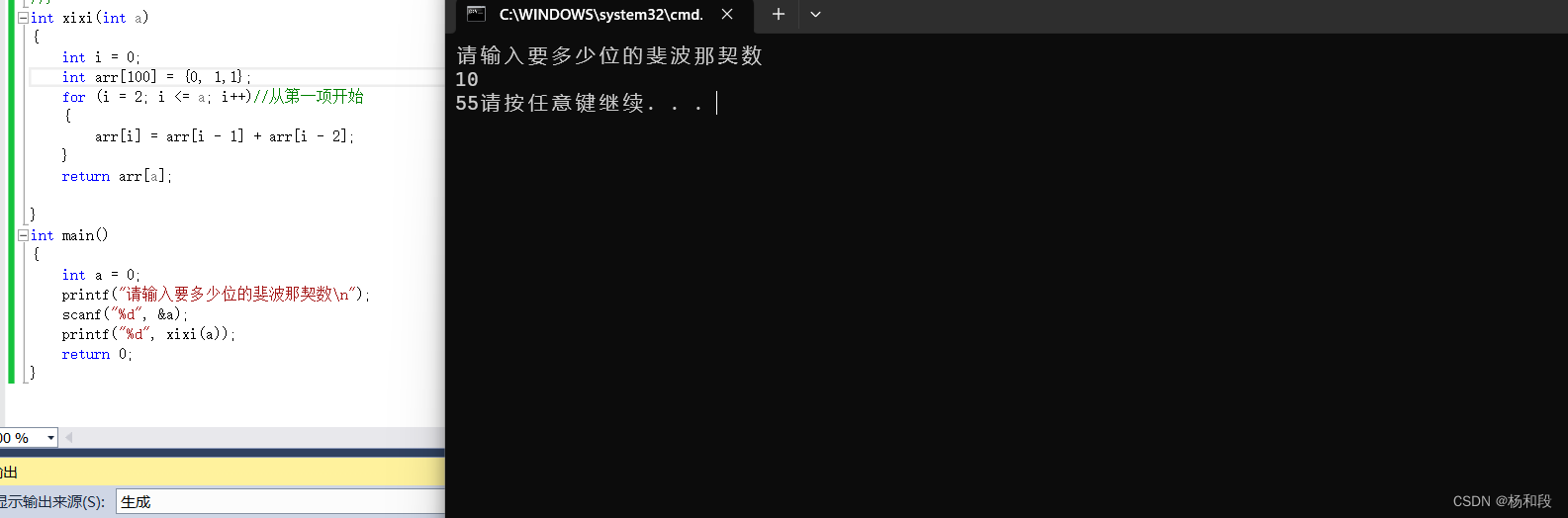
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档
文章目录
- 摘要
- Abstract
- 文献阅读:用于视频识别的快慢网络
- 1、文献摘要
- 2、提出方法
- 2.1、SlowFast模型
- 2.2、SlowFast 提出思想
- 3、相关方法
- 3.1、时空间卷积
- 3.2、基于光流的视频识别
- 3.3、横向连接(Lateral connections)
- 4、实验工作
- 4.1、动作分类实验
- 4.2、消融实验
- 5、总结
- YOLO V5 -- 架构学习
- Backbone -- CSPDarknet
- Backbone CSPDarknet 代码实现
- FPN 代码实现
- 总结
摘要
本周主要阅读了CVPR文章, SlowFast Networks for Video Recognition。SlowFast模型网络是一种用于视频识别任务的深度学习模型。它的核心思想是将两种不同帧率的路径(慢途径和快途径)结合在一起,以便更好地捕捉视频中的时空特征。一个慢途径和一个快途径。慢途径以较低的帧率运行,负责处理低帧率下的信息,这意味着它具有较低的时间分辨率;而快途径以较高的帧率运行,负责处理高帧率下的信息,具有较高的时间分辨率。除了阅读文献之外,还学习了yoloV5框架的代码知识。
Abstract
This week, the main focus was on reading the CVPR paper, “SlowFast Networks for Video Recognition.” The SlowFast model network is a deep learning model designed for video recognition tasks. Its core concept involves integrating two pathways with different frame rates—the slow pathway and the fast pathway—to better capture the spatiotemporal features within videos. There is a slow pathway and a fast pathway. The slow pathway operates at a lower frame rate, processing information at a reduced frame rate, which means it has lower temporal resolution; whereas the fast pathway runs at a higher frame rate, handling information at an increased frame rate, thus possessing higher temporal resolution. In addition to studying the literature, knowledge of the code for the YOLOv5 framework was also acquired.
文献阅读:用于视频识别的快慢网络
Title: SlowFast Networks for Video Recognition
Author:Christoph Feichtenhofer Haoqi Fan Jitendra Malik Kaiming H
From:2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
1、文献摘要
随着深度学习和计算机视觉技术的快速发展,视频行为识别成为了一个备受关注的研究领域。文献提出了用于视频识别的SlowFast网络,模型包括:(i)以低帧速率的慢速路径来捕获空间语义;(ii)以高帧速率的快速路径来捕获精细时间分辨率的运动。快速路径可以通过减少通道容量而变得非常轻量级,并且可以学习有用的时间信息用于视频识别。文献的 SlowFast 模型在视频中的行为分类和检测方面都取得了很好的性能,概念也有很大的改进。SlowFast 模型在没有使用任何预训练的情况下,得到Kinetics数据集的准确率为79.0%,AVA数据集的mAP为28.2%。
2、提出方法
2.1、SlowFast模型
文献提出了SlowFast模型,SlowFast模型网络是一种用于视频识别任务的深度学习模型。它的核心思想是将两种不同帧率的路径(慢途径和快途径)结合在一起,以便更好地捕捉视频中的时空特征。一个慢途径和一个快途径。慢途径以较低的帧率运行,负责处理低帧率下的信息,这意味着它具有较低的时间分辨率。然而,由于较低的帧率,它可以处理更长的时间跨度,从而捕捉到视频中的长期依赖关系,具有较低的时间分辨率;而快途径以较高的帧率运行,负责处理高帧率下的信息,具有较高的时间分辨率。这意味着它可以更敏感地捕捉到视频中的快速变化和短期动态。在实际应用中,SlowFast网络会将慢途径和快途径的特征进行融合,以便同时利用两种途径的优势。这种设计使得SlowFast网络在处理视频识别任务时能够取得较好的性能。
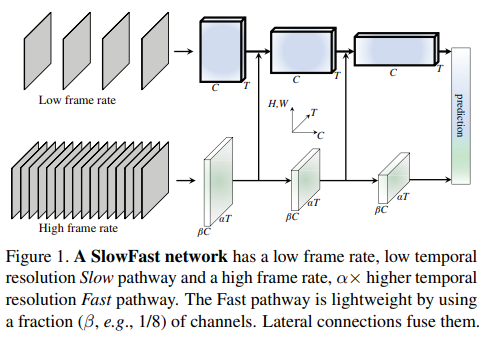
2.2、SlowFast 提出思想
SlowFast模型是受到灵长类动物视觉系统中视网膜神经节细胞的生物学研究启发的。这些细胞中约80%是小细胞(P-cells),它们提供精细的空间细节和颜色信息,但时间分辨率较低;而约15-20%是大细胞(M-cells),它们对快速时间变化敏感,但对空间细节或颜色不敏感。视觉内容的分类空间语义通常变化缓慢,而运动可以比它们的主题身份变化快得多。因此,Slow路径设计用于捕获可以由图像或少数稀疏帧提供的信息,而Fast路径则负责捕获快速变化的运动,基于这些理论研究,提出了快慢路径融合的方法。
3、相关方法
3.1、时空间卷积
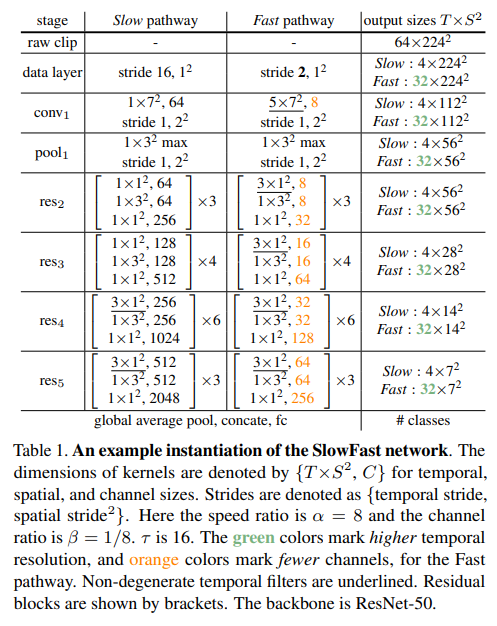
在视频处理和分析中同时对视频帧的空间维度(即图像的宽度和高度)和时间维度进行卷积操作。其能够捕捉视频中的局部空间特征(如纹理和形状)以及随时间变化的特征(如物体的运动)。这种卷积操作通常在3D CNN中实现,其中卷积核在视频的帧序列上滑动,从而提取出具有时间连续性的特征。时间空间卷积可以有效地捕捉视频中的动作模式,因为它们能够考虑到帧与帧之间的时间关系。这使得3D CNN特别适合于动作识别、视频分类和其他需要理解视频中时间动态的任务。 时间空间卷积的核心优势在于其能够同时处理空间和时间信息,生成一个综合了视觉内容和运动信息的特征表示,这对于准确的视频内容分析至关重要。下图为SlowFast的网络结构表,其中T x S2的T为时间维度,S为普通的二维内容。
3.2、基于光流的视频识别
基于光流的视频识别是一种利用视频中物体运动信息来进行动作识别或视频内容分析的方法。光流(Optical Flow)是指图像中物体亮度模式的移动,它是由场景中物体的运动引起的。它通过分析视频中连续帧之间像素点的移动来捕捉物体的运动信息,光流图像可以被转换成特征向量,这些特征向量可以描述物体的运动模式,从而识别视频中的动作或事件。这种技术尤其适合于理解视频中的动态变化,因为它直接提取了物体运动的速度和方向。
3.3、横向连接(Lateral connections)
Lateral connections指的是在神经网络中用于连接不同路径或层的连接,特别是在SlowFast网络中,它们被用于将信息从Fast pathway融合到Slow pathway。这些连接允许两个路径在不同时间速度上处理信息,并通过合并它们的特征来提高网络的整体性能。在SlowFast网络中,这些lateral connections有助于结合两个路径的优势,从而更有效地进行视频分类任务。
需要注意的是横向连接具有以下三种方式,文献中主要使用的是T-conv方法,因其简单性和有效性而被选作默认的融合方式。通过这种方式,Fast pathway的特征被有效地合并到Slow pathway中,使得网络能够更好地利用视频数据中的时间和空间信息来进行视频分类任务。
- Time-to-channel (TtoC):这是一种通过重塑和转置Fast pathway的特征来匹配Slow pathway的特征的方法。它将Fast pathway的输出(具有高时间分辨率和低通道容量)转换为与Slow pathway的输出具有相同的时间维度和通道维度的形式,然后通过求和或拼接的方式将其与Slow pathway的输出融合。
- Time-strided sampling (T-sample):这种方法通过时间步长对Fast pathway的输出进行下采样,使其与Slow pathway的输出在时间维度上匹配,然后再将它们融合。
- Time-strided convolution (T-conv):这种方法应用了时间步长卷积,它通过在时间维度上应用1×1卷积来减少Fast pathway的通道数,使其与Slow pathway的输出相匹配,然后将它们融合。
4、实验工作
4.1、动作分类实验
使用动作分类的数据集包括UCF-Crime、Kinetics、HMDB-51、UCF-101,使用这些数据集评估SlowFast的模型性能,并使用标准的评估协议。除此之外选择了诸如top-1准确率(Top-1 Accuracy)、top-5准确率(Top-5 Accuracy)和GFLOPs(Giga Floating-point Operations Per Second,用于衡量模型的计算量)等指标来评价模型性能,以下是使用这些标准与其他模型进行性能对比的实验图。
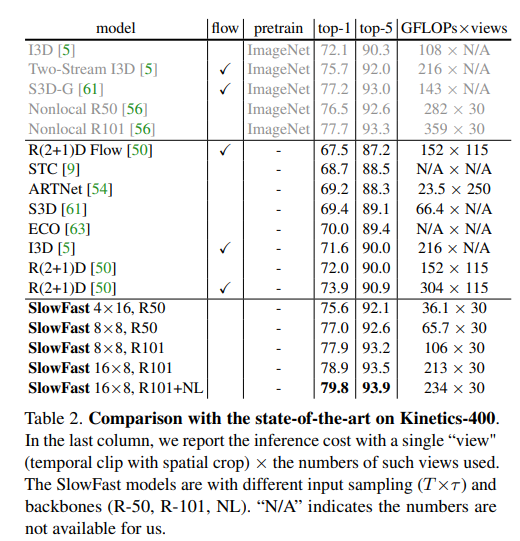
在Kinetics-400数据集上,SlowFast(绿色)与仅Slow(蓝色)架构的准确性与复杂性权衡。在所有情况下,SlowFast始终优于其仅Slow对应物(绿色箭头)。SlowFast比时间密集型的仅Slow(例如红色箭头)提供更高的准确性和更低的成本。
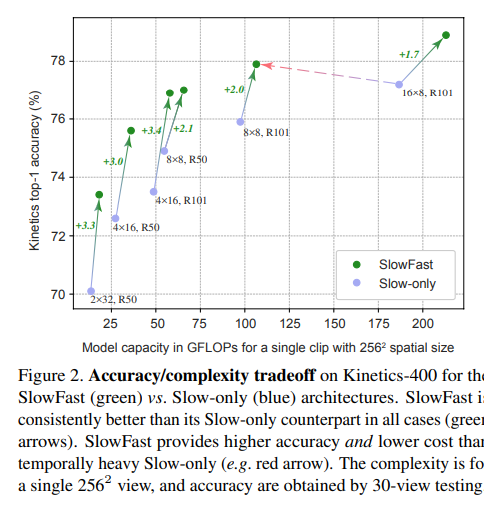
Kinetics-600数据集上与最先进技术的比较,其中包含不同规格的SlowFast模型。
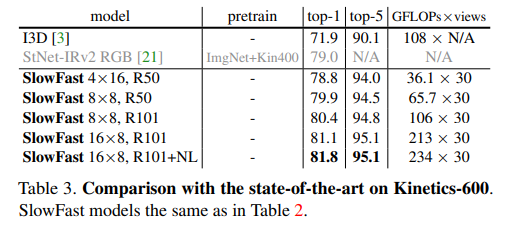
Charades数据集上与最先进技术的比较,其中包含不同规格的SlowFast模型。
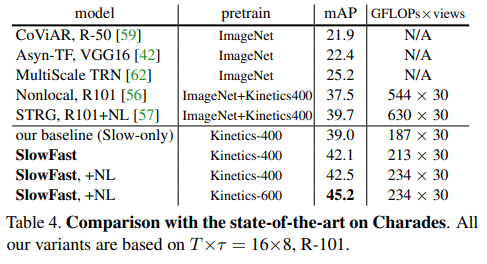
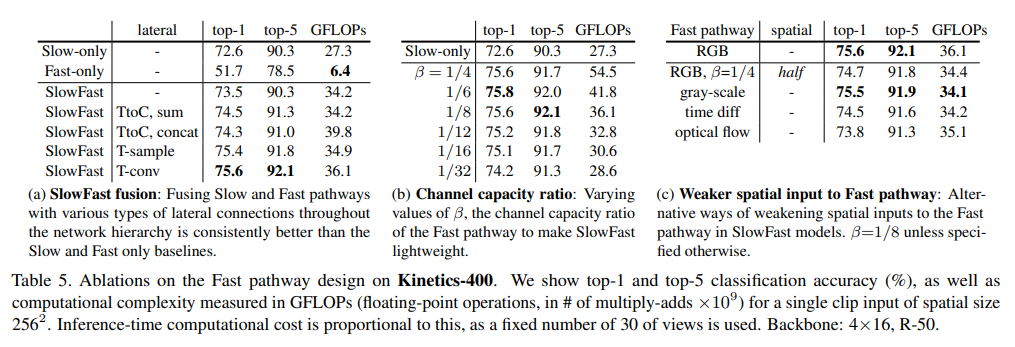
4.2、消融实验
文献的消融实验主要关注于评估SlowFast网络中各个组件对视频识别性能的具体贡献。通过改变网络的不同部分,如调整Fast路径的通道容量比例、融合方式、以及对Fast路径输入的空间信息进行减弱等,研究者能够逐一分析这些变化对模型准确度的影响。例如,通过减少Fast路径的通道数,研究者发现即使在降低计算量的情况下,网络仍能有效捕捉运动信息。此外,实验还发现,即使是灰度图像或时间差分图像,Fast路径也能提供与RGB图像相似的性能,同时减少计算量。这些发现表明,SlowFast网络的Fast路径是一个高效且轻量级的视频识别组件。
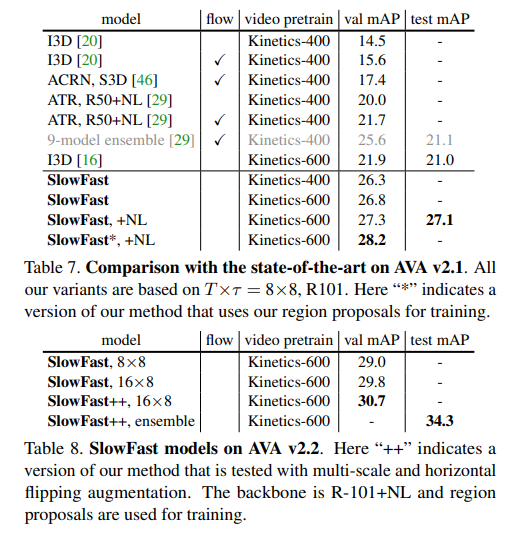
在AVA数据集上的动作检测任务中,消融实验进一步证明了SlowFast网络相比于仅使用Slow路径的模型在性能上的显著提升。通过对比Slow-only基线和SlowFast模型的每类平均精度(AP),研究者发现SlowFast模型在多个动作类别上都有较大的增益,尤其是在那些动态性较强的动作上。这些实验结果不仅验证了SlowFast网络设计的有效性,也为后续的视频识别研究提供了宝贵的洞察。
5、总结
论文提出了一种创新的视频识别框架——SlowFast网络,它通过结合两个互补的子网络来同时捕捉视频中的空间语义和动态运动信息。Slow路径负责处理低帧率视频,以提取缓慢变化的视觉内容,而Fast路径则以高帧率运行,专注于捕获快速运动的细节。这种架构使得模型能够灵活地处理视频中的复杂动态,同时保持计算效率。论文中的实验表明,SlowFast网络在多个视频识别基准测试中取得了突破性的性能,包括Kinetics、Charades和AVA数据集,验证了其设计的有效性。此外,作者还提供了模型的开源代码,鼓励社区进一步探索和改进视频识别技术。这一研究不仅推动了视频识别领域的进展,也为未来在视频理解和分析方面的研究提供了新的思路和工具。
YOLO V5 – 架构学习
yolo V5总体结构图:
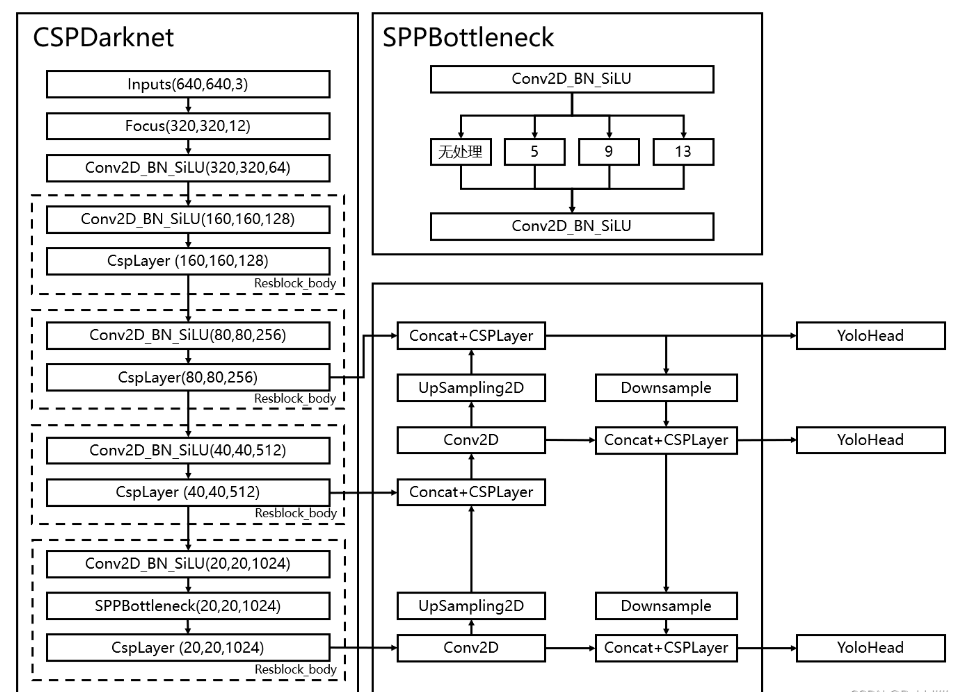
Backbone – CSPDarknet
YOLOv5的设计中采用了多种技术来提高效率和准确性,其中之一就是 Cross Stage Partial Network(CSPNet)的概念。
CSPDarknet 是 YOLOv5 架构中的一个组件,它是一种特殊的网络结构,用于减少计算复杂度和模型大小,同时尽量保持检测性能。CSP 的核心思想是在网络的每个阶段只使用部分计算资源来处理输入,而不是全部资源。这种方法可以显著减少模型的参数数量和计算量,从而加快推理速度,特别是在资源受限的环境中。
Backbone CSPDarknet 代码实现
下列代码结构完全按照上述结构图实现,其中输入图片是640, 640, 3,且初始的基本通道base_channels是64。
class CSPDarknet(nn.Module):
def __init__(self, base_channels, base_depth, phi, pretrained):
super().__init__()
# 利用focus网络结构进行特征提取
# 640, 640, 3 -> 320, 320, 12 -> 320, 320, 64
self.stem = Focus(3, base_channels, k=3)
# 完成以下卷积之后,320, 320, 64 -> 160, 160, 128
self.dark2 = nn.Sequential(
# 320, 320, 64 -> 160, 160, 128
Conv(base_channels, base_channels * 2, 3, 2),
# 160, 160, 128 -> 160, 160, 128
C3(base_channels * 2, base_channels * 2, base_depth),
)
# 完成卷积之后,160, 160, 128 -> 80, 80, 256
# 完成CSPlayer之后,80, 80, 256 -> 80, 80, 256
self.dark3 = nn.Sequential(
Conv(base_channels * 2, base_channels * 4, 3, 2),
C3(base_channels * 4, base_channels * 4, base_depth * 3),
)
# 完成卷积之后,80, 80, 256 -> 40, 40, 512
# 完成CSPlayer之后,40, 40, 512 -> 40, 40, 512
self.dark4 = nn.Sequential(
Conv(base_channels * 4, base_channels * 8, 3, 2),
C3(base_channels * 8, base_channels * 8, base_depth * 3),
)
# 完成卷积之后,40, 40, 512 -> 20, 20, 1024
# 完成SPP之后,20, 20, 1024 -> 20, 20, 1024
self.dark5 = nn.Sequential(
Conv(base_channels * 8, base_channels * 16, 3, 2),
SPP(base_channels * 16, base_channels * 16),
C3(base_channels * 16, base_channels * 16, base_depth, shortcut=False),
)
def forward(self, x):
x = self.stem(x)
x = self.dark2(x)
# dark3的输出为80, 80, 256,是一个有效特征层
x = self.dark3(x)
feat1 = x
# dark4的输出为40, 40, 512,是一个有效特征层
x = self.dark4(x)
feat2 = x
# dark5的输出为20, 20, 1024,是一个有效特征层
x = self.dark5(x)
feat3 = x
##此处返回的为进入FPN三个层次
return feat1, feat2, feat3
FPN 代码实现
class YoloBody(nn.Module):
def __init__(self, anchors_mask, num_classes, phi, backbone='cspdarknet', pretrained=False, input_shape=[640, 640]):
super(YoloBody, self).__init__()
base_channels = int(wid_mul * 64) # 64
base_depth = max(round(dep_mul * 3), 1) # 3
# 生成CSPdarknet53的主干模型
# 获得三个有效特征层,他们的shape分别是:
# 80,80,256
# 40,40,512
# 20,20,1024
self.backbone = CSPDarknet(base_channels, base_depth, phi, pretrained)
feat1_c, feat2_c, feat3_c = in_channels
self.conv_1x1_feat1 = Conv(feat1_c, base_channels * 4, 1, 1)
self.conv_1x1_feat2 = Conv(feat2_c, base_channels * 8, 1, 1)
self.conv_1x1_feat3 = Conv(feat3_c, base_channels * 16, 1, 1)
self.upsample = nn.Upsample(scale_factor=2, mode="nearest")
self.conv_for_feat3 = Conv(base_channels * 16, base_channels * 8, 1, 1)
self.conv3_for_upsample1 = C3(base_channels * 16, base_channels * 8, base_depth, shortcut=False)
self.conv_for_feat2 = Conv(base_channels * 8, base_channels * 4, 1, 1)
self.conv3_for_upsample2 = C3(base_channels * 8, base_channels * 4, base_depth, shortcut=False)
self.down_sample1 = Conv(base_channels * 4, base_channels * 4, 3, 2)
self.conv3_for_downsample1 = C3(base_channels * 8, base_channels * 8, base_depth, shortcut=False)
self.down_sample2 = Conv(base_channels * 8, base_channels * 8, 3, 2)
self.conv3_for_downsample2 = C3(base_channels * 16, base_channels * 16, base_depth, shortcut=False)
# 80, 80, 256 => 80, 80, 3 * (5 + num_classes) => 80, 80, 3 * (4 + 1 + num_classes)
self.yolo_head_P3 = nn.Conv2d(base_channels * 4, len(anchors_mask[2]) * (5 + num_classes), 1)
# 40, 40, 512 => 40, 40, 3 * (5 + num_classes) => 40, 40, 3 * (4 + 1 + num_classes)
self.yolo_head_P4 = nn.Conv2d(base_channels * 8, len(anchors_mask[1]) * (5 + num_classes), 1)
# 20, 20, 1024 => 20, 20, 3 * (5 + num_classes) => 20, 20, 3 * (4 + 1 + num_classes)
self.yolo_head_P5 = nn.Conv2d(base_channels * 16, len(anchors_mask[0]) * (5 + num_classes), 1)
def forward(self, x):
# backbone
feat1, feat2, feat3 = self.backbone(x)
if self.backbone_name != "cspdarknet":
feat1 = self.conv_1x1_feat1(feat1)
feat2 = self.conv_1x1_feat2(feat2)
feat3 = self.conv_1x1_feat3(feat3)
# 20, 20, 1024 -> 20, 20, 512
P5 = self.conv_for_feat3(feat3)
# 20, 20, 512 -> 40, 40, 512
P5_upsample = self.upsample(P5)
# 40, 40, 512 -> 40, 40, 1024
P4 = torch.cat([P5_upsample, feat2], 1)
# 40, 40, 1024 -> 40, 40, 512
P4 = self.conv3_for_upsample1(P4)
# 40, 40, 512 -> 40, 40, 256
P4 = self.conv_for_feat2(P4)
# 40, 40, 256 -> 80, 80, 256
P4_upsample = self.upsample(P4)
# 80, 80, 256 cat 80, 80, 256 -> 80, 80, 512
P3 = torch.cat([P4_upsample, feat1], 1)
# 80, 80, 512 -> 80, 80, 256
P3 = self.conv3_for_upsample2(P3)
# 80, 80, 256 -> 40, 40, 256
P3_downsample = self.down_sample1(P3)
# 40, 40, 256 cat 40, 40, 256 -> 40, 40, 512
P4 = torch.cat([P3_downsample, P4], 1)
# 40, 40, 512 -> 40, 40, 512
P4 = self.conv3_for_downsample1(P4)
# 40, 40, 512 -> 20, 20, 512
P4_downsample = self.down_sample2(P4)
# 20, 20, 512 cat 20, 20, 512 -> 20, 20, 1024
P5 = torch.cat([P4_downsample, P5], 1)
# 20, 20, 1024 -> 20, 20, 1024
P5 = self.conv3_for_downsample2(P5)
#---------------------------------------------------#
# 第三个特征层
# y3=(batch_size,75,80,80)
#---------------------------------------------------#
out2 = self.yolo_head_P3(P3)
#---------------------------------------------------#
# 第二个特征层
# y2=(batch_size,75,40,40)
#---------------------------------------------------#
out1 = self.yolo_head_P4(P4)
#---------------------------------------------------#
# 第一个特征层
# y1=(batch_size,75,20,20)
#---------------------------------------------------#
out0 = self.yolo_head_P5(P5)
return out0, out1, out2
总结
本周主要阅读了CVPR文章, SlowFast Networks for Video Recognition。SlowFast模型网络是一种用于视频识别任务的深度学习模型。它的核心思想是将两种不同帧率的路径(慢途径和快途径)结合在一起,以便更好地捕捉视频中的时空特征。一个慢途径和一个快途径。慢途径以较低的帧率运行,负责处理低帧率下的信息,这意味着它具有较低的时间分辨率;而快途径以较高的帧率运行,负责处理高帧率下的信息,具有较高的时间分辨率。除了阅读文献之外,还学习了yoloV5框架的代码知识。下周再接再厉!