概述
本文记录下列命令执行的过程,通过对过程中的关键步骤进行记录,掌握 python-docx 库中 opc 与 parts 模块的源码、以及加深对 OPC 的理解。
import docx
# fp 为 docx 文件路径, docx 包含一个 hello 字符串、一张 jepg 图片及一个表格。
document = docx.api.Document(fp)
上述命令执行的大体流程如下图所示:
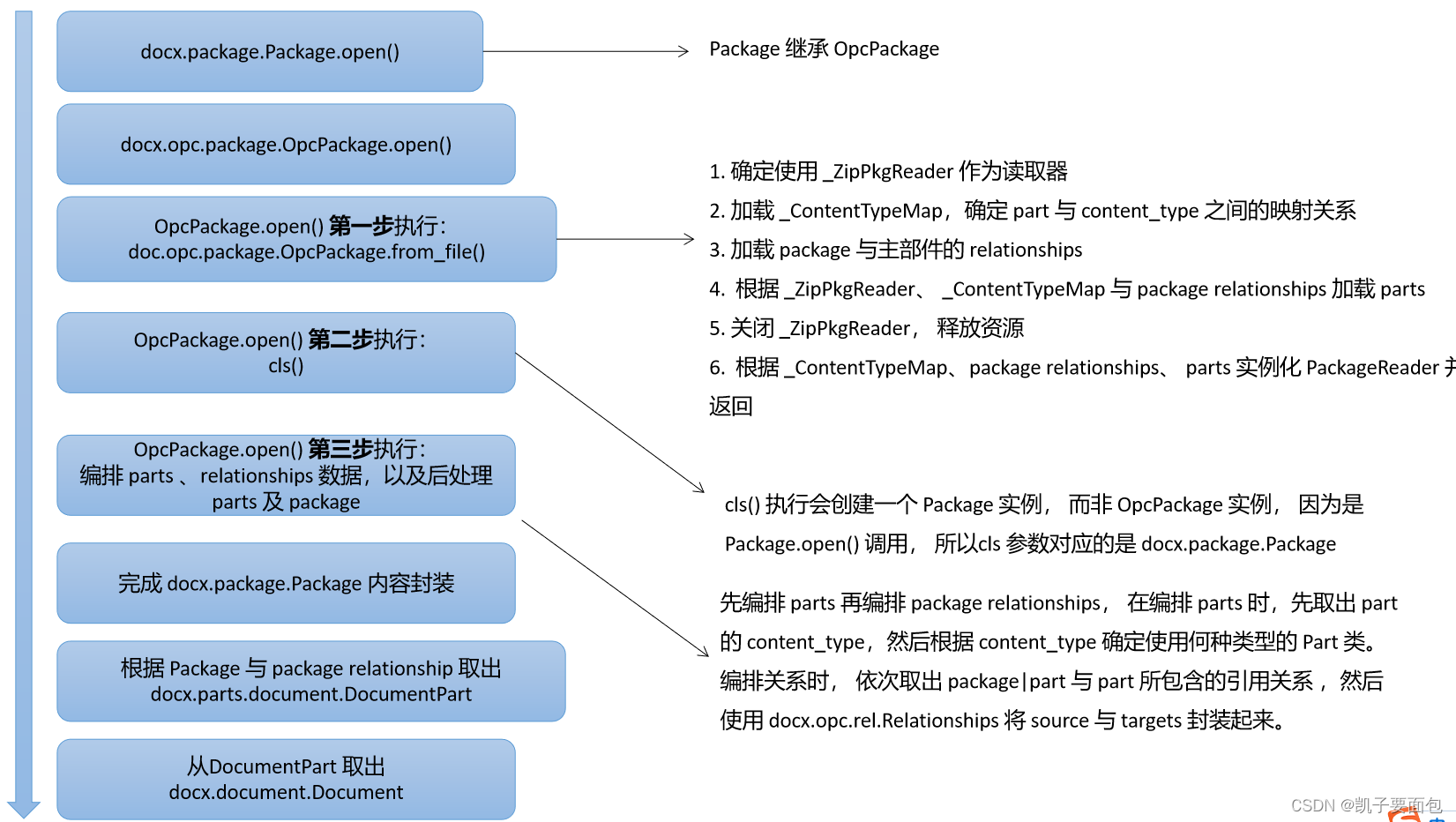
docx.package.Package.open() 第一步详解
pkg_reader = PackageReader.from_file(pkg_file)
docx.opc.pkgreader.PackageReader 部分源码如下所示:
class PackageReader(object):
"""
Provides access to the contents of a zip-format OPC package via its
:attr:`serialized_parts` and :attr:`pkg_srels` attributes.
"""
def __init__(self, content_types, pkg_srels, sparts):
super(PackageReader, self).__init__()
self._pkg_srels = pkg_srels # 存储 package 与主部件之间的关系
self._sparts = sparts # 存储“序列化”的 parts
@staticmethod
def from_file(pkg_file):
"""
Return a |PackageReader| instance loaded with contents of *pkg_file*.
"""
phys_reader = PhysPkgReader(pkg_file) # docx 文件遵循 zip 标准, 因此使用 docx.opc.phys_pkg._ZipPkgReader 读取类
content_types = _ContentTypeMap.from_xml(phys_reader.content_types_xml) # 取出 [Content_Types].xml 内容, 并使用lxml.etree 解析,构建 part 与媒体类型之间的映射关系
pkg_srels = PackageReader._srels_for(phys_reader, PACKAGE_URI) # 取出 _rels.rels.xml 内容,得到“序列化”的 Relationships,这些关系记录了 package 与主部件之间的关系。
sparts = PackageReader._load_serialized_parts(
phys_reader, pkg_srels, content_types
)
phys_reader.close() # docx.opc.phys_pkg._ZipPkgReader 释放资源
return PackageReader(content_types, pkg_srels, sparts) # 构建 PackageReader, 将 package 与主部件之间的“序列化”关系、以及“序列化” parts 存储在实例属性中,便于后续构建 Package 是访问。
其中比较重要的部分就是创建“序列化” parts 的部分,PackageReader._load_serialized_parts 的源码如下所示:
@staticmethod
def _load_serialized_parts(phys_reader, pkg_srels, content_types):
"""
Return a list of |_SerializedPart| instances corresponding to the
parts in *phys_reader* accessible by walking the relationship graph
starting with *pkg_srels*.
"""
sparts = []
part_walker = PackageReader._walk_phys_parts(phys_reader, pkg_srels) # 返回一个生成器
for partname, blob, reltype, srels in part_walker:
content_type = content_types[partname] # 此处就用到了之前构建的“part name” 与 “part content_type” 之间的映射关系
spart = _SerializedPart(
partname, content_type, reltype, blob, srels
)
sparts.append(spart)
return tuple(sparts)
@staticmethod
def _walk_phys_parts(phys_reader, srels, visited_partnames=None):
"""
Generate a 4-tuple `(partname, blob, reltype, srels)` for each of the
parts in *phys_reader* by walking the relationship graph rooted at
srels.
"""
if visited_partnames is None:
visited_partnames = []
for srel in srels:
if srel.is_external:
continue
partname = srel.target_partname
if partname in visited_partnames:
continue
visited_partnames.append(partname)
reltype = srel.reltype
part_srels = PackageReader._srels_for(phys_reader, partname) # 得到是是 part 的引用关系列表
blob = phys_reader.blob_for(partname)
yield (partname, blob, reltype, part_srels)
next_walker = PackageReader._walk_phys_parts(
phys_reader, part_srels, visited_partnames
)
for partname, blob, reltype, srels in next_walker:
yield (partname, blob, reltype, srels)
在创建“序列化” parts 时,采用了深度优先搜索的策略,初次调用 PackageReader._walk_phys_parts 方法时,第二个位置参数传入的实参值是 pkg_srels, 其表示“ package 与 主部件之间的引用关系”。在迭代子节点时, 第二个位置参数传入的便是 part 的引用关系 part_srels。
这里分别举两个例子进一步阐释,当 pkg_rels 中的关系对应的是 “_rels/.rels.xml” 中的下列项时:
<Relationship Id="rId3" Type="http://schemas.openxmlformats.org/package/2006/relationships/metadata/core-properties" Target="docProps/core.xml"/>
此时 Relationship 两端中的 source 便是 package, 而 target 便是 “docProps/core.xml”, 当调用 PackageReader._srels_for(phys_reader, "docProps/core.xml") ,返回的 part_srels 并不包含任何引用关系,因为 “docProps/core.xml” 存储的是文档属性值,并不需要再引用其它 part 或者其它外部资源,因此引用关系为空, 即输出 ("docProps/core.xml", blob, "http://schemas.openxmlformats.org/package/2006/relationships/metadata/core-properties" , part_srels) 之后,新创建的 next_walker 实质是一个空迭代器,因此会直接跳到 “_rels/.rels.xml” 中的下一项。
而当下一项是:
<Relationship Id="rId1" Type="http://schemas.openxmlformats.org/officeDocument/2006/relationships/officeDocument" Target="word/document.xml"/>
由于 “word/document.xml” 存储了 docx 文档的文本信息,因此一般情况都会引用其它 part,比如引用字体信息:
<Relationship Id="rId5" Type="http://schemas.openxmlformats.org/officeDocument/2006/relationships/fontTable" Target="fontTable.xml"/>
那么调用 PackageReader._srels_for(phys_reader, "word/document.xml") 得到的 part_srels 就包含其它关系,此时就会进入“以 word/document.xml 为 source part” 的搜索中。
在深度优先策略搜索的策略下,最终得到所有“序列化”的 parts。
Serialized means any target part is referred to via its partname rather than a direct link to an in-memory |Part| object.
docx.package.Package.open() 第二步详解
package = cls()
这里需要注意,返回的是 docx.package.Package 实例,而非 docx.opc.package.OpcPackage 实例, 因为上层调用是 Package.open(), 因此 cls 参数实质是指 docx.package.Package。
docx.package.Package.open() 第三步详解
Unmarshaller.unmarshal(pkg_reader, package, PartFactory) # 将 package_reader 中的 pkg_rels 与 spart 编排到 package 中,并对 part 与 package 做后处理, 这里的 part交由PartFactory 管理。
docx.__init__.py 对 docx.opc.part.PartFactory 进行了初始化配置, 指明了不同类型的 part,采用不同的 Part 类来构建。
def part_class_selector(content_type, reltype):
if reltype == RT.IMAGE:
return ImagePart
return None
PartFactory.part_class_selector = part_class_selector
PartFactory.part_type_for[CT.OPC_CORE_PROPERTIES] = CorePropertiesPart
PartFactory.part_type_for[CT.WML_DOCUMENT_MAIN] = DocumentPart
PartFactory.part_type_for[CT.WML_FOOTER] = FooterPart
PartFactory.part_type_for[CT.WML_HEADER] = HeaderPart
PartFactory.part_type_for[CT.WML_NUMBERING] = NumberingPart
PartFactory.part_type_for[CT.WML_SETTINGS] = SettingsPart
PartFactory.part_type_for[CT.WML_STYLES] = StylesPart
class Unmarshaller(object):
"""Hosts static methods for unmarshalling a package from a |PackageReader|."""
@staticmethod
def unmarshal(pkg_reader, package, part_factory):
"""
Construct graph of parts and realized relationships based on the
contents of *pkg_reader*, delegating construction of each part to
*part_factory*. Package relationships are added to *pkg*.
"""
parts = Unmarshaller._unmarshal_parts(
pkg_reader, package, part_factory
) # 编排 parts
Unmarshaller_unmarshal_relationships(pkg_reader, package, parts) # 编排关系
for part in parts.values():
part.after_unmarshal() # 对 part 进行后处理
package.after_unmarshal() # 对 package 进行后处理
将 XML 文件解析为 ElementTree 发生在此处, 以编排 “/docProps/core.xml” part 为例,编排首先会从 PackageReader 中取出“序列化” 的 part —— PackageReader 的实例属性中存储了 spart 与 pkg_srels。 序列化的 part 中包含 “/docProps/core.xml” partname、content_type、reltype、blob 值,根据 content_type 值选择对应的 CorePropertiesPart 类,然后先将 blob 解析成 ElementTree,注意 CorePropertiesPart.load() 中使用的 parse_xml 函数是 docx.oxml.init.py 中定义的, 并且将 CT_Coreproperties 类注册到 “http://schemas.openxmlformats.org/package/2006/metadata/core-properties” 命名空间下, 最后 CT_CoreProperties 元素会封装在 CorePropertiesPart 中。
另外对于读写文档的核心属性 docx.document.Document().core_properties, 遵从以下的操作顺序“Document -> DocumentPart -> Package -> CorePropertiesPart -> CT_Coreproperties -> docx.opc.coreprops.CoreProperties ”, docx.opc.coreprops.CoreProperties 会封装 CT_Coreproperties, 并对外提供读写接口。