文章目录
- 一、聚合函数
- 1.1 COUNT()函数
- 1.2 SUM()函数
- 1.3 AVG()函数
- 1.4 MAX()函数
- 1.5 MIN()函数
- 二、分组查询及过滤分组
- 2.1 创建分组
- 2.2 使用HAVING过滤分组
- 2.3 WHERE和HAVING的对比
前置知识:
一、数据库开发与实战专栏导学及数据库基础概念入门
二、MySQL 介绍及 MySQL 安装与配置
三、MySQL 数据库的基本操作
四、MySQL 存储引擎及数据类型
五、数据导入与基本的 SELECT 语句
六、MySQL 数据库练习题1(包含前5章练习题目及答案)
七、MySQL 多表查询详解(附练习题及答案----超详细)
八、MySQL 常用函数汇总(1)
九、MySQL 常用函数汇总(2)
一、聚合函数
有时候并不需要返回实际表中的数据,而只是对数据进行总结。MySQL 提供一些查询功能,可以对获取的数据进行分析和报告。这些函数的功能有:计算数据表中记录行数的总数、计算某个字段列下数据的总和,以及计算表中某个字段下的最大值、最小值或者平均值。本小节将介绍这些函数及其用法,这些聚合函数的名称和作用如下表所示:
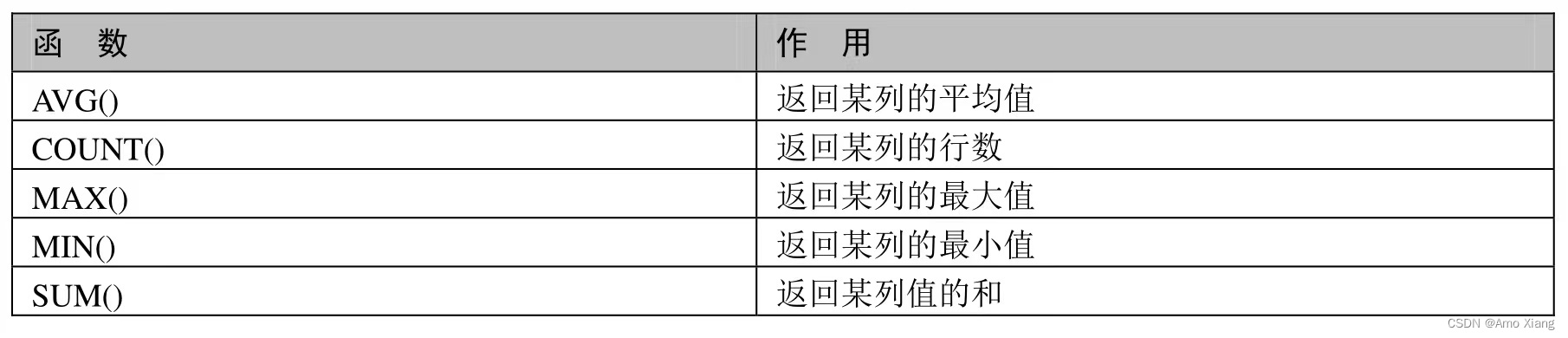
接下来,将详细介绍各个函数的使用方法。
1.1 COUNT()函数
COUNT() 函数统计数据表中包含的记录行的总数,或者根据查询结果返回列中包含的数据行数。其使用方法有两种:
- COUNT(*/1/2具体数值):计算表中总的行数,不管某列是否有数值或者为空值。
- COUNT(字段名):计算指定列下总的行数,计算时将忽略空值的行。
【示例1】查询employees表中总的行数,SQL语句如下:
mysql> SELECT COUNT(1),COUNT('a'),COUNT('2023-01-17'),COUNT(*) FROM employees;
+----------+------------+---------------------+----------+
| COUNT(1) | COUNT('a') | COUNT('2023-01-17') | COUNT(*) |
+----------+------------+---------------------+----------+
| 107 | 107 | 107 | 107 |
+----------+------------+---------------------+----------+
1 row in set (0.00 sec)
由查询结果可以看到,返回employees表中记录的总行数。【示例2】查询employees表中有 commission_pct 员工的总数,SQL语句如下:
mysql> SELECT COUNT(commission_pct) FROM employees;
+-----------------------+
| COUNT(commission_pct) |
+-----------------------+
| 35 |
+-----------------------+
1 row in set (0.00 sec)
由查询结果可以看到,表中 107 个 employees 只有 35 个有 commission_pct,employees 的 commission_pct 为空值 NULL 的记录没有被 COUNT() 函数计算。
提示:两个例子中不同的数值说明了两种方式在计算总数的时候对待
NULL值的方式不同:指定列的值为空的行被COUNT()函数忽略;如果不指定列,而在COUNT()函数中使用星号*,则所有记录都不忽略。
问题:用count(*)、count(1)、count(列名)谁好呢? 其实,对于MyISAM引擎的表是没有区别的。这种引擎内部有一计数器在维护着行数。Innodb引擎的表用 count(*)、count(1)直接读行数,复杂度是O(n),因为innodb真的要去数一遍。但好于具体的count(列名)。
1.2 SUM()函数
SUM() 是一个求总和的函数,返回指定列值的总和。 【示例3】在employees表中,查询员工总工资,SQL语句如下:
#提示:SUM()函数在计算时,忽略列值为NULL的行
mysql> SELECT SUM(commission_pct),SUM(salary) FROM employees;
+---------------------+-------------+
| SUM(commission_pct) | SUM(salary) |
+---------------------+-------------+
| 7.80 | 691400.00 |
+---------------------+-------------+
1 row in set (0.00 sec)
1.3 AVG()函数
AVG() 函数通过计算返回的行数和每一行数据的和,求得指定列数据的平均值。 【示例4】在employees表中,查询员工平均薪资,SQL语句如下:
#AVG()函数使用时,其参数为需要计算的列名称。如果想要得到多个列的多个平均值,则需要在每一列上使用AVG()函数。
mysql> SELECT AVG(salary),SUM(salary)/107,SUM(salary)/COUNT(*),SUM(salary)/COUNT(commission_pct) FROM employees;
+-------------+-----------------+----------------------+-----------------------------------+
| AVG(salary) | SUM(salary)/107 | SUM(salary)/COUNT(*) | SUM(salary)/COUNT(commission_pct) |
+-------------+-----------------+----------------------+-----------------------------------+
| 6461.682243 | 6461.682243 | 6461.682243 | 19754.285714 |
+-------------+-----------------+----------------------+-----------------------------------+
1 row in set (0.00 sec)
mysql> SELECT SUM(salary)/COUNT(IFNULL(commission_pct, 0)) FROM employees;
+----------------------------------------------+
| SUM(salary)/COUNT(IFNULL(commission_pct, 0)) |
+----------------------------------------------+
| 6461.682243 |
+----------------------------------------------+
1 row in set (0.00 sec)
1.4 MAX()函数
MAX() 函数返回指定列中的最大值。 【示例5】在employees表中,查找薪资最高的员工,SQL语句如下:
mysql> SELECT MAX(salary) FROM employees;
+-------------+
| MAX(salary) |
+-------------+
| 24000.00 |
+-------------+
1 row in set (0.00 sec)
【示例6】在employees表中,查找last_name的最大值,SQL语句如下:
#MAX()函数不仅适用于查找数值类型,也可应用于字符类型
mysql> SELECT MAX(last_name) FROM employees;
+----------------+
| MAX(last_name) |
+----------------+
| Zlotkey |
+----------------+
1 row in set (0.00 sec)
由结果可以看到,MAX() 函数可以对字母进行大小判断,并返回最大的字符或者字符串值。
提示:
MAX()函数除了用来找出最大的列值或日期值之外,还可以返回任意列中的最大值,包括返回字符类型的最大值。在对字符类型数据进行比较时,按照字符的ASCII码值 大小进行比较,从a~z,a的ASCII码最小,z的最大。在比较时,先比较第一个字母,如果相等,继续比较下一个字符,一直到两个字符不相等或者字符结束为止。例如,b与t比较时,t为最大值;bcd与bca比较时,bcd为最大值。
1.5 MIN()函数
MIN() 函数返回查询列中的最小值。 【示例7】在employees表中,查找last_name的最小值,SQL语句如下:
mysql> SELECT MIN(last_name) FROM employees;
+----------------+
| MIN(last_name) |
+----------------+
| Abel |
+----------------+
1 row in set (0.00 sec)
#由结果可以看到,MIN ()函数查询出了last_name字段的最小值Abel
#MIN()函数与MAX()函数类似,不仅适用于查找数值类型,也可应用于字符类型
二、分组查询及过滤分组
分组查询是对数据按照某个或多个字段进行分组。MySQL 中使用 GROUP BY 关键字对数据进行分组,基本语法形式为:
[GROUP BY 字段] [HAVING <条件表达式>]
字段值为进行分组时所依据的列名称;HAVING <条件表达式> 指定满足表达式限定条件的结果将被显示。
2.1 创建分组
GROUP BY 关键字通常和集合函数一起使用,比如 MAX()、MIN()、COUNT()、SUM()、AVG()。例如,要返回 employees 表中每个部门员工的数量,这时就要在分组过程中使用 COUNT() 函数,把数据分为多个逻辑组,并对每个组进行集合计算。
【示例8】根据department_id对employees表中的数据进行分组,SQL语句如下:
mysql> SELECT department_id,COUNT(*)AS "Total" FROM employees GROUP BY department_id;
+---------------+-------+
| department_id | Total|
+---------------+-------+
| NULL | 1 |
| 10 | 1 |
| 20 | 2 |
| 30 | 6 |
| 40 | 1 |
| 50 | 45 |
| 60 | 5 |
| 70 | 1 |
| 80 | 34 |
| 90 | 3 |
| 100 | 6 |
| 110 | 2 |
+---------------+-------+
12 rows in set (0.00 sec)
查询结果显示,department_id 表示部门的 id,Total 字段使用 COUNT() 函数计算得出,GROUP BY 子句按照 department_id 排序并对数据分组。如果要查看每个部门员工的姓名,该怎么办呢?在 MySQL 中,可以在 GROUP BY 子句中使用 GROUP_CONCAT() 函数,将每个分组中各个字段的值显示出来。
SELECT department_id,GROUP_CONCAT(last_name) AS "names" FROM employees GROUP BY department_id;
查询结果如下:
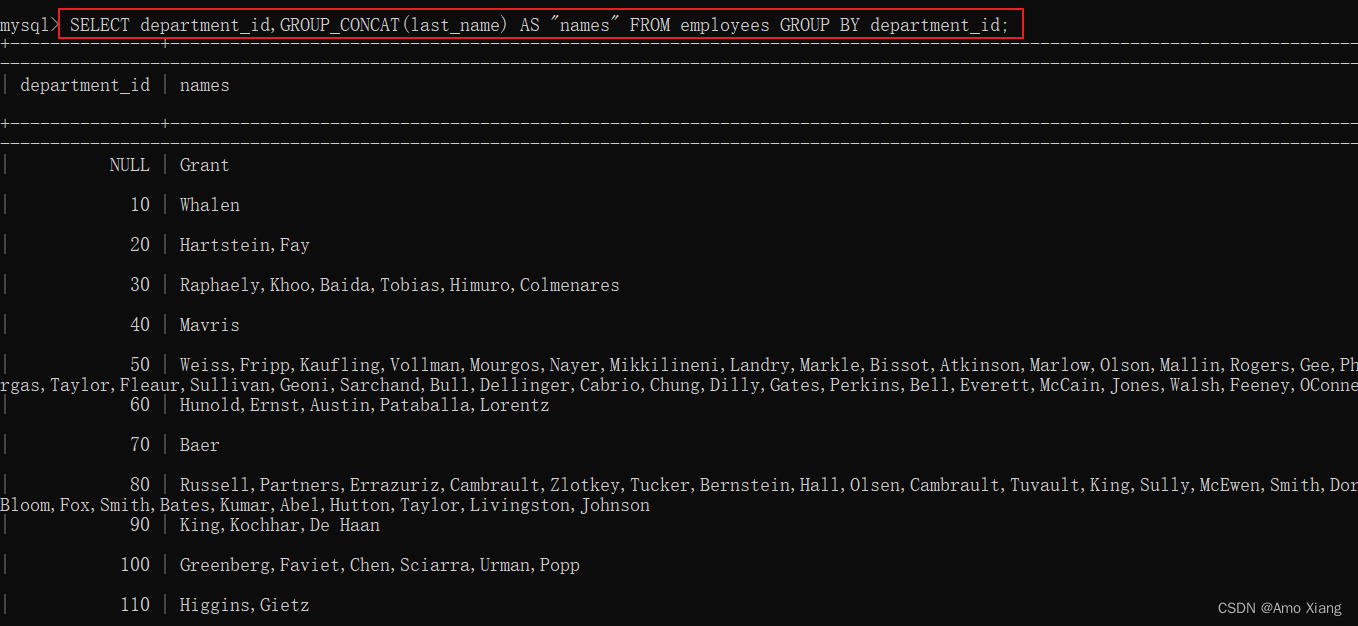
由结果可以看到,GROUP_CONCAT() 函数将每个分组中的名称显示出来了,其名称的个数与 COUNT() 函数计算出来的相同。
补充说明: 在 SELECT 列表中所有未包含在组函数中的列都应该包含在 GROUP BY 子句中,尽管在 MySQL 中不会报语法错误(但是在其他数据库软件中会报错),这样没有任何意义。
【示例9】使用多个列分组,SQL语句如下:
mysql> SELECT department_id dept_id, job_id, SUM(salary) FROM employees GROUP BY department_id,job_id;
+---------+------------+-------------+
| dept_id | job_id | SUM(salary) |
+---------+------------+-------------+
| 90 | AD_PRES | 24000.00 |
| 90 | AD_VP | 34000.00 |
| 60 | IT_PROG | 28800.00 |
| 100 | FI_MGR | 12000.00 |
| 100 | FI_ACCOUNT | 39600.00 |
| 30 | PU_MAN | 11000.00 |
| 30 | PU_CLERK | 13900.00 |
| 50 | ST_MAN | 36400.00 |
| 50 | ST_CLERK | 55700.00 |
| 80 | SA_MAN | 61000.00 |
| 80 | SA_REP | 243500.00 |
| NULL | SA_REP | 7000.00 |
| 50 | SH_CLERK | 64300.00 |
| 10 | AD_ASST | 4400.00 |
| 20 | MK_MAN | 13000.00 |
| 20 | MK_REP | 6000.00 |
| 40 | HR_REP | 6500.00 |
| 70 | PR_REP | 10000.00 |
| 110 | AC_MGR | 12000.00 |
| 110 | AC_ACCOUNT | 8300.00 |
+---------+------------+-------------+
20 rows in set (0.00 sec)
多个字段分组查询时,会先按照第一个字段进行分组。如果第一个字段中有相同的值,MySQL 才会按照第二个字段进行分组。如果第一个字段中的数据都是唯一的,那么 MySQL 将不再对第二个字段进行分组。
【示例10】下面根据employees表中的department_id字段进行分组查询,并使用WITH ROLLUP显示记录的总和。SQL语句如下:
mysql> SELECT department_id,COUNT(*) FROM employees GROUP BY department_id WITH ROLLUP;
+---------------+----------+
| department_id | COUNT(*) |
+---------------+----------+
| NULL | 1 |
| 10 | 1 |
| 20 | 2 |
| 30 | 6 |
| 40 | 1 |
| 50 | 45 |
| 60 | 5 |
| 70 | 1 |
| 80 | 34 |
| 90 | 3 |
| 100 | 6 |
| 110 | 2 |
| NULL | 107 |
+---------------+----------+
13 rows in set (0.00 sec)
WITH POLLUP 关键字用来在所有记录的最后加上一条记录,这条记录是上面所有记录的总和,即统计记录数量。注意: 当使用 ROLLUP 时,不能同时使用 ORDER BY 子句进行结果排序,即 ROLLUP 和 ORDER BY 是互相排斥的。
2.2 使用HAVING过滤分组
GROUP BY 可以和 HAVING 一起限定所查询的记录需要满足的条件,只有满足条件的分组才会被显示。【示例11】先按部门进行分组,筛选出其中存在员工最高薪资大于10000的部门,SQL语句如下:
mysql> SELECT department_id,MAX(salary) FROM employees GROUP BY department_id HAVING MAX(salary)>10000;
+---------------+-------------+
| department_id | MAX(salary) |
+---------------+-------------+
| 20 | 13000.00 |
| 30 | 11000.00 |
| 80 | 14000.00 |
| 90 | 24000.00 |
| 100 | 12000.00 |
| 110 | 12000.00 |
+---------------+-------------+
6 rows in set (0.00 sec)
【示例12】根据department_id对employees表中的数据进行分组,并显示部门中员工数量大于20的分组信息,SQL语句如下:
mysql> SELECT department_id,COUNT(*) FROM employees GROUP BY department_id HAVING COUNT(*)>20;
+---------------+----------+
| department_id | COUNT(*) |
+---------------+----------+
| 50 | 45 |
| 80 | 34 |
+---------------+----------+
2 rows in set (0.00 sec)
2.3 WHERE和HAVING的对比
区别1: WHERE 可以直接使用表中的字段作为筛选条件,但不能使用分组中的计算函数作为筛选条件;HAVING 必须要与 GROUP BY 配合使用,可以把分组计算的函数和分组字段作为筛选条件。这决定了,在需要对数据进行分组统计的时候,HAVING 可以完成 WHERE 不能完成的任务。这是因为, 在查询语法结构中,WHERE 在 GROUP BY 之前,所以无法对分组结果进行筛选。HAVING 在 GROUP BY 之后,可以使用分组字段和分组中的计算函数,对分组的结果集进行筛选,这个功能是 WHERE 无法完成的。另外,WHERE 排除的记录不再包括在分组中。
区别2: 如果需要通过连接从关联表中获取需要的数据,WHERE 是先筛选后连接,而 HAVING 是先连接后筛选。 这一点,就决定了在关联查询中,WHERE 比 HAVING 更高效。因为 WHERE 可以先筛选,用一个筛选后的较小数据集和关联表进行连接,这样占用的资源比较少,执行效率也比较高。HAVING 则需要先把结果集准备好,也就是用未被筛选的数据集进行关联,然后对这个大的数据集进行筛选,这样占用的资源就比较多,执行效率也较低。
小结如下:
- WHERE 先筛选数据再关联,执行效率高,不能使用分组中的计算函数进行筛选。HAVING 可以使用分组中的计算函数,在最后的结果集中进行筛选,执行效率较低
- 一般情况下,WHERE 用于过滤数据行,而 HAVING 用于过滤分组
- WHERE 在数据分组前进行过滤,而 HAVING 在数据分组后进行过滤
- WHERE 针对数据库文件进行过滤,而 HAVING 针对查询结果进行过滤。也就是说,WHERE 根据数据表中的字段直接进行过滤,而 HAVING 是根据前面已经查询出的字段进行过滤
- WHERE 查询条件中不可以使用字段别名,而 HAVING 查询条件中可以使用字段别名
开发中的选择: WHERE 和 HAVING 也不是互相排斥的,我们可以在一个查询里面同时使用 WHERE 和 HAVING。包含分组统计函数的条件用 HAVING,普通条件用 WHERE。这样,我们就既利用了 WHERE 条件的高效快速,又发挥了 HAVING 可以使用包含分组统计函数的查询条件的优点。当数据量特别大的时候,运行效率会有很大的差别。
【示例13】分别使用HAVING和WHERE关键字查询出employees表中薪资大于14000的员工姓名、部门及薪资信息。SQL 语句和运行结果如下:
mysql> SELECT last_name,department_id,salary FROM employees WHERE salary>14000;
+-----------+---------------+----------+
| last_name | department_id | salary |
+-----------+---------------+----------+
| King | 90 | 24000.00 |
| Kochhar | 90 | 17000.00 |
| De Haan | 90 | 17000.00 |
+-----------+---------------+----------+
3 rows in set (0.00 sec)
mysql> SELECT last_name,department_id,salary FROM employees HAVING salary>14000;
+-----------+---------------+----------+
| last_name | department_id | salary |
+-----------+---------------+----------+
| King | 90 | 24000.00 |
| Kochhar | 90 | 17000.00 |
| De Haan | 90 | 17000.00 |
+-----------+---------------+----------+
3 rows in set (0.00 sec)
上述实例中,因为在 SELECT 关键字后已经查询出了 salary 字段,所以 HAVING 和 WHERE 都可以使用。但是如果 SELECT 关键字后没有查询出 salary 字段,使用 HAVING 关键字,MySQL 就会报错,如下所示:
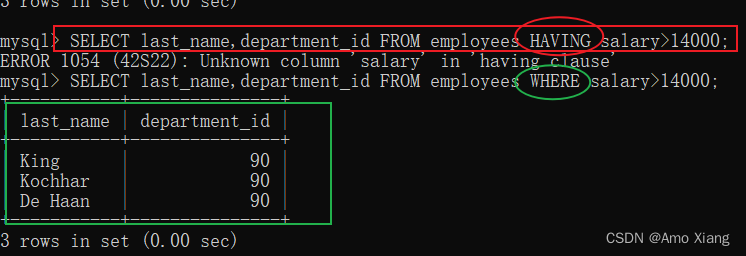
如果在 WHERE 查询条件中使用聚合函数,MySQL 会提示错误信息:无效使用组函数,如下所示:
mysql> SELECT department_id,MAX(salary)>14000 FROM employees WHERE MAX(salary)>14000 GROUP BY department_id;
ERROR 1111 (HY000): Invalid use of group function
至此今天的学习就到此结束了,笔者在这里声明,笔者写文章只是为了学习交流,以及让更多学习数据库的读者少走一些弯路,节省时间,并不用做其他用途,如有侵权,联系博主删除即可。感谢您阅读本篇博文,希望本文能成为您编程路上的领航者。祝您阅读愉快!

好书不厌读百回,熟读课思子自知。而我想要成为全场最靓的仔,就必须坚持通过学习来获取更多知识,用知识改变命运,用博客见证成长,用行动证明我在努力。
如果我的博客对你有帮助、如果你喜欢我的博客内容,请点赞、评论、收藏一键三连哦!听说点赞的人运气不会太差,每一天都会元气满满呦!如果实在要白嫖的话,那祝你开心每一天,欢迎常来我博客看看。
编码不易,大家的支持就是我坚持下去的动力。点赞后不要忘了关注我哦!