一、说明
初学Docker就一个字:乱!这是因为Docker是一个庞大体系,初学时不了解全貌,处于“盲人摸象”状态,因不能通晓要领,学了一点,过后就忘了。而了解Docker全貌并非易事,官方文档也比较乱,找不到初学的切入点。本文试图回顾(或叫反思)Docker这种技术,从宏观上俯视Docker,期望对初学者起到“导游”的意义。然而“说一漏万”,存在诸多说不太透的地方,不期望大家谅解,而是期望初学者们诚心诚意地付出时间和努力,勤学勤练,最后彻底掌握。
二、Docker的目的
为什么要有Docker,不学Docker能死吗?
要回答此类问题,首先应从Docker产生的时代背景,以及它对开发的影响说起,结论读者自己总结。
2.1 时势造Docker
Docker没有出现之前,开发领域教科书是《软件工程》所提出的:结构化、模块化、对象化。然而,随着互联网的成果推进,出现如下事实:1 要求跨平台 2 模块体系越来越大 3 交叉技术模块相互整合不易 4 软件集成有困难。
出现以上现象的原因,一方面因为网上功能爆炸式增长,云计算、大数据、人工智能的出现,使得开发不再是单一的,因而掌握复杂的开发和部署需要“全才”,而“全才”非常稀缺。因此,不跳出传统框架,已经无能为力。而Docker就是另辟新途径的划时代新发明。
2.2 Docker的概念源头
Docker的出现,不是突发的。而是通过已经存在的技术,逐步“催化”产生,它继承了现有诸多的软件成果,具体内容如下。
2.2.1 对于跨平台的构思
Docker以虚拟机的概念为基础的,每个独立最小单元称之为容器,容器内部包含一个独立小型Linix操作系统(这里注意Docker是基于Linux的,不是windows、也不是iso)。
2.2.2 对于docker模块之间的信息交换
是基于网络的(注意不是进程间通信,而是网络主机与主机的通信,即便在一台电脑上也是这样).
2.2.3 人机交互
CS结构,这一点类似于mysql数据库,有一个client、有一个server,docker体系中存在这样的关系。
2.2.4 云服务端
docker不是孤立的本地小系统、而是社会化的大系统,对于镜像的管理是在云端实现,这和github类似,具有一定的开源共享性。
2.3 Docker对开发的影响
对于项目开发,团队的专业分工依然存在,Docker无法避免,但是,Docker可以使得庞大松散的产品从一个环竟迁移到另一个环境变得容易。
传统Linix开发存在问题是经常性的安装版本,使用docker后,通过社会化共享,使得网上拉取镜像代替了安装,不仅节约了时间,而且结构上更加可靠。
大的复杂系统,传统上是把小系统通过集成构造出大系统,而有了Docker概念,可以以Docker为颗粒,设计大系统,免除了集成的麻烦。
开发团队与运维团队存在沟通不力的问题,传统开发是开发人员“进驻”运维团队,有了Docker使得运维更加方便,“进驻”的力度大大降低。
三、docker一般概念
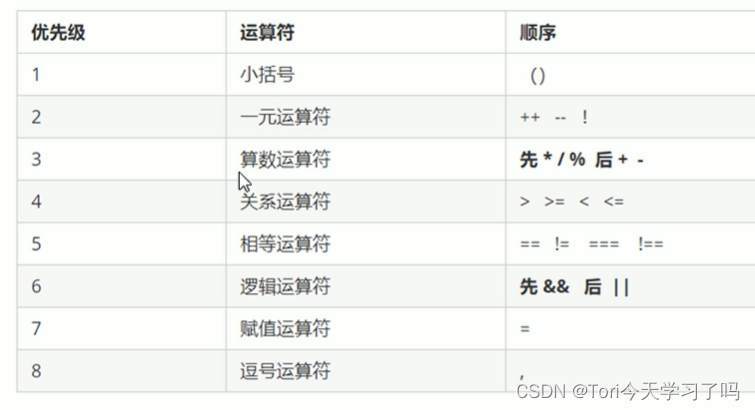
3.1 知识点
- docker体系结构:Docker内部运作机理是啥?
- 开发者活动:开发者如何参与Docker活动?
- 更加宏观地看待Docker整体活动:开发者如何应用docker的便利,去开发项目?
- docker存储和复用:docker的社会管理,hub和阿里云等
- 文件复用:Docker如何搬家?备份和存储?
3.2 docker体系结构:Docker内部运作机理是啥?
因为初学者接触Docker,不能回避安装这个过程。我们这里就从Docker的安装语句上说起,让大家立刻进入某种思考状态。
安装语句:
$ sudo yum install docker-ce docker-ce-cli containerd.io docker-compose-plugin
以上安装语句直观地告诉我们,Docker有很多部件构成,他们是:
- docker-ce 引擎
- docker-ce-cli 客户端
- containerd.io 输入输出接口
- docker-compose-plugin 组成插件
一个docker体系,在安装完成后,将有如下图所示的结构:
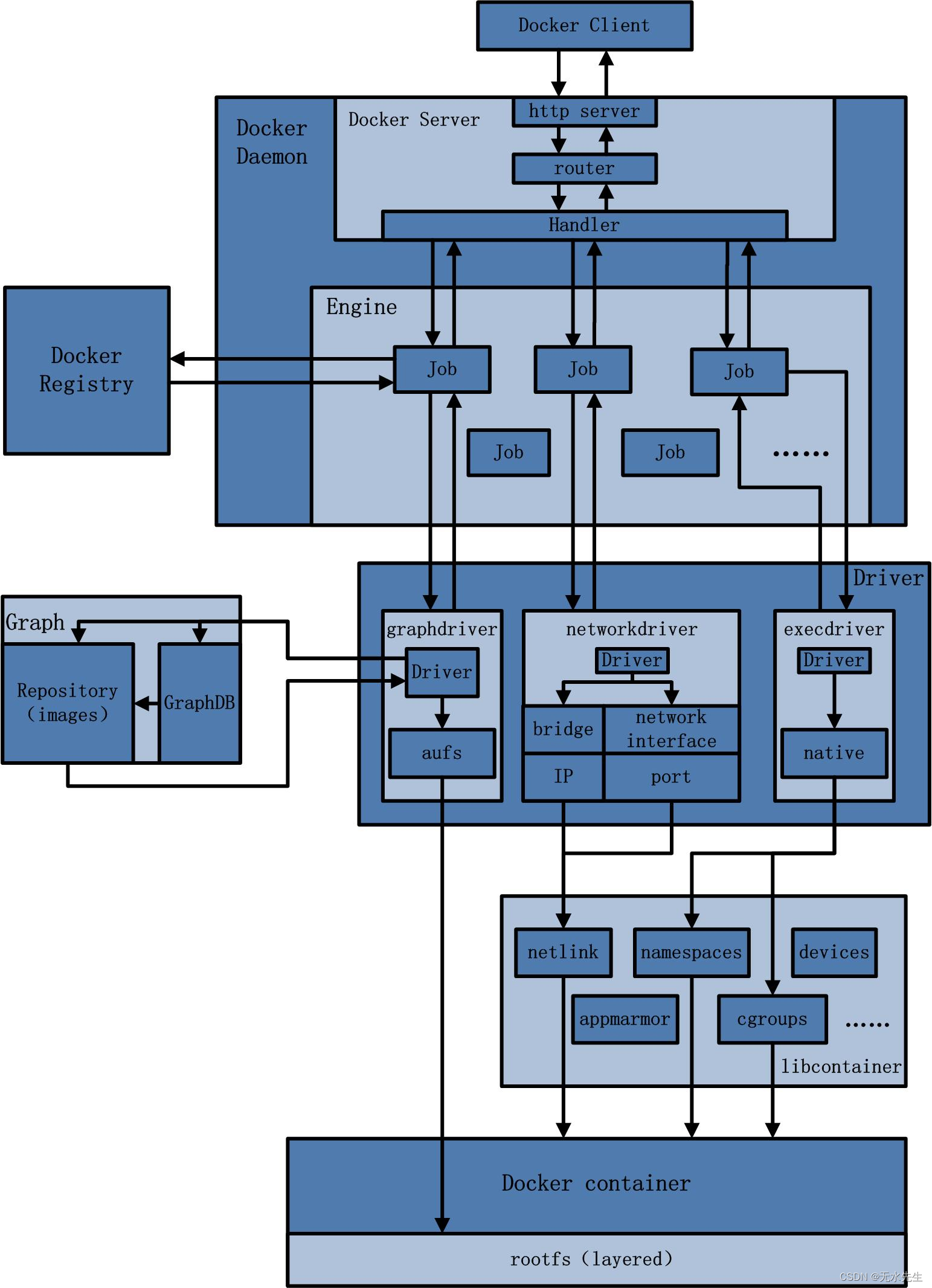
对上图的解释:
1 CS结构实现指令输入输出
这是实现人机交互的部分,也是CS构架,其中包括:
- Docker Client客户端终端
- Docker Server伺服务器
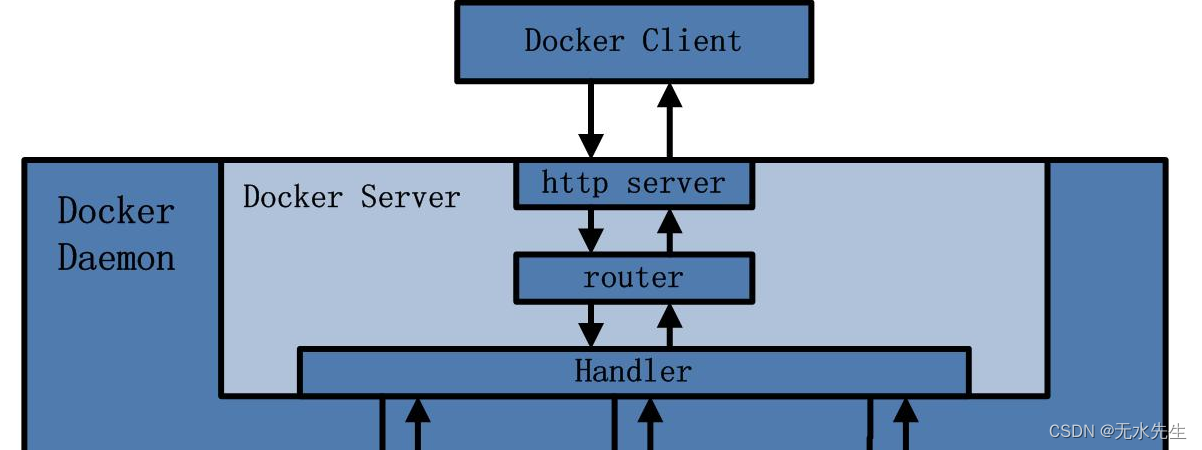
2 Engine引擎部分
这部分有两部分功能
- 指令解析成job
- 分配job任务
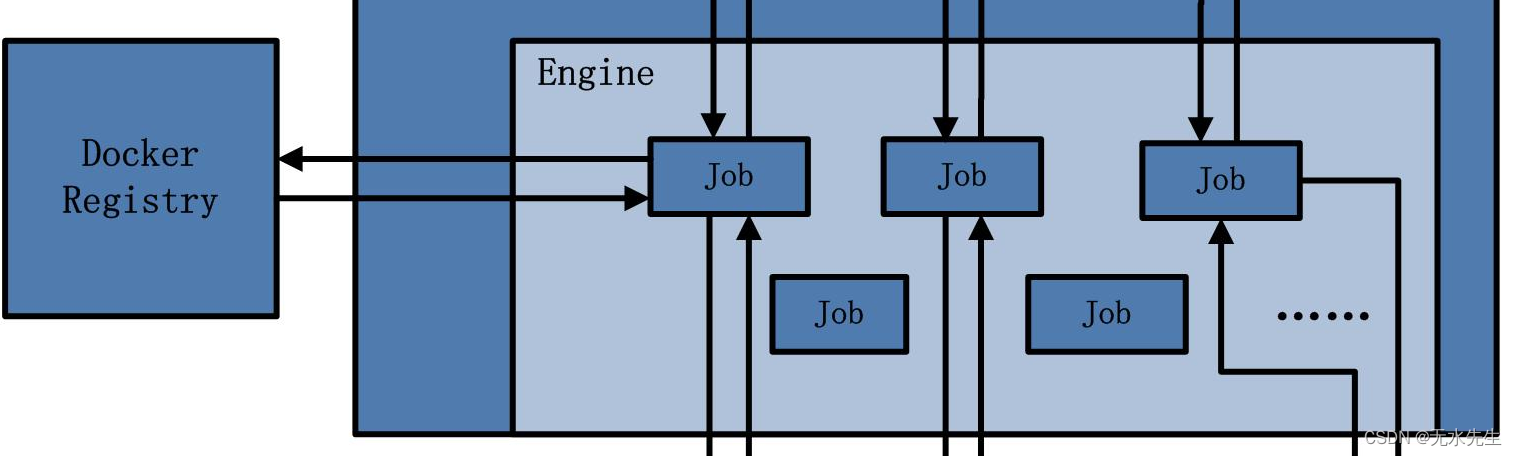
示例指令1:
Docker pull Ubuntu其中 “pull”就是一个job,其中功能, 1)如果本地有个ubuntu Image,那么提示存在 ,否则 2)从网上下载一个存在本地。因此有如下过程:

其中(4)是从本地Image仓库查找,如果有,就拉取之并存在当前环境中。如果本地仓库无,转入(7)步,即从网上云端拉取。
示例指令2:
docker create --name myrunoob nginx:latest 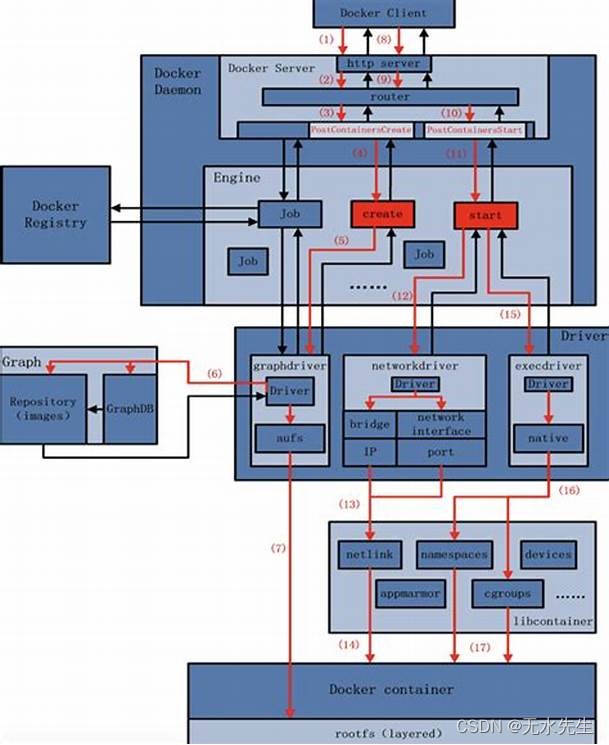
流程分解:
1)分析指令后,分解出Create指令
2)如果当前环境有Ngix镜像,就沿着(5)执行构建一个Container。
3)如果当前环境没有Ngix镜像,(6)从云仓库拉取ngix镜像,沿着(5)执行构建一个Container。
示例指令3:
启动一个容器,通过IO口,将本地容器启动起来。可以看出,容器已经ready,通过程序的driver库将容器进程启动起来。(注意:容器不是宿主机进程,无法在宿主机启动,必须通过Docker引擎干预)。
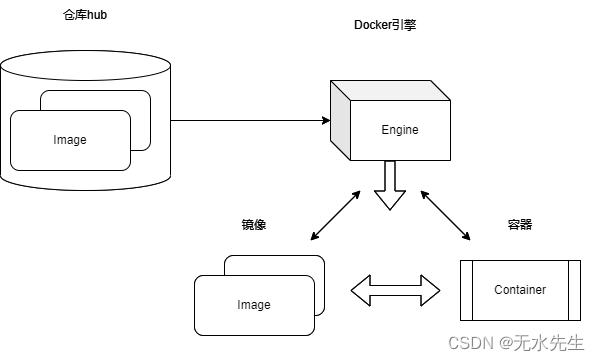
3.3 Docker的四个基本概念
Docker存在是个重要概念: 镜像、容器、引擎、仓库;这里不讲它们之间的关系,但是务必搞清这四个概念。
3.4 Docker和虚拟机的区别
docker和虚拟机存在重要区别,主要表现两个方面
1)从体量上比较
- 虚拟机内存在完整的,尽善尽美的操作系统,因此十分庞大,一般几个G的存储量,安装时间有几十分钟。
- docker是简体版操作系统,是将操作系统裁剪到刚好支持内部程序,十分小,一般有几十个M的存储量。
2)从设计思路上
- 虚拟机是在做“加法”的,该有的尽有。
- docker是做减法的,能不要的就尽量不要。
3.5 容器和进程的区别
容器和进程有类似,但也有区别,分别如下:
1)集成的观点看两者有共同性
- 进程与进程可以构成更大的系统,但是这种集成规模不能过大,比如上万个进程可能就存在无法管理的问题。
- Docker的多个容器合成更大系统和多进程系统有类似之处,但是每个容器中可以包含一个系统,比如Ubuntu容器,内涵整个操作系统。tomcat容器,内部包含整个tomcat的功能,这种大规模的集成是多进程系统所无法完成的。
2)从功能上看
- 从功能上看,进程与进程构成的系统功能比较单一、不够强大。
- docker的容器之间集成的系统规模庞大,功能更强大,因为每个容器内部嵌入一个简版操作系统,可以将网络功能、服务器、数据库、互联网、大数据、人工智能等各种大系统集成起来,因而功能之强大是前所未有的。
四、docker集群的观念
4.1. 理解集群(swarm)
swarm是一组运行着Docker的机器,它们一起加入到一个集群。swarm中的机器既可以是物理机,也可以是虚拟机。
在加入到一个swarm后,每台机器被称为一个节点。以前,我们执行docker命令由对应的机器去执行,而现在多台机器组成swarm后,Docker命令由swarm manager去执行,swarm manager也管理Node内容器得增添、删除等。
能够集群得工具很多,这里介绍两个:docker swarm和kubernetes。
4.2 docker swarm 集群工具
Docker Swarm是针对 Docker 容器技术创建的集群工具。最关键的是 Dcoker Swarm 对外提供的是完全标准的 Docker API,因此任何使用 Docker API 与 Docker 进行通讯的工具(Docker ClI, Docker Compose, Dokku, Krane)都可以完全无缝地和 Docker Swarm协同工作。这一点对 Docker Swarm 来说既是一个优点,也是一个缺点。
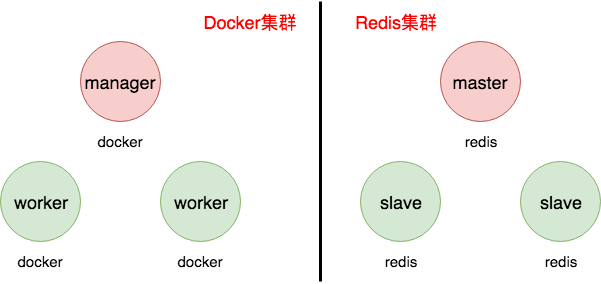
- swarm就是集群,是Docker集群,它是一组运行着Docker的机器组成的
- 组成Docker集群以后,集群中的每台机器被称之为一个node,其中有一台机器是这个集群的管理者,称之为manager,其余的称之为worker
- 在集群中,你的命令都是由manager去执行的,这与你当前在那台机器上输入的命令无关
- 与集群模式相对的是单机模式,之前我们一直是以单机模式使用Docker的
- 类比Redis机器的话,manager就相当于master,worker相当于slave
4.3 kubernetes容器集群管理系统
k8s是一个开源的容器集群管理系统,可以实现容器集群的自动化部署、自动扩缩容、维护等功能。而Docker是一个开源的应用容器引擎,是一种容器化技术。
docker是容器层面的,kubernetes是容器编排和组织管理层面的。
Kubernetes 是基于 google 自身多年使用 linux 容器的经验创建出来的,所以可以说它是 Google自身多年操作经验的一个复制,只是 google 把这些操作经验应用到了 Docker 上。 使用Kubernetes 来管理容器在多个方面都将带来很大的好处,而其中最重要的就是 Google 把他们多年使用容器的经验带入了这个工具。如果你是从 Docker1.0 (或者更早之前的版本)开始使用Kubernetes,你会发现使用 Kubernetes 来管理 docker 容器是非常愉悦的体验。
值得注意的是,K8S虽然支持Docker,但不是为Docker量身定做的,而是支持所有的其它容器的集群。
五、小结
本篇叙述Docker概要,动笔较为仓促,但作为一种框架先推放出去,后期我将在本文基础上,逐步改进其粗糙面,添加更多细节,使叙述更完善,内容更充实、更具备可阅读性。