在该章节中更多是体验与尝试
一、理论学习
类型:语言大模型和多模态大模型这两种是主要的类型。
挑战:要想办法建立一个全面的评价体系,还要能处理大规模的数据,并且要保证评测的准确性和可重复性,真不是一件容易的事。
评测类型:客观评测和主观评测是主要的两种方式。
二、提示词工程
作用:提示词真的能起到很大作用,能让大模型的性能和准确性提高不少。
示例:有指令、问题,还有指令加上问题一起的那种。
三、opencompass
opencompass 的功能:能对模型进行评估,还能进行数据分析和可视化,功能挺多的。
能力维度:通用能力和特色能力这些方面。
评测流水线:从数据准备开始,然后进行模型评估,接着分析结果,最后还要可视化,这一系列步骤都不能少。
四、代码实战
资源准备:得先把数据集、模型和工具都下载好,这是基础。
启动评测:可以用命令行参数或者配置文件来启动评测,要选适合的方式。
自定义客观数据集:创建的步骤包括准备数据集文件、配置文件,还要有代码示例来参考。
五、总结
通过学习大模型评测的相关知识和使用 opencompass 工具进行代码实战,我对大模型评测有了更深入的了解。

借鉴思维导图
作业:
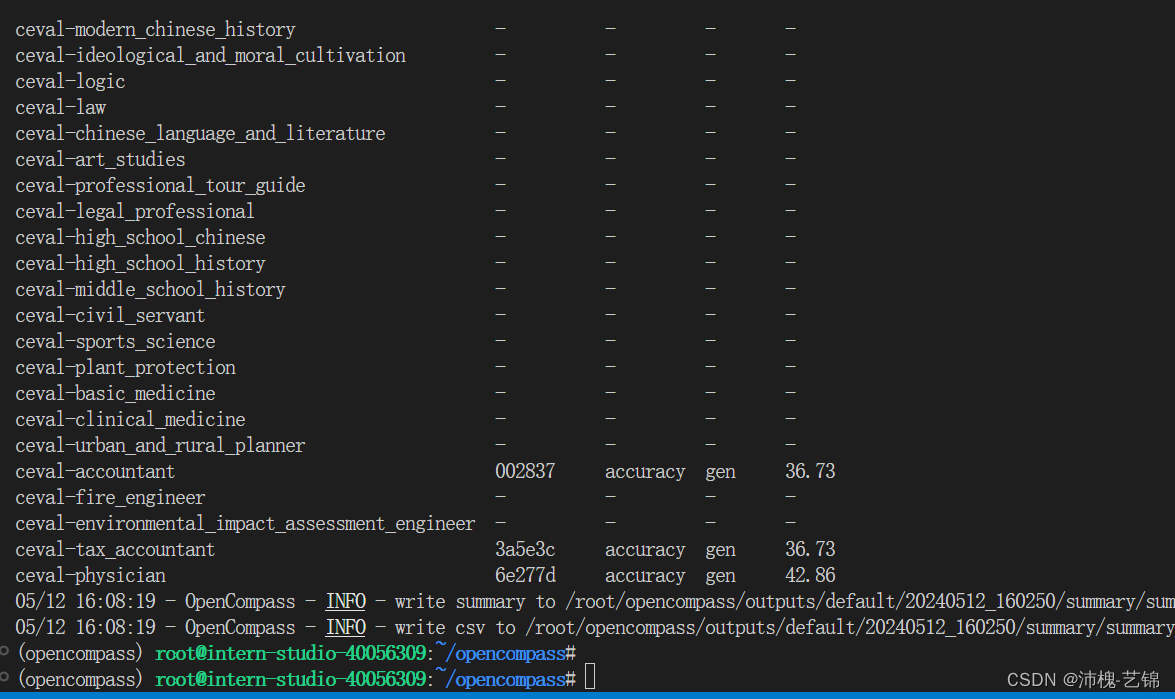
完整使用以下代码,即可完成作业测评,
cd ~
studio-conda -o internlm-base -t opencompass
source activate opencompass
git clone -b 0.2.4 https://github.com/open-compass/opencompass
cd opencompass
pip install -r requirements.txt #一定要先安装所有依赖库,再安装e.
pip install -e .
pip install protobuf
export MKL_SERVICE_FORCE_INTEL=1
cp /share/temp/datasets/OpenCompassData-core-20231110.zip /root/opencompass/
unzip OpenCompassData-core-20231110.zip
python run.py --datasets ceval_gen --hf-path /share/new_models/Shanghai_AI_Laboratory/internlm2-chat-1_8b --tokenizer-path /share/new_models/Shanghai_AI_Laboratory/internlm2-chat-1_8b --tokenizer-kwargs padding_side='left' truncation='left' trust_remote_code=True --model-kwargs trust_remote_code=True device_map='auto' --max-seq-len 2048 --max-out-len 16 --batch-size 4 --num-gpus 1 --debug






![[嵌入式系统-75]:RT-Thread-快速上手:正点原子探索者 STM32F407示例](https://img-blog.csdnimg.cn/img_convert/26603420183b22ef3cc660398726387e.gif)