Go map 实现原理
go map 源码路径在:
src/runtime/map.go
go 源码结构
|– AUTHORS — 文件,官方 Go语言作者列表
|– CONTRIBUTORS — 文件,第三方贡献者列表
|– LICENSE — 文件,Go语言发布授权协议
|– PATENTS — 文件,专利
|– README — 文件,README文件,大家懂的。提一下,经常有人说:Go官网打不开啊,怎么办?其实,在README中说到了这个。该文件还提到,如果通过二进制安装,需要设置GOROOT环境变量;如果你将Go放在了/usr/local/go中,则可以不设置该环境变量(Windows下是C:\go)。当然,建议不管什么时候都设置GOROOT。另外,确保$GOROOT/bin在PATH目录中。
|– VERSION — 文件,当前Go版本
|– api — 目录,包含所有API列表,方便IDE使用
|– doc — 目录,Go语言的各种文档,官网上有的,这里基本会有,这也就是为什么说可以本地搭建”官网”。这里面有不少其他资源,比如gopher图标之类的。
|– favicon.ico — 文件,官网logo
|– include — 目录,Go 基本工具依赖的库的头文件
|– lib — 目录,文档模板
|– misc — 目录,其他的一些工具,相当于大杂烩,大部分是各种编辑器的Go语言支持,还有cgo的例子等
|– robots.txt — 文件,搜索引擎robots文件
|– src — 目录,Go语言源码:基本工具(编译器等)、标准库
`– test — 目录,包含很多测试程序(并非_test.go方式的单元测试,而是包含main包的测试),包括一些fixbug测试。可以通过这个学到一些特性的使用。
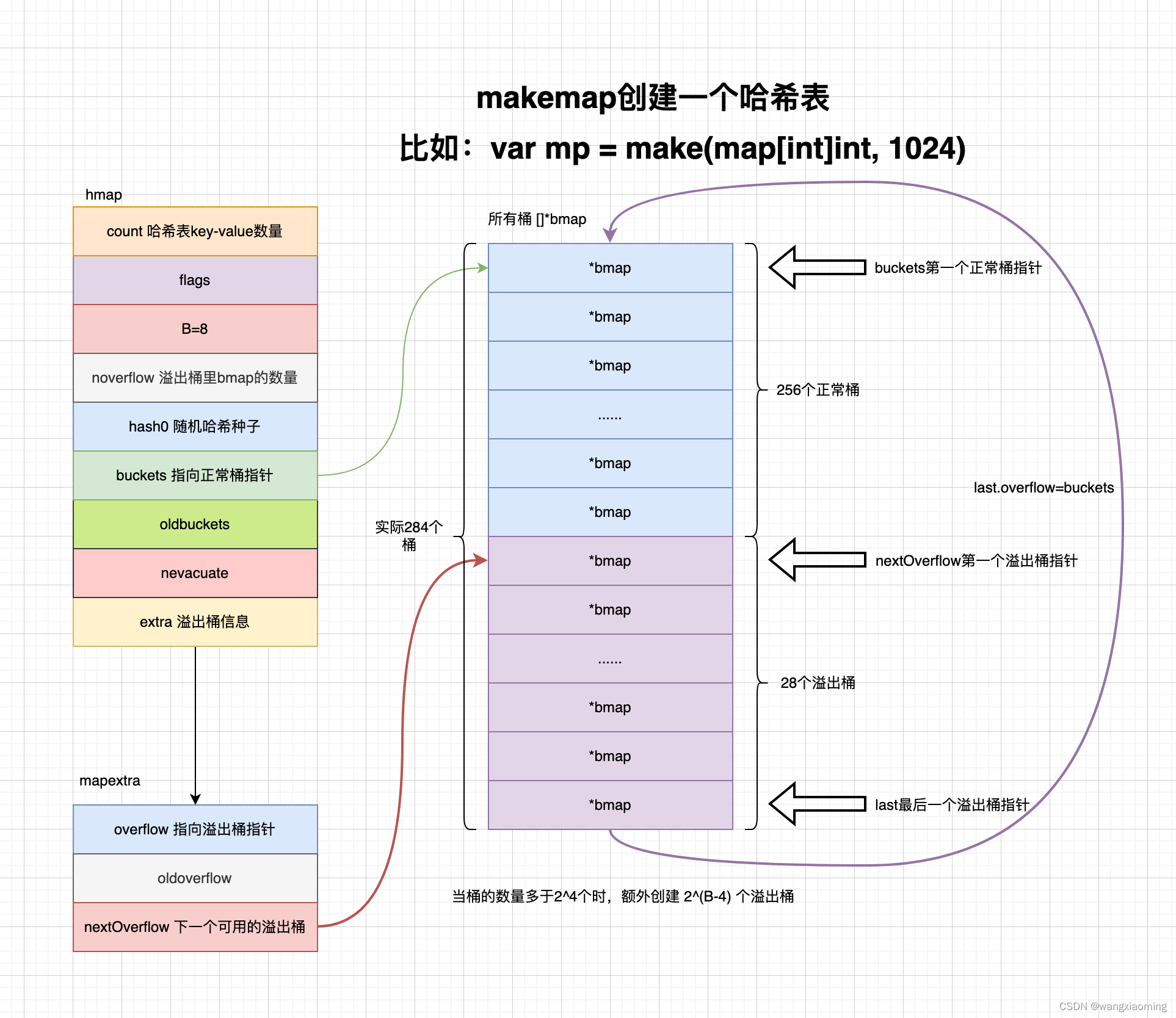
Map的数据结构
// A header for a Go map.
type hmap struct {
// 元素个数,调用 len(map) 时,直接返回此值
count int
flags uint8
// buckets 的对数 log_2
B uint8
// overflow 的 bucket 近似数
noverflow uint16
// 计算 key 的哈希的时候会传入哈希函数
hash0 uint32
// 指向 buckets 数组,大小为 2^B
// 如果元素个数为0,就为 nil
buckets unsafe.Pointer
// 等量扩容的时候,buckets 长度和 oldbuckets 相等
// 双倍扩容的时候,buckets 长度会是 oldbuckets 的两倍
oldbuckets unsafe.Pointer
// 指示扩容进度,小于此地址的 buckets 迁移完成
nevacuate uintptr
extra *mapextra // optional fields
}
// 每个哈希桶bmap结构最多存放8组键值对槽位,注意 src/runtime/map.go bmap结构体只有 tophash 字段
type bmap struct {
tophash [bucketCnt]uint8 // 保存高八位 hash,快速比较,这里高8位不是用来当作key/value在bucket内部的offset的,而是作为一个主键,在查找时对tophash数组的每一项进行顺序匹配的。先比较hash值高位与bucket的tophash[i]是否相等,如果相等则再比较bucket的第i个的key与所给的key是否相等。如果相等,则返回其对应的value,反之,在overflow buckets中按照上述方法继续寻找
keys [bucketCnt] keytype // 保存键
elems [bucketCnt] valuetype // 保存键值
// 存放了对应使用的溢出桶hmap.extra.overflow里的bmap的地址
// 将正常桶hmap.buckets里的bmap关联上溢出桶hmap.extra.overflow的bmap
// 也就是 *bmap
overflow unsafe.Pointer
}
// 溢出桶信息
type mapextra struct {
// 如果 key 和 value 都不包含指针,并且可以被 inline(<=128 字节)
// 就使用 hmap的extra字段 来存储 overflow buckets,这样可以避免 GC 扫描整个 map
// 然而 bmap.overflow 也是个指针。这时候我们只能把这些 overflow 的指针
// 都放在 hmap.extra.overflow 和 hmap.extra.oldoverflow 中了
// overflow 包含的是 hmap.buckets 的 overflow 的 buckets
// oldoverflow 包含扩容时的 hmap.oldbuckets 的 overflow 的 bucket
// 参考:https://liangtian.me/post/go-map
overflow *[]*bmap
oldoverflow *[]*bmap
// 指向预分配的溢出桶里下一个可以使用的bmap
// nextOverflow=nil,表示预分配的溢出桶已经满了
nextOverflow *bmap
}
bucketCntBits = 3
bucketCnt = 1 << bucketCntBits // 8
总的来说,Go 中的 map 结构是个哈希表,不是红黑树。

哈希地址解决冲突一般是:
- 线性探测(当hash冲突,顺序查找下一个位置,直到找到一个空位置)
- 开放地址法(使用某种探测算法在散列表中寻找下一个空的散列地址,只要散列表足够大,空的散列地址总能找到)
- 拉链法(使用链表来保存发生hash冲突的key,即不同的key有一样的hash值,组成一个链表)
如何构建一个 map
当编译器确定 map 大小不大于 8,则通过 makemap_small 构建hmap,否则通过 makemap()
// makemap_small implements Go map creation for make(map[k]v) and
// make(map[k]v, hint) when hint is known to be at most bucketCnt
// at compile time and the map needs to be allocated on the heap.
func makemap_small() *hmap {
h := new(hmap)
h.hash0 = fastrand()
return h
}
// hint 表示初始容量
func makemap(t *maptype, hint int, h *hmap) *hmap {
// 内存容量 = 桶个数 * 每个桶大小
mem, overflow := math.MulUintptr(uintptr(hint), t.bucket.size)
if overflow || mem > maxAlloc {
hint = 0
}
if h == nil {
h = new(hmap)
}
// 快速生成随机哈希种子
h.hash0 = fastrand()
// 负载因子
B := uint8(0)
for overLoadFactor(hint, B) {
B++
}
h.B = B
if h.B != 0 {
var nextOverflow *bmap
h.buckets, nextOverflow = makeBucketArray(t, h.B, nil)
// 是否需要溢出桶
if nextOverflow != nil {
h.extra = new(mapextra)
// 关联下一个可以使用的溢出桶
// 也就是之后可以通过 hmap.extra.nextOverflow 快速查找下一个可以使用的溢出桶
h.extra.nextOverflow = nextOverflow
}
}
return h
}
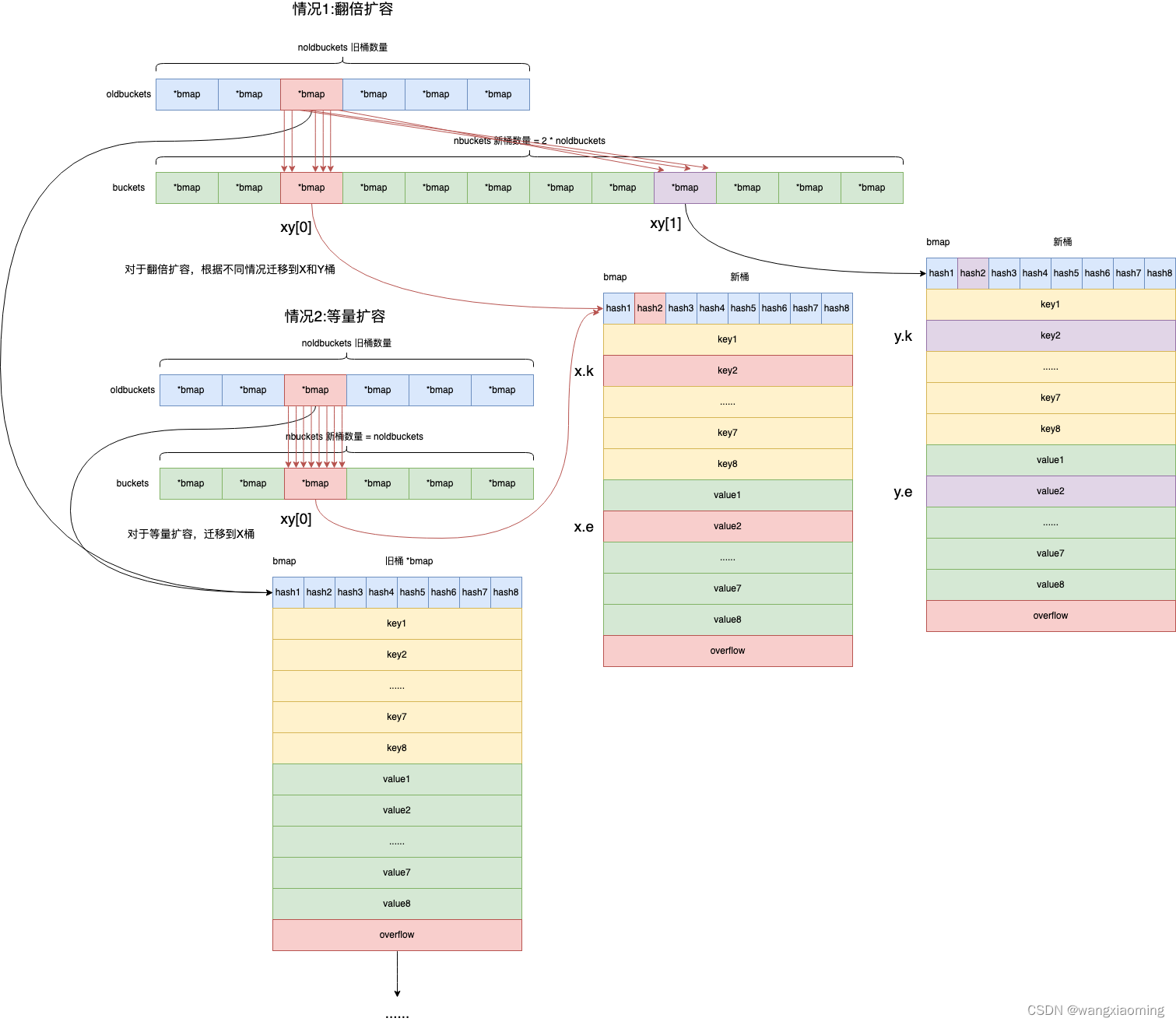
如何扩容
// bucket 表示需要迁移第几个旧桶
func evacuate(t *maptype, h *hmap, oldbucket uintptr) {
// 本次将要迁移的旧桶bmap
b := (*bmap)(add(h.oldbuckets, oldbucket*uintptr(t.bucketsize)))
// 旧桶数量
newbit := h.noldbuckets()
// 旧桶是否已经迁移完成
if !evacuated(b) {
// xy contains the x and y (low and high) evacuation destinations.
var xy [2]evacDst
x := &xy[0]
// 等量时新桶位置
x.b = (*bmap)(add(h.buckets, oldbucket*uintptr(t.bucketsize)))
// 存放在新桶中的key内存地址
x.k = add(unsafe.Pointer(x.b), dataOffset)
// 存放在新桶中的value内存地址
x.e = add(x.k, bucketCnt*uintptr(t.keysize))
// 翻倍扩容
if !h.sameSizeGrow() {
// Only calculate y pointers if we're growing bigger.
// Otherwise GC can see bad pointers.
y := &xy[1]
// 数量翻倍后的新桶位置
y.b = (*bmap)(add(h.buckets, (oldbucket+newbit)*uintptr(t.bucketsize)))
// 存放在新桶中的key内存地址
y.k = add(unsafe.Pointer(y.b), dataOffset)
// 存放在新桶中的value内存地址
y.e = add(y.k, bucketCnt*uintptr(t.keysize))
}
// 遍历所有旧桶(正常桶和溢出桶),将每一个桶的key-value迁移到新桶
for ; b != nil; b = b.overflow(t) {
// 获取旧桶bmap中keys内存起始地址
k := add(unsafe.Pointer(b), dataOffset)
// 获取旧桶bmap中values内存起始地址
e := add(k, bucketCnt*uintptr(t.keysize))
// 遍历8个槽位,获取对应槽位上的 tophash-key-value
for i := 0; i < bucketCnt; i, k, e = i+1, add(k, uintptr(t.keysize)), add(e, uintptr(t.elemsize)) {
top := b.tophash[i]
// 空槽位
if isEmpty(top) {
// 标记该槽位迁移后为空,即没有key-value需要迁移
b.tophash[i] = evacuatedEmpty
continue
}
if top < minTopHash {
throw("bad map state")
}
// 获取key
k2 := k
if t.indirectkey() {
k2 = *((*unsafe.Pointer)(k2))
}
var useY uint8
// 翻倍扩容
if !h.sameSizeGrow() {
// Compute hash to make our evacuation decision (whether we need
// to send this key/elem to bucket x or bucket y).
// 计算key哈希值,也就是key位于哪一个桶
hash := t.hasher(k2, uintptr(h.hash0))
if h.flags&iterator != 0 && !t.reflexivekey() && !t.key.equal(k2, k2) {
// If key != key (NaNs), then the hash could be (and probably
// will be) entirely different from the old hash. Moreover,
// it isn't reproducible. Reproducibility is required in the
// presence of iterators, as our evacuation decision must
// match whatever decision the iterator made.
// Fortunately, we have the freedom to send these keys either
// way. Also, tophash is meaningless for these kinds of keys.
// We let the low bit of tophash drive the evacuation decision.
// We recompute a new random tophash for the next level so
// these keys will get evenly distributed across all buckets
// after multiple grows.
// 当遇到math.NaN()的key时由tophash最低位决定迁移到X或者Y桶
// 因为使用math.Nan()作为key每次求hash都是不一样的。
useY = top & 1
// 重新计算tophash
top = tophash(hash)
} else {
// 是否可以将数据存放在翻倍后的Y桶位置
if hash&newbit != 0 {
useY = 1
}
}
}
if evacuatedX+1 != evacuatedY || evacuatedX^1 != evacuatedY {
throw("bad evacuatedN")
}
// 标记当前旧桶对应槽位迁移到哪个目标桶,是X还是Y
b.tophash[i] = evacuatedX + useY // evacuatedX + 1 == evacuatedY
// 迁移到目标桶
dst := &xy[useY] // evacuation destination
// 迁移目标桶槽位满了
if dst.i == bucketCnt {
// 创建一个溢出桶
dst.b = h.newoverflow(t, dst.b)
dst.i = 0
dst.k = add(unsafe.Pointer(dst.b), dataOffset)
dst.e = add(dst.k, bucketCnt*uintptr(t.keysize))
}
// 记录tophash
dst.b.tophash[dst.i&(bucketCnt-1)] = top // mask dst.i as an optimization, to avoid a bounds check
// 迁移key,复制内存中的值
if t.indirectkey() {
*(*unsafe.Pointer)(dst.k) = k2 // copy pointer
} else {
typedmemmove(t.key, dst.k, k) // copy elem
}
// 迁移value,复制内存中的值
if t.indirectelem() {
*(*unsafe.Pointer)(dst.e) = *(*unsafe.Pointer)(e)
} else {
typedmemmove(t.elem, dst.e, e)
}
// 继续迁移当前桶的下一个 key-value槽位
dst.i++
dst.k = add(dst.k, uintptr(t.keysize))
dst.e = add(dst.e, uintptr(t.elemsize))
}
}
// 迁移完成,清空旧桶bmap中的keys和values
if h.flags&oldIterator == 0 && t.bucket.ptrdata != 0 {
b := add(h.oldbuckets, oldbucket*uintptr(t.bucketsize))
// keys起始内存地址
ptr := add(b, dataOffset)
// 所有的keys和values字节
n := uintptr(t.bucketsize) - dataOffset
memclrHasPointers(ptr, n)
}
}
if oldbucket == h.nevacuate {
advanceEvacuationMark(h, t, newbit)
}
}
如何查找
- 根据
key计算出hash值。 - 如果存在
old bucket, 首先在old bucket中查找,如果找到的bucket已经evacuated,转到步骤3。 反之,返回其对应的value。 - 在
new buckets中查找对应的value。
查找代码如下
func mapaccess1(t *maptype, h *hmap, key unsafe.Pointer) unsafe.Pointer {
if raceenabled && h != nil {
callerpc := getcallerpc()
pc := funcPC(mapaccess1)
racereadpc(unsafe.Pointer(h), callerpc, pc)
raceReadObjectPC(t.key, key, callerpc, pc)
}
if msanenabled && h != nil {
msanread(key, t.key.size)
}
if h == nil || h.count == 0 {
if t.hashMightPanic() {
t.hasher(key, 0) // see issue 23734
}
return unsafe.Pointer(&zeroVal[0])
}
if h.flags&hashWriting != 0 {
throw("concurrent map read and map write")
}
// 1. 根据`key`计算出`hash`值
hash := t.hasher(key, uintptr(h.hash0))
m := bucketMask(h.B)
b := (*bmap)(add(h.buckets, (hash&m)*uintptr(t.bucketsize)))
// 2. 如果存在`old bucket`, 首先在`old bucket`中查找,如果找到的`bucket`已经`evacuated`,从 new buckets 中查找。 反之,返回其对应的`value`
if c := h.oldbuckets; c != nil {
if !h.sameSizeGrow() {
// There used to be half as many buckets; mask down one more power of two.
m >>= 1
}
oldb := (*bmap)(add(c, (hash&m)*uintptr(t.bucketsize)))
if !evacuated(oldb) {
b = oldb
}
}
top := tophash(hash)
bucketloop:
for ; b != nil; b = b.overflow(t) {
for i := uintptr(0); i < bucketCnt; i++ {
if b.tophash[i] != top {
if b.tophash[i] == emptyRest {
break bucketloop
}
continue
}
k := add(unsafe.Pointer(b), dataOffset+i*uintptr(t.keysize))
if t.indirectkey() {
k = *((*unsafe.Pointer)(k))
}
if t.key.equal(key, k) {
e := add(unsafe.Pointer(b), dataOffset+bucketCnt*uintptr(t.keysize)+i*uintptr(t.elemsize))
if t.indirectelem() {
e = *((*unsafe.Pointer)(e))
}
return e
}
}
}
return unsafe.Pointer(&zeroVal[0])
}
mapaccess2
该函数大部分逻辑处理和mapaccess1一样,不过返回的是一个value指针和bool,bool用于指示该key是否存在。
mapaccessK
当通过语法 for k, v := range h {} 遍历map时,Go会在编译期间调用 mapaccessK 。遍历逻辑还是和mapaccess1一样,该函数返回两个指针,分别表示键和值的地址
如何插入
Go 不能往将 nil 数据写入到 map 中,会报错 panic: assignment to entry in nil map , 但是却可以读取一个nil 的 map,这个比较奇怪吧!!!
func mapassign(t *maptype, h *hmap, key unsafe.Pointer) unsafe.Pointer {
...
// 计算key的哈希值
hash := t.hasher(key, uintptr(h.hash0))
// 添加 hashWriting 标志位,防止并发写情况下其他goroutine读取map
h.flags ^= hashWriting
if h.buckets == nil {
h.buckets = newobject(t.bucket) // newarray(t.bucket, 1)
}
again:
// key映射到哪一个桶
bucket := hash & bucketMask(h.B)
// 如果正在扩容,则在每一次写入时迁移一部分旧桶数据到新桶中
if h.growing() {
growWork(t, h, bucket)
// 当旧桶中的数据迁移到新桶后,
// 就可以继续通过 h.buckets 访问新桶中的数据
}
// 获取key在buckets中对应的bmap桶
b := (*bmap)(add(h.buckets, bucket*uintptr(t.bucketsize)))
// 计算key哈希值高8位
top := tophash(hash)
// 存放要修改的tophash、key、value引用
var inserti *uint8
var insertk unsafe.Pointer
var elem unsafe.Pointer
// 遍历正常桶和所有溢出桶中的对应bmap
bucketloop:
for {
// 遍历bmap的所有tophash/keys/values
for i := uintptr(0); i < bucketCnt; i++ {
if b.tophash[i] != top {
// 该位置为空,可插入
if isEmpty(b.tophash[i]) && inserti == nil {
inserti = &b.tophash[i]
insertk = add(unsafe.Pointer(b), dataOffset+i*uintptr(t.keysize))
elem = add(unsafe.Pointer(b), dataOffset+bucketCnt*uintptr(t.keysize)+i*uintptr(t.elemsize))
}
// 桶为空
if b.tophash[i] == emptyRest {
break bucketloop
}
continue
}
// 获取该位置的key指针
k := add(unsafe.Pointer(b), dataOffset+i*uintptr(t.keysize))
if t.indirectkey() {
k = *((*unsafe.Pointer)(k))
}
// key不相同则遍历下一个位置
if !t.key.equal(key, k) {
continue
}
...
// 获取该位置的value指针
elem = add(unsafe.Pointer(b), dataOffset+bucketCnt*uintptr(t.keysize)+i*uintptr(t.elemsize))
goto done
}
// 遍历下一个溢出桶
ovf := b.overflow(t)
// 结束
if ovf == nil {
break
}
b = ovf
}
// 是否需要扩容
if !h.growing() && (overLoadFactor(h.count+1, h.B) || tooManyOverflowBuckets(h.noverflow, h.B)) {
hashGrow(t, h)
goto again // Growing the table invalidates everything, so try again
}
// inserti = nil 说明bmap桶已经满了, 找不到插入槽位
if inserti == nil {
// 创建一个新的溢出桶bmap并关联到hmap.extra.overflow溢出桶中
newb := h.newoverflow(t, b)
// 使用新的溢出桶存放 tophash-key-value
inserti = &newb.tophash[0]
insertk = add(unsafe.Pointer(newb), dataOffset)
elem = add(insertk, bucketCnt*uintptr(t.keysize))
}
if t.indirectkey() {
// 为key分配新的内存
kmem := newobject(t.key)
*(*unsafe.Pointer)(insertk) = kmem
insertk = kmem
}
if t.indirectelem() {
// 为value分配新的内存
vmem := newobject(t.elem)
*(*unsafe.Pointer)(elem) = vmem
}
// 将key保存到对应的位置
typedmemmove(t.key, insertk, key)
// 存储tophash
*inserti = top
// 数量+1
h.count++
done:
if h.flags&hashWriting == 0 {
throw("concurrent map writes")
}
// 取消并发写标志
h.flags &^= hashWriting
// 解引用,返回 unsafe.Pointer 指针类型
if t.indirectelem() {
elem = *((*unsafe.Pointer)(elem))
}
return elem
}
插入逻辑,还有个寻找溢出桶的逻辑 newoverflow 这个函数在前面的
newoverflow 主要流程如下:
如何删除
参考资料
- https://github.com/wangxiaoming/go
- https://www.joxrays.com/go-map/
- https://tiancaiamao.gitbooks.io/go-internals/content/zh/02.3.html
![[leetcode]刷题--关于位运算的几道题](https://img-blog.csdnimg.cn/3d4f3a11a3a34a75acd00c9287c1a9bc.png)