去年10月底的时候,我们的监控系统因为一个偶然的问题,出乎意料地发生了重大的故障,这次故障暴露了当前监控系统存在的一下重大隐患。
故障背景及现象
我们的监控系统基于Thanos构建,基本架构如下(箭头表示数据流向):
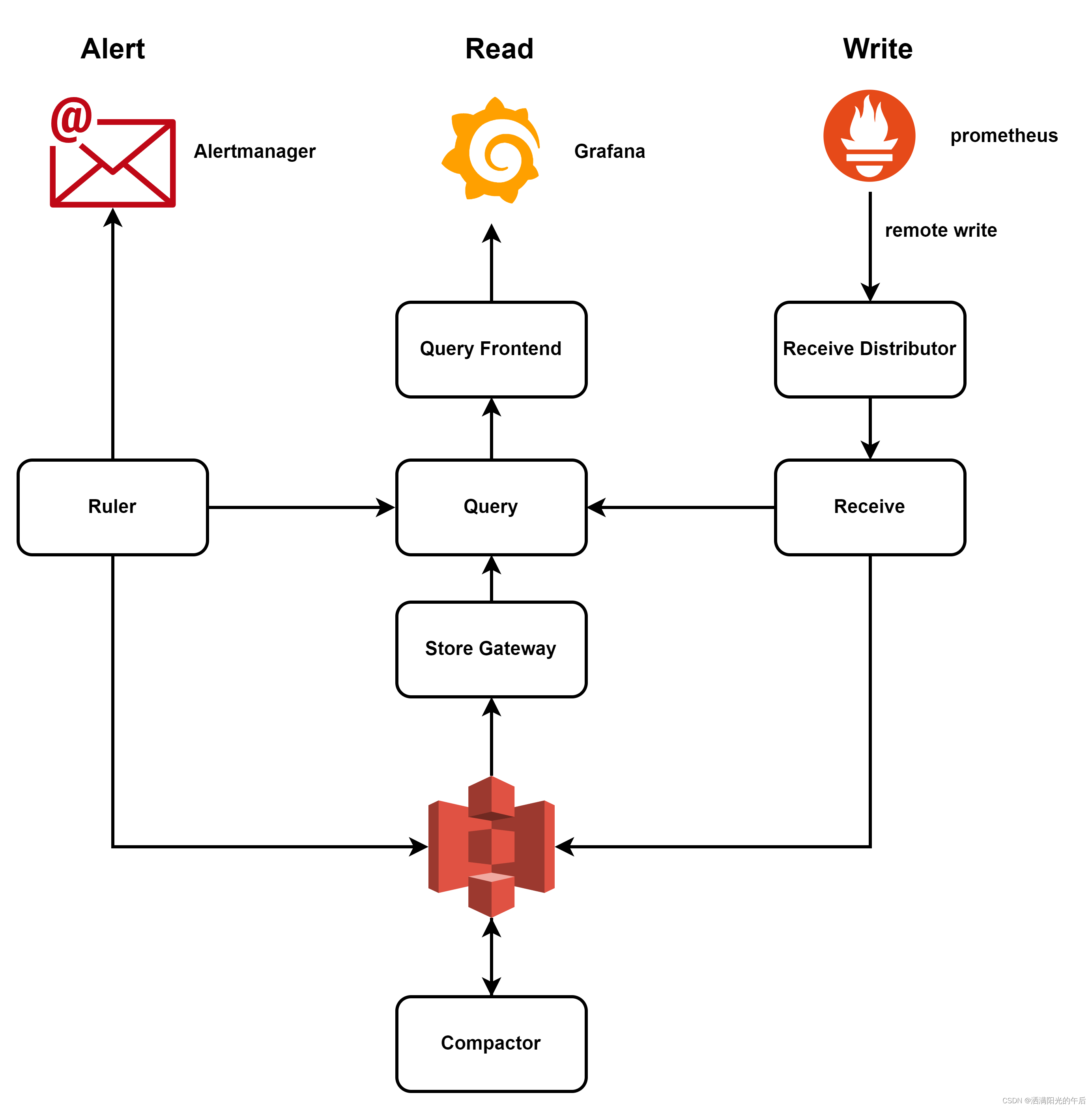
分布在各个区域的prometheus负责指标采集并通过远程写将数据发送给运维中心部署的Thanos套件,Thanos套件负责将指标数据持久化进对象存储并提供统一视图及统一告警能力。
某一次因为网络问题,A区域的prometheus与Thanos之间的发生了长时间中断,当网络重新连接时,A区域大量涌入的数据造成Thanos的distributor与receive组件反复崩溃重启CrashLoopBackOff,引发所有区域的prometheus远程写失败,整个系统处于瘫痪状态。
此时,prometheus端大量发生如下报错:
ts=2022-10-30T16:12:58.897Z caller=dedupe.go:112 component=remote level=error remote_name=da5e4a url=* msg="non-recoverable error" count=3 exemplarCount=0
err="server returned HTTP status 409 Conflict: 2 errors: forwarding request to endpoint thanos-prod-receive-2.thanos-prod-receive-headless.thanos-prod.svc.cluster.local:10901: rpc error: code = AlreadyExists desc = store locally for endpoint thanos-prod-receive-2.thanos-prod-receive-headless.thanos-prod.svc.cluster.local:10901: conflict; forwarding request to endpoint thanos-prod-receive-0.thanos-prod-receive-headless.thanos-prod.svc.cluster.local:10901: rpc error: code = AlreadyExists desc = store locally for endpoint thanos-prod-receive-0.thanos-prod-receive-headless.thanos-prod.svc.cluster.local:10901: conflict"Thanos receive大量发生如下报错:
level=warn ts=2022-10-30T16:12:58.492368127Z caller=writer.go:184 component=receive component=receive-writer tenant=default-tenant
msg="Error on ingesting samples that are too old or are too far into the future" numDropped=3问题分析
该问题的产生源于如下两个事实和两条限制。
两个事实:
prometheus的remote write失败时具有重传机制,remote write并发数会根据数据量及传输情况自动调整;
Thanos基于prometheus源代码构建,receive组件的本地tsdb与prometheus的tsdb具有相同的特性;
旧版Prometheus的TSDB具有如下两条写入限制:
同一序列:无法摄入时序早于当前最新样本的样本,称为out of order samples;
所有序列:无法摄入时序早于当前最新样本1h的样本,称为too old samples(假定storage.tsdb.min-block-duration为默认值2h);
限制1容易理解,可以认为是旧版“时序”数据库TSDB的特点,即数据必须按时间顺序写入。限制2原理可以通过这幅图来表达:
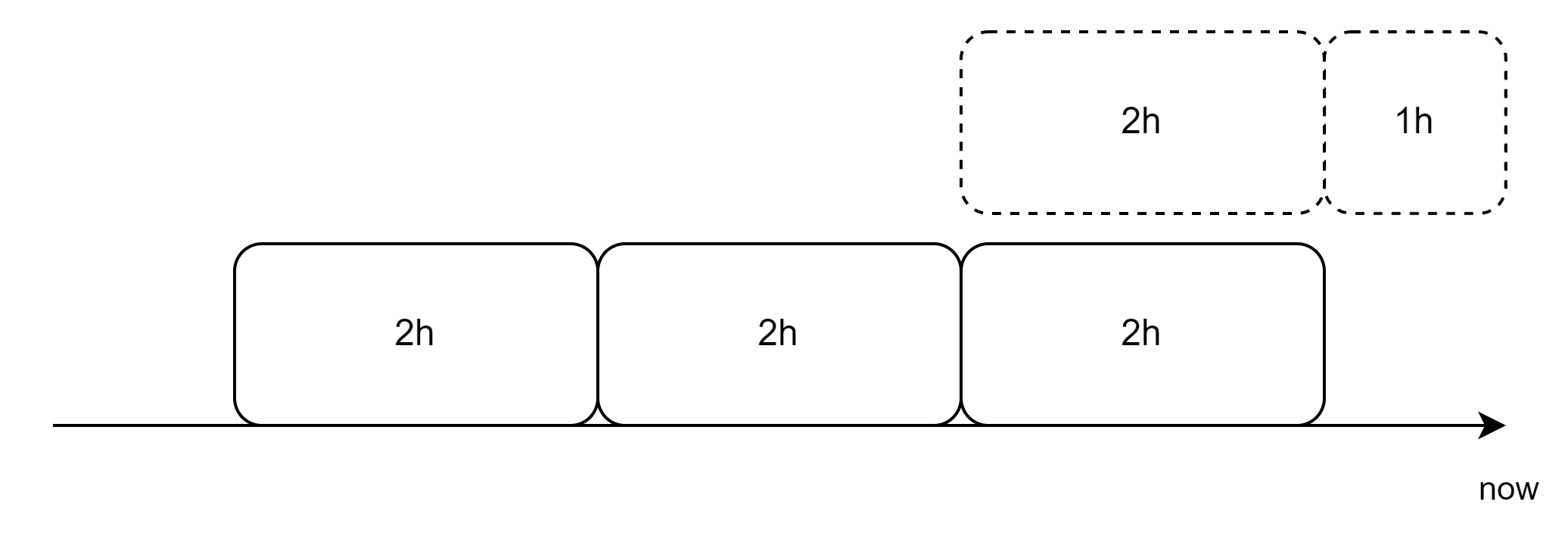
图中每个方块代表含有不同序列组成的数据块(block),虚线表示暂存于内存中尚未刷新到磁盘中的数据,实线表示已经刷新到磁盘的数据。当storage.tsdb.min-block-duration为默认值2h,TSDB并不会在内存中数据时间跨度达到2h时立即落盘,而是再等待1h才会落盘,防止数据切分处产生问题。而数据块一旦落盘后,就不可写入,因为存在限制2。
这两条限制在一些应用场景下会造成较为严重的问题,例如:
在多Prometheus的场景下,如果某个Prometheus因网络故障与Thanos断开连接超过一个小时,而这段时间内其他Prometheus的样本是被Thanos成功摄入的,那么当该Prometheus 网络恢复正常并试图重新推送旧样本时,这些样本将被Thanos拒绝,指标将永久丢失;
使用消息队列(如kafka)的复杂指标传递架构可能会由于拥塞、随机分片或数据预处理产生延迟,进而导致指标无法写入而丢失;
一些指标生产者可能需要聚合过去数小时的数据,然后发送带有旧时间戳的聚合结果,这样的聚合结果无法被TSDB接收;
通过长时间断开网络来节省电量的物联网设备无法可靠地推送指标;
故障回溯
了解了上述一些技术背景后,现在我们来回溯本次故障发生的过程。
Prometheus A网络恢复后,开始重传中断期间发送失败的数据,且由于数据量较大,Prometheus自动增大了远程写的并发数;
由于数据too old,Thanos拒绝了这些数据,并返回4XX报错;
Prometheus A接收到4XX报错,认为发送失败但远端并无问题,所以再次重传;
上述过程反复重复,造成Thanos distributor及receive大量报错并发生拥塞,liveness健康检查失败,并造成pod反复重启;
由于Thanos distributor及receive的反复崩溃重启,造成中心的Thanos系统无法正常接收各个区域Prometheus的远程写,因为所有区域的Prometheus均进行了重写,Thanos端压力进一步增加,引起雪崩;
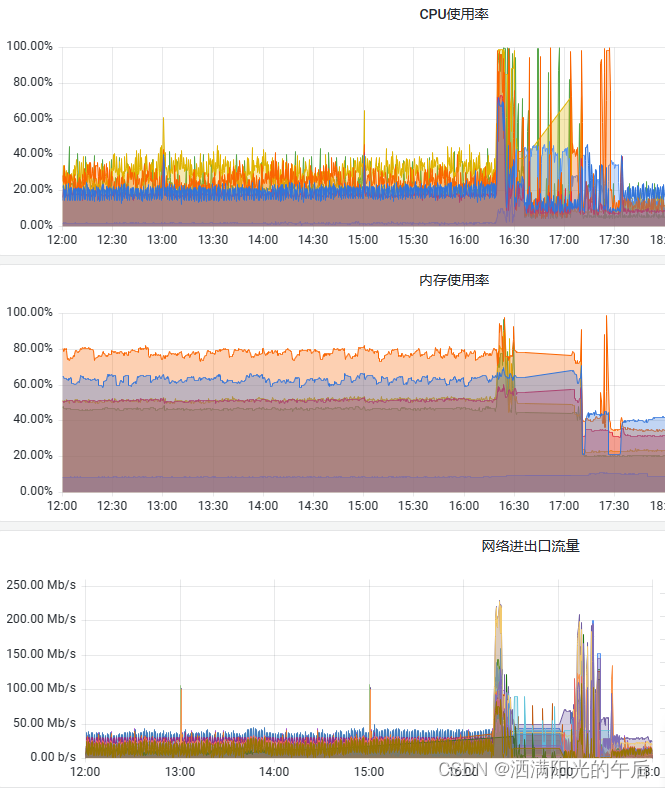
Prometheus端的反复重写造成的系统网络流量、内存、CPU负载的急剧升高,引发的OOM问题,也是本次故障的重要表征:
故障的临时解决方案
为了解决尽快解决这个问题,当时采取了两个不恰当的临时措施:
关闭Thanos receive distributor前的负载均衡端口,拒绝所有Prometheus的数据写入,然后恢复Thanos系统的正常运行;
重启所有区域的Prometheus pod(因为各区域的Prometheus均部署于k8s并使用emptyDir作为数据目录,因此重启pod相当于丢弃了本地所有的历史数据,从而避免大量历史数据的反复重写),然后重新开启Thanos receive distributor的负载均衡端口;
造成的后果是丢失了部分历史数据。
故障的长期解决方案
得益于Prometheus与Thanos社区的高活跃,事后我在Prometheus 2.39.0版本的发布日志中找到了该问题的长期解决方案:
[FEATURE] experimental TSDB: Add support for ingesting out-of-order samples. This is configured via out_of_order_time_window field in the config file; check config file docs for more info. #11075相关的提交见:https://github.com/prometheus/prometheus/pull/11075,其中的设计文档对该问题的解决进行了详细释义。
Thanos社区也迅速跟进,在提交https://github.com/thanos-io/thanos/pull/5839中为receive组件增加了对乱序数据的支持,并于今天1月最新发布的v0.30.0版本中正式上线该特性。
因此针对Prometheus数据回填问题的长期解决方案可以从以下几个方面入手:
Thanos端的优化
升级Thanos至v0.30.1版本及以上,并为receive模块增加如下三个启动参数,启用乱序数据支持:
#If true, shipper will skip failed block uploads in the given iteration and retry later.
#This means that some newer blocks might be uploaded sooner than older block.
#This can trigger compaction without those blocks and as a result will create an overlap situation.
#Set it to true if you have vertical compaction enabled and wish to upload blocks as soon as possible without caring about order.
--shipper.allow-out-of-order-uploads
#Allow overlapping blocks, which in turn enables vertical compaction and vertical query merge.#Does not do anything, enabled all the time.
--tsdb.allow-overlapping-blocks
#[EXPERIMENTAL] Configures the allowed time window for ingestion of out-of-order samples.
#Disabled (0s) by default. Please note if you enable this option and you use compactor, make sure you have the --enable-vertical-compaction flag enabled, otherwise you might risk compactor halt.
--tsdb.out-of-order.time-window=7d为compactor模块增加如下启动参数,启用垂直压缩:
--compact.enable-vertical-compactionPrometheus端的优化
Prometheus端通过配置远程写的queue_config,限制异常时Prometheus的发送速率,减轻Thanos端的压力,以下参数根据实际情况选配,建议优先配置max_shards限制数据发送的并发量,其余参数可使用默认值。
# Configures the queue used to write to remote storage.
queue_config:
# Number of samples to buffer per shard before we block reading of more
# samples from the WAL. It is recommended to have enough capacity in each
# shard to buffer several requests to keep throughput up while processing
# occasional slow remote requests.
capacity: 2500
# Maximum number of shards, i.e. amount of concurrency.
max_shards: 5
# Minimum number of shards, i.e. amount of concurrency.
min_shards: 1
# Maximum number of samples per send.
max_samples_per_send: 500
# Maximum time a sample will wait in buffer.
batch_send_deadline: 5s
# Initial retry delay. Gets doubled for every retry.
min_backoff: 30ms
# Maximum retry delay.
max_backoff: 5s参看:https://prometheus.io/docs/prometheus/latest/configuration/configuration/#remote_write
其余优化项
增加Prometheus离线告警,尽可能避免边缘Prometheus的长时间离线;
为可能的异常情况预留较为充足的CPU、内存资源,避免长时间高位运行;
![[leetcode]刷题--关于位运算的几道题](https://img-blog.csdnimg.cn/3d4f3a11a3a34a75acd00c9287c1a9bc.png)