一、响应式流是什么?
Reactive Streams 是 2013 年底由 Netflix、Lightbend 和 Pivotal(Spring 背后的公司)的工程师发起的一项计划,响应式流旨在为无阻塞异步流处理提供一个标准。它旨在解决处理元素流的问题——如何将元素流从发布者传递到订阅者,而不需要发布者阻塞,或订阅者有无限制的缓冲区或丢弃。
响应式流模型存在两种基本的实现机制。一种就是传统开发模式下的“拉”模式,即消费者主动从生产者拉取元素;而另一种就是“推”模式,在这种模式下,生产者将元素推送给消费者。相较于“拉”模式,“推”模式下的数据处理的资源利用率更好,下图所示的就是一种典型的推模式处理流程。
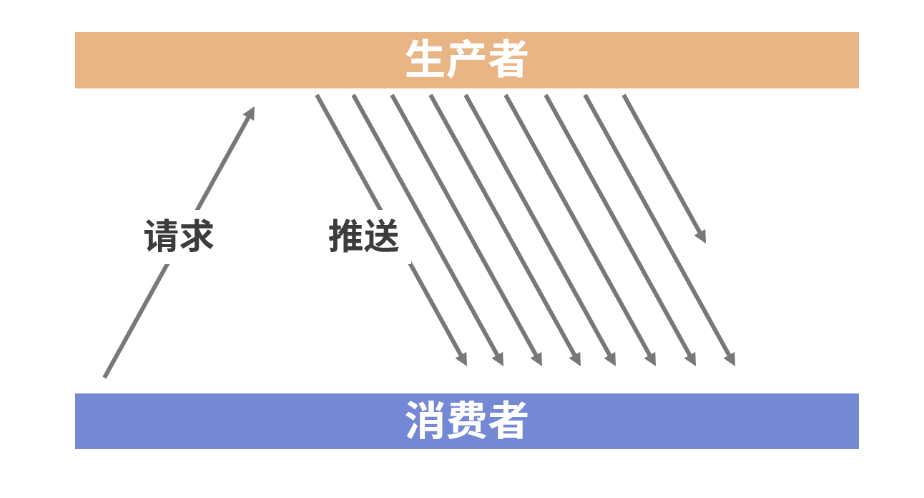
上图中,数据流的生产者会持续地生成数据并推送给消费者。这里就引出了流量控制问题,即如果数据的生产者和消费者处理数据的速度是不一致的,我们应该如何确保系统的稳定性呢?
二、流量控制
2.1 生产者生产数据的速率小于消费者的场景
这种场景对于消费者来说没啥压力,正常消费就好了,这里也就不需要所谓的流量控制了。
2.2 生产者生产数据的速率大于消费者的场景
生产者生产数据的速率大于消费者的场景,应该是我们业务中经常遇到的场景了,这种场景由于消费者处理不过来导致崩溃,业界通常的做法是在生产者与消费者之间加一个队列做缓冲。我们知道队列具有存储与转发的功能,所以可以用它来进行一定的流量控制。

如何对于流量进行很好的控制?这就转变到了如何设计好一个队列了,目前 Java 业界主流的队列有以下三种:
2.2.1 无界队列
见名知意,无界队列在原则上是拥有无线大小容量的队列,可以存放生产者产生的所有消息。

- 优势:确保消费者消费到所有的数据
- 劣势:系统的回弹性降低,任何一个系统不可能拥有无限的资源,一旦内存等资源耗尽,系统就可能会有崩溃的风险。
2.2.2 有界丢弃队列
为了避免上面无界队列的弊端,有界丢弃队列采用的是如果队列满了,就会采用丢弃后面传入的值,这里可以设置一些丢弃策略,比如说按照优先级或先进先出等。

- 优势:考虑到资源的限制,适合允许丢消息的业务场景。
- 劣势:消息重要性很高的场景不建议采取这种队列
2.2.3 有界阻塞队列
像一些支付金融级别的场景,是不允许丢数据的,所以我们引出有界阻塞队列,我们会在队列消息数量达到上限后阻塞生产者,而不是直接丢弃消息。

- 优势:解决了不允许丢数据的业务场景
- 劣势:当队列满了的时候,会阻塞生产者停止生产数据,这种场景不可能实现异步操作的。
所以,无论从回弹性、弹性还是即时响应性出发,上述的队列都不是响应式流的上佳解决办法。
三、背压机制
上面说的那几种队列纯“推”模式下的数据流量会有很多不可控制的因素,并不能直接应用,而是需要在“推”模式和“拉”模式之间考虑一定的平衡性,从而优雅地实现流量控制。这就需要引出响应式系统中非常重要的一个概念——背压机制(Backpressure)。
什么是背压?简单来说就是下游能够向上游反馈流量请求的机制。通过前面的分析,我们知道如果消费者消费数据的速度赶不上生产者生产数据的速度时,它就会持续消耗系统的资源,直到这些资源被消耗殆尽。
这个时候,就需要有一种机制使得消费者可以根据自身当前的处理能力通知生产者来调整生产数据的速度,这种机制就是背压。采用背压机制,消费者会根据自身的处理能力来请求数据,而生产者也会根据消费者的能力来生产数据,从而在两者之间达成一种动态的平衡,确保系统的即时响应性。
四、响应式流规范
有了背压机制,我们再来看下响应式流是如何基于这种机制去设计的一套规范,规范详情请参考:Reactive Streams
Java API 的响应式流只定义了四个核心接口:
- Publisher<
T> - Subscriber<
T> - Subscription
- Processor<
T,R>
4.1 Publisher<T>
Publisher 代表的就是一种可以生产无限数据的发布者,接口如下:
public interface Publisher<T> {
public void subscribe(Subscriber<? super T> s);
}
可以看到,Publisher 里的 subscribe 方法传入的是 Subscriber 接口,其实这里用的是回调,Publisher 根据收到的请求向当前订阅者 Subscriber 发送元素。
4.2 Subscriber<T>
Subscriber 代表的是一种可以从发布者那里订阅并接收元素的订阅者,接口如下:
public interface Subscriber<T> {
public void onSubscribe(Subscription s);
public void onNext(T t);
public void onError(Throwable t);
public void onComplete();
}
Subscriber 接口定义的这组方法构成了数据流请求和处理的基本流程,其中,onSubscribe() 从命名上看就是一个回调方法,当发布者的 subscribe() 方法被调用时就会触发这个回调。而在该方法中有一个参数 Subscription,可以把这个 Subscription 看作是一种用于订阅的上下文对象。Subscription 对象中包含了这次回调中订阅者想要向发布者请求的数据个数。
当订阅关系已经建立,那么发布者就可以调用订阅者的 onNext() 方法向订阅者发送一个数据。这个过程是持续不断的,直到所发送的数据已经达到 Subscription 对象中所请求的数据个数。这时候 onComplete() 方法就会被触发,代表这个数据流已经全部发送结束。而一旦在这个过程中出现了异常,那么就会触发 onError() 方法,我们可以通过这个方法捕获到具体的异常信息进行处理,而数据流也就自动终止了。
4.3 Subscription
Subscription 代表的就是一种订阅上下文对象,它在订阅者和发布者之间进行传输,从而在两者之间形成一种契约关系,接口如下:
public interface Subscription {
public void request(long n);
public void cancel();
}
这里的 request() 方法用于请求 n 个元素,订阅者可以通过不断调用该方法来向发布者请求数据;而 cancel() 方法显然是用来取消这次订阅。请注意,Subscription 对象是确保生产者和消费者针对数据处理速度达成一种动态平衡的基础,也是流量控制中实现背压机制的关键所在。

4.4 Processor<T,R>
Processor 代表的就是订阅者和发布者的处理阶段,Processor 接口继承了 Publisher 和 Subscriber 接口。 它用于转换发布者——订阅者管道中的元素。 Processor<T,R> 订阅类型 T 的数据元素,接收并转换为类型 R 的数据,并发布变换后的数据。接口如下:
public interface Processor<T,R> extends Subscriber<T>, Publisher<R> {
}
下图显示了处理者在发布者——订阅和管道中作为转换器的作用,可以拥有多个处理者。

五、总结
- 响应式流规范定义的很简洁,但实现起来并不简单,发布者和订阅者之间的所有交互的异步性质以及背压机制使得实现变得复杂。
- 响应式流规范非常灵活,还可以提供独立的“推”模型和“拉”模型。如果为了实现纯“推”模型,我们可以考虑一次请求足够多的元素;而对于纯“拉”模型,相当于就是在每次调用 Subscriber 的 onNext() 方法时只请求一个新元素。
- JDK 9 中提供了 Flow 响应式流接口,与响应式流兼容的接口,可以看得出,JDK 团队后续的发展趋势也是想往响应式流这块靠近。

![[有人@你]请查收你的年终总结报告](https://img-blog.csdnimg.cn/04c0ab15cc474ade804e2a524c4ce92d.png)