本文背景
应一个用户的好心和好奇心,在最近水深火热的百忙之中抽时间写完了一个简短的项目介绍,其实就是几个azkaban的批量操作脚本,但在大数据集群的“运维生涯”中,还是帮了自己不少忙,也算是为了它做一个简单的回顾吧
项目背景
azkaban 是一个大数据领域通用的任务管理服务,它的运行模式和其他任务管理服务类似,都是将任务下发到执行器,定期执行,它的优势主要在于可定义任务流,同个项目下不同任务可引用同个模板,大数据领域的任务正好比较具有复用性,因此在 azkaban 诞生的时代(第一个release在2014年),它还是成为了当时比较流行的开源任务调度服务
azkaban 的操作方式比较容易上手,通过界面即可完成所有的操作,包括上传项目、执行项目中定义的job、查看job日志、给任务配置调度时间等,操作并不复杂。但如果需要批量做一些操作,在界面一个个点就不太方便了
之前没有做这个项目的时候,隔三差五用户就要来找我“能不能帮忙…”(具体对话参考下面),终于有一天没忍住,本项目就此诞生…
项目主要是参考了 azkaban api 文档,通过若干脚本实现了一些常见的批量操作,项目地址: azkaban-tools
目前实现的批量操作场景如下:
批量操作① 启动任务
每年都会有个一两次的真实对话
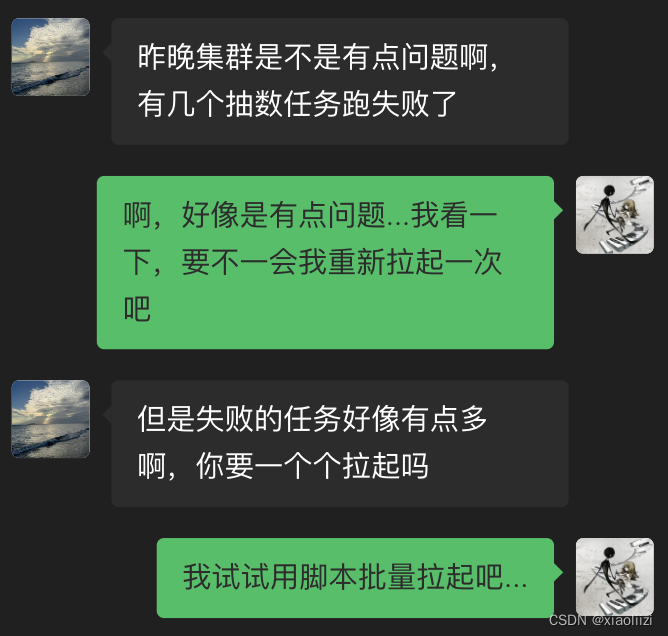
批量操作② 启动任务
azkaban 默认不允许同时执行同一个任务,因此如果任务在上个周期执行一直没结束,到下个周期也不会被触发
于是偶尔也会有以下的对话
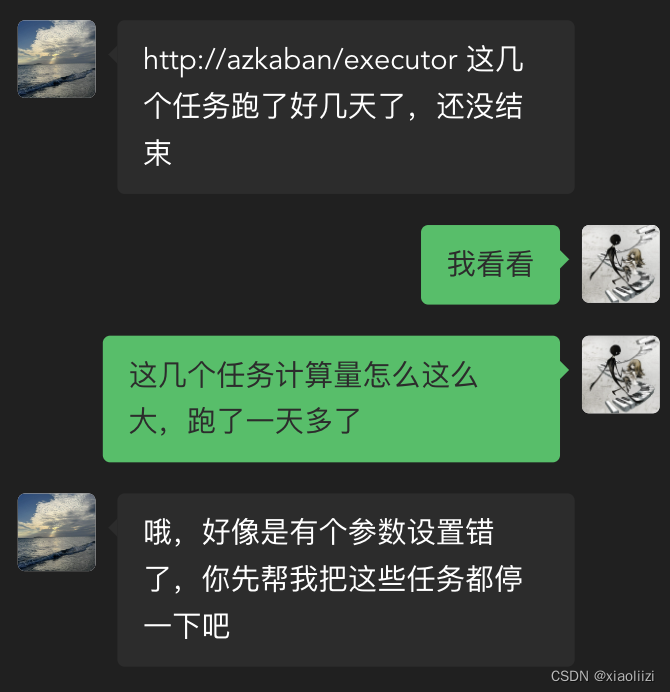
批量操作③ 设置调度
对离线抽数任务来说,一般都会在每天一个固定的时间调度一次,抽数完后执行上层的任务,一般就是这种场景

批量操作④ 设置调度
背景同上,调度周期如果要修改,比如从早上8点改成9点,需要先把原来的调度删除后再创建新的调度
如何使用
本地部署 azkaban
azkaban 提供两种部署模式: solo (单节点)和 webserver+executor集群模式,生产环境肯定是采用后者,本地测试可以通过 solo 模式快速部署
# 第三方镜像
docker run -d -p 8081:8081 --name azkaban-srv -e TZ='Asia/Shanghai' haxqer/azkaban
# 下载代码
git clone https://github.com/azkaban/azkaban
# 注意: 官方仓库久未维护,编译会有报错,也可以拉取笔者 fork 后修复的仓库
git clone https://github.com/smiecj/azkaban -b b_3_90_extend
# 编译
./gradlew build installDist
# 本地solo模式启动
cd azkaban-solo-server/build/install/azkaban-solo-server
./bin/start-solo.sh
访问刚启动的 solo 服务器: http://localhost:8081 ,默认用户名密码都是 azkaban
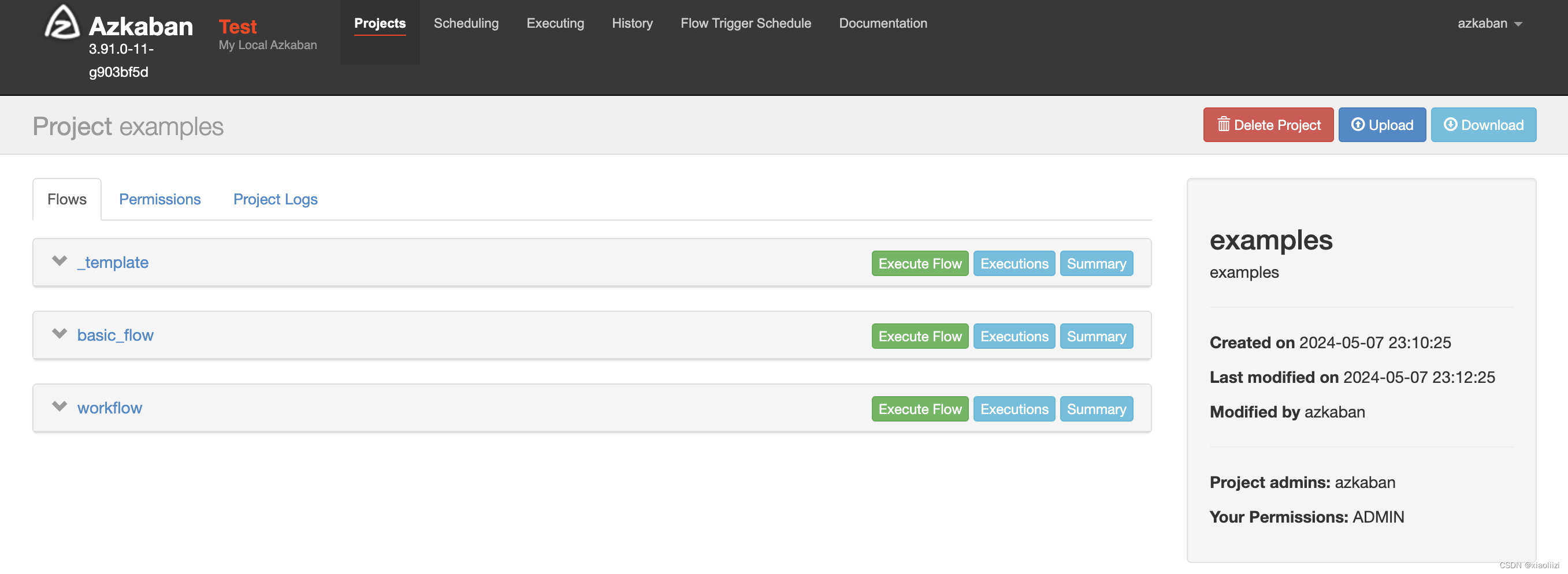
上传项目
这里我们创建一个示例项目 examples, 并以 azkaban_examples 作为项目代码,压缩成zip包后上传
git clone https://github.com/joeharris76/azkaban_examples
zip -r azkaban_examples.zip azkaban_examples
azkaban 项目下的任务结构一般是 flow->job->template,flow 是父任务,job 为子任务。flow 可以通过串行或并行定义一组job的关系,job 可以直接定义任务行为,也可以引用template,在template中定义具体行为
以笔者实际维护的离线抽数作为例子,就是一个比较标准的azkaban任务格式:
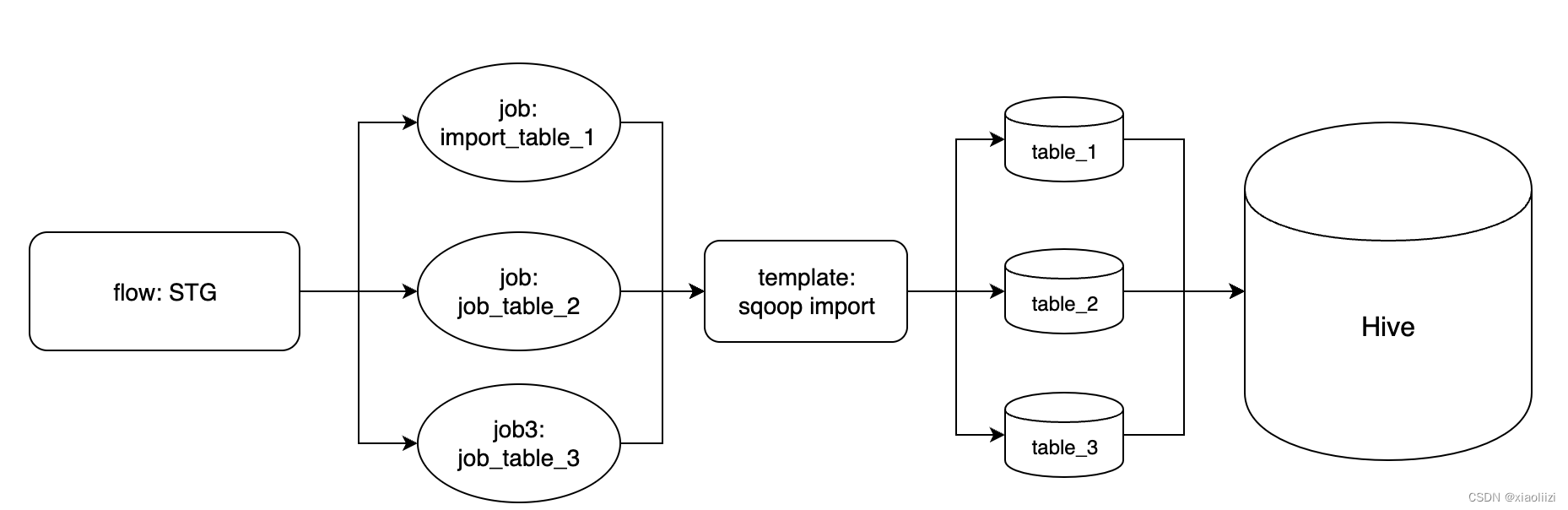
所有抽数任务都在每天早上7点执行,每个抽数任务都对应一张mysql表,具体指令都是通过sqoop指令将数据从mysql导入hive表,区别只是执行sqoop的参数(即库表名)。这种任务我们就可以在 template 中编写sqoop的执行逻辑,每个表的同步任务作为一个job,都引用 template ,在job配置中定义表明即可
具体的任务定义示例:
# template/sqoop.job
command=sqoop import -Dmapreduce.job.user.classpath.first=true --connect jdbc:mysql://mysql_host:mysql_port/${mysql_db} --username mysql_user --password mysql_pwd --table ${mysql_table} -m 1 --target-dir /import/stg/${mysql_table} --as-avrodatafile
# stg/table1.job
mysql_db=element
mysql_table=orders
command=echo "import mysql table"
type=flow
flow.name=sqoop
examples 项目结构也比较简单,basic_flow 和 workflow 是最上层的 flow,basic_flow 引用的8个job直接定义了执行echo的行为;workflow引用的4个job则都属于同一个template,同样都是echo操作,只是最后打印的内容不同
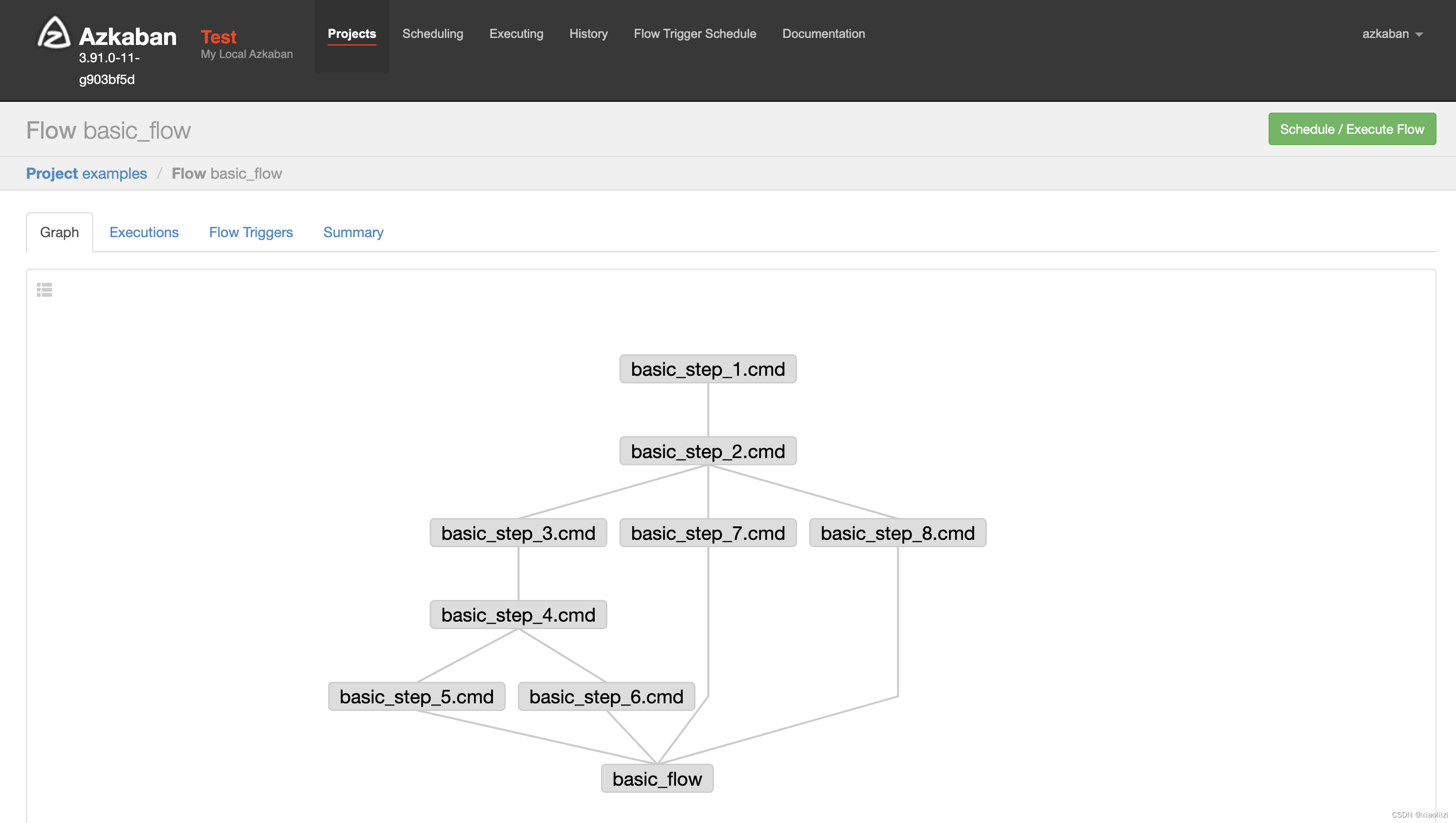
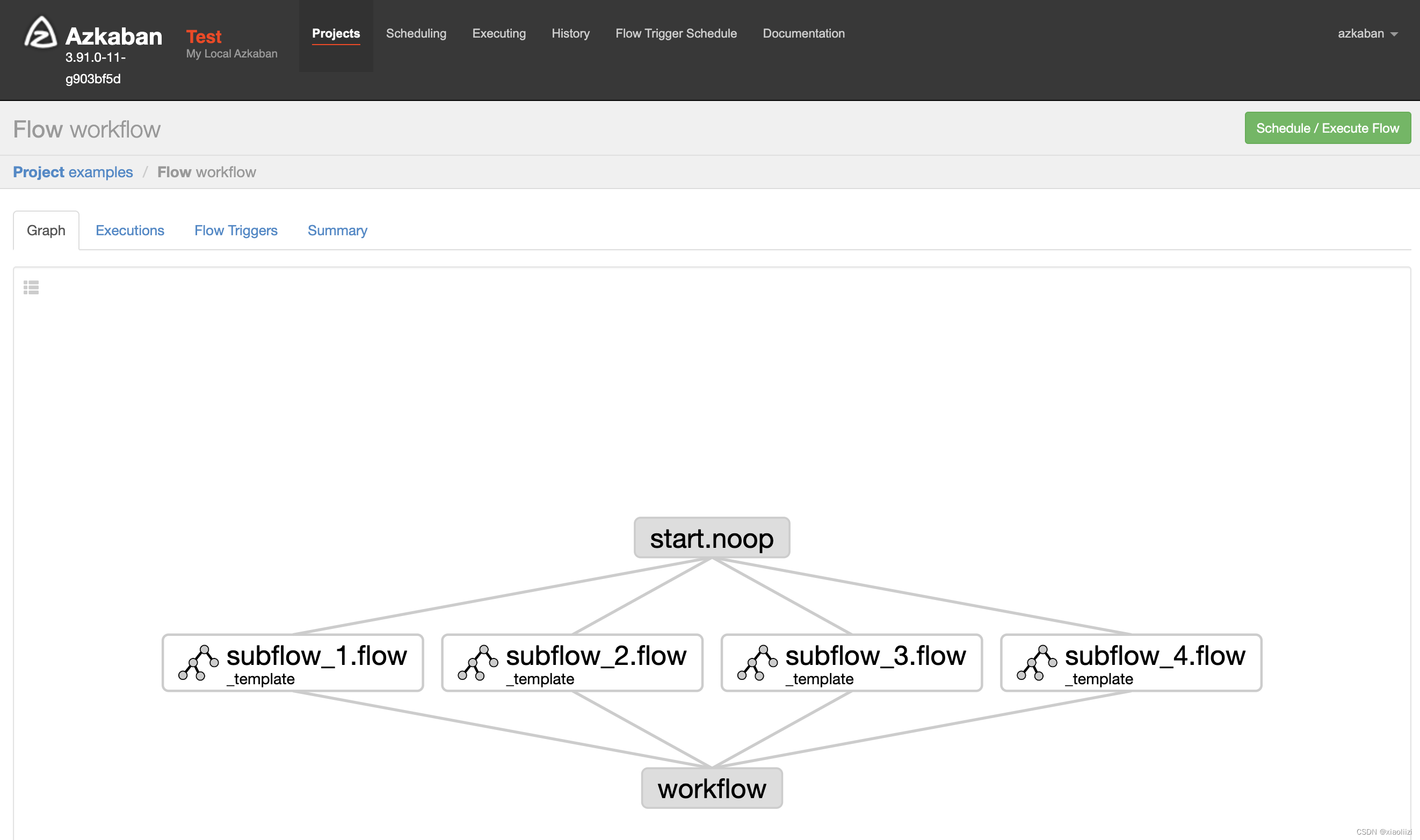
手动执行两个flow,可以看到它们的执行速度都非常快,因为到最后的子任务都只是执行 echo
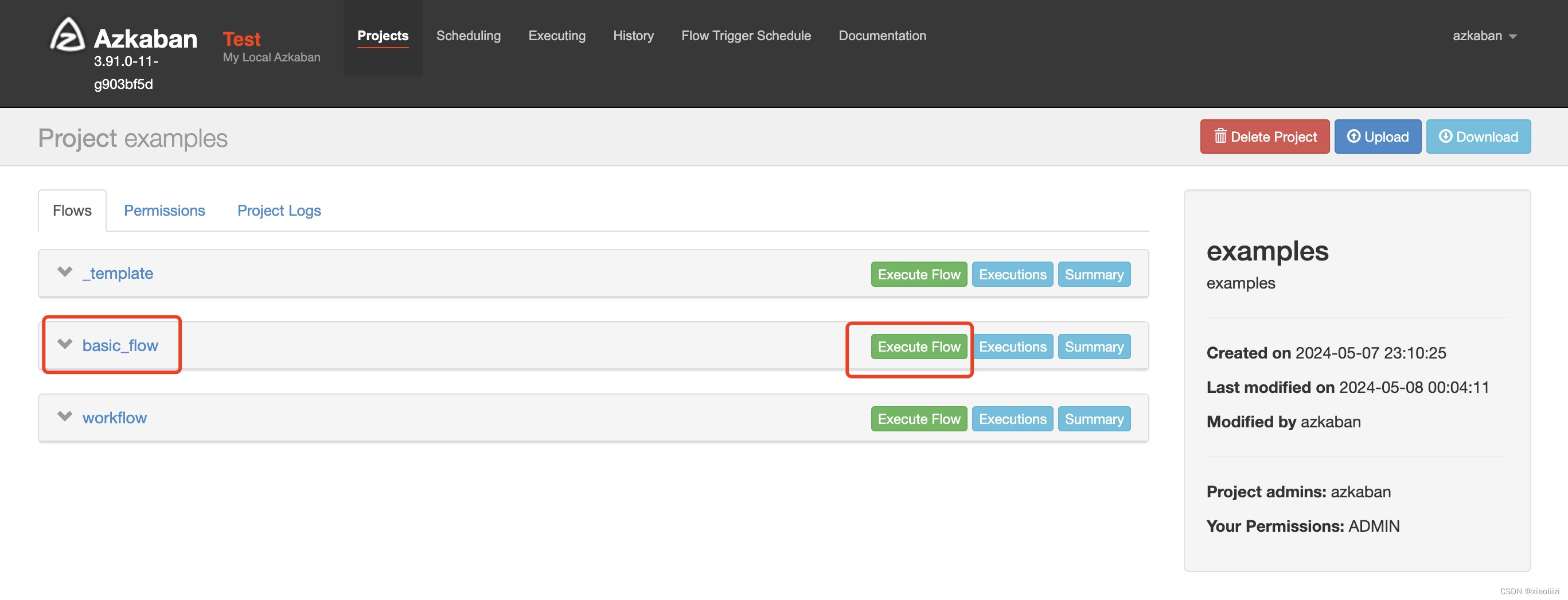
为了方便接下来的测试,我们可以给basic_flow下的job添加sleep以增加执行时间
# 每个job增加睡眠时间,序号越大睡眠时间越长
for i in {1..8}
do
echo "command.1=sleep ${i}" >> basic_flow/basic_step_${i}.cmd.job
done
登录配置
在正式使用 azkaban-tools 之前,我们需要先修改 env.sh 中和服务相关的配置
# search_env_name: 查询操作的环境
search_env_name=produce
# exec_env_name: 执行、修改等操作的环境
# 注: 一开始开发这个项目是为了将一个老集群部署的azkaban上的所有任务调度都迁移到新集群服务上。为防止误操作生产环境,区分了进行查询和执行操作时使用不同的环境
exec_env_name=test
## produce env 连接信息
produce_azkaban_address=localhost:8081
produce_azkaban_user=azkaban
produce_azkaban_password=azkaban
## test env 连接信息
## 这里故意将测试环境地址配置成和生产环境不同(虽然都是本地地址),是为了接下来测试批量停止任务时,不会因为脚本中判断“执行环境地址和生产环境地址完全一致”而停止执行
test_azkaban_address=127.0.0.1:8081
test_azkaban_user=azkaban
test_azkaban_password=azkaban
jq 工具
项目通过 jq 工具来解析 azkaban 接口返回的json数据
jq 可以通过 yum/apt 安装,或者直接下载可执行文件
wget https://github.com/stedolan/jq/releases/download/jq-1.6/jq-linux64
mv jq-linux64 /usr/local/bin/jq
chmod +x jq
jq 作为命令行工具,解析json还是非常好用的,常用指令可以参考后面的章节
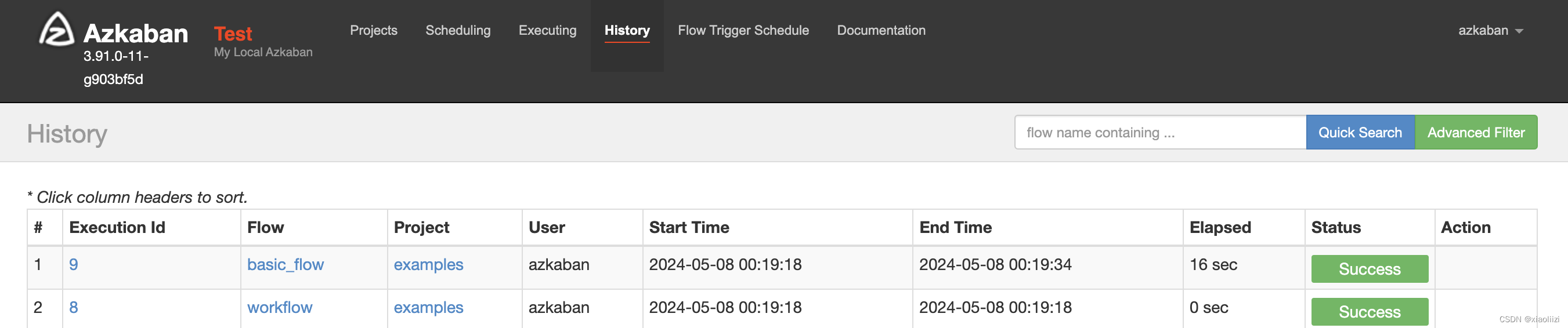
批量启动任务
如果需要把examples的两个flow都调度起来,可以这么配置:
# 需要执行的项目名
execute_project_name="examples"
# 禁止执行的任务名
execute_block_flow_names="(^_template$)"
# 允许执行的任务名
execute_allow_flow_names=""
配置完成后直接执行 make run,即可同时拉起两个任务
批量停止任务
配置和启动任务一样,执行 make kill,即可把项目下所有执行中的任务停止
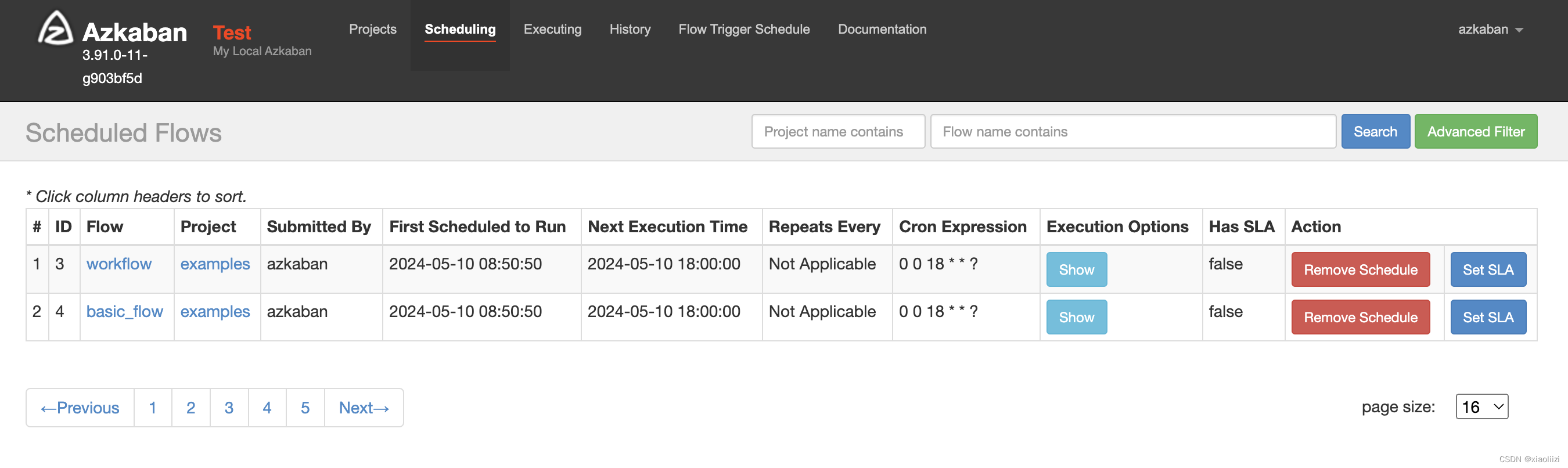
批量创建调度
# 操作项目名
target_project_name="examples"
# 需要设置调度的白名单,不配置默认会设置项目下的所有任务
flow_name_allowlist="(^workflow$|^basic_flow$)"
# 设置的调度周期,java cron 格式
fix_schedule_cron="0 0 18 * * ?"
注: 已经配有调度的任务不会覆盖
批量删除调度
配置和创建调度相同,执行 make clean_cron即可删除任务调度
部分脚本逻辑
登录
# 登录方法需要返回azkaban地址和登录成功得到的session id 两个信息
login() {
local env_name=$1
eval $(get_azkaban_env_info_by_envname $env_name)
local login_ret=`curl -X POST --data "action=$command_login&username=$tmp_azkaban_user&password=$tmp_azkaban_password" http://$tmp_azkaban_address 2>/dev/null`
local tmp_session_id=`echo "$login_ret" | jq '.["session.id"] // empty' | tr -d '"'`
echo "tmp_azkaban_address=$tmp_azkaban_address"
echo "tmp_session_id=$tmp_session_id"
}
# eval $(login $exec_env_name)
# session_id=$tmp_session_id
# azkaban_address=$tmp_azkaban_address
shell脚本中返回多个值的方法参考,eval: 将传入的字符串当成指令执行
获取任务下的所有 flow
get_project_flow() {
local project_name=$1
local session_id=$2
local azkaban_address=$3
local get_project_ret=`curl "http://$azkaban_address/manager?ajax=$command_get_project_flows&project=$project_name&session.id=$session_id" 2>/dev/null`
local tmp_project_id=`echo "$get_project_ret" | jq '.projectId // empty'`
local tmp_flow_count=`echo "$get_project_ret" | jq '.flows | length'`
local tmp_flow_name=`echo "$get_project_ret" | sed "s/ //g" | jq -r '[.flows[].flowId] | join(",")'`
echo "project_id=$tmp_project_id"
echo "flow_name_join_str=$tmp_flow_name"
echo "flow_count=$tmp_flow_count"
}
jq 基本用法
参考了这篇文档和官方文档
# 获取某个key-value
echo '{"hello": "world"}' | jq '.hello' # world
# 获取数组
echo '{"arr": [1,2,3]}' | jq '.arr' # [1,2,3]
# 数组所有元素用逗号组合
# 注意: 如果数组元素类型是数字,还要先通过tostring转成字符串
# -r: 直接打印,不再组装成json
echo '{"arr": [1,2,3]}' | jq -r '[.arr[] | tostring] | join(",")' # 1,2,3
# 判断
echo '{"hello": "world"}' | jq 'has("world")' # false
# 选择器
echo '{"arr": [1,2,3,4,5]}' | jq -r '[.arr[] | select(.>2) | tostring] | join(",")' # 3,4,5
# 选择器和映射
echo '{"arr": [1,2,3,4,5]}' | jq -r '.arr | map(select(.>2))' # [3,4,5]
# 排序
echo '{"arr": [5,4,3,2,1]}' | jq -r '.arr | sort' # [1,2,3,4,5]




![[嵌入式系统-75]:RT-Thread-快速上手:正点原子探索者 STM32F407示例](https://img-blog.csdnimg.cn/img_convert/26603420183b22ef3cc660398726387e.gif)