要的元素个数了,那么就没有必要搜索了
优化过程如下:
- 已经选择的元素个数:path.size()
- 还需要的元素个数:k-path.size()
- 集合中至多要从该起始位置:n-(k-path.size())+1,开始遍历
由于起始位置是从1开始的,因此起始位置要+1,举个例子就可以知道了
因此,剪枝优化后的for循环如下:
for(int i=index;i<=n-(k-path.size())+1;i++)
2. 组合总和III
216. 组合总和 III
找出所有相加之和为 n 的 k 个数的组合。组合中只允许含有 1 - 9 的正整数,并且每种组合中不存在重复的数字。
说明:
- 所有数字都是正整数。
- 解集不能包含重复的组合。
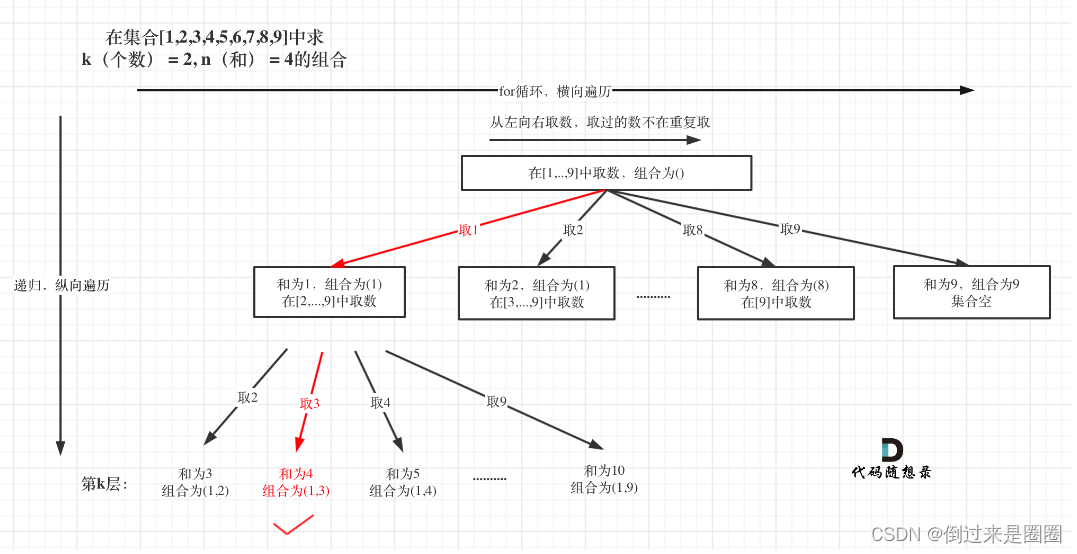
递归树
相比于77.组合,多了一个和为n的限制,并且整个集合是固定的[1,…,9],而上一题集合为非固定的[1,…,n]
递归树如下:
回溯三部曲
- 递归函数参数
类似上一题 组合,同样需要path存放单次结果和res存放全部结果
除此之外,递归函数参数中,k和index必然存在,还需要记录目标和的targetSum以及记录path中元素总和的sum。
所以参数如下:
List<Integer>path=new ArrayList<>();
List<List<Integer>>res=new ArrayList<>();
public void dfs(int k,int index,int targetSum,int sum)
-
终止条件
依据题意,path元素数目达到k && sum==targetSum时终止递归 -
单层搜索过程
和上一题77.组合的区别有二,
一是集合固定为[1,…,9],因此for循环固定i<=9;
二是需要sum来统计path中元素总和。
代码如下:
for(int i=index;i<=9;i++){
path.add(i);
sum+=i;
dfs(n,k,i+1,sum);
sum-=i;
path.remove(path.size()-1);
}
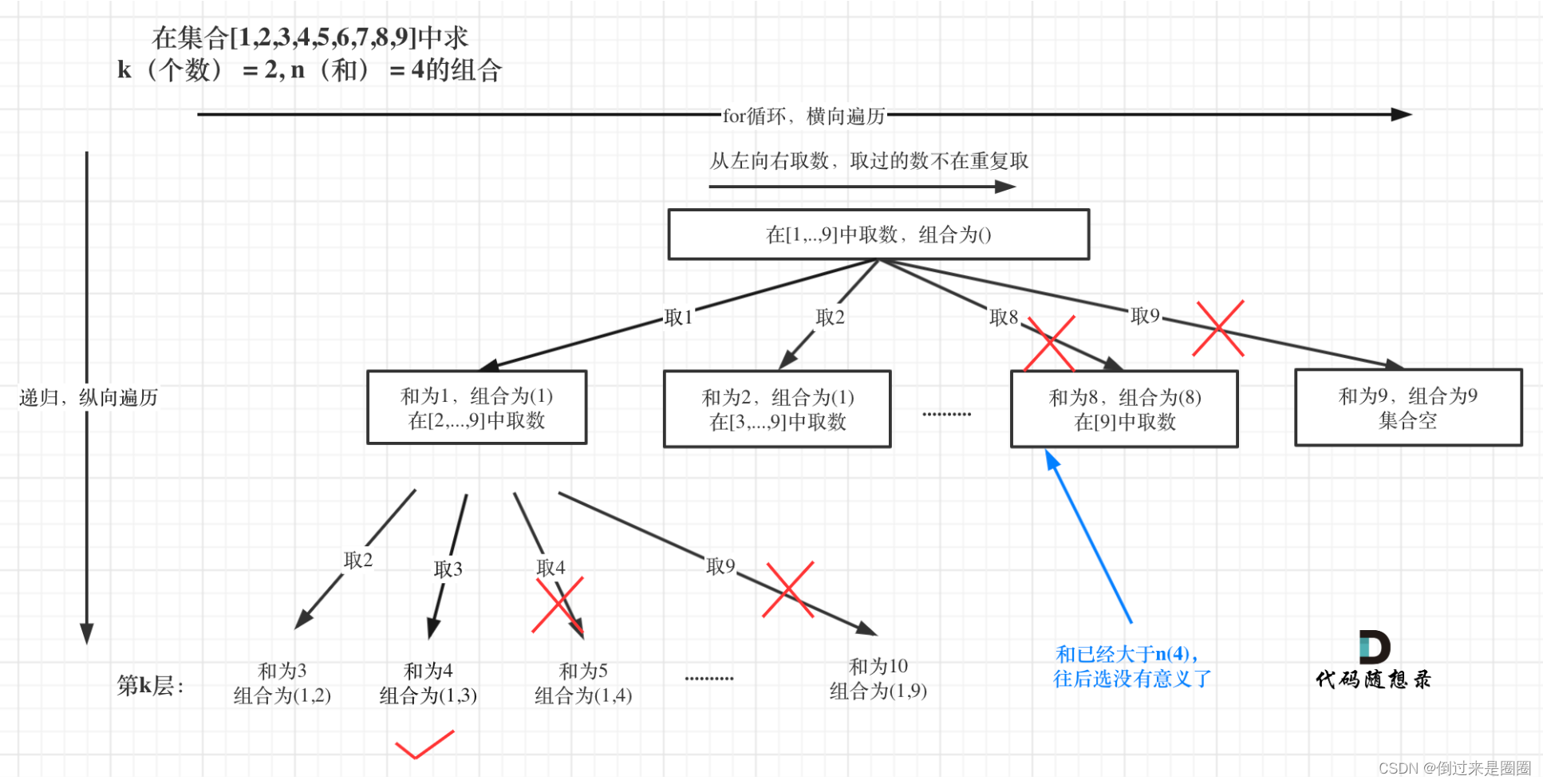
剪枝优化
两部分可以剪枝:
- 同77.组合,for循环的范围可以进行剪枝,
i<9-(k-path.size())+1,或者直接当path.size()>k时返回 - sum已经大于n时,往后遍历没有意义,直接剪掉,如下图所示:
剪枝后代码:
for(int i=index;i<=9-(k-path.size())+1;i++){
if(sum<=n){
path.add(i);
sum+=i;
dfs(n,k,i+1,sum);
sum-=i;
path.remove(path.size()-1);
}
}
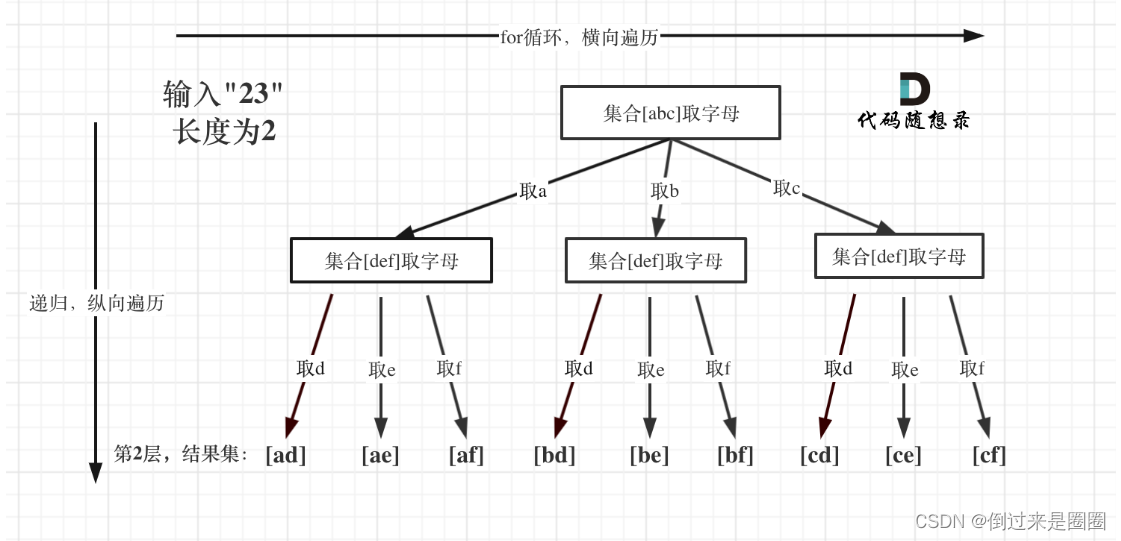
3. 电话号码的数字总和
17. 电话号码的字母组合
给定一个仅包含数字 2-9 的字符串,返回所有它能表示的字母组合。
给出数字到字母的映射如下(与电话按键相同)。注意 1 不对应任何字母。

递归树
回溯三部曲
- 递归函数参数
类似上一题 组合,同样需要path存放单次结果和res存放全部结果
除此之外,递归函数参数中,digits必然存在,另外还有int型的index参数。
需要注意的是,这里index的含义和77.组合以及216. 组合总和 III中表示起始位置的index不同,这里的index记录的是遍历的第几个数字,就是用来遍历digits的。
所以参数如下:
StringBuffer path=new StringBuffer();
List<List<Integer>>res=new ArrayList<>();
public void dfs(String digits,int index)
-
终止条件
依据题意,index==digits.length() 时终止递归 -
单层搜索过程
int num=digits.charAt(index)-'0';
String value=strs[num-2];//数字对应的字符集
for(int i=0;i<value.length();i++){
sb.append(value.charAt(i));
dfs(digits,index+1);//处理digits的下一个位置
sb.deleteCharAt(sb.length()-1);
}
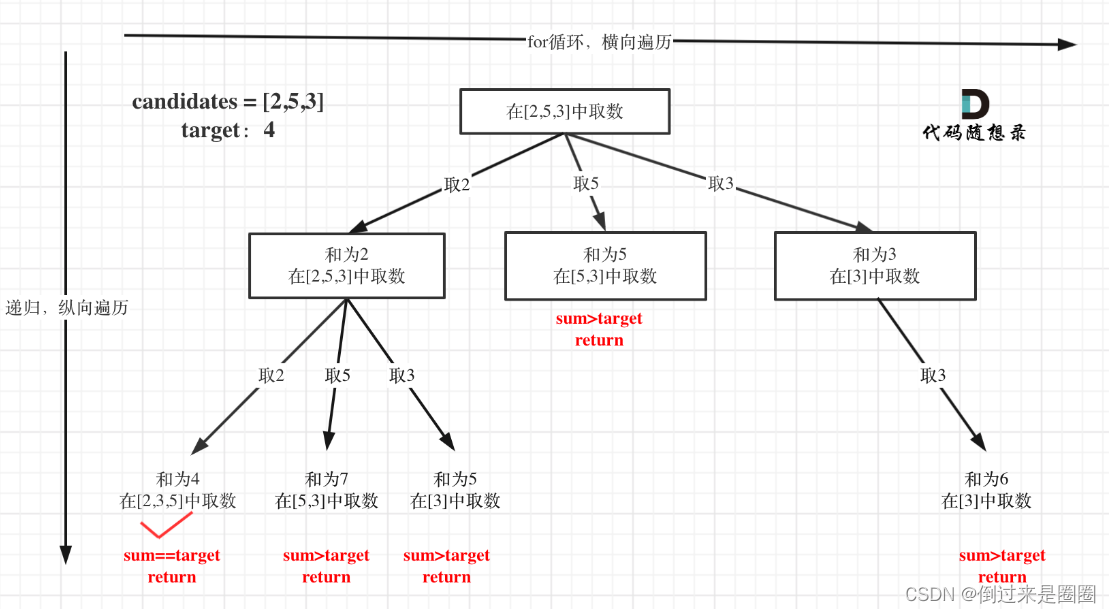
4. 组合总和
39. 组合总和
给定一个无重复元素的数组 candidates 和一个目标数 target ,找出 candidates 中所有可以使数字和为 target 的组合。
candidates 中的数字可以无限制重复被选取。
说明:
所有数字(包括 target)都是正整数。
解集不能包含重复的组合。
递归树
回溯三部曲
- 递归函数参数
path和res全局变量,是固定套路
递归函数中集合candidates和目标值target必存在,除此之外还需要sum来记录path中元素总和 以及 startIndex来控制for循环起始位置
这里衍生出的一个重要问题是,对于组合问题,什么时候需要 startIndex 作为循环开始位置呢?
如果是一个集合求组合,就需要startIndex,如:77.组合,216.组合总和III
如果是多个集合取组合,各个集合之间互不影响,就不用startIndex,如:17.电话号码的字母组合
注意以上仅针对组合问题,排列问题是另一个分析方法。 - 递归终止条件
sum==target时,收集结果并返回 - 单层搜索过程
for(int i=index;i<n;i++){
if(sum<target){//剪枝
path.add(candidates[i]);
dfs(candidates,target,i,sum+candidates[i]);//关键点:不需要i+1!表示可以重复读取当前元素
path.remove(path.size()-1);
}
}
总结
这题和之前的77.组合、216. 组合总和 III有两点不同:
- 组合没有数量要求(77和216都要求k个数的组合)
- 元素可无限重复选取(77和216都要求无重复数字)
对于组合问题,啥时候用startIndex,啥时候不用做了总结,主要对比17. 电话号码的字母组合题
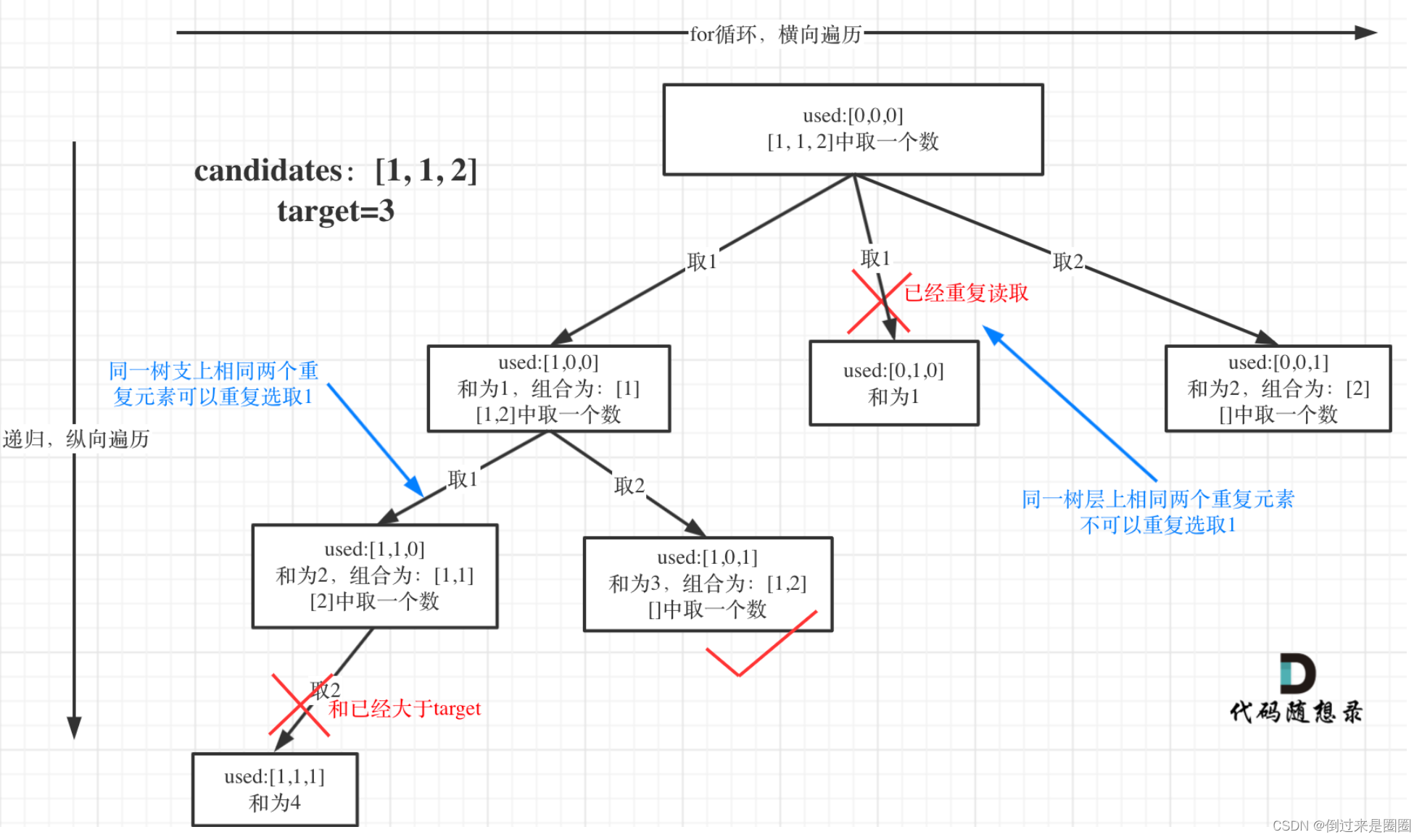
5. 组合总和II
40.组合总和II
给定一个数组 candidates 和一个目标数 target ,找出 candidates 中所有可以使数字和为 target 的组合。
candidates 中的每个数字在每个组合中只能使用一次。
说明: 所有数字(包括目标数)都是正整数。解集不能包含重复的组合。
递归树
这题和上一题39. 组合总和的主要区别如下:
- 39题集合中有重复数字,而本题集合中无重复数字
- 39题集合中数字可以无限次使用,而本题每个数字只能使用一次
本题难点在于:有重复数字,但是还不能有重复组合
回溯三部曲
- 递归函数参数
List<Integer>path=new ArrayList<>();
List<List<Integer>>res=new ArrayList<>();
public void dfs(int[] candidates,int target,int index,int sum){
-
递归终止条件
sum==target 时,收集结果并返回 -
单层搜索过程
需要额外注意的就是去重这里,“位于同一树层”&&“两元素相同”则跳过
for(int i=index;i<n;i++){
//对同一树层使用过的元素进行跳过
if(i>index&&candidates[i]==candidates[i-1])
continue;
if(sum<target){//剪枝
path.add(candidates[i]);
dfs(candidates,target,i+1,sum+candidates[i]);
path.remove(path.size()-1);
}
}
切割问题
切割问题类似于组合问题,例如对于字符串abcdef:
- 组合问题:选取一个a之后,在bcdef中再去选取第二个,选取b之后在cdef中再选取第三个…。
- 切割问题:切割一个a之后,在bcdef中再去切割第二段,切割b之后在cdef中再切割第三段…。
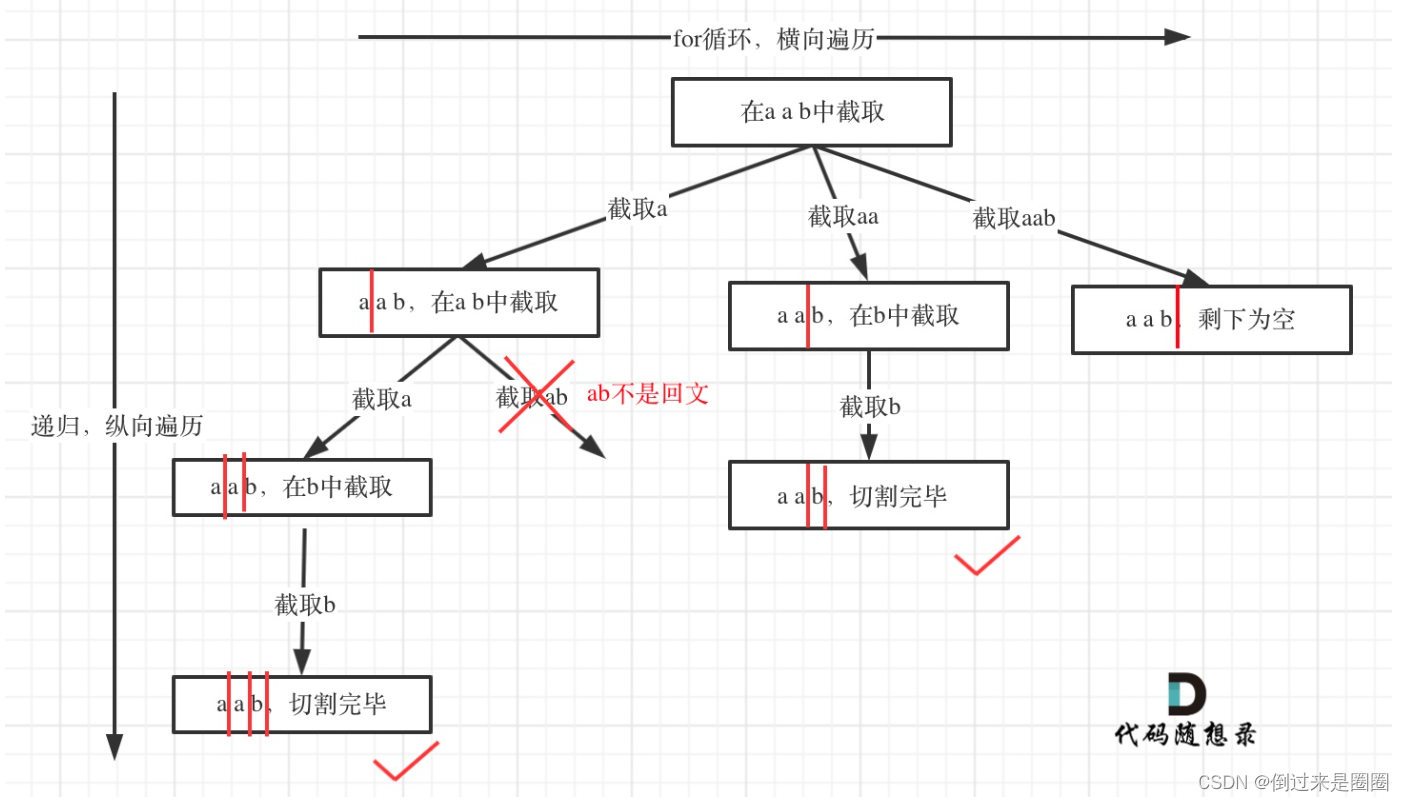
1. 分割字符串
131.分割回文串
给定一个字符串 s,将 s 分割成一些子串,使每个子串都是回文串。
返回 s 所有可能的分割方案。
示例: 输入: “aab” 输出: [ [“aa”,“b”], [“a”,“a”,“b”] ]
递归树
看递归树可以发现,切割问题的回溯搜索的过程和组合问题的回溯搜索的过程是差不多的。
回溯三部曲
- 递归函数参数
切割过的地方不能重复切割,因此需要startIndex参数,和组合问题保持一致
List<String>path=new ArrayList<>();
List<List<String>>res=new ArrayList<>();
public void dfs(String s,int startIndex)
- 递归终止条件
index>=s.length() 时,收集结果并返回 - 单层搜索过程
for(int i=index;i<n;i++){
//index到i是回文串,切割
if(isPalindrome(s,index,i)){
String str=s.substring(index,i+1);
path.add(str);
dfs(s,i+1);//不能重复切割,因此传入i+1
path.remove(path.size()-1);
}
}
那么如何判断字符串是回文串呢?
可以使用双指针法,一个指针从前向后,另一个指针从后向前,如果前后指针所指向的元素都是相等的,就是回文字符串了。
public boolean isPalindrome(String s,int start,int end){
for(int i=start,j=end;i<j;i++,j--){
if(s.charAt(i)!=s.charAt(j))
return false;
}
return true;
}
优化
优化的思路是:如何更高效的计算一个字符串是否是回文串?
对于字符串s,给定起始下标和终止下标,判断截取出的字符串是否为回文串,其中一定有重复计算存在:
例如给定“abcde”,在已知“bcd”不是回文串的情况下,不需要双指针判断“abcde”而可以直接判定它一定不是回文串。
具体来说,给定一个字符串s,长度为n,它成为回文串的充要条件是s[0]==s[n-1]且s[1,…,n-2]是回文串。因此使用动态规划的方法对回文串判断进行改进。
对于动态规划的方法,先一次性计算出,对于字符串s,它的任何子串是否是回文串,然后在回溯函数中直接查询即可,省去了双指针移动判断这一步骤。
代码如下:
//动态规划计算s的各个子串是否是回文串
f=new boolean[n][n];
for(int i=n-1;i>=0;i--){
//需要倒序判断,保证第i行时,第i+1行已经计算好了
for(int j=i;j<n;j++){
char t1=s.charAt(i),t2=s.charAt(j);
if(i==j)
f[i][j]=true;
//相邻字符串
else if(j-i==1)
f[i][j]=(t1==t2);
else
f[i][j]=(t1==t2&&f[i+1][j-1]);
}
}
//回溯过程
for(int i=index;i<n;i++){
if(f[index][i]){
String str=s.substring(index,i+1);
path.add(str);
dfs(s,i+1);
path.remove(path.size()-1);
}
}
总结
总结一下本题的难点:
- 如何模拟切割线
- 切割问题中递归如何终止
- 在递归循环中如何截取子串
- 如何判断回文
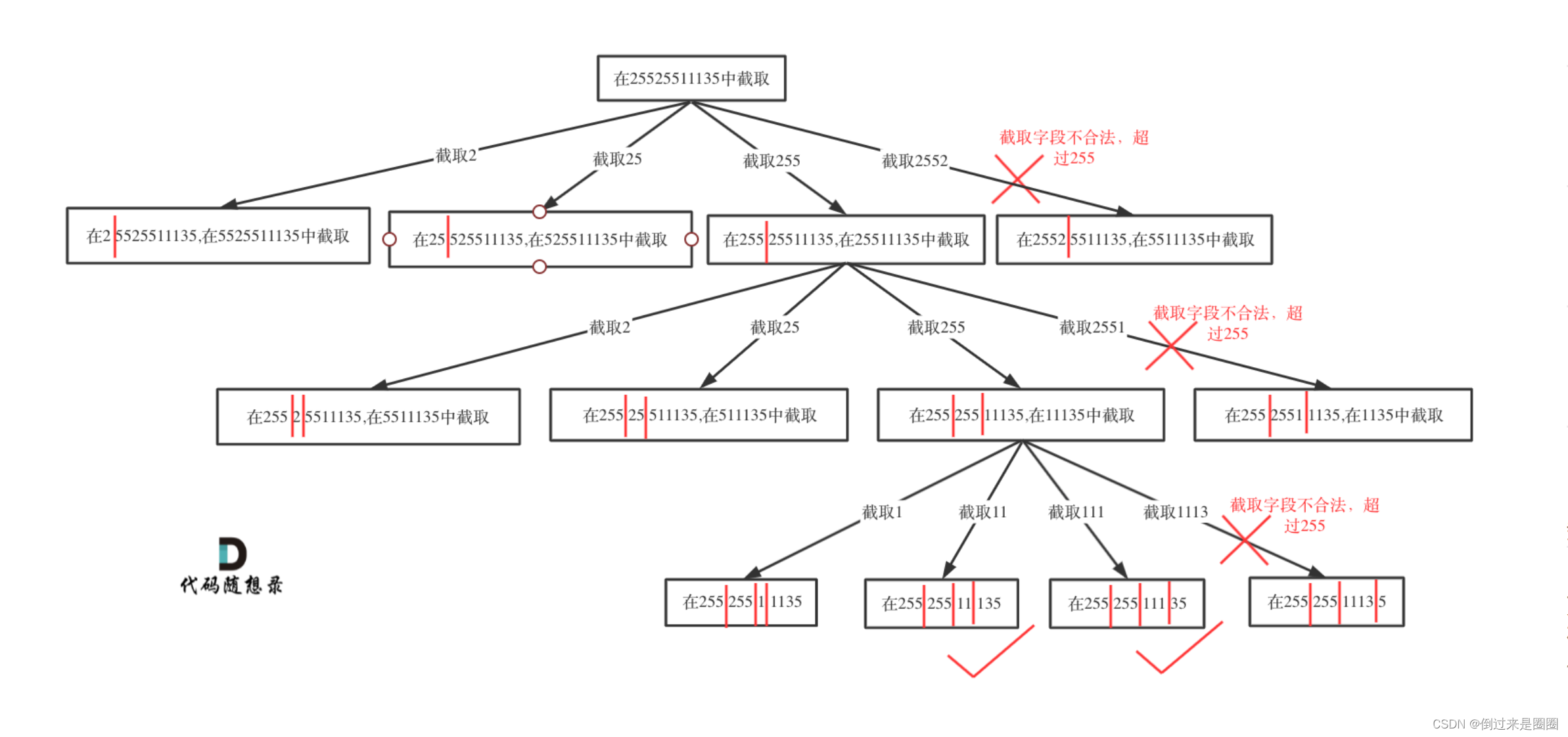
2. 复原IP地址
93.复原IP地址
给定一个字符串 s,将 s 分割成一些子串,使每个子串都是回文串。
返回 s 所有可能的分割方案。
示例: 输入: “aab” 输出: [ [“aa”,“b”], [“a”,“a”,“b”] ]
递归树
回溯三部曲
- 递归函数参数
由于不能重复分割,因此index一定是需要的,记录下一层递归分割的开始位置
对于本题还需要一个变量 pointNum ,记录IP地址中加逗号的数量。
所以代码如下:
List<String>res=new ArrayList<>();
public void dfs(String s,int index,int poinNum)
- 递归终止条件
由于涉及IP地址,而不是简单的切割,因此与131.分割回文串还不一样
本题明确要求分成4段,所以不能用切割线切到最后作为终止条件!
pointNum表示逗号数量,因此当pointNum为3时说明字符串分为4段了,如果此时第四段合法,则加入结果集中
代码如下:
if(pointNum==3){
注意这里一定要用s.length()而不能用n,因为s要加分割符,长度会变!
if(isValid(s,index,s.length()-1))
res.add(s);
return;
}
- 单层搜索过程
- 截取子串
切割后的字符串如果合法,就在后面加上“.”
如果不合法,则结束本层循环 - 递归和回溯过程
递归调用时,下一层递归开始的index要从 i+2 开始(因为在字符串中添加了“.”),同时记录分隔符数目的pointNum要+1
回溯的时候,将添加的“.”删掉,并且pointNum要-1
for(int i=index;i<s.length();i++){
if(isValid(s,index,i)){
s=s.substring(0,i+1)+"."+s.substring(i+1);//添加.
dfs(s,i+2,pointNum+1);
s=s.substring(0,i+1)+s.substring(i+2);//删掉.
}
else
break;//不合法直接结束本层循环
}
判断子串是否合法
主要考虑如下三点:
- 段位以0开头不合法
- 段位含有非正整数字符不合法
- 段位大于255不合法
isValid函数代码如下:
//判断字符串s在左闭右闭区间[start, end]所组成的数字是否合法
public boolean isValid(String s,int start,int end){
if(start>end)
return false;
//以0开头
if(s.charAt(start)=='0'&&start!=end)
return false;
int num=0;
for(int i=start;i<=end;i++){
char ch=s.charAt(i);
//含非正整数字符
if(ch<'0'||ch>'9')
return false;
//大于255
num=num*10+(ch-'0');
if(num>255)
return false;
}
return true;
}
子集问题
1. 子集
78.子集
给定一组不含重复元素的整数数组 nums,返回该数组所有可能的子集(幂集)。
说明:解集不能包含重复的子集。你可以按 任意顺序 返回解集。
示例: 输入: “aab” 输出: [ [“aa”,“b”], [“a”,“a”,“b”] ]
递归树
如果把子集问题、组合问题、分割问题都抽象成一棵树的话,那么组合问题和分割问题都是收集树的叶子节点,而子集问题是找树的所有节点!
子集也是一种组合问题,因为它的集合是无序的,子集{1,2}和{2,1}是一样的
那么既然是无序的,取过的元素不会重复取,写回溯算法的时候,for就要从startIndex开始,而不是从0开始!
求子集问题抽象成递归树如下:
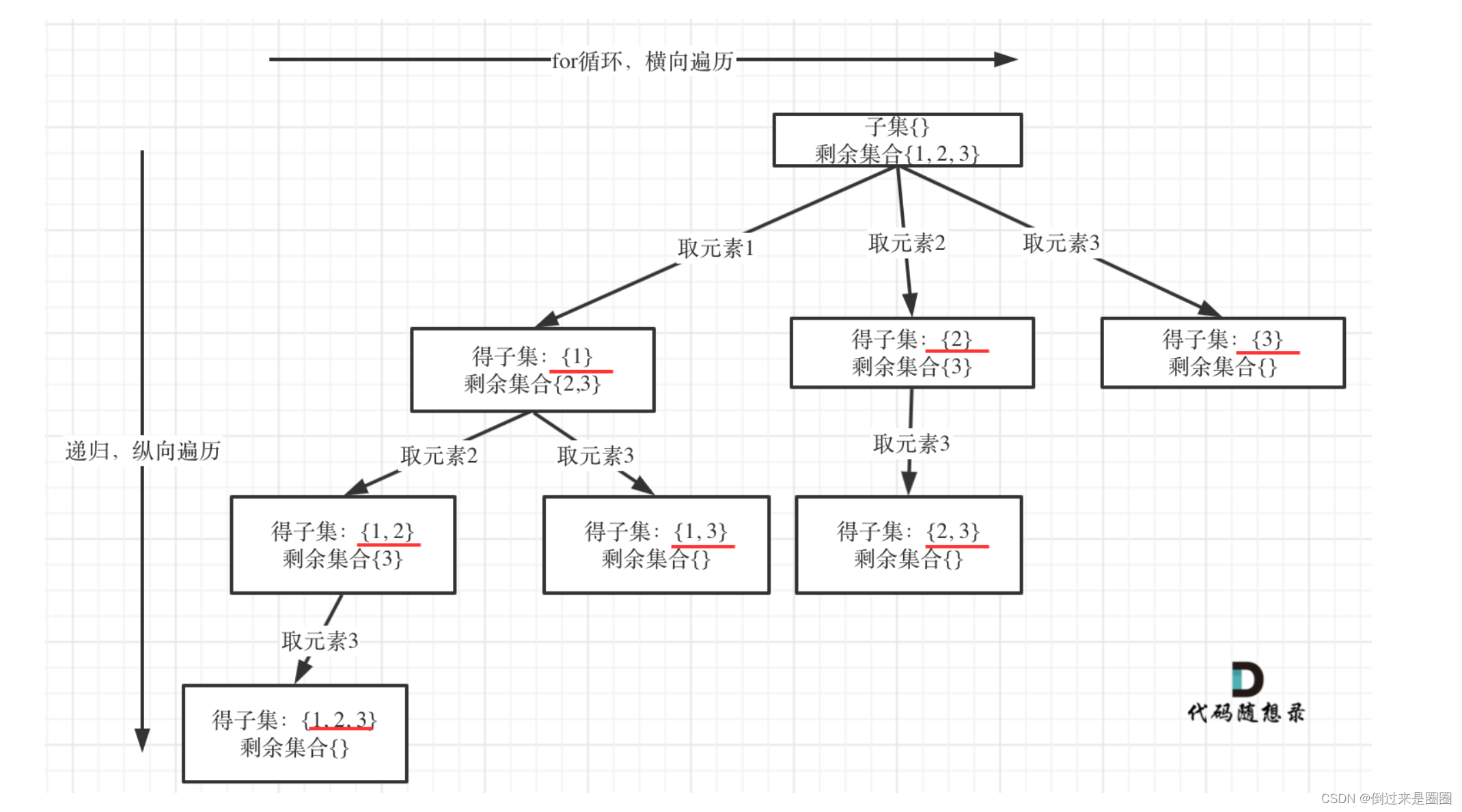
从图中红线部分,可以看出遍历这个树的时候,把所有节点都记录下来,就是要求的子集集合。
回溯三部曲
-
递归函数参数
常规参数:单次结果path,全部结果res,数组nums,递归开始位置startIndex。 -
递归终止条件
从递归树中可以看出,剩余集合为空的时候,就是叶子节点。
那么什么时候剩余集合为空呢?
就是startIndex > 数组长度的时候,终止。
但其实可以不用加终止条件,因为startIndex>=nums.length,本层for循环本来也结束了。 -
单层搜索过程
求取子集问题,不需要任何剪枝!因为子集就是要遍历整棵树!
for(int i=index;i<n;i++){
path.add(nums[i]);
dfs(nums,i+1);
path.remove(path.size()-1);
}
跟上述组合、切割问题比起来,子集问题还是蛮简单的
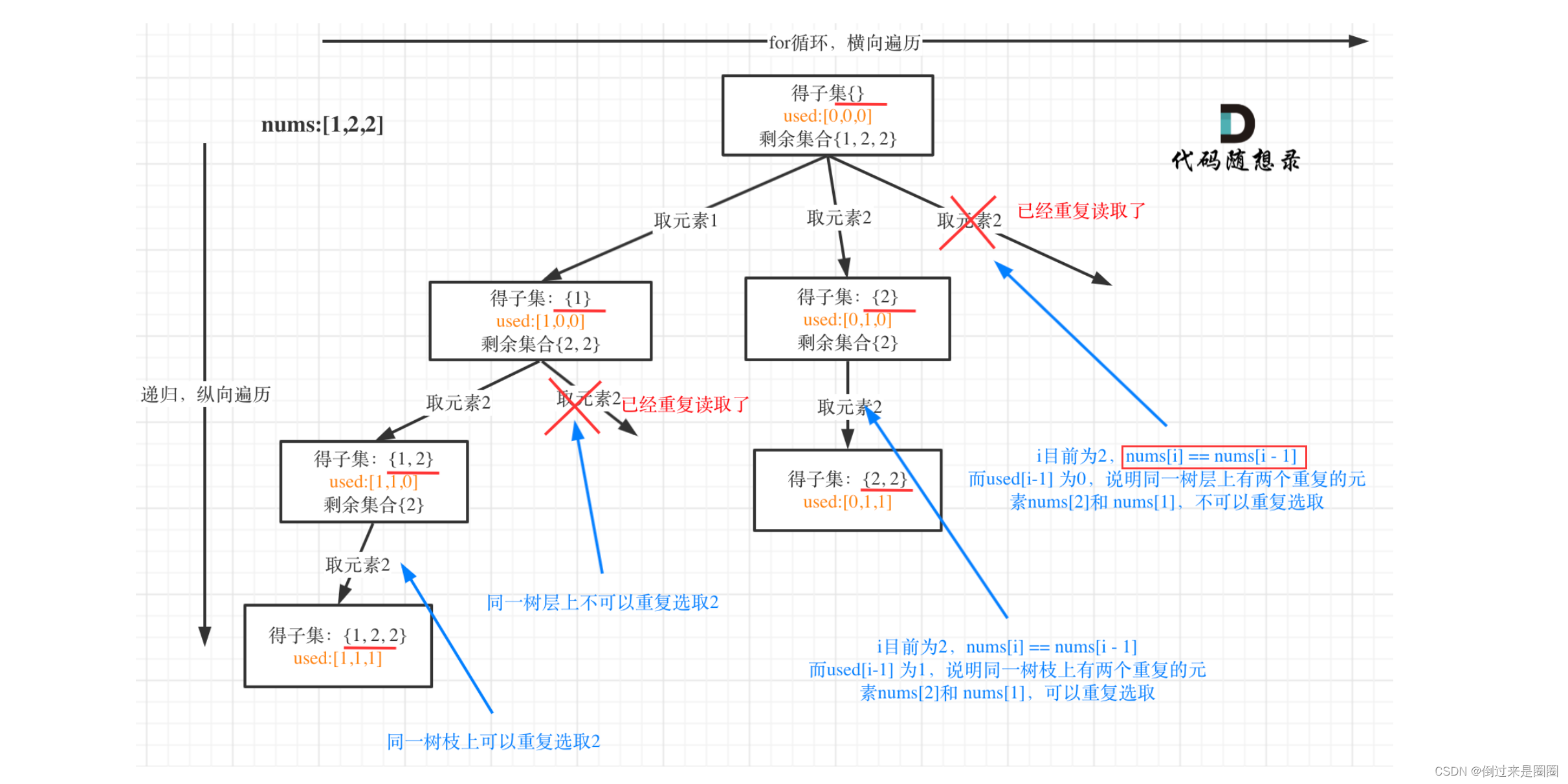
2. 子集II
90.子集II
给定一个可能包含重复元素的整数数组 nums,返回该数组所有可能的子集(幂集)。
说明:解集不能包含重复的子集。
示例:
输入: [1,2,2]
输出: [ [2], [1], [1,2,2], [2,2], [1,2], [] ]
递归树
子集+去重的一道题
子集可以参考上一题,去重参考40.组合总和II
本题过于简单,甚至没有回溯三部曲,代码如下:
class Solution {
int n;
List<Integer>path=new ArrayList<>();
List<List<Integer>>res=new ArrayList<>();
public List<List<Integer>> subsetsWithDup(int[] nums) {
n=nums.length;
Arrays.sort(nums);
dfs(nums,0);
return res;
}
public void dfs(int[] nums,int index){
res.add(new ArrayList<>(path));
for(int i=index;i<n;i++){
if(i>index&&nums[i]==nums[i-1])
continue;
path.add(nums[i]);
dfs(nums,i+1);
path.remove(path.size()-1);
}
}
}
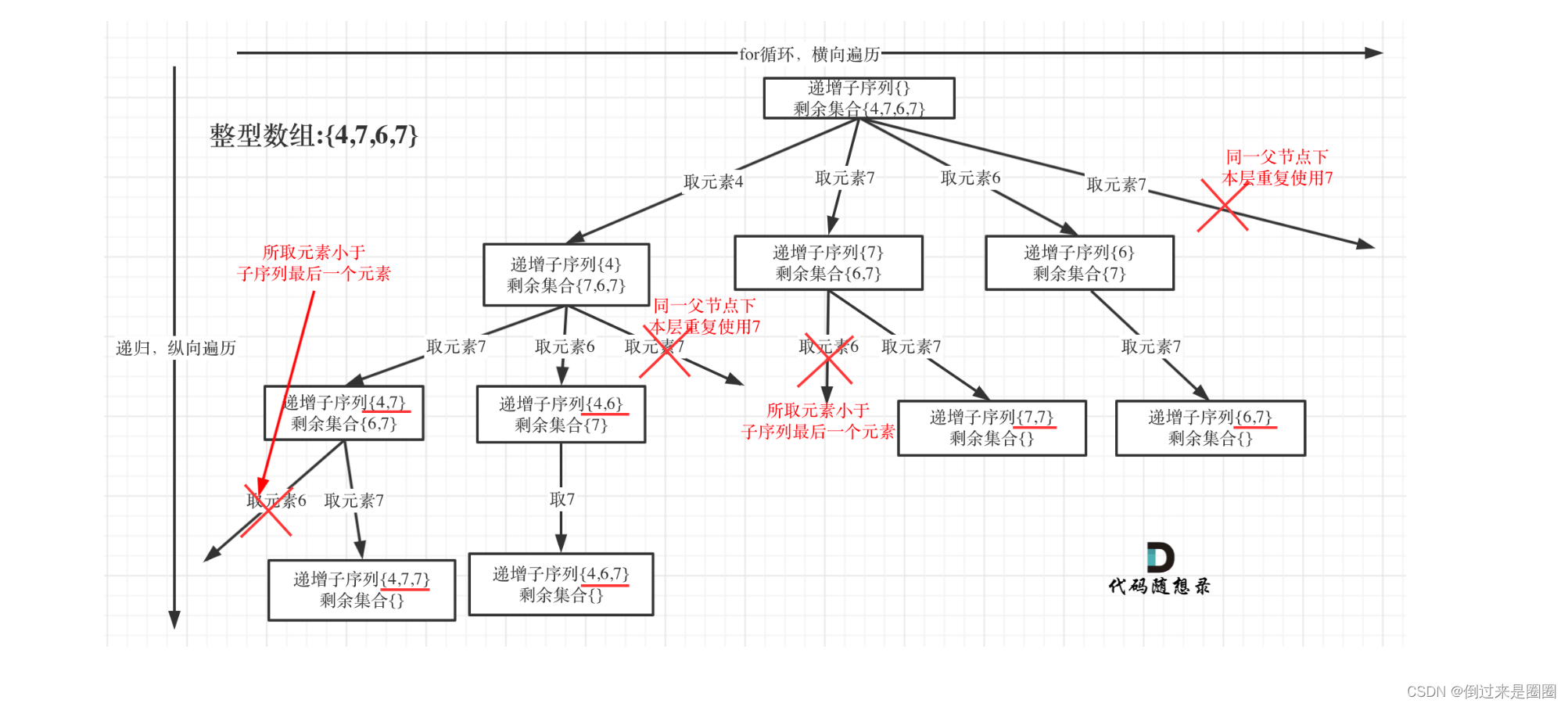
3. 递增子序列
491.递增子序列
给定一个整型数组, 你的任务是找到所有该数组的递增子序列,递增子序列的长度至少是2。
示例:
输入: [4, 6, 7, 7]
输出: [[4, 6], [4, 7], [4, 6, 7], [4, 6, 7, 7], [6, 7], [6, 7, 7], [7,7], [4,7,7]]
说明:
给定数组的长度不会超过15。
数组中的整数范围是 [-100,100]。
给定数组中可能包含重复数字,相等的数字应该被视为递增的一种情况。
递归树
本题递增子序列类似取有序的子集,且不能有重复的子序列出现,即需要去重
但是!本题要求的是递增子序列,是不能对原数组进行排序的!因此不能使用之前的去重逻辑!
(原有去重逻辑:先sort,再剔除nums[i]==nums[i-1]的)
回溯三部曲
- 递归函数参数
List<Integer>path=new ArrayList<>();
List<List<Integer>>res=new ArrayList<>();
public void dfs(int[] nums,int index)
- 递归终止条件
//注意这里不要return,因为要返回树上所有节点
if(path.size()>=2){
res.add(new ArrayList<>(path));
}
- 单层搜索过程
从递归树中可以看出,同一父节点下的同层使用过的元素就不能再使用了

本题去重方法:利用used数组,同层遍历过的数组元素used=1,否则为0
int[] used=new int[201];
for(int i=index;i<n;i++){
//非递增 或者 同层已经遍历过了,跳过
if((!path.isEmpty()&&nums[i]<path.get(path.size()-1))||used[nums[i]+100]==1)
continue;
path.add(nums[i]);
used[nums[i]+100]=1;//加100是为了避免下标出现负数,nums值最小为-100
dfs(nums,i+1);
path.remove(path.size()-1);
}
排列问题
1. 全排列
46.全排列
给定一个 没有重复 数字的序列,返回其所有可能的全排列。
示例:
输入: [1,2,3]
输出: [ [1,2,3], [1,3,2], [2,1,3], [2,3,1], [3,1,2], [3,2,1] ]
递归树
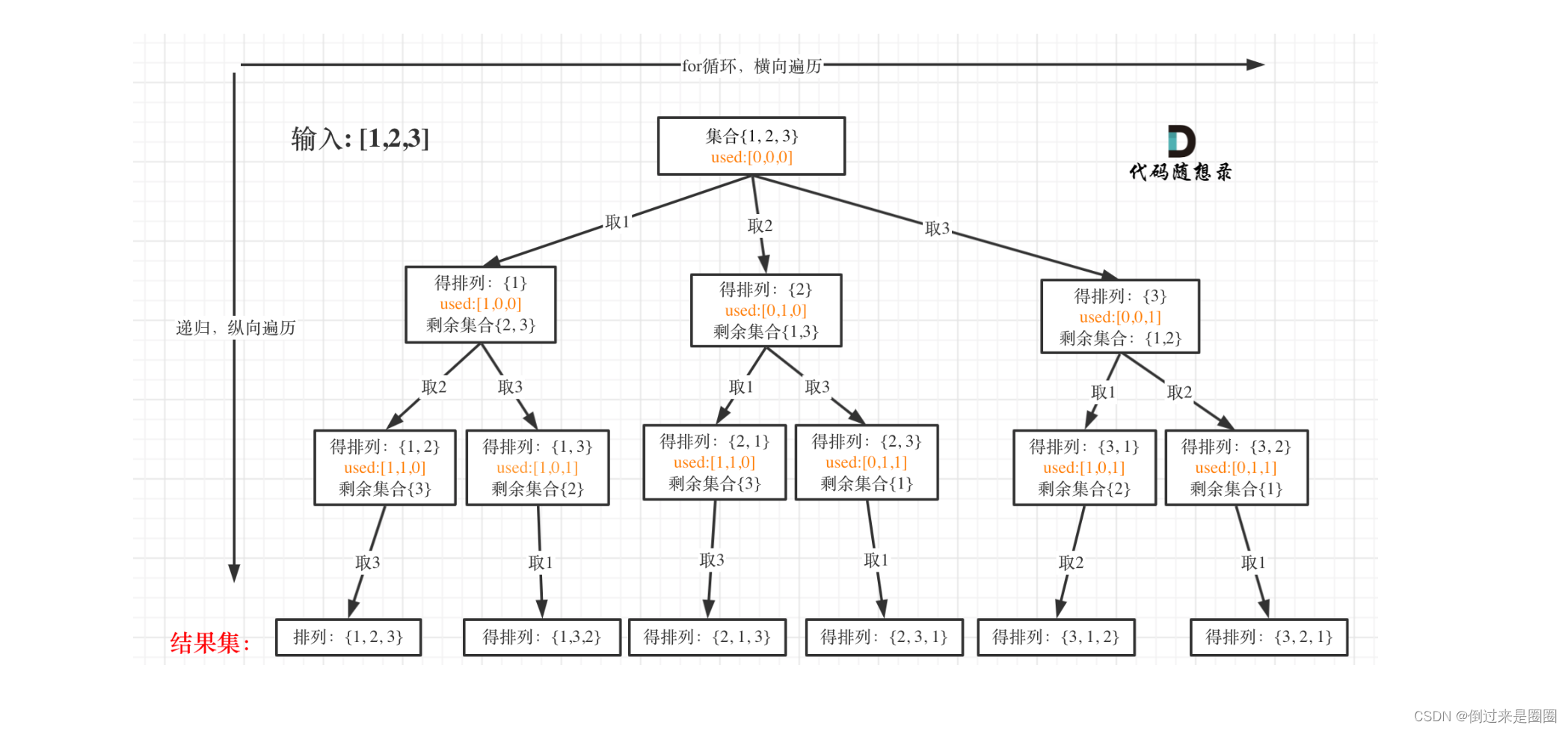
回溯三部曲
首先,排列是有序的!{1,2} 和 {2,1} 是两个不同的排列,这是和子集以及组合问题不同的地方。
- 递归函数参数
排列问题需要used数组,标记已经选择的元素
boolean[] used;//记录数组中每个元素是否被使用过
List<Integer>path=new ArrayList<>();
List<List<Integer>>res=new ArrayList<>();
public void dfs(int[] nums)
- 递归终止条件
观察递归树,什么时候到达叶子节点呢?path中元素个数==nums.length时
if(path.size()==n){
res.add(new ArrayList<>(path));
return;
}
- 单层搜索过程
排列问题每次都要从头开始搜索,例如元素1已经在{1,2}中用过了,但是还要在{2,1}中再用一次。
因此需要used数组,记录当前path中哪些元素使用过了,一个排列里一个元素只能使用一次。
for(int i=0;i<n;i++){
if(!used[i]){
path.add(nums[i]);
used[i]=true;
dfs(nums);
used[i]=false;
path.remove(path.size()-1);
}
}
总结
此时应该能感受到排列问题的不同:
- 每层都是从0开始!而不是startIndex
- 需要used数组记录path里都放了哪些元素!
2. 全排列II
47.全排列 II
给定一个可包含重复数字的序列 nums ,按任意顺序 返回所有不重复的全排列。
示例 :
输入:nums = [1,1,2]
输出: [[1,1,2], [1,2,1], [2,1,1]]
递归树
这道题目和46.全排列的区别在与给定一个可包含重复数字的序列,要返回所有不重复的全排列。
这里又涉及到去重了。
去重一定要对元素进行排序,这样才方便通过相邻节点判断是否重复使用了。
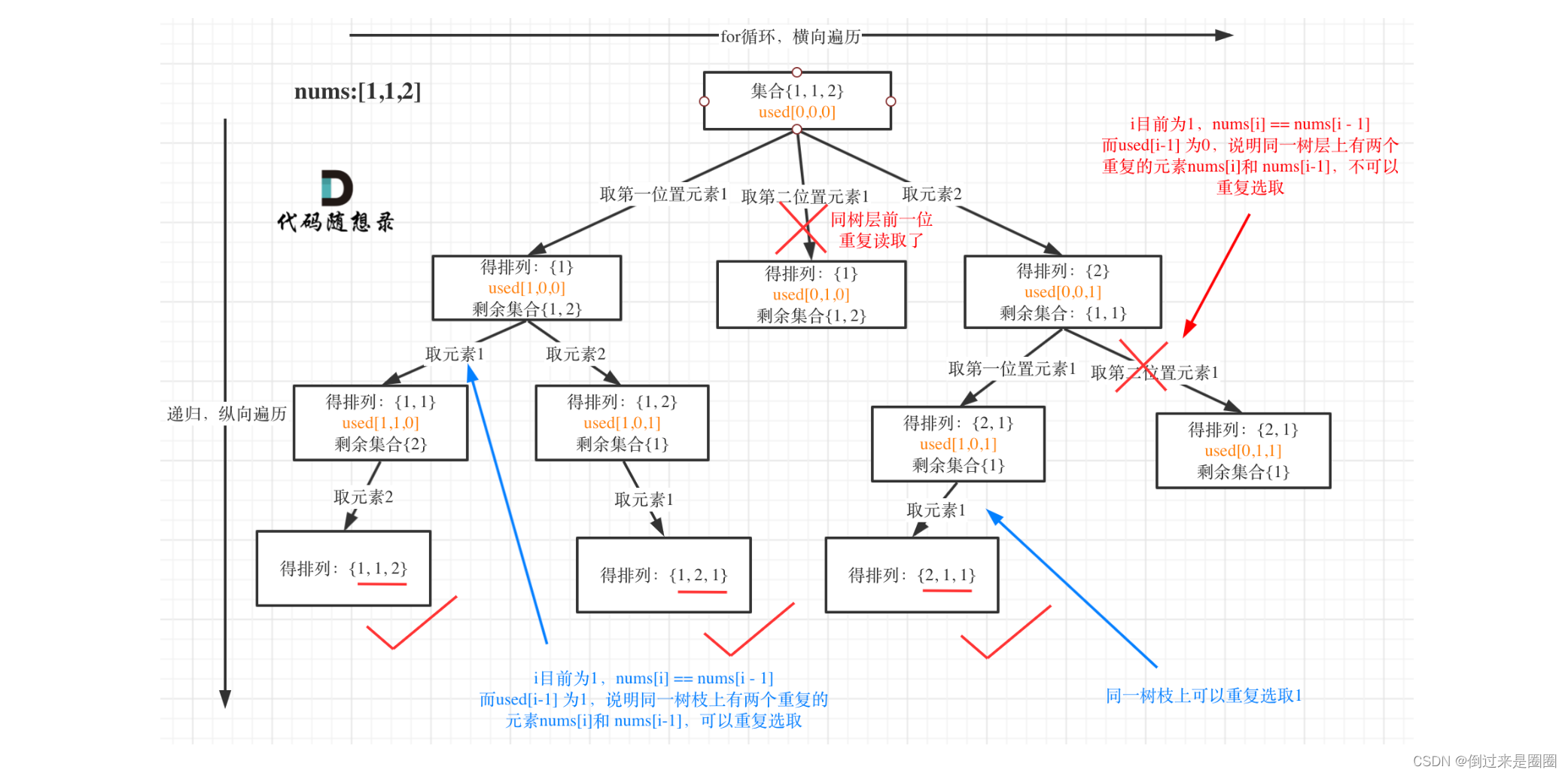
图中我们对同一树层,前一位如果使用过,那么就进行去重。
一般来说,
- 组合、排列问题:叶子节点上收集结果
- 子集问题:取树上所有节点的结果。
回溯三部曲
public void dfs(int[] nums){
//递归终止条件
if(path.size()==n){
res.add(new ArrayList<>(path));
return;
}
for(int i=0;i<n;i++){
//used[i-1] == true,说明同一树枝nums[i-1]使用过
//used[i-1] == false,说明同一树层nums[i-1]使用过
//如果同一树层nums[i-1]使用过则直接跳过
if(i>0&&nums[i]==nums[i-1]&&used[i-1]==false)
continue;
if(!used[i]){
path.add(nums[i]);
used[i]=true;
dfs(nums);
used[i]=false;
path.remove(path.size()-1);
}
}
}
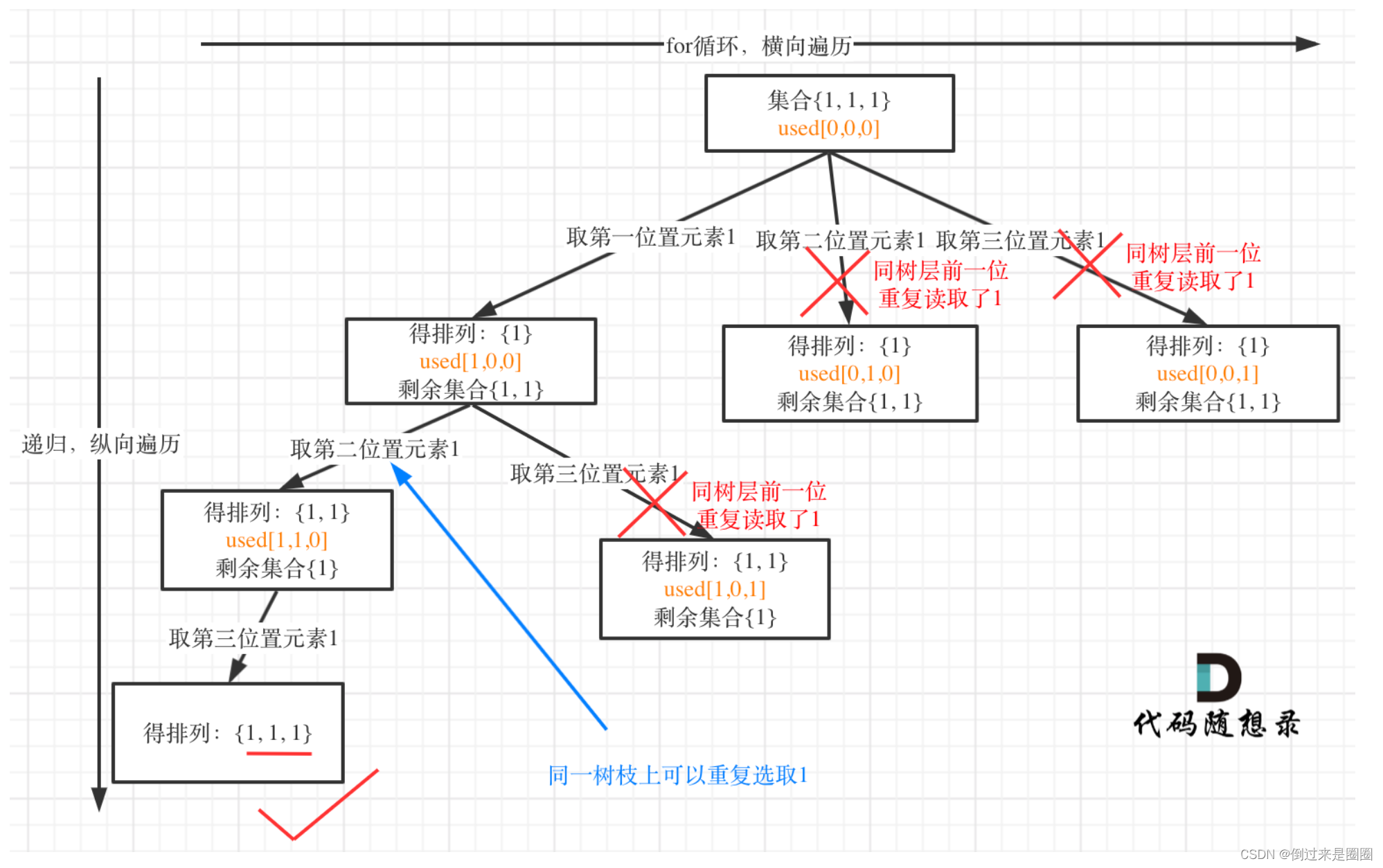
拓展
去重最关键的部分:
if(i>0&&nums[i]==nums[i-1]&&used[i-1]==false)
continue;
如果改成used[i]==true也是正确的!
if(i>0&&nums[i]==nums[i-1]&&used[i-1]==true)
continue;
这是为什么呢?
used[i-1] == false:树层前一位去重
used[i-1] == true:树枝前一位去重
用[1,1,1]举个例子:
树层上去重(used[i-1] == false)的树形结构如下:
树枝上去重(used[i-1] == true)的树形结构如下:
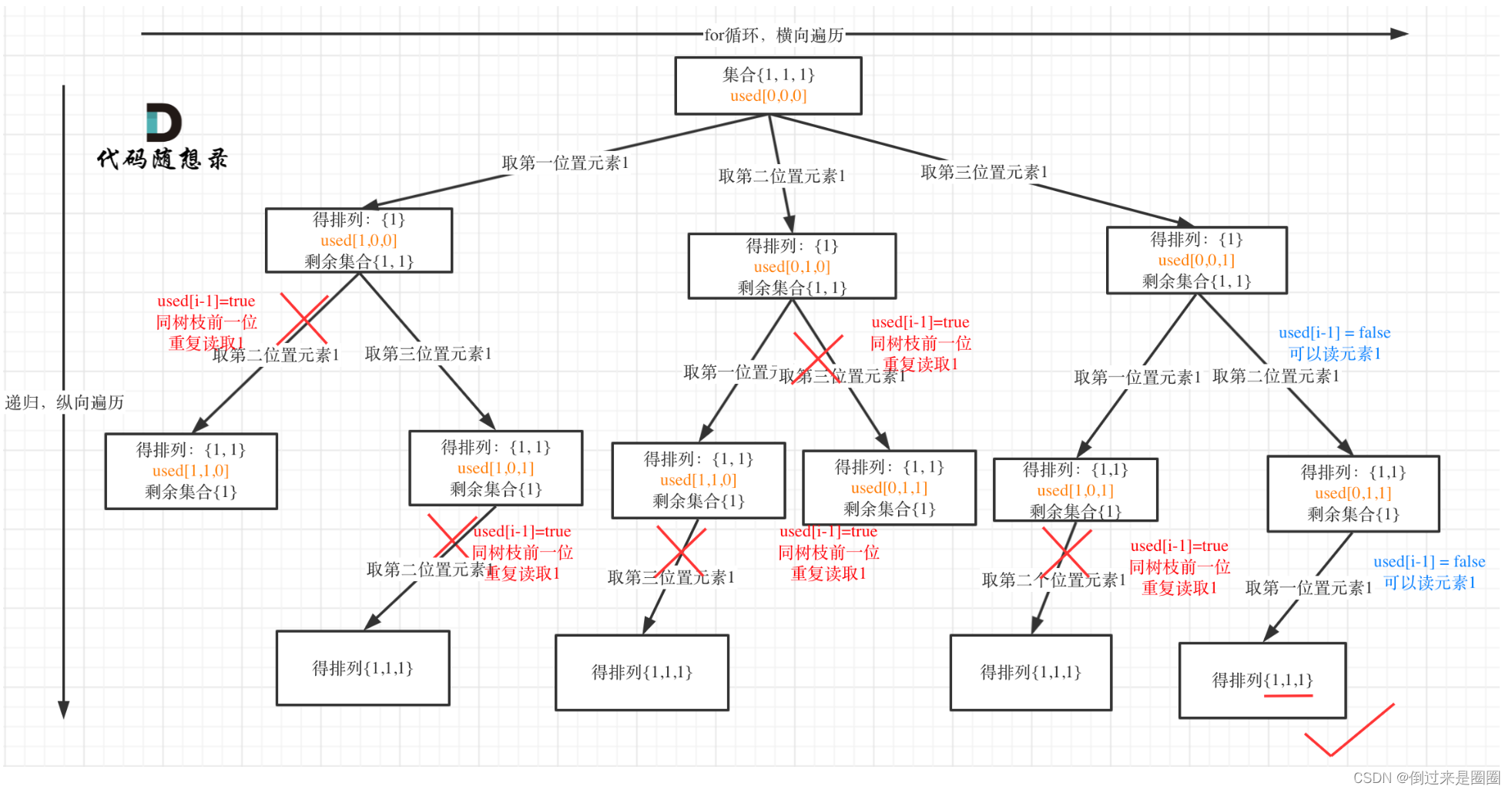
树层上对前一位去重非常彻底,效率很高,树枝上对前一位去重虽然可以得到最后的答案,但做了很多无用的搜索。
棋盘问题
N皇后
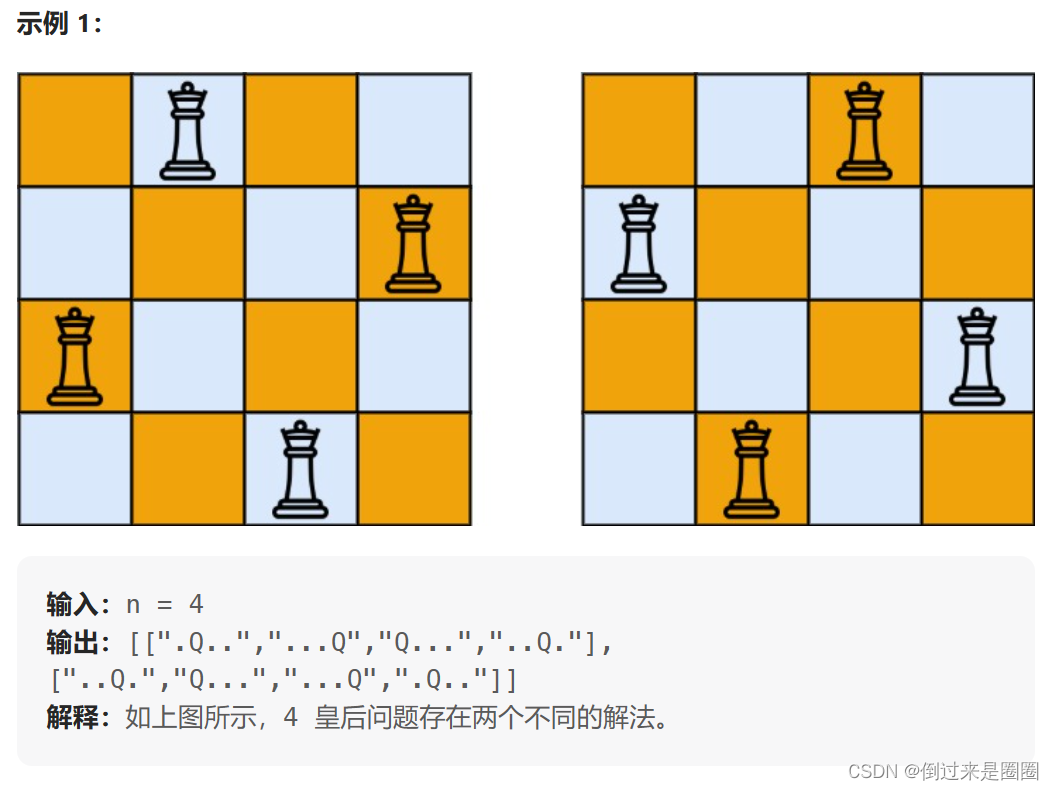
51. N 皇后
按照国际象棋的规则,皇后可以攻击与之处在同一行或同一列或同一斜线上的棋子。
n 皇后问题 研究的是如何将n个皇后放置在n×n的棋盘上,并且使皇后彼此之间不能相互攻击。
给你一个整数n ,返回所有不同的n皇后问题的解决方案。
每一种解法包含一个不同的 n 皇后问题 的棋子放置方案,该方案中 ‘Q’ 和 ‘.’ 分别代表了皇后和空位。
递归树
首先确定n皇后问题的约束条件:
- 不能同行
- 不能同列
- 不能同斜线
然后去看看怎么确定皇后的位置,可以抽象为一棵树。
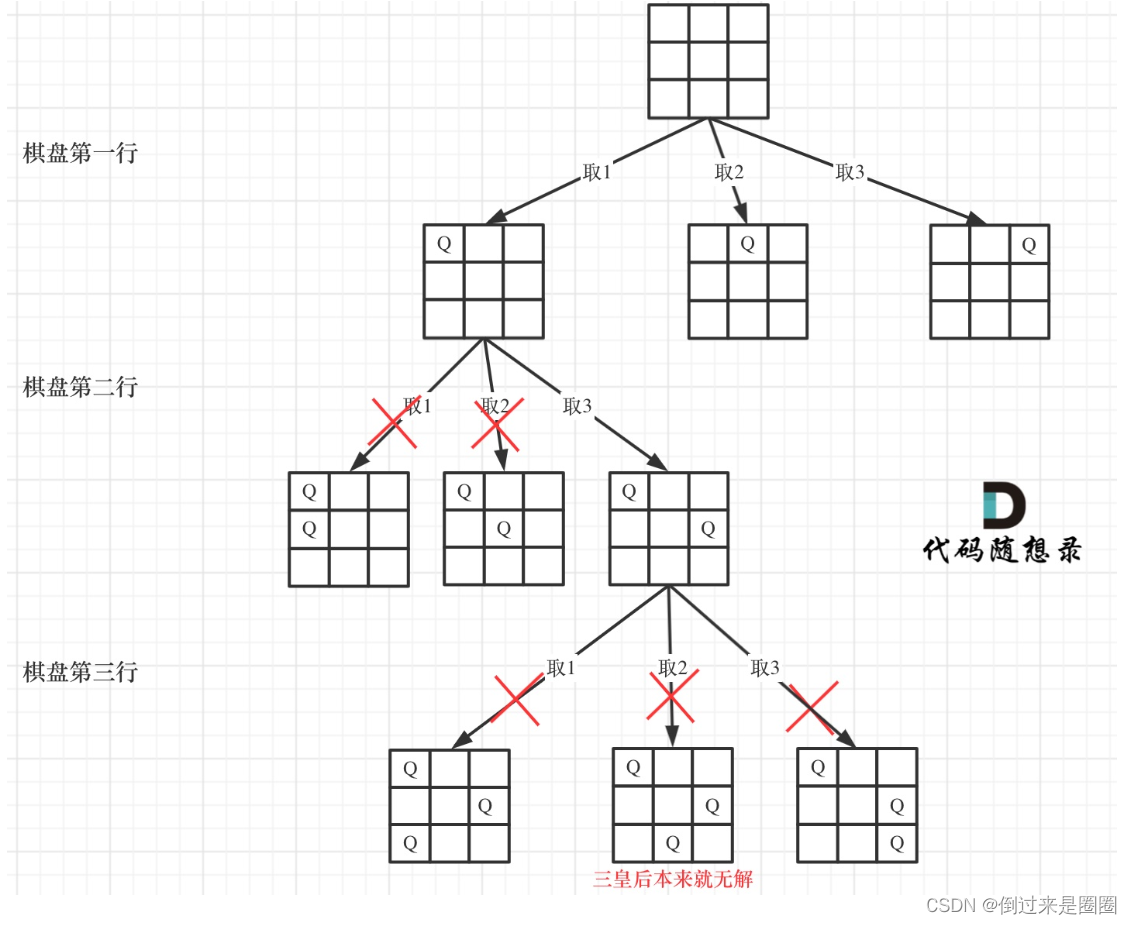
从图中可以看出,二维矩阵的高度就是这棵树的高度,矩阵的宽就是树形结构中每一个节点的宽度。
我们用皇后的约束条件,来回溯搜索这棵树,只要搜索到了树的叶子节点,说明就找到了皇后们的合理位置。
回溯三部曲
- 递归函数参数
n是矩阵的行列数,row记录当前遍历到棋盘的第几层了。
List<List<String>>res=new ArrayList<>();
public void dfs(int n,int row,char[][] chessboard)
- 递归终止条件
递归到叶子节点(棋盘到底了),即row==n时,收集结果并返回。
if(row==n){
res.add(Array2List(chessboard));
return;
}
//char[][]转List
public List Array2List(char[][] chessboard){
List<String>list=new ArrayList<>();
for(char[] c:chessboard){
list.add(String.copyValueOf(c));
}
return list;
}
- 单层搜索过程
row控制棋盘的行,也就是递归深度;col控制棋盘的列,确定皇后的放置位置。
每一行都是从第0列开始搜,因此col都是从0开始。
for(int col=0;col<n;col++){
if(isValid(row,col,n,chessboard)){//位置合法才可以放
chessboard[row][col]='Q';//放置皇后
dfs(n,row+1,chessboard);
chessboard[row][col]='.';//撤回皇后
}
}
- 验证棋盘是否合法
按照棋盘的三个约束条件,不能同行同列同斜线(45度和135度)进行去重。
如果左斜上方已经放置了皇后,则该位置不合法不能再放置皇后。
public boolean isValid(int row,int col,int n,char[][] chessboard){
//同列无皇后
for(int i=0;i<row;i++){
if(chessboard[i][col]=='Q')
return false;
}
//右斜上无皇后
for(int i=row-1,j=col+1;i>=0&&j<n;i--,j++){
if(chessboard[i][j]=='Q')
return false;
}
//左斜上无皇后
for(int i=row-1,j=col-1;i>=0&&j>=0;i--,j--){
if(chessboard[i][j]=='Q')
return false;
}
return true;
}
解数独
37. 解数独
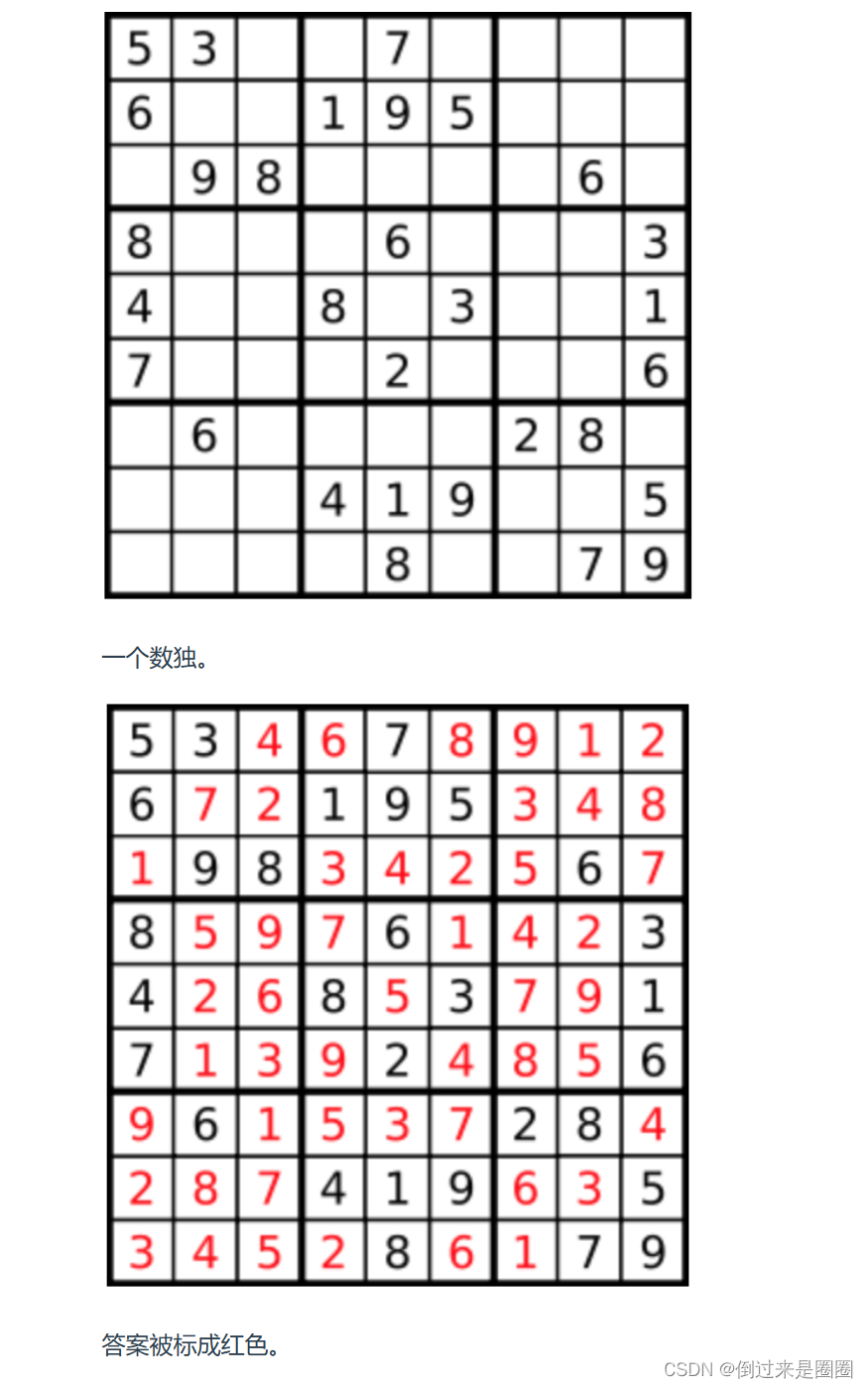
编写一个程序,通过填充空格来解决数独问题。
数独的解法需 遵循如下规则:
数字 1-9 在每一行只能出现一次。
数字 1-9 在每一列只能出现一次。
数字 1-9 在每一个以粗实线分隔的 3x3 宫内只能出现一次。(请参考示例图)
数独部分空格内已填入了数字,空白格用 ‘.’ 表示。
提示:
- 给定的数独序列只包含数字 1-9 和字符 ‘.’ 。
- 你可以假设给定的数独只有唯一解。
- 给定数独永远是 9x9 形式的。
递归树
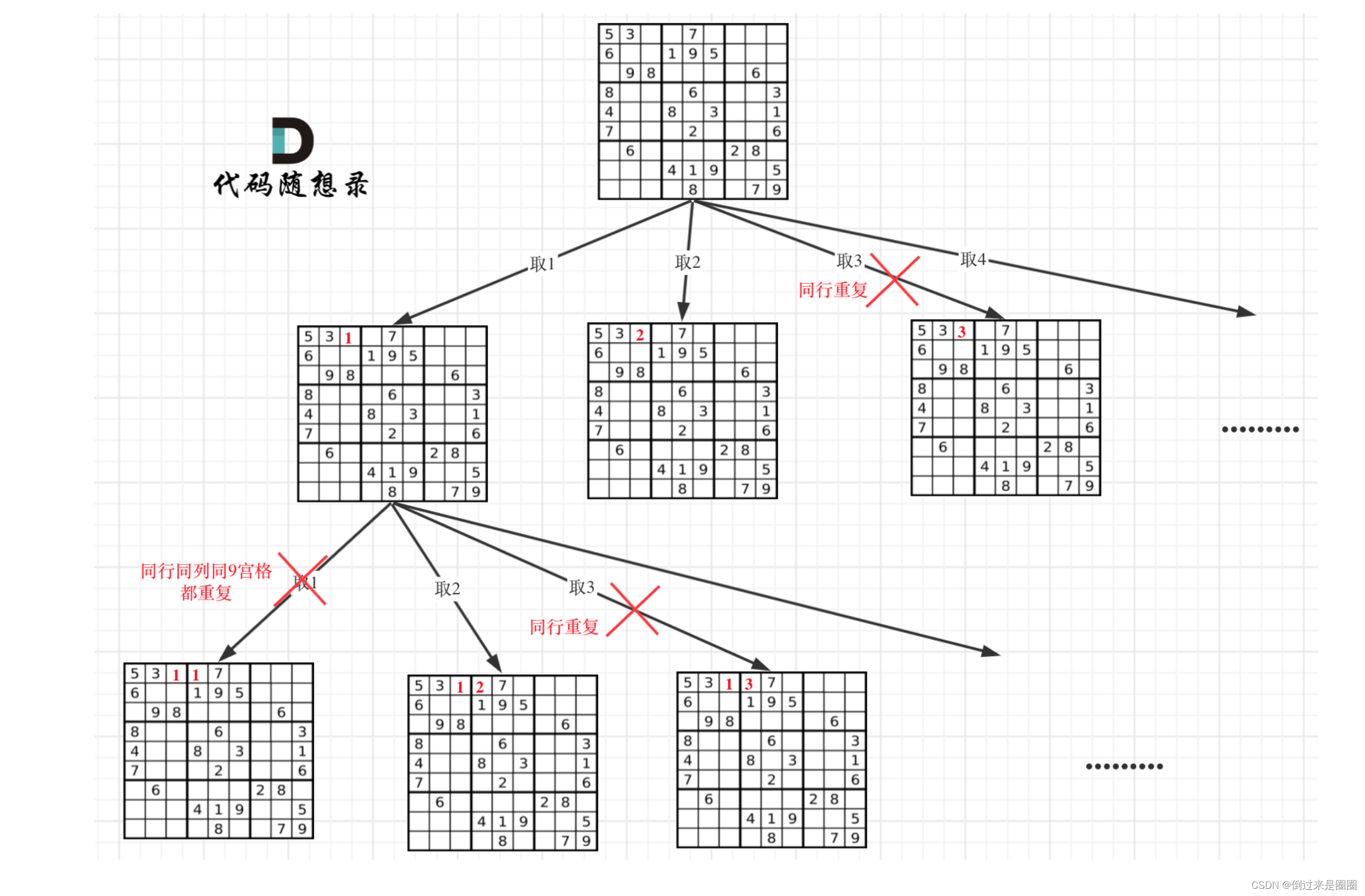
本题要做的是二维递归!
N皇后问题是因为每行每列只放一个皇后,只需要一层for循环遍历一行,递归来遍历列,然后一行一列确定皇后的唯一位置。
本题就不一样了,棋盘中的每一个位置都需要放置一个数字(N皇后一行只放一个皇后),并检查数字是否合法,解数独的递归树比N皇后问题更深更宽。
回溯三部曲
- 递归函数以及参数
递归函数的返回值是boolean型!
因为解数独找到一个符合条件立即返回,相当于找从根节点到叶子节点一条唯一路径,所以需要boolean返回值。
public boolean dfs(char[][] board)
-
递归终止条件
不需要递归终止条件!
因为解数独是要遍历整个递归树,找到可能的叶子节点就立刻返回。
递归的下一层棋盘一定比上一层多一个数,等数填满了自然就终止了,所以不需要终止条件! -
单层搜索过程
由递归树中可以看出我们需要一个二维的递归(两个for循环嵌套着递归)
一个for循环遍历棋盘的行,一个for循环遍历棋盘的列,一行一列确定下来之后,递归遍历这个位置放9个数字的可能性!
public boolean dfs(char[][] board){
for(int i=0;i<board.length;i++){
for(int j=0;j<board[0].length;j++){
if(board[i][j]!='.')
continue;
//board[i][j]放k是否合适
for(char k='1';k<='9';k++){
if(isValid(i,j,k,board)){
board[i][j]=k;
if(dfs(board)) return true;//找到一组合适的立刻返回
board[i][j]='.';
}
}
return false;//9个数都不合适,返回
}
}
return true;//遍历完没有返回false,说明找到了合适棋盘位置了
}
注意这里return false!
如果一行一列确定下来了,尝试了9个数都不行,说明这个棋盘找不到解决数独问题的解。
那么就会直接返回,所以即使没有终止条件也不会由于填不满棋盘而无限递归下去。
- 判断棋盘是否合法
判断合法的三个维度:同行、同列、9宫格内,是否重复
除此之外,第 i 行第 j 列的格子位于( ⌊i/3⌋, ⌊j/3⌋ )个九宫格中,注意一下这里下标的计算。
public boolean isValid(int row,int col,char val,char[][] board){
//检查行重复
for(int i=0;i<9;i++){
if(board[i][col]==val)
return false;
}
//检查列重复
for(int i=0;i<9;i++){
if(board[row][i]==val)
return false;
}
//检查九宫格重复
int startRow=(row/3)*3;
int startCol=(col/3)*3;
for(int i=startRow;i<startRow+3;i++){
for(int j=startCol;j<startCol+3;j++){
if(board[i][j]==val)
return false;
}
}
return true;
}
总结
性能分析
| 问题类型 | 时间复杂度 | 空间复杂度 | 备注 |
|---|---|---|---|
| 子集 | O ( n × 2 n ) O(n\times2^n) O(n×2n) | O(n) | 每个元素取或者不取-> 2 n 2^n 2n;构造每一组子集填进数组->n |
| 排列 | O ( n ! ) O(n!) O(n!) | O(n) | |
| 组合 | O ( n × 2 n ) O(n\times2^n) O(n×2n) | O(n) | 组合问题其实就是一种子集问题,最坏情况也不会超过子集的时间复杂度 |
| N皇后 | O ( n ! ) O(n!) O(n!) | O(n) | 皇后之间不能见面有剪枝,所以最差就是 O ( n ! ) O(n!) O(n!) |
| 解数独 | O ( 9 m ) O(9^m) O(9m) | O ( n 2 ) O(n^2) O(n2) | m是‘.’的数目,递归深度是 n 2 n^2 n2 |
几个问题
复习回溯的时候可以考虑如下几个问题:
- 如何理解回溯法的搜素过程?
- 如何去重?如何理解“树枝去重”和“树层去重”?
- 去重的几种方法?
- 如何理解二维递归?
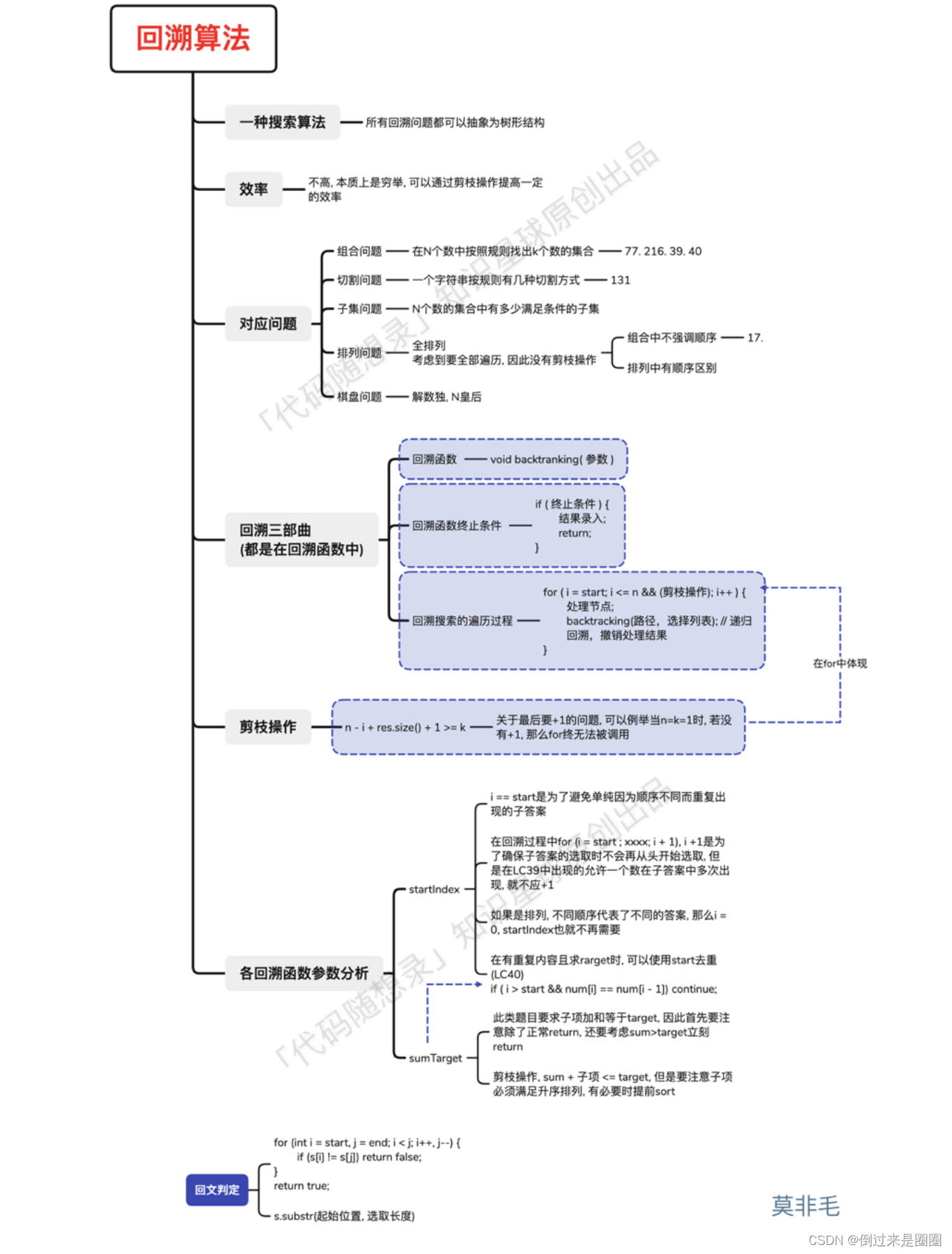
以上均参考自代码随想录-回溯算法。
p.s 历时9天,终于把回溯法学完了!
起初只是因为组合问题又忘了,一气之下决定好好总结一下回溯算法,这么多天下来对于回溯算法的分析方法有了更深程度的掌握,确实获益匪浅!