目录
一、安装收集日志组件 Fluentd
二、kibana 可视化展示查询 k8s 容器日志
三、测试 efk 收集生产环境业务 pod 日志
四、基于 EFK+logstash+kafka 构建高吞吐量的日志平台
4.1 部署 fluentd
4.2 接入 kafka
4.3 配置 logstash
4.4 启动 logstash
本篇文章所用到的资料文件下载地址:https://download.csdn.net/download/weixin_46560589/87392272
一、安装收集日志组件 Fluentd
我们使用 daemonset 控制器部署 fluentd 组件,这样可以保证集群中的每个节点都可以运行同样 fluentd 的 pod 副本,这样就可以收集 k8s 集群中每个节点的日志。在 k8s 集群中,容器应用程序的输入输出日志会重定向到 node 节点里的 json 文件中,fluentd 可以 tail 和过滤以及把日志转换成指定的格式发送到 elasticsearch 集群中。除了容器日志,fluentd 也可以采集 kubelet、kube-proxy、docker 的日志。
# 离线镜像压缩包 fluentd.tar.gz 上传到各个节点上,手动解压:
[root@k8s-master1 ~]# docker load -i fluentd.tar.gz
[root@k8s-node1 ~]# docker load -i fluentd.tar.gz
[root@k8s-node2 ~]# docker load -i fluentd.tar.gz
[root@k8s-master1 efk]# vim fluentd.yaml
apiVersion: v1
kind: ServiceAccount
metadata:
name: fluentd
namespace: kube-logging
labels:
app: fluentd
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:
name: fluentd
labels:
app: fluentd
rules:
- apiGroups:
- ""
resources:
- pods
- namespaces
verbs:
- get
- list
- watch
---
kind: ClusterRoleBinding
apiVersion: rbac.authorization.k8s.io/v1
metadata:
name: fluentd
roleRef:
kind: ClusterRole
name: fluentd
apiGroup: rbac.authorization.k8s.io
subjects:
- kind: ServiceAccount
name: fluentd
namespace: kube-logging
---
apiVersion: apps/v1
kind: DaemonSet
metadata:
name: fluentd
namespace: kube-logging
labels:
app: fluentd
spec:
selector:
matchLabels:
app: fluentd
template:
metadata:
labels:
app: fluentd
spec:
serviceAccount: fluentd
serviceAccountName: fluentd
tolerations:
- key: node-role.kubernetes.io/master
effect: NoSchedule
containers:
- name: fluentd
image: fluent/fluentd-kubernetes-daemonset:v1.4.2-debian-elasticsearch-1.1
imagePullPolicy: IfNotPresent
env:
- name: FLUENT_ELASTICSEARCH_HOST
value: "elasticsearch.kube-logging.svc.cluster.local"
- name: FLUENT_ELASTICSEARCH_PORT
value: "9200"
- name: FLUENT_ELASTICSEARCH_SCHEME
value: "http"
- name: FLUENTD_SYSTEMD_CONF
value: disable
resources:
limits:
memory: 512Mi
requests:
cpu: 100m
memory: 200Mi
volumeMounts:
- name: varlog
mountPath: /var/log
- name: varlibdockercontainers
mountPath: /var/lib/docker/containers
readOnly: true
terminationGracePeriodSeconds: 30
volumes:
- name: varlog
hostPath:
path: /var/log
- name: varlibdockercontainers
hostPath:
path: /var/lib/docker/containers
[root@k8s-master1 efk]# kubectl apply -f fluentd.yaml
[root@k8s-master1 efk]# kubectl get pods -n kube-logging | grep fluentd
fluentd-6vmdc 1/1 Running 0 24s
fluentd-mtgxg 1/1 Running 0 24s
fluentd-nzv4n 1/1 Running 0 24s二、kibana 可视化展示查询 k8s 容器日志
Fluentd 启动成功后,我们可以前往 Kibana 的 Dashboard 页面中,点击 Try our sample data:
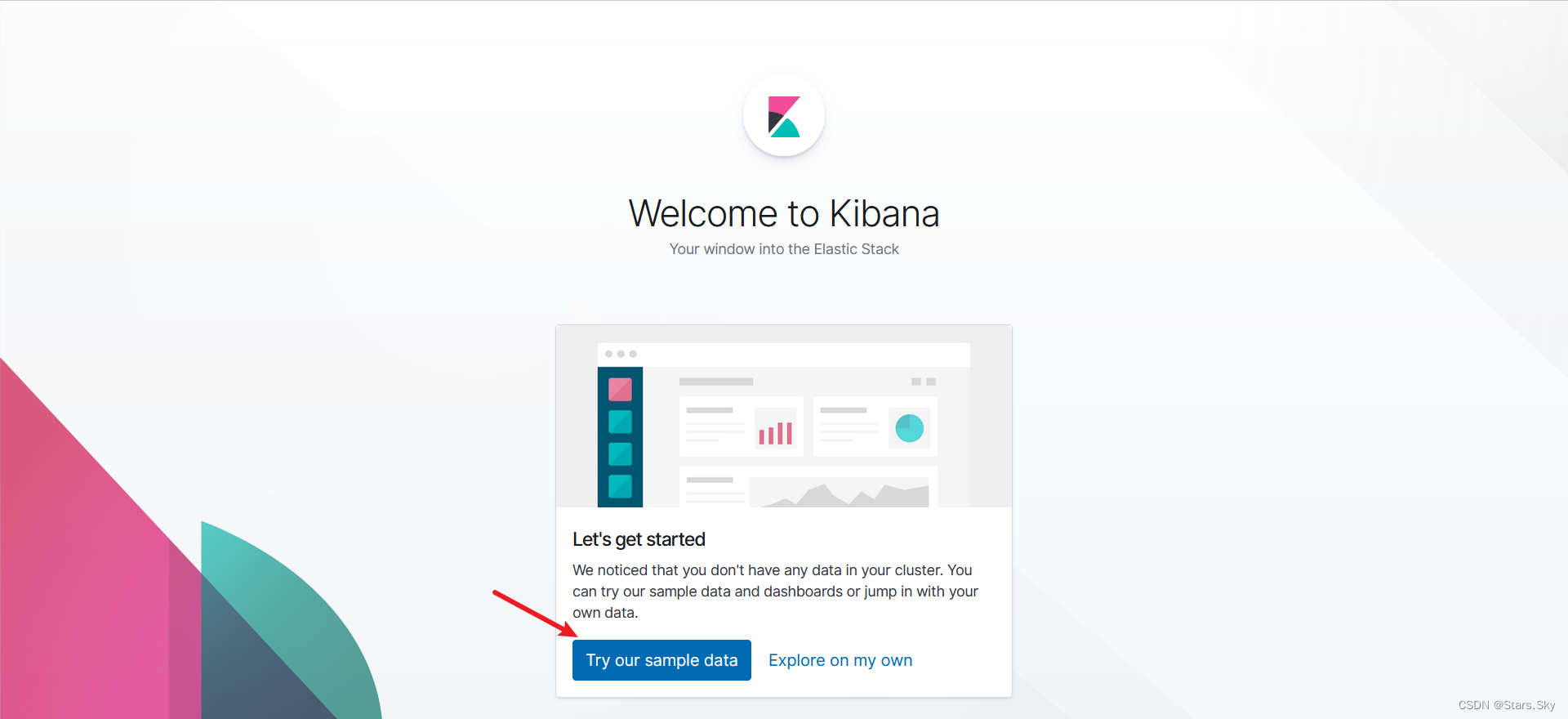
点击左侧的 Discover

可以看到如下配置页面

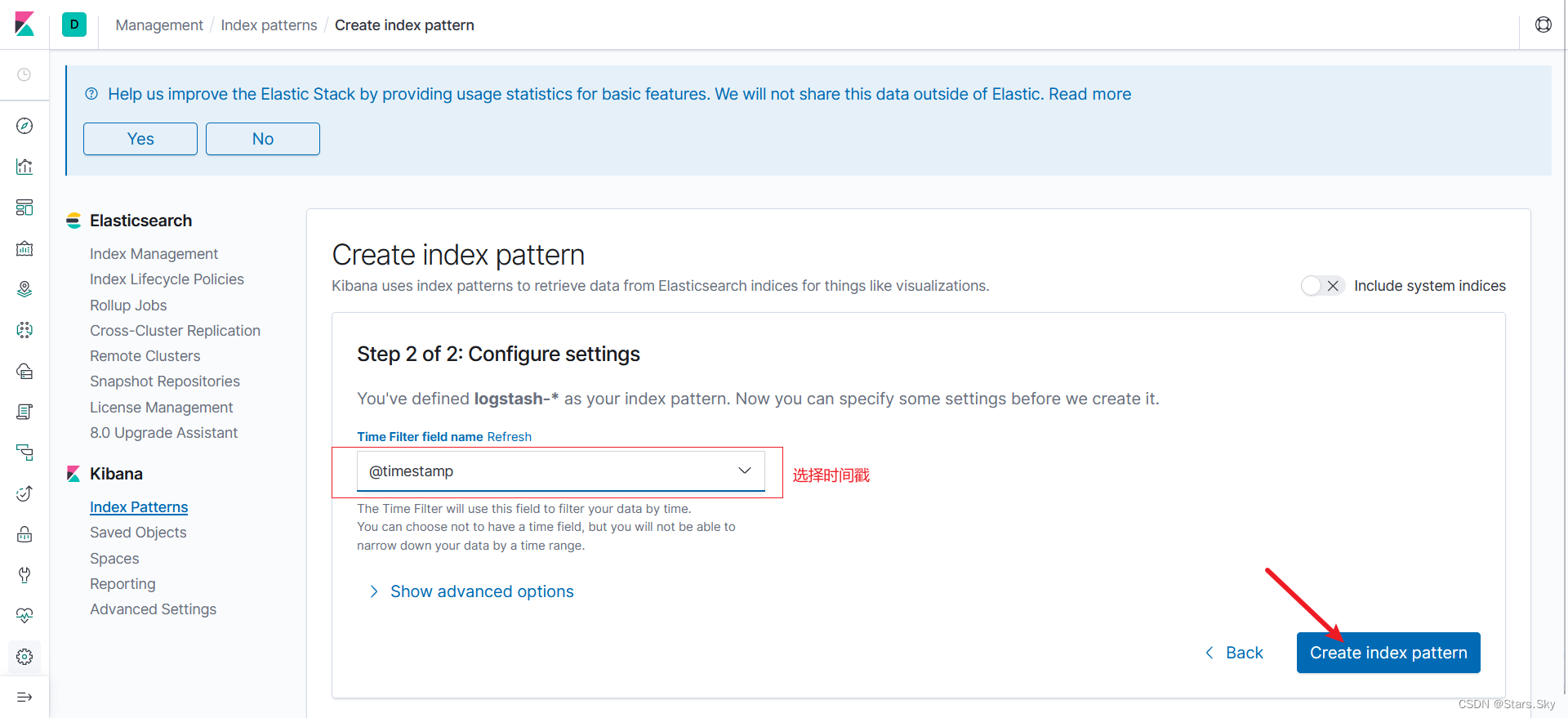
在这里可以配置我们需要的 Elasticsearch 索引,前面 Fluentd 配置文件中我们采集的日志使用的是 logstash 格式,这里只需要在文本框中输入logstash-* 即可匹配到 Elasticsearch 集群中的所有日志数据。点击 Next step:

选择 @timestamp,创建索引
点击左侧的 discover,可看到如下
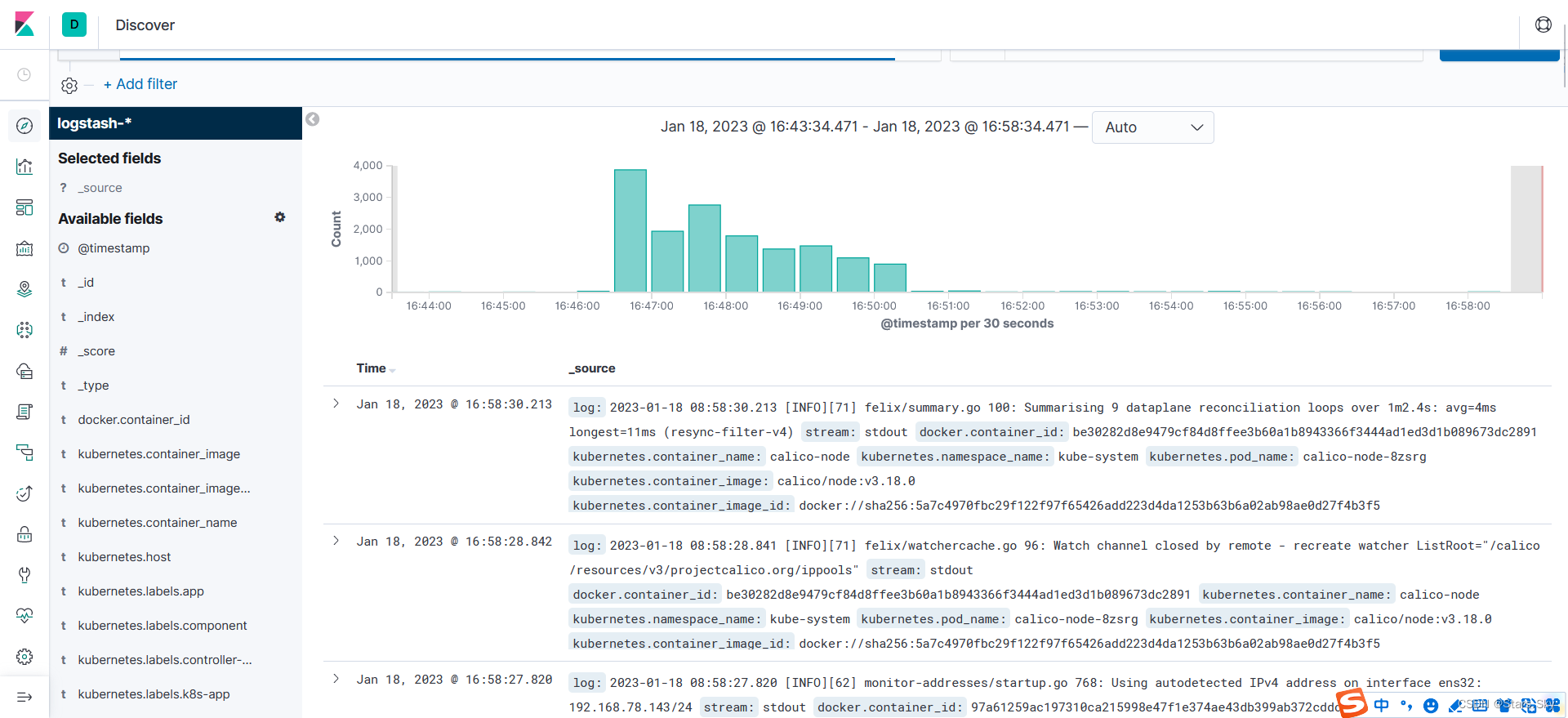
三、测试 efk 收集生产环境业务 pod 日志
[root@k8s-master1 efk]# vim pod.yaml
apiVersion: v1
kind: Pod
metadata:
name: counter
spec:
containers:
- name: count
image: busybox
imagePullPolicy: IfNotPresent
args: [/bin/sh, -c,'i=0; while true; do echo "$i: $(date)"; i=$((i+1)); sleep 1; done']
[root@k8s-master1 efk]# kubectl apply -f pod.yaml
[root@k8s-master1 efk]# kubectl get pods
NAME READY STATUS RESTARTS AGE
counter 1/1 Running 0 25s
nfs-provisioner-6988f7c774-f478v 1/1 Running 2 (56m ago) 138mKibana 查询语言 KQL 官方地址:Kibana Query Language | Kibana Guide [7.2] | Elastic
登录到 kibana 的控制面板,在 discover 处的搜索栏中输入 kubernetes.pod_name:counter,这将过滤名为 counter 的 Pod 的日志数据 ,如下所示:
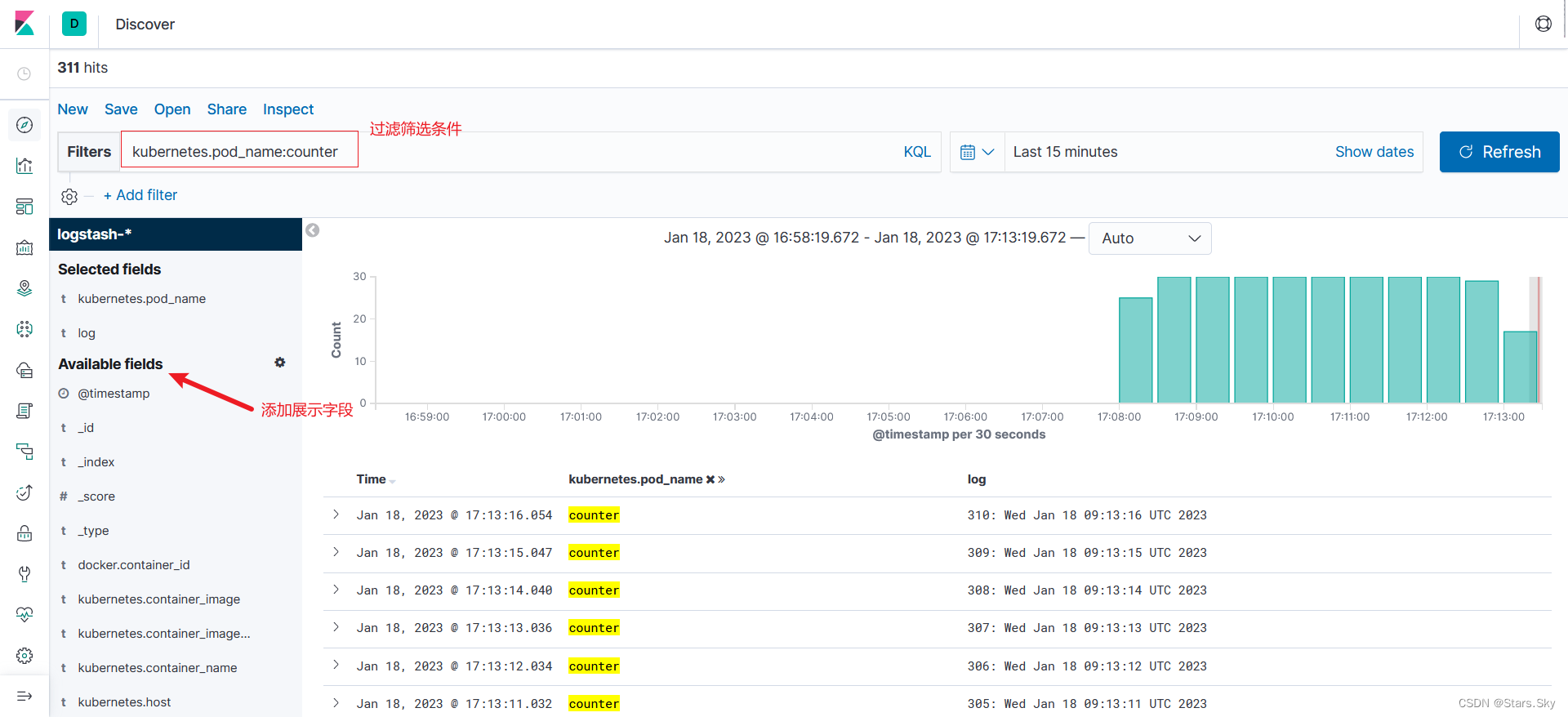
通过前面的实验,我们已经在 k8s 集群成功部署了 elasticsearch、fluentd、kibana,这里使用的 efk 系统包括 3 个 Elasticsearch Pod,一个 Kibana Pod 和一组作为 DaemonSet 部署的Fluentd Pod。
四、基于 EFK+logstash+kafka 构建高吞吐量的日志平台
fluentd --> kafka --> logstash --> elasticsearch --> kibana
适用于数据量大的场景。此处只提供思路方法,有待验证。
4.1 部署 fluentd
[root@k8s-master1 efk]# vim fluentd-configmap.yaml
kind: ConfigMap
apiVersion: v1
metadata:
name: fluentd-config
namespace: logging
labels:
addonmanager.kubernetes.io/mode: Reconcile
data:
system.conf: |-
<system>
root_dir /tmp/fluentd-buffers/
</system>
containers.input.conf: |-
<source>
@id fluentd-containers.log
@type tail
path /var/log/containers/*.log
pos_file /var/log/es-containers.log.pos
time_format %Y-%m-%dT%H:%M:%S.%NZ
localtime
tag raw.kubernetes.*
format json
read_from_head true
</source>
# Detect exceptions in the log output and forward them as one log entry.
<match raw.kubernetes.**>
@id raw.kubernetes
@type detect_exceptions
remove_tag_prefix raw
message log
stream stream
multiline_flush_interval 5
max_bytes 500000
max_lines 1000
</match>
system.input.conf: |-
# Logs from systemd-journal for interesting services.
<source>
@id journald-docker
@type systemd
filters [{ "_SYSTEMD_UNIT": "docker.service" }]
<storage>
@type local
persistent true
</storage>
read_from_head true
tag docker
</source>
<source>
@id journald-kubelet
@type systemd
filters [{ "_SYSTEMD_UNIT": "kubelet.service" }]
<storage>
@type local
persistent true
</storage>
read_from_head true
tag kubelet
</source>
forward.input.conf: |-
# Takes the messages sent over TCP
<source>
@type forward
</source>
output.conf: |-
# Enriches records with Kubernetes metadata
<filter kubernetes.**>
@type kubernetes_metadata
</filter>
<match **>
@id elasticsearch
@type elasticsearch
@log_level info
include_tag_key true
host 192.168.78.143 # es 主机 ip
port 9200
logstash_format true
request_timeout 30s
<buffer>
@type file
path /var/log/fluentd-buffers/kubernetes.system.buffer
flush_mode interval
retry_type exponential_backoff
flush_thread_count 2
flush_interval 5s
retry_forever
retry_max_interval 30
chunk_limit_size 2M
queue_limit_length 8
overflow_action block
</buffer>
</match>
[root@k8s-master1 efk]# kubectl apply -f fluentd-configmap.yaml
[root@k8s-master1 efk]# vim fluentd-daemonset.yaml
apiVersion: v1
kind: ServiceAccount
metadata:
name: fluentd-es
namespace: logging
labels:
k8s-app: fluentd-es
kubernetes.io/cluster-service: "true"
addonmanager.kubernetes.io/mode: Reconcile
---
kind: ClusterRole
apiVersion: rbac.authorization.k8s.io/v1
metadata:
name: fluentd-es
labels:
k8s-app: fluentd-es
kubernetes.io/cluster-service: "true"
addonmanager.kubernetes.io/mode: Reconcile
rules:
- apiGroups:
- ""
resources:
- "namespaces"
- "pods"
verbs:
- "get"
- "watch"
- "list"
---
kind: ClusterRoleBinding
apiVersion: rbac.authorization.k8s.io/v1
metadata:
name: fluentd-es
labels:
k8s-app: fluentd-es
kubernetes.io/cluster-service: "true"
addonmanager.kubernetes.io/mode: Reconcile
subjects:
- kind: ServiceAccount
name: fluentd-es
namespace: logging
apiGroup: ""
roleRef:
kind: ClusterRole
name: fluentd-es
apiGroup: ""
---
apiVersion: apps/v1
kind: DaemonSet
metadata:
name: fluentd-es
namespace: logging
labels:
k8s-app: fluentd-es
version: v2.0.4
kubernetes.io/cluster-service: "true"
addonmanager.kubernetes.io/mode: Reconcile
spec:
selector:
matchLabels:
k8s-app: fluentd-es
version: v2.0.4
template:
metadata:
labels:
k8s-app: fluentd-es
kubernetes.io/cluster-service: "true"
version: v2.0.4
# This annotation ensures that fluentd does not get evicted if the node
# supports critical pod annotation based priority scheme.
# Note that this does not guarantee admission on the nodes (#40573).
annotations:
scheduler.alpha.kubernetes.io/critical-pod: ''
spec:
serviceAccountName: fluentd-es
containers:
- name: fluentd-es
image: cnych/fluentd-elasticsearch:v2.0.4
env:
- name: FLUENTD_ARGS
value: --no-supervisor -q
resources:
limits:
memory: 500Mi
requests:
cpu: 100m
memory: 200Mi
volumeMounts:
- name: varlog
mountPath: /var/log
- name: varlibdockercontainers
mountPath: /var/lib/docker/containers
readOnly: true
- name: config-volume
mountPath: /etc/fluent/config.d
nodeSelector:
beta.kubernetes.io/fluentd-ds-ready: "true"
tolerations:
- key: node-role.kubernetes.io/master
operator: Exists
effect: NoSchedule
terminationGracePeriodSeconds: 30
volumes:
- name: varlog
hostPath:
path: /var/log
- name: varlibdockercontainers
hostPath:
path: /var/lib/docker/containers
- name: config-volume
configMap:
name: fluentd-config
# 创建节点标签
[root@k8s-master1 efk]# kubectl label nodes k8s-master1 beta.kubernetes.io/fluentd-ds-ready=true
[root@k8s-master1 efk]# kubectl label nodes k8s-node1 beta.kubernetes.io/fluentd-ds-ready=true
[root@k8s-master1 efk]# kubectl label nodes k8s-node2 beta.kubernetes.io/fluentd-ds-ready=true
[root@k8s-master1 efk]# kubectl apply -f fluentd-daemonset.yaml 4.2 接入 kafka
[root@k8s-master1 efk]# vim kafka-config.yaml
kind: ConfigMap
apiVersion: v1
metadata:
name: fluentd-config
namespace: logging
labels:
addonmanager.kubernetes.io/mode: Reconcile
data:
system.conf: |-
<system>
root_dir /tmp/fluentd-buffers/
</system>
containers.input.conf: |-
<source>
@id fluentd-containers.log
@type tail
path /var/log/containers/*.log
pos_file /var/log/es-containers.log.pos
time_format %Y-%m-%dT%H:%M:%S.%NZ
localtime
tag raw.kubernetes.*
format json
read_from_head true
</source>
# Detect exceptions in the log output and forward them as one log entry.
<match raw.kubernetes.**>
@id raw.kubernetes
@type detect_exceptions
remove_tag_prefix raw
message log
stream stream
multiline_flush_interval 5
max_bytes 500000
max_lines 1000
</match>
system.input.conf: |-
# Logs from systemd-journal for interesting services.
<source>
@id journald-docker
@type systemd
filters [{ "_SYSTEMD_UNIT": "docker.service" }]
<storage>
@type local
persistent true
</storage>
read_from_head true
tag docker
</source>
<source>
@id journald-kubelet
@type systemd
filters [{ "_SYSTEMD_UNIT": "kubelet.service" }]
<storage>
@type local
persistent true
</storage>
read_from_head true
tag kubelet
</source>
forward.input.conf: |-
# Takes the messages sent over TCP
<source>
@type forward
</source>
output.conf: |-
# Enriches records with Kubernetes metadata
<filter kubernetes.**>
@type kubernetes_metadata
</filter>
<match **>
@id kafka
@type kafka2
@log_level info
include_tag_key true
# list of seed brokers
brokers kafka ip:9092
use_event_time true
# buffer settings
<buffer>
@type file
path /var/log/fluentd-buffers/kubernetes.system.buffer
flush_mode interval
retry_type exponential_backoff
flush_thread_count 2
flush_interval 5s
retry_forever
retry_max_interval 30
chunk_limit_size 2M
queue_limit_length 8
overflow_action block
</buffer>
# data type settings
<format>
@type json
</format>
# topic settings
topic_key topic
default_topic messages
# producer settings
required_acks -1
compression_codec gzip
</match>
[root@k8s-master1 efk]# kubectl apply -f kafka-config.yaml
# 重启 fluentd
[root@k8s-master1 efk]# kubectl delete -f fluentd-daemonset.yaml
[root@k8s-master1 efk]# kubectl apply -f fluentd-daemonset.yaml 4.3 配置 logstash
配置 logstash 消费 messages 日志写入 elasticsearch
[root@k8s-master1 efk]# vim config/kafkaInput_fluentd.conf
input {
kafka {
bootstrap_servers => ["kafka ip:9092"]
client_id => "fluentd"
group_id => "fluentd"
consumer_threads => 1
auto_offset_reset => "latest"
topics => ["messages"]
}
}
filter {
json{
source => "message"
}
ruby {
code => "event.set('timestamp', event.get('@timestamp').time.localtime + 8*60*60)"
}
ruby {
code => "event.set('@timestamp',event.get('timestamp'))"
}
ruby {
code => "event.set('find_time',event.get('@timestamp').time.localtime - 8*60*60)"
}
mutate {
remove_field => ["timestamp"]
remove_field => ["message"]
}
}
output {
elasticsearch{
hosts => ["es ip地址: 9200"]
index => "kubernetes_%{+YYYY_MM_dd}"
}
# stdout {
# codec => rubydebug
# }
}4.4 启动 logstash
[root@k8s-master1 efk]# nohup ./bin/logstash -f config/kafkaInput_fluentd.conf --config.reload.automatic --path.data=/opt/logstash/data_fluentd 2>&1 > fluentd.log &上一篇文章:【Kubernetes 企业项目实战】04、基于 K8s 构建 EFK+logstash+kafka 日志平台(中)_Stars.Sky的博客-CSDN博客