环境
- Ubuntu 22.04
- IntelliJ IDEA 2022.1.3
- JDK 17.0.3.1
- Spring Boot 3.0.1
- Firefox 108.0.2
问题和分析
在IntelliJ IDEA中创建Spring Boot项目 test0116 ,并选中 Spring Web 依赖。
在 src/main/java 下创建 MyController.java 如下:
package com.example.test0116.controller;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController;
@RestController
public class MyController {
@RequestMapping("/test")
public String test(String data) {
String result = "<h1>The input data is:</h1>" + data;
return result;
}
}
运行程序,测试一下效果:
➜ ~ curl --silent "http://localhost:8080/test?data=abcdefg"
<h1>The input data is:</h1>abcdefg
➜ ~
同理,用浏览器来测试一下:
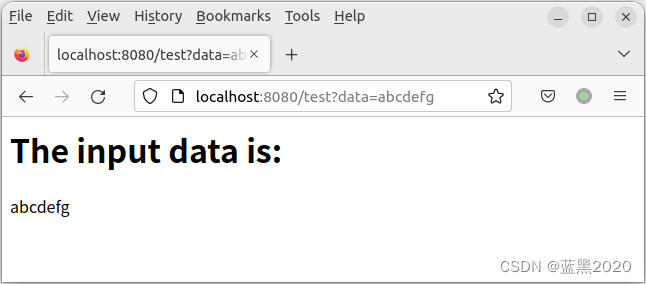
看起来没有什么问题。API请求包含了 data=xxxxx 的参数,服务器返回的response里也包含了该参数值。
但是,如果 xxxxx 是一段script或者HTML元素的文本,那么实际在页面上显示时,并不是只显示 xxxxx 的文本,而是会把 xxxxx 当作script或者HTML来解析。
例如,令 xxxxx 为 <button onclick="alert('haha')">click me</button> ,如下:
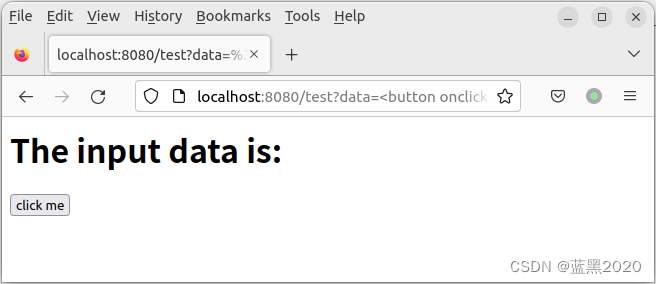
点击按钮,如下:
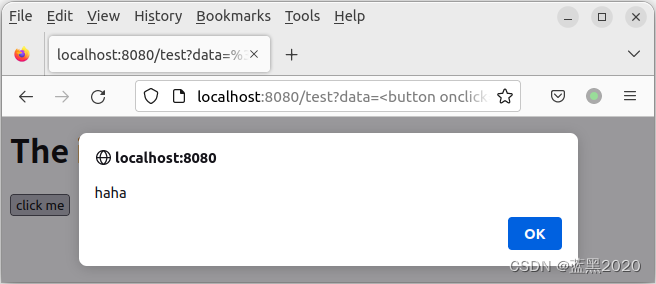
可见,这个API有潜在的风险。比如黑客可以把这个链接发给别人,同时把 xxxxx 替换为一段恶意代码,则其他人如果打开该链接,就会遭受恶意攻击。
比如,黑客给别人的链接里,令 xxxxx 为 <a href="http://bad_link">hello</a> ,则别人打开该链接,页面上就会出现一个恶意网站的链接:

若点击页面上的链接,就会遭受恶意网站攻击。
同理,网站的页面也可能会被攻击。比如,在 src/main/resources/static 目录下创建HTML文件 test.html :
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta http-equiv="X-UA-Compatible" content="IE=edge">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>Document</title>
</head>
<body>
<input id="input1"></input>
<button id="btn1">btn1</button>
<div id="div1"></div>
<script>
const btn1 = document.getElementById('btn1');
btn1.onclick = function () {
const xhr = new XMLHttpRequest();
const input = document.getElementById('input1').value;
xhr.open('GET', "http://localhost:8080/test?data=" + input);
xhr.send();
xhr.onreadystatechange = function () {
if (xhr.readyState === 4 && xhr.status === 200) {
const data = xhr.responseText;
const div1 = document.getElementById("div1");
div1.innerHTML = data;
}
}
}
</script>
</body>
</html>
打开浏览器,访问 http://localhost:8080/test.html ,如下:
在输入框中输入一些文本,然后点击 btn1 按钮,如下:
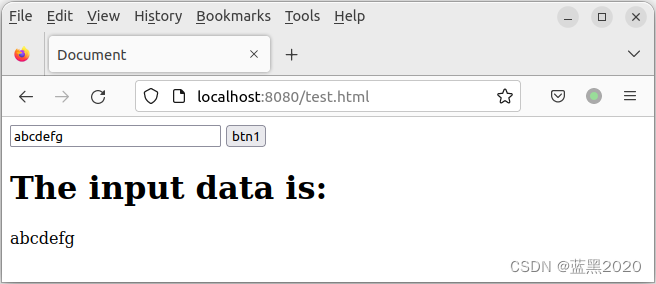
看起来没有问题,但是,类似的,也可以在输入框中输入恶意代码(当然,本例中攻击的是自己的浏览器,这只是一个示例):
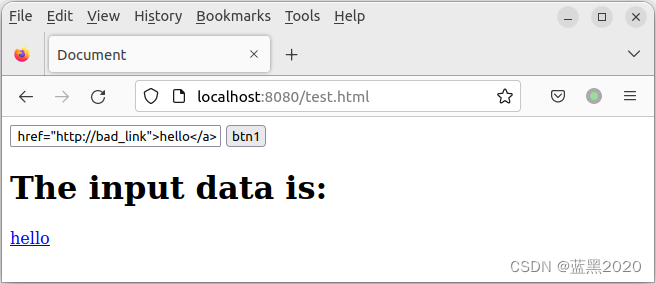
可见,页面上出现了一个恶意链接。
这种攻击手段称为“Cross Site Scripting”,简称“XSS”。
常见的XSS攻击有:
- 存储型:持久化在服务器中,例如评论功能,发表的评论会存储在服务器,评论本来应该是纯文本,但如果包含了恶意代码,将来就有可能运行并造成攻击。比如在评论中包含JavaScript代码,这样别人在获取评论时,就可能遭受攻击;
- 反射型:刚才的例子就是反射型,利用用户恶意输入的请求内容,在响应里包含恶意代码;
- DOM型:不经过服务器,比如发送请求时,本地的脚本会先解析请求的参数,脚本只把参数值看作纯文本,而实际上参数值可能包含了恶意代码,如果脚本处理不当,就有可能造成攻击;
其它
之所以研究这个话题,是因为在代码里,后端代码里会对API请求做参数验证,如果参数值不符合要求,会返回error,以及一个message,大意是“输入参数有误,请检查并更改。参数值:xxxxxx”。也就是说,会把用户不符合条件的参数原封不动的返回给用户。这就跟本文中的例子有点类似,有遭受恶意代码攻击的风险。
如何解决
在网上搜“XSS”,有很多讨论和解决办法,有待深入研究。
如果是像本文中的例子,API返回的是字符串,而且response里既包含HTML或脚本,又包含纯文本,那么很难控制,这应该算是程序设计上的缺陷,因为在服务器端的字符串里,已经把代码和纯文本混在一起,没法区分了。
一个变通的办法是把数据编码,也就是利用转义,强制令其为纯文本,这就不会有代码注入的风险。但是这样一来,前端得到的数据就变了,需要再对其解码,恢复为原先的文本。比如参数验证,明明用户的参数A有误,服务器却告诉用户参数B不正确,这貌似不太合理,不是完美的解决办法。
如果仅返回数据,那么编码/解码应该是OK的。
其实如果返回的是纯文本,比如字符串或者JSON数据,那么只要前端正确的处理,严格把返回数据当作文本,不给其运行的机会,应该也还好吧。