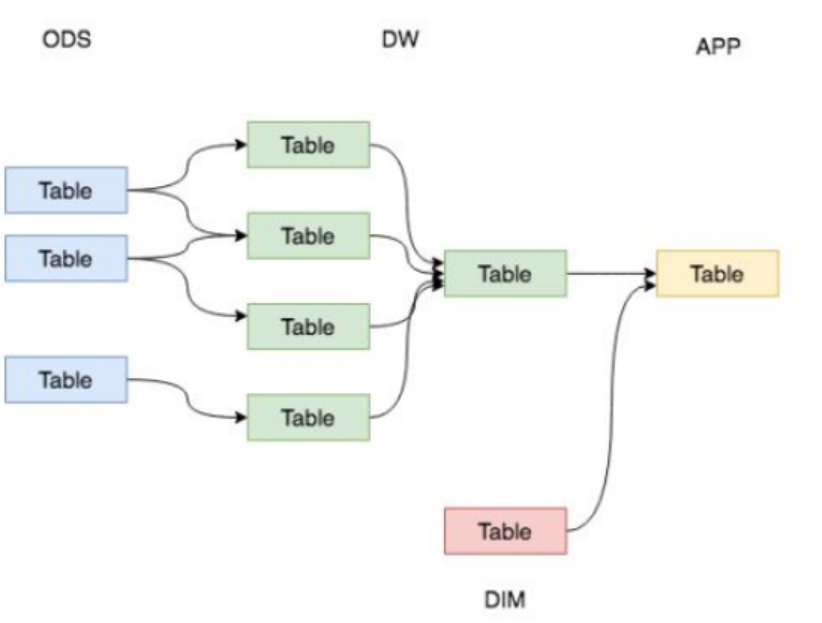
在概要设计阶段,技术方案选型是核心环节之一,需综合考虑系统需求、技术可行性、团队能力及长期维护成本。以下是技术方案选型需包含的核心内容及设计要点,结合行业实践和搜索结果中的方法论:
理论
一、系统架构选型
- 整体架构模式
- 选择分层架构(如MVC、DDD领域驱动设计)、微服务架构、事件驱动架构等,需明确各层职责和交互方式。
- 示例:若系统需高并发处理,可选微服务架构;若业务逻辑复杂,可结合DDD划分领域边界. 技术选型依据
- 成熟度:优先选择经过验证的技术(如Redis缓存、Kafka消息队列),避免过度追求新技术带来的风险。
- 兼容性:确保与现有系统(如数据库、第三方服务)的技术栈兼容,减少集成成本。
- 扩展性:支持未来业务增长,例如通过分库分表、弹性伸缩设计应对数据量增长。
二、技术栈选型
-
核心组件选型
- 存储方案:关系型数据库(MySQL、PostgreSQL)或NoSQL(MongoDB、Cassandra),需根据数据一致性要求选择。
- 中间件:消息队列(Kafka、RabbitMQ)、缓存(Redis、Memcached)、搜索引擎(Elasticsearch)等。
- 开发框架:后端框架(Spring Boot、Go Gin)、前端框架(React、Vue)等,需匹配团队技术能力。
-
工具链选型
- 持续集成/持续部署(CI/CD)工具(Jenkins、GitLab CI)、监控工具(Prometheus、SkyWalking)、日志系统(ELK Stack)等。
三、数据模型与存储设计
-
数据模型设计
- 定义实体关系(ER模型)、范式优化(如第三范式平衡冗余与查询效率),明确主键、索引策略。
- 示例:用户订单表需包含订单状态、时间戳等字段,结合业务场景设计冗余字段提升查询性能。
-
存储方案选型
- 根据数据量、读选择存储类型:
- 热数据:内存数据库(Redis)或SSD存储。
- 冷数据:对象存储(MinIO、AWS S3)或归档存储。
- 根据数据量、读选择存储类型:
四、接口与交互设计
-
API设计规范
- 定义RESTful或GraphQL接口,明确请求/响应格式(JSON/XML)、状态码、鉴权方式(OAuth2、JWT)。
- 示例:用户登录接口需返回Token并设置有效期,支持OAuth2.0第三方登录。
-
上下游系统交互
- 确定交互模式(推/拉)、协议(HTTP/HTTPS、gRPC)、数据格式(Protobuf、Avro),明确系统边界与责任。
五、安全性设计
-
数据安全
- 加密策略:传输层(TLS/SSL)、存储层(AES加密敏感字段)。
- 防攻击措施:SQL注入防护、XSS过滤、限流熔断(Sentinel、Hystrix)。
-
权限控制
- 基于角色的访问控制(RBAC)或属性基访问控制(ABAC),结合审计日志追踪操作记录。
六、性能与可维护性
-
性能优化方案
- 缓存策略(本地缓存+分布式缓存)、异步处理(消息队列削峰)、数据库读写分离。
- 示例:秒杀场景使用Redis预减库存+消息队列异步下单。
-
可维护性设计
- 模块化设计:高内聚低耦合,通过接口隔离变化。
- 日志与监控:全链路日志追踪(如Zipkin)、性能监控(APM工具)。
七、团队适配性评估
-
技术能力匹配
- 评估团队对选型技术的熟悉程度,避免引入需长期学习的新技术。
- 示例:若团队熟悉Java生态,优先选择Spring Cloud而非Go语言微服务框架。
-
工具链支持
- 确保开发、测试、运维工具链完善,降低学习成本(如使用IntelliJ IDEA作为IDE)。
八、成本与风险评估
-
成本分析
- 硬件成本(云服务器、存储)、软件成本(商业授权)、人力成本(学习与维护)。
- 示例:开源方案(如MySQL)可降低授权成本,但需评估社区支持力度。
-
风险预案
- 技术风险:如Redis集群故障时的降级方案(切换至本地缓存)。
- 业务风险:预留扩展接口应对需求变更。
九、选型验证与决策
- 原型验证
- 通过PoC(概念验证)验证关键技术点,例如测试Redis集群在高并发下的稳定性。
- 决策文档
- 记录选型依据、对比分析(如MySQL vs. PostgreSQL)、风险评估,形成《技术选型报告》。
总结
技术方案选型需围绕业务需求和团队能力展开,平衡技术先进性与落地可行性。关键点包括:架构模式、技术栈适配性、数据模型合理性、安全性及成本效益。建议通过可视化工具(如C4模型、架构图)清晰表达选型逻辑,确保干系人共识。
实战
以下是为短域名系统设计的技术方案选型内容,基于Go语言、阿里云Redis/MySQL、Gin框架等技术栈,结合行业实践和搜索结果中的设计思路:
一、系统架构设计
1. 整体架构模式
- 分层架构:采用经典的三层架构(接口层、业务逻辑层、数据存储层),结合微服务思想解耦核心模块。
- 通信协议:HTTP/HTTPS协议,支持RESTful API设计。
- 交互模式:短链生成(POST请求)、短链解析(GET请求重定向)。
2. 核心模块划分
- 短链生成模块:负责将长URL转换为短码。
- 存储模块:持久化存储长URL与短码映射关系。
- 缓存模块:加速高频访问的短链解析。
- 安全模块:防遍历、防重复生成、限流等。
二、技术选型明细
1. 核心组件
| 组件 | 技术选型 | 选型依据 |
|---|---|---|
| 开发语言 | Go | 高并发性能优异,生态完善,适合微服务场景 |
| Web框架 | Gin | 轻量级、高性能,支持中间件快速开发 |
| 数据库 | 阿里云MySQL | 关系型数据库,支持事务和复杂查询,用于持久化存储映射关系 |
| 缓存 | 阿里云Redis | 支持高并发读写,用于缓存短链映射、布隆热点数据 |
| ORM工具 | GORM | 简化MySQL操作,支持事务、预加载、连接池管理 |
2. 关键算法与工具
- 短码生成算法:
- 发号器模式:基于MySQL自增ID或Redis的
INCR命令生成全局唯一ID,转换为62进制短码(字符集:a-z, A-Z, 0-9)。 - 防遍历优化:ID生成时加盐(如时间戳或随机数),避免短码规律性暴露。
- 发号器模式:基于MySQL自增ID或Redis的
- 布隆过滤器:Redis实现,用于快速判断长URL是否已存在,减少重复存储。
- 重定向策略:HTTP 302重定向,支持后续修改跳转目标(如统计需求)。
3. 存储设计
- MySQL表结构:
CREATE TABLE url_mapping ( id BIGINT AUTO_INCREMENT PRIMARY KEY COMMENT '自增主键', short_code VARCHAR(10) UNIQUE COMMENT '短码(7位62进制)', long_url TEXT NOT NULL COMMENT '原始长URL', expire_at DATETIME COMMENT '过期时间', created_at DATETIME DEFAULT CURRENT_TIMESTAMP, INDEX idx_short_code (short_code) ) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4; - Redis数据结构:
- Hash:存储短码→长URL的映射(
HSET short_urls: sBc http://long.url)。 - 布隆过滤器:判断长URL是否已生成过短码。
- Sorted Set:按过期时间排序,定期清理。
- Hash:存储短码→长URL的映射(
4. 性能优化方案
- 缓存策略:
- 本地缓存:使用Go的
sync.Map缓存热点短码→长URL映射(TTL 5分钟)。 - Redis缓存:设置短码映射的TTL为24小时,结合LRU淘汰策略。
- 本地缓存:使用Go的
- 异步处理:长URL的合法性校验(如HTTP状态码检查)通过Goroutine异步执行。
- 分库分表:若数据量超10亿,按短码首字符分库(如
shard_0~shard_9)。
5. 安全设计
- 防重复生成:通过布隆过滤器和Redis唯一键约束双重校验。
- 防遍历攻击:
- 短码生成时加入随机盐(如
short_code = base62(id + salt))。 - 限制同一IP的生成频率(如每分钟≤10次)。
- 短码生成时加入随机盐(如
- HTTPS加密:强制使用HTTPS协议,防止中间人篡改。
三、接口设计示例
1. 生成短链接口
- URL:
POST /api/generate - 请求体:
{ "long_url": "https://example.com/very/long/url", "custom_code": "abc123" // 可选自定义短码 } - 响应:
{ "short_url": "https://short.url/sBc" } - 逻辑:
- 检查
custom_code是否已存在(Redis查询)。 - 若无,生成新ID→转62进制→校验唯一性。
- 写入MySQL并缓存到Redis。
- 检查
2. 解析短链接口
- URL:
GET /:short_code - 逻辑:
- 从Redis缓存获取长URL。
- 未命中则查询MySQL,回填缓存。
- 返回HTTP 302重定向。
四、部署与运维
1. 基础设施
- 阿里云ECS:部署Go服务,配置自动扩缩容(按CPU/内存使用率)。
- Redis集群:主从架构+哨兵模式,保障高可用。
- MySQL集群:主库+读写分离从库,定期备份至OSS。
2. 监控与日志
- 监控指标:
- QPS、响应延迟、缓存命中率、Redis内存使用率。
- 日志方案:
- ELK(Elasticsearch+Logstash+Kibana)集中分析。
- 关键日志:短链生成/解析耗时、错误请求。
3. 容灾方案
- 异地多活:在华东、华南部署双活集群,通过DNS分流流量。
- 故障转移:Redis/MySQL主节点宕机时,自动切换至备节点。
五、风险与应对
- ID耗尽风险:
- 7位62进制ID可支持约50亿条数据,按日均10万QPS计算,可用约14年。若需扩展,可增加短码长度至8位。
- 缓存雪崩:
- 设置Redis缓存过期时间的随机偏移(如
TTL = 3600 ± 600秒)。
- 设置Redis缓存过期时间的随机偏移(如
- 数据库写入瓶颈:
- 批量写入(如每100条合并提交),减少MySQL事务开销。
六、技术验证
- 压力测试:
- 使用
wrk或hey模拟高并发请求,验证Redis和MySQL的吞吐量。
- 使用
- 故障演练:
- 模拟Redis主节点宕机,观察服务降级和自动切换流程。
通过以上选型,系统可实现高并发(10万QPS)、低延迟(<10ms)和高可用(99.99%),同时满足低成本运维需求。