文章目录
- YOLO V3概述
- 网络结构
- backbone:darknet-53
- 特征细化(多scale)
- 残差连接
- 残差网络的发家史
- 先验框
- softmax改进
YOLO V3概述
yolo v3论文地址:https://pjreddie.com/media/files/papers/YOLOv3.pdf
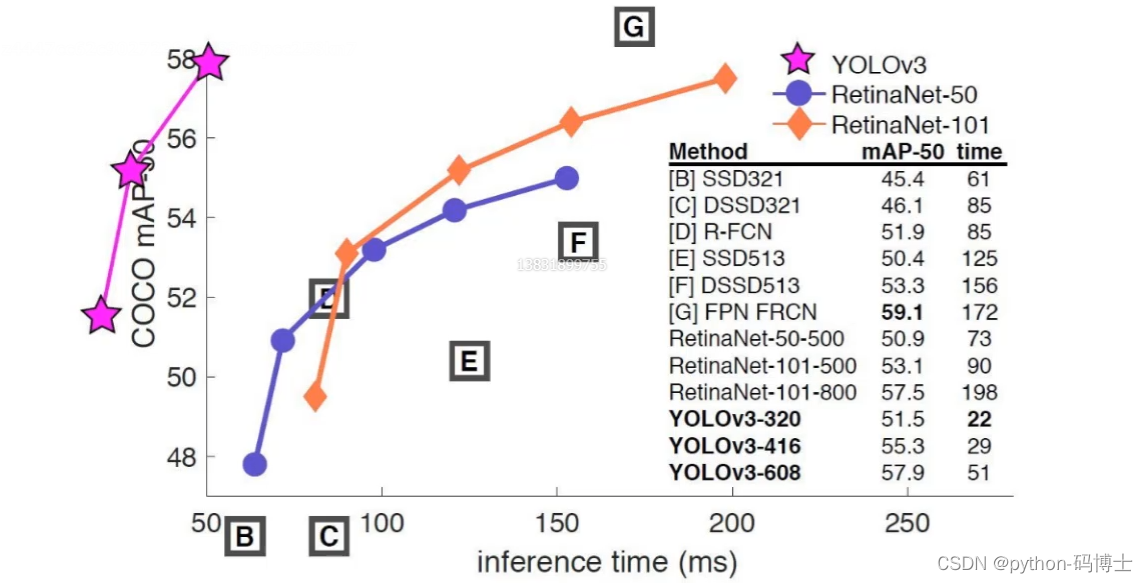
先说说yolo v3的效果:
yolo v3把自己放到了第二象限,将自己与其他的模型区分开来,可见速度之快。(注意,横坐标原点并不是0,而是50),当然mAP值也有提高。
接下来看看yolo v3在yolov2,yolo v1上做了哪些保留和改进,先看看yolo_v3上保留的东西:
- “分而治之”,从yolo_v1开始,yolo算法就是通过划分单元格来做检测,只是划分的数量不一样。
- 采用"leaky ReLU"作为激活函数。
- 端到端进行训练。一个loss function搞定训练,只需关注输入端和输出端。
- 从yolo_v2开始,yolo就用batch normalization作为正则化、加速收敛和避免过拟合的方法,把BN层和leaky relu层接到每一层卷积层之后。
- 多尺度训练。在速度和准确率之间tradeoff。想速度快点,可以牺牲准确率;想准确率高点儿,可以牺牲一点速度。
- yolo每一代的提升很大一部分决定于backbone网络的提升,从v2的darknet-19到v3的darknet-53。yolo_v3还提供替换backbone——tiny darknet。要想性能牛叉,backbone可以用Darknet-53,要想轻量高速,可以用tiny-darknet。总之,yolo就是天生“灵活”,所以特别适合作为工程算法。
- 当然,yolo_v3在之前的算法上保留的点不可能只有上述几点。其他的可以自己探索一下面进入正题,看看yolo v3的改进。
网络结构
这里借个图
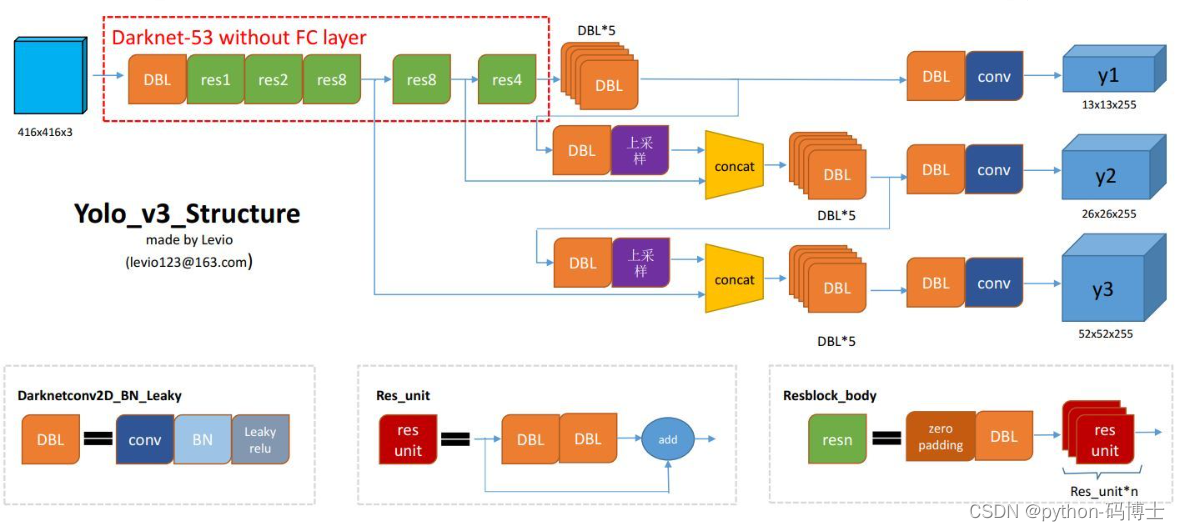
DBL:代码中的Darknetconv2d_BN_Leaky,是yolo_v3的基本组件。就是卷积+BN+Leaky relu。
resn:n代表数字,有res1,res2, … ,res8等等,表示这个res_block里含有多少个res_unit。不懂resnet请戳这儿
concat:张量拼接。将darknet中间层和后面的某一层的上采样进行拼接。拼接的操作和残差层add的操作是不一样的,拼接会扩充张量的维度,而add只是直接相加不会导致张量维度的改变。
为了达到更好的分类效果,作者自己设计训练了darknet-53。作者在ImageNet上实验发现这个darknet-53,的确很强,相对于ResNet-152和ResNet-101,darknet-53不仅在分类精度上差不多,计算速度还比ResNet-152和ResNet-101强多了,网络层数也比他们少。
我们可以借鉴netron来分析网络层,整个yolo_v3_body包含252层,组成如下:

根据表0可以得出,对于代码层面的layers数量一共有252层,包括add层23层(主要用于res_block的构成,每个res_unit需要一个add层,一共有1+2+8+8+4=23层)。除此之外,BN层和LeakyReLU层数量完全一样(72层),在网络结构中的表现为: 每一层BN后面都会接一层LeakyReLU。卷积层一共有75层,其中有72层后面都会接BN+LeakyReLU的组合构成基本组件DBL。看结构图,可以发现上采样和concat都有2次,和表格分析中对应上。每个res_block都会用上一个零填充,一共有5个res_block。
backbone:darknet-53
整个v3结构里面,是没有池化层和全连接层的。前向传播过程中,张量的尺寸变换是通过改变卷积核的步长来实现的,比如stride=(2, 2),这就等于将图像边长缩小了一半(即面积缩小到原来的1/4)。在yolo_v2中,要经历5次缩小,会将特征图缩小到原输入尺寸的1 / 2 5 1/2^51/2
5
,即1/32。输入为416x416,则输出为13x13(416/32=13)。
yolo_v3也和v2一样,backbone都会将输出特征图缩小到输入的1/32。所以,通常都要求输入图片是32的倍数。可以对比v2和v3的backbone看看:(DarkNet-19 与 DarkNet-53)

yolo_v2中对于前向过程中张量尺寸变换,都是通过 最大池化来进行,一共有5次。而v3是通过卷积核 增大步长来进行,也是5次。(darknet-53最后面有一个全局平均池化,在yolo-v3里面没有这一层,所以张量维度变化只考虑前面那5次)。
也可以看这个图,更清楚

也就是52个卷积层(Residual是残差模块,下面会讲到)加1个全连接层构成了主干网络。
这也是416x416输入得到13x13输出的原因。从图2可以看出,darknet-19是不存在残差结构(resblock,从resnet上借鉴过来)的,和VGG是同类型的backbone(属于上一代CNN结构),而darknet-53是可以和resnet-152正面刚的backbone,看下表:

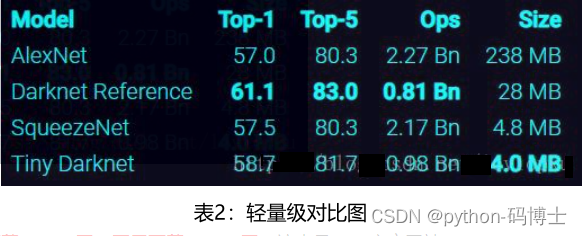
从上表也可以看出,darknet-19在速度上仍然占据很大的优势。其实在其他细节也可以看出(比如bounding box prior采用k=9), yolo_v3并没有那么追求速度,而是在保证实时性(fps>36)的基础上追求performance。不过前面也说了,你要想更快,还有一个 tiny-darknet作为backbone可以替代darknet-53,在官方代码里用一行代码就可以实现切换backbone。搭用tiny-darknet的yolo,也就是tiny-yolo在轻量和高速两个特点上,显然是state of the art级别,tiny-darknet是和squeezeNet正面刚的网络,详情可以看下表:
所以,有了yolo v3,就真的用不着yolo v2了,更用不着yolo v1了。这也是yolo官方网站,在v3出来以后,就没提供v1和v2代码下载链接的原因了。
特征细化(多scale)

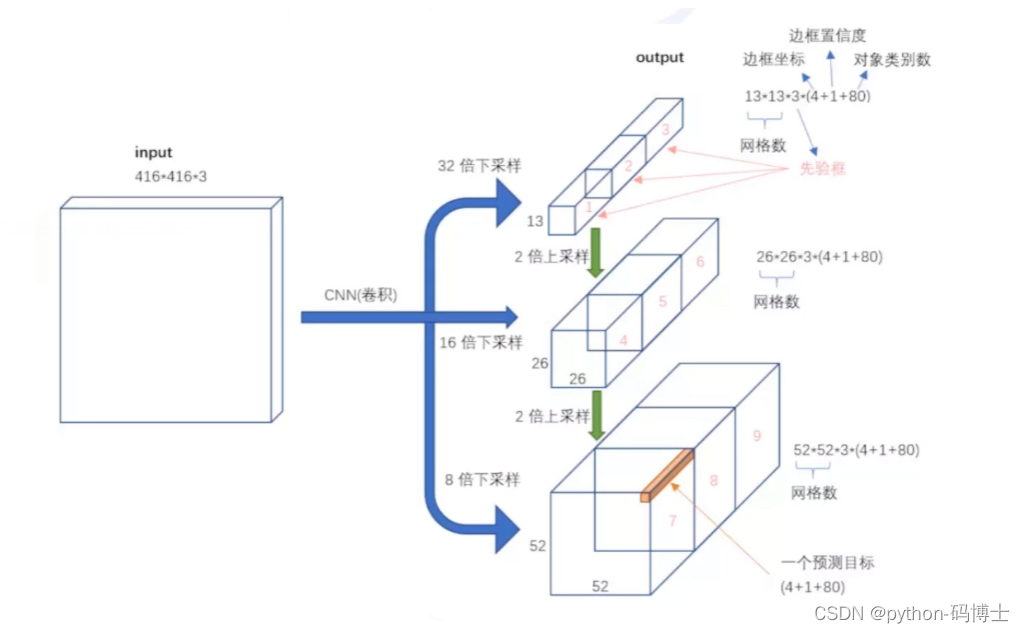
yolo v3输出了3个不同尺度的feature map,如上图所示的Scale 1, Scale 2, Scale 3。这也是v3论文中提到的为数不多的改进点:predictions across scales。
还是感受野的问题,随着网络层数的加深,一个grid cell所包含的信息也就越多,越适合预测大物体,看下面的来理解:
yolo v2的做法是将3层的特征融合到一起,就好像一个人擅长攻击,另一个人擅长防守,把两个人的特征融合在一起就变成2个都会点但是并不是很精通了。所以yolo v3采用了多scale的方法,也就是大中小物体分开来检测。

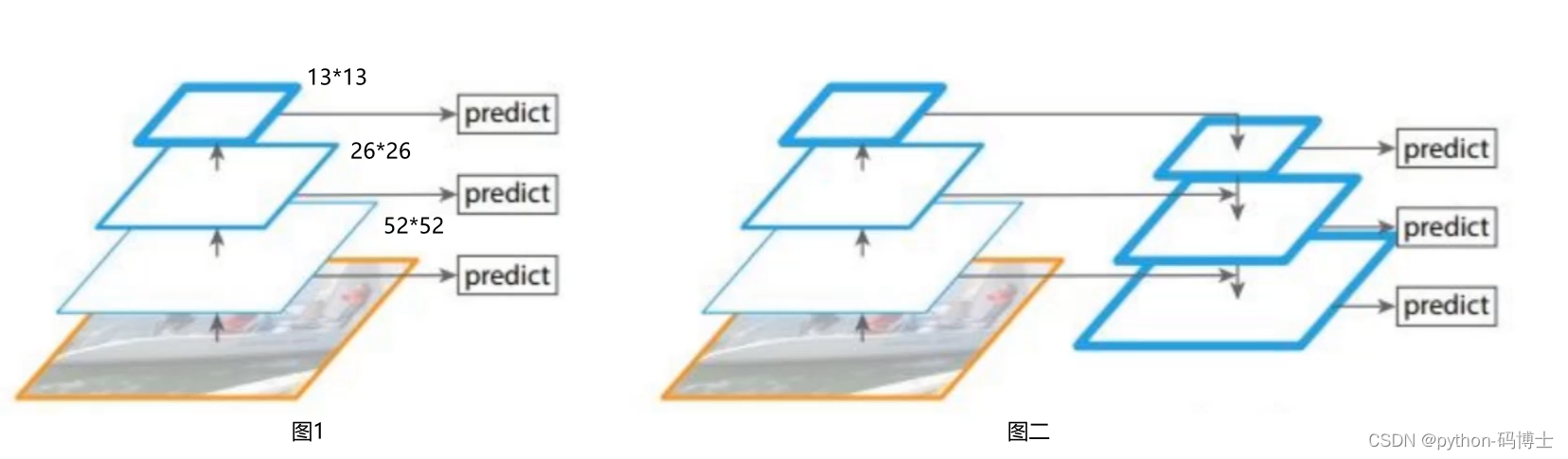
至于分开预测的方式我们先看看下面这张图的图像金字塔思想可以吗?
首先解释一下图像金字塔和单一的输出:
- 图像金字塔:就是可以通过改变图片分辨率的方式,使得每一张图像经过DarkNet52网络层后输出相应大小的特征。
- 单一的输出:yolo v1的做法
这种做法显然是不可以的,因为这样训练速度会大打折扣,yolo本来就是拼速度的。

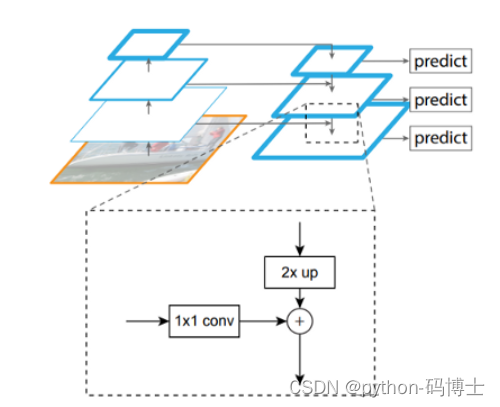
那是不是下面图一的做法呢,其实并不是简单的图一做法。而是图二的做法,在预测2626特征的时候会把1313的特征做一下upsample,也就变成了2626,再和原来的2626特征融合;在预测5252特征的时候会把特征融合过的2626的特征做一下upsample,也就变成了5252,再和原来的5252特征融合,类似FPN的upsample和融合做法。这样做的好处就好像是有一个见多识广的前辈给一些指点。
下面这张图解释的更清楚一些:
残差连接
从今天来看,几乎所有的网络都用上了残差连接的方法。
V3也用了resnet的方法,堆叠更多的层来进行特征提取。
残差网络的发家史
首先在14年的时候VGG网络特别的火,我们都觉得网络层数越多效果越好,但是VGG在做到19层的时候就不行了,后面的结果都比19层的差。就好像下面这张图,56层的网络还没有20层的网络效果好。也是在那个年头,resnet思想横空出世,救活了神经网络,目前各种主流算法都是基于resnet去做的。
那么什么叫resnet呢?
通俗解释一下,比如我做到19层做不下去了,那不可能每一层都做不好吧,比如20层、21层做不好,就沿着20层、21层继续做,同时再把19层的网络映射过来(1*1的卷积),也就是把19层和21层的特征做一个融合,做到“至少不比原来差”。
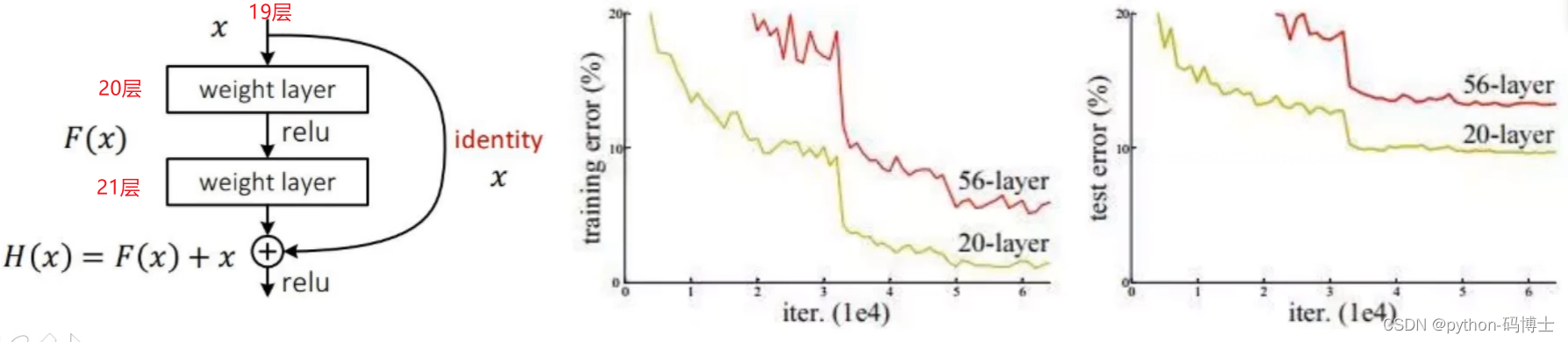
更详细的讲解可以看这篇文章:深度学习——ResNet超详细讲解,详解层数计算、各层维度计算
先验框
这张图帮助理解,没啥难度。
yolo v2中选了5个先验框,而yolo v3更狠一点,选了9个先验框,并且将聚类出来的9个先验框分了3类,分别对应1313,2626,52*52的特征图。

softmax改进
YOLOv3对类别预测的激活函数进行了修改,但是没有使用softmax。首先说明一下为什么不用softmax,原来分类网络中的softmax层都是假设一张图像或一个object只属于一个类别,但是在一些复杂场景下,一个object可能属于多个类,比如你的类别中woman和person这两个类,那么如果一张图像中有一个woman,那么你检测的结果中类别标签就要包含woman和person两个类,这就是多标签分类。
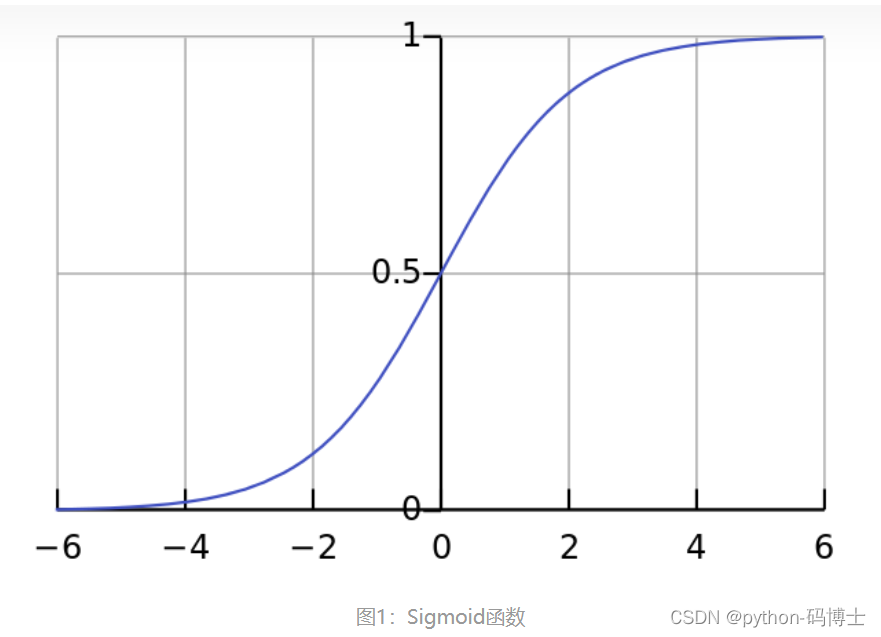
所以YOLOv3用逻辑回归层来对每个类别做二分类。逻辑回归层主要用到sigmoid函数,该函数可以将输出约束在0到1的范围内,因此当一张图像经过特征提取后的某一类输出经过sigmoid函数约束后如果大于0.5,就代表属于该类,这样一个框就可以预测多个类别。代价函数用的是sigmoid的交叉熵。
softmax是多分类,把所有类别概率统一,求出一个最大的概率,也就是最后只有一个类别,无法多标签。
sigmoid把每个类别做二分类,大于某个阈值则是次类,每个输出的分类值不和其他比较,只确定自己是否是某个类别

再通俗的讲一下softmax和sigmoid函数吧,还可以点这里看更详细的讲解。
softmax就好像是单一的数除以总数得到的概率,最终每个数的概率和为1。
sigmoid是把每个数都放到下面图像中,映射出它自身的概率,与图像函数式有关,与其他数值无关。