🤵♂️ 个人主页:@艾派森的个人主页
✍🏻作者简介:Python学习者
🐋 希望大家多多支持,我们一起进步!😄
如果文章对你有帮助的话,
欢迎评论 💬点赞👍🏻 收藏 📂加关注+
目录
1.项目背景
2.项目简介
2.1研究目的及意义
2.2研究方法与思路
2.3技术工具
3.算法原理
4.项目实施步骤
4.1理解数据
4.2探索性数据分析
4.3数据预处理
4.4特征筛选
4.5模型构建
4.6模型评估
5.实验总结
源代码
1.项目背景
当今以互联网、移动终端等为代表的技术力量正深刻地影响着金融支付市场,信息化、网络化、无线终端等技术的应用,使金融机构特别是银行业的经营发生了天翻地覆的变化,传统的银行柜台和网点业务,正渐渐被电子化交易所替代,电子银行以其便利性和增值服务各方面的优势,已经成为银行业保持活力和竞争力的主要发展动力。围绕电子渠道信息泄露、资金被盗、诈骗等威胁与日俱增,欺诈信息、木马病毒、仿制克隆卡等欺诈手段层出不穷,让各家银行头疼不已。本次实验,使用Python大数据分析方法,构建金融反欺诈模型,解决欺诈问题。
2.项目简介
2.1研究目的及意义
以银行信用卡中心为例,影响反欺诈效果的因素包括数据的来源及质量、算法模型的有效性、系统构架以及对应的反制措施。在反欺诈系统中,能否形成全面的用户画像,进而对用户下一步的欺诈风险进行预测,多维度和深度的大数据是必不可少的条件。随着互联网和移动互联网渠道的不断发展,从各类场景识别欺诈行为的重要性将日渐突显。
2.2研究方法与思路
1.读取数据并进行数据探索
2.对数据进行预处理(缺失值、重复值等)
3.特征选择并构建模型进行选择最优模型
4.对模型进行评估
2.3技术工具
Python版本:3.9
代码编辑器:jupyter notebook
3.算法原理
决策树( Decision Tree) 又称为判定树,是数据挖掘技术中的一种重要的分类与回归方法,它是一种以树结构(包括二叉树和多叉树)形式来表达的预测分析模型。其每个非叶节点表示一个特征属性上的测试,每个分支代表这个特征属性在某个值域上的输出,而每个叶节点存放一个类别。一般,一棵决策树包含一个根节点,若干个内部结点和若干个叶结点。叶结点对应于决策结果,其他每个结点对应于一个属性测试。每个结点包含的样本集合根据属性测试的结果划分到子结点中,根结点包含样本全集,从根结点到每个叶结点的路径对应了一个判定的测试序列。决策树学习的目的是产生一棵泛化能力强,即处理未见示例强的决策树。使用决策树进行决策的过程就是从根节点开始,测试待分类项中相应的特征属性,并按照其值选择输出分支,直到到达叶子节点,将叶子节点存放的类别作为决策结果。
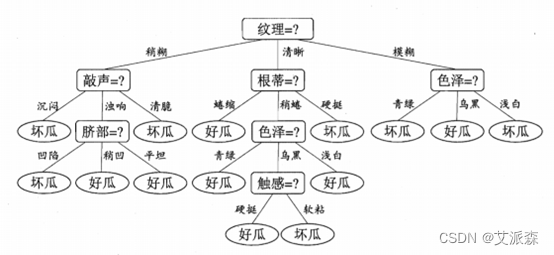
决策树的构建
特征选择:选取有较强分类能力的特征。
决策树生成:典型的算法有 ID3 和 C4.5, 它们生成决策树过程相似, ID3 是采用信息增益作为特征选择度量, 而 C4.5 采用信息增益比率。
决策树剪枝:剪枝原因是决策树生成算法生成的树对训练数据的预测很准确, 但是对于未知数据分类很差, 这就产生了过拟合的现象。涉及算法有CART算法。
决策树的划分选择
熵:物理意义是体系混乱程度的度量。
信息熵:表示事物不确定性的度量标准,可以根据数学中的概率计算,出现的概率就大,出现的机会就多,不确定性就小(信息熵小)。
决策树的剪枝
剪枝:顾名思义就是给决策树 "去掉" 一些判断分支,同时在剩下的树结构下仍然能得到不错的结果。之所以进行剪枝,是为了防止或减少 "过拟合现象" 的发生,是决策树具有更好的泛化能力。
具体做法:去掉过于细分的叶节点,使其回退到父节点,甚至更高的节点,然后将父节点或更高的叶节点改为新的叶节点。
剪枝的两种方法:
预剪枝:在决策树构造时就进行剪枝。在决策树构造过程中,对节点进行评估,如果对其划分并不能再验证集中提高准确性,那么该节点就不要继续王下划分。这时就会把当前节点作为叶节点。
后剪枝:在生成决策树之后再剪枝。通常会从决策树的叶节点开始,逐层向上对每个节点进行评估。如果剪掉该节点,带来的验证集中准确性差别不大或有明显提升,则可以对它进行剪枝,用叶子节点来代填该节点。
注意:决策树的生成只考虑局部最优,相对地,决策树的剪枝则考虑全局最优。
4.项目实施步骤
4.1理解数据
使用pandas加载数据并查看数据前五行
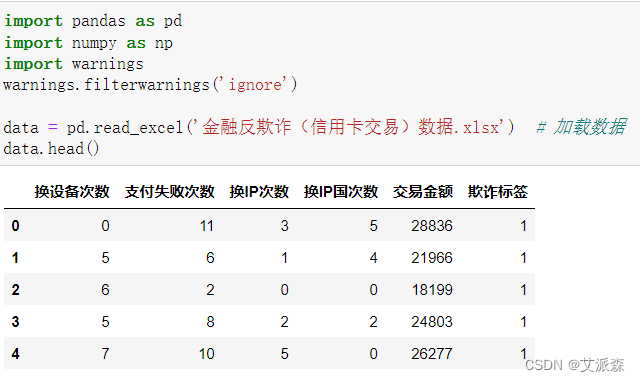
查看数据大小
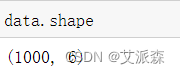
从结果看出,数据共有1000行,6列
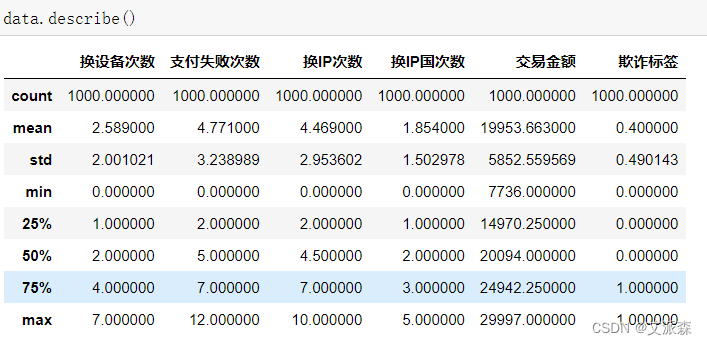
查看数据描述性统计
4.2探索性数据分析
查看交易金额分布情况

从图中看出,交易金额主要分布在10000~30000元之间。
查看欺诈标签的比例
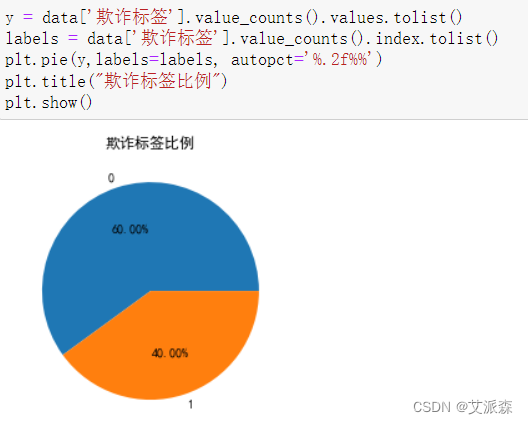
从图中看出,1欺诈标签略微低于0非欺诈标签。
4.3数据预处理
查看数据缺失值情况

从结果中看出数据没有缺失值,不需要进行缺失值处理。
检测数据中是否存在重复值
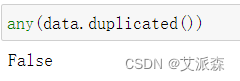
结果为False,说明不存在重复值,不要进行重复值处理。
4.4特征筛选
我们选择除了欺诈标签的数据为特征变量,选择欺诈标签为目标变量。接着对数据集进行拆分,测试集比例为0.2,训练集为0.8。

4.5模型构建
构建KNN算法模型

KNN算法模型的准确率为0.575
构建svm支持向量机模型

svm支持向量机模型的准确率为0.615
构建决策树模型

决策树模型的准确率为0.88
三个模型中,决策树模型的准确率最高,所以最后应该选择决策树模型作为训练模型。
4.6模型评估
对决策树模型进行可视化


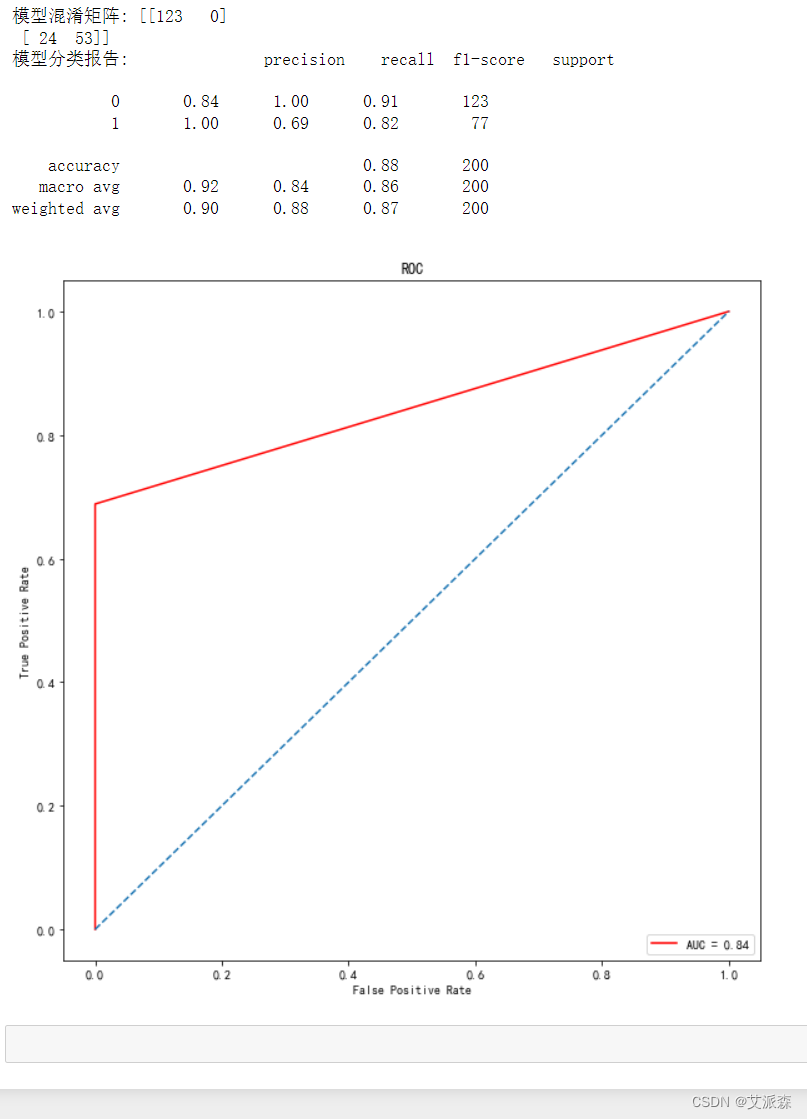
从模型混淆矩阵中可看出模型在0和1分类上正确的个数和错误的个数,从分类报告中可看出模型在0和1分类上的精确率、召回率、f1值等数据。
5.实验总结
通过这次Python项目实战,我学到了许多新的知识,这是一个让我把书本上的理论知识运用于实践中的好机会。原先,学的时候感叹学的资料太难懂,此刻想来,有些其实并不难,关键在于理解。
在这次实战中还锻炼了我其他方面的潜力,提高了我的综合素质。首先,它锻炼了我做项目的潜力,提高了独立思考问题、自我动手操作的潜力,在工作的过程中,复习了以前学习过的知识,并掌握了一些应用知识的技巧等
在此次实战中,我还学会了下面几点工作学习心态:
1)继续学习,不断提升理论涵养。在信息时代,学习是不断地汲取新信息,获得事业进步的动力。作为一名青年学子更就应把学习作为持续工作用心性的重要途径。走上工作岗位后,我会用心响应单位号召,结合工作实际,不断学习理论、业务知识和社会知识,用先进的理论武装头脑,用精良的业务知识提升潜力,以广博的社会知识拓展视野。
2)努力实践,自觉进行主角转化。只有将理论付诸于实践才能实现理论自身的价值,也只有将理论付诸于实践才能使理论得以检验。同样,一个人的价值也是透过实践活动来实现的,也只有透过实践才能锻炼人的品质,彰显人的意志。
3)提高工作用心性和主动性。实习,是开端也是结束。展此刻自我面前的是一片任自我驰骋的沃土,也分明感受到了沉甸甸的职责。在今后的工作和生活中,我将继续学习,深入实践,不断提升自我,努力创造业绩,继续创造更多的价值。
这次Python实战不仅仅使我学到了知识,丰富了经验。也帮忙我缩小了实践和理论的差距。在未来的工作中我会把学到的理论知识和实践经验不断的应用到实际工作中,为实现理想而努力。
源代码
import pandas as pd
import numpy as np
import warnings
warnings.filterwarnings('ignore')
data = pd.read_excel('金融反欺诈(信用卡交易)数据.xlsx') # 加载数据
data.head()
data.shape
data.describe()
import seaborn as sns
import matplotlib.pylab as plt
plt.rcParams['font.sans-serif'] = ['SimHei'] #解决中文显示
plt.rcParams['axes.unicode_minus'] = False #解决符号无法显示
data['交易金额'].hist()
plt.show()
y = data['欺诈标签'].value_counts().values.tolist()
labels = data['欺诈标签'].value_counts().index.tolist()
plt.pie(y,labels=labels, autopct='%.2f%%')
plt.title("欺诈标签比例")
plt.show()
data.isnull().sum()
any(data.duplicated())
X = data.drop('欺诈标签',axis=1)
y = data['欺诈标签']
# 拆分数据集
from sklearn.model_selection import train_test_split
x_train, x_test, y_train, y_test = train_test_split(X, y,test_size=0.2)
# KNN算法模型
from sklearn.neighbors import KNeighborsClassifier
knn = KNeighborsClassifier()
knn.fit(x_train,y_train)
print(knn.score(x_test,y_test))
# svm支持向量机模型
from sklearn.svm import SVC
svc = SVC()
svc.fit(x_train,y_train)
print(svc.score(x_test,y_test))
# 决策树模型
from sklearn.tree import DecisionTreeClassifier
tree = DecisionTreeClassifier(max_depth=4)
tree.fit(x_train,y_train)
print(tree.score(x_test,y_test))
# 决策树可视化
import graphviz
import pydotplus
from six import StringIO
from sklearn.tree import export_graphviz
from IPython.display import Image
# 文件缓存
dot_data = StringIO()
# 将决策树导入到dot中
export_graphviz(tree, out_file=dot_data,
filled=True, rounded=True,
special_characters=True,feature_names = data.columns[:-1],class_names=['0','1'])
# 将生成的dot文件生成graph
graph = pydotplus.graph_from_dot_data(dot_data.getvalue())
# 将结果存入到png文件中
graph.write_png('tree.png')
graph.write_pdf('tree.pdf')
# 显示
Image(graph.create_png())
# 模型评估
from sklearn.metrics import confusion_matrix,classification_report,roc_curve, auc
y_pred = tree.predict(x_test)
print('模型混淆矩阵:',confusion_matrix(y_test,y_pred))
print('模型分类报告:',classification_report(y_test,y_pred))
# 画出ROC曲线
y_prob = tree.predict_proba(x_test)[:,1]
false_positive_rate, true_positive_rate, thresholds = roc_curve(y_test, y_prob)
roc = auc(false_positive_rate, true_positive_rate)
plt.figure(figsize=(10,10))
plt.title('ROC')
plt.plot(false_positive_rate,true_positive_rate, color='red',label = 'AUC = %0.2f' % roc)
plt.legend(loc = 'lower right')
plt.plot([0, 1], [0, 1],linestyle='--')
plt.axis('tight')
plt.ylabel('True Positive Rate')
plt.xlabel('False Positive Rate')
plt.show()