文章目录
- 1、fastdfs文件系统原理简述
- 2、storage server状态
- 2.1 组内新增加一台storage server A时,由系统自动完成已有数据同步,处理逻辑如下:
- 第一步:
- 第二步:
- 第三步:
- 第四步:
- 3、同步时间管理
- 4、Binlog文件
- 5、Storage Server具体同步过程
- 6、上传和下载流程
- 7、参考
1、fastdfs文件系统原理简述
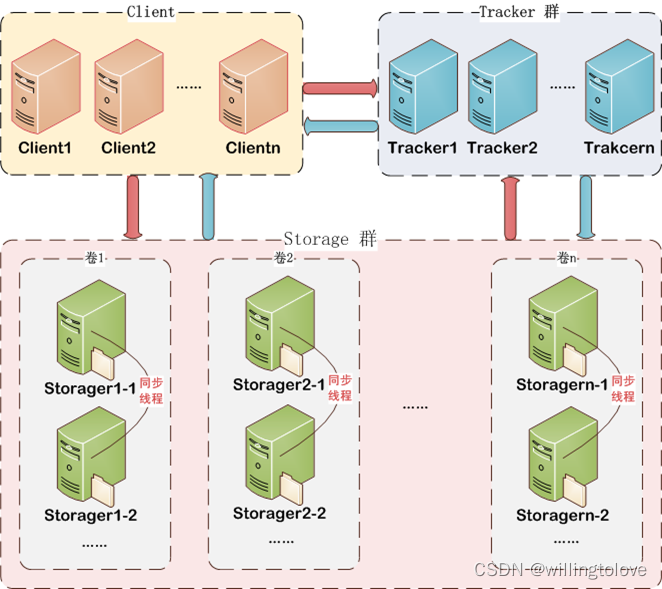
tracker server的配置文件中没有出现storage server,而storage server的配置文件中会列举出所有的tracker server。
这就决定了storage server和tracker server之间的连接由storage server主动发起,storage server为每个tracker server启动一个线程进行连接和通讯。
tracker server会在内存中保存storage分组及各个组下的storage server,并将连接过自己的storage server及其分组
保存到文件中,以便下次重启服务时能直接从本地磁盘中获得storage相关信息。storage server会在内存中记录本组的所有服务器,
并将服务器信息记录到文件中。tracker server和storage server之间相互同步storage server列表:
- 如果一个组内增加了新的storage server或者storage server的状态发生了改变,tracker server都会将storage server列表同步给该组内的所有storage server。以新增storage server为例,因为新加入的storage server主动连接tracker server,tracker server发现有新的storage server加入,就会将该组内所有的storage server返回给新加入的storage server,并重新将该组的storage server列表返回给该组内的其他storage server;
- 如果新增加一台tracker server,storage server连接该tracker server,发现该tracker server返回的本组storage server列表比本机记录的要少,就会将该tracker server上没有的storage server同步给该tracker server。
同一组内的storage server之间是对等的,文件上传、删除等操作可以在任意一台storage server上进行。文件同步只在同组内的storage server之间进行,采用push方式,即源服务器同步给目标服务器。以文件上传为例,假设一个组内有3台storage server A、B和C,文件F上传到服务器B,由B将文件F同步到其余的两台服务器A和C。我们不妨把文件F上传到服务器B的操作为源头操作,在服务器B上的F文件为源头数据;文件F被同步到服务器A和C的操作为备份操作,在A和C上的F文件为备份数据。
同步规则总结如下:
- 只在本组内的storage server之间进行同步;
- 源头数据才需要同步,备份数据不需要再次同步,否则就构成环路了;
- 上述第二条规则有个例外,就是新增加一台storage server时,由已有的一台storage server将已有的所有数据(包括源头数据和备份数据)同步给该新增服务器;
2、storage server状态
FDFS_STORAGE_STATUS_INIT :初始化,尚未得到同步已有数据的源服务器
FDFS_STORAGE_STATUS_WAIT_SYNC :等待同步,已得到同步已有数据的源服务器
FDFS_STORAGE_STATUS_SYNCING :同步中
FDFS_STORAGE_STATUS_DELETED :已删除,该服务器从本组中摘除(注:本状态的功能尚未实现)
FDFS_STORAGE_STATUS_OFFLINE :离线
FDFS_STORAGE_STATUS_ONLINE :在线,尚不能提供服务
FDFS_STORAGE_STATUS_ACTIVE :在线,可以提供服务
2.1 组内新增加一台storage server A时,由系统自动完成已有数据同步,处理逻辑如下:
第一步:
storage server A连接tracker server,tracker server将storage server A的状态设置为FDFS_STORAGE_STATUS_INIT。storage server A询问追加同步的源服务器和追加同步截至时间点,如果该组内只有storage server A或该组内已成功上传的文件数为0,则没有数据需要同步,storage server A就可以提供在线服务,此时tracker将其状态设置为FDFS_STORAGE_STATUS_ONLINE,否则tracker server将其状态设置为FDFS_STORAGE_STATUS_WAIT_SYNC,进入第二步的处理;
第二步:
假设tracker server分配向storage server A同步已有数据的源storage server为B。同组的storage server和tracker server通讯得知新增了storage server A,将启动同步线程,并向tracker server询问向storage server A追加同步的源服务器和截至时间点。storage server B将把截至时间点之前的所有数据同步给storage server A;而其余的storage server从截至时间点之后进行正常同步,只把源头数据同步给storage server A。到了截至时间点之后,storage server B对storage server A的同步将由追加同步切换为正常同步,只同步源头数据;
第三步:
storage server B向storage server A同步完所有数据,暂时没有数据要同步时,storage server B请求tracker server将storage server A的状态设置为FDFS_STORAGE_STATUS_ONLINE;
第四步:
当storage server A向tracker server发起heart beat时,tracker server将其状态更改为FDFS_STORAGE_STATUS_ACTIVE。
3、同步时间管理
从上面了解了fastdfs文件系统中组内的多个storage server之间同步的机制,那文件同步是什么时候进行呢?是文件上传成功后,其它的storage server才开始同步,其它的storage server怎么去感知,tracker server是怎么通知storage server呢?
当一个文件上传成功后,客户端马上发起对该文件下载请求(或删除请求)时,tracker是如何选定一个适用的存储服务器呢?
其实每个存储服务器都需要定时将自身的信息上报给tracker,这些信息就包括了本地同步时间(即,同步到的最新文件的时间戳)。
而tracker根据各个存储服务器的上报情况,就能够知道刚刚上传的文件,在该存储组中是否已完成了同步。在storage server中这些信息是
以Binlog文件的形式存在的。
4、Binlog文件
当Storaged server启动时会创建一个 base_path/data/sync 同步目录,该目录中的文件都是和同组内的其它 Storaged server之间的同步状态文件,如192.168.1.2_23001.mark、 192.168.1.3_23001.mark、 binlog.000、binlog_index.dat;
Binlog文件内容:在该文件中是以binlog日志组成,比如:
1653482441 c M00/00/00/wKgCU2KOI8mAQ45iAAI2W1kwaRk715.jpg
1653482449 C M00/00/00/wKgCU2KOI9GAUF7DAAIFk_wQ4xI485.jpg
1653482449 d M00/00/00/wKgCU2KOI9GAJ6qIAABe0Hy7THE119.jpg
1653495360 D M00/00/00/wKgCU2KOVkCAA7jEAARNo91NgIc894.jpg
其中的每一条记录都是使用空格符分成三个字段,分别为:
第一个字段 表示文件upload时间戳 如:1653482441
第二个字段 表示文件执行操作,值为下面几种:
C表示源创建、c表示副本创建
A表示源追加、a表示副本追加
D表示源删除、d表示副本删除
T表示源Truncate、t表示副本Truncate
其中源表示客户端直接操作的那个Storage即为源,其他的Storage都为副本.
第三个字段 表示文件标识, 如:M00/00/00/wKgCU2KOVkCAA7jEAARNo91NgIc894.jpg
5、Storage Server具体同步过程
Storaged server之间的同步都是由一个独立线程负责的,这个线程中的所有操作都是以同步方式
执行的。比如一组服务器有A、B、C三台机器,那么在每台机器上都有两个线程负责同步,如A机器,线程1负责同步数据到B,线程2负责同步数据到C。每个同步线程负责到一台Storage的同步,以阻塞方式进行。
以IP为192.168.1.1的Storaged severe的服务器为例,它的同步目录下有192.168.1.2_23001.mark、192.168.1.3_23002.mark、binlog.100等文件。
现在192.168.1.1向192.168.1.2同步数据:
- 打开对应92.168.1.2的mark文件(192.168.1.2_23001.mark),从中读取binlog_index、binlog_offset两个字段值,如取到值为:0、1000,那么就打开binlog.000文件,seek到1000这个位置。
- 进入一个while循环,尝试着读取一行,若读取不到则睡眠等待。若读取到一行,并且该行的操作方式为源操作,如C、A、D、T(大写的都是),则将该行指定的操作同步给对方(非源操作不需要同步),同步成功后更新binlog_offset标志,该值会定期写入到192.168.1.2_23001.mark文件之中。
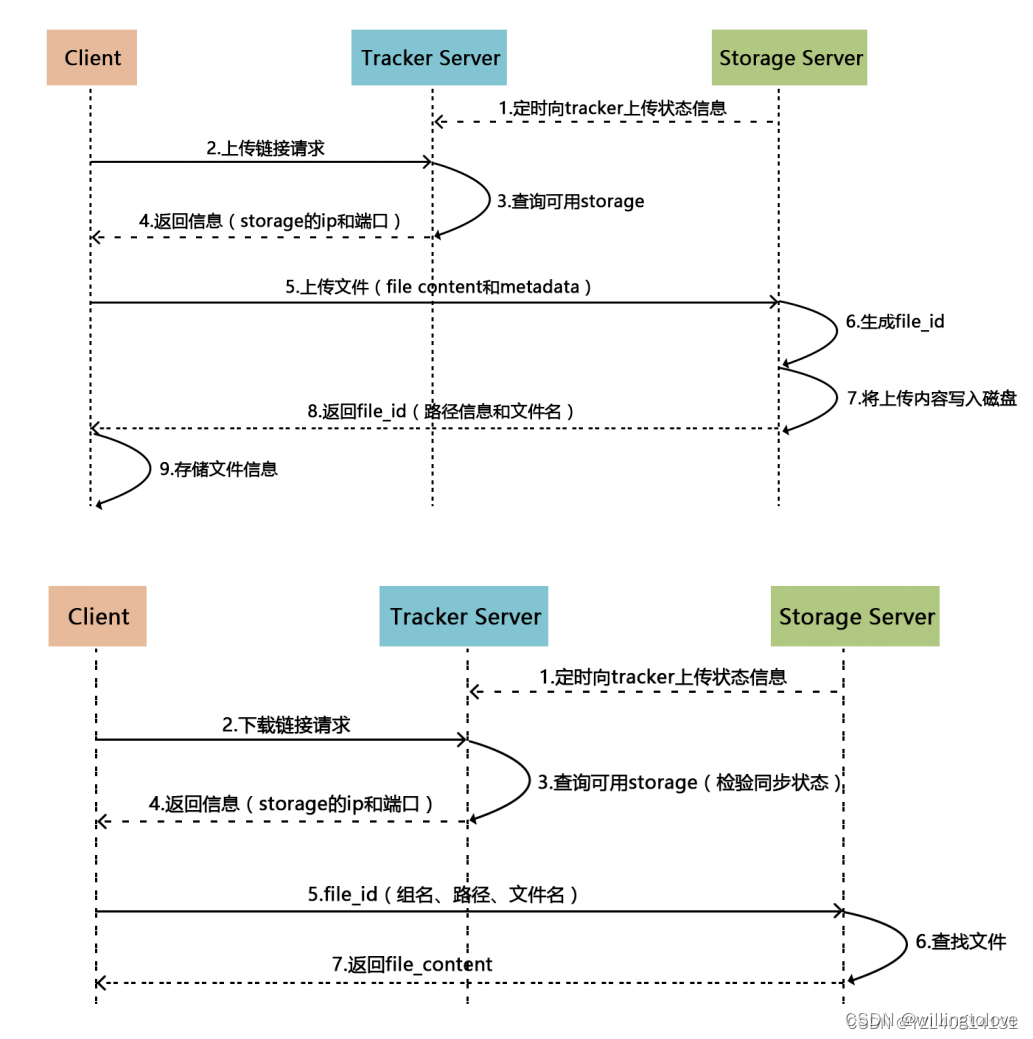
6、上传和下载流程
7、参考
Chinaunix FastDFS讨论区
![[有人@你]请查收你的年终总结报告](https://img-blog.csdnimg.cn/04c0ab15cc474ade804e2a524c4ce92d.png)