提起Memory Pin机制,就不得不提到swap的概念,这两个概念息息相关,为了避免在CPU忙碌的时候,也就是在缺页异常发生的时候,临时搜索可供换出的内存页面并加以换出,Linux内核定期地检查系统的空闲页面数量是否小于预定义的极限,一旦发现空闲页面数太少,就预先将若干页面换出,以减轻缺页异常发生时系统所承受的负担,当然,由于无法确切地预测页面的使用,即使这样做了也还可能出现缺页异常发生时内存依然没有足够的空闲页面。但是,预换出毕竟能减少空闲页面不够用的利率。并且通过选择适当的参数,比如每隔多久换出一次,每次换出多少页,可以使临时寻找要换出页面的情况很少发生,为此,linux内核设置了一个专伺定期将页面换出的守护进程kswapd.kswapd的分析参考博客:
https://blog.csdn.net/tugouxp/article/details/119896712?spm=1001.2014.3001.5502
swap的原理是,当内存不足的时候,把最近很少访问的没有存储设备支持的物理页(其实就是匿名页)数据暂时保存到交换区,释放内存空间,当交换区中的存储页被访问的时候,再把数据从交换页读取到内存中。
Pin Memory
交换功能并不是在所有场景下就是需要的,以CUDA为例,熟悉cuda的同学一定知道cudaMallocHost函数,cudaMallocHost和malloc分配的都是主机端内存,但是他们是有区别的。cudaMallocHost函数用于分配页锁定内存,使用方法如下:
cudaMallocHost((void**)&pdataA, MATRIX_M * MATRIX_N * sizeof(int));
cudaHostGetDevicePointer((void**)&pdata_gpuA, (void*)pdataA, 0);使用malloc分配的内存是swapable(交换页)的(malloc的都是匿名页),而上面的代码例子中,调用cudaHostGetDevicePointer的目的,实质是强制让分配得到的页面不参与页交换,目的是让一片用户
buffer永驻内存,从而提高系统应用效率。
下图是nvidia关于函数cudaHostGetDevicePointer的官方文档,可以明显看到pin memory的字眼。
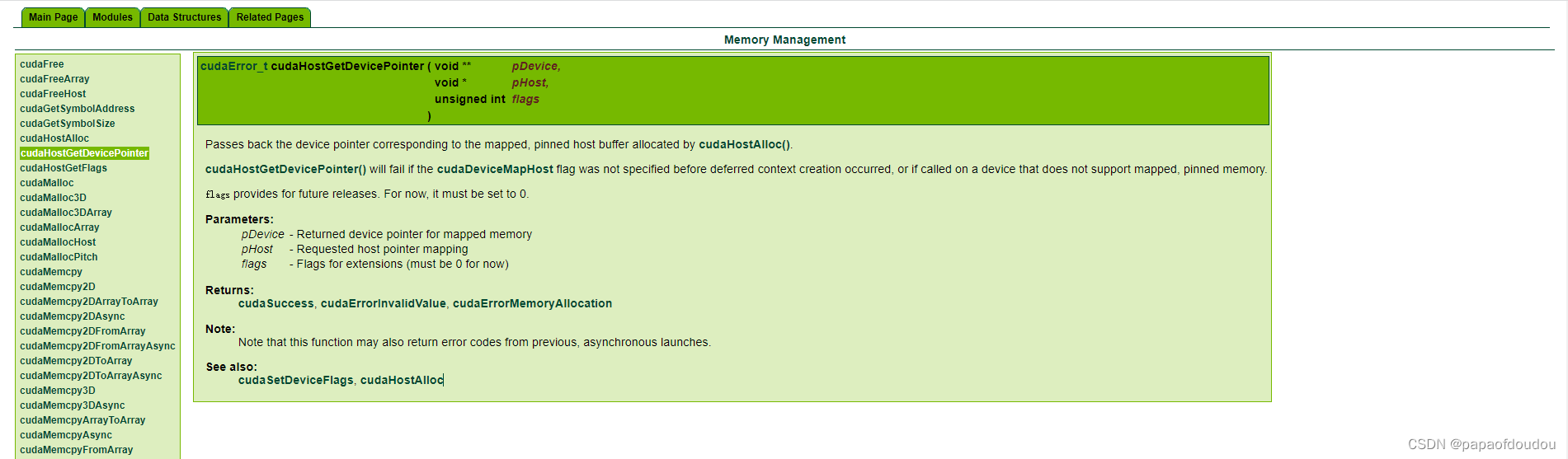

如何操作一片用户memory为Pin Memory?
Linux内核提供了完善的pin memory API接口供开发者调用,可以将一块malloc得到的匿名内存区域设置为为pin memory,防止其被交换出去。
关于pin memory 操作的API,稍微老一点的内核是通过get_user_page, get_user_page_remote,put_page实现的,最新的内核新增了两个API,pin_user_pages和unpin_user_pages,用来完成PIN的功能。
下面我们就基于内核提供的API,实现一个将用户malloc内存pin住的用例,用例包含两个部分,分别为内核模块和用户态测试代码。
内核实现部分:
#include <linux/kernel.h>
#include <linux/init.h>
#include <linux/types.h>
#include <linux/spinlock.h>
#include <linux/blkdev.h>
#include <linux/module.h>
#include <linux/fs.h>
#include <linux/errno.h>
#include <linux/mm.h>
#include <linux/cdev.h>
#include <linux/miscdevice.h>
#define MISC_NAME "miscdriver"
static int temp_data = 0;
static int misc_open(struct inode *inode, struct file *file)
{
printk("misc_open.\n");
return 0;
}
static void page_count_output(struct page** page, int cnt)
{
int i;
for(i = 0; i < cnt; i ++)
{
printk("%s line %d, page count %d, page map count %d.\n", __func__, __LINE__, page_count(page[i]), page_mapcount(page[i]));
}
}
static long misc_ioctl( struct file *file, unsigned int cmd, unsigned long arg)
{
switch(cmd)
{
case 0x100:
if(copy_from_user(&temp_data, (int *)arg, sizeof(int)))
return -EFAULT;
break;
case 0x101:
if(copy_to_user( (int *)arg, &temp_data, sizeof(int)))
return -EFAULT;
break;
case 0x102:
{
int pined = 4;
int ret, i;
int page_cache_pins = 0;
struct page *user_pages[4];
ret = get_user_pages(arg, pined, FOLL_WRITE | FOLL_LONGTERM, user_pages, NULL);
if(ret == pined) {
printk("%s line %d, pined 4 user pages success.\n", __func__, __LINE__);
} else {
printk("%s line %d, pined 4 user pages failure.\n", __func__, __LINE__);
return -EFAULT;
}
page_cache_pins = PageTransHuge(user_pages[0]) && PageSwapCache(user_pages[0]) ? 100:1;
printk("%s line %d, arg = 0x%lx, %d, %d.\n", __func__, __LINE__, arg, page_has_private(user_pages[0]), page_cache_pins);
page_count_output(user_pages, pined);
//unpined
for( i = 0; i < pined; i ++ ) {
put_page(user_pages[i]);
}
page_count_output(user_pages, pined);
break;
}
}
//printk(KERN_NOTICE"ioctl CMD%d done!\n",temp);
return 0;
}
static const struct file_operations misc_fops = {
.owner = THIS_MODULE,
.open = misc_open,
.unlocked_ioctl = misc_ioctl,
};
static struct miscdevice misc_dev = {
.minor = MISC_DYNAMIC_MINOR,
.name = MISC_NAME,
.fops = &misc_fops,
};
static int __init misc_init(void)
{
int ret;
ret = misc_register(&misc_dev);
if (ret)
{
printk("misc_register error.\n");
return ret;
}
return 0;
}
static void __exit misc_exit(void)
{
misc_deregister(&misc_dev);
}
module_init(misc_init);
module_exit(misc_exit);
MODULE_LICENSE("GPL");
MODULE_AUTHOR("czl");测试用例:
#include <stdio.h>
#include <fcntl.h>
#include <stdlib.h>
#include <string.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <unistd.h>
#include <sys/ioctl.h>
int main(void)
{
int fd;
int ret;
int wdata, rdata;
void *ptr;
fd = open("/dev/miscdriver", O_RDWR);
if( fd < 0 ) {
printf("open miscdriver WRONG!\n");
return 0;
}
ret = ioctl(fd, 0x101, &rdata);
printf("ioctl: ret=%d rdata=%d\n", ret, rdata);
wdata = 42;
ret = ioctl(fd, 0x100, &wdata);
ret = ioctl(fd, 0x101, &rdata);
printf("ioctl: ret=%d rdata=%d\n", ret, rdata);
ptr = malloc(16 * 1024);
if(ptr == NULL) {
printf("%s line %d, malloc failure.\n", __func__, __LINE__);
ret = -1;
}
printf("%s line %d, ptr = %p.\n", __func__, __LINE__, ptr);
ret = ioctl(fd, 0x102, (unsigned long)ptr);
free(ptr);
close(fd);
return ret;
}Makefile:
ifneq ($(KERNELRELEASE),)
obj-m:=miscdriver.o
else
KERNELDIR:=/lib/modules/$(shell uname -r)/build
PWD:=$(shell pwd)
all:
$(MAKE) -C $(KERNELDIR) M=$(PWD) modules
clean:
rm -rf *.o *.mod.c *.mod.o *.ko *.symvers *.mod .*.cmd *.order
endif运行结果:

Memory Pin机制是通过page->_refcount成员发挥作用的,其核心逻辑上对_refcount进行递增操作,使其不满足swapout的条件,在swap的关键流程节点pageout一步中,会对page是否swapable进行判断,以此方式来阻止指定页面被交换出去。关键流程如下图所示:
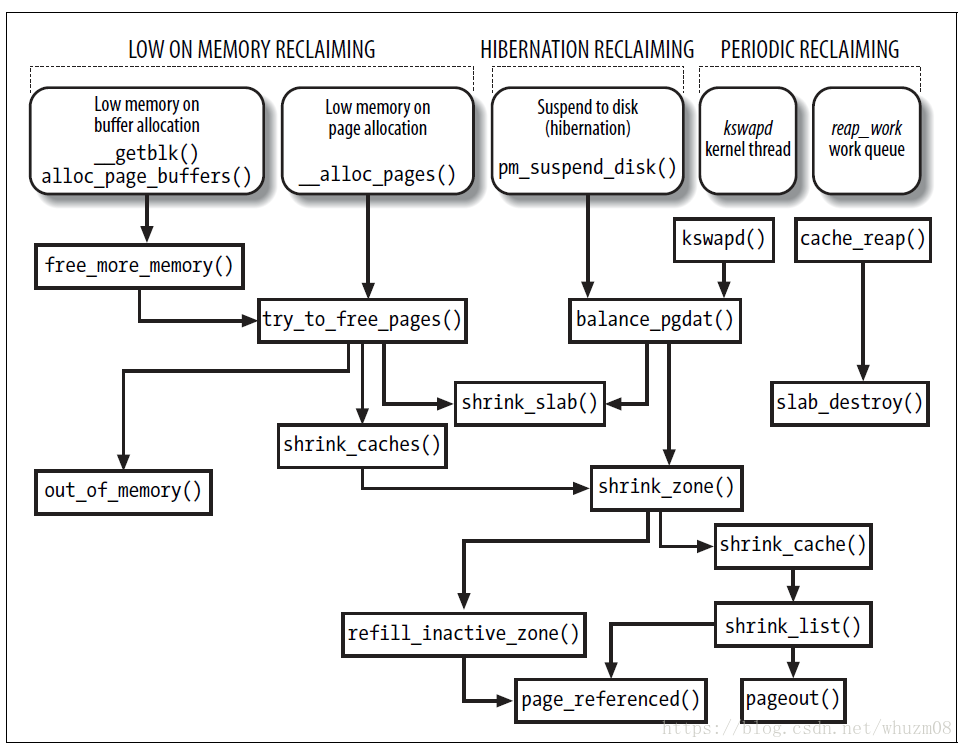
为何CUDA用的HOST内存一定要PIN的?
PIN内存不能换出,linux kernel内核函数pageout函数再进行页面判断的时候,会调用is_page_cache_freeable检查页面是否符合换出条件,如果发现是pin page memory,就直接返回不会调用swapper_writepage将页面换出。
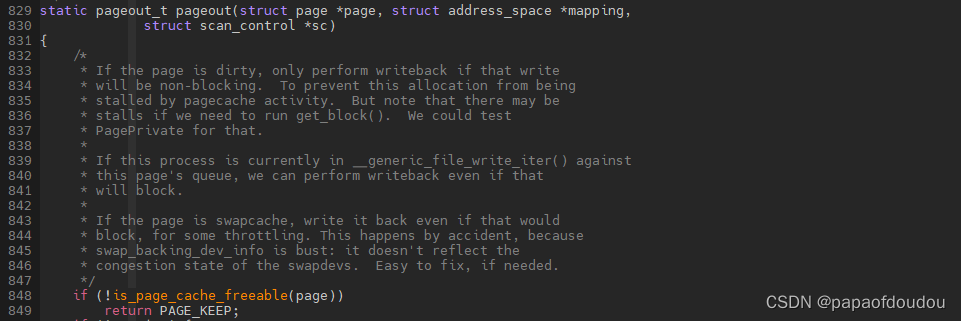
方式则是很老套的检查page计数,关于page计数的逻辑后续在分析,总之,通过这个函数过滤,经过pin的内存就不会再被swap out掉了。

从注释中可以知道,可以swap出去的页面的引用计数有三个特征。
1.由分配(isolated)发起的引用计数+1,在alloc_pages的调用栈中.(prep_new_page函数)
2.由page cache引起的计数器递增+1,在handle page fault处理的过程__lru_cache_add中。
3.作为buffer cache 页面指向buffer_head结构时 +1.
所以作为匿名页面,只有1和2条件满足,可以交换出去的页面引用计数为2,对于buffer cache,则引用计数为3,比如文件交换到back file,此时的计数为3.
注意这个条件是充分且必要的,即便对于那种驱动分配的页面,由于其没有2和3,引用计数为1,也不会发生交换出去的操作。
交换的最终目的是页面的回收,并非内存中所有的页面都是可以交换出去的,只有与用户空间建立了映射关系的物理页面才会被换出去,而内核空间中的内核所占用的页面则常驻内存。这部分就包括用alloc_pages分配的页面。
从这个角度看,用户态进程的堆空间和代码空间(page private不为空,refcount为3)都可以swap出去。
那么,为什么GPU端一定要PIN memory呢?原因除了提高效率之外,恐怕最重要的一点是,当GPU访问的PAGE被换出后,无法像CPU端那样支持将page swap in进来。CPU操作系统支持page fault,并且MMU page walk也支持检测这种换出类型的swap pte item并上报CPU,这一套逻辑,GPU都不一定具备,所以,cuda用的HOST内存,一定要pin 住的。
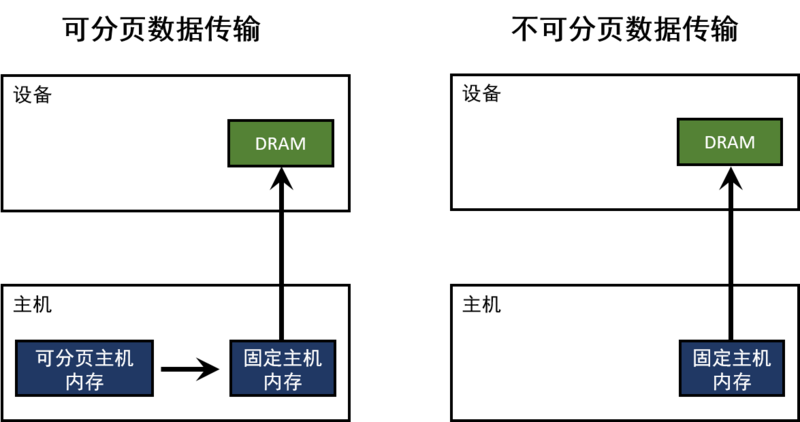
主机(CPU)数据分配的内存默认是可分页的。GPU不能直接访问可分页的主机内存,所以当从可分页内存到设备内存的进行数据传输时,CUDA驱动必须首先分配一个临时的不可分页的或者固定的主机数组,然后将主机数据拷贝到固定数组里,最后再将数据从固定数组转移到设备内存,如下图所示:
pin memory的释放
在4.x-5.6的内核上,pin memory的释放是通过put_page实现的,在最新的内核上则新增了一个佳作unref_pin_page的API专门负责 pin memory的释放,重点是pin meomory是通过page结构的引用计数来实现的,这一点只有在put_page的函数实现中比较明显,见下图:

用户态mlock/munlock函数和和memory pin的联系
关于用户态常用的操作memory的函数总结如下:
void *malloc (size_t);
void free (void *);
void *mmap (void *, size_t, int , int , int , off_t);
int munmap (void *, size_t);
int mprotect (void *, size_t, int);
int msync (void *, size_t, int);
int mlock (const void *, size_t);
int munlock (const void *, size_t);
int mlockall (int);
int munlockall (void);
void *mremap (void *, size_t, size_t, int, ...);
int remap_file_pages (void *, size_t, int, size_t, int);其中的mlock/munlock做的事情本质上和上面的用例类似,都是将一片用户内存作为pin memory防止交换的发生。mlock/munlock在musl libc中中的实现如下:


在内核中,则是通过get_free_page/put_page实现的。
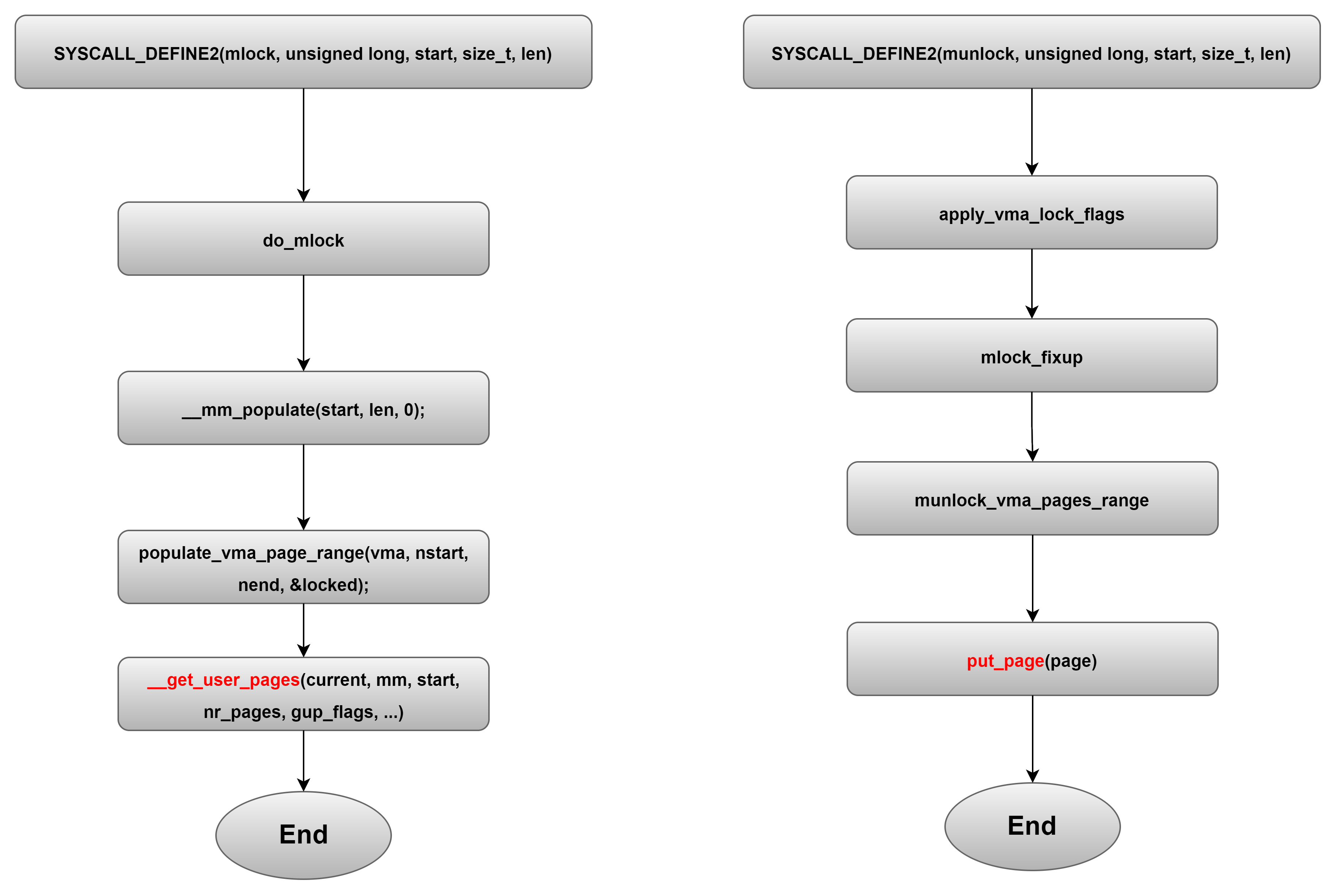

内核中其它模块应用pin memory的例子
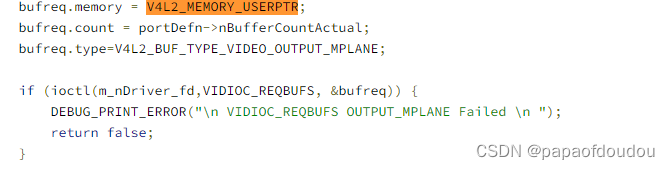
窃以为,Linux内核所有模块中对Memory Buffer的管理最复杂,花样最多的,应该是V4L2模块了,这并不是随口乱讲,要知道,最早的DMABUF机制的开发者,就是V4L2模块的维护者。在V4L2模块中,涉及了非常多的用户态和内核态共享buffer的实现要求。自然关于memory pin机制,在V4L2中也有出现,下面几张图展示了用户态调用V4L2_MEMORY_USERPTR 将buffer pin住的操作:





![[RootersCTF2019]ImgXweb](https://img-blog.csdnimg.cn/f88b5736a6b649acaa912322789ced9e.png)